
【论文导读】2024年论文导读第二十一期
【论文导读】2024年论文导读第二十一期
CCF多媒体专委会 2024年10月22日 18:48 北京


论文导读
2024年论文导读第二十一期(总第一百一十二期)
目 录
|
1 |
Occlusion-Aware Feature Recover Model for Occluded Person Re-Identification |
|
2 |
GPT-based Knowledge Guiding Network for Commonsense Video Captioning |
|
3 |
Spectrum-Driven Mixed-Frequency Network for Hyperspectral Salient Object Detection |
|
4 |
FreqAlign: Excavating Perception-Oriented Transferability for Blind Image Quality Assessment From a Frequency Perspective |
|
5 |
Improving Adaptive Real-Time Video Communication via Cross-Layer Optimization |
01
Occlusion-Aware Feature Recover Model for Occluded Person Re-Identification
作者:
边远1,2、刘敏1,2*、王学平3、唐毅1,2、王耀南1,2
单位:
1湖南大学电气与信息工程学院
2机器人视觉感知与控制技术国家工程研究中心
3湖南师范大学信息科学与工程学院
邮箱:
yuanbian@hnu.edu.cn,
liu_min@hnu.edu.cn,
wang_xueping@hnu.edu.cn,
tyhnu@hnu.edu.cn,
yaonan@hnu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10314802
代码:
https://github.com/yuanbianGit/OAFR
发表期刊:TMM2023
*通讯作者
1.研究背景
行人再识别(Re-ID)用于从多个不重叠摄像机视角中识别相同的目标行人。然而,在实际应用场景中,行人通常会被其他人或静态物体(如车辆、建筑物等)部分遮挡,导致行人特征丢失或混淆,进而对识别结果产生负面影响。现有的遮挡行人再识别方法通常依赖于辅助模型,如姿态估计和人体解析模型,来识别未遮挡的部分,从而消除遮挡引入的噪声。然而,这些方法计算开销大,难以应对行人之间的遮挡(即人对人遮挡)问题。此外,仅依靠未遮挡部
分进行匹配也可能不足,因为某些情况下,遮挡的行人与查询图像之间可能没有共同的可见部分或显著特征。为了解决这些问题,本文提出了一种遮挡感知的特征恢复模型,该模型通过模拟各种遮挡场景,提高模型处理不同遮挡情况的能力,并通过恢复遮挡的行人特征来改善识别效果。

2.论文方法
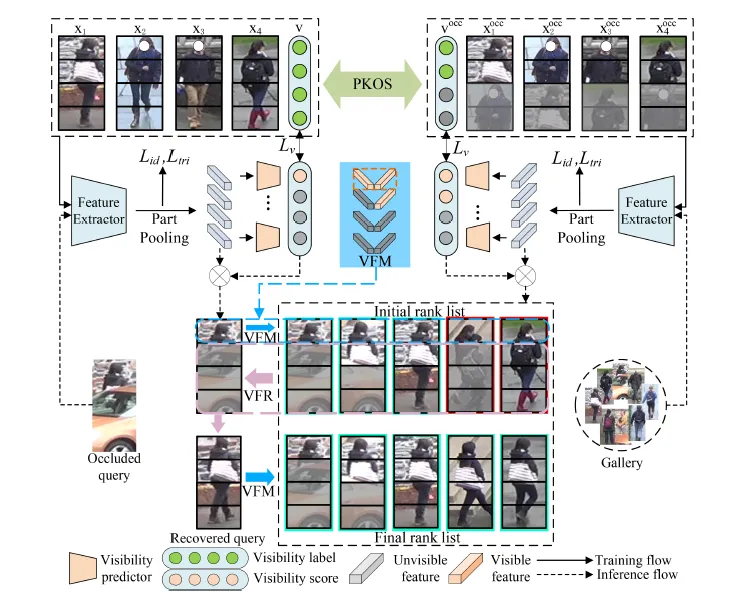
本文提出了一种创新的遮挡感知特征恢复模型(Occlusion-Aware Feature Recover, OAFR),该模型通过遮挡感知和特征恢复机制解决遮挡行人再识别中的特征丢失与遮挡干扰问题。模型的主要构成包括:先验知识遮挡模拟模块(PKOS)、可见性引导的特征匹配模块(VFM)和可见性引导的特征恢复模块(VFR)。
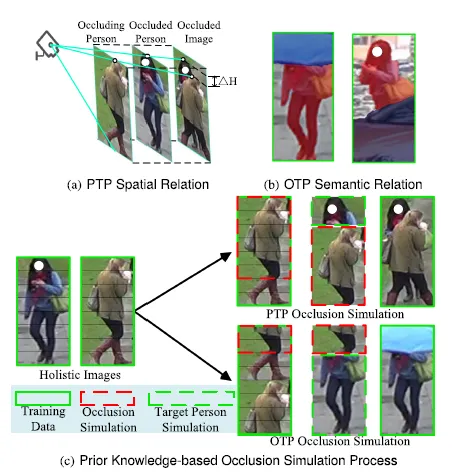
为了增强模型在遮挡场景下的鲁棒性,本文提出了一种基于先验知识的遮挡模拟方法。该模块用于模拟不同类型的遮挡场景,包括行人与行人之间的遮挡(Person-to-Person,PTP)和行人与物体之间的遮挡(Object-to-Person,OTP)。具体来说,利用自监督学习的方式,通过观察摄像机视角下的空间和语义遮挡关系,合成多种遮挡情况。例如,在PTP遮挡场景中,遮挡者通常出现在被遮挡行人的下方部分,而在OTP遮挡中,遮挡物的语义信息与目标行人的语义信息无关。基于此,模型能够通过这些遮挡模拟数据学习遮挡区域的空间关系和语义差异,从而提高在实际遮挡场景中的表现。
为了解决遮挡噪声对特征相似度计算的干扰,本文设计了一个可见性引导的特征匹配模块(Visibility-guided Feature Matching,VFM)。该模块通过预测图像中各部分的可见性得分,来引导特征相似度的计算,从而减少遮挡部分对特征匹配的负面影响。可见性得分预测器首先在自监督学习的框架下进行训练。利用遮挡模拟过程中生成的遮挡标签,模型可以有效预测目标行人身体各部分的可见性,而不依赖额外的辅助模型。在推理阶段,模型将输入图像划分为多个部分,并预测每个部分的可见性得分。
在特征匹配模块生成初步匹配结果后,本文引入特征恢复模块以提升遮挡行人的特征完整性。首先从前K个候选图像中选取与查询图像有较多可见部分重合的图像,然后利用这些图像的局部特征替换查询图像中被遮挡的部分。为确保恢复的鲁棒性,本文采用了基于可见性加权平均的特征替换方法,按可见性得分对恢复部分进行加权平均。该方法既保留了查询图像中的原有未遮挡特征,又通过候选图像的可见特征弥补了被遮挡的信息缺失。
3.实验结果
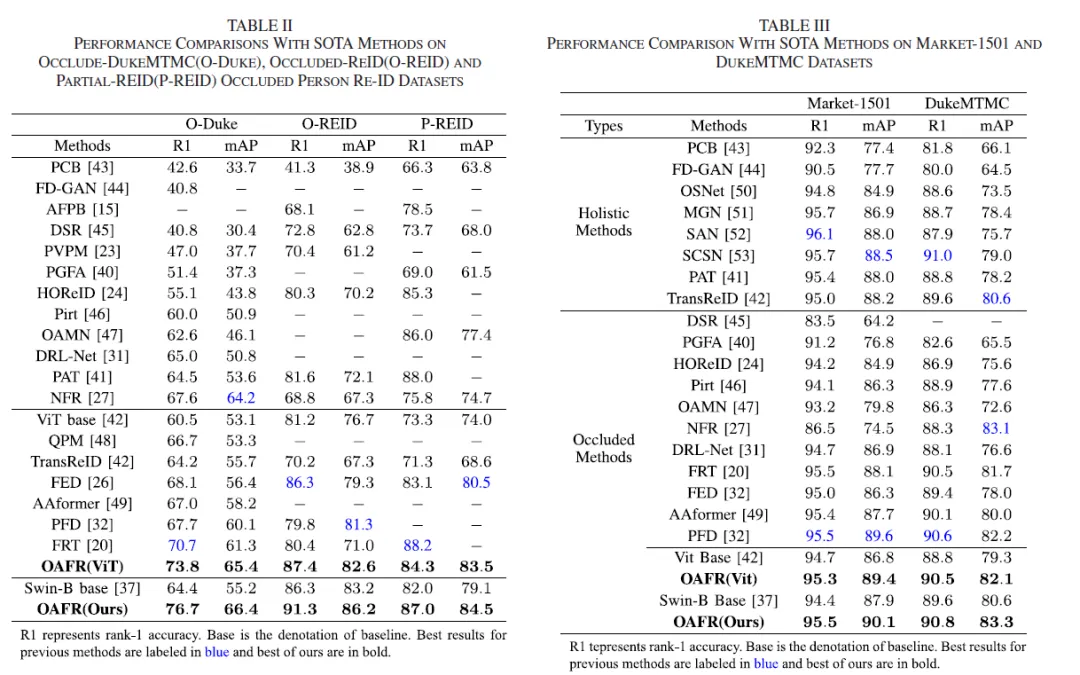
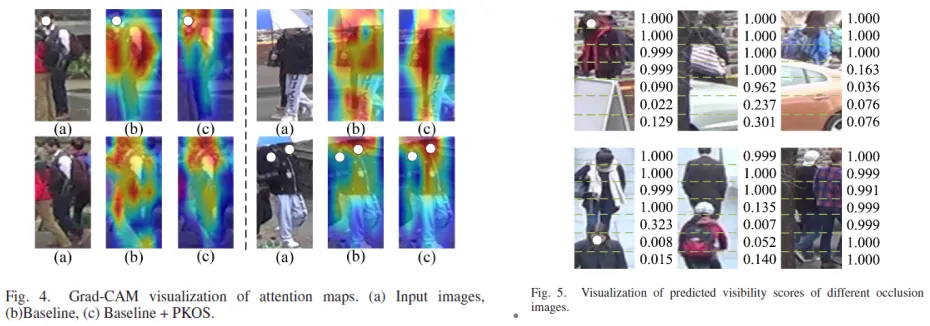
实验结果表明,本文提出的模型在多个数据集上优于现有方法,特别是Occluded-DukeMTMC数据上表现显著提升,在Rank-1精度上超过SOTA方法6.0%。多个可视化结果也说明了所提出各模块的有效性。
