
【论文导读】2024年论文导读第二十二期
【论文导读】2024年论文导读第二十二期
CCF多媒体专委会 2024年11月05日 09:40 北京


论文导读
2024年论文导读第二十二期(总第一百一十三期)
目 录
|
1 |
Unleashing Knowledge Potential of Source Hypothesis for Source-Free Domain Adaptation |
|
2 |
Cross-Domain Detection Transformer Based on Spatial-Aware and Semantic-Aware Token Alignment |
|
3 |
Improving Multi-Person Pose Tracking With a Confidence Network |
|
4 |
UniMF: A Unified Multimodal Framework for Multimodal Sentiment Analysis in Missing Modalities and Unaligned Multimodal Sequences |
|
5 |
Online Handwritten Chinese Character Recognition Based on 1-D Convolution and Two-Streams Transformers |
01
Unleashing Knowledge Potential of Source Hypothesis for Source-Free Domain Adaptation
作者:
胡冰玉1,刘嘉威*1,郑可成2,查正军1
单位:
中国科学技术大学1,浙江大学2
邮箱:
hby0728@mail.ustc.edu.cn,
jwliu6@ustc.edu.cn,
zkcys001@mail.ustc.edu.cn,
zhazj@ustc.edu.cn
论文:
https://ieeexplore.ieee.org/document/10319072
