
【论文导读】2024年论文导读第十八期
【论文导读】2024年论文导读第十八期
CCF多媒体专委会 2024年09月10日 09:51 北京


论文导读
2024年论文导读第十八期(总第一百零九期)
目 录
|
1 |
Disguised Heterogeneous Face Generation With Iterative-Adversarial Style Unification |
|
2 |
MobiRFPose: Portable RF-Based 3D Human Pose Camera |
|
3 |
Rethinking graph contrastive learning: an efficient single-view approach via instance discrimination |
|
4 |
Feature First: Advancing Image-Text Retrieval Through Improved Visual Features |
|
5 |
Centralized Error Distribution-Preserving Adaptive Steganography for HEVC |
01
Disguised Heterogeneous Face Generation With Iterative-Adversarial Style Unification
作者:
彭春蕾1,孔子墨1,刘德成1,王楠楠*1,高新波2
单位:
1西安电子科技大学,
2重庆邮电大学
邮箱:
clpeng@xidian.edu.cn
论文:
https://ieeexplore.ieee.org/document/10250995
发表期刊:TMM2023
*通讯作者
论文简介
异质人脸识别 (Heterogeneous Face Recognition, HFR) 是指将不同模态的人脸图像进行匹配,该领域的研究对于公共安全至关重要。尽管 HFR 近年来取得了令人鼓舞的进展,但 HFR 场景中的带遮挡人脸仍然是一个重大挑战,原因如下。首先,大多数现有的 HFR 方法都侧重于没有人脸面部遮挡的传统场景,直接应用于带遮挡情况时识别性能会下降。其次,目前尚缺少带遮挡的异质人脸数据集,限制了这方面的相关研究。第三,彩色面部遮挡物在模态方面与异质人脸图像存在风格差异,直接在异质人脸上添加面部遮挡会导致风格不一致和质量较差。因此,我们提出了一种基于迭代对抗风格统一框架的带遮挡异质人脸生成方法,如图1所示。我们的方法旨在通过多次对抗迭代逐渐学习异质人脸风格特点,从而实现面部遮挡物和异质人脸的风格统一。与此同时,我们还构建了一个带遮挡的异质人脸数据集,其中包含带遮挡的 NIR-VIS 子集和带遮挡的素描-照片子集。此外,我们还提供了在我们构建数据集上进行的基准评估,包括人脸识别和图像质量评估,证明了我们的方法优于直接添加面部遮挡物的方案和两种现有的带遮挡人脸生成技术。
