
2024年论文导读第五期
CCF多媒体专委会 2024-03-12 09:00 山东


论文导读
2024年论文导读第五期(总第九十六期)
目 录
|
1 |
3DGStream: On-the-fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos |
|
2 |
Illumination Distillation Framework for Nighttime Person Re-Identification and A New Benchmark |
|
3 |
Wave-like Class Activation Map with Representation Fusion for Weakly-Supervised Semantic Segmentation |
|
4 |
A Dual Reinforcement Learning Framework for Weakly Supervised Phrase Grounding |
|
5 |
A Structure-Preserving and Illumination-Consistent Cycle Framework for Image Harmonization |
|
5 |
Improving Handwritten Mathematical Expression Recognition via Similar Symbol Distinguishing |
01
3DGStream: On-the-fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos
3DGStream:用于高效构建逼真的自由视点视频流的即时3D高斯训练
作者:孙嘉锴、焦涵、李光远、张占杰、赵磊*,邢卫
单位:浙江大学计算机学院
邮箱:
cszhl@zju.edu.cn
论文:
https://arxiv.org/abs/2403.01444
代码:
https://sjojok.github.io/3dgstream
在三维视觉领域中,构建来自多视角视频的动态场景的逼真自由视点视频(FVV)仍然是一项具有挑战性的工作。尽管当前神经渲染技术取得了显著的进展,但这些方法通常需要完整的视频序列进行离线训练,并且无法进行实时渲染。
为了解决这些限制,孙嘉锴(导师为赵磊副教授)等提出了3DGStream,如图1所示。这是一种能够在现实世界的动态场景中实现高效FVV流式传输的方法,具有快速(约10秒)的即时逐帧重建和实时渲染(约200 FPS)的能力。我们提出两种策略:(a)利用3D高斯模型(3DGs)来对场景进行建模,然而,我们并不直接针对每帧优化3DGs,而是使用紧凑的神经变换缓存(NTC)来模拟3DGs的平移和旋转,显著减少了用于每个FFV帧所需的训练时间和模型存储。(b)使用一种自适应的3DG添加策略,以处理动态场景中的瞬态物体。实验证明,与最先进的方法相比,3DGStream在渲染速度、图像质量、训练时间和模型存储方面都取得了竞争性的性能,如图2和图3。
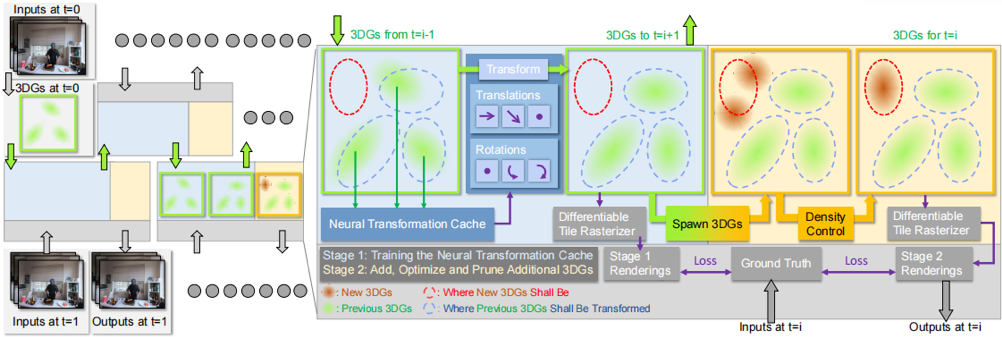
图1 3DGStream体系结构概述。给定一组多视角视频流,3DGStream旨在动态构建捕捉到的场景的高质量自由视点视频流。最初,我们优化一组3D图形(3DGs)来表示时间步0的场景。对于每个后续的时间步i,我们使用时间步i-1的3DGs作为初始化,然后进行两阶段的训练过程:第一阶段:我们训练神经变换缓存(NTC)来“缓存”3DG的平移和旋转。训练完成后,NTC转换3DG,为下一个时间步和当前时间步中的下一阶段做准备。第二阶段:我们在潜在位置生成额外的3DG,并通过定期修剪和添加进行优化。虽然转换后的和额外生成的3DG都用于渲染,但只有额外生成的3DG会被优化。