发表期刊:TMM2023
*通讯作者
1.研究背景
无监督域自适应旨在将模型从有标签的源域迁移至无标签的目标域。现有方法虽已取得优异表现,但依赖源域数据的访问,而这一需求在隐私保护的背景下可能难以实现。因此,研究者们开始探索源数据无关的域自适应方法。目前的主流方法基于假说迁移学习,即冻结源分类器并训练目标域特征提取器,以学习与源特征分布对齐的目标特征。但固定源分类器在处理分布差异较大样本时,可能无法准确识别边界附近的样本,导致分类性能的下降。为此,本文提出了基于Transformer的完备源分类假说迁移方法,深入挖掘源模型的语义知识,探索目标域数据的内在结构,通过揭示源域和目标域数据间的潜在联系,促进了深层次的知识迁移。
2.研究方法
本文提出的模型框架如图1所示。首先,本文深入研究了跨不同Transformer层的分类表示元之间的相关性,揭示了预训练源模型中隐藏的识别相关权重,并构建了完备源分类假说空间。如图2所示,可以观察到前11层的分类表示元之间存在高度相关性,而其他表示元随着网络加深相关性不断增加。这一观察结果表明,最后一层的参数在汇聚分类表示元内分类所需的信息方面发挥着重要作用。因此,本文尝试固定更多的源域权重来构建完备的源分类空间。通过将目标域特征对齐到这个全面的分类空间,本文的模型促进了更广泛的与识别相关的知识迁移到目标域。此外,本文引入了一个显著表示元扩展模块,通过在表示元之间传播显着信息来捕获目标域特定的辨别线索,这一机制丰富了模型理解和整合目标特定细微差别的能力。具体地,该模块通过动态识别最为显著的嵌入特征,并有选择地抑制这些特征的更新,从而促进其他未被充分利用的嵌入特征得到进一步的学习和优化,提取更多目标域数据内在语义信息。

图1 基于Transformer的完备源分类假说迁移模型
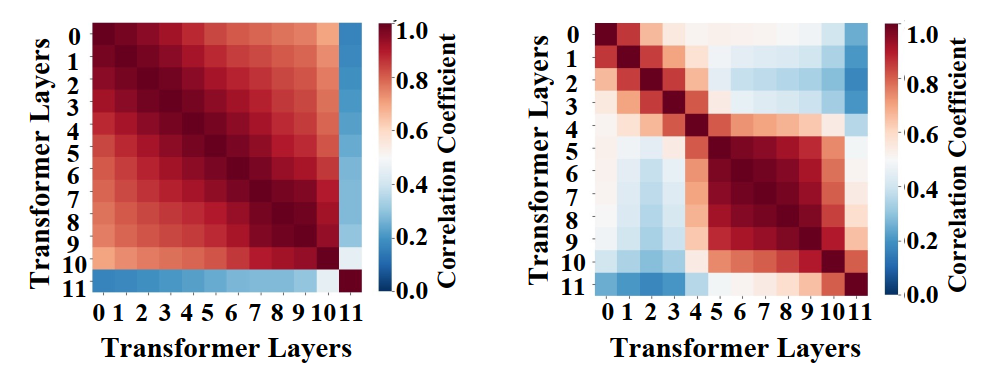
图2 跨不同Transformer层分类表示元和其他表示元的相关性
3.实验分析
