
【论文导读】2024年论文导读第二十期
【论文导读】2024年论文导读第二十期
CCF多媒体专委会 2024年10月08日 15:17 天津


论文导读
2024年论文导读第二十期(总第一百一十一期)
目 录
|
1 |
Locate before Answering: Answer Guided Question Localization for Video Question Answering |
|
2 |
FedSH: Towards Privacy-Preserving Text-Based Person Re-Identification |
|
3 |
Synthesize Boundaries: A Boundary-Aware Self-Consistent Framework for Weakly Supervised Salient Object Detection |
|
4 |
◦ |
|
5 |
Video Compressed Sensing Reconstruction via an Untrained Network with Low-Rank Regularization |
01
Locate before Answering: Answer Guided Question Localization for Video Question Answering
视频问答中基于答案引导的问题定位方法
作者:
钱天文1,崔然2,陈静静1*,彭湃3,郭晓威3,姜育刚1
单位:
1复旦大学视觉与学习实验室,
2The Australian National University,
3哔哩哔哩
邮箱:
twqian19@fudan.edu.cn,
ran.cui@anu.edu.au,
chenjingjing@fudan.edu.cn,
ygj@fudan.edu.cn
论文:
https://ieeexplore.ieee.org/document/10278436
发表期刊:TMM2023
*通讯作者
1.引言