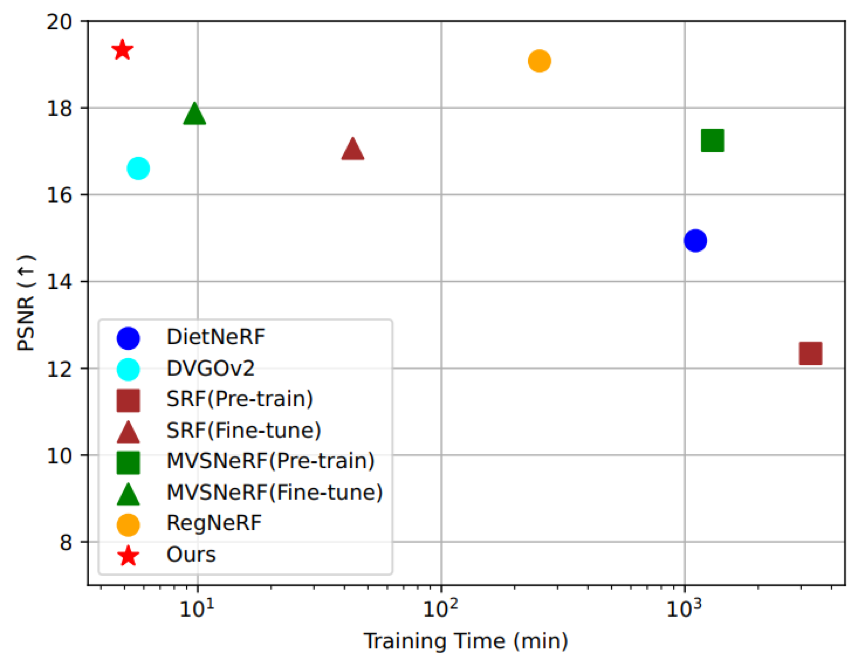
图2在N3DV数据集上的将3DGStream与其他方法进行了比较。□表示每帧从头开始训练,△表示在完整视频上进行离线训练,⃝表示在视频流上进行在线训练。在实现在线训练的同时,3DGStream在渲染速度和整体训练时间上均达到了最先进的水平。

图3 对Meet Room数据集的讨论场景和N3DV数据集的煎牛排场景进行定性比较。所有实验都是用相同的输入。
02
Illumination Distillation Framework for Nighttime Person Re-Identification and A New Benchmark
适用于夜间行人重识别的光照蒸馏框架以及一个新基准
作者:鹿安东1,张彰2,黄岩2,张一帆2,李成龙1,汤进1,王亮2
单位:1安徽大学,2中国科学院自动化研究所
邮箱:
adlu_ah@foxmail.com
zzhang@nlpr.ia.ac.cn
huangyan.750@outlook.com
yifanzhang.cs@gmail.com
lcl1314@foxmail.com
tangjin@ahu.edu.cn
wangliang@nlpr.ia.ac.cn
论文:
https://ieeexplore.ieee.org/document/10098634
代码:
https://github.com/Alexadlu/IDF
1. 引言
夜间行人重识别(Re-ID)是一项非常重要且具有挑战性的任务,但目前对该问题的研究还不深入。在低照度条件下,行人身份识别方法的性能通常会急剧下降。为了解决夜间行人Re-ID中光照不足的问题,本文提出了一种光照蒸馏框架(IDF),该框架利用光照增强和光照蒸馏方案来促进Re-ID模型在夜间场景的性能表现。此外,为了促进夜间行人Re-ID的研究,我们建立了一个真实的夜间行人Re-ID数据集,名为Night600,其中包含了在复杂室外环境下从不同视角和夜间光照条件下捕获的600个行人身份。
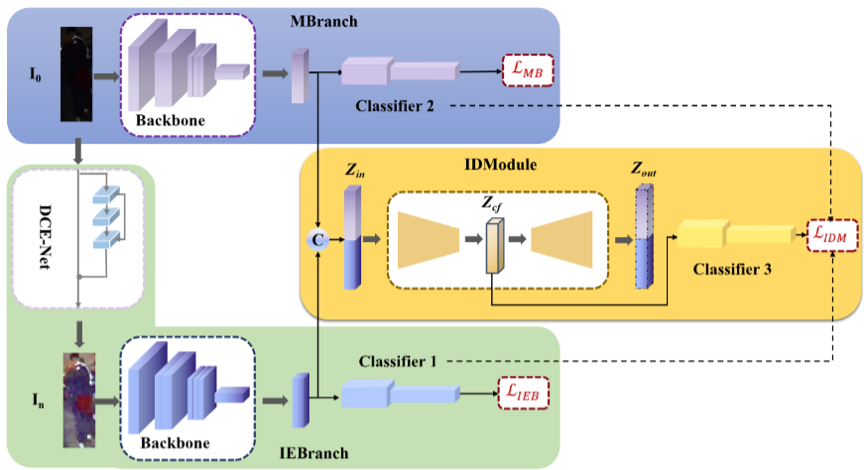
图1 IDF网络架构
2. 光照蒸馏框架
主分支:主分支用于从夜间图像中提取特征,虽然光照增强图像在视觉上可能比夜间图像更好,但在光照增强过程中可能会引入一些噪声,特别是在非常暗的区域。因此,在夜间图像中捕获额外的信息,这可以看作是对光照增强分支的补充。它可以减轻光照增强图像中的噪声干扰或过度增强问题。
光照增强分支:光照增强分支包含一个自监督光照增强网络 DCE-Net 和一个通用特征提取器。它首先使用 DCE-Net 增强夜间图像,然后使用特征提取器从光照增强图像中提取增强特征。
光照蒸馏模块:夜间和增强特征通常包含由于不稳定的光照条件和增强失败的数据噪声。为了充分利用夜间和增强功能的互补优势,同时抑制数据噪声,我们提出了一个光照蒸馏模块。光照蒸馏模块通过瓶颈融合模型将两个分支的特征融合,然后使用融合的特征以在线蒸馏的方式指导两个分支的学习。
3. Night600数据集
Night600 数据集是使用八个不重叠的摄像机从现实世界的夜间场景收集的,这些摄像机在常见的监控场景中具有平行和向下的视角。
表1 Night600和其他数据集的比较


