
【论文导读】2024年论文导读第十九期
【论文导读】2024年论文导读第十九期
CCF多媒体专委会 2024年09月24日 09:00 北京


论文导读
2024年论文导读第十九期(总第一百一十期)
目 录
|
1 |
CLIP-VG: Self-paced Curriculum Adapting of CLIP for Visual Grounding |
|
2 |
DACOD360: Deadline-Aware Content Delivery for 360-degree Video Streaming over MEC Networks |
|
3 |
Dual-Perspective Fusion Network for Aspect-Based Multimodal Sentiment Analysis |
|
4 |
UEDG:Uncertainty-Edge Dual Guided Camouflage Object Detection |
|
5 |
Hiding Multiple Images into a Single Image Using Up-Sampling |
01
CLIP-VG: Self-paced Curriculum Adapting of CLIP for Visual Grounding
作者:
肖麟慧1,2,3,杨小汕1,2,3,彭芳1,2,3,严明4,王耀威2,徐常胜1,2,3,*
单位:
1中国科学院自动化研究所多模态人工智能系统全国重点实验室,
2鹏城实验室,
3中国科学院大学人工智能学院,
4阿里巴巴集团达摩院
邮箱:
xiaolinhui16@mails.ucas.ac.cn,
xiaoshan.yang@nlpr.ia.ac.cn,
pengfang21@mails.ucas.ac,
ym119608@alibaba-inc.com,
wangyw@pcl.ac.cn,
csxu@nlpr.ia.ac.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10269126
代码和数据集:
https://github.com/linhuixiao/CLIP-VG
发表期刊:TMM2023
*通讯作者
1.论文简介
视觉定位(VG)是视觉语言领域的一个重要课题,它涉及到在图像中定位由表达句子所描述的特定区域。为了减少对人工标记数据的依赖,无监督的方法使用伪标签学习区域定位的能力。然而,现有的无监督方法的性能高度依赖于伪标签的质量,并且这些方法总是遇到多样性有限的问题。为了利用视觉语言预训练模型来解决定位问题,并合理利用伪标签,本文提出了一种新颖的方法,命名为CLIP-VG,它可以实现基于伪语言标签对CLIP进行自步式课程自适应。首先,本文提出了一个简单而高效的端到端网络架构来实现CLIP到视觉定位任务的迁移。其次,如图1所示,在以CLIP为基础的架构上,本文进一步提出了单源和多源课程自适应算法,这些算法可以逐步找到更可靠的伪语言标签来学习最优模型,从而实现伪语言标签在可靠度和多样性之间取得平衡。本文的方法在单源和多源无监督场景下的RefCOCO/+/g数据集上都明显优于当前最先进的无监督方法,提升幅度分别为从6.78%至10.67%和11.39%至14.87%。同时,本文的方法甚至优于现有的弱监督方法。此外,本文的模型在全监督设置下也具有一定的竞争力,可以达到SoTA的速度和能效优势。在与全监督SoTA模型QRNet相比,本文仅使用其更新参数的7.7%,同时在训练和推理方面获得了高达26.84倍和7.41倍的加速。代码、模型、和单源及多源伪标签数据集均已开源。