现阶段的主流视频问答算法在剪辑好的短视频数据集上取得了令人满意的性能。然而,随着互联网的发展,用户生产了越来越多的未剪辑长视频。这些视频时长通常在分钟级以上,更长的视频持续时间意味着更多的场景变化和更多的动作、事件组合。现阶段的主流视频问答算法由于缺乏对这些变化带来的噪音和冗余信息的处理能力,因此在长视频数据集上往往表现不佳。本文研究发现,尽管这些视频的时长较长,但是其相应的查询问题通常仅针对在整个时间范围内的某一短时刻的单一场景或动作。针对这一特性,本文提出了一种先定位再回答的长视频问答范式,先在视频时序上定位出查询问题所关注的区间,然后再依据定位后的片段推断问题的答案。本文提出了LocAns视频问答算法,将问题定位模块和答案预测模块集成到一个端到端的模型中。模型的训练仅依赖答案标注,不需要额外的时序定位标签。此外,我们还设计了一种模块解耦的交替训练策略,依次训练定位模块和问答模块,实现了模型的稳定、快速收敛。通过在常见的长视频问答数据集NExT-QA,ActivityNet-QA以及AGQA上的大量实验,我们验证了LocAns对于长视频问答的优越性能,并且通过大量的可视化样本展示了问题定位模块的准确性。
2.方法概述
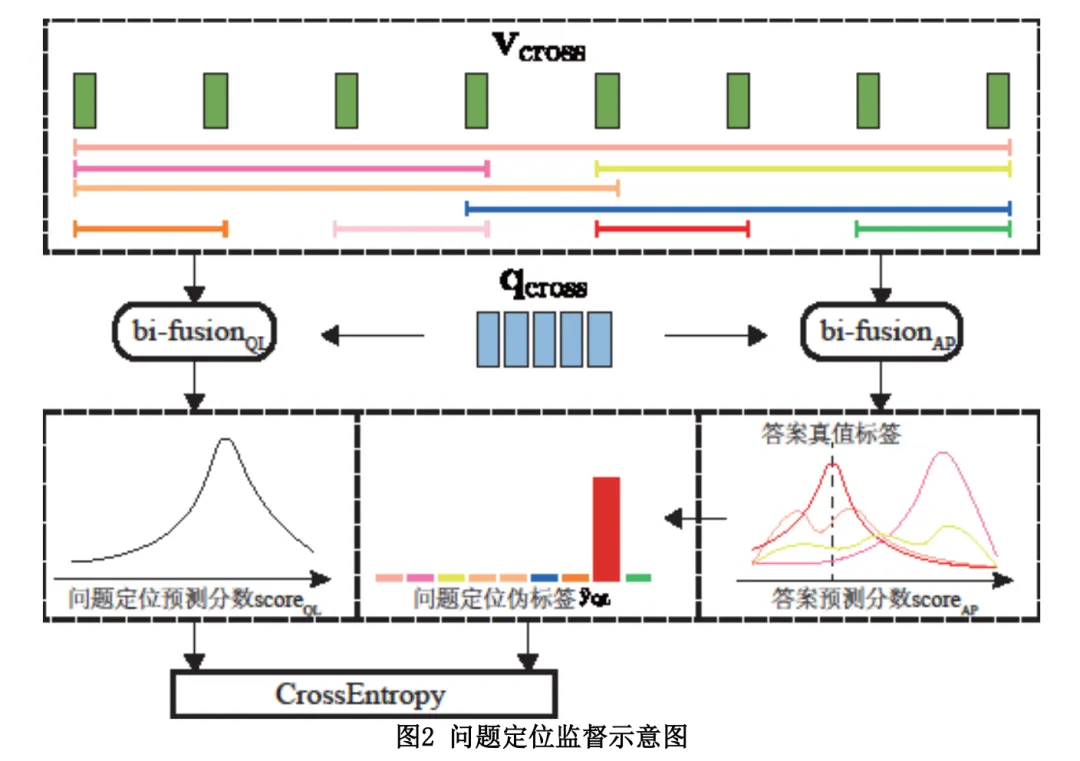
本文所提的LocAns算法框架如图1所示,主要由特征表示模块、问题定位模块以及答案预测模块三个部分组成。首先,原始视频和查询问题分别输入两个预训练特征提取器抽取特征。然后,特征表示模块通过自注意力将两种模态的原始特征映射到视觉问答任务中来。接着,问题定位模块使用跨模态注意力和双线性融合(bi-linear fusion)操作将两种模态的特征融合,并基于预设的时序候选框进行问题定位。最后,答案预测模块使用时序定位后的融合特征进行答案解码。

问题定位模块是LocAns的核心。由于缺乏问题定位的时序标注,因此无法直接用回归模型实现这一功能。为此,本文巧妙地将利用一系列预设的时序候选框将定位任务从回归问题转化为了分类问题。同时,如图2所示,我们使用答案预测模块为定位模块提供伪标签。此外,受到最大期望算法的启发,我们利用答案预测和问题定位模块的相互依赖性,设计了一种两个模块交替的训练策略,很大程度上提升了模型训练的稳定性和收敛速度。更多关于方法的细节请参见论文。
3.实验对比
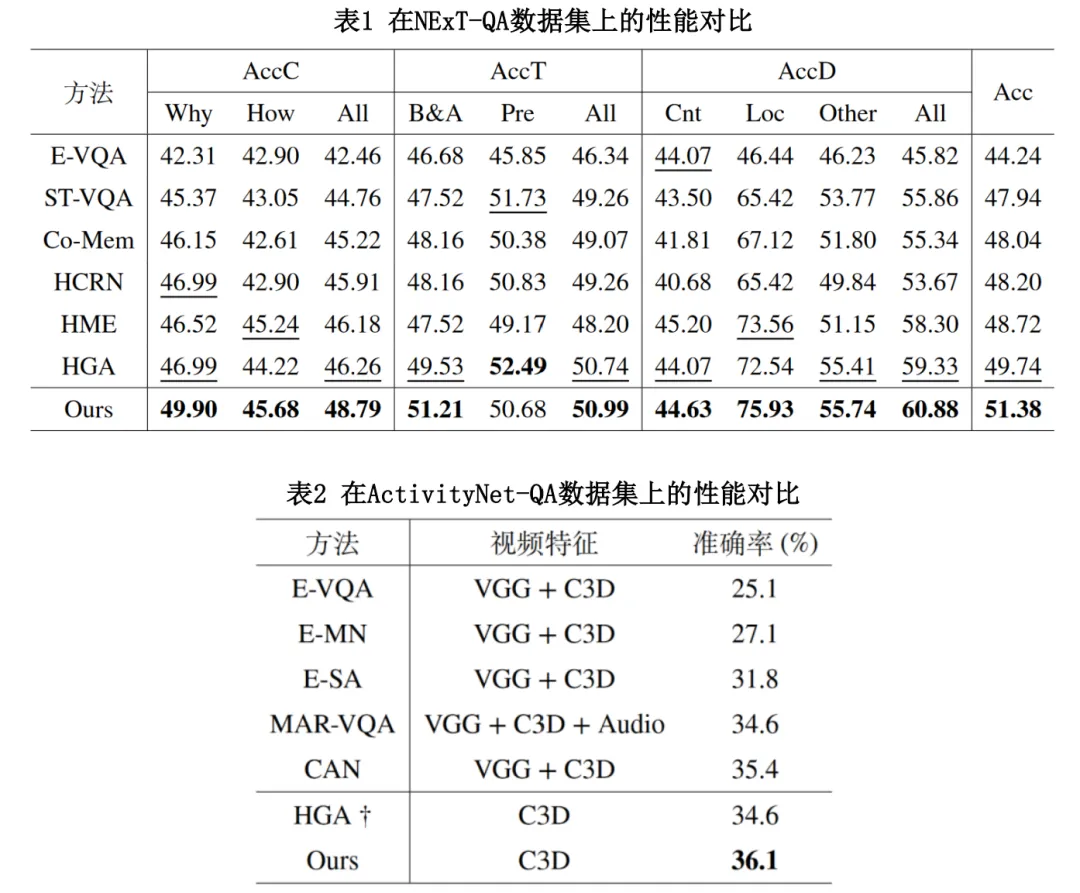
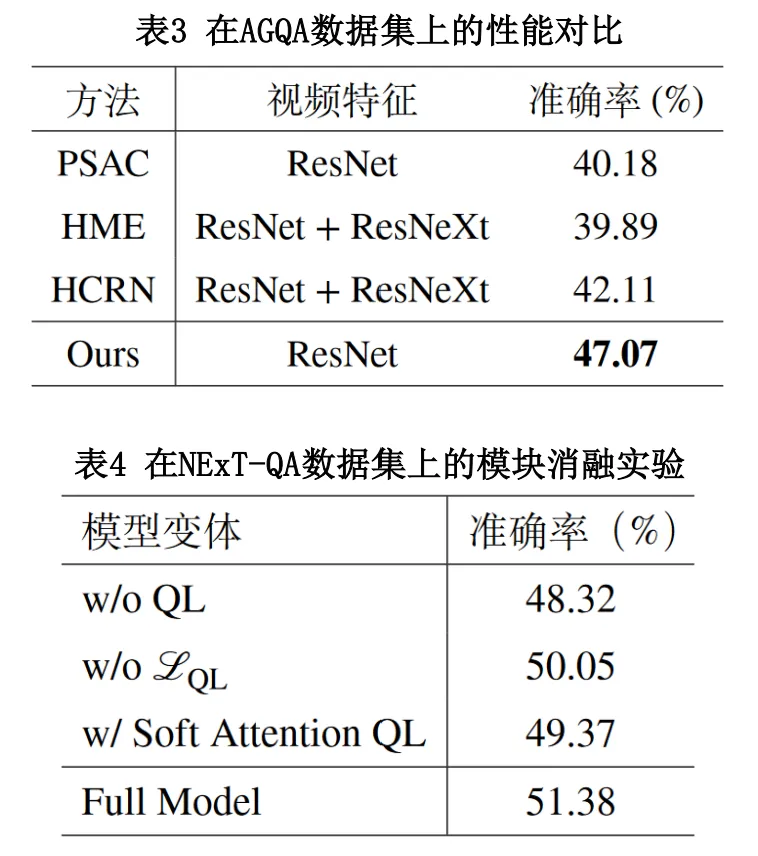
我们在NExT-QA,ActivityNet-QA以及AGQA数据集上将LocAns与此前先进的算法进行了全面的对比,实验结果如表1到表3所示。观察表格数据,我们可以发现LocAns在三个数据集上均取得了最佳的性能,其中在NExT-QA数据集的各个细分问题类型上也表现优异。表4展示了LocAns各个模块在NExT-QA数据集上的消融实验,验证了各个模块的有效性。