图2 Night600和 Knight数据集的一些典型示例。Night600显示出比Knight更多样化的光照条件和摄像机视图
4. 实验
(1)基于可见光图像的夜间行人再识别必要性分析
虽然红外图像对于夜间 Re-ID 任务似乎更合理,但研究基于可见光图像的夜间 Re-ID 有以下三个主要原因:1) 热红外成本高昂,可见光摄像机在当前的监控系统中占大多数。因此,基于RGB的夜间Re-ID的研究十分必要;2) 由于红外光谱的限制,红外图像在捕捉详细的颜色和纹理信息方面存在固有缺陷,而这些信息在Re-ID任务中起着至关重要的作用;3)深度学习模型的训练依赖于大规模预训练模型,这些模型主要在可见图像数据集上进行训练,迁移到其他模态中往往存在域间差异。
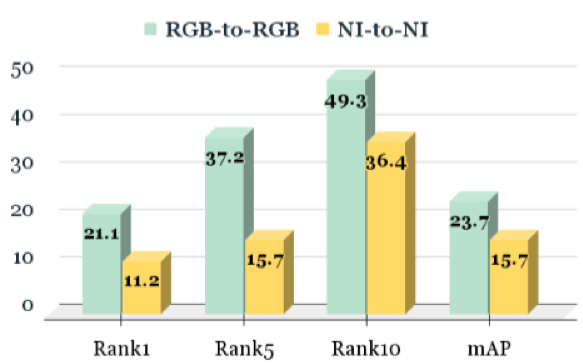
图3 AGW算法对 RGBNT201 数据集中可见光模态子集(RGB-to-RGB)和红外模态子集(NI-to-NI)的评估结果
如图3所示,AGW在可见光模态下取得了最好的性能,表明可见光模态相比近红外模态即使在夜间场景下仍然具有优势。
(2)数据集评估及方法有效性验证
我们对两个夜间行人Re-ID数据集进行总体评估和比较,最后进行深入分析以验证我们方法的有效性。
表2 现有的先进重识别方法在 Night600 数据集上的性能比较
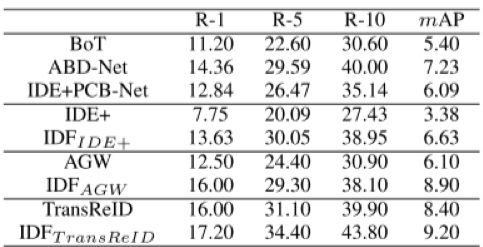
表3 三种低光照增强方法与现有 Re-ID 方法在 Night600 数据集上的性能比较
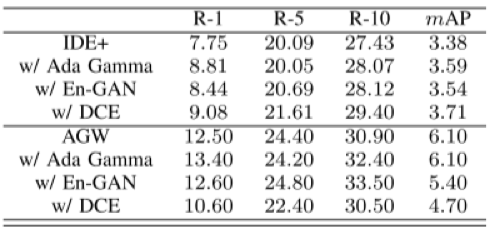
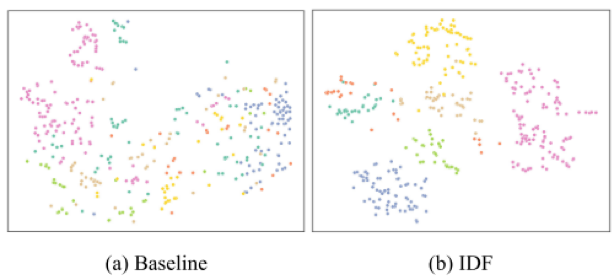
图4 IDF和基线特征分布的可视化。不同的颜色代表不同的ID
5. 总结
通过综合实验,我们展示了所提出的 IDF 的有效性。目前夜间重识别任务尚处于起步阶段,性能还有很大提升空间。在未来的工作中,我们考虑域适应技术,通过利用白天行人重识别数据来提高夜间行人重识别的性能。
03
Wave-like Class Activation Map with Representation Fusion for Weakly-Supervised Semantic Segmentation
作者:许镕涛、王常维、徐士彪、孟维亮、张晓鹏
单位:中国科学院自动化研究所多模态人工智能系统国家重点实验室,北京邮电大学
邮箱:
shibiaoxu@bupt.edu.cn,
weiliang.meng@ia.ac.cn
论文:
https://arxiv.org/pdf/2308.10449.pdf
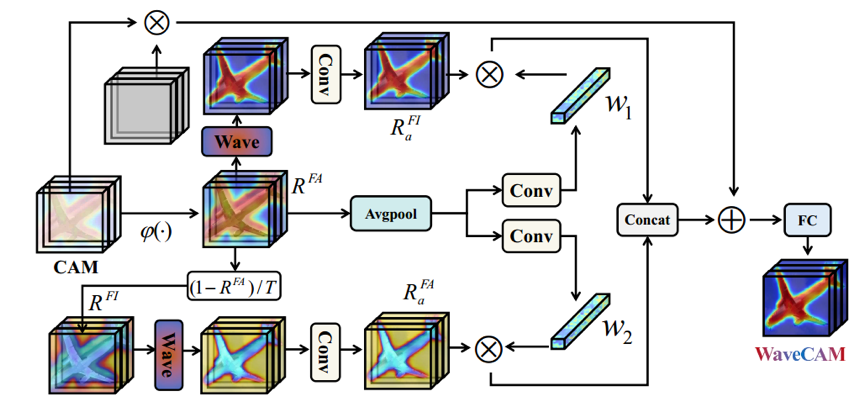
近年来,为了实现自动驾驶、面部分割、医学影像等需求,语义分割技术逐渐进入大众的视野中。为了节省资源,现在的主流方法是通过生成伪标签来实现弱监督语义分割技术。在此之前生成伪标签的主流方法是Class Activation Map(CAM),但是此方法没有考虑前景无关信息的建模,容易产生假阳性像素,为了解决这个问题,我们设计了WaveCAM方法,此方法在生成伪标签过程中将前景感知表示建模、前景无关表示建模融合在一起。正如图1所示,我们将前景感知表示(RFA)和前景无关表示(RFI)表示成带幅度和相位的波函数,初始化后动态聚合表示并提取语义信息,然后通过自适应融合模块进行融合。同时为了补充原始信息,我们将原始CAM与ReCAM启发的输入特征相乘,加入到前面生成的自适应融合表示中,得到初步的WaveCAM,最后再对其进行细化之后就成功生成了伪标签。