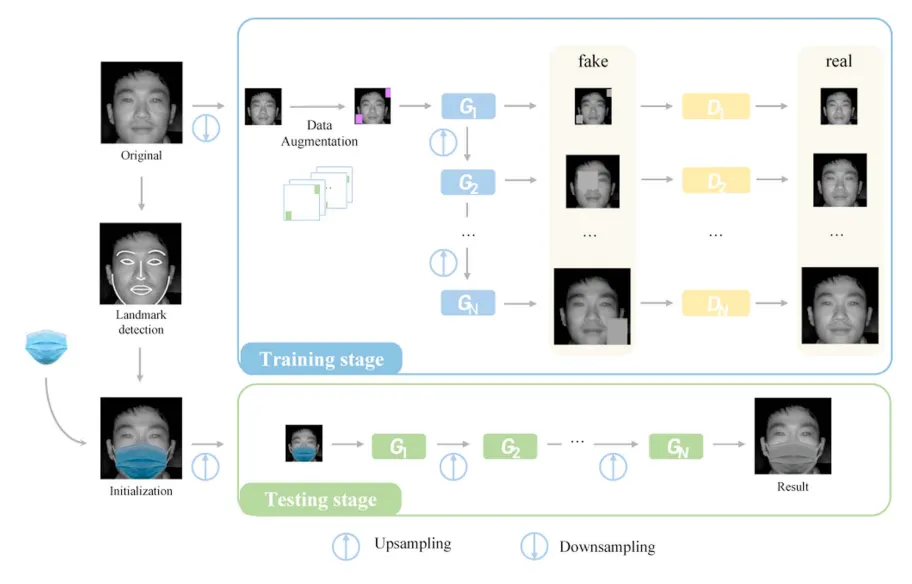
图1 带遮挡异质人脸生成框架
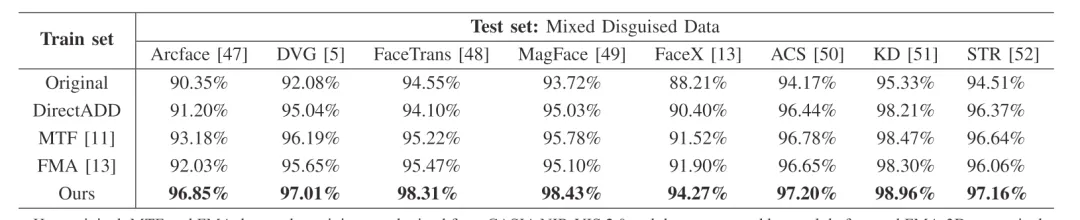
为了验证我们所提出方法对于带遮挡异质人脸识别研究的有效性,我们构建了一个混合遮挡测试数据集进行评估,如表1所示。我们采用了 CASIA NIR-VIS 2.0原始无遮挡数据、直接添加彩色面部遮挡方法(DirectADD)、两种现有的带遮挡人脸生成技术(MaskTheFace、FMA-3D )和我们的方法生成的带遮挡人脸数据作为训练集来训练多个人脸识别模型,然后随机选取上述方法生成的图像,构建了一个混合遮挡类型数据的测试集。当实验中的八个人脸识别模型在各类带遮挡人脸数据上进行训练时,基于我们的方法所得到的训练模型在所有这些识别方法中均表现最佳,这表明我们提出的方法可以生成有效的带遮挡异质人脸来协助训练异质人脸识别模型,从而有助于填补带遮挡 HFR 人脸数据的空白,并提高复杂不可控场景下异质人脸识别系统的性能。
表1 带遮挡异质人脸识别结果
02
MobiRFPose: Portable RF-Based 3D Human Pose Camera
基于无线信号的便携式三维人体姿态估计相机
作者:
俞聪,张东恒,武治,解春阳,卢智,胡洋,陈彦
单位:
中国工程物理研究院电子工程研究所,
中国科学技术大学网络空间安全学院,
电子科技大学信息与通信工程学院,
中国科学技术大学信息科学技术学院
邮箱:
congyu@std.uestc.edu.cn,
dongheng@ustc.edu.cn,
wzwyyx@mail.ustc.edu.cn,
chunyangxie@std.uestc.edu.cn,
zhilu@ustc.edu.cn,
eeyhu@ustc.edu.cn,
eecyan@ustc.edu.cn
论文:
https://ieeexplore.ieee.org/document/10250968
发表期刊:TMM2023
1. 引言
现有基于无线信号的人体姿态估计技术通常模型臃肿且计算复杂,无法满足移动设备的实时处理和便携性要求。针对这一问题,本文介绍了一种轻量级无线人体姿态估计模型MobiRFPose,从而构建便携式无线人体姿态估计相机。与传统光学相机相比,基于无线信号的相机由于不会捕获视觉信息,具有良好的隐私保护特性。