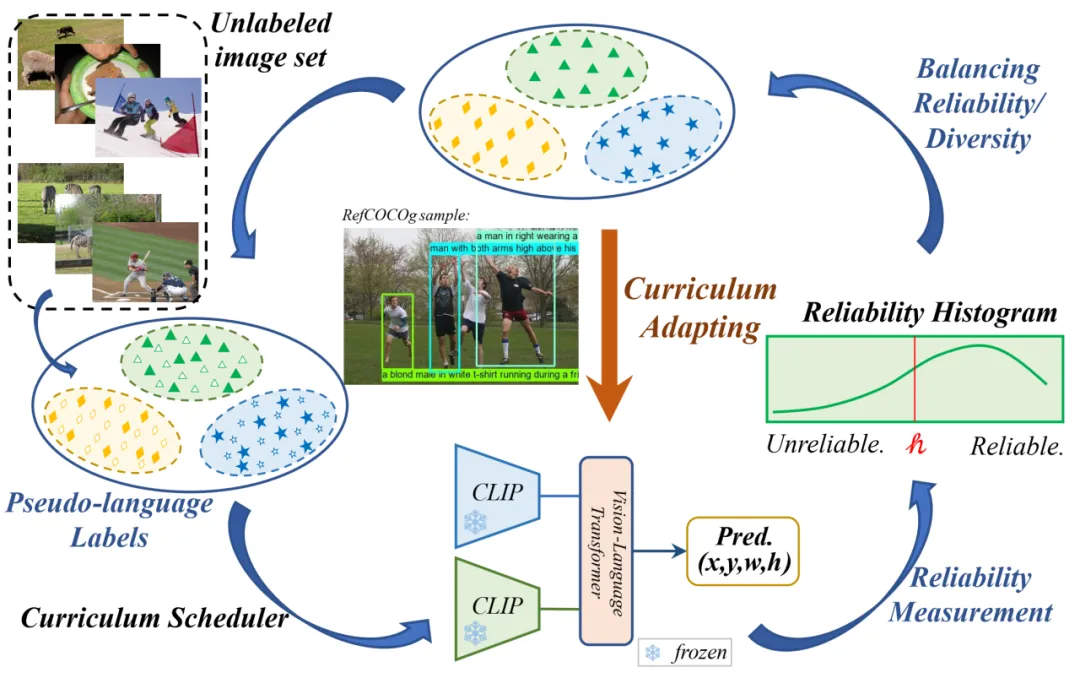
图1 CLIP-VG的主要思想
2.所提方法
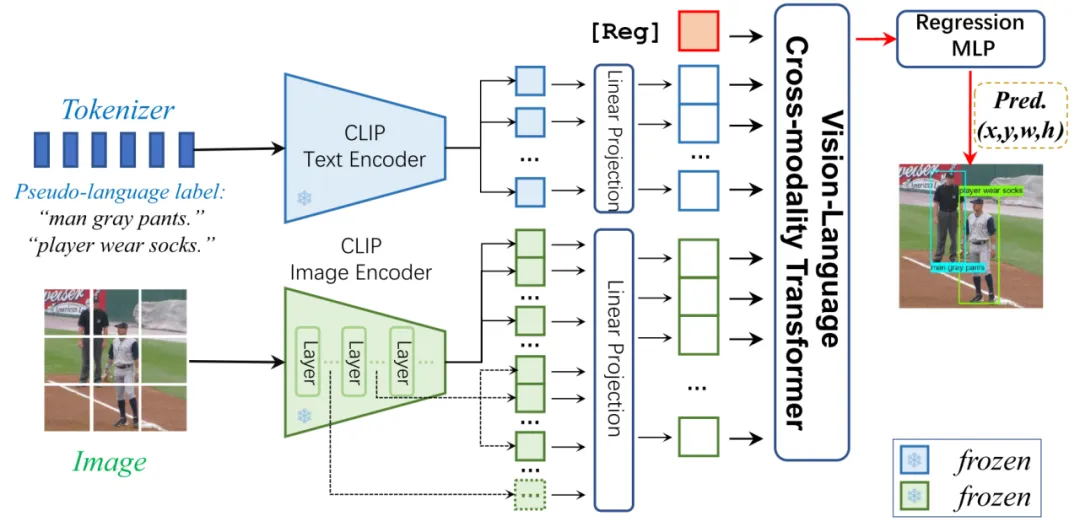
图2 CLIP-VG的模型结构
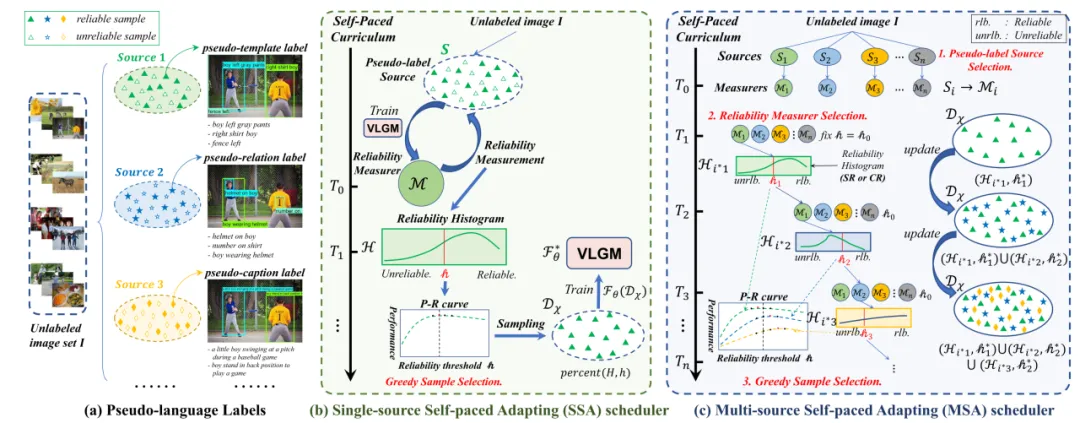
图3 伪语言标签,单源自步自适应算法,和多源自步自适应算法
本文提出CLIP-VG,它是一种可以通过利用伪语言标签进行自步课程自适应来解决视觉定位问题的新颖方法。本文的方法主要包括: (1)一个简单而高效的基于CLIP的纯Transformer的视觉定位模型; (2)一个样本可靠度评估方案; (3)一个单源场景下的自适应算法; (4)一个进一步扩展的多源自适应算法。具体来说,首先,如图2所示,本文提出一个简单而高效的端到端纯Transformer且仅编码器的网络架构。该结构只需要自适应少量的参数,花费最少的训练资源,就能实现CLIP在视觉定位任务的迁移。其次,如图3所示,为了通过寻找可靠的伪标签来实现对CLIP网络架构更稳定的自适应迁移,本文提出了一种评估实例级标签质量的方法和一种基于自步课程学习(SPL)的渐进自适应算法,即可靠度评估(论文III-C部分)和单源自步自适应算法(SSA,论文III-D部分)。实例级可靠度被定义为特定标签源学习的评估器模型对其样本正确预测的可能性。具体而言,本文学习一个初步的定位模型作为可靠度评估器,以CLIP为模型的主干,然后对样本的可靠度进行评分,构建可靠度直方图(RH)。接下来,根据构建的直方图,以自步的方式执行SSA算法,逐步采样更可靠的伪标签,以提高定位的性能。为了有效地选择伪配对的数据子集,本文设计了一种基于改进的二叉搜索的贪心样本选择策略,以实现可靠度和多样性之间的最优平衡。第四,本文所提出的CLIP-VG的一个主要优点是其渐进式自适应框架,其不依赖于伪标签的特定形式或质量。因此,CLIP-VG可以灵活扩展,从而可以访问多个伪标签源。在多源场景中,本文制备了三种伪标签源。本文首先独立学习每个伪标签源特定源的定位模型。然后,本文提出了源级复杂度的评估标准。具体而言,在SPL的不同步骤中,本文根据每个表达文本中实体的平均数量,从简单到复杂逐步选择伪标签源。在SSA的基础上,本文进一步提出了特定源可靠度(SR)和跨源可靠度(CR),以及多源自适应(MSA)算法(III-E节)。特定源可靠度定义为使用当前标签源学习的定位模型正确预测当前伪标签的近似可能性。相应的,交叉源可靠度的定义是通过与其他标签源学习的定位模型正确预测当前源伪标签的近似可能性。实验发现不同的样本标签对特定源可靠性和交叉源可靠性有不同的敏感性,并可以学习到不同的泛化特征。基于此,MSA方法渐进式地利用伪标签以由易到难的课程范式来学习定位模型,最大限度地利用不同源的伪标签,从而保证基础模型的泛化能力。