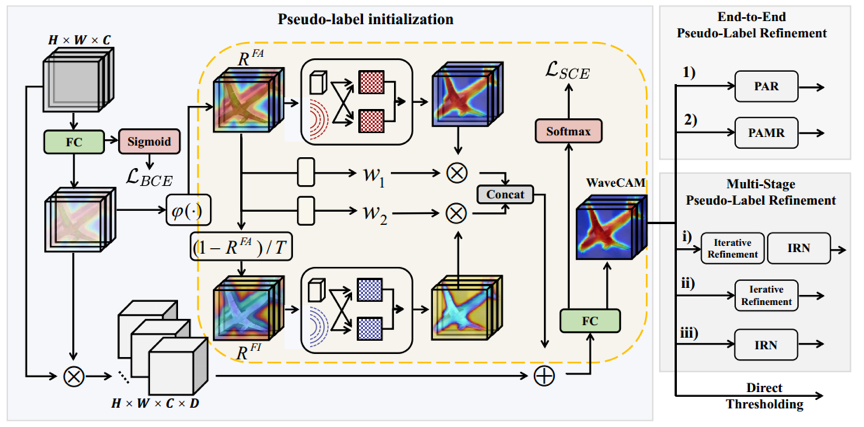
图1 使用WaveCAM为WSSS生成伪标签示意图
方法简介:
前景感知表示模型和前景无关表示模型建立
为了生成更加优良的伪标签,文章提出了将前景感知表示和前景无关表示进行融合的方法,首先需要对两种表示模型进行初始化,对于前景感知表示模型的初始化,文章提出直接使用Vanilla CAM进行初始化,如公式(1)所示,前景无关表示模型则使用公式(2)进行初始化。
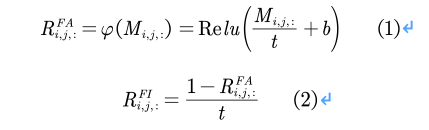
完成初始化后,由于有效的聚合前景感知表示和前景无关表示有利于补充前景和背景信息,提高CAM的质量,因此良好的进行表示聚合也是至关重要的。文章受量子计算的启发,为了提取有效的语义信息,这两种表示都被表示为带相位和振幅的波函数,因为波可以进一步用相位和振幅表示,以便在训练过程中动态调整权重。振幅可以表示表征的真实值,而相位项可以调制表征与固定权值之间的关系,将两种表示转换成波函数的公式如下:
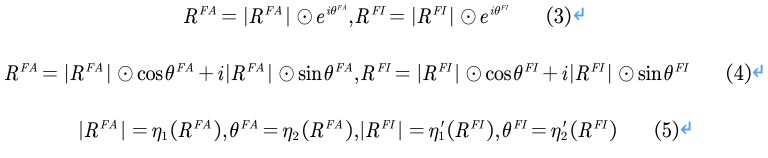
其中|RFA|、|RFI|表示振幅,��FA、��FI表示相位。计算细节如图2所示
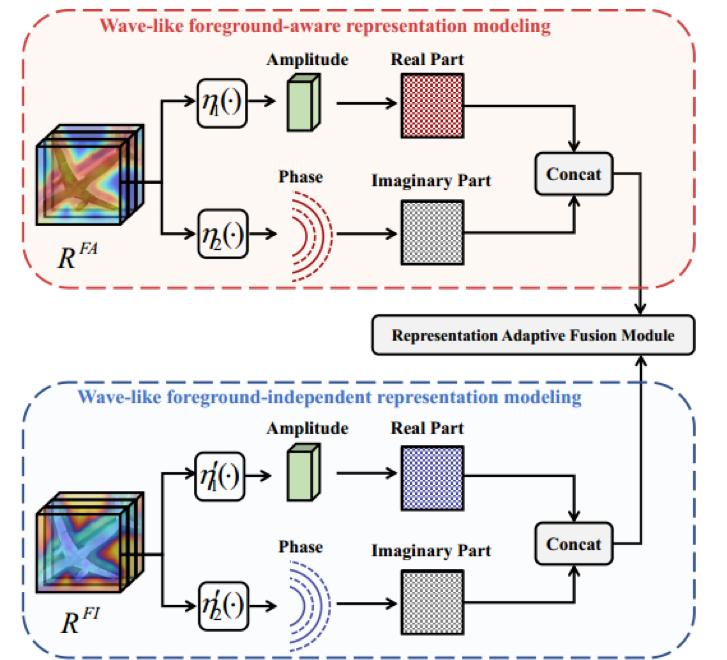
图2 类波感知前景表示建模和类波前景无关建模计算示意图
表示自适应融合模块
为了进一步增强前景感知表示 和前景无关表示的表达能力,我们又对其进行了加工,首先对结果RFA和RFI应用1*1卷积层,得到聚合RFA��和RFI��聚合,公式可以表示为:
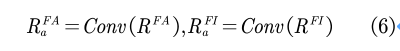
同时,为了自适应融合RFA��和RFI��,我们引入了可学习的自适应权值,即将初始化的RFA输入到平均池化层中进行空间聚合,然后分别通过不同的1*1卷积学习两个自适应权重(��1,��2),公式表示为:
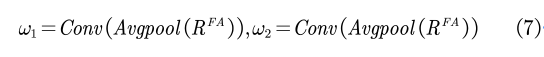
最后将得到的两个权重与对应的两个表示相乘并连接在一起,并且为了补充原始信息,我们还将原始CAM和受ReCAM启发的特征映射F相乘,并添加到自适应融合表示中,便成功得到WaveCAM,计算方法如公式(8),整体结构如图3所示

优化与应用
这里我们使用BCE损失函数来监督Vanilla CAM的全连接层,使用SCE损失函数来监督我们的WaveCAM的全连接层,其中SCE的损失函数表示为:

生成的WaveCAM的总体目标函数表示为:
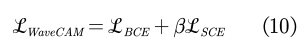
对于多级WSSS方法,我们在生成最终的伪标签后,我们训练了一个完全监督的语义分割模型来预测分割结果,完全监督分割模型的目标函数表示为:
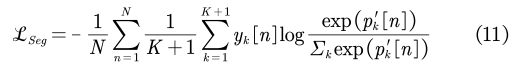
对于端到端WSSS,由于WaveCAM也是即插即用的端到端WSSS方法,所以我们只需要将CAM的生成替换为我们的WaveCAM的生成,并添加生成WaveCAM的目标函数即可,在文章中,端到端WSSS实现的总损失函数表示为:
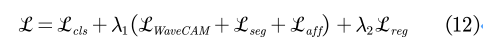
实验部分:
文章在PASCAL VOC 2012数据集和MS COCO 2014数据集构建实验,采用平均交并差(mloU)作为评价标准。