02
FedSH: Towards Privacy-Preserving Text-Based Person Re-Identification
面向隐私保护的文本-图像跨模态行人重识别
作者:
马文涛1,吴欣怡2,赵山3,周桐庆2,郭丹3,辜丽川1,蔡志平2,汪萌3
单位:
1安徽农业大学,2国防科技大学,3合肥工业大学
邮箱:
wtma@ahau.edu.cn,
wuxinyi17@nudt.edu.cn,
zhaoshan@hfut.edu.cn,
zhoutongqing@nudt.edu.cn,
guodan@hfut.edu.cn,
glc@ahau.edu.cn,
zpcai@nudt.edu.cn,
eric.mengwang@gmail.com
论文:
https://ieeexplore.ieee.org/document/10310121
代码:
https://github.com/Lab-ANT/FedSH
发表期刊:TMM2023
论文简介
行人重识别技术已在城市安防、消费者轨迹分析和智慧零售等领域得到了广泛的应用,该技术旨在判别由不同视域摄像头捕获的数据中某个行人的身份,进而能够在大规模监控网络中对目标人物进行快速、有效地排查和追踪。
然而,在一些复杂场景中,可获取的行人图像信息往往是不完备的,如在犯罪调查或者商场内查找走丢儿童时,目标行人的视觉线索无法获取,警方只能通过目击者对目标人物的外貌描述来检索,即基于文本的跨模态行人重识别——一种特定场景的跨模态检索任务。现有基于文本的行人重识别方法通常都是采用集中式的训练策略:将不同区域摄像机捕获的行人图像数据收集到一个服务器上进行训练,这给个人敏感信息构成了严重的隐私威胁。
因此,本文致力于探索面向隐私保护的文本-图像跨模态行人重识别,即利用联邦学习范式提出一种分布式跨模态行人重识别模型——FedSH。具体来说,FedSH 通过构建多粒度特征表征和语义自对齐网络,以解决由机构内部数据同质性和机构间数据异构性所造成的局部模型泛化弱和实体边界模糊的问题。同时,在联邦学习过程中采用更新特征表征公共子空间的方式来减少多模态嵌入带来的通信负担。在两个公共基准数据集上进行广泛的实验,结果表明与一些SoTA 基线方法和一系列的消融变体相比,FedSH在多个指标上取得了较好的性能。需要说明的是,本文是首次提出将联邦学习应用到基于文本的跨模态行人重识别场景。