2.方法概述
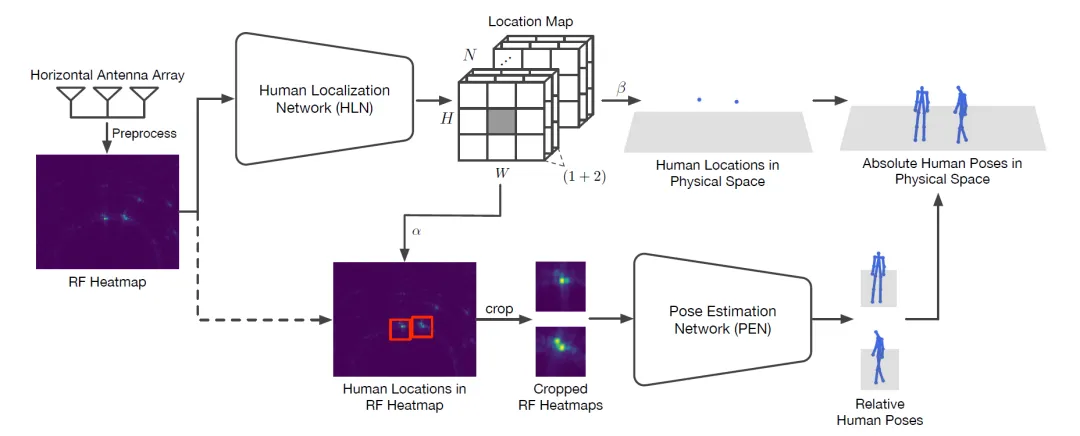
图1 MobiRFPose模型结构示意图
文采用仅配备水平方向天线阵列的毫米波雷达收发无线信号,并设计了一个从整体到局部的模型结构以实现快速的三维人体姿态估计,即首先估计信号热力图上人体位置并裁剪人体位置区域,进而根据裁剪后较小信号热力图快速估计人体姿态。
人体定位模块(HLN)设计
人体定位模块将毫米波热力图映射成定位特征图,其形状为,其中和表示毫米波热力图被划分成的检测网格,表示一个网格单元中最多出现个人体目标。对每个可能的人体目标,都存在一个置信度分数来表示该人体目标出现在网格单元中的概率,并且存在一对坐标值来表示该人体目标在该单元格中的位置。
人体姿态估计模块(PEN)设计
在获取人体目标在毫米波热力图上的位置后,以该点为中心,对毫米波热力图进行裁剪,得到裁剪后的毫米波热力图。与完整的毫米波热力图相比,裁剪后的毫米波热力图具有更小的尺寸,这意味着网络模型的参数量和计算量更少。人体姿态估计模块通过姿态特征选择组件从裁剪后的毫米波热力图中估计相对的人体姿态骨架。
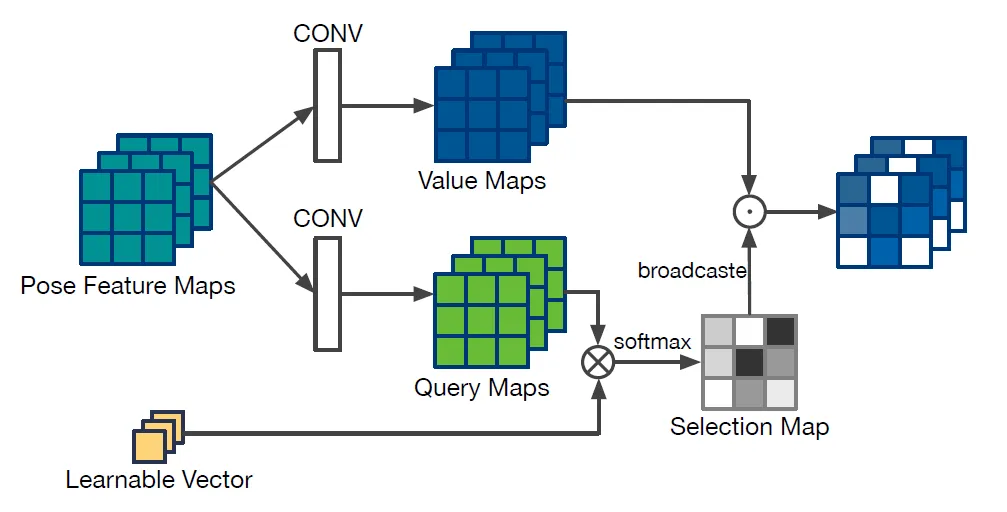
图2 姿态特征选择组件结构示意图
姿态特征选择组件将使PEN模块更加关注有助于人体姿态估计的特征而忽略噪声带来的干扰,以极小的参数量和计算复杂度的提升,确保了模型人体姿态估计的精度。
3.实验结果
为评估系统性能,在实验部分,本文将MobiRFPose模型与现有的无线人体姿态估计技术进行了比较,实验结果表明,本文提出的MobiRFPose模型能够以更少的模型参数量和模型计算量实现准确的三维人体姿态估计,其中单人情况的估计误差为11.05 cm,多人情况的估计误差为11.29 cm。为了进一步验证模型能够实时运行在移动端以满足系统的便携性要求,本文还使用移动设备的CPU对训练好的MobiRFPose模型进行了测试,其中模型结构和模型参数分别仅占用268 KB和3226 KB的磁盘空间,且模型能够达到66 FPS的处理速度。此外,尽管MobiRFPose模型是由室内场景的无线数据训练而来,但其直接应用于室外场景仍具有良好的跨环境泛化性能。在讨论部分,本文还对MobiRFPose模型的结构设计进行了更细致的讨论。特别地,本文提供了另一个版本的MobiRFPose,该版本同时使用水平方向和垂直方向的毫米波信号来估计三维人体姿态,本文对这两个版本的MobiRFPose模型进行了详细的比较。
表1 与其他方法的对比实验定量结果

表2 移动端部署实验结果


图3 与其他方法的对比实验定性结果