02
GPT-based Knowledge Guiding Network for Commonsense Video Captioning
作者:
袁梦奇1, 贾耕云1, 鲍秉坤*1
单位:
1南京邮电大学
邮箱:
2020010306@njupt.edu.cn,
gengyun.jia@njupt.edu.cn,
bingkunbao@njupt.edu.cn
论文:
https://ieeexplore.ieee.org/document/10310122
代码:
https://github.com/yuan687198/TKG-Net
发表期刊:TMM2023
*通讯作者
1.研究背景
基于视频的常识描述生成是一个跨模态生成任务,它需要模型不光生成视频内容的文本描述,还需要生成视频背后所包含的常识描述。其中常识描述具体可包括三个部分:视频中人物的意图、视频中事件会产生什么样的影响、视频中人物或事件的属性特点,如图1(a)所示。
前人的方法一般采用编解码器的架构,它们首先提取视频中的视觉特征来生成视频内容的描述,并将视频特征和视频内容描述结合起来,通过解码器生成关于视频背后的常识描述。然而,它们难以处理不可见的常识和可见的视频之间存在的复杂语义鸿沟的问题。针对此问题,我们引入在外部大规模语料库上预训练的GPT模型。通过借助GPT丰富的想象力和推理能力,来支持可见的视频和不可见的常识之间的复杂关系学习,如图1(b)所示。
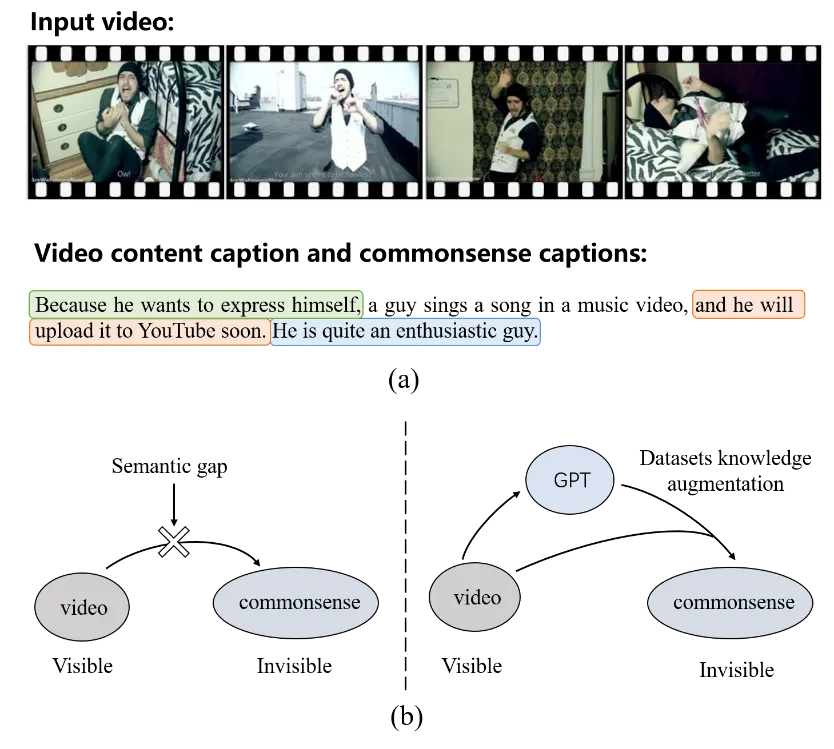
图1(a)基于视频生成的常识文本样例。(b)我们引入GPT处理视频和常识间的复杂语义鸿沟问题。
2.方法概述
本文提出的框架如图2所示,该网络通过知识增强和知识融合两个阶段生成常识描述。在知识增强阶段,我们通过设置提示词对GPT进行微调,以充分利用其想象力和推理能力,使模型能够学习视频中没有出现的常识。考虑到GPT不能直接使用视觉特征,我们首先利用基于Transformer的解码器生成GPT能够理解的视频内容描述。随后,我们引入了一个知识扩展模块,该模块为不同的常识设置了三种不同的提示词,以指导GPT的调优。在知识融合阶段,我们设计了一个多模态编码器,该编码器将GPT获得的文本知识与视频特征结合。其中,我们引入了基于Bert的文本语义提取模块,提取文本知识的高阶语义表示来指导训练。此外,为了确保推理与视频内容相关,我们引入了多模态知识融合的交叉注意机制。通过将不同模态的特征映射到同一维度的共享语义空间中,我们的模型可以实现多模态特征的充分语义交互,生成精确的常识描述。
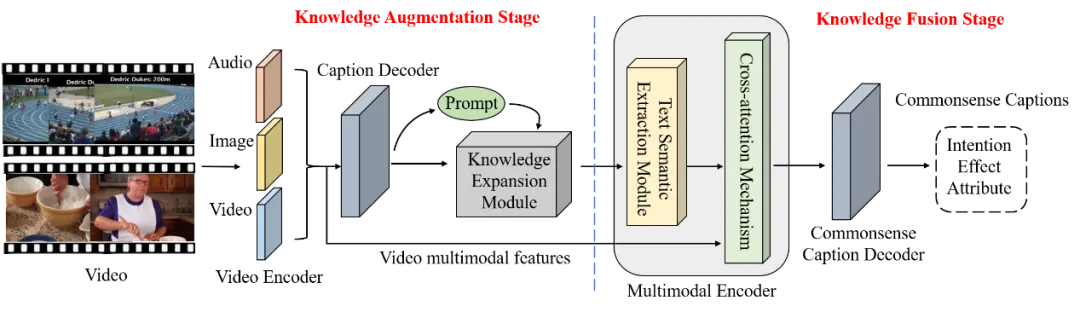
图2 两阶段知识引导网络(TKG-Net)模型框架
3.实验分析
我们在Video-to-Commonsense(V2C)数据集上开展了实验,表1展示了我们的TKG-Net和前人的方法的性能结果。可以发现我们的结果优于前人的方法。此外,图3展示了我们的方法生成的常识描述样例。
表1与前人方法在各类常识下的性能比较。最佳结果使用加粗表示

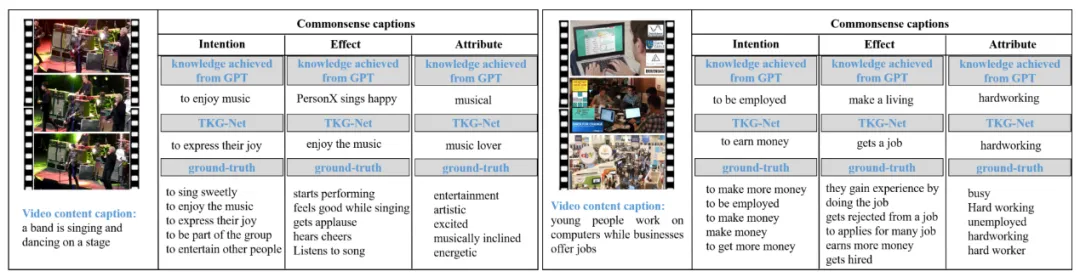
图3 我们的方法生成的常识描述的可视化样例
03
Spectrum-Driven Mixed-Frequency Network for Hyperspectral Salient Object Detection
作者:
刘沛甫,许廷发*,陈欢,周诗韵,秦昊林,李佳男*
单位:
北京理工大学
邮箱:
laprf@bit.edu.cn,
ciom_xtf1@bit.edu.cn,
huanchen@bit.edu.cn,
zhoushiyun@bit.edu.cn,
3120225333@bit.edu.cn,
lijianan@bit.edu.cn
论文:
https://ieeexplore.ieee.org/document/10313066
代码:
https://github.com/laprf/SMN
发表期刊:TMM2023
* 通讯作者
1.引言
利用光谱信息进行显著性目标检测有助于克服复杂光照对目标检测的干扰,如图1所示。现有的高光谱显著性目标检测方法光谱利用率低、推理速度慢、计算冗余高。针对这些问题,本文提出了一种新型的轻量级光谱驱动的混频网络(SMN),通过从光谱中提取两个不同的频率分量,低频光谱显著性和高频光谱边缘,进行显著性目标检测。
2.方法概述

图1 所提出的SMN框架
本文提出的模型整体架构图如图1所示,主要包括光谱显著性生成器、光谱边缘算子、频率特定嵌入操作和混合频率注意力模块。
光谱显著性生成器和光谱边缘算子
光谱显著性生成器通过构建逐层模糊的高斯金字塔,利用层间光谱角距离生成显著性图。光谱边缘算子首先计算像素与邻域的光谱角距离,再通过多种卷积核计算梯度,生成边缘图。这两个算子均能快速计算且无需学习参数。
频率特定嵌入操作
光谱显著性图与边缘图通过频率特定嵌入分别转化为深度特征。低频嵌入生成显著性特征,高频嵌入结合卷积层与边缘检测捕捉复杂边缘细节。由于边缘为低级特征,高频嵌入比低频嵌入浅,有效地提升了特征提取的效率并减少了参数量。
混合频率注意力模块
该模块包含两个注意力头:低频头处理显著性特征,利用自注意机制突出重要区域;高频头处理显著性和边缘特征,计算交叉注意力。为避免频率间的长距离交互引入噪声,本文采用局部注意机制,保证有限邻域内的有效交互,减轻计算负担。
3.实验分析