03
Synthesize Boundaries: A Boundary-Aware Self-Consistent Framework for Weakly Supervised Salient Object Detection
作者:
徐斌伟,梁浩然*,梁荣华,陈朋
单位:
浙江工业大学
邮箱:
xubinwei@zjut.edu.cn,
haoran@zjut.edu.cn,
rhliang@zjut.edu.cn,
chenpeng@zjut.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10269049
发表期刊:TMM2023
* 通讯作者
1.论文简介
显著性目标检测旨在识别并分割图像中最引人注目的对象。尽管现有的显著目标检测模型已取得显著进展,但它们依赖于像素级标注标签进行训练,这类标签的获取成本高昂且耗时。为降低标注负担,研究人员提出了基于涂鸦标注的弱监督方法。这种方法使用稀疏标注替代像素级标注,从而减少了人工标注的工作量和成本。然而,从缺乏边缘信息的涂鸦标注中学习精确的边界分割极具挑战。现有方法虽设计了基于颜色和空间的规则,但由于缺乏边界相关的强监督信息,模型在预测显著目标时容易聚焦于那些易于区分的区域,而难以辨别较为复杂的凹凸区域和细长部分。因此,为了解决边界感知不佳的问题并进一步探索涂鸦标注的潜力,本文提出了一种从合成凹陷区域中学习显著性区域边界区分的方法(见图1中的合成图像)。对凹陷区域进行精细分割不仅是一项挑战,也是构建更优显著目标检测模型的关键。通过模拟这些凹陷区域,合成图像可以获得部分像素级标注。这些包含边界信息的标注将引导模型进一步关注边缘周围的区域,从而生成更精细的分割结果。

图1 合成凹陷区域示意图
2.论文方法
本文方法(如图2所示)由全局整体分支(GIB)和边界感知分支(BAB)组成。具体而言,BAB的目标是引导显著性检测器专注于边界区域,以帮助预测更加精确的边界。其输入为通过在原始图像中插入合成凹陷区域生成的合成图像。GIB则主要通过局部显著性一致性(LSC)损失、显著性结构一致性(SSC)损失和部分交叉熵(PCE)损失的监督,识别完整的显著性目标,防止显著性模型过度关注边缘细节而忽略目标的整体性。通过自监督学习,该自一致框架平衡了GIB和BAB两个分支,使其能够发挥互补优势,即在识别显著性目标的同时准确预测目标边界。此外,自一致框架放大了合成图像的优势,帮助BAB捕捉更多边界细节信息。