为了验证所提方法TagSHOT的性能,本文基于两种Transformer模型,即ViT-S、ViT-B,在三种不同规模的数据集Office-31、Office-Home和VisDA-C上分别进行了实验。实验结果如表1-3所示,TagSHOT在所有数据集上的表现均优于现有方法。此外,以Office-Home中Art域迁移到Product域验证场景为例,图3展示了源域特征和目标域特征t-SNE可视化,其中Source Only为没有进行学习的源模型,SHOT为同时期最优模型。从实验结果可以看出,所提方法TagSHOT可以实现更好的特征对齐,显著提升了模型迁移的效果。
表1 所提出的方法与现有方法在Office-31数据集上的性能比较
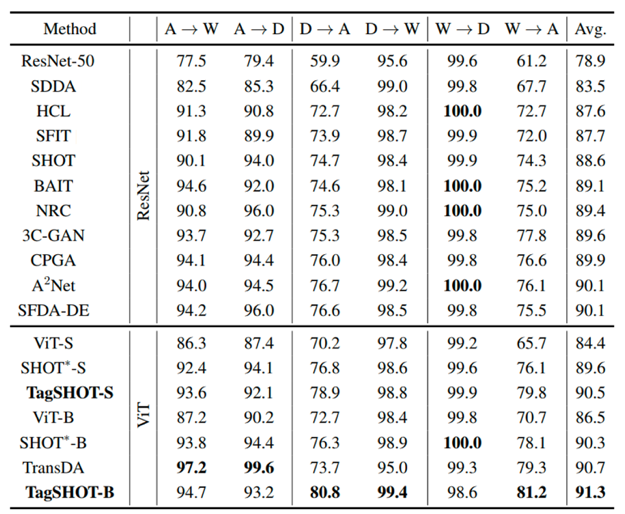
表2 所提出的方法与现有方法在Office-Home数据集上的性能比较
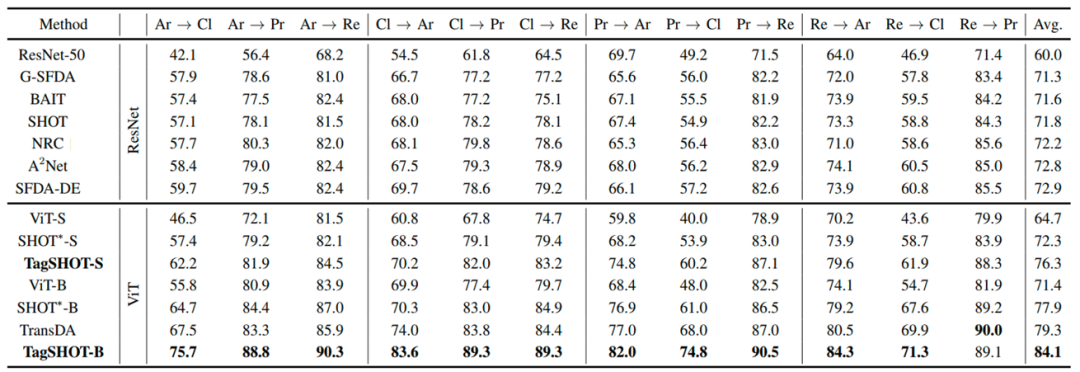
表3 所提出的方法与现有方法在VisDA-C数据集上的性能比较
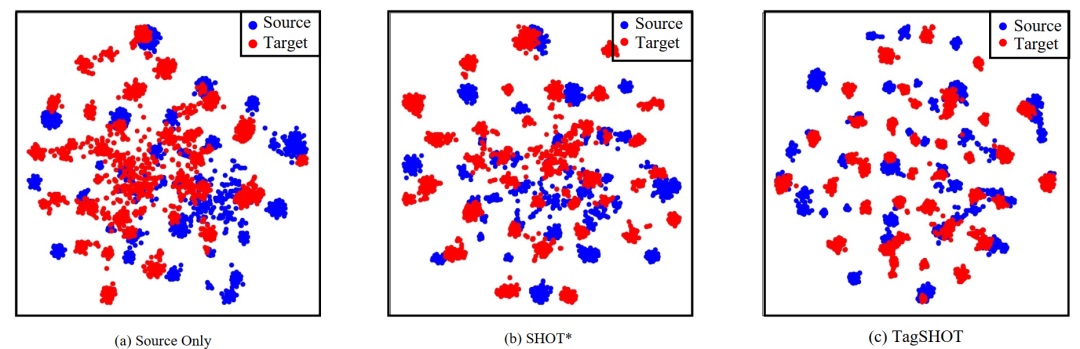
图3 源域特征和目标域特征的t-SNT可视化
02
Cross-Domain Detection Transformer Based on Spatial-Aware and Semantic-Aware Token Alignment
作者:
邓金红1,张潇月1,李文1,段立新1,徐东2
单位:
1电子科技大学, 2香港大学
邮箱:
jhdengvision@gmail.com,
xzhangeo@connect.ust.hk,
liwen@uestc.edu.cn,
lxduan@uestc.edu.cn,
dongxu@hku.hk
论文:
https://ieeexplore.ieee.org/document/10310154
发表期刊:TMM2023
论文介绍