03
Rethinking graph contrastive learning: an efficient single-view approach via instance discrimination
作者:
高媛1,李鑫2,严慧1*
单位:
南京理工大学计算机科学与工程学院,
南京邮电大学计算机学院
邮箱:
maxgaoyuan@gmail.com,
yanhui@njust.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10286310
代码:
https://github.com/maxgaocode/LSGCL
发表期刊:TMM2023
* 通讯作者
1.简介
随着对比学习和图神经网络的成功融合,图对比学习(GCL)在图表示学习方面表现出了卓越的性能。早期的研究倾向于使用双视图框架。然而,它们需要高昂的计算成本;此外,发现双视图对比学习的训练过程在两个重要指标(对齐性和均匀性)之间摇摆不定,导致它们很难获得稳健的结果。为了解决这些问题,本文设计了一种新颖的单视图范式,称为轻量化单视图对比学习(LSGCL)。
2.预实验与方法概述
本文的灵感来源于一个尝试性实验,当使用了把经过不同比率去边操作的图同时分别喂入对比学习两支视图后,得到的分类精度与将经过不同增强的图喂入双视图相当甚至更好。预实验具体设置可参考原文。
为了减少时间消耗,本文采用了单视图框架。具体来说,将不经过任何增强操作的输入图直接喂入编码器得到一系列隐藏表示,使用归一化后进行串联操作。接下来,本文采用了一种新颖的单视角实例判别方法,本文重新定义了锚点、正样本和负样本。锚点本身即为正样本,其它节点为负样本。尽管简单,与先进的基线方法相比,本文的LSGCL可以提供更好的分类性能,且需花更少的时间成本。本文还讨论了LSGCL 能成功的原因,它权衡对齐性(alignment)和均匀性(uniformity),模型输出的表示是完美对齐的,另外可视化效果表明该表示能在均匀性指标下取得最前沿的效果。换言之,单支视图使得模型在对齐性指标上为0,而所设计的编码器和损失函数都在进一步优化均匀性。
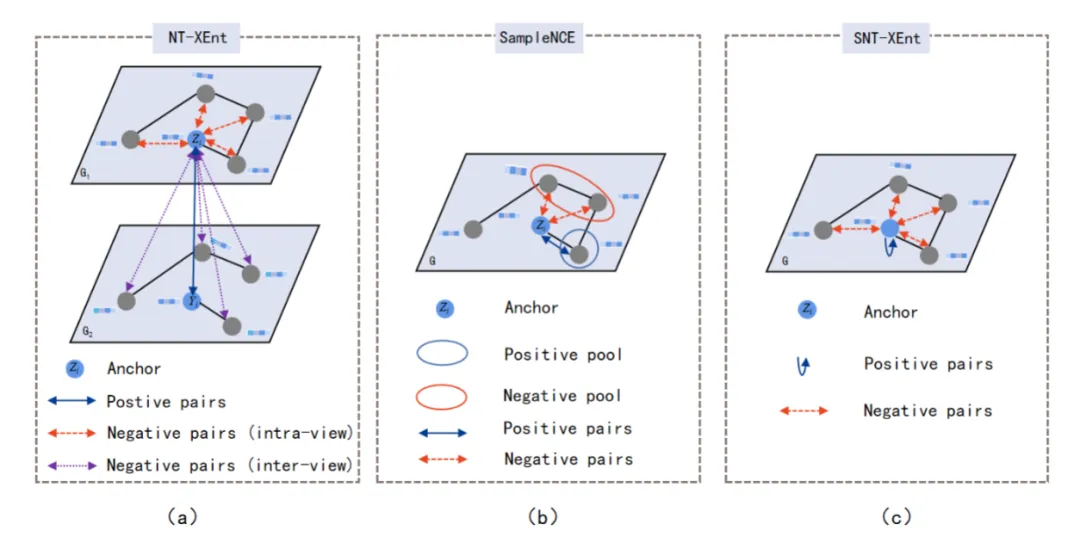
图1 之前对比学习损失函数(a)(b)与LSGCL的损失函数(c)
3.实验结果
将流行的图对比模进行了拆解,简化模型的训练模块,在此基础上得到了一个轻量级而有效的模型 LSGCL。由于篇幅有限,在这里值展示了部分主要研究成果。
表1 LSGCL与经典双视图和单视图对比学习的平均精度对比,另外也比较了一些半监督方法(如2.5%的训练集+5%的验证集)