本文在HSOD-BIT和HS-SOD两个公开的数据集上进行了实验测试与评估,定量结果如表1所示。可以观察到,无论在哪个数据集上,本文提出的SMN方法均取得了最好的检测性能,优于所对比的所有方法。
表1 HSOD-BIT和HS-SOD数据集上的定量结果
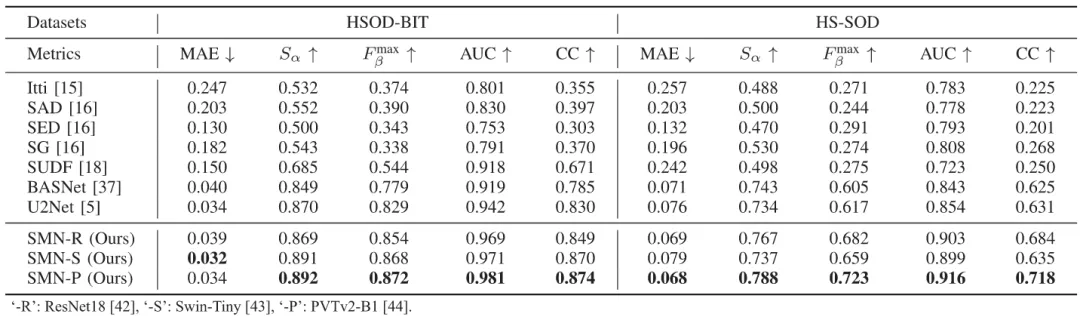
图2展示了在HSOD-BIT数据集上的可视化比较结果。相比其他高光谱显著性目标检测方法,本文提出的SMN能够更准确、完整地检测显著目标。而使用伪彩色图像的U2Net在复杂光照下表现不佳,进一步验证了光谱信息用于显著性检测的必要性。

图2 HSOD-BIT数据集上可视化结果比较
如图3所示,卷积核大小显著影响边缘特征生成:较小卷积核产生细致边缘,较大卷积核生成清晰整体轮廓。金字塔上层对(小层索引c)产生的显著图包含完整目标,下层对(大层索引c)产生的显著图可以更精确地捕捉显著区域。

图3 光谱边缘图和光谱显著性图的可视化
04
FreqAlign: Excavating Perception-Oriented Transferability for Blind Image Quality Assessment From a Frequency Perspective
作者:
李鑫,陆亦婷,陈志波
单位:
中国科学技术大学
邮箱:
xin.li@ustc.edu.cn;
luyt31415@mail.ustc.edu.cn;
chenzhibo@ustc.edu.cn
论文:
https://ieeexplore.ieee.org/document/10287591
发表期刊:TMM2023
1.论文简介
盲图像质量评估(BIQA)在数据分布偏移发生时易受到模型泛化性差的影响,例如从合成失真到真实失真。为了缓解这一问题,一些研究尝试设计无监督域适应(UDA)方案来应用于BIQA,旨在通过基于对抗的特征对齐来消除域偏移。然而,特征对齐通常在特征的低频空间进行(全局平均池化操作)。这忽略了在其他频率成分中的可迁移感知知识,导致了UDA在BIQA中的次优解决方案。为了克服这一问题,我们从一个新的频率视角出发,提出了一种有效的对齐策略,即频率对齐(简称FreqAlign),来挖掘BIQA在频率空间中的感知导向迁移能力。具体来说,我们研究了哪些特征的频率成分更适合于感知导向对齐。基于此,我们通过执行特征频率分解并选择包含丰富可迁移感知知识的频率成分来进行对齐,从而提高BIQA的感知导向迁移能力。为了实现稳定有效的频率选择,我们进一步提出了带有滑动窗口的频率移动来找到最佳对齐频率,包括三种策略,即预训练热身、基于频率移动的选择和基于扰动的微调。
2.方法概述
从频率空间探究BIQA无监督域适应
我们对不同频率成分中存在的可迁移感知知识进行了全面的实验分析。如图2所示。最低频率成分位于网格的左上角。从左到右,从上到下,频率成分在水平和垂直维度上变得更高。为了衡量每个频率成分中的可迁移感知知识,我们对源域中的每个频率成分采用主观质量回归,并在目标域上测试性能。所有频率成分在目标域上的感知结果“SROCC”以图2中的网格呈现,其中更亮的颜色表示更高的感知迁移能力。

我们可以得出两个关键发现:1)挖掘可迁移感知知识的最有效频率成分取决于不同的场景。(例如,对于KADID10k−→KonIQ-10k而言,最优频率成分在(0, 7),但对于KonIQ-10k−→KADID10k则在(7, 4))。2)性能相近的频率成分倾向于聚集在一起。以上发现促使我们为IQA的UDA开发一种有效的特征对齐策略(基于频率移动的对齐)。
基于频率移动的域对齐
为了实现稳定且高效的频率选择和对齐,我们提出了频率移动方法,该方法在频率对齐过程中通过滑动窗口向前移动频率带。通过这种方式,我们可以使用共享的特征提取器和判别器,获得每个频率带的感知导向迁移能力,然后选择最优的频率带。
我们在本文中采取了三个步骤来实现频率移动,即预训练热身、基于频率移动的选择和基于扰动的对齐。
预训练热身。通常,网络的不充分训练会导致频率选择不准确,潜在的早期频率带容易被忽视。因此,第一步需要对BIQA模型和判别器进行热身,以获得用于频率选择的良好训练的初始模型。模型在第一个频率带进行热身,使迁移能力度量ϵ稳定,这将防止骨干网络训练不足的影响。
基于频率移动的选择。第二步,我们旨在通过频率移动选择最佳频率带进行频率对齐。如图4所示,遵循预定义轨迹,我们用滑动窗口移动频率带,并在该频率带对源域和目标域进行对齐,以测量该频率带的迁移能力ϵ。我们可以通过在整体频率带上使用滑动窗口来测量所有频率带的迁移能力来选择最佳频率带。
基于扰动的微调。在获得最佳频率带后,一个直观的想法是用这个频率带微调整个BIQA模型。然而,这缺乏对第二步中不稳定频率选择的容忍能力。为了避免这一点,我们引入了基于频率扰动的微调来进行频率移动。具体来说,以选择的第j∗个频率带为中心,我们在微调过程中在区间[j∗ − k, j∗ + k]内扰动频率带。扰动是通过首先将滑动窗口向右移动来实现的。当MMD [52]降低时,扰动方向将保持在该区间内,并在MMD [1]增加时反转。通过这种方式,模型能够在最佳频率带中收敛,并实现最佳的迁移能力。
以上三个步骤可以见图2的代码流程图
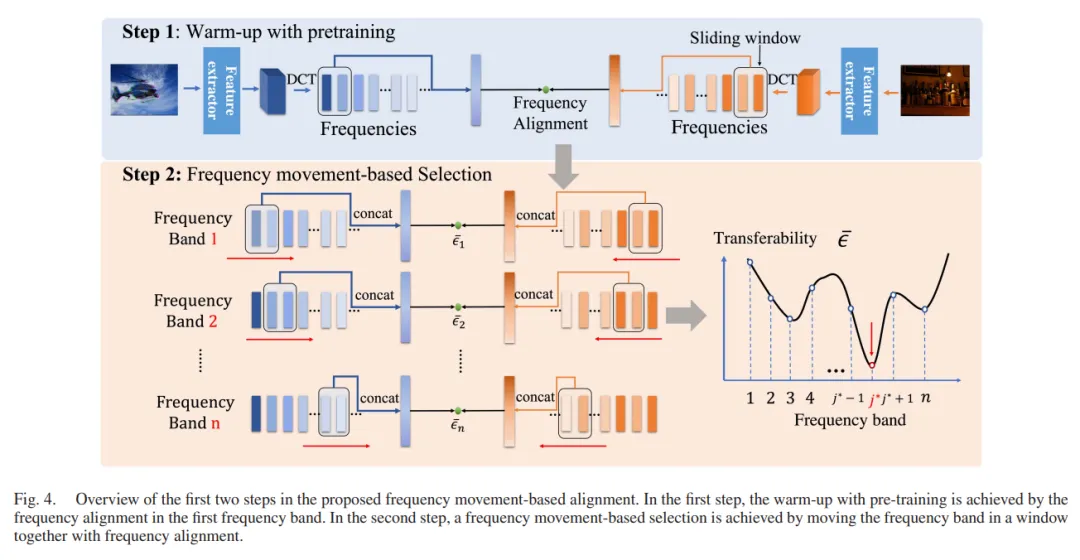
图1 freqalign的流程图
为了提高BIQA模型的感知迁移能力,我们在方法中引入了三个损失,即基于对抗的特征对齐损失,回归损失,和目标域的自监督损失。其中,针对目标域的自监督损失 是由SFUDA [12] 提出的,它揭示了他们提出的自监督损失能够在结合BIQA的特性时改善BIQA的无源UDA。受此启发,我们进一步采用自监督损失函数来约束目标数据的分布,并学习目标域的判别性信息.