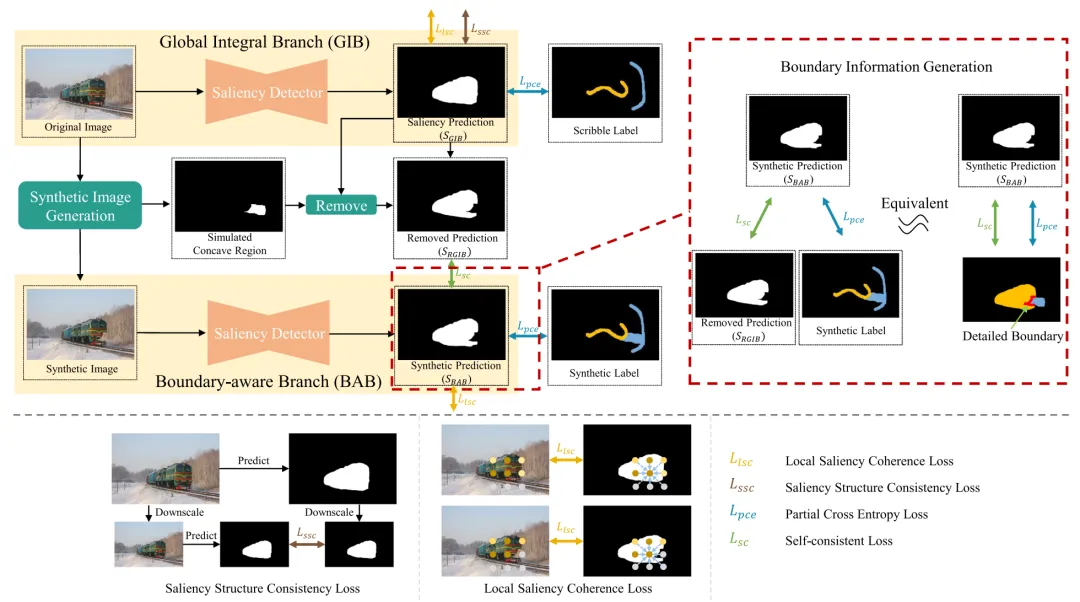
图2 网络框架
如图3所示,本文提出的模拟显著性目标真实凹陷区域的合成图像生成方法,通过在显著性目标中嵌入合成的凹陷区域,提供了边缘相关信息,以缓解原始涂鸦标注中边缘信息不足的问题。合成图像生成包括三个主要步骤:端点选择、凹陷区域生成和纹理生成。
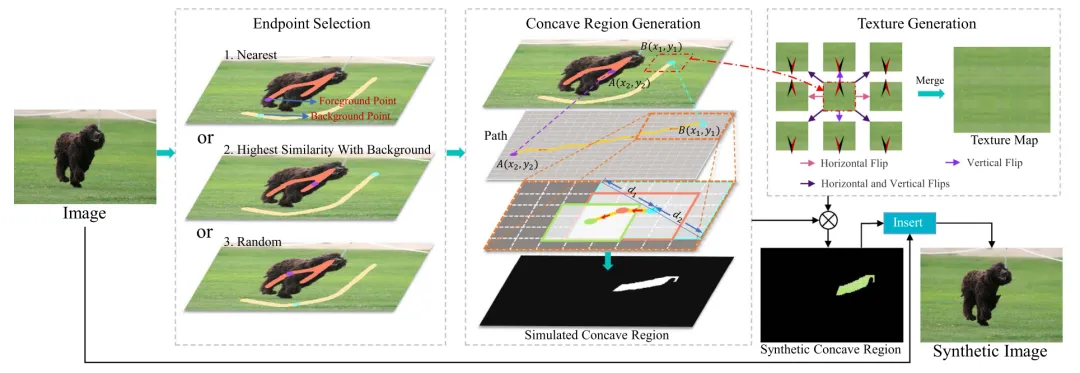
图3 合成图像生成示意图
3.实验结果
本文方法在常见数据集上进行了实验验证。表1展示了本文方法与其他方法在PASCAL-S、ECSSD、HKU-IS、DUT-OMRON、DUTS-TE五个常用数据集上的对比结果,图4展示了显著性目标检测结果的可视化对比效果,表3则展示了关键模块的消融实验。实验结果表明,本文方法在提升弱监督显著性目标检测性能方面表现出色,尤其在边缘分割效果上取得了显著的提升。
表1 和其他方法在常用数据集上的比较
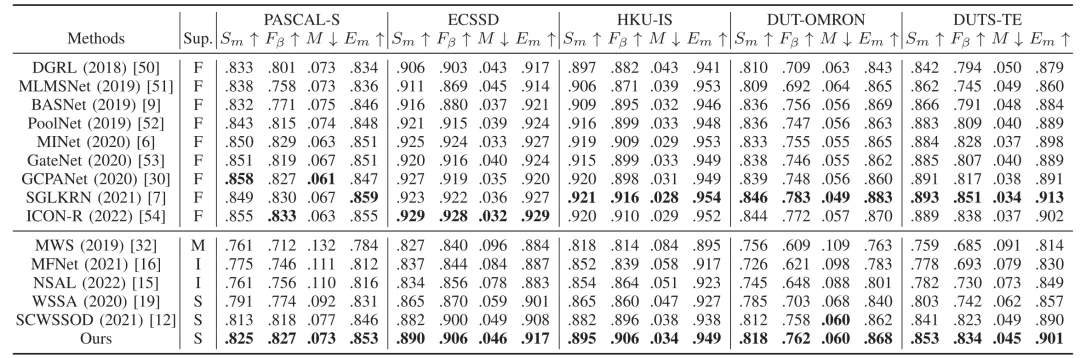
表2 消融实验
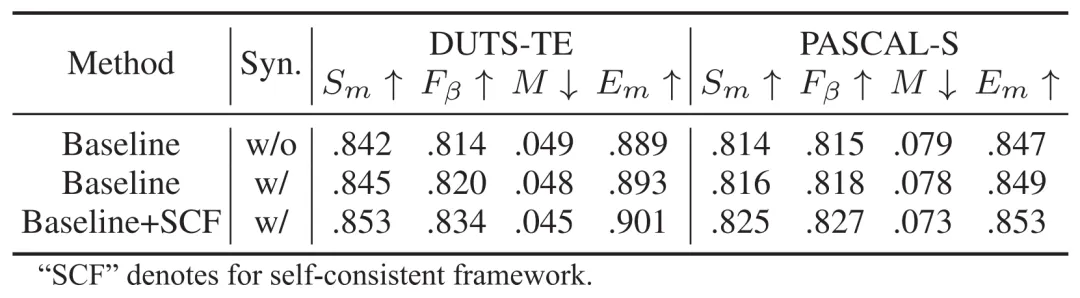

图4 定性结果比较
04
Distortion-Aware Self-Supervised Indoor 360◦ Depth Estimation via Hybrid Projection Fusion and Structural Regularities
作者:
王旭1、孔伟锋1、张秋丹1*、杨铀2、赵铁松3、江健民1
单位:
1深圳大学计算机与软件学院
2华中科技大学电子信息与通信学院
3福州大学物理与信息工程学院
邮箱:
wangxu@szu.edu.cn,
weifengkong.cs@gmail.com,
qiudanzhang@szu.edu.cn,
yangyou@hust.edu.cn,
t.zhao@fzu.edu.cn,
jianmin.jiang@szu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10261254
代码:
https://github.com/kongweifeng678/TMM