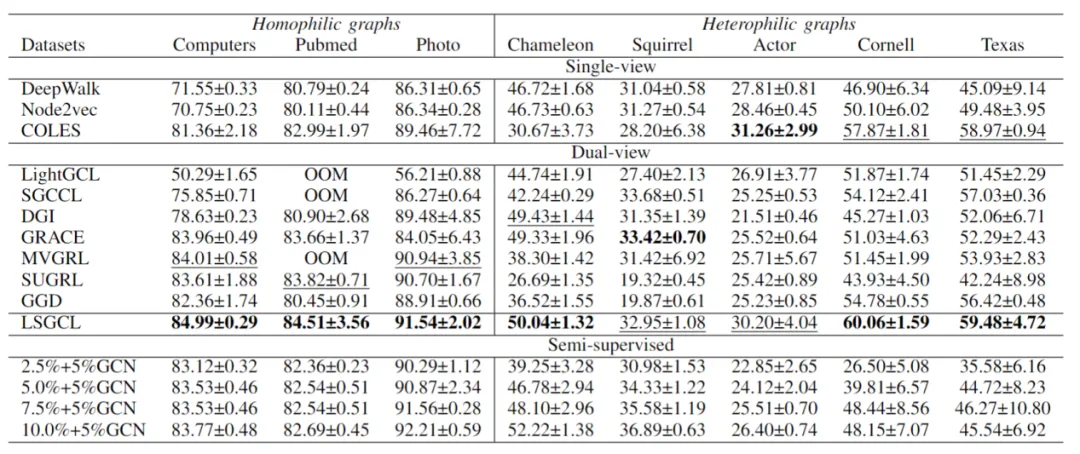
图2的每个数据集对应的左半部分展示基准方法与本文的模型,为了更清晰地展示不同方法的训练效果,右半部分又分别在上下两个子图中展示了双视图和单视图的结果。可以观察到本文的模型LSGCL 达到完美对齐(y 轴对应指标等于 0)的同时在均匀性(x 轴)指标上也达到最先进的结果。
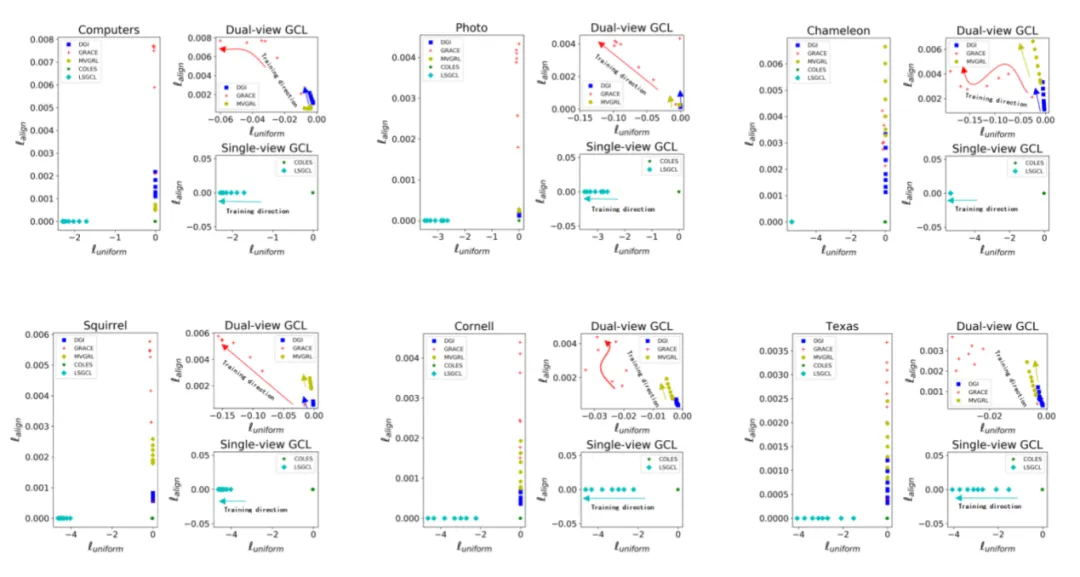
图2 LSGCL与经典双视图和单视图对比学习的对齐性(lalign)和均匀性(luniformity)指标对比,两个指标的值越小越好,其中lalign是大于等于0的
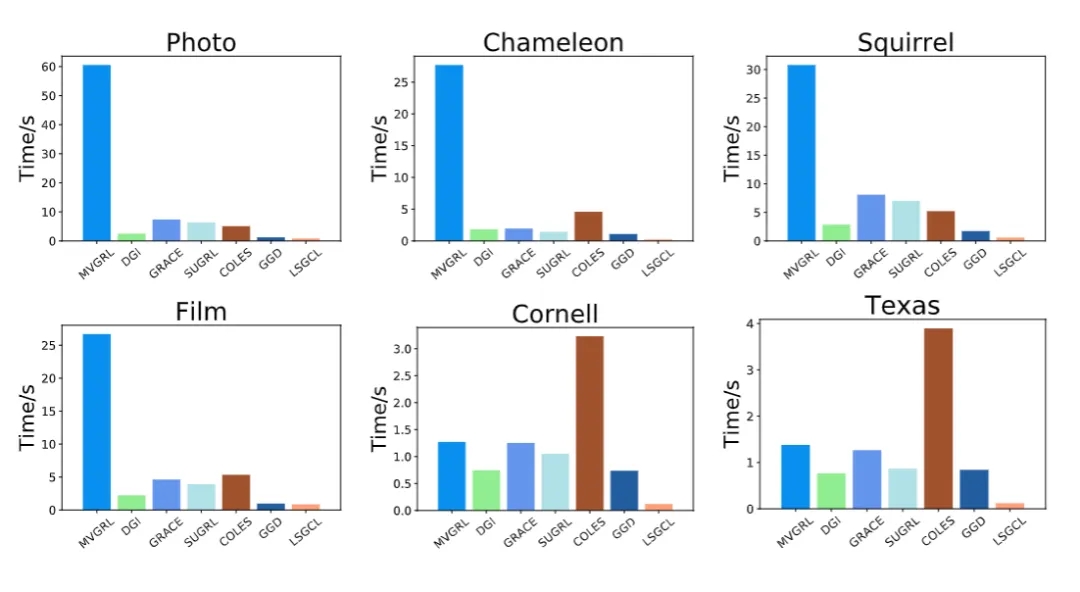
图3 各个模型的时间消耗对比
04
Feature First: Advancing Image-Text Retrieval Through Improved Visual Features
作者:
吴东庆,李晖晖*,谷仓,刘航,徐翠丽,侯寅轩,郭雷
单位:
西北工业大学
邮箱:
wudongqing@mail.nwpu.edu.cn,
lihhui@nwpu.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10252008
代码:
https://github.com/NPULHH/ITR
发表期刊:TMM2023
*通讯作者
1.引言
跨模态图文检索方法一般包含三个工作流程:特征提取、模态交互和相似性计算。对于现有的方法来说,模态交互和相似性计算是它们的研究重要,很少有研究考虑从输入图像中提取的视觉特征。我们认为,在跨模态图像文本检索任务中,理想的视觉特征应该展现出三种特性,即目标层次、语义丰富和语言对齐。然而,主流的区域特征只能满足第一个属性,由于缺乏上下文信息、目标细节的丢失以及模态间信息密度的差异等问题,并不能很好地满足后两个属性。图1详细地说明了区域特征存在的上述三个问题。
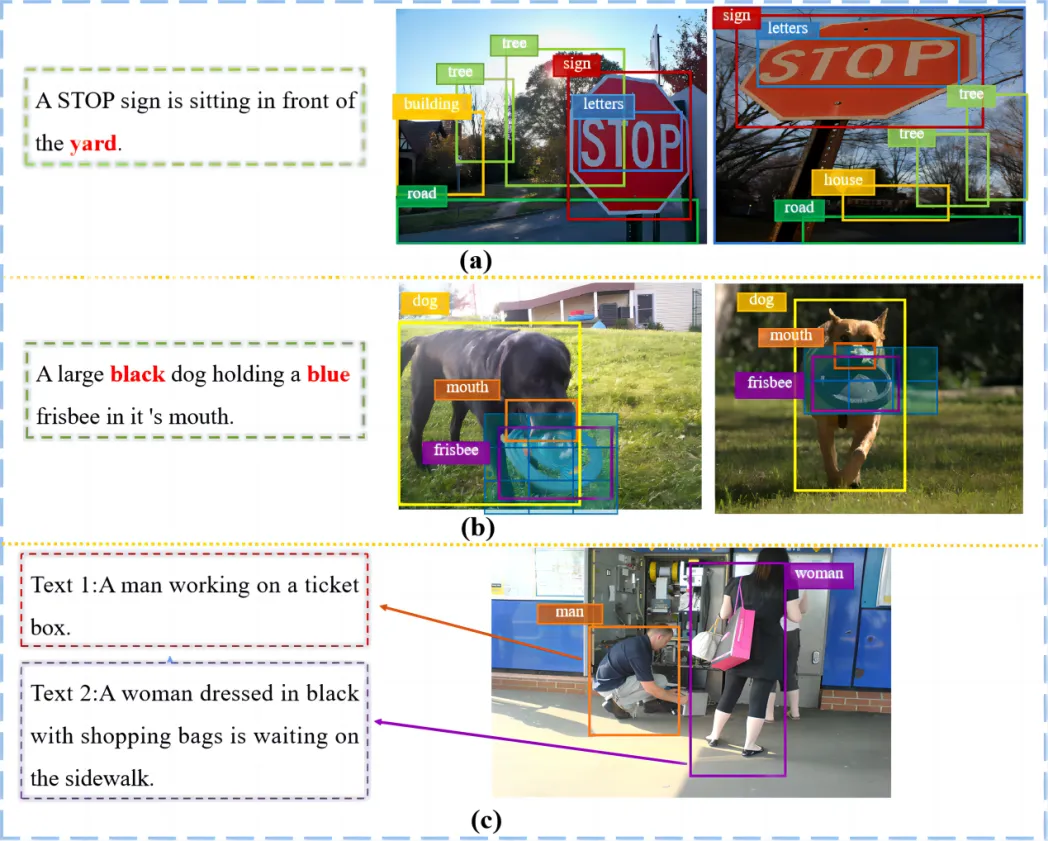
图1 区域特征存在的三种问题的说明:(a)缺乏上下文信息;(b)目标细节的丢失;(c)模态之间信息密度的差异,即句子通常只描述感兴趣的部分图像区域。在(a)和(b)中,从左到右分别表示查询句子,真值图像和不匹配的图像。在(c)中,“Text 1”和“Text 2”从不同的角度对右边的图像进行描述。