目标检测作为计算机视觉基础感知任务之一,具有重要的实际应用价值,对人工智能系统落地应用十分关键。然而,当前数据驱动的深度目标检测问题经常遇到领域差异问题,即将源域训练的目标检测器应用到新的领域(目标域)会有严重的性能下降。因此,跨域目标检测模型被提出来解决此问题,传统的跨域目标检测模型主要研究基于卷积神经网络的目标检测模型,对基于Transformer架构的目标检测模型(即DETR)研究较少。因此,本文主要针对DETR目标检测模型探索其跨域检测能力,提出空间感知和类别感知的词元(Token)对齐方法,学习领域不变的词元表示,实现 Transformer 架构检测器知识从源域到目标域的有效迁移。
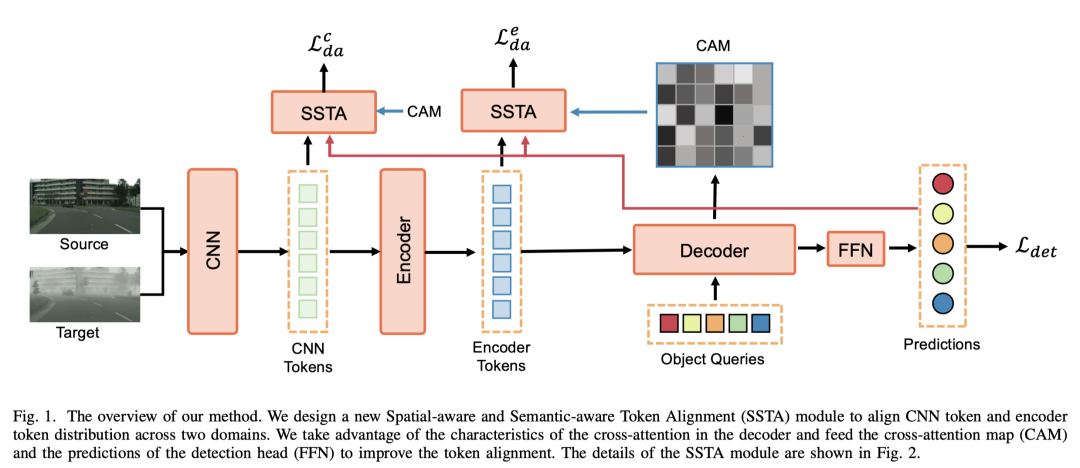
图1 整体架构图
整体架构如图1所示,我们利用 DETR 中使用的交叉注意 (Cross-attention) 特性,新开发了两种策略,即空间感知词元对齐和语义感知词元对齐来指导特征的跨领域对齐。在DETR中,解码器的交叉注意力机制计算 Object Query到编码器输出的交叉注意力从而中聚合信息用于最终的分类和回归预测。在此过程中,为了准确检测目标,只需要注意图像词元其中的一小部分。对于空间感知的词元对齐(图2右),我们可以从交叉注意力图(cross-attention map, CAM)中提取信息,根据每一个词元和 Object Query 的注意力大小来调整分布对齐的强度。对于语义感知的词元对齐(图2左),我们将类别信息注入到交叉注意图中并构建领域嵌入来指导多类领域鉴别器的学习,从而在整个适应过程中建模类别关系并实现类别级对齐。

图2 方法细节图
本论文提出的方法在多个场景中进行验证,包括晴天到雾天、合成到真实、不同场景差异、相机视角差异等。实验的结果表明(如表1所示,其为晴天到雾天的 Cityscapes to Foggy Cityscapes结果),我们的方法相比于未迁移的模型(Source)提升了16.8% mAP,极大地提升了模型在目标域上的检测性能,验证了DETR检测器的跨域检测能力。此外,相比以前的跨域目标检测方法也具有较大的提升,证明了所提方法的有效性。Transformer作为当前先进的深度学习模型架构,具有统一多模态输入的能力,本论文对 DETR 目标检测器的可迁移性的探索,可为未来多模态大模型的可迁移性提供支撑。