如图4所示,为了定性的分析伪标签生成的质量,我们展示了一些视觉示例,可以看出,与ReCAM方法相比,我们的方法可以生成具有更完整覆盖和更少过度激活像素的CAM以及更高质量的伪标签。
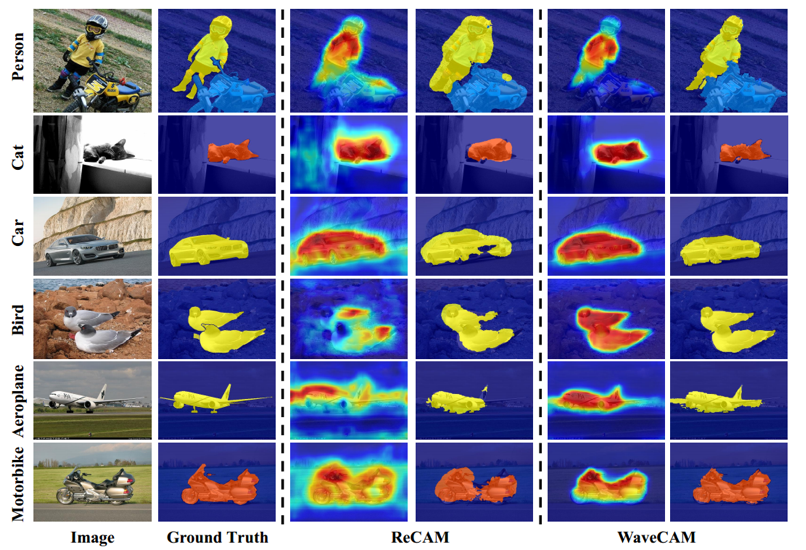
图4 在PASCAL VOC数据集上使用ReCAM和WaveCAM生成的伪标签的比较示意图
表2 在两个框架上不同语义分割模型对比
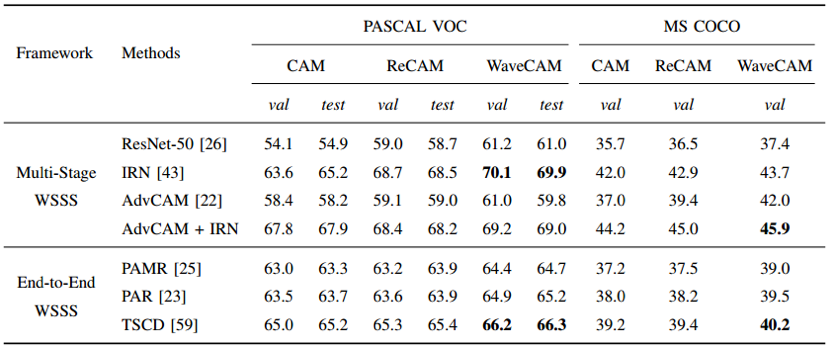
从表2可以看出,我们所使用的方法无论是在PASCAL VOC数据集还是在MS COCO数据集上面的molU值都高于基于相同图像级监督的最先进方法。对于伪标签细化方法,IRN和PAR分别基于我们的WaveCAM在多级WSSS和端到端WSSS上实现了最先进的性能。
图5展示了在PASCAL VOC数据集上语义分割结果的一些视觉示例,图6给出了在MS COCO 数据集上的一些语义分割结果,可以看出无论在哪种数据集我们的方法相比较与ReCAM能够更好的生成与对象边界很好对齐的分割掩码,但是我们的方法在捕获彼此之间或者颜色与周围环境相似的重叠对象方面还是存在不足,如图5中的人与摩托车之间的像素。

图5 ReCAM和WaveCAM在PASCAL VOC数据集上的语义分割效果对比

图6 ReCAM和WaveCAM在MS COCO数据集上的语义分割效果对比
本项工作得到了国家自然科学基金(项目编号U21A20515、62271074、U2003109、62171321、62071157和62162044)、中国科学院空间应用工程与技术中心开放研究基金(项目编号LSU-KFJJ-2021-05)以及模式识别国家重点实验室开放项目计划的支持。
04
A Dual Reinforcement Learning Framework for Weakly Supervised Phrase Grounding
作者:王志宇1,杨超1,*,蒋斌1,袁浚菘2
单位:1湖南大学,2纽约州立大学布法罗分校
邮箱:
zhiyuwang@hnu.edu.cn
yangchaoedu@hnu.edu.cn
jiangbin@hnu.edu.cn
jsyuan@buffalo.edu
论文:
https://ieeexplore.ieee.org/document/10098112
1. 研究背景和动机
短语定位旨在图像中定位出文本短语所描述的目标,而弱监督短语定位则面临着更大的挑战,其在缺乏文本描述-区域目标的细粒度标注信息的情况下,仅依靠文本描述-图像的粗粒度信息,实现高精度的短语定位。现有的主流方法可以分为两大类:短语描述重建和图像-文本对齐。然而,现有方法的优化目标为图像层级的语义对齐,而短语定位的优化目标为目标层级的语义对齐,两者存在显著的优化目标差异。本文提出了一种直接对齐目标层级语义的新方法,所提方法的核心思想是查询目标和短语描述之间存在的双向对应关系。具体来说,如果一个短语查询被正确地定位,那么就能够基于定位的目标重新生成相似的短语描述(如图1 (a) 所示)。类似地,如果使用自然语言准确地描述了某一目标,则可以根据生成的短语查询定位出所描述目标的位置(如图1 (b) 所示)。因此,短语定位任务和自然语言查询生成任务可以互相充当代理任务,为彼此提供反馈信号以衡量模型的性能。
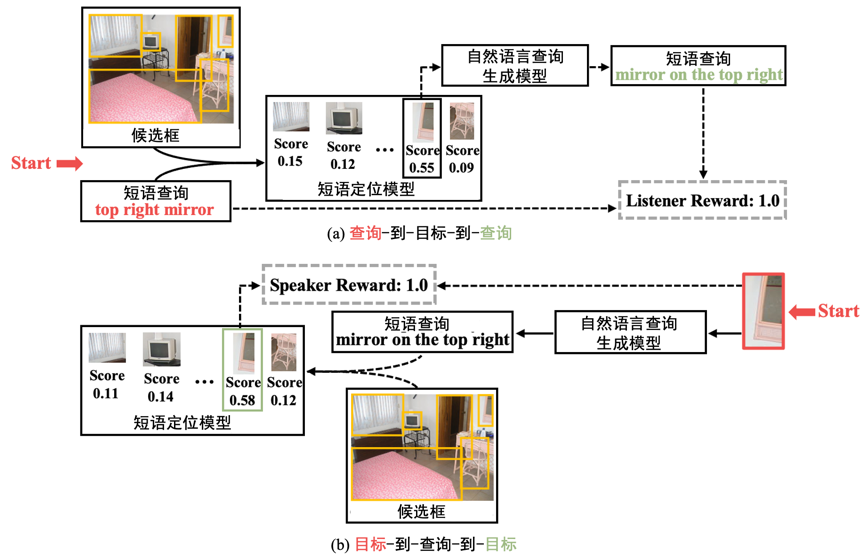
图1 查询目标与查询短语的双向对应关系
2. 方法概述
本文提出了一种新颖的对偶强化学习框架,利用短语定位和自然