近年来,一些多模态工作重新开始使用网格特征来表示图像。由于网格特征覆盖了整个图像,并且提供了上下文信息和目标细节的有效表示,因此并不会受到后两个问题的影响。但是,网格特征缺乏目标层次的信息,通常需要大量的网络来描述一个目标。因此,我们在文章中提出了一个新的视觉表示框架,该框架致力于产生更全面和更强有力的视觉特征,以同时满足理想的视觉特征所必须具备的三个属性,从而促进跨模态图像文本检索的性能。
2.方法介绍
本文提出的模型整体框架图所图2所示,主要包含两步交互模块、文本集成的视觉嵌入模块和多注意力池化模块。
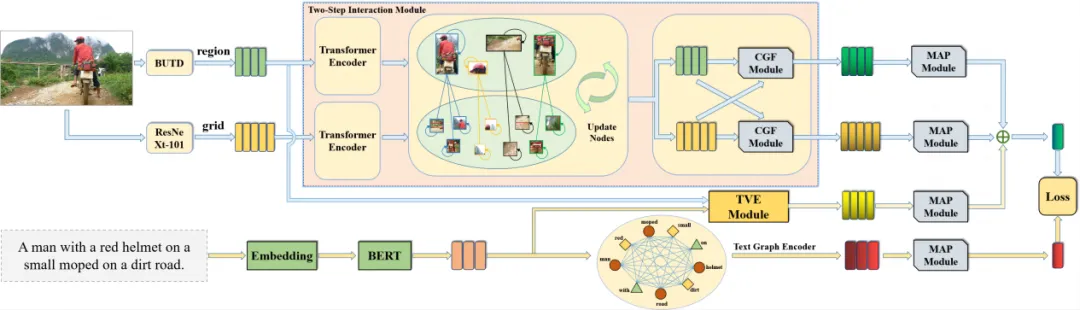
图2 本文方法的框架图
1)两步交互模块
该模块从空间和语义两个角度来从空间和语义两个角度来挖掘区域特征和网格特征之间复杂的交互关系,从而充分集成它们的互补信息,使得融合后的特征即具有目标层次又包含丰富的语义信息。
2)文本集成的视觉嵌入模块
该模块使用文本信息作为指导,对区域特征进行调整和修改,过滤掉部分与句子无关的区域信息,从而有效地弥合不同模态之间的信息密度差异。由于该模块可以看做一个轻量的交叉注意力机制,因此生成的文本指导的区域特征是语言对齐的。
3)多注意力池化模块
该模块的目的是将具有区分性的局部特征聚合成整体嵌入。与常见的池化操作不同,该模块考虑了维度之间的差异,并通过将特征聚合的权重从标量改为维度特定的向量来实现更细粒度的聚合。
3.实验分析
本文在Flickr30K和MS-COCO两个公开的基准数据集上进行了大量的实验测试和评估。定量实验结果如表1所示。
从表中可以观察到,本文提出的方法以图搜文和以文搜图两个检索任务上的所有评价指标都到了最好的性能,明显优于上述比较的所有方法,特别是R@1指标。定量实验结果充分证明了本文提出的方法的优越性和有效性。
表1 Flickr30K和MS-COCO数据集上的定量结果
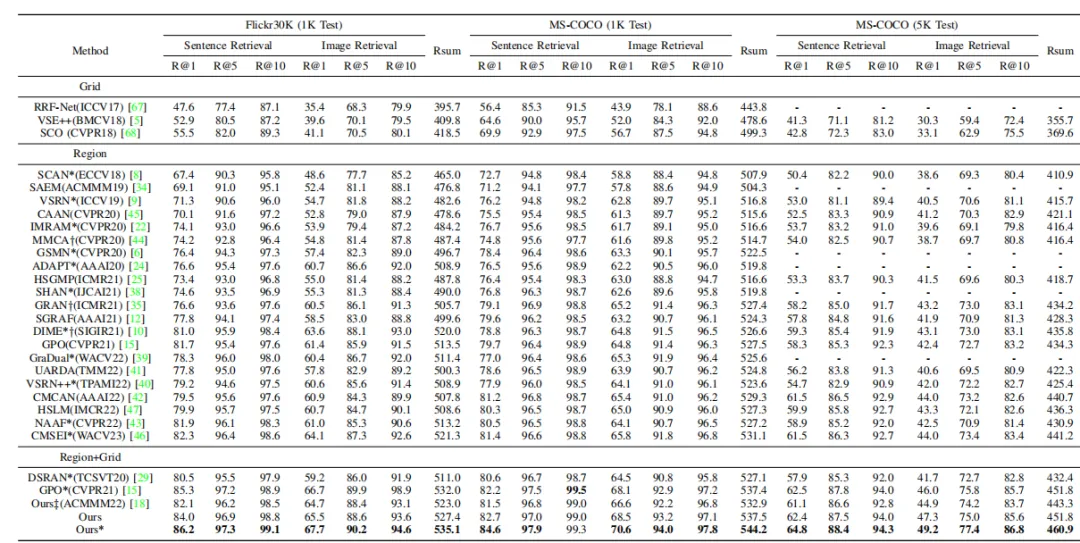
从表中可以观察到,本文提出的方法以图搜文和以文搜图两个检索任务上的所有评价指标都到了最好的性能,明显优于上述比较的所有方法,特别是R@1指标。定量实验结果充分证明了本文提出的方法的优越性和有效性。

图3 句子检索和图像检索的可视化结果
图3展示了本文方法的可视化结果。我们发现检索得到的句子详细地描述了图像中的视觉场景,证明了模型生成的图像表示能够很好地捕获目标的细节和丰富的上下文信息。即使是错误的检索结果,它的描述也很接近原始图像。而对于图像检索,模型可以准确地区分出具有相似语义概念的模糊样本,并检索出真实图像。
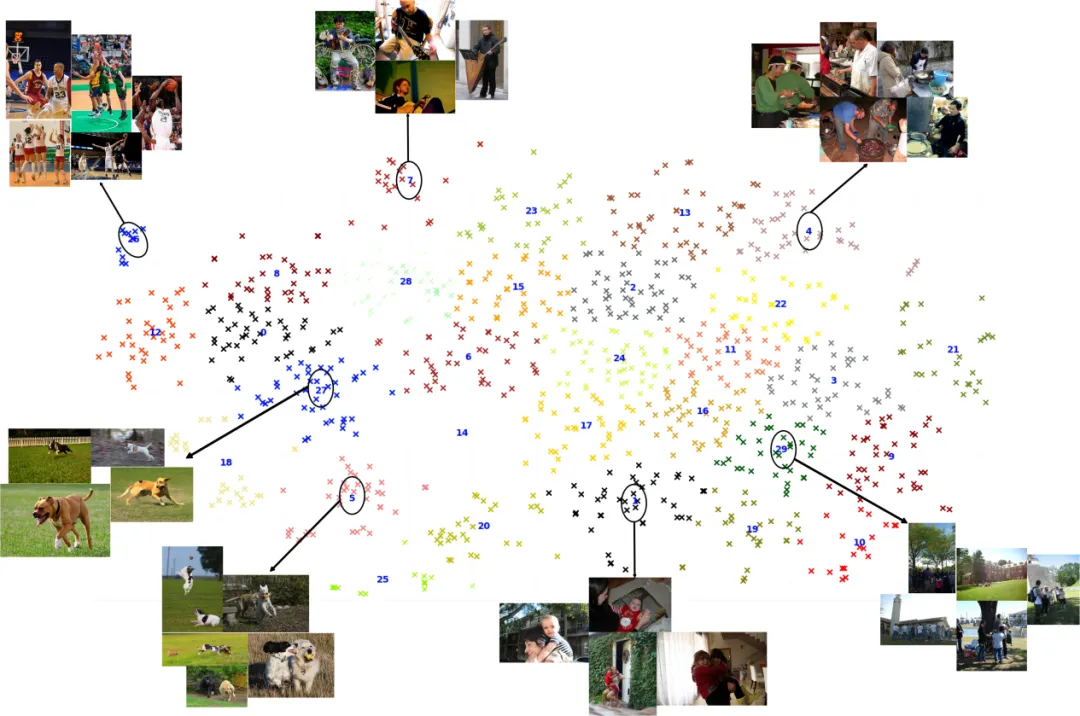
图4 视觉特征的可视化结果
图4展示了模型学习到的视觉特征的可视化结果,我们可以发现来自相同类的图像具有很强的语义一致性,而来自不同类别的图像能够被很好地区分。