发表期刊:TMM2023
*通讯作者
1.论文简介
全景图像相比透视图像具有更大的视场,深度估计算法能以低成本的方式获取场景的深度信息,可广泛应用于虚拟现实、增强现实和自动驾驶等领域。全景图像深度估计根据监督方式的不同,主要可以分为全监督与自监督两类。目前,全监督全景图像深度估计已得到了广泛的研究,也具有较好的深度预测精度。然而,全监督的方式需要真实深度图像作为监督信号,这种真实深度图像的获取需要花费较大的时间与人力成本。自监督的深度估计方式仅通过已知相对位置差异的图像对即可实现对模型的监督,能够极大地降低数据获取成本。
本文主要聚焦于自监督全景图像深度估计任务。该任务主要存在全景图像投影失真,图像弱纹理区域难以方向传播,以及立体图像对存在遮挡等挑战。具体的,本文1)提出基于投影融合的双分支全景图像深度估计策略,以消除等距柱状投影引入的失真;2)构造失真感知模块,以解决等距柱状投影图像中存在的的不均匀采样问题;3)利用室内全景图像规则的结构信息构造几何约束,以解决图像弱纹理区域难以反向传播的挑战。
2.方法概述
等距柱状投影具有完整的视场,但是有严重的投影失真问题;而立方体投影具有较小的投影失真,但是其视场较小,且边缘部分存在严重的不连续性。如图1所示,本文提出的基于投影融合的双分支全景图像深度估计策略,将立方体投影图像的特征融合到等距柱状投影图像的特征中,以处理等距柱状投影图像的投影失真问题。同时,考虑到球面图像映射到等距柱状投影时,赤道附近区域采样率高,两极附近区域采样率低的不均匀采样问题,设计了失真感知模块。该模块将球面加权后的特征与原来的特征进行融合,使模型更加关注采样率较高的低纬度区域,从而解决了等距柱状投影图像的不均匀采样问题。
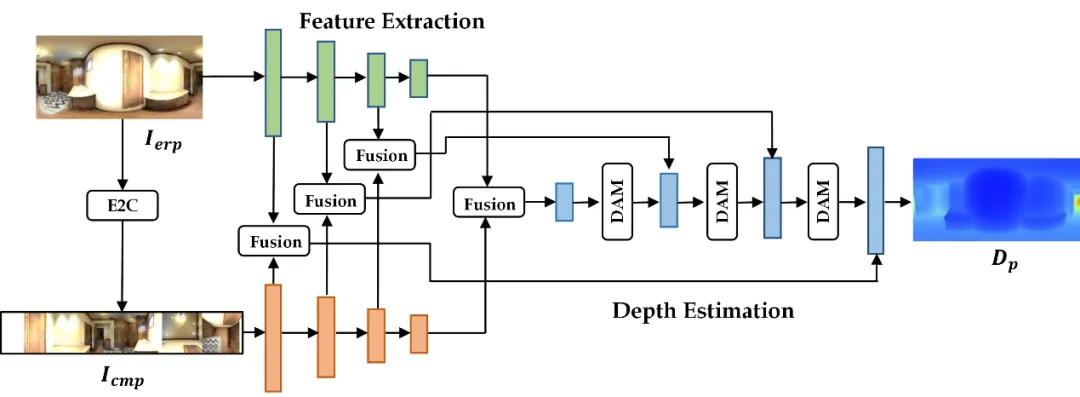
图1 全景图像深度估计推理模块
自监督训练阶段的整体框图如图2所示,本文在普通的光度一致性约束中引入了球面加权,以约束球面视图合成过程中全景图像的投影不均匀分布问题。此外,通过显著方向法线约束和平面一致性深度约束两个结构正则项的引入,有效解决了弱纹理区域的反向传播问题。
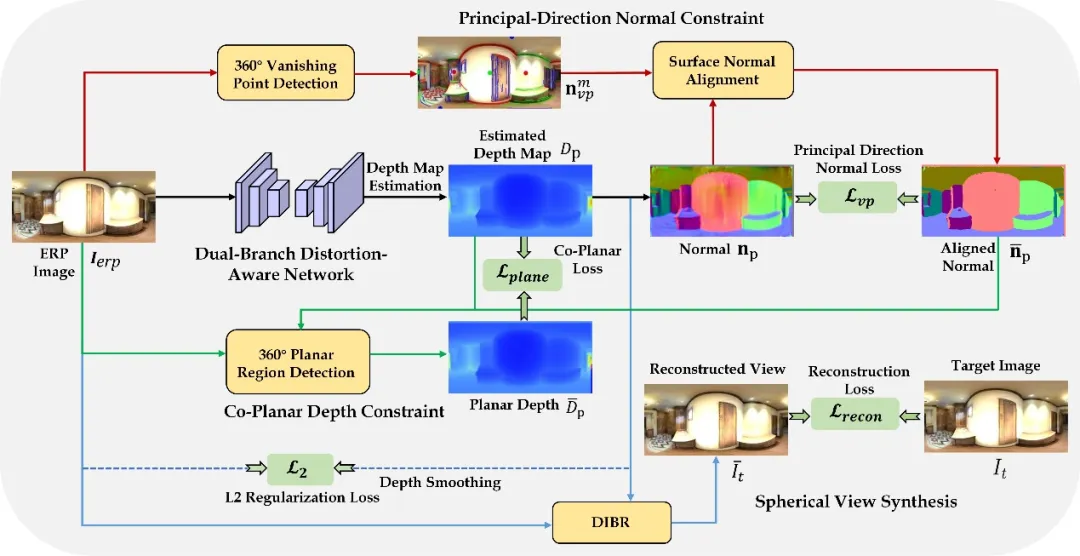
图2 自监督全景图像深度估计训练框架
3.实验分析