语言查询生成任务的对偶性提供目标层级的对齐监督方式。如图2所示,该框架包含了两个模型的协同训练:短语定位模型(Listener)和自然语言查询生成模型(Speaker),其中Listener模型的目标是基于自然语言查询(短语描述)进行目标定位,而Speaker模型的目标是生成描述目标对象的自然语言查询。值得一提的是,该框架不依赖于特定的Listener和Speaker模型,具备一定的通用性。例如,能够使用更加先进的短语定位模型替代Listener,进一步提升所提框架的性能。由于Speaker模型在生成短语查询过程中需要逐单词采样,而该采样过程不可导,因此本文采用强化学习算法对模型进行优化。本文设计了两个奖励函数,即图中的Listener reward和Speaker reward,分别用于衡量定位目标和生成自然语言查询的准确性。此外,为了解决模型初期难以训练的问题,本文进一步提出了一种启发式算法(如图2 (b) 所示),利用预训练的目标检测器生成伪目标-查询对,并用这些伪标签数据预训练的Listener和Speaker模型。
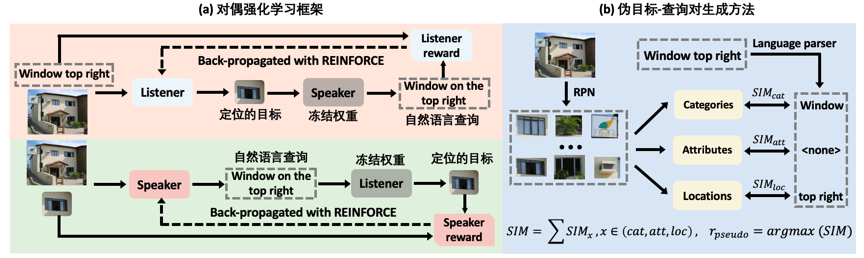
图2 基于对偶强化学习的弱监督短语定位方法
3. 实验分析
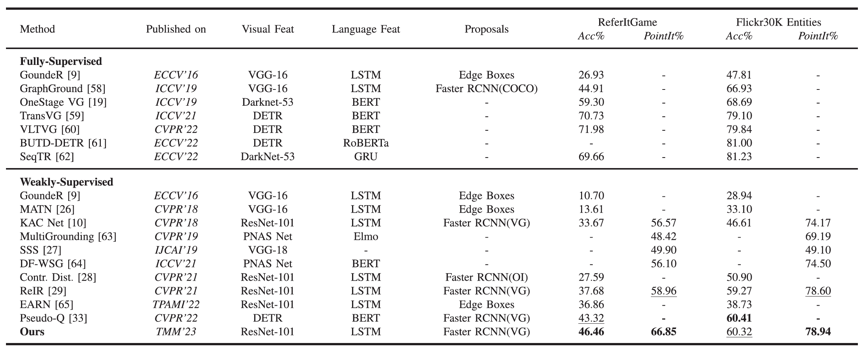
本文在ReferIt和Flickr30K Entities两个主流数据集上进行实验,实验结果如下表所示,证明了方法的有效性。
表1 所提方法在两个主流数据集上的实验结果
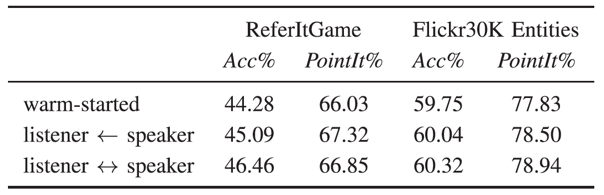
此外,在两个数据集的进一步消融实验也证明了利用短语定位和自然语言查询的对偶性能够提升弱监督短语定位的性能。
表2 所提方法在两个主流数据集上的消融实验
05
A Structure-Preserving and Illumination-Consistent Cycle Framework for Image Harmonization
基于结构保持和光照一致性循环架构的图像和谐化
作者:蔡珣、史清杰、高艳博*、李帅、华炜†,谢天†
单位:山东大学,†之江实验室
邮箱:
ybgao@sdu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10078341
背景:
在图像的应用中,常需要将人物放入各种风景图像中,并对图像进行编辑和合成。合成图像中的前景和背景往往来自不同的场景,比如不同的季节和光照条件,因此会导致前、背景图像风格的不一致,降低合成图像的真实感。为解决合成图像前景和背景之间颜色光照不和谐问题,图像和谐化技术被提出。
图像和谐化作为计算机视觉领域中的重要问题,需要在保持结构的同时将合成图像的前景调整到背景风格或域信息下,使合成图像在主观感受上更加真实。其可应用于图像增强、图像风格转化等多个领域。
方法:
目前的前景图像和谐化算法通常会使用一种基于重建损失函数的方法来监督学习过程来训练网络。然而,简单的监督整张图像,不区分图像结构和光照信息,这并不适用于图像和谐化任务,因为图像的中像素点值的改变可能是来自光照,也可能是来自结构。
为了解决这个问题,本文将前景图像和谐化分解为两个子任务:图像的前景光照与背景光照一致,保持图像前景的结构信息不变,用公式表示为:
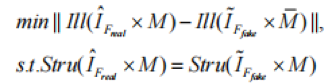
在公式中, ∙和∙分别代表图像的光照和结构;|| • ||表示不同图像之间的光照距离。由于图像中的光照和结构往往相互混合,直接从图像中提取结构或光照是不可能的,或提取到的特征信息非常不准确。因此,本文提出了一种基于循环生成对抗网络的前景光照一致性与结构保持(SP-IC)循环架构,利用背景来辅助分解图像的光照信息和结构。