表1 从晴天到雾天的实验结果

03
Improving Multi-Person Pose Tracking With a Confidence Network
作者:
傅泽华†1,2,左文航†1,胡征慧2,刘庆杰*1,2,王蕴红1,2
单位:
1虚拟现实技术与系统国家重点实验室,北京航空航天大学
2北京航空航天大学杭州创新研究院
邮箱:
zehua_fu@buaa.edu.cn,
qingjie.liu@buaa.edu.cn,
zhenghuihu2021@buaa.edu.cn,
zuowenhang@gmail.com,
yhwang@buaa.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10310126
发表期刊:TMM2023
*通讯作者
†共同一作
1.研究背景
多人姿态跟踪是计算机视觉中被广泛研究的问题,在人体行为理解和场景分析领域中具有广泛的应用场景,如人机交互、视频监控、动作识别、体育视频分析等。尽管现有的基于自顶向下框架的多人姿态跟踪方法已经取得了一定的成果,但是仍然存在以下问题:一方面,关节点识别的准确性直接影响着多人姿态跟踪性能,而现有方法仅关注于关节点位置识别准确性的研究,却忽略了对关节点可用性识别的探索。该类方法仅使用关节点位置概率为依据,通过阈值卡控进行不可用关节点过滤,在遮挡以及帧模糊情况下容易产生关节点错检测和漏检测。另一方面,现有方法的跟踪方式过于依赖行人检测的结果。该类方法在行人检测基础上进行帧间匹配,当行人检测出现漏检时,容易导致跟踪轨迹断裂或抖动。此外,这种基于检测的跟踪方式无法重新识别曾丢失视野的行人轨迹。
2.研究方法