图2 频率移动的算法流程图
3.实验分析
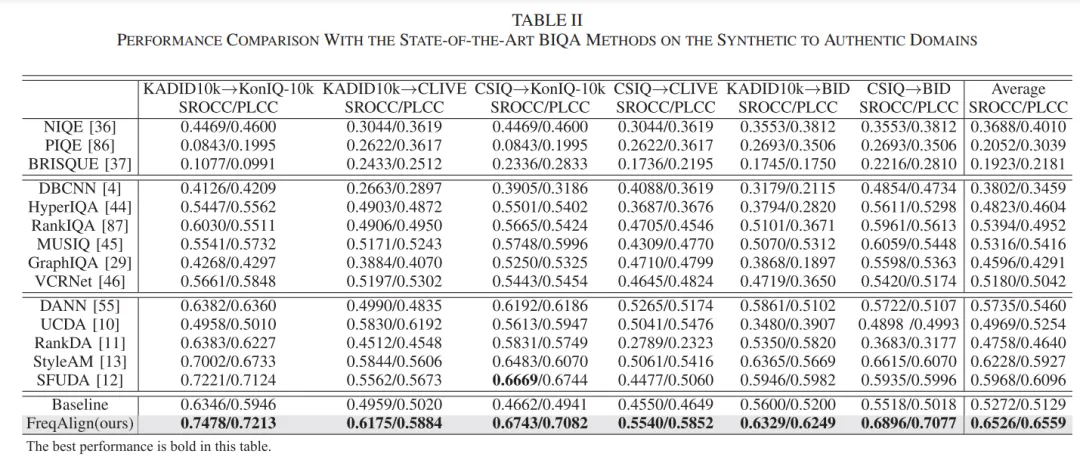
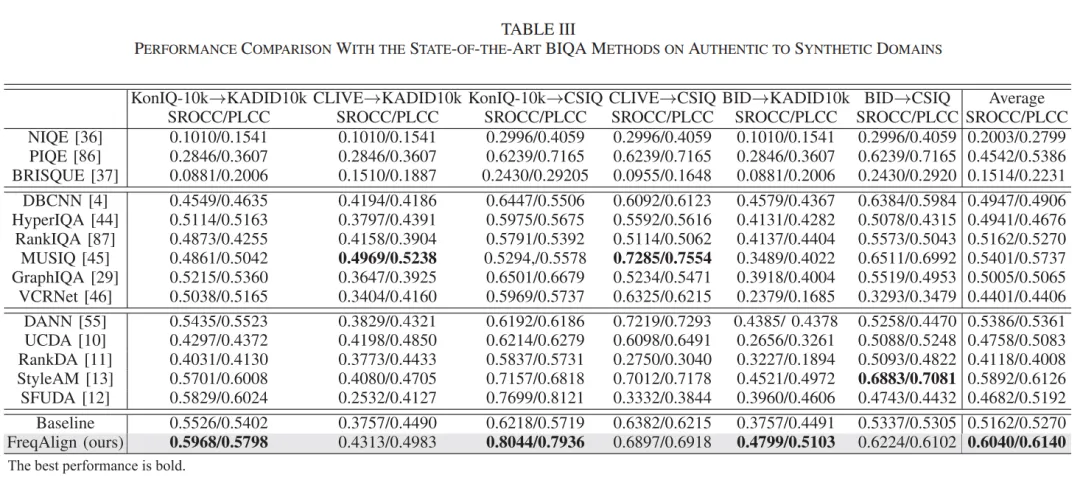
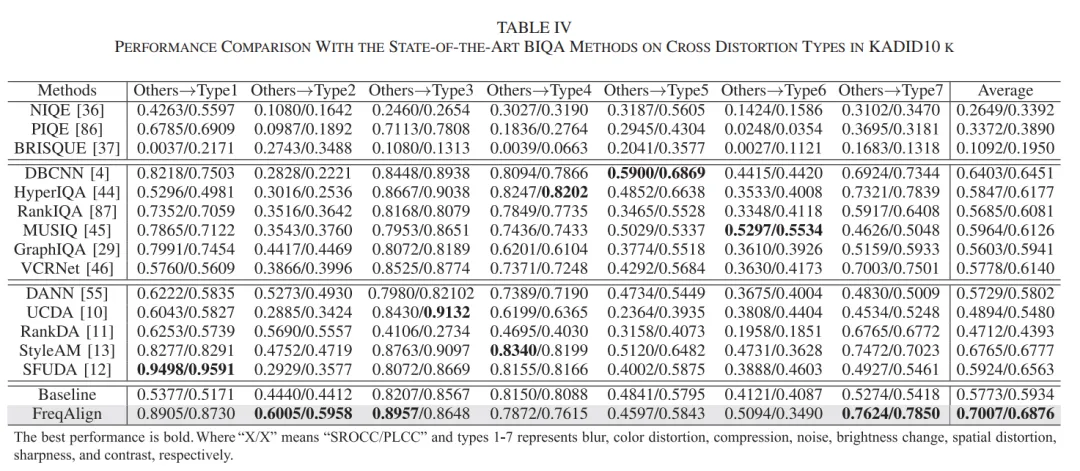
算法性能对比见下面表格(分别是合成失真场景到真实场景、真实场景到合成场景、不同失真之间迁移)
消融实验的结果见下表,可以看到我们的预训练热身,基于频率移动的选择和基于扰动的微调的组合可以取得最好的性能。
此外我们的方法在美学数据集上的泛化也可以取到较好的性能。

05
Improving Adaptive Real-Time Video Communication via Cross-Layer Optimization
作者:
李岳恒,陈浩,徐泊巍,张子丞,马展*
单位:
南京大学电子科学与工程学院
邮箱:
yueheng.li@smail.nju.edu.cn;chenhao1210@nju.edu.cn;
xubowei@smail.nju.edu.cn;zichengzhang@smail.nju.edu.cn;mazhan@nju.edu.cn
论文:
https://ieeexplore.ieee.org/document/10316603
发表期刊:TMM2023
*通讯作者
1.研究背景与动机
现有的基于规则和基于学习的自适应比特率(Adaptive Bit Rate, ABR)解决方案大多都是将可用网络带宽的估计和视频编码码率控制分离,假设在客户端接收到的视频质量与视频比特率高度相关,通过调整视频比特率来适应动态的网络带宽,从而提升用户体验质量(Quality of Experience,QoE)。
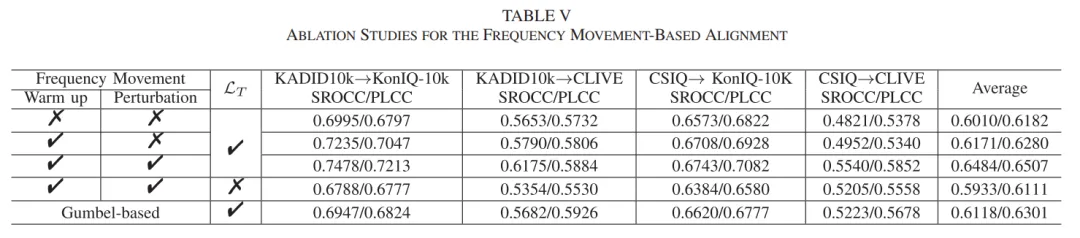
然而,实时视频通信(Real-Time Video Communication,RTVC)系统中用户的QoE不仅仅受视频比特率影响,同时受传输层和应用层的各种因素的影响。图1展示了在固定带宽下传输高动态场景的第一人称射击游戏视频时,Palette(本文提出的工作)与现有3种ABR算法的QoE对比,可见现有方法通过最大化带宽利用率并不能保证最佳的QoE。此外,现有的RTVC系统只依赖于视频编码器来生成尽可能接近目标比特率的压缩视频,编解码器与传输的不协调(即网络可用带宽的变化是毫秒级的,而视频编码器至少需要一秒甚至几秒来稳定和匹配目标比特率)经常导致显著的自适应滞后,引发视频卡顿以及延迟(图2)。
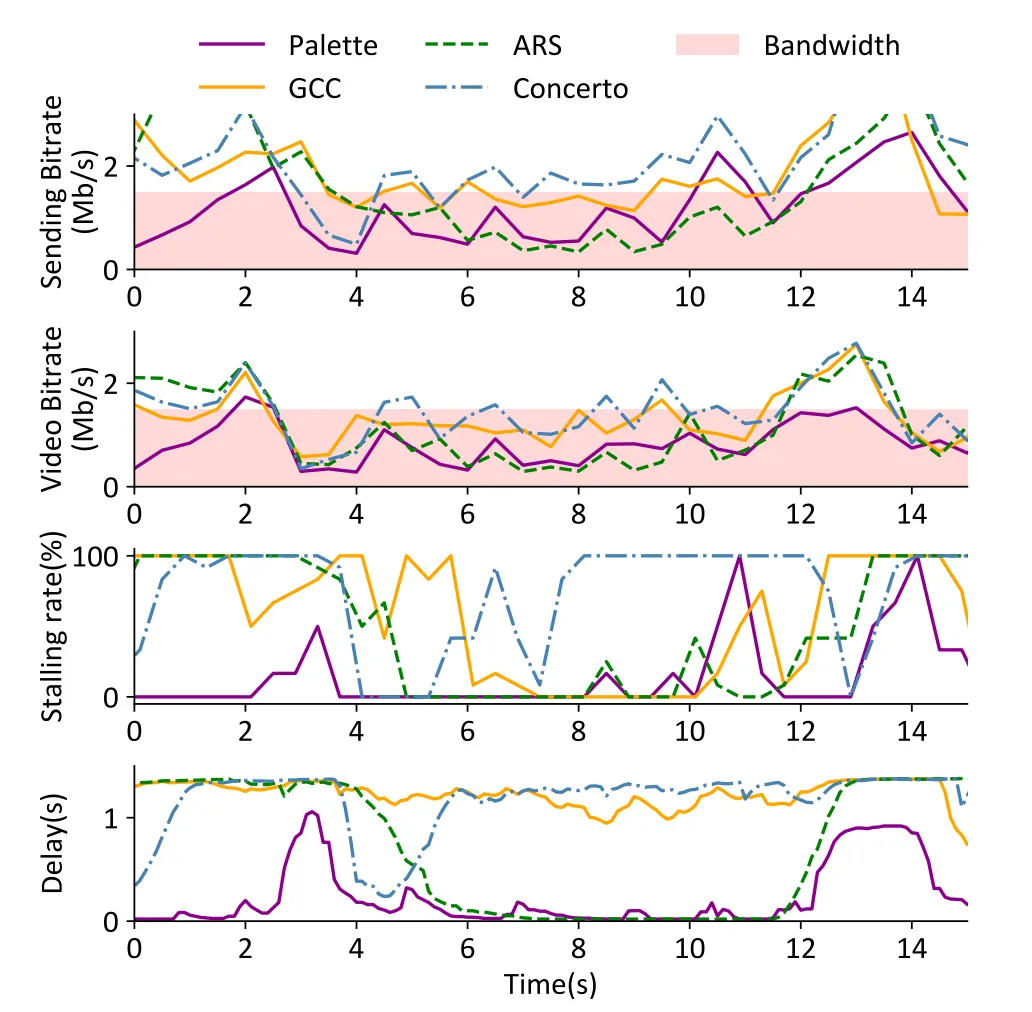
图1 最大化带宽利用无法保证最佳QoE
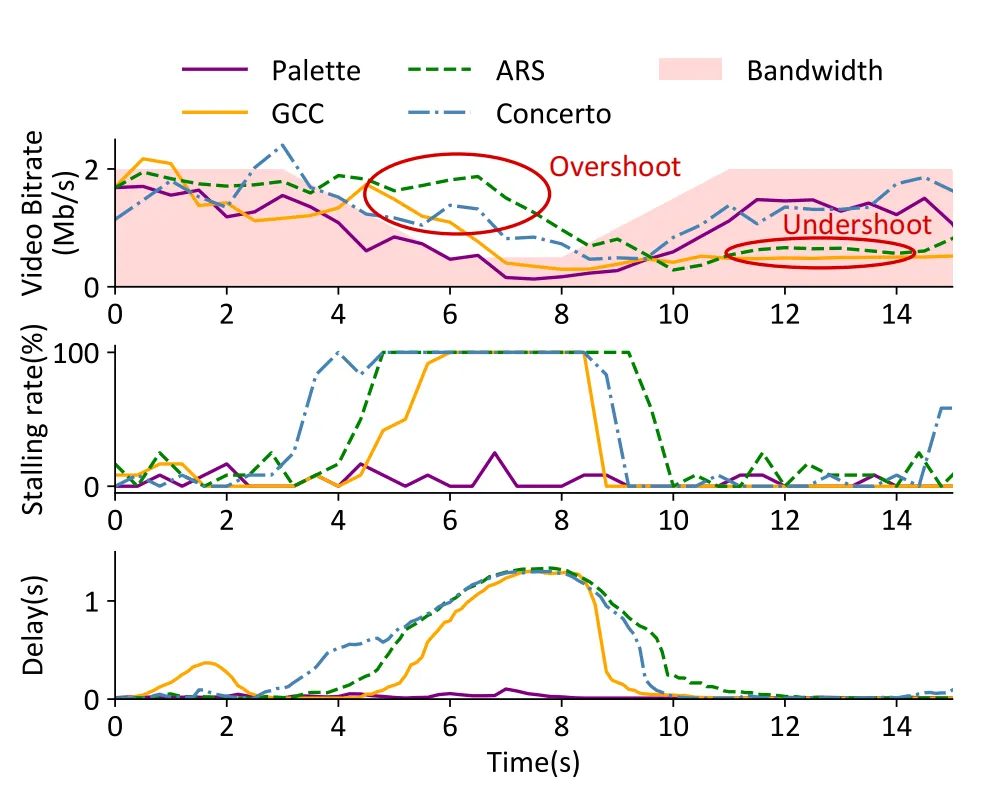
图2 自适应调整的滞后现象
2.方法概述
本工作提出了一种基于强化学习的ABR算法Palette,联合传输层的拥塞控制和视频应用层的码率控制,利用跨层观测结果来决策下一帧(或几帧)的编码参数。同时以视频质量、卡顿率和延迟的加权函数作为QoE指标,直接最大化目标QoE,而不是最大化带宽利用率,成功地解决了编解码器与传输层的不协调问题,更好地适应了网络的波动。
Palette的结构如图3所示。Palette通过不断地从环境中观测跨层状态,包括网络条件、视频编码参数和从原始帧中提取的视频内容复杂度,并利用RL(Reinforcement Learning)智能体(Agent)将观察到的状态映射到一个细粒度的压缩因子平均CRF(Constant Rate Factor),最后将其转换为每帧的QP(Quantization Parameter),以用于压缩未来的视频帧进行网络传输。其中智能体使用A3C深度强化学习生成Palette的ABR策略,Actor网络结构如图4所示。
图3 Palette的体系结构
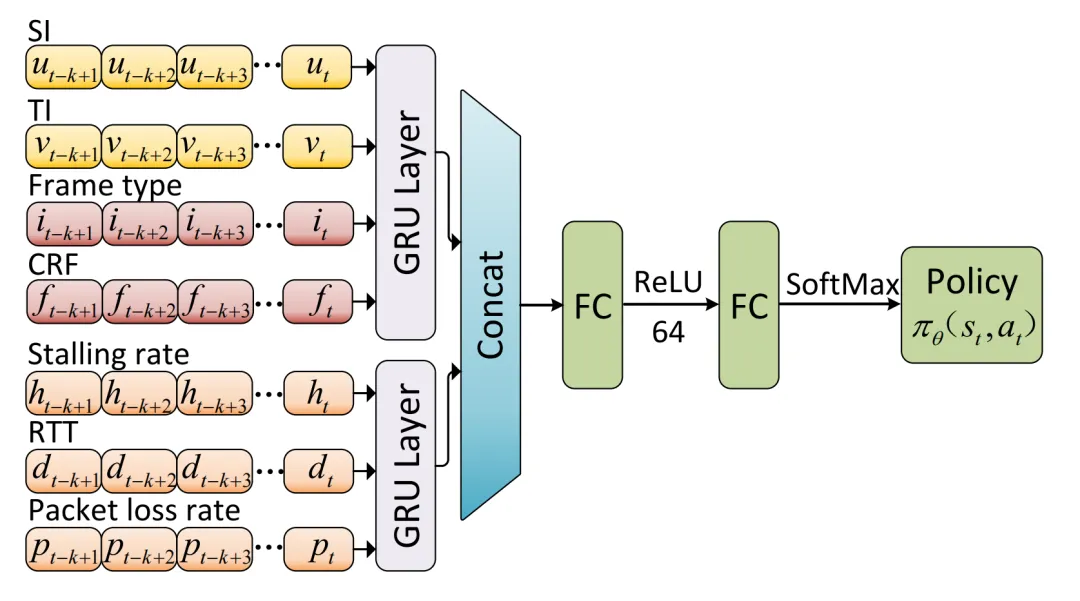
图4 Palette的神经网络模型
3.实验分析
本文使用公开网络带宽数据集进行了大规模的仿真实验来验证Palette的性能,并进一步在真实世界中部署Palette以验证其实用性。大规模仿真实验使用来自不同公开数据集的多种网络接入类型的的网络带宽跟踪数据,包括HSDPA、Oboe、FCC以及MMGC2019,全面地模拟了真实世界的网络行为。图5和图6分别显示了Palette与现有的3种ABR算法在公开网络带宽数据集上的比特率、VMAF、卡顿率以及往返延迟的性能对比。实验对比结果表明,提出的Palette方法取得了最好的性能,同时在累积分布性能上展现出跨越整个范围的性能领先。
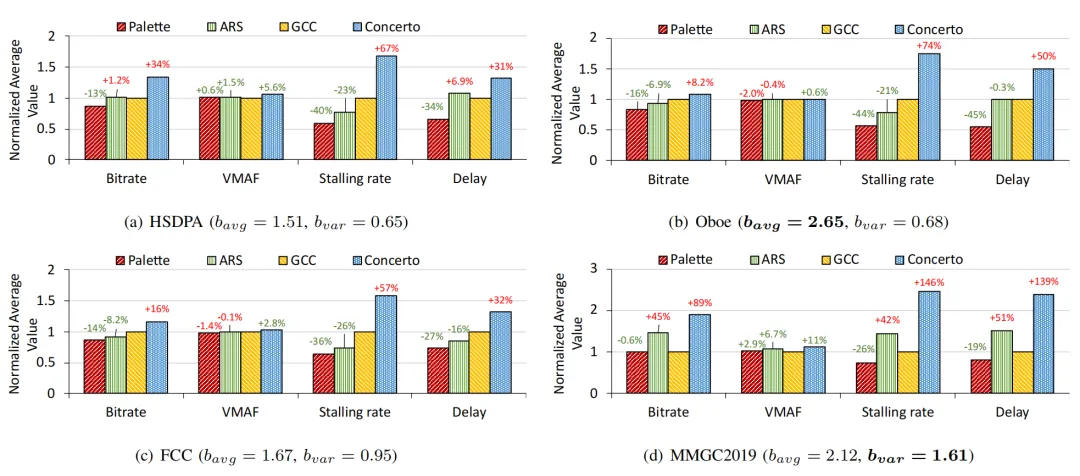
图5 Palette在公开网络带宽数据集上的平均性能对比
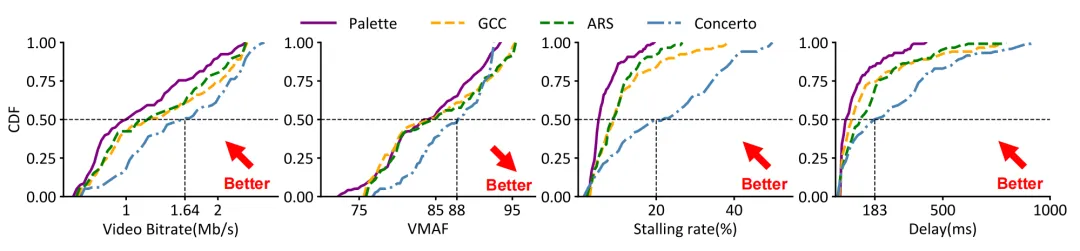
图6 Palette在公开网络带宽数据集上的累积分布性能对比
本文进一步在真实世界中使用不同主流接入网(4G、5G和WiFi),和包括咖啡馆、步行、公交车以及地铁在内的不同场景进行性能验证。图7(a)和图7(b)分别展示了现场测试的总体性能与单一场景下的性能。可以看到Palette性能指标的平均值和标准差都优于其他的ABR方法。总的来说,Palette在所有场景和连接下都表现出显著优势。
