
【论文导读】2024年论文导读第四期
CCF多媒体专委会 2024-02-27 18:03 山东


论文导读
2024年论文导读第四期(总第九十五期)
目 录
|
1 |
Feature Staleness Aware Incremental Learning for CTR Prediction |
|
2 |
Hierarchical Locality-Aware Deep Dictionary Learning for Classification |
|
3 |
ATZSL: Defensive Zero-Shot Recognition in the Presence of Adversaries |
|
4 |
GraphCFC: A Directed Graph Based Cross-Modal Feature Complementation Approach for Multimodal Conversational Emotion Recognition |
|
5 |
Reinforcement Learning Approaches for Traffic Signal Control under Missing Data |
|
5 |
Exploring large language model for graph data understanding in online job recommendations |
01
Feature Staleness Aware Incremental Learning for CTR Prediction
特征陈旧性感知增量学习方法在点击率(CTR)预测中的应用(FeSAIL)
作者:王智恺1,沈艳艳1,张梓滨2,林康熠2
单位:1上海交通大学计算机科学与工程系,2腾讯
邮箱:
cloudcatcher.888@sjtu.edu.cn,
shenyy@sjtu.edu.cn,
bingoozhang@tencent.com,
plancklin@tencent.com
论文:
https://www.ijcai.org/proceedings/2023/0261.pdf
代码:
https://github.com/cloudcatcher888/FeSAIL