3. 实验分析
如下表1和论文表2所示,在RefCOCO/+/g、RefitGame和Flickr30K Entities这五个主流测试基准中,本文的模型在单源和多源场景下的性能都明显优于SOTA无监督定位方法Pseudo-Q,分别达到6.78% ~ 10.67% 和11.39% ~ 14.87%。所提出的SSA算法和MSA算法的性能增益为3%以上。此外,本文的方法甚至优于现有的弱监督方法。如表2所示,与全监督SOTA模型QRNet相比,本文仅使用其更新参数的7.7% 就获得了相当的结果,同时在训练和推理方面都获得了显著的加速,分别高达26.84倍和7.41倍,本文的模型在速度和能效方面也达到了SOTA。
表1 在RefCOCO/+/g三个数据集上的无监督和全监督SoTA对比分析实验
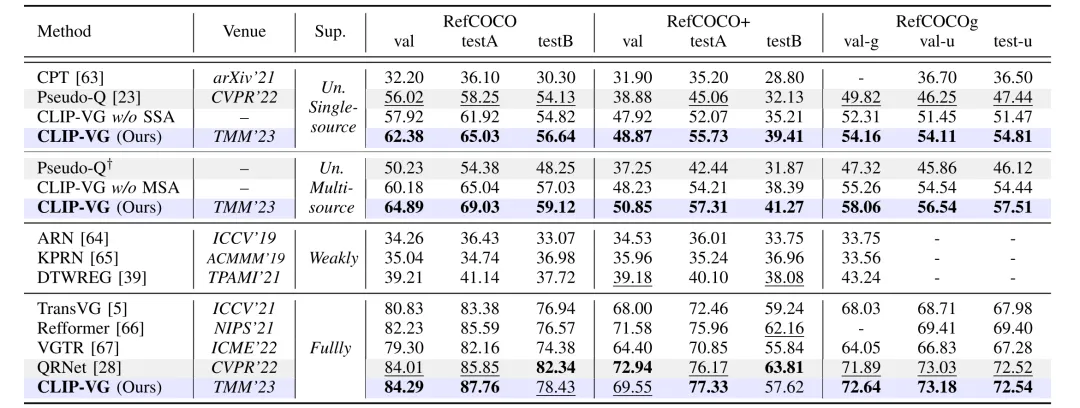
表2 在训练和推理上的能效对比分析实验

图4 特定源可靠性和跨源可靠性的分布直方图

图5 在RefCOCO/+/g三个数据集上MSA算法执行前后的泛化特征分布图对比
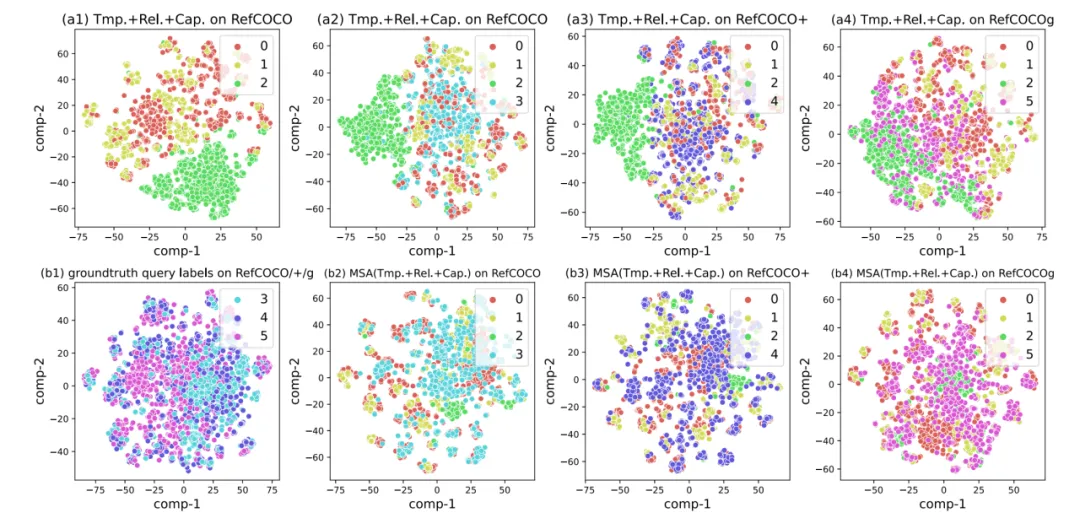
在实验中,本文发现不同源的伪标签由于其特定的标签质量和语言分类词汇差异而表现出不同的分布(如图4- (a1)-(b2)-(c3)),而不同的可靠度评估器对同一标签源的伪标签具有不同的区分能力(如图4- (a1)-(b1)-(c1))。这为本文的方法的性能提升提供了一个解释。从图5中可以看出,在MSA算法执行前,伪语言标签和真实查询标签的分布差异较大,但在MSA算法执行后,分布差异明显变小。这表明MSA可以有效地选择更可靠或更接近真实查询标签分布的伪标签。
02
DACOD360: Deadline-Aware Content Delivery for 360-degree Video Streaming over MEC Networks
作者:
谭小彬12,王顺义1,徐祥1,郑烇12*,杨坚12,陈双武12
单位:
1中国科学技术大学自动化系,
2人工智能研究院合肥综合性国家科学中心
邮箱:
xbtan@ustc.edu.cn,
wsy12@mail.ustc.edu.cn,
xux20@mail.ustc.edu.cn,
qzheng@ustc.edu.cn,
jianyang@ustc.edu.cn,
chensw@ustc.edu.cn
论文:
https://ieeexplore.ieee.org/document/10271717
发表期刊:TMM2023
*通讯作者
1. 论文简介
近年来,信息技术和5G网络的快速发展使得虚拟现实(VR)应用备受关注。360度视频或叫全景或沉浸式视频,是VR的重要组成部分,在学术界和工业界引起了极大的关注。然而,传输360度视频所需的网络带宽是传统视频的几十倍,同时用户对360度视频的时延也有着极为苛刻的要求,高带宽低时延的需求对现有网络构成了巨大的压力。在本文中,我们提出了DACOD360,这是一个基于边缘计算网络的360度视频流媒体内容交付系统。