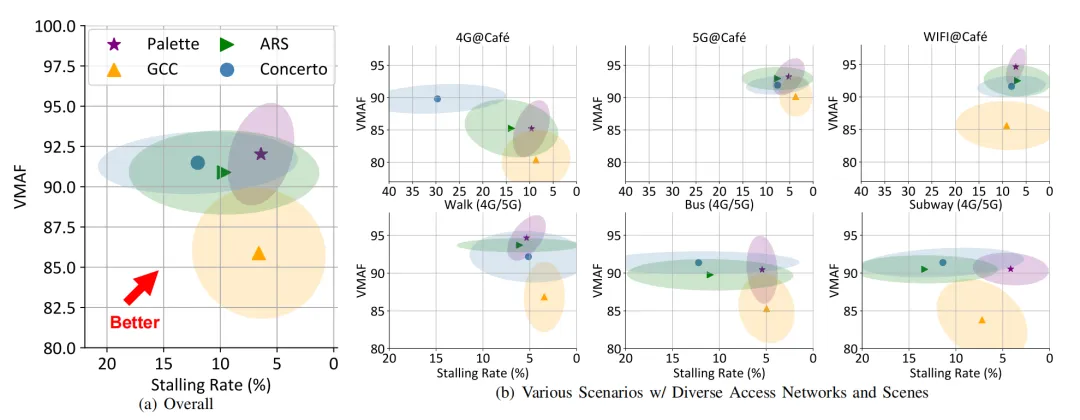
图7 Palette在真实世界中部署的性能

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
【论文导读】2024年论文导读第二十一期
CCF多媒体专委会 2024年10月22日 18:48 北京
论文导读
2024年论文导读第二十一期(总第一百一十二期)
目 录
|
1 |
Occlusion-Aware Feature Recover Model for Occluded Person Re-Identification |
|
2 |
GPT-based Knowledge Guiding Network for Commonsense Video Captioning |
|
3 |
Spectrum-Driven Mixed-Frequency Network for Hyperspectral Salient Object Detection |
|
4 |
FreqAlign: Excavating Perception-Oriented Transferability for Blind Image Quality Assessment From a Frequency Perspective |
|
5 |
Improving Adaptive Real-Time Video Communication via Cross-Layer Optimization |
01
Occlusion-Aware Feature Recover Model for Occluded Person Re-Identification
作者:
边远1,2、刘敏1,2*、王学平3、唐毅1,2、王耀南1,2
单位:
1湖南大学电气与信息工程学院
2机器人视觉感知与控制技术国家工程研究中心
3湖南师范大学信息科学与工程学院
邮箱:
yuanbian@hnu.edu.cn,
liu_min@hnu.edu.cn,
wang_xueping@hnu.edu.cn,
tyhnu@hnu.edu.cn,
yaonan@hnu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10314802
代码:
https://github.com/yuanbianGit/OAFR
发表期刊:TMM2023
*通讯作者
1.研究背景
行人再识别(Re-ID)用于从多个不重叠摄像机视角中识别相同的目标行人。然而,在实际应用场景中,行人通常会被其他人或静态物体(如车辆、建筑物等)部分遮挡,导致行人特征丢失或混淆,进而对识别结果产生负面影响。现有的遮挡行人再识别方法通常依赖于辅助模型,如姿态估计和人体解析模型,来识别未遮挡的部分,从而消除遮挡引入的噪声。然而,这些方法计算开销大,难以应对行人之间的遮挡(即人对人遮挡)问题。此外,仅依靠未遮挡部
分进行匹配也可能不足,因为某些情况下,遮挡的行人与查询图像之间可能没有共同的可见部分或显著特征。为了解决这些问题,本文提出了一种遮挡感知的特征恢复模型,该模型通过模拟各种遮挡场景,提高模型处理不同遮挡情况的能力,并通过恢复遮挡的行人特征来改善识别效果。
2.论文方法
本文提出了一种创新的遮挡感知特征恢复模型(Occlusion-Aware Feature Recover, OAFR),该模型通过遮挡感知和特征恢复机制解决遮挡行人再识别中的特征丢失与遮挡干扰问题。模型的主要构成包括:先验知识遮挡模拟模块(PKOS)、可见性引导的特征匹配模块(VFM)和可见性引导的特征恢复模块(VFR)。
为了增强模型在遮挡场景下的鲁棒性,本文提出了一种基于先验知识的遮挡模拟方法。该模块用于模拟不同类型的遮挡场景,包括行人与行人之间的遮挡(Person-to-Person,PTP)和行人与物体之间的遮挡(Object-to-Person,OTP)。具体来说,利用自监督学习的方式,通过观察摄像机视角下的空间和语义遮挡关系,合成多种遮挡情况。例如,在PTP遮挡场景中,遮挡者通常出现在被遮挡行人的下方部分,而在OTP遮挡中,遮挡物的语义信息与目标行人的语义信息无关。基于此,模型能够通过这些遮挡模拟数据学习遮挡区域的空间关系和语义差异,从而提高在实际遮挡场景中的表现。
为了解决遮挡噪声对特征相似度计算的干扰,本文设计了一个可见性引导的特征匹配模块(Visibility-guided Feature Matching,VFM)。该模块通过预测图像中各部分的可见性得分,来引导特征相似度的计算,从而减少遮挡部分对特征匹配的负面影响。可见性得分预测器首先在自监督学习的框架下进行训练。利用遮挡模拟过程中生成的遮挡标签,模型可以有效预测目标行人身体各部分的可见性,而不依赖额外的辅助模型。在推理阶段,模型将输入图像划分为多个部分,并预测每个部分的可见性得分。
在特征匹配模块生成初步匹配结果后,本文引入特征恢复模块以提升遮挡行人的特征完整性。首先从前K个候选图像中选取与查询图像有较多可见部分重合的图像,然后利用这些图像的局部特征替换查询图像中被遮挡的部分。为确保恢复的鲁棒性,本文采用了基于可见性加权平均的特征替换方法,按可见性得分对恢复部分进行加权平均。该方法既保留了查询图像中的原有未遮挡特征,又通过候选图像的可见特征弥补了被遮挡的信息缺失。