在实际的推荐系统中,点击率(CTR)预测任务通常面对着每天数以亿计的用户交互记录。为了提高训练效率,人们通常采用增量方式更新CTR预测模型,即利用新产生的数据以及部分历史数据进行增量学习。然而,当特定特征在当前的增量数据中不再出现时,这些特征的嵌入表示会变得陈旧,从而导致模型性能下降,我们称之为特征陈旧性问题。为了解决这一问题,我们提出了一种面向CTR预测的特征陈旧性感知增量学习方法(FeSAIL),该方法能够自适应地重复利用包含陈旧特征的样本。首先,我们引入了一种基于特征陈旧性的样本采样算法(SAS),它可以有效选取包含陈旧特征的固定数量样本,将其作为最大加权覆盖问题进行贪婪求解,以确保采样效率。接着,引入了一种基于特征陈旧性的正则化机制(SAR),对低频特征的更新进行了精细化的控制。我们将FeSAIL实现在一个通用的基于深度学习的CTR预测模型上,并通过在四个基准数据集上的实验结果证明了FeSAIL在性能上优于现有的多种技术方法。
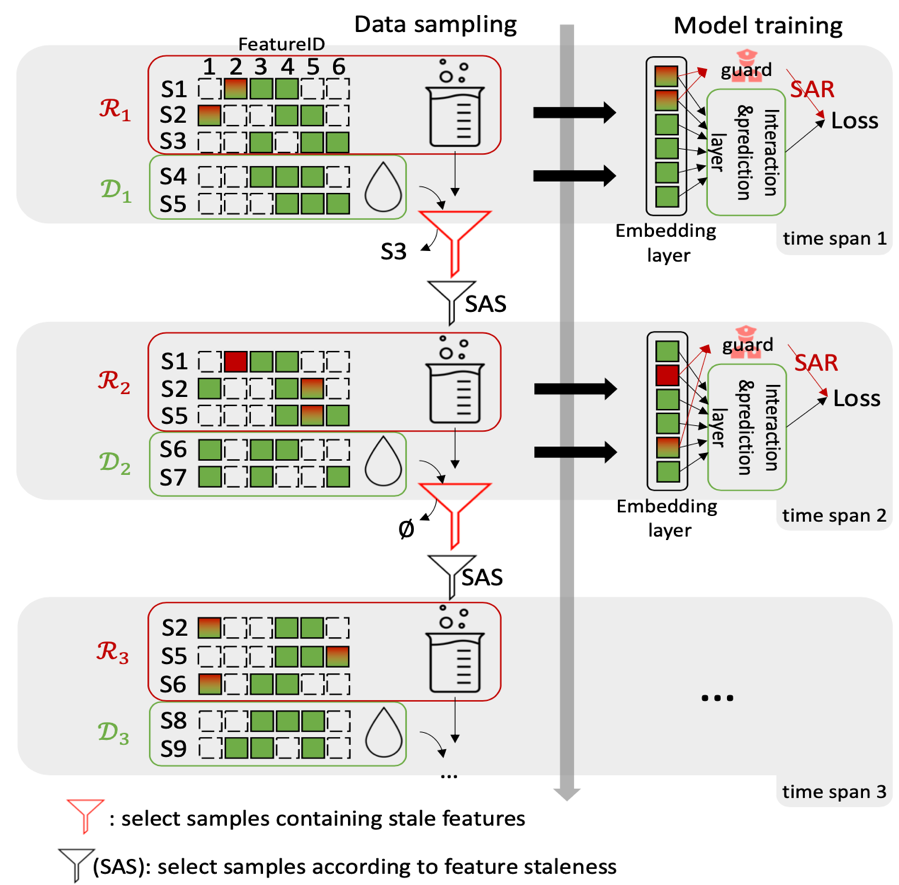
框架示意图
实验也进一步深化了我们的理论分析。在现有的三个公共数据集和一个私有数据集的测试中,FeSAIL与最先进的增量学习方法相比,在平均AUC上取得了1.21%的提升。这些实验展示了FeSAIL如何有效地减轻特征陈旧性问题,以及如何提高CTR预测的准确性。
02
Hierarchical Locality-Aware Deep Dictionary Learning for Classification
分层局部感知深度字典学习分类
作者:苟建平1,何鑫2,Lan Du3,Baosheng Yu4,陈雯柏5,章毅6
单位:1西南大学,2江苏大学,3莫纳什大学,4悉尼大学,5北京信息科技大学,6四川大学
邮箱:
cherish.gjp@gmail.com
论文:
https://ieeexplore.ieee.org/document/10100909
1.引言
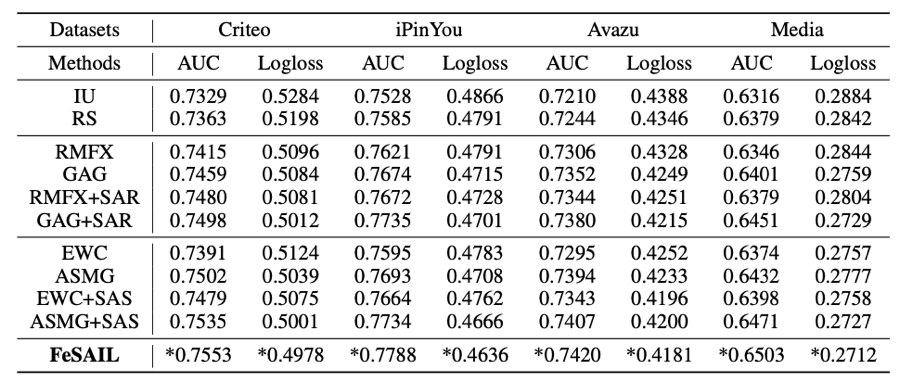
深度字典学习(DDL)在计算机视觉分类领域取得了显著的效果。现有的深度字典学习方法虽然能提取比浅层字典更抽象的图像特征,但在字典学习方法中直接使用所有字典元来最优重构原始输入样本,忽略每层输入数据表示与学习到的字典元之间的局部关系,导致在特征编码阶段学习到的数据表示缺乏有效的可鉴别性。为了解决该问题,提出一种新的深度字典学习框架即分层局部感知深度字典学习(HILADLE)模型(如图1),主要通过分层字典学习在不同抽象层次上学习局部性约束的字典元。所提深度字典学习框架结合了字典学习和深度学习的优势,能够在特征编码阶段保留数据的局部结构信息,同时提取样本更抽象的特征表示,且在各字典学习层间选择了ReLU非线性激活函数来处理过度参数化所导致的过拟合问题,从而提高模式分类性能。