为了应对用户视野的动态性、边缘缓存的不充分、以及高并发请求和动态带宽等挑战,我们将截止时间感知的交付问题建模成为一个长期整数规划问题,在网络带宽、缓存容量和截止时间的约束下最大化长期用户体验质量(QoE)。这一优化问题是一个复杂的序列决策问题,它同时考虑了时间尺度上受截止时间约束的服务质量和空间尺度上的多用户资源分配。为了解决该问题,我们将原始问题分解为两个子问题,并使用深度强化学习(DRL)和讨价还价博弈(CBG)迭代求解。我们在多种环境中进行了全面的实验,结果表明我们提出的方案在长期QoE、流量负载以及其他指标方面优于现有的最先进方案。
2.论文方法
边缘计算网络中的带宽是动态变化的,用户的视野和视频流行度也是动态变化的,但是边缘缓存资源有限,缓存内容分布存在差异,目前没有一种方案同时考虑上述问题。由于客户端驱动的交付方案中,缺乏系统范围的调度和管理,加剧了用户对资源的激烈竞争,因此我们采用边缘服务器统一调度的方式实现内容交付决策控制。考虑到动态变化的带宽和用户请求,我们采用强化学习方法实现长期的QoE优化,在时延约束下保证服务质量。针对边缘缓存资源和带宽资源有限的问题,我们采用讨价还价博弈理论实现公平高效的码率分配。 如图1所示,我们利用边缘计算网络的缓存和计算能力,在边缘服务器中部署缓存服务代理,并对多用户视频交付实现统一的调度和管理。
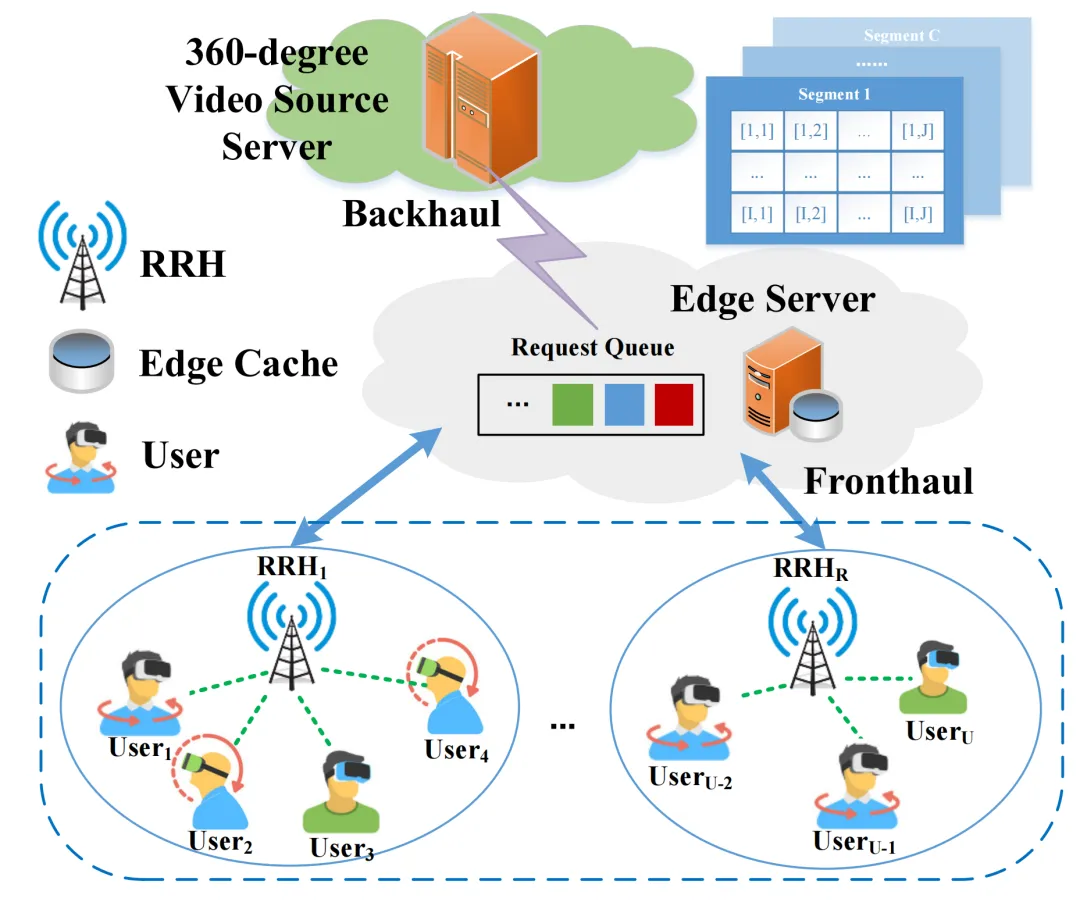
图1 基于边缘计算网络的360度视频交付场景
针对上述场景中的问题,我们采用比例公平模型优化长期的多用户QoE,该问题可以建模为:
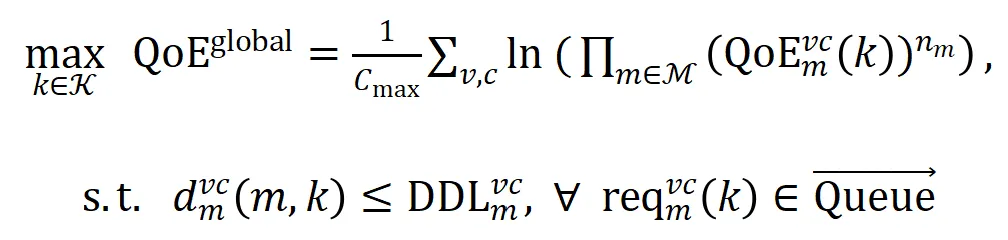
其中单用户的QoE模型可以表示为,包括码率、码率切换和抖动,并且需要满足用户的截止时间需求。
为了求解上述复杂的问题,我们按照时空关系将其解耦为交付规划和码率分配子问题。交付规划问题是一个长期的序贯决策问题,需要根据用户的截止时间需求,带宽变化情况动态调整交付时间,以权衡交付时延和服务质量的关系。如图2所示,我们采用A3C强化学习算法来适应时变特征。
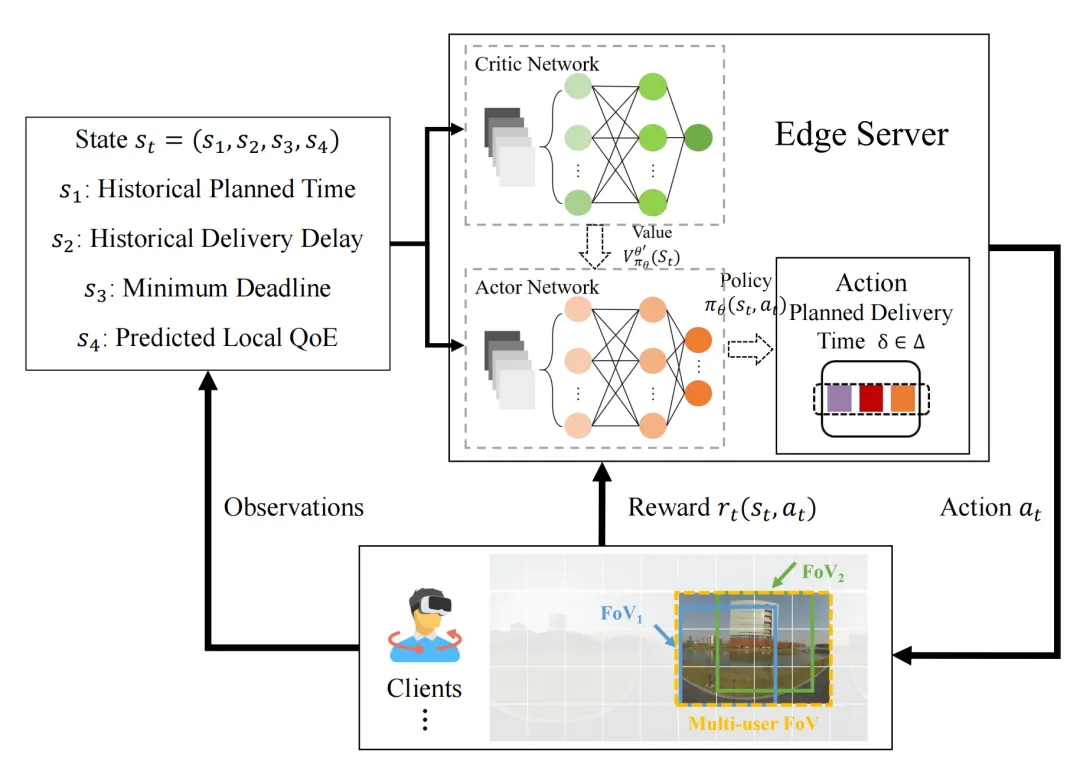
图2 基于A3C深度强化学习的交付规划算法架构
求解得到最优的计划交付时间后,可以根据预测带宽确定预估的交付数据总量,将该可用数据量分配给每个请求。通过求解KKT条件可以得到每个请求的纳什均衡解:
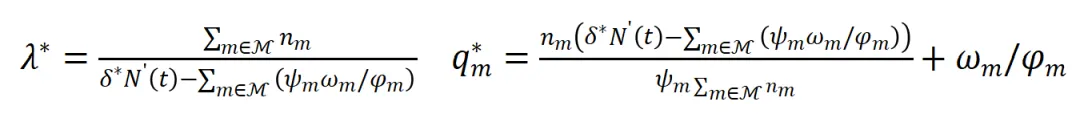
由公式可以看出,当该请求聚合了较多的用户,或者已经在边缘服务器中存在缓存,单位带宽能够获得更高的收益,因此可以分配得到更多的资源,这种分配方法既保证了资源利用的充分性,又保证了用户的公平性。通过结合上述的基于强化学习的交付规划算法和基于讨价还价博弈的码率分配算法,可以保障及时视频交付的同时实现长期的多用户QoE优化。
3.实验分析
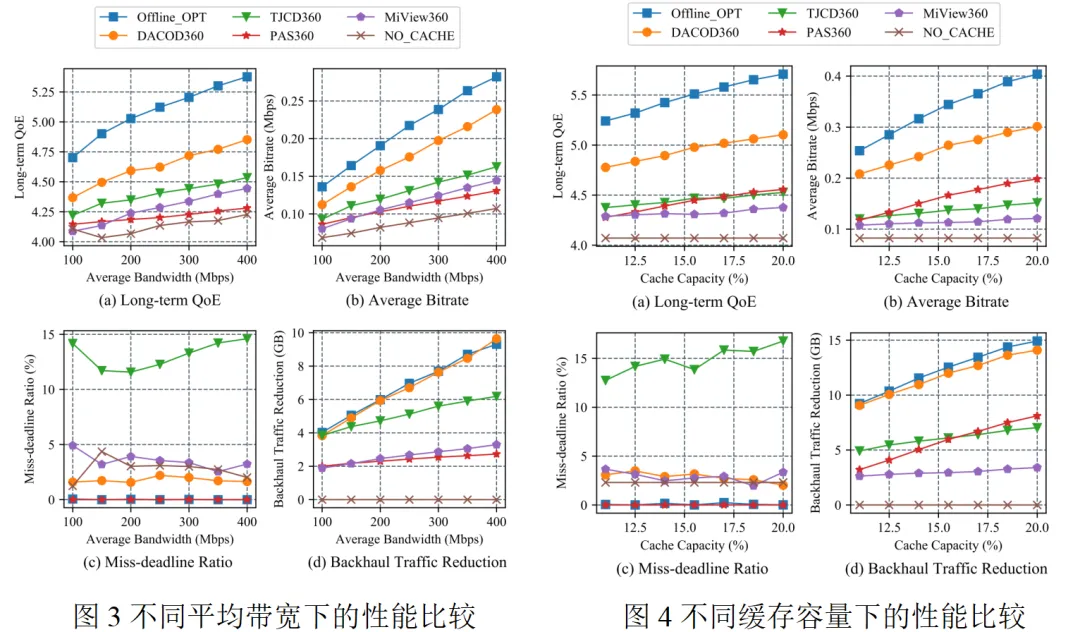