本文针对现有基于自顶向下框架的多人姿态跟踪方法中存在的上述难点进行研究。针对关节点识别中出现的错检测和漏检测问题,从空间信息增强的角度提出了一种基于关节点置信度网络的多人姿态跟踪方法,如图1所示。本文设计的关节点置信度网络利用了人体全局空间结构信息获取关节点位置以及关节点置信度。对于关节点置信度,本文在原有位置概率的基础上增加了可用性建模,有效解决了关节点错检测和漏检测问题,进而提高跟踪性能。针对现有方法过于依赖行人检测结果的问题,本文从时序信息增强的角度提出了一个基于时序追踪模型的多人姿态跟踪方法。如图2所示,时序追踪模型包含三个模块:匹配模块、行人检索模块和边框找回模块。匹配模块用于进行相邻帧的轨迹分配。行人检索模块利用历史轨迹信息重新识别丢失视野的行人身份ID。边框找回模块通过光流信息生成人体光流姿态缓解检测器漏检测问题。相比于现有方法,本文设计的时序追踪模型利用了时序信息,不仅缓解了漏检测问题,还能重新识别曾丢失轨迹的行人身份ID,进而实现更鲁棒的跟踪。
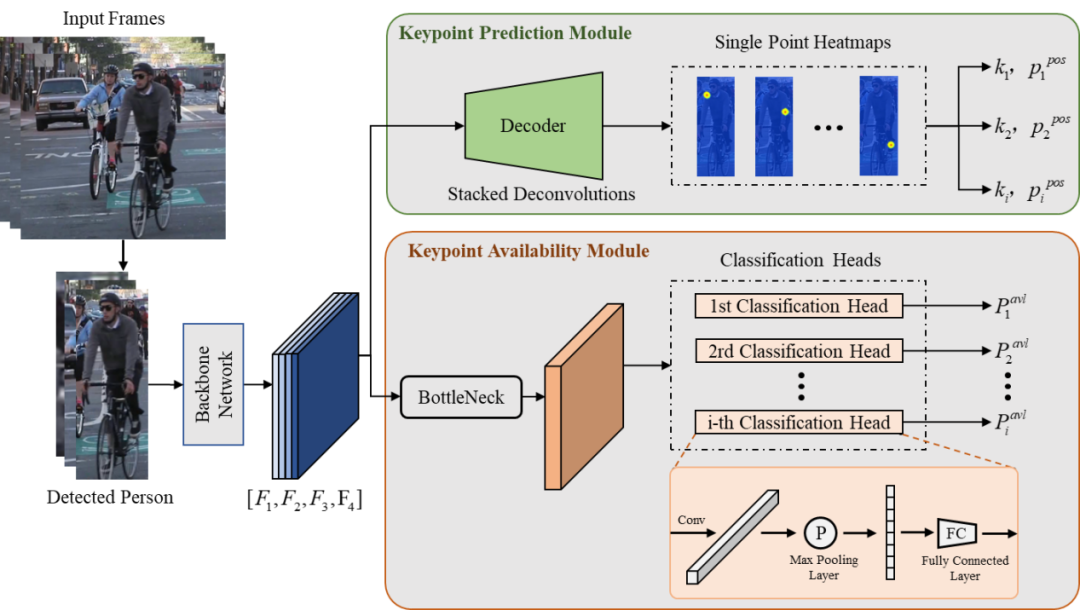
图1 本文提出的关节点置信度网络示意图
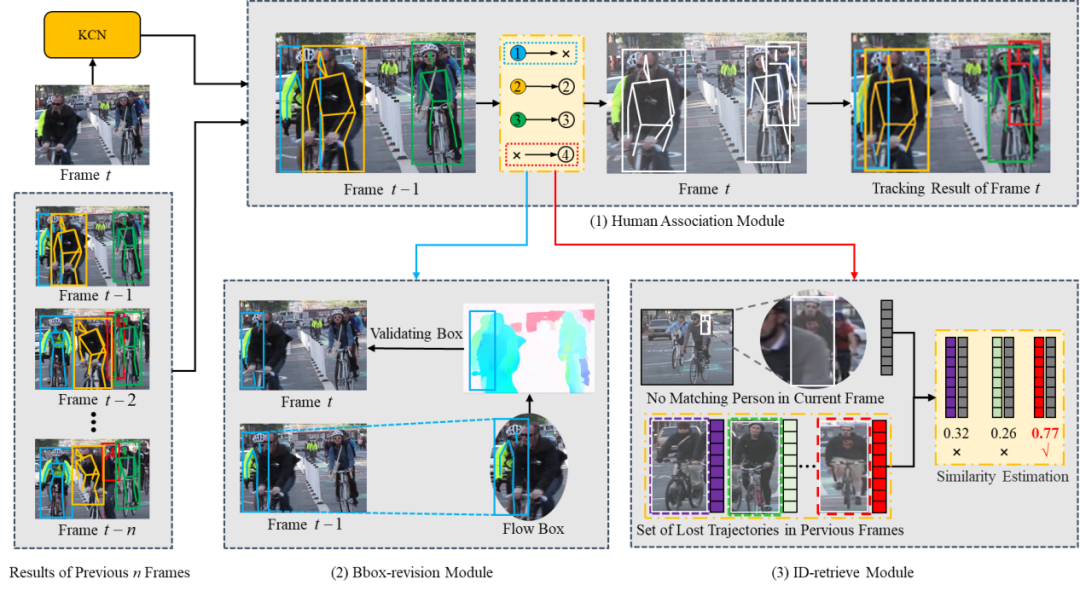
图2 基于时序追踪模型的多人姿态跟踪方法框架图
3.实验分析
本文同时在PoseTrack 2017 和PoseTrack 2018 两个多人姿态跟踪数据集上对提出的方法进行了性能评估。表1为多人姿态估计方法在PoseTrack验证集上的的性能比较,表2展示了本文方法在PoseTrack 验证集的MOTA(%)指标性能对比,从表中可以看出,本文的方法均达到了先进水平,并在PoseTrack 2018数据集上和LDGNNTrack并列第一。表3为在PoseTrack 2018验证集上使用不同的姿态估计网络(HRNet、Hourglass和Pose_ResNet),并在此基础上增加关节点置信度模块后的性能对比。从表中可以看出,在增加了置信度模块后,HRNet、Hourglass和Pose_ResNet在MOTA指标上均有性能提升。在置信度模块的加持下,HRNet提升了7.0%,Pose_ResNet提升了4.4%,Hourglass提升了3.6%。由此证明关节点置信度模块具有通用性和有效性。