2.方法
(1)分层局部感知深度字典学习框架:提出一种新的深度字典学习框架,考虑每层字典学习的输入数据表示与字典元间的局部结构信息。具体来说,在字典学习阶段,通过局部约束将局部信息嵌入到分层字典学习过程中,使得学习到的字典更好地进行数据表示。在编码阶段,输入数据表示主要由与其最接近的字典元来表达,从而在字典更新中保留输入数据的局部性结构信息,生成更具信息量的字典和更具鉴别性的数据表示。
(2)激活函数:使用ReLU激活函数确保特征编码的稀疏性,解决模型过参数化所导致的过拟合问题,并通过全连接层融合所有字典学习层学到的特征表示,作为最终分类器的输入。
(3)无监督学习:HILADLE的学习过程不需要监督信号,使其适应能力更加广泛,适用于处理有限的标注数据。
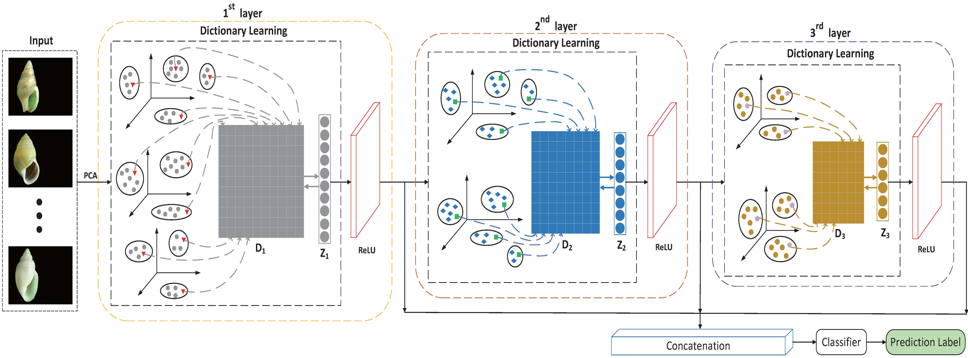
图1分层局部感知深度字典学习
为了更好地展示输入数据和字典元间的局部性结构信息,且验证所提深度字典学习的有效性,可视化了DDL与HILADLE各分层字典中输入数据表示与字典元间的2-D表示(如图2)。结果显示HILADLE对输入数据的局部可鉴别结构信息进行有效编码,即输入数据表示主要由离它最近的字典元来构造,而DDL没有这种特性。
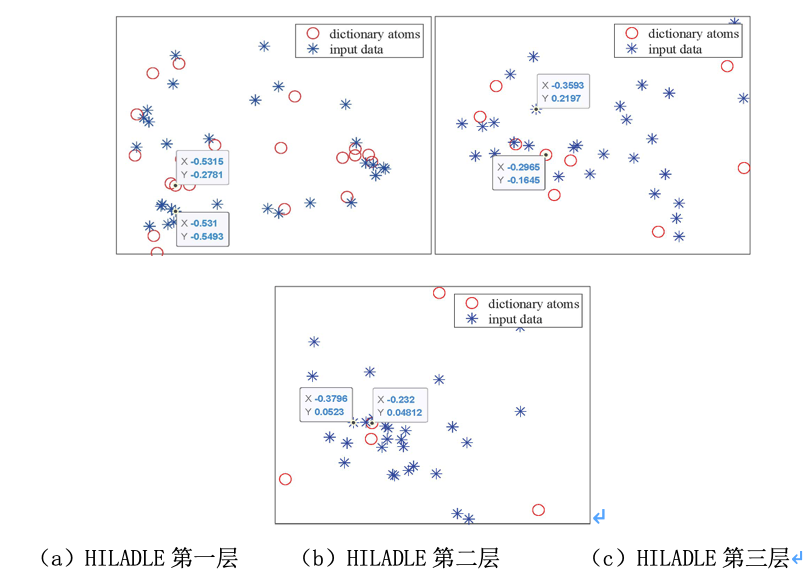
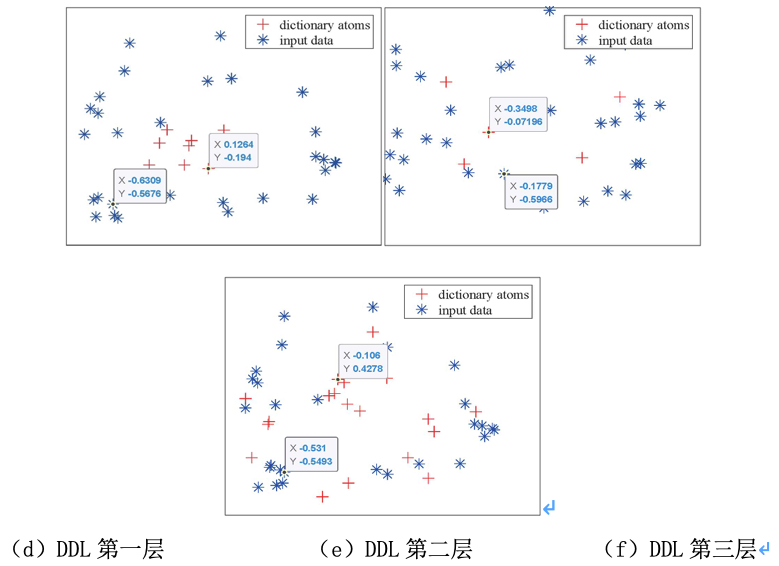
图2 DDL与HILADLE在2D空间的多层字典学习输入数据和字典原子示例
3.实验
所提方法在三个人脸识别数据集(AR Face、Extended YaleB Face和CropGT Face)和四个图像分类数据集(Shell、UCI Folio Leaf、COIL-100和Scene-15),以及一个年龄估计数据集(FG-NET)上进行了对比实验,实验结果表明所提HILADLE优于其他字典学习、深度字典学习等方法,原因在于其在深度字典学习过程中考虑了数据的局部结构信息,能够提取到更具鉴别性的特征表示信息, 从而提高模式识别能力。
表1人脸数据集实验结果

表2图像数据集实验结果
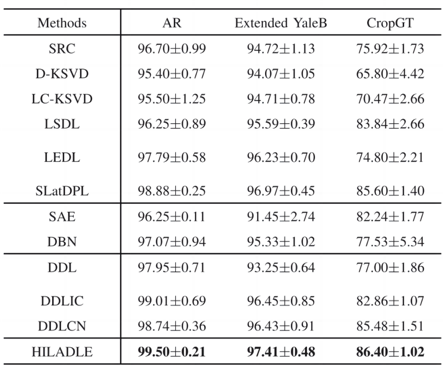
表3 FG-NET数据集实验结果

03
ATZSL: Defensive Zero-Shot Recognition in the Presence of Adversaries
作者:张幸幸1,贵书鹏2,金鉴3,朱振峰4,赵耀4
单位:1清华大学,2 Meta,3南洋理工大学, 4北京交通大学