3.实验结果
实验结果表明,本文提出的模型在多个数据集上优于现有方法,特别是Occluded-DukeMTMC数据上表现显著提升,在Rank-1精度上超过SOTA方法6.0%。多个可视化结果也说明了所提出各模块的有效性。
02
GPT-based Knowledge Guiding Network for Commonsense Video Captioning
作者:
袁梦奇1, 贾耕云1, 鲍秉坤*1
单位:
1南京邮电大学
邮箱:
2020010306@njupt.edu.cn,
gengyun.jia@njupt.edu.cn,
bingkunbao@njupt.edu.cn
论文:
https://ieeexplore.ieee.org/document/10310122
代码:
https://github.com/yuan687198/TKG-Net
发表期刊:TMM2023
*通讯作者
1.研究背景
基于视频的常识描述生成是一个跨模态生成任务,它需要模型不光生成视频内容的文本描述,还需要生成视频背后所包含的常识描述。其中常识描述具体可包括三个部分:视频中人物的意图、视频中事件会产生什么样的影响、视频中人物或事件的属性特点,如图1(a)所示。
前人的方法一般采用编解码器的架构,它们首先提取视频中的视觉特征来生成视频内容的描述,并将视频特征和视频内容描述结合起来,通过解码器生成关于视频背后的常识描述。然而,它们难以处理不可见的常识和可见的视频之间存在的复杂语义鸿沟的问题。针对此问题,我们引入在外部大规模语料库上预训练的GPT模型。通过借助GPT丰富的想象力和推理能力,来支持可见的视频和不可见的常识之间的复杂关系学习,如图1(b)所示。
图1(a)基于视频生成的常识文本样例。(b)我们引入GPT处理视频和常识间的复杂语义鸿沟问题。
2.方法概述
本文提出的框架如图2所示,该网络通过知识增强和知识融合两个阶段生成常识描述。在知识增强阶段,我们通过设置提示词对GPT进行微调,以充分利用其想象力和推理能力,使模型能够学习视频中没有出现的常识。考虑到GPT不能直接使用视觉特征,我们首先利用基于Transformer的解码器生成GPT能够理解的视频内容描述。随后,我们引入了一个知识扩展模块,该模块为不同的常识设置了三种不同的提示词,以指导GPT的调优。在知识融合阶段,我们设计了一个多模态编码器,该编码器将GPT获得的文本知识与视频特征结合。其中,我们引入了基于Bert的文本语义提取模块,提取文本知识的高阶语义表示来指导训练。此外,为了确保推理与视频内容相关,我们引入了多模态知识融合的交叉注意机制。通过将不同模态的特征映射到同一维度的共享语义空间中,我们的模型可以实现多模态特征的充分语义交互,生成精确的常识描述。
图2 两阶段知识引导网络(TKG-Net)模型框架
3.实验分析
我们在Video-to-Commonsense(V2C)数据集上开展了实验,表1展示了我们的TKG-Net和前人的方法的性能结果。可以发现我们的结果优于前人的方法。此外,图3展示了我们的方法生成的常识描述样例。
表1与前人方法在各类常识下的性能比较。最佳结果使用加粗表示
图3 我们的方法生成的常识描述的可视化样例
03
Spectrum-Driven Mixed-Frequency Network for Hyperspectral Salient Object Detection
作者:
刘沛甫,许廷发*,陈欢,周诗韵,秦昊林,李佳男*
单位:
北京理工大学
邮箱:
laprf@bit.edu.cn,
ciom_xtf1@bit.edu.cn,
huanchen@bit.edu.cn,
zhoushiyun@bit.edu.cn,
3120225333@bit.edu.cn,
lijianan@bit.edu.cn
论文:
https://ieeexplore.ieee.org/document/10313066
代码:
https://github.com/laprf/SMN
发表期刊:TMM2023
* 通讯作者
1.引言
利用光谱信息进行显著性目标检测有助于克服复杂光照对目标检测的干扰,如图1所示。现有的高光谱显著性目标检测方法光谱利用率低、推理速度慢、计算冗余高。针对这些问题,本文提出了一种新型的轻量级光谱驱动的混频网络(SMN),通过从光谱中提取两个不同的频率分量,低频光谱显著性和高频光谱边缘,进行显著性目标检测。
2.方法概述
图1 所提出的SMN框架
本文提出的模型整体架构图如图1所示,主要包括光谱显著性生成器、光谱边缘算子、频率特定嵌入操作和混合频率注意力模块。
光谱显著性生成器和光谱边缘算子
光谱显著性生成器通过构建逐层模糊的高斯金字塔,利用层间光谱角距离生成显著性图。光谱边缘算子首先计算像素与邻域的光谱角距离,再通过多种卷积核计算梯度,生成边缘图。这两个算子均能快速计算且无需学习参数。
频率特定嵌入操作
光谱显著性图与边缘图通过频率特定嵌入分别转化为深度特征。低频嵌入生成显著性特征,高频嵌入结合卷积层与边缘检测捕捉复杂边缘细节。由于边缘为低级特征,高频嵌入比低频嵌入浅,有效地提升了特征提取的效率并减少了参数量。