其总体结构如下图1所示:
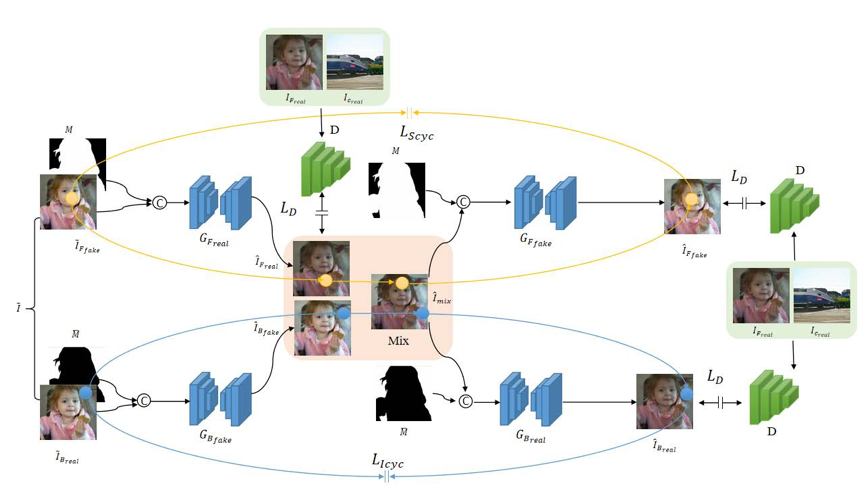
图1 基于结构保持和光照一致循环的图像和谐化架构
在光照一致性循环中(下部分),合成图像\hat{IFfake}和前景掩膜\overline{M}输入到生成器GBfake中,得到前景根据原始背景改变的和谐化图像\hat{IBfake}。然后将\hat{IFreal}和\hat{IBfake}根据不同掩膜混合,构成一个由假背景和真前景组成的混合合成图像mix。根据此混合合成图像和背景掩膜\overline{M},假背景可以根据mix中前景Freal的光照再次和谐化,此过程构成了一种光照一致性前景和谐化循环。
而在结构保持前景和谐化循环中(上部分),合成图像\hat{IFfake}和前景掩膜M输入到生成器中,得到前景根据原始背景光照改变的和谐化图像\hat{IFreal},这也是整个架构的目标和谐化图像。而和谐化的前景又被用于恢复原始假前景,该循环通过保证中间的被和谐化后前景结构与真实前景结构一致,以确保和谐化过程中前景结构信息不改变。
实验:
为验证本文提出的SP-IC循环架构的有效性,将提出SP-IC循环架构与现有的具有代表性、最新的图像和谐化方法进行比较。与现有的工作相同,采用MSE、PSNR和SSIM作为本工作的评估指标,并且将fMSE用作附加评估指标,来比较算法在不同的前景占比范围的效果。在iHarmony4中的四个测试子数据集上,分别对这些方法进行评估,其比较结果如表1所示。并将基准图像和生成图像之间的差异使用不同的颜色映射表示展示到图2中,红色代表差异大,与之相反,蓝色代表差异小。与其他算法相比,SP-IC循环架构取得了较好的结果。
表1 不同算法在iHarmony4测试数据集上结果比较
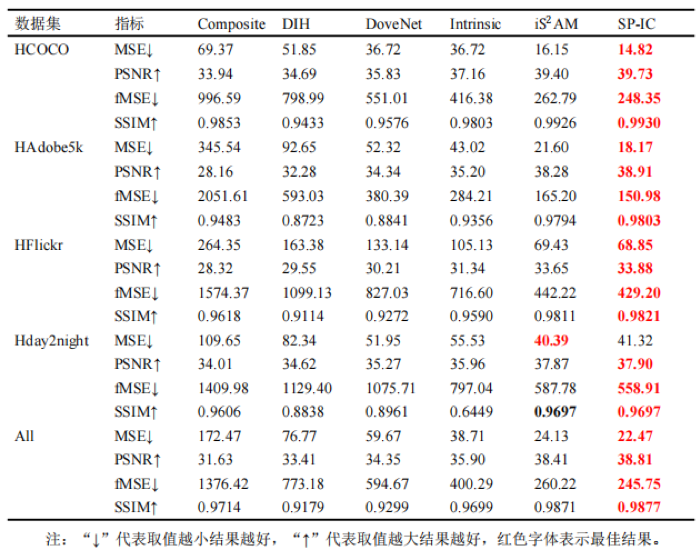
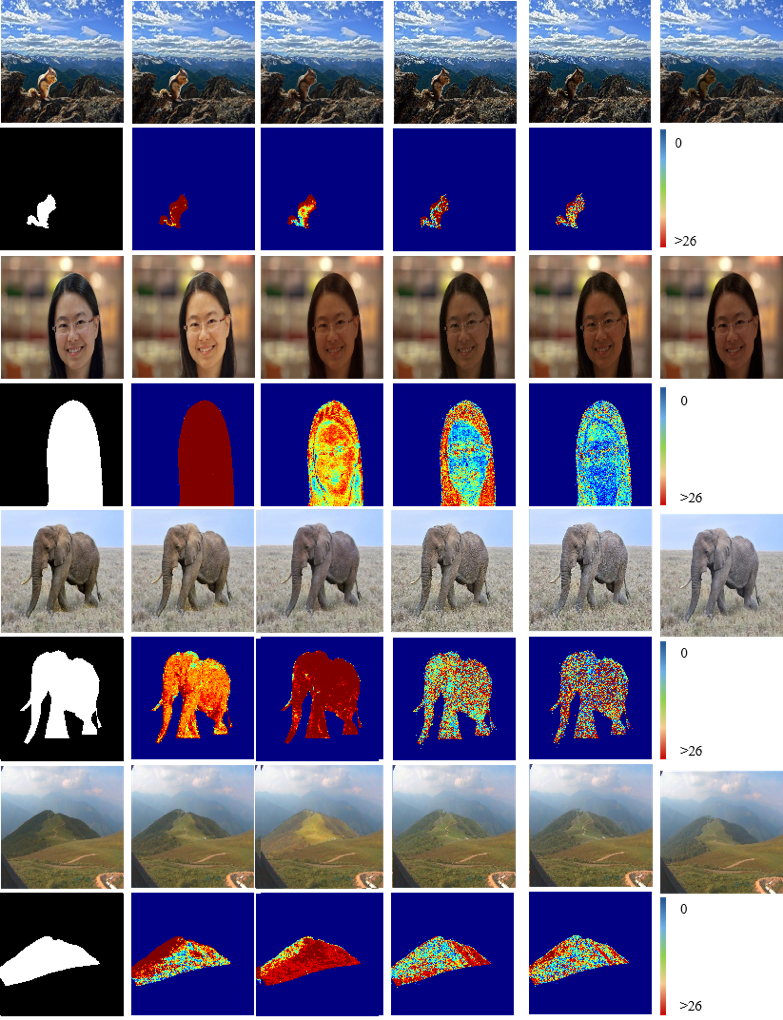
图2 不同方法在 iHarmony4 测试集上的对比。(a) 输入/掩膜 (b) DoveNet (c) Intrinsic (d) i AM (e) SP-IC (f) 基准图像
06
Improving Handwritten Mathematical Expression Recognition via Similar Symbol Distinguishing
一种针对形近符号辨识的手写数学公式识别方法
作者:李喆1,4,王欣雨2,刘禹良3,金连文1,黄毅超4,丁凯4
单位:1华南理工大学,2阿德莱德大学,3华中科技大学,4上海合合信息科技股份有限公司
邮箱:
zheli0205@foxmail.com
xinyu.wang02@adelaide.edu.au
ylliu@hust.edu.cn
eelwjin@scut.edu.cn
charlie_huang@intsig.net
danny_ding@intsig.net
论文:
https://ieeexplore.ieee.org/abstract/document/10078345
1. 引言
近年来,随着深度学习技术的不断发展,手写数学公式识别算法已经取得突破性的进展,并被广泛应用于人机交互、自动化办公和智慧教育等多个场景。然而,现有的手写数学公式识别算法在识别视觉形状相似的符号时容易出现错误,大大降低了算法在实际应用场景下的性能。如图1所示,来自数字、英文字母和希腊字母等不同字符集的符号在形状上具有很高的相似性。同时,变化多样的书写风格进一步加大了算法辨识视觉形状相似符号的难度。为了解决这一问题,本文基于注意力编解码器模型,从特征提取增强、语言模型纠正和多模型集成三个角度提出了三种创新方法:(1)路径积分特征提取方法;(2)符号组语言模型纠正方法;(3)基于DTW的模型集成方法。