邮箱:
xxzhang1993@gmail.com;
shupenggui@gmail.com;
jian.jin@ntu.edu.sg;
zhfzhu@bjtu.edu.cn;
yzhao@bjtu.edu.cn
论文:
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10078354
【摘要】零样本学习 (Zero-shot learning, ZSL) 由于在细粒度目标识别、检索和图像字幕等领域的广泛应用而受到了极大的关注。由于缺乏训练样本且对防御迁移能力的要求很高,ZSL模型特别容易受到对抗性攻击的影响。最近的研究也表明,对抗性鲁棒泛化需要更多的数据。这可能会显著影响ZSL的鲁棒性。然而,针对这一方向的努力还很少。在本文中,我们首次尝试提出了一个通用的建模方式,为学习防御性的ZSL模型提供了一个系统的解决方案(命名为ATZSL)。它能在只对原始图像的性能几乎没有影响的情况下,通过将ZSL问题转化为一个最小-最大优化问题,实现对各种对抗性目标识别的更好泛化。为了求解这个优化问题,我们设计了一个防御性关系预测网络,它可以通过目标之间的属性信息将已知和未知类域桥接起来,以泛化预测和防御策略。此外,我们的框架还可以扩展到处理未知类属性的中毒场景。然后,我们设计了一组广泛的实验,证明ATZSL在各种设置下,与当前可用的替代方案相比,获得了在模型可转移性和鲁棒性之间显著更有利的权衡。
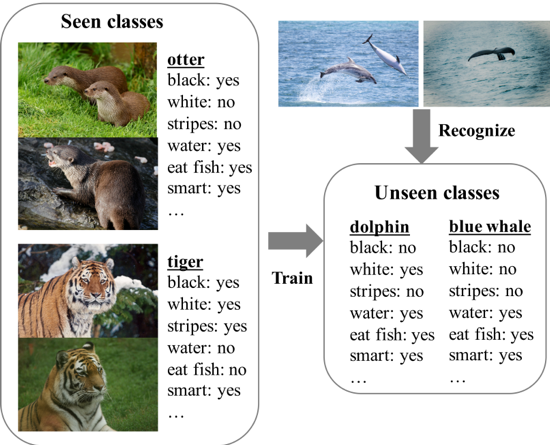
图1用视觉图像和类原型定义ZSL问题(基于AWA2数据集)
【方法】为了提高ZSL模型的鲁棒性,我们在模型训练过程中进一步向训练集中注入对抗性样本。具体来说,当一个干净图像xtri输入到ZSL模型时,攻击者被允许以有界幅度��扰动该图像变成xtr'i。然后根据干净图像的ZSL损失函数L

我们提出了ATZSL的整体优化公式。这里,ATZSL算法被建模为如下min-max优化问题:
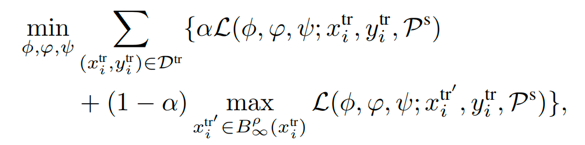
其中,第二项旨在通过最大限度地破坏ZSL模型的性能来生成对抗样本。α用于平衡干净样本和对抗样本的效果。
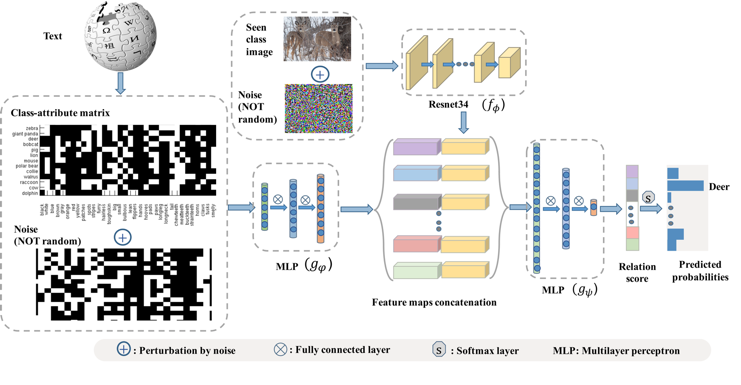
图2本文提出的ATZSL架构,旨在利用防御性关系预测网络实现鲁棒地零样本识别。其中,f�� 、g��和g�� 分别代表特征提取模块、属性嵌入模块和关系预测模块。