混合频率注意力模块
该模块包含两个注意力头:低频头处理显著性特征,利用自注意机制突出重要区域;高频头处理显著性和边缘特征,计算交叉注意力。为避免频率间的长距离交互引入噪声,本文采用局部注意机制,保证有限邻域内的有效交互,减轻计算负担。
3.实验分析
本文在HSOD-BIT和HS-SOD两个公开的数据集上进行了实验测试与评估,定量结果如表1所示。可以观察到,无论在哪个数据集上,本文提出的SMN方法均取得了最好的检测性能,优于所对比的所有方法。
表1 HSOD-BIT和HS-SOD数据集上的定量结果
图2展示了在HSOD-BIT数据集上的可视化比较结果。相比其他高光谱显著性目标检测方法,本文提出的SMN能够更准确、完整地检测显著目标。而使用伪彩色图像的U2Net在复杂光照下表现不佳,进一步验证了光谱信息用于显著性检测的必要性。
图2 HSOD-BIT数据集上可视化结果比较
如图3所示,卷积核大小显著影响边缘特征生成:较小卷积核产生细致边缘,较大卷积核生成清晰整体轮廓。金字塔上层对(小层索引c)产生的显著图包含完整目标,下层对(大层索引c)产生的显著图可以更精确地捕捉显著区域。
图3 光谱边缘图和光谱显著性图的可视化
04
FreqAlign: Excavating Perception-Oriented Transferability for Blind Image Quality Assessment From a Frequency Perspective
作者:
李鑫,陆亦婷,陈志波
单位:
中国科学技术大学
邮箱:
xin.li@ustc.edu.cn;
luyt31415@mail.ustc.edu.cn;
chenzhibo@ustc.edu.cn
论文:
https://ieeexplore.ieee.org/document/10287591
发表期刊:TMM2023
1.论文简介
盲图像质量评估(BIQA)在数据分布偏移发生时易受到模型泛化性差的影响,例如从合成失真到真实失真。为了缓解这一问题,一些研究尝试设计无监督域适应(UDA)方案来应用于BIQA,旨在通过基于对抗的特征对齐来消除域偏移。然而,特征对齐通常在特征的低频空间进行(全局平均池化操作)。这忽略了在其他频率成分中的可迁移感知知识,导致了UDA在BIQA中的次优解决方案。为了克服这一问题,我们从一个新的频率视角出发,提出了一种有效的对齐策略,即频率对齐(简称FreqAlign),来挖掘BIQA在频率空间中的感知导向迁移能力。具体来说,我们研究了哪些特征的频率成分更适合于感知导向对齐。基于此,我们通过执行特征频率分解并选择包含丰富可迁移感知知识的频率成分来进行对齐,从而提高BIQA的感知导向迁移能力。为了实现稳定有效的频率选择,我们进一步提出了带有滑动窗口的频率移动来找到最佳对齐频率,包括三种策略,即预训练热身、基于频率移动的选择和基于扰动的微调。
2.方法概述
从频率空间探究BIQA无监督域适应
我们对不同频率成分中存在的可迁移感知知识进行了全面的实验分析。如图2所示。最低频率成分位于网格的左上角。从左到右,从上到下,频率成分在水平和垂直维度上变得更高。为了衡量每个频率成分中的可迁移感知知识,我们对源域中的每个频率成分采用主观质量回归,并在目标域上测试性能。所有频率成分在目标域上的感知结果“SROCC”以图2中的网格呈现,其中更亮的颜色表示更高的感知迁移能力。
我们可以得出两个关键发现:1)挖掘可迁移感知知识的最有效频率成分取决于不同的场景。(例如,对于KADID10k−→KonIQ-10k而言,最优频率成分在(0, 7),但对于KonIQ-10k−→KADID10k则在(7, 4))。2)性能相近的频率成分倾向于聚集在一起。以上发现促使我们为IQA的UDA开发一种有效的特征对齐策略(基于频率移动的对齐)。
基于频率移动的域对齐
为了实现稳定且高效的频率选择和对齐,我们提出了频率移动方法,该方法在频率对齐过程中通过滑动窗口向前移动频率带。通过这种方式,我们可以使用共享的特征提取器和判别器,获得每个频率带的感知导向迁移能力,然后选择最优的频率带。
我们在本文中采取了三个步骤来实现频率移动,即预训练热身、基于频率移动的选择和基于扰动的对齐。
预训练热身。通常,网络的不充分训练会导致频率选择不准确,潜在的早期频率带容易被忽视。因此,第一步需要对BIQA模型和判别器进行热身,以获得用于频率选择的良好训练的初始模型。模型在第一个频率带进行热身,使迁移能力度量ϵ稳定,这将防止骨干网络训练不足的影响。
基于频率移动的选择。第二步,我们旨在通过频率移动选择最佳频率带进行频率对齐。如图4所示,遵循预定义轨迹,我们用滑动窗口移动频率带,并在该频率带对源域和目标域进行对齐,以测量该频率带的迁移能力ϵ。我们可以通过在整体频率带上使用滑动窗口来测量所有频率带的迁移能力来选择最佳频率带。
基于扰动的微调。在获得最佳频率带后,一个直观的想法是用这个频率带微调整个BIQA模型。然而,这缺乏对第二步中不稳定频率选择的容忍能力。为了避免这一点,我们引入了基于频率扰动的微调来进行频率移动。具体来说,以选择的第j∗个频率带为中心,我们在微调过程中在区间[j∗ − k, j∗ + k]内扰动频率带。扰动是通过首先将滑动窗口向右移动来实现的。当MMD [52]降低时,扰动方向将保持在该区间内,并在MMD [1]增加时反转。通过这种方式,模型能够在最佳频率带中收敛,并实现最佳的迁移能力。