图1 易混淆的形近符号
2. 方法
路径积分特征提取方法:每份数学公式的书写轨迹数据是一条二维平面上的采样点坐标序列。为了提取手写数学公式的特征,现有的方法主要采用RNN直接对坐标序列进行特征编码,或CNN对从坐标序列恢复的手写图像进行特征编码。然而,前者忽略了具有空间语义特征的图像信息,且容易受到书写笔画乱序的影响,后者则忽略了符号书写轨迹的信息,例如笔画的顺序、方向和速度等。本文提出一种路径积分特征(path signature features)提取方法,通过对书写轨迹计算路径迭代积分并进行二维平面上的位置特征映射,同时保留了书写轨迹中的局部书写笔画信息和全局空间结构信息。这个方法不依赖于书写笔画的顺序,且几乎没有引入额外的模型计算量和参数量。
符号组语言模型纠正方法:文本行识别算法通常使用语言模型,利用初步识别的文本序列中的上下文语义信息,计算序列各个位置具体符号类别的识别概率,从而纠正文本行识别结果。然而,这种方法并不适用于公式识别算法。当前主流的公式识别算法通常以LaTeX序列作为识别结果。LaTeX序列中每个位置可能有多个符号满足语法并具备相关的语义,利用语言模型预测具体的符号类别会造成歧义。而通过观察发现,包括图1例子在内的形近符号,它们在公式中通常具有不同的含义。受此启发,本文提出了一个符号组语言模型纠正方法,先根据符号在公式中的常见含义对符号进行分组,再利用初步识别结果的语义信息预测序列各个位置所属符号组的概率,最终通过排斥属于其他符号组的符号识别结果实现纠正。
基于DTW的模型集成方法:神经网络的优化结果是一个局部最优解,并非全局最优解,且不同的初始化参数会导致不同的收敛结果。这导致了手写数学公式识别模型存在拟合偏好,不同模型对易混淆的形近符号具有不同的识别倾向。当前的公式识别算法利用多模型集成来缩小模型拟合偏差并提升整体的识别性能。这些方法通常是基于位置对齐的,在相同序列位置将多个模型的预测概率进行累加,并将累加后的最大概率符号作为最终的预测。然而,不同识别模型对同一个样本的识别序列长度可能是不一致的,上述方法会导致部分符号的预测概率被累加到错误的位置。本文提出一种基于DTW的模型集成方法,先通过DTW对齐不同模型的预测序列,再对模型的预测概率进行累加,从而实现集成预测。
整体算法框架如图2所示。
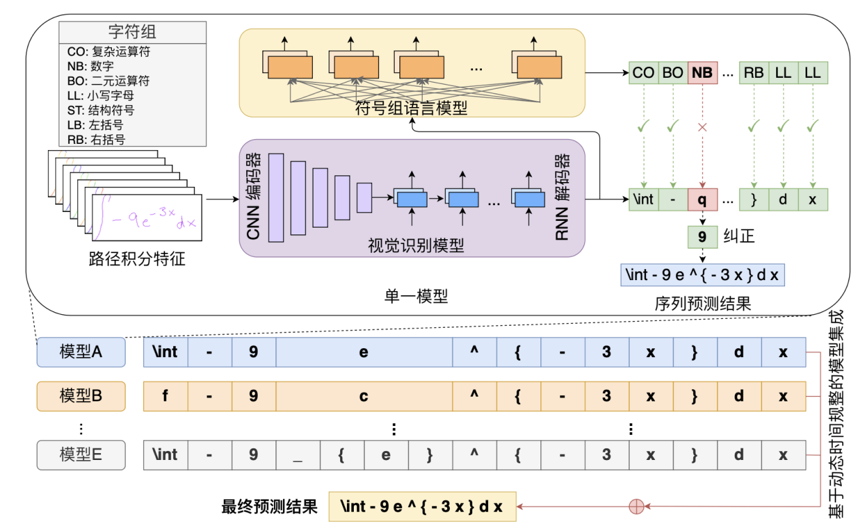
图2 算法整体框架
3. 实验
本文所提出的算法采用公开的CROHME训练集进行训练,并采用CROHME2014、CROHME2016和CROHME2019进行性能测试。本文使用表达式识别率(ExpRate)作为评估指标,考量整条公式LaTeX序列的识别正确率。表1、表2和表3分别为路径积分特征提取方法、符号组语言模型纠正方法和基于DTW的模型集成方法的消融实验。实验结果证明了本文提出方法的有效性。
表1 路径积分特征方法消融实验结果
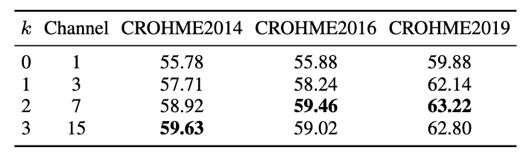
表2 符号组语言模型消融实验结果
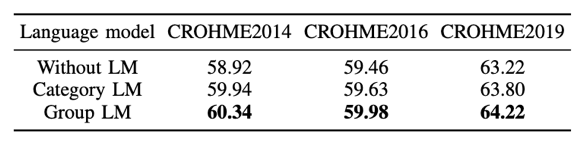
表3 基于DTW的模型集成方法消融实验结果

 京公网安备11010802017125号
京公网安备11010802017125号