【实验】本文首先在AWA2和CUB数据集上展示了标准ZSL结果,这些结果包括视觉和语义空间中的各种攻击。
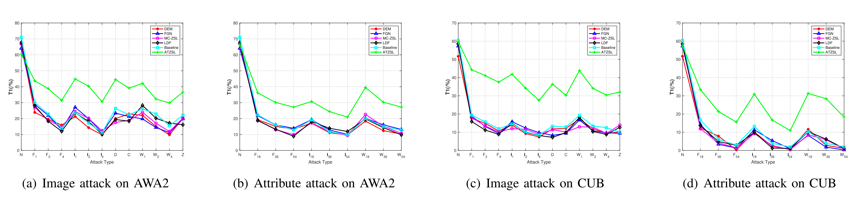
然后进一步提供了更为通用的ZSL(测试数据同时涉及见过和没见过的类)的实验结果。
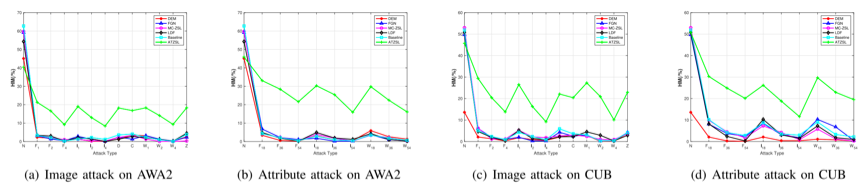
总的来说,实验结果展示了ATZSL在干净和对抗数据上可以达到明显更具竞争力的标准ZSL性能权衡。更重要的是,正如上述结果所示,这些明显的改进并没有牺牲ATZSL在无攻击场景下的性能。
【总结】在这项工作中,我们解决了在零样本学习中同时实现高鲁棒性和高迁移性这一新问题。为此,我们开发了ATZSL:一种通过将这两个目标整合到一个统一的约束优化框架中的对抗性训练零样本模型。具体来说,设计了一种防御性关系预测网络,用于将知识从已见类别域迁移到未见类别域。同时,在训练阶段,我们向网络中注入了对抗性图像或属性,以将知识从干净域迁移到对抗性域,从而学习到一种防御性的零样本学习模型。通过以下观察,进行了广泛的实验来证明ATZSL的有效性和效率:1)与最先进的零样本学习模型及其变体相比,我们的ATZSL在各种对抗性数据上对零样本识别任务的表现始终更好,同时在干净数据上的性能损失微不足道;2)在标准或广义零样本学习设置下,ATZSL能够始终对不同的攻击者保持鲁棒性。
04
GraphCFC: A Directed Graph Based Cross-Modal Feature Complementation Approach for Multimodal Conversational Emotion Recognition
GraphCFC:面向多模态对话情绪识别的有向图跨模态特征互补方法
作者:李江,王小平,吕国庆,曾志刚
单位:华中科技大学
邮箱:
lijfrank@hust.edu.cn,
wangxiaoping@hust.edu.cn,
guoqinglv@hust.edu.cn,
zgzeng@hust.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10078161
对话中的情绪识别(Emotion Recognition in Conversation,ERC)在人机交互系统中发挥着重要作用,因为它可以提供共情服务。近年来,图神经网络(Graph Neural Network,GNN)因其在关系建模方面的优越性能而被广泛应用于各个领域。在多模态 ERC 中,GNN 能够提取远距离上下文信息和模态间交互信息。