05
Centralized Error Distribution-Preserving Adaptive Steganography for HEVC
作者:
杨璘1,王让定1,徐达文2,董理1,何松翰1
单位:
1宁波大学, 2宁波工程学院
邮箱:
2011082340@nbu.edu.cn,
wangrangding@nbu.edu.cn,
dawenxu@126.com,
dongli@nbu.edu.cn,
2111082349@nbu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10269068
发表期刊:TMM2023
1.研究背景和动机
HEVC视频隐写是一项旨在以不可查觉的方式向HEVC视频内容中嵌入隐秘信息的科学研究,主要应用于军事、金融、政法举证等秘密数据的隐蔽传输和保密通信等领域。在HEVC视频系数域隐写中,通常使用失真补偿算法来解决因失真漂移现象导致画面失真问题,如图1所示。然而,这一方法无可避免地会留下名为“聚集失真”的隐写痕迹,因此,使用由聚集失真为特征的隐写分析方法能高效地对这类隐写视频集进行辨别。因此,本文将从提高这类系数域隐写视频的安全性角度出发,从数理层面对聚集失真特征进行建模,使用大量实验验证聚集失真特征在各个子特征之间的关联性,并提出维持单一子特征来实现高安全性的HEVC视频系数域自适应隐写方案。

图1 视频失真漂移导致的画面失真
本文的主要贡献两个:1)现有的聚集失真特征仅应用在上一代视频压缩标准H.264/AVC中,由于HEVC在新一轮视频压缩技术的迭代中新增了许多全新的技术方法,因此需要根据AVC和HEVC的共性和特性来构建适用于HEVC标准的聚集失真特征。2)由于聚集失真特征的子特征之间存在一定重合特征点,本文通过分析各个子特征之间的关联性,发现它们之间存在较强的相关性。因此,本文提出了一种以维持单一子特征为目标的全新失真代价函数,实现了一种高安全性的HEVC视频隐写。
2.论文方法
2.1 基于HEVC编码标准的聚集失真特征构建
本文通过相关数学公式推导发现,在AVC系数域隐写中,因失真补偿算法导致的聚集失真通常集中在视频分块的第二、三行和第二、三列中,而HEVC系数域隐写中,该现象则集中在第三行和第三列中,如图2所示。因此,通过借鉴AVC中的聚集失真特征,本文对该特征迁移至HEVC中的特征点构成进行了重新选择,两者特征点选择对比图如图3所示,得到了适用于HEVC标准的聚集失真特征。

图2 AVC和HEVC的聚集失真现象对比
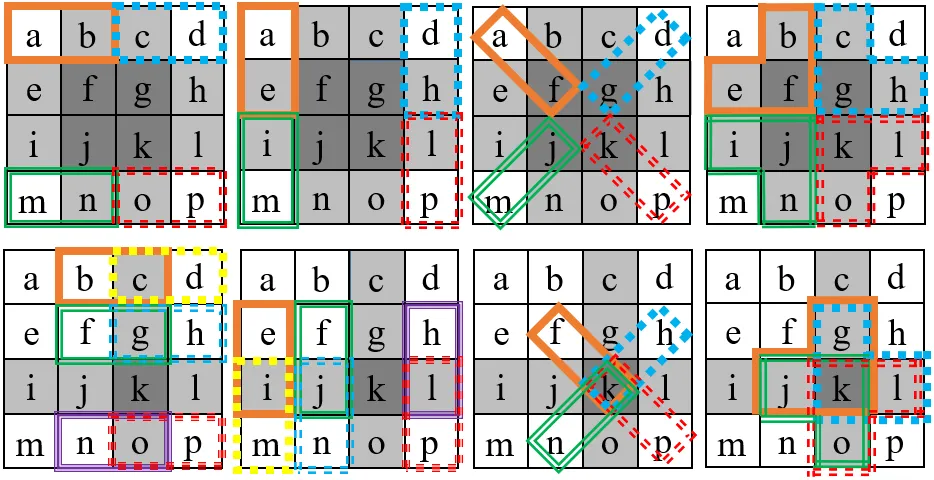