如表1所示,本文提供了在3D60数据集中的Matterport3D与Standford2D3D数据集上分别训练并测试的结果,在各种自监督方法中取得了最优的性能。此外,为了测试模型的泛化性,本文用3D60-Matterport3D数据集上训练的模型测试Matterpot3D-2K与ShanghaiTech-Kujiale Indoor 360中的数据,结果表明本算法在至少六个指标上的性能都要优于其它自监督模型。
图3提供了在真实场景数据集上的可视化预测结果,不难看出,本文提出的方法细节更加丰富,对室内结构拟合更好,泛化性更强。
表1 本算法与最先进的方法在 3D60 的 Matterport3D、Stanford2D3D、Matterpot3D-2K与ShanghaiTech-Kujiale Indoor 360 数据集上的评估表现
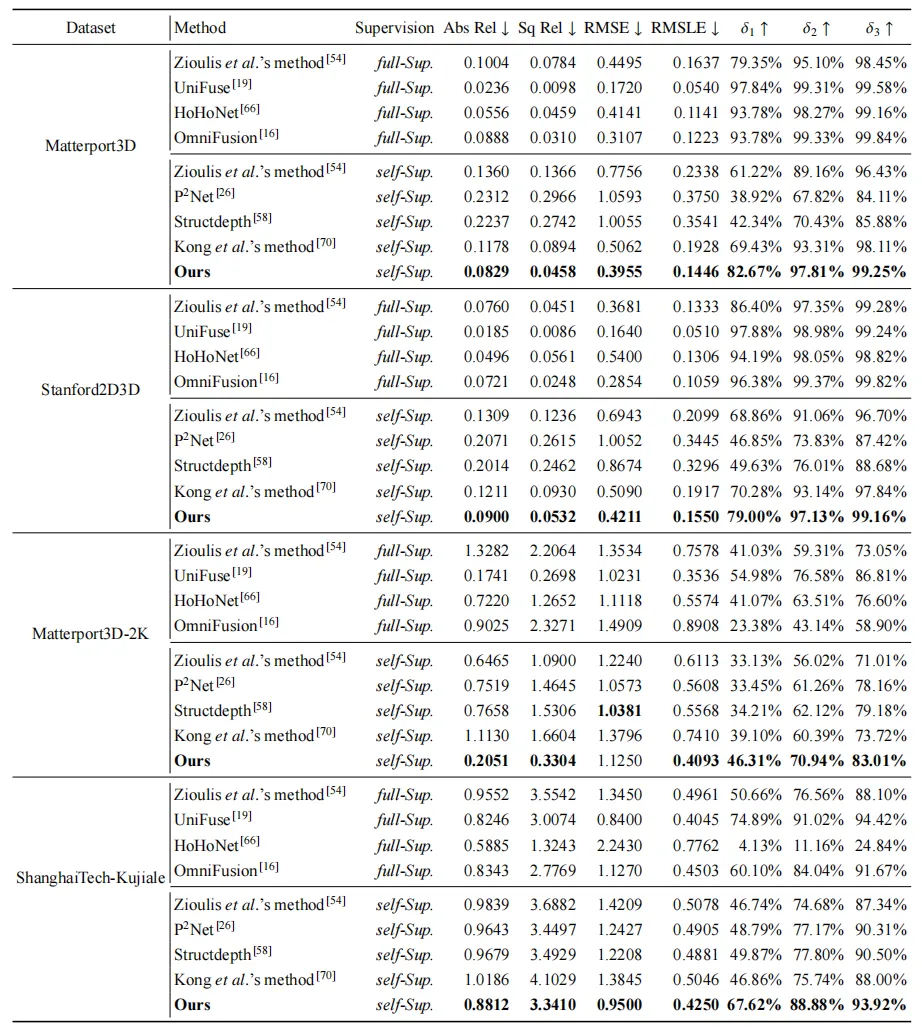

图3 本算法与三种最先进的深度估计方法在真实场景数据集上的可视化比较
05
Video Compressed Sensing Reconstruction via an Untrained Network with Low-Rank Regularization
作者:
仲元红1,张晨旭1,杨勋2,王姗姗3
单位:
1重庆大学微电子与通信工程学院,
2中国科学技术大学信息科学技术学院,
3安徽大学物质科学与信息技术研究院
邮箱:
zhongyh@cqu.edu.cn,
zhangchenxu@cqu.edu.cn,
xyang21@ustc.edu.cn,
wang.shanshan@ahu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10285022
发表期刊:TMM2023
1.论文简介
深度图像先验(deep image prior, DIP)表明,生成网络的结构本身足以捕获大量低级图像统计信息,不需要额外的训练数据即可实现图像重构。DIP弥补了深度学习方法与传统优化方法之间的鸿沟,在图像压缩感知(compressed sensing, CS)重构任务上展现出巨大的潜力。对于视频压缩感知重构任务,可以采用图像压缩感知重构方法对视频进行逐帧的重构,然而这样的方式会忽视视频信号本身的时空冗余特性,产生次优的重构结果。本文提出了新颖的视频压缩感知重构框架LRR-VCSNet,框架结合DIP与低秩正则,探索视频的时空相关性实现视频压缩感知重构。在六个标准 CIF视频上进行的大量实验表明,提出的框架优于传统的视频压缩感知重构方法,并且与主流的基于学习的视频压缩感知重构方法相比取得了良好的性能。