不幸的是,诸如MMGCN之类的现有方法直接融合多种模态,可能会产生冗余信息并且丢失多样性信息。在这项工作中,研究人员提出了一种基于有向图的跨模态特征互补模块——GraphCFC,该模块可以有效地提取上下文和交互信息。 GraphCFC 通过利用多个子空间提取器和成对跨模态互补(PairCC)策略缓解了多模态融合中的异质性差距问题。本工作从构建的图中提取多种类型的边进行编码,使 GNN 在执行消息传递时能够更准确地提取重要的上下文和交互信息。此外,研究人员设计了一种称为 GAT-MLP 的 GNN 结构,它可以为多模态学习提供新的统一网络框架。整体架构如图1所示。
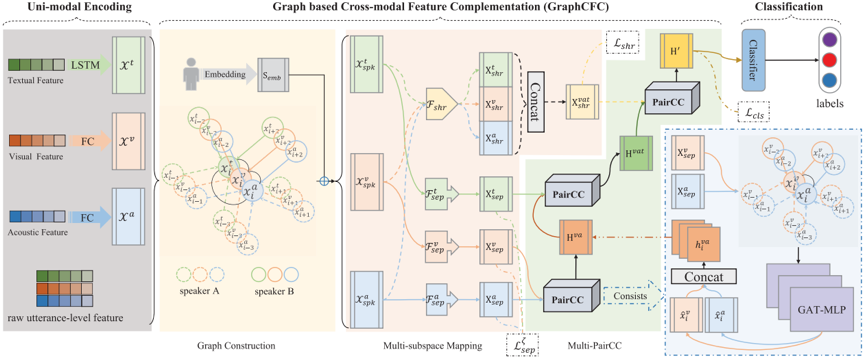
图1本文方法的整体架构
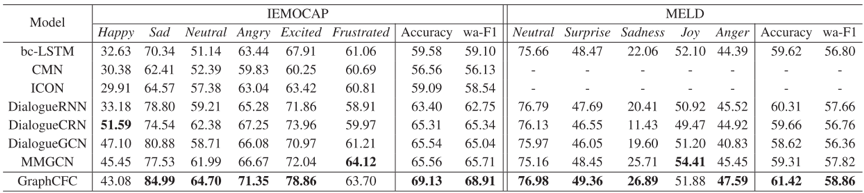
在两个基准数据集上进行了大量的对比实验和消融研究。如表1所示。实验结果表明,提出的 GraphCFC 能够有效地补充和融合多模态特征,与现有的 SOTA 方法相比,获得了最佳性能。
表1多模态设置下所有模型整体表现
为了探究GAT-MLP的有效性,研究人员在表2中报告了 GAT-MLP 层中 MultiGAT 和 FeedForward 的表现。当不采用 MultiGAT 层或 FeedForward 层时,模型性能会明显下降。另外,GAT-MLP中跳跃连接对模型的影响如图 2 所示。可以看到,如果去掉跳跃连接,随着网络层数的增加,模型性能会随着数量的增加而急剧下降;相反,如果保持跳跃连接,模型性能会缓慢下降。因此,跳跃连接可以在一定程度上缓解了过度平滑的问题。
表2 GAT-MLP 层中MultiGAT和FeedForward的表现
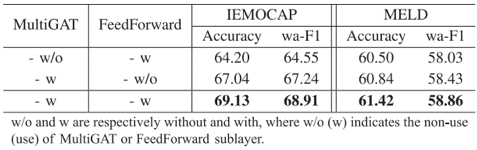
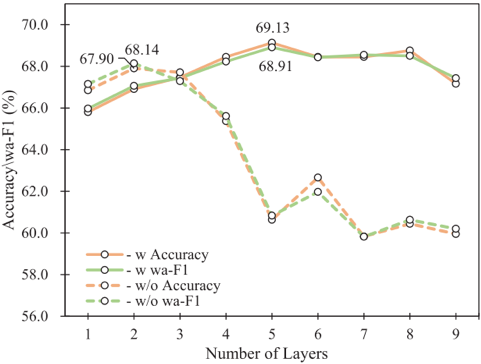
图2跳跃连接对模型的影响
05
Reinforcement Learning Approaches for Traffic Signal Control under Missing Data
作者:梅淏,李俊贤,师斌,魏华
单位:新泽西理工学院,西安交通大学
邮箱:
hmei7@asu.edu ,
ljx201806@stu.xjtu.edu.cn ,
shibin@xjtu.edu.cn ,
hwei27@asu.edu
论文:
https://www.ijcai.org/proceedings/2023/0251.pdf
代码:
https://github.com/derekmei233/MissLight
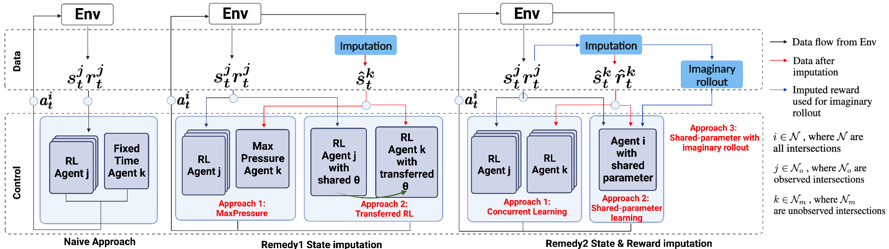
介绍:强化学习在交通灯控制领域已经取得了令人瞩目的成绩,然而在在训练阶段智能体需要状态和奖励,另外在部署阶段也需要实时获取状态。这使得依靠强化学习的方法不能很好应对地图中确缺失分数据的情况。而在现实环境下,路口信息缺失场景十分广泛。比如,由于路口传感器异常,导致实时的状态观测缺失;另外由于预算限制,只在部分重要路口布置传感器,在这种强况下将给自适应控制带来更大的挑战。为了解决上述问题,我们分别从如何利用推断补全缺失路口的信息;在可观测路口和缺失路口分别如何布置智能体,两方面进行了研究。并基于观察,针对状态缺失的路口提出了两种不同策略,1)通过推断补全状态进而实现自适应控制。2)同时推断和补全状态和奖励,在缺失路口训练智能体,进而实现自适应控制。

方法:我们通过引入交通领域中一种用于推测补全交通路口信息情况的store-and-froward模型,用于补全缺失路口的信息。同时因为引入补全的信息会造成误差和偏差,使用补全信息训练智能体难以收敛,因此我们在第一种策略中尝试在部署阶段仅使用推断补全状态,在可观测路口信息训练智能体并迁移到缺失路口。由于观测与缺失路口数据分布不同,在第一中策略中基于可观测路口数据训练的智能体将因为数据分布飘移(distribution shift)而无法给出最佳决策。为了解决这一问题,在第二种策略中,我们同时推测推断补全状态和奖励,并使用推断和补全后的数据混合可观测路口数据同时训练共享参数的智能体,从而减轻分布飘移的问题。同时,受到基于模型的强化学习的启发,我们尝试动态更新奖励函数,从而提高推断补全奖励的精度。
实验:我们通过在合成与真是数据集上分别对不同程度缺失进行了测试。结果表明相比于不使用补全数据,在缺失路口使用非自适应控制的方法比较,两种策略都有明显效果提升。其中通过不断更新奖励函数,并使用推断补全数据进行训练的策略性能最佳。
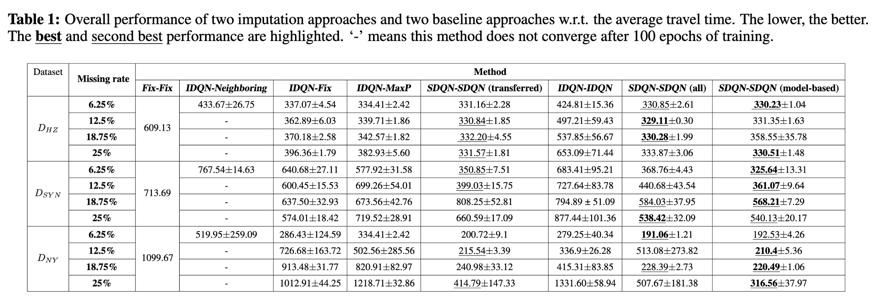
结论:我们提出的两种解决部分路口状态缺失,导致自适应性方法无法正常进行控制的方法。实验表明两种方法都可以有效解决上述问题,其中通过动态更新奖励函数,并推断补全缺失路口的状态和奖励达到训练智能体的方法,取得了最佳的控制效果。成功使基于强化学习的交通灯控制方法适应更广泛的真实环境,同时也潜在地减少了在交通路口部署传感器的预算和任务复杂程度。
06