表1 多人姿态估计方法在PoseTrack验证集上的的性能比较(mAP %)
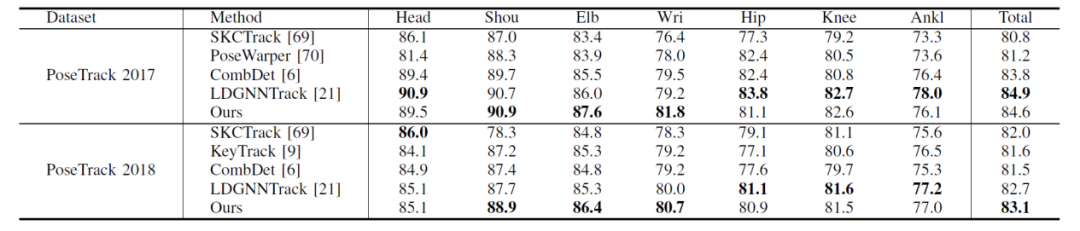
表2 多人姿态跟踪方法在 PoseTrack验证集上的的性能比较(MOTA %)
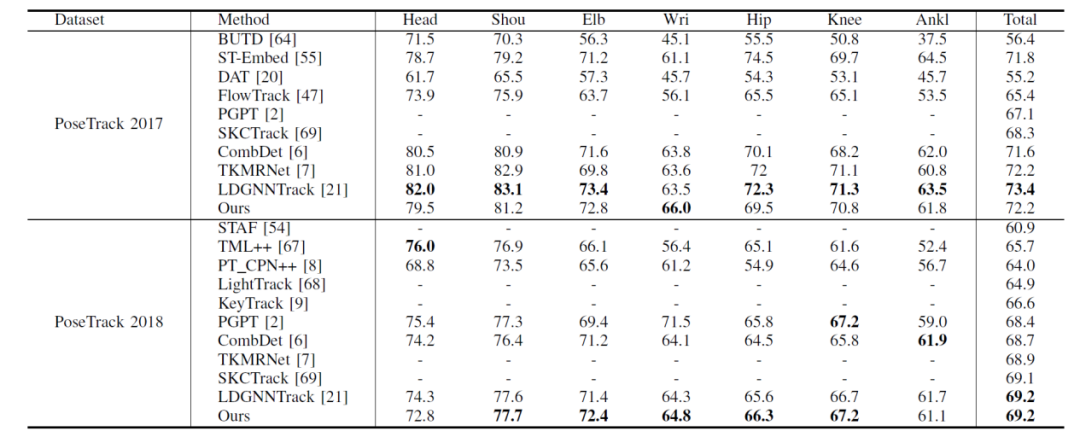
表3 KCN 方法在PoseTrack 2018 验证集上通用性分析(MOTA %)
04
UniMF: A Unified Multimodal Framework for Multimodal Sentiment Analysis in Missing Modalities and Unaligned Multimodal Sequences
作者:
宦若虹,钟国伟,陈朋,梁荣华*
单位:
浙江工业大学计算机科学与技术学院
邮箱:
huanrh@zjut.edu.cn
guoweizhong@zjut.edu.cn
chenpeng@zjut.edu.cn
rhliang@zjut.edu.cn
论文:
https://ieeexplore.ieee.org/document/10339893
代码:
https://github.com/gw-zhong/UniMF
发表期刊:TMM2023
*通讯作者
1.引言
多模态情感分析(Multimodal Sentiment Analysis,MSA)是一种将语言、音频、视觉等多种模态进行融合的情感分析方法。由于不同模态往往可以捕捉到不同层面的情感信息,因此多模态情感分析可以更全面地理解人类情感。然而,现有的大多数方法仅专注于解决模态缺失或模态序列未对齐这二者中的某一个问题。尽管,如今已有少数方法能同时处理二者问题,但它们往往需要多阶段训练、额外的数据输入或复杂的特征提取及重构网络。因此,为了以轻量化的方式同时解决上述二者问题,本文提出了一种统一的多模态框架UniMF,通过注意力机制掩码的方式分别完成缺失模态的解码和多模态序列的融合。
2.方法介绍