图3展示了不同核心网络带宽情况下的性能比较。当带宽资源严重不足时,我们的方法显著提高了用户的长期QoE,并将超时比例严格控制在2%-3%范围内。另外,我们的方法提高了至少40%的平均码率,减少了核心网络的传输流量,这表明我们的方法有效地利用了带宽和缓存资源。图4展示了不同缓存容量的情况下的性能比较,我们的方法在长期QoE和平均码率方面均有显著提升。结果说明了边缘缓存和聚合在内容交付中所起的关键作用。随着缓存容量的增加,显著减少了核心网路流量,有更多的数据不通过核心网络而从边缘网络中获取,更多带宽用来进一步提升视频码率。基于讨价还价博弈的码率分配算法通过求解纳什均衡解,在带宽资源有效分配方面起着至关重要的作用,这种有序的分配机制确保了资源的合理利用。
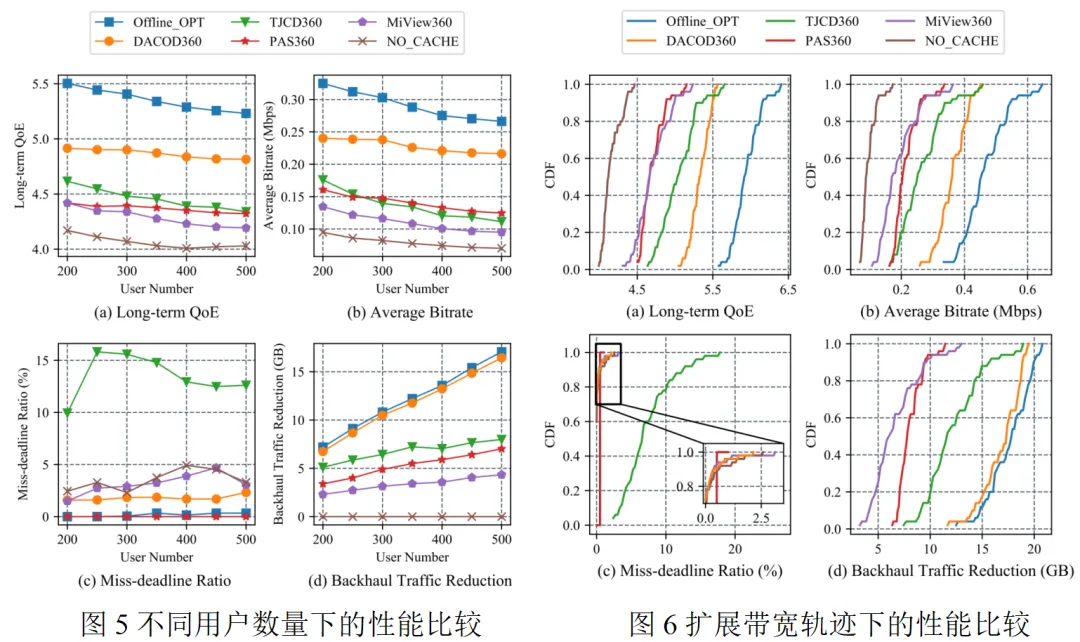
为了评估系统的可扩展性,我们将用户数量从200扩展到500。如图5所示,所有算法的长期QoE和平均码率会随着用户数量的增加而减少。然而,我们的方法始终优于其他方法,保持了其优越的性能。随着用户规模的扩大,我们的方法能有效地利用可用的带宽和缓存资源来保持服务质量。另外,我们从测试数据集中随机选择50个带宽轨迹来进行评估。如图6所示,在所有网络轨迹中,我们的方法与其他方案相比,始终获得更好的QoE性能,特别是在带宽严重受限的情况下。这是因为我们的方法有效地提高了视频的平均码率,确保了及时的请求响应,并减少了在核心网络上的传输负担。
03
Dual-Perspective Fusion Network for Aspect-Based Multimodal Sentiment Analysis
作者:
王笛1,*,田昌宁1,梁潇1,赵林2,何立火1,王泉1
单位:
西安电子科技大学1,南京理工大学2
邮箱:
wangdi@xidian.edu.cn,
cntian@stu.xidian.edu.cn,
ecoxial2012@outlook.com,
linzhao@njust.edu.cn,
lhhe@mail.xidian.edu.cn,
qwang@xidian.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10269001
代码:
https://github.com/cntian0/DPFN
发表期刊:TMM2023
* 通讯作者
1.研究背景与动机
方面级多模态情感分析(ABMSA)是一项重要的情感分析任务,它通过分析多模态数据(通常包括文本和图像)来识别每个指定方面术语的情感极性。例如,在评论文本“虽然服务很差,但食物很美味”中,对于“食物”和“服务”这两个方面术语,其情感极性分别是积极和消极。这项技术广泛应用于评论分析、舆情监测等领域。现有工作在分析每个方面术语的情感时,通常忽略了与特定方面的情感高度相关的整体情感倾向,也未能探索和充分利用与方面术语密切相关的细粒度多模态信息。为解决这些限制,我们提出了一个双视角融合网络(DPFN),该网络考虑了多模态数据中的全局和局部细粒度情感信息。从全局视角,我们使用文本-图像标题对来获取包含整体情感倾向信息的全局表征。从局部细粒度视角,我们构建了两种图结构来探索文本和图像中的细粒度信息。最终,通过分析全局和局部细粒度情感信息的结合,可以得到方面级别的情感极性。
2.方法概述
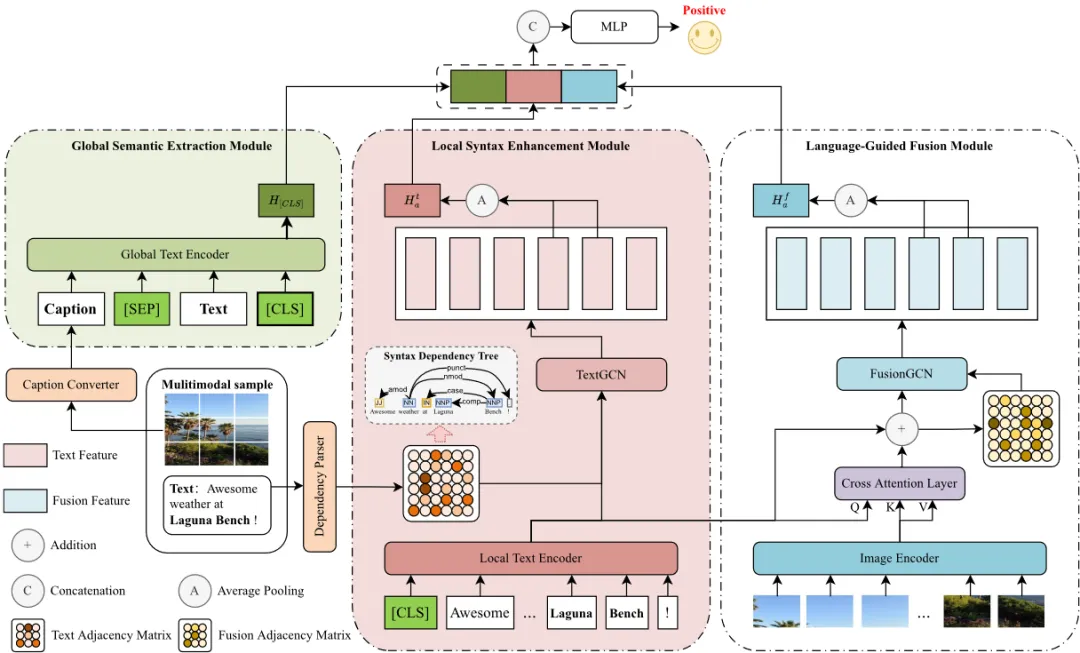
图1 双视角融合网络(DPFN)整体结构图