2.方法概述
提出的LRR-VCSNet框架如图1所示。每个视频被划分为多组图像序列,每组图像序列包含一个关键帧和多个非关键帧,关键帧的测量率远高于非关键帧的测量率。通过同时参考前向关键帧与后向关键帧,LRR-VCSNet一次恢复一组图像序列。
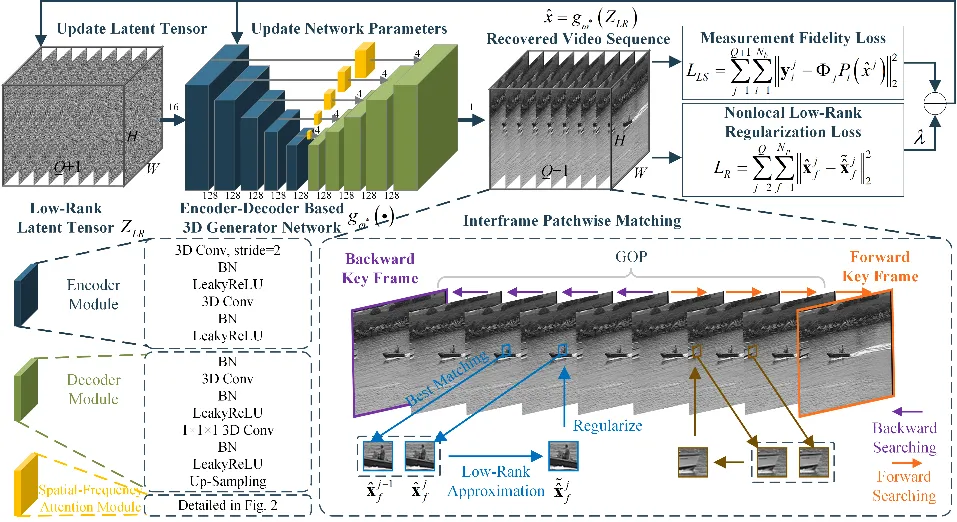
图1 提出的LRR-VCSNet示意图
框架包含初始重构过程与增强重构过程,其中初始重构过程利用DIP探索图像序列的时空相关性,实现图像序列的初始重构,增强重构过程进一步利用图像序列的时间冗余来增强重构效果。LRR-VCSNet在隐空间中利用低秩隐张量实现对图像序列的全局低秩正则,除此之外,在增强重构过程中进一步利用帧间低秩逼近来实现逐帧的非局部低秩正则,提升非关键帧的恢复效果。此外,采用空频注意力模块改进网络架构,进一步提升生成网络对低级统计信息的捕获能力,更好地探索DIP实现视频压缩感知重构。空频注意力模块如图2所示。
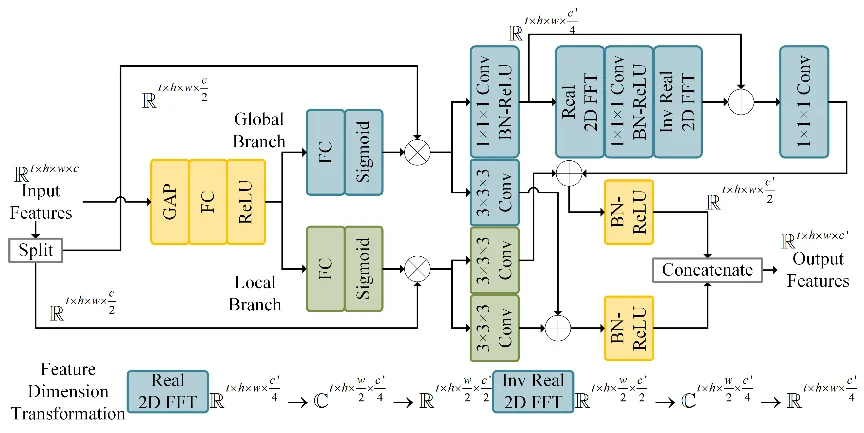
图2 空频注意力模块示意图
3.实验分析
本文在六个标准CIF视频上测试了性能。表1、表2分别为所提框架与当前主流图像、视频CS方法的性能对比。图3、图4分别为所提框架与当前主流图像、视频CS方法的视觉效果对比。本文提出的框架与当前主流的图像和视频CS方法相比都取得了良好的性能。
表1 不同深度学习图像CS方法与提出的LRR-VCSNet
在六个CIF视频前两组图像序列上的性能对比
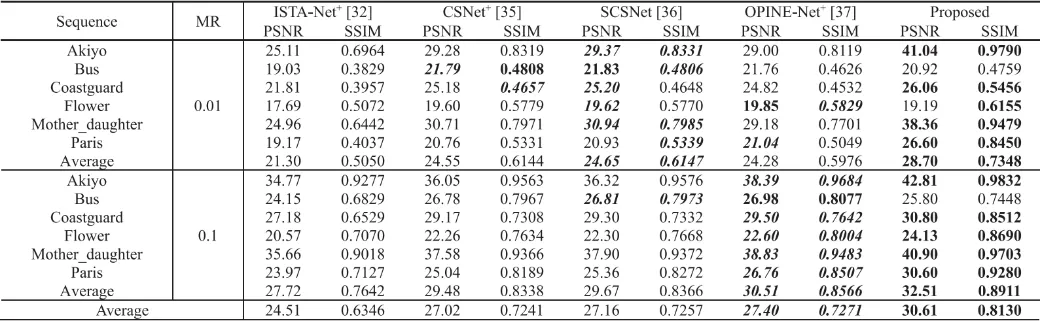

图3 测量率为0.1时视频序列Mother_daughter第16帧的视觉效果对比
表2 不同视频CS方法与提出的LRR-VCSNet在六个CIF视频前两组图像序列上的性能对比
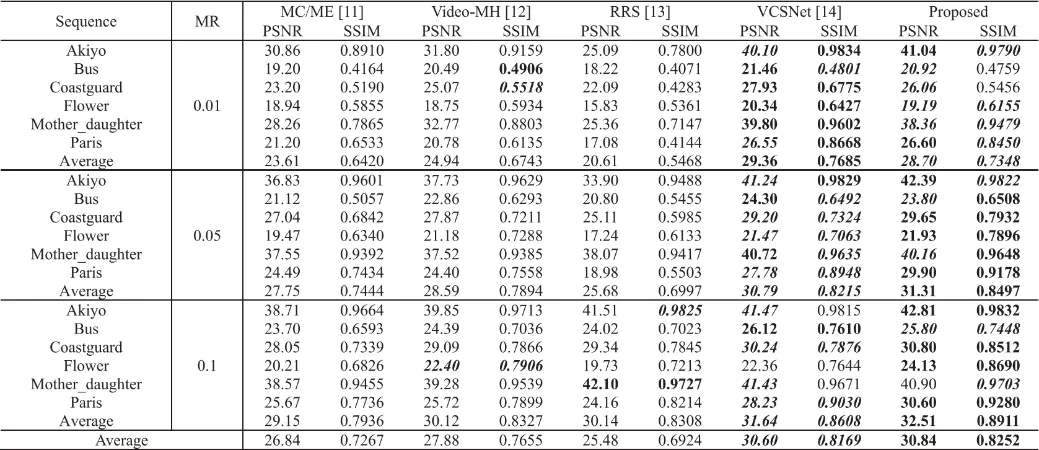

图4 测量率为0.1时视频序列Flower第10帧的视觉效果对比

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东

微信扫一扫
关注该公众号
 京公网安备11010802017125号
京公网安备11010802017125号