Exploring large language model for graph data understanding in online job recommendations
探索大语言模型对岗位推荐场景中图结构数据的理解能力
作者:吴李康、邱昭鹏、郑值、祝恒书、陈恩红
单位: 中国科学技术大学
邮箱:
wulk@mail.ustc.edu.cn
论文:https://arxiv.org/pdf/2307.05722
代码:https://github.com/WLiK/GLRec
大模型已经在自然语言处理任务中引发了全面变革,展示了它在不同领域的优秀能力。然而,目前大语言模型理解图数据的潜力仍有待全面探索。本研究重点揭示大型语言模型在理解行为图方面的能力,并利用该能力增强在线招聘中的推荐任务,包括提升其对于分布外(OOD)目标的判断能力。
为了让大模型理解行为图这种异质图数据,本研究引入了异质图语义挖掘中常用的元路径(Meta Path)概念。如图所示,c1-->interview-->j1--message-->c2是一条从用户C1出发的元路径,包含不同的类型节点和连边类型,该路径天然携带丰富的语义知识,可以自然地转化为自然语言描述性质的Prompt:“C1 interviewed for position J1. This position discussed with a job seeker C2.” 实际输入时只需将用户和岗位的关键信息填入即可。

模型框架
在构造路径Prompt之后,本研究在训练模型时发现了将多种路径Prompt组合成序列输入时产生的位置偏差问题。传统的判别式推荐系统不需要对路径构建输入序列,因此也不会出现人为引入的先后顺序偏差;然而大语言模型会面临这个问题。例如,路径输入序列的先后位置不同时,推荐系统给出的结果也不同。为此本研究提出了一种路径顺序的乱序机制,即训练时针对同一个样本对其打乱若干次,以缓解位置偏差问题同时增加模型的鲁棒性。此外,本研究还发现不同元路径提示对于模型的决策的影响也是不同的。因此提出了一种基于Token embedding层次的路径Prompt权重学习层,其通过训练路径软选择器的参数矩阵得到不同路径的影响权重,在此基础上与不同路径中的Token embedding相乘并输入模型的Transformer block层。
实验验证
业务数据上的实验证明了提出框架的有效性。本研究不仅揭示了大型语言模型未被充分探索的图数据理解潜力,还为在线招聘中智能推荐系统提的进一步发展提供了有价值的参考。


 京公网安备11010802017125号
京公网安备11010802017125号