本文提出的双视角融合网络(Dual-Perspective Fusion Network, DPFN)整体架构如图1所示。DPFN从多模态数据中提取全局情感信息和局部细粒度情感信息,并从全局和局部两个视角获得最终的方面级情感极性。DPFN由三个模块组成:全局语义提取模块(Global Semantic Extraction Module, GSEM)、局部语法增强模块(Local Syntax Enhancement Module, LSEM)和语言引导融合模块(Language Guided Fusion Module, LGFM)。具体来说,在全局语义提取模块中,将图片转换成图像说明并与评论文本一起作为全局预训练文本编码器的输入,以从文本和图像两种模态中提取全局语义信息,同时消除图像模态和文本模态之间的语义差距。局部语法增强模块利用依赖解析器捕捉与方面术语相关的语法信息,并利用图卷积神经网络增强局部文本编码器,以提取细粒度语义信息。语言引导融合模块利用跨模态注意力引导细粒度文本特征和视觉特征的融合,同时学习图像块与词语之间的细粒度对应关系。最后将全局语义特征、局部语法增强的细粒度文本特征和语言引导的细粒度视觉特征结合起来,实现多模态方面情感分类。
3.实验分析
为综合评估所提方法的性能,论文在两个方面级多模态情感分析数据集Twitter-2015和Twitter-2017上进行了实验,实验结果如表1所示。结果显示,论文提出的DPFN在两个数据集的所有指标上都显著超过了现有方法,证实了DPFN在方面级多模态情感分析任务上的有效性。表2给出了各个模块的消融实验结果,可以看到移除文本图构建和图卷积操作会导致模型性能下降,因为模型无法通过图卷积操作从文本特征中学习与方面词相关的信息。同样,当移除融合特征上的图卷积操作后,模型无法学习通过关联细粒度图像块来获取场景信息,性能显著下降。此外,实验结果还表明,从全局视角和局部细粒度视角考虑情感极性的方法是有效的,移除任何一个视角都会大幅度降低模型的性能。测试用例可视化分析如图2所示。
表1 双视角融合网络的性能比较
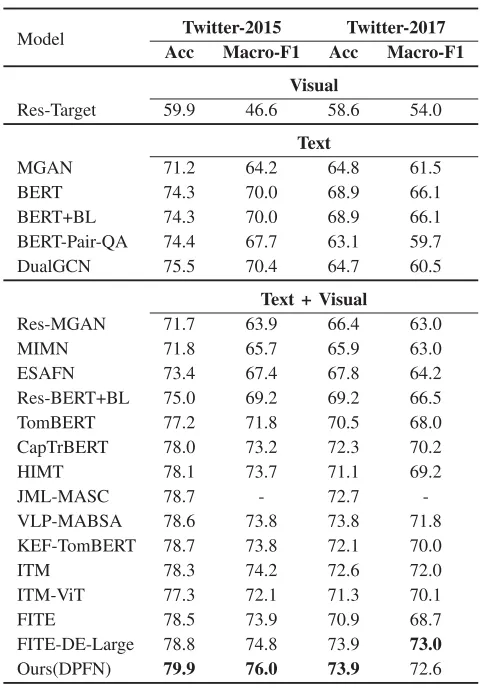
表2 各模块消融实验结果
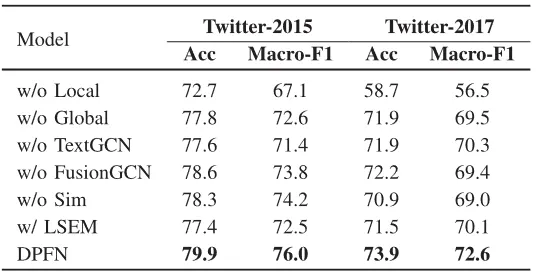

图2 不同方法的测试用例可视化
04
UEDG:Uncertainty-Edge Dual Guided Camouflage Object Detection
作者:
吕毅轩,张弘,李岩,刘翰阳,杨一帆*,袁丁
单位:
北京航空航天大学
邮箱:
yixuan.lyu@nyu.edu,
dmrzhang@buaa.edu.cn,
yanliz@buaa.edu.cn,
by2015102@buaa.edu.cn, stephenyoung@buaa.edu.cn, dyuan@buaa.edu.cn
论文:
https://ieeexplore.ieee.org/document/10183371
代码:
https://github.com/lyu-yx/UEDG
发表期刊:TMM2023
*通讯作者
1.背景与动机