以上三个步骤可以见图2的代码流程图
图1 freqalign的流程图
为了提高BIQA模型的感知迁移能力,我们在方法中引入了三个损失,即基于对抗的特征对齐损失,回归损失,和目标域的自监督损失。其中,针对目标域的自监督损失 是由SFUDA [12] 提出的,它揭示了他们提出的自监督损失能够在结合BIQA的特性时改善BIQA的无源UDA。受此启发,我们进一步采用自监督损失函数来约束目标数据的分布,并学习目标域的判别性信息.
图2 频率移动的算法流程图
3.实验分析
算法性能对比见下面表格(分别是合成失真场景到真实场景、真实场景到合成场景、不同失真之间迁移)
消融实验的结果见下表,可以看到我们的预训练热身,基于频率移动的选择和基于扰动的微调的组合可以取得最好的性能。
此外我们的方法在美学数据集上的泛化也可以取到较好的性能。
05
Improving Adaptive Real-Time Video Communication via Cross-Layer Optimization
作者:
李岳恒,陈浩,徐泊巍,张子丞,马展*
单位:
南京大学电子科学与工程学院
邮箱:
yueheng.li@smail.nju.edu.cn;chenhao1210@nju.edu.cn;
xubowei@smail.nju.edu.cn;zichengzhang@smail.nju.edu.cn;mazhan@nju.edu.cn
论文:
https://ieeexplore.ieee.org/document/10316603
发表期刊:TMM2023
*通讯作者
1.研究背景与动机
现有的基于规则和基于学习的自适应比特率(Adaptive Bit Rate, ABR)解决方案大多都是将可用网络带宽的估计和视频编码码率控制分离,假设在客户端接收到的视频质量与视频比特率高度相关,通过调整视频比特率来适应动态的网络带宽,从而提升用户体验质量(Quality of Experience,QoE)。
然而,实时视频通信(Real-Time Video Communication,RTVC)系统中用户的QoE不仅仅受视频比特率影响,同时受传输层和应用层的各种因素的影响。图1展示了在固定带宽下传输高动态场景的第一人称射击游戏视频时,Palette(本文提出的工作)与现有3种ABR算法的QoE对比,可见现有方法通过最大化带宽利用率并不能保证最佳的QoE。此外,现有的RTVC系统只依赖于视频编码器来生成尽可能接近目标比特率的压缩视频,编解码器与传输的不协调(即网络可用带宽的变化是毫秒级的,而视频编码器至少需要一秒甚至几秒来稳定和匹配目标比特率)经常导致显著的自适应滞后,引发视频卡顿以及延迟(图2)。
图1 最大化带宽利用无法保证最佳QoE
图2 自适应调整的滞后现象
2.方法概述
本工作提出了一种基于强化学习的ABR算法Palette,联合传输层的拥塞控制和视频应用层的码率控制,利用跨层观测结果来决策下一帧(或几帧)的编码参数。同时以视频质量、卡顿率和延迟的加权函数作为QoE指标,直接最大化目标QoE,而不是最大化带宽利用率,成功地解决了编解码器与传输层的不协调问题,更好地适应了网络的波动。
Palette的结构如图3所示。Palette通过不断地从环境中观测跨层状态,包括网络条件、视频编码参数和从原始帧中提取的视频内容复杂度,并利用RL(Reinforcement Learning)智能体(Agent)将观察到的状态映射到一个细粒度的压缩因子平均CRF(Constant Rate Factor),最后将其转换为每帧的QP(Quantization Parameter),以用于压缩未来的视频帧进行网络传输。其中智能体使用A3C深度强化学习生成Palette的ABR策略,Actor网络结构如图4所示。
图3 Palette的体系结构
图4 Palette的神经网络模型
3.实验分析
本文使用公开网络带宽数据集进行了大规模的仿真实验来验证Palette的性能,并进一步在真实世界中部署Palette以验证其实用性。大规模仿真实验使用来自不同公开数据集的多种网络接入类型的的网络带宽跟踪数据,包括HSDPA、Oboe、FCC以及MMGC2019,全面地模拟了真实世界的网络行为。图5和图6分别显示了Palette与现有的3种ABR算法在公开网络带宽数据集上的比特率、VMAF、卡顿率以及往返延迟的性能对比。实验对比结果表明,提出的Palette方法取得了最好的性能,同时在累积分布性能上展现出跨越整个范围的性能领先。
图5 Palette在公开网络带宽数据集上的平均性能对比
图6 Palette在公开网络带宽数据集上的累积分布性能对比
本文进一步在真实世界中使用不同主流接入网(4G、5G和WiFi),和包括咖啡馆、步行、公交车以及地铁在内的不同场景进行性能验证。图7(a)和图7(b)分别展示了现场测试的总体性能与单一场景下的性能。可以看到Palette性能指标的平均值和标准差都优于其他的ABR方法。总的来说,Palette在所有场景和连接下都表现出显著优势。
图7 Palette在真实世界中部署的性能
编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号