图3 AVC和HEVC的聚集失真特征点选择对比图
2.2 聚集失真子特征的关联性分析
本文使用皮尔逊积矩相关系数(Pearson product-moment correlation coefficient, PPMCC)和主成分分析法(Principal Component Analysis, PCA)分别从分量在全局平均统计分布上的相关性和分量在单帧独立统计分布上的相关性进行了分析,其结果如图4所示。由此得出结论:聚集失真特征的子特征在全局和单帧两个角度都存在较强的相关性,因此,可以通过维持单一子特征的分布来实现抵抗聚集失真特征的效果。
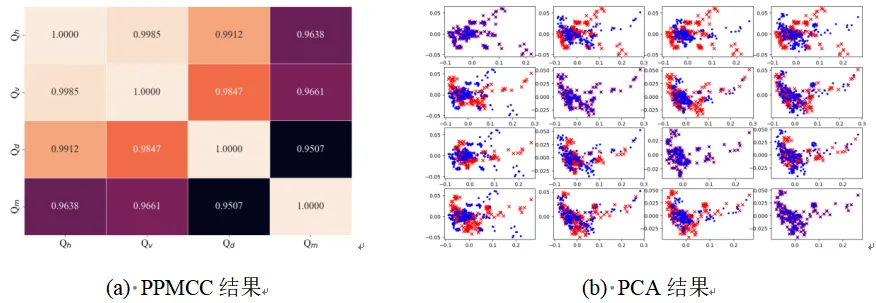
图4 聚集失真子特征在全局平均统计分布和单帧独立统计分布上的结果
2.3 提出的失真代价函数
根据上述结论,本文对于不同的载体候选块使用不同的子特征作为目标维持特征,以CBh载体块为例,由于这类载体块所受的隐写失真痕迹主要存在于第三行中,因此,以c、g、o为特征点的子特征并不会对隐写分析结果产生影响,相反,以i、j、l为特征点的子特征Rv分布会发生偏移。因此,对于CBh载体块,本文选择Rv子特征作为目标维持特征。对于CBv载体块则同理。最终,并以其选择的特征点的改变量为基础,设计了如下失真代价函数。
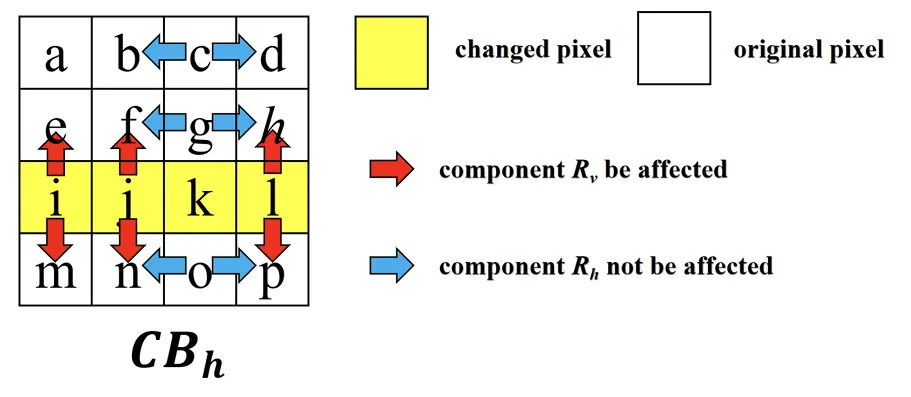
图5 CBh载体块失真痕迹影响示意图
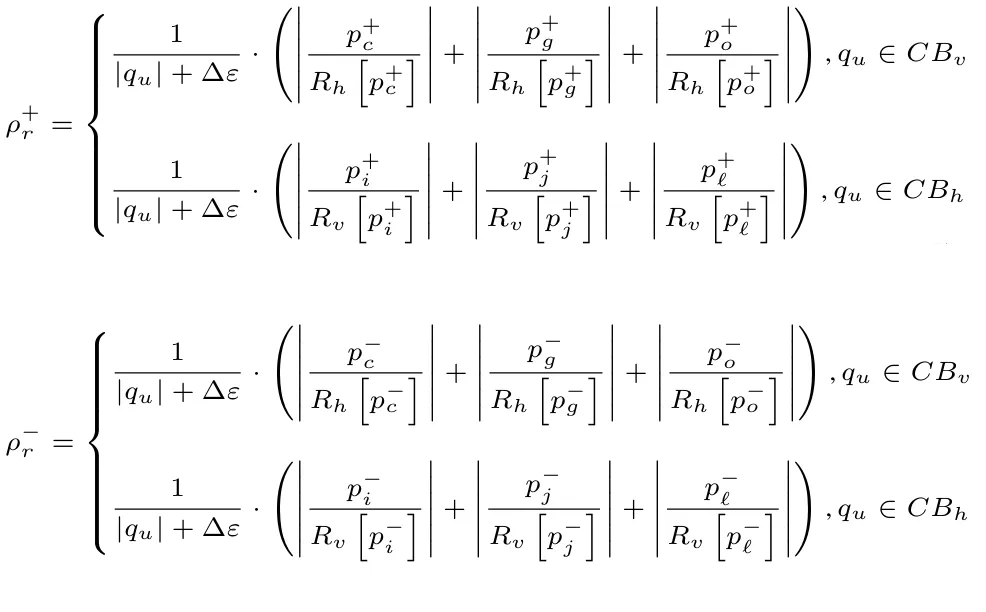
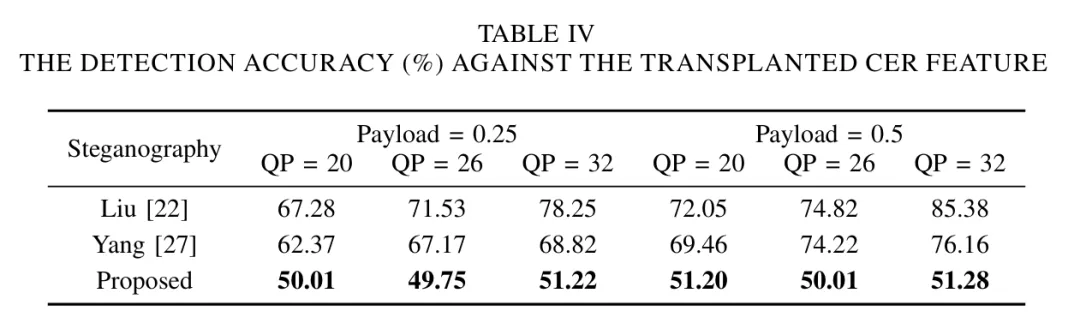
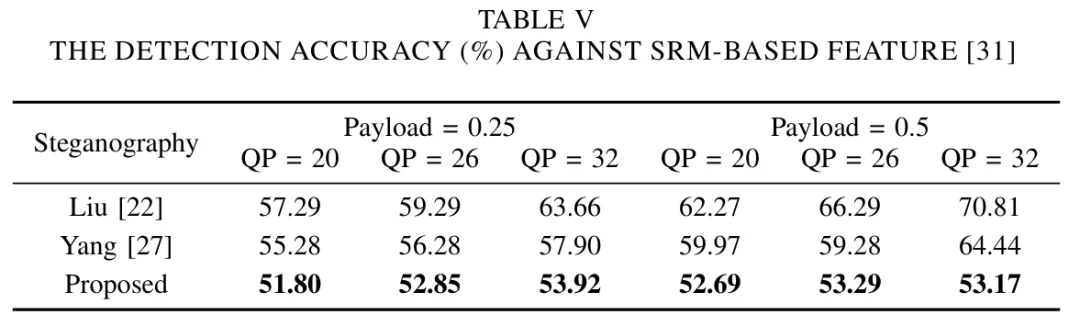
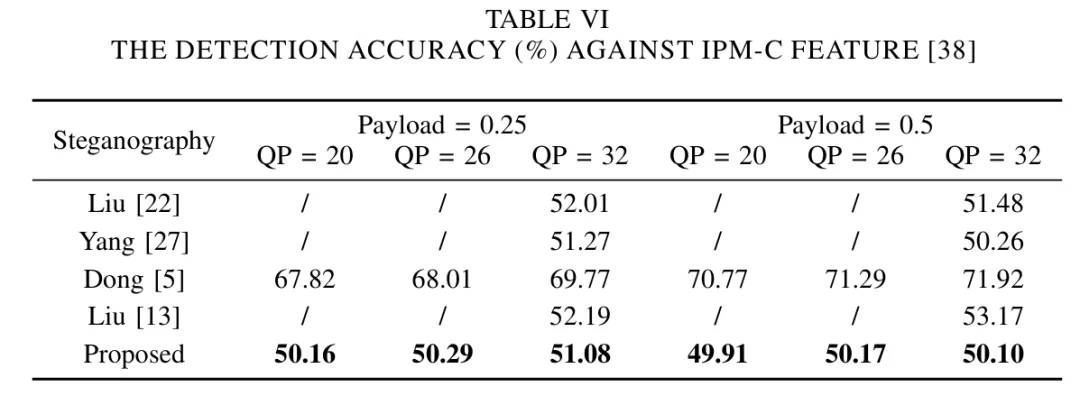
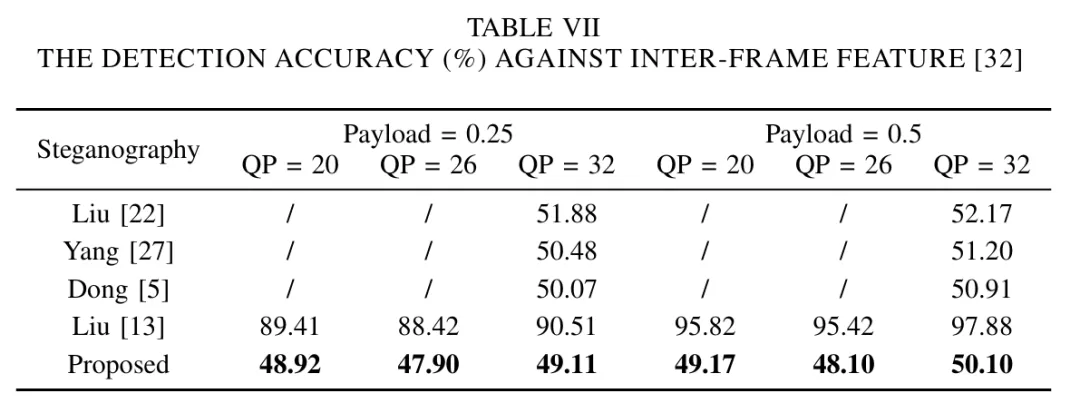
3.实验分析
为体现本文方法在安全性上的性能提升,本文使用了四种隐写分析方法对提出的方案进行了综合评估,其结果如下表所示。其结果表明,无论是对于抵抗聚集失真特征(Table Ⅳ)、以空域像素点分布变化为基础的SRM特征(Table Ⅴ)、以IPM编码空间的分布变化为基础的IPMC特征(Table Ⅵ)还是抵抗帧间特征(Table Ⅶ),本文所提出的方案都有着更优的性能。

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东

微信扫一扫
关注该公众号
 京公网安备11010802017125号
京公网安备11010802017125号