背景:根据达尔文的自然选择进化理论,野生动物为了躲避捕食者,已经发展出了令人惊叹的伪装策略,例如隐蔽性伪装和拟态伪装。近年来,学术界对这种反侦察能力的兴趣日益增长,特别是在计算机视觉领域。在众多研究领域中,伪装物体检测(COD)扮演了重要角色,其目标是在各种背景中识别出不显眼的物体。这一研究成果可以拓展到多个不同的领域,包括道路裂缝检测、显著性和伪装物体的互相转换、伪装生成以及医学异常组织分割 等。
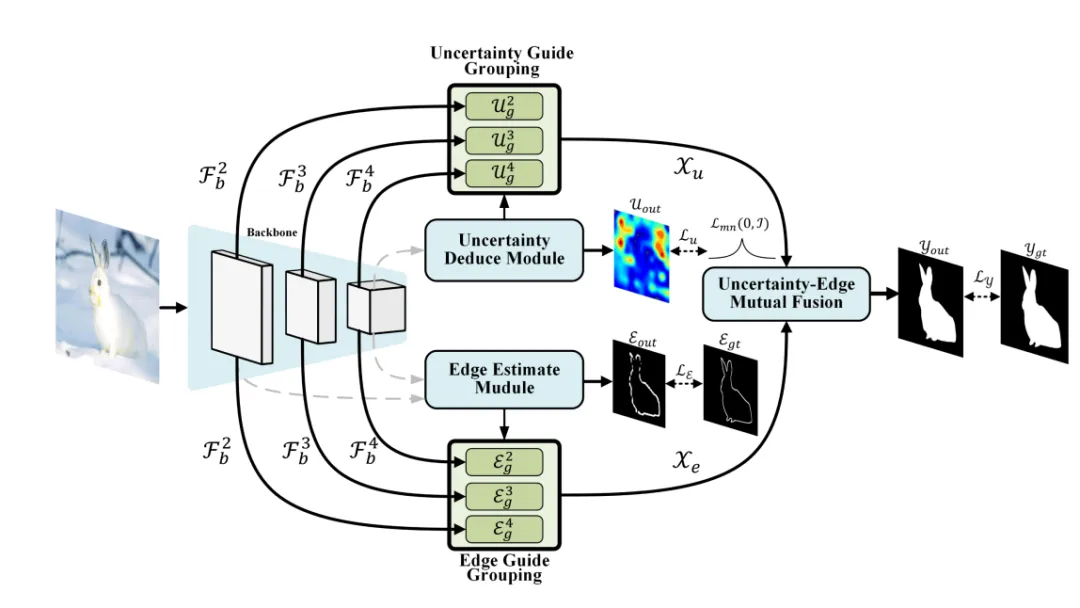
动机:从生物学的角度来看,猎物通过打破空间的不连续性,如边缘信息,固有纹理来避免被发现。受此启发,理解边缘信息可以增强方法的揭示能力。除此之外,当人类试图从杂乱的场景中识别出伪装的物体时,一般很难立即得出准确的结果,尤其是当前场景当存在遮挡,复杂细节和隐性边界等影响时。面对这种复杂任务,人类更倾向于首先赋予困难识别区域一个概率或也就是不确定性,然后再对该区域进行细节上的关注,进而实现前景与背景的区分。本文提出的UEDG受这两点的启发,分别使用基于确定网络的边缘回归分支和基于概率网络的不确定度回归网络进行伪装目标的识别。

图1 边缘,不确定度示意图
2.贡献
论文的主要贡献包括:
一种新颖的COD任务结构,该结构能够同时利用多个辅助任务(例如在UEDG中的不确定性和边缘任务),以提升伪装物体检测(COD)的性能。
通过精心设计特征融合机制,通过不确定性-边缘互融合(UEMF)模块在可接受的计算复杂度下实现了双向精细化、跨层次融合和抗模糊技术。此外,不确定性推导模块(UDM)和边缘估计模块(EEM)的推理结果通过不确定性/边缘引导分组(UGG/EGG)模块得到了进一步增强,并在端到端的结构中被UEMF充分利用。
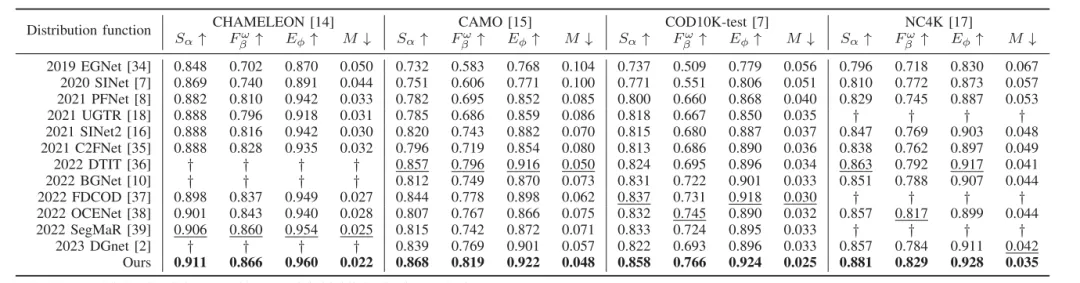
在四个广泛使用的基准上,CHAMELEON、CAMO、COD10K和 NC4K,我们展示了SOTA性能,并且相比于第二好的伪装物体检测模型有显著的性能提升。
3.方法
不确定性-边缘双重引导网络 (UEDG) 概述。Pyramid Vision Transformer (PVT) 用于特征提取。不确定性推导模块 (UDM) 和边缘估计模块 (EEM) 用于不确定性和边缘推理。不确定性/边缘引导分组 (UGG/EGG) 用于特征引导分组。不确定性-边缘互融合模块 (UEMF) 用于特征融合。
4.结果
本方法超越多个方法,在有限计算量和参数量的情况下达到了SOTA。

05
Hiding Multiple Images into a Single Image Using Up-Sampling
作者:
平萍*1,郭波标1,Olano Teah Bloh1,毛莺池1,许峰1
单位:
河海大学计算机与软件学院
邮箱:
pingpingnjust@163.com,
guobobiao@163.com,
otbloh@gmail.com,
maoyingchi@gmail.com,
njxufeng@163.com
论文:
https://ieeexplore.ieee.org/document/10272621
代码:
https://github.com/Hohai-PingPing/IH-US
发表期刊:TMM2023
*通讯作者
1.研究背景
随着互联网的广泛应用和数字媒体交换的增加,保护敏感数字图像免受未经授权的访问变得尤为重要,这也推动了图像隐藏的快速发展。为了满足不同应用场景的需求,目前已有两类基于传统方法的图像隐藏方法得到广泛应用,具体方法和结构分别如下图1和图2。其中,基于颜色转换的图像隐藏方法(Image Hiding by Color Transformation, IH-CT)具备高容量和秘密图像无损恢复的优点,但难以隐藏多张秘密图像且伪装图像质量较差;而基于压缩感知的图像隐藏方法(Image Hiding by Compressive Sensing, IH-CS)则能够提供高质量的伪装图像,但其容量较低且秘密图像只能有损恢复。
鉴于此,本文创新性地提出了第三类图像隐藏方法(如图3),即基于上采样的图像隐藏(Image Hiding by Up-Sampling, IH-US)。这种新方法综合高容量、多秘密图像同时隐藏且无损恢复以及伪装图像质量高的多重优势,极大地拓宽图像隐藏方法在各种应用场景中的实用价值。
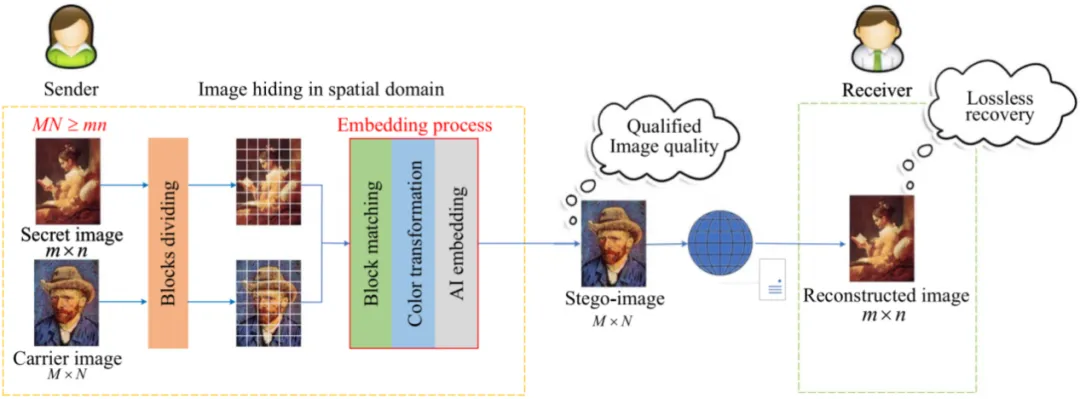
图1 基于颜色转换的图像隐藏框架图(IH-CT)
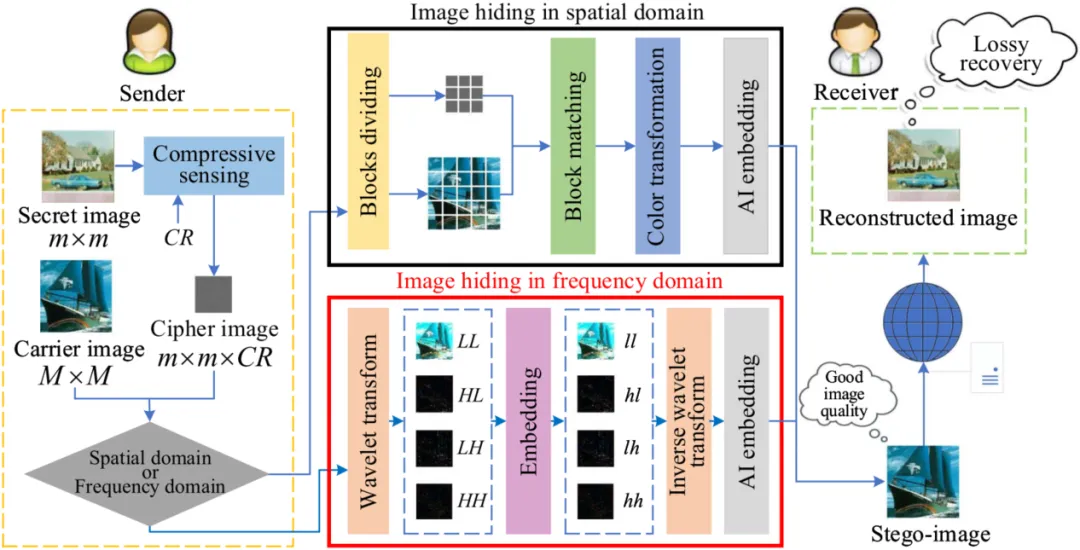
图2 基于颜色转换的图像隐藏框架图(IH-CS)
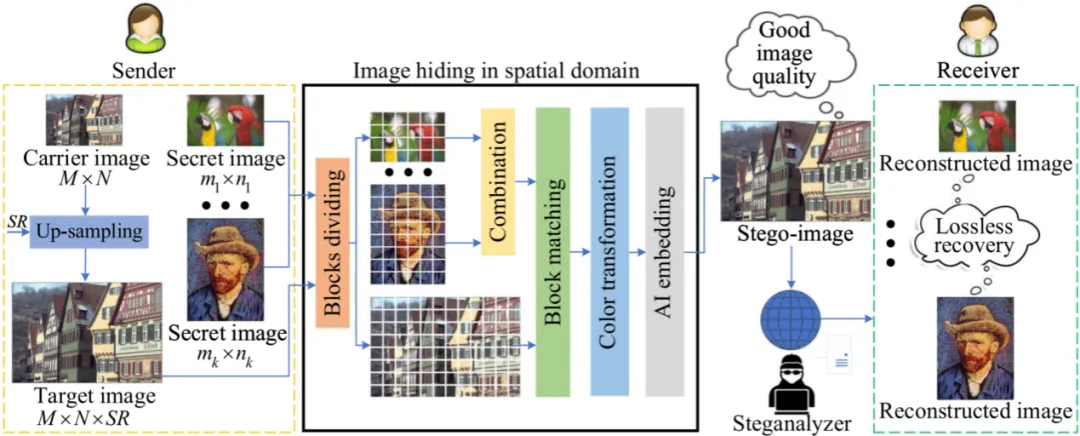
图3 基于颜色转换的图像隐藏框架图(IH-US)
2.研究方法
本文提出一种新的图像隐藏方法(如图4),能够将多张秘密图像无损地隐藏到单一载体图像中,并且能够实现秘密图像的无损恢复。首先,利用上采样技术(包括最邻近插值、双线性插值和三次卷积插值算法)对载体图像进行放大,以生成目标图像;接着,采用块匹配和颜色转换技术将多幅秘密图像嵌入到目标图像中,生成伪装图像。为提升伪装图像的质量,本文还创新性地提出一种基于欧氏距离的块匹配方法,该方法兼顾局部最优与全局最优,有效提高块匹配的效果。秘密图像的恢复过程与隐藏过程相反,确保秘密图像的无损恢复。
图4 本文多图像隐藏方法的框架图
3.实验分析
本文从图像质量和安全性两个维度评估所提方法的性能,并与IH-CT、IH-CS以及基于深度学习的方法进行比较。在图像质量方面,所提方法不仅能生成高质量的伪装图像,还能无损恢复多幅秘密图像,具体结果见表1。在安全性方面,该方法不仅能有效躲避先进的隐写分析工具SRNet的检测,还能抵抗JPEG压缩、高斯噪声等多种图像攻击,详见表2和表3。此项研究展示了所提方法在图像隐藏中的优越性,具有较高的实用价值。
表1 伪装图像和重构秘密图像的质量
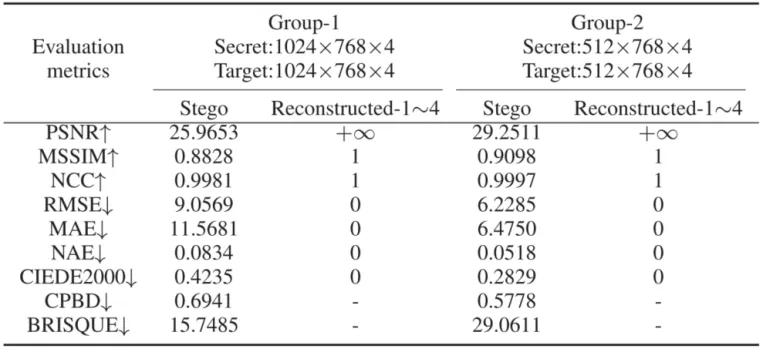
表2 SRNet的检测准确性
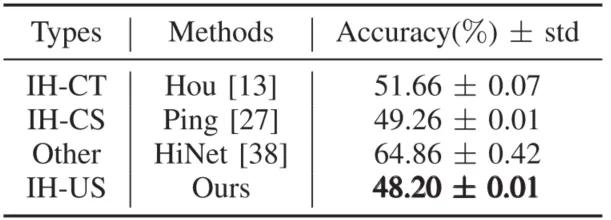
表3 对不同攻击方法的鲁棒性

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东

微信扫一扫
关注该公众号
 京公网安备11010802017125号
京公网安备11010802017125号