本文提出的UniMF整体框架如图1所示,主要包括翻译模块(Translation Module)和预测模块(Prediction Module)。以缺失视觉模态为例,在翻译模块中首先利用已有的语言、音频模态的信息,通过多模态生成Transformer(Multimodal Generation Transformer,MGT)解码出伪视觉模态,然后再在预测模块中通过多模态理解Transformer(Multimodal Understanding Transformer,MUT)将三者进行融合,得到情感分析结果。
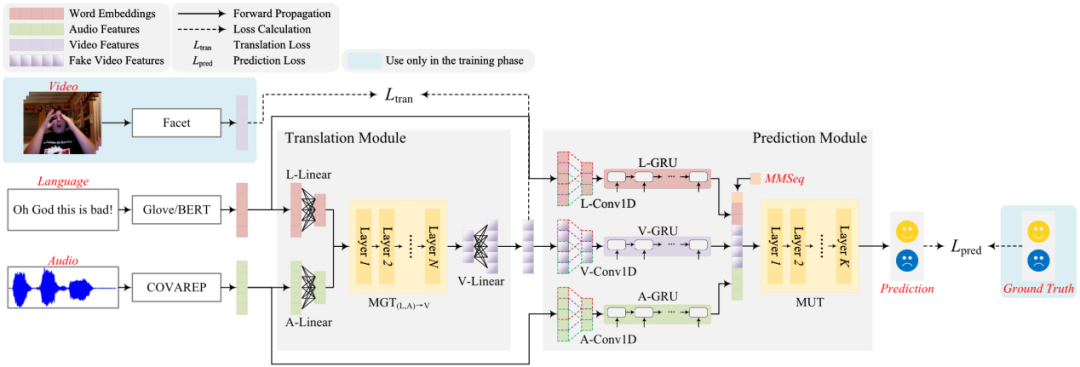
图1 UniMF框架
1)多模态生成Transformer(MGT)
多模态生成Transformer主要由多模态生成掩码(Multimodal Generation Mask,MGM)注意力机制组成。如图2所示,同样以缺失视觉模态为例,我们为注意力矩阵加上模态翻译方向特定的掩码矩阵,从而使得已有模态的编码和缺失模态的解码可以在一次注意力计算中完成。此外,我们还引入了随机初始化的[multi]字符,以充当编码和解码之间的桥梁,它既编码了已有模态的信息,又充当着解码缺失模态时的起始符。总而言之,对于不同的模态缺失情形,我们共设计了9类MGM,如图3所示。
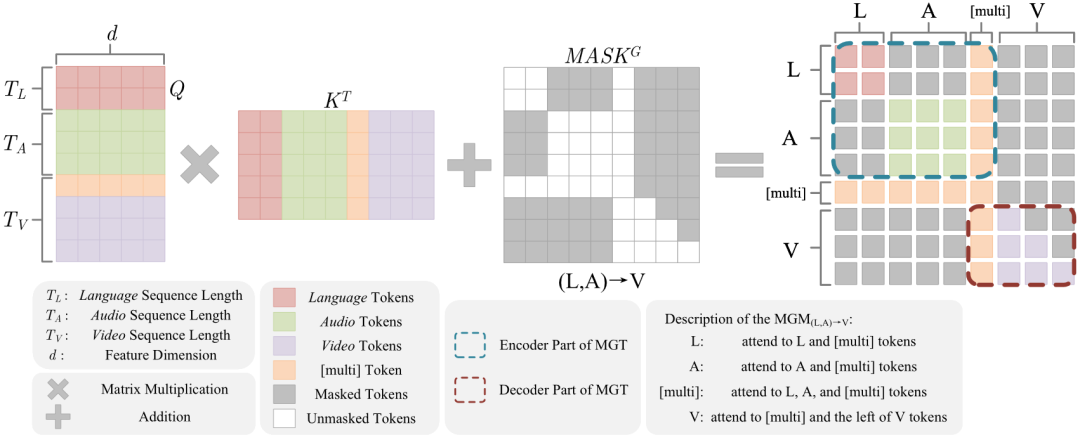
图2 翻译方向为(L,A)→V的MGM
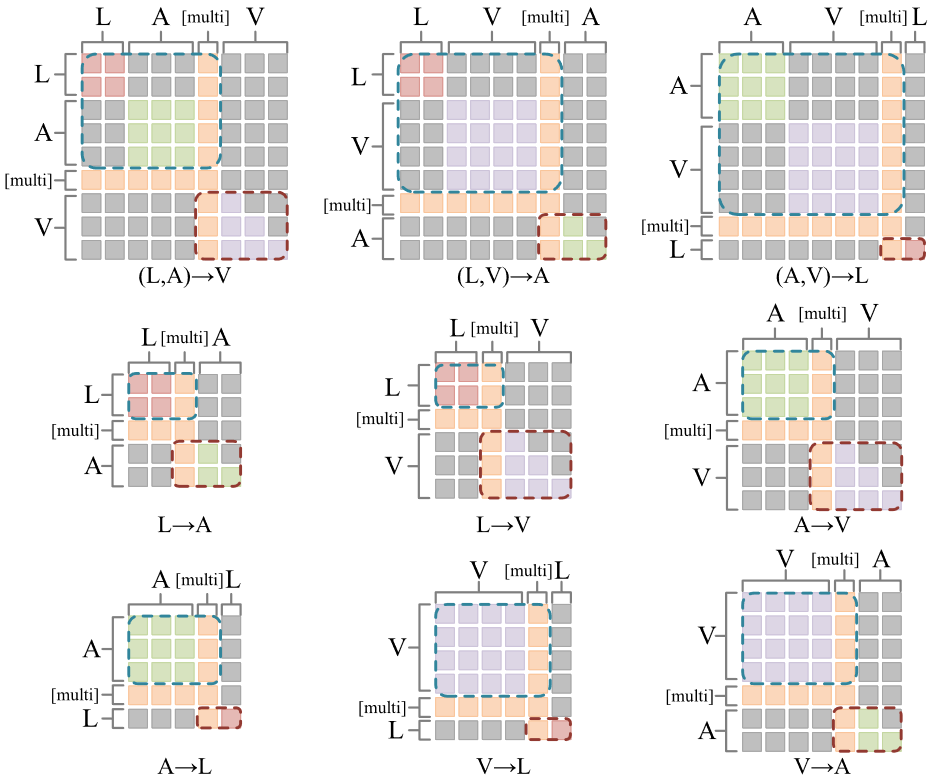
图3 不同翻译方向的MGM
1)多模态理解Transformer(MUT)
多模态理解Transformer主要由多模态理解掩码(Multimodal Understanding Mask,MUM)注意力机制组成。如图4所示,我们为注意力矩阵加上特定的掩码,从而使每个模态能够在一次注意力计算中同时完成模态内和模态间的交互。为了更好地得到多模态表征,我们还引入了一个随机初始化的序列MMSeq,用以汇聚所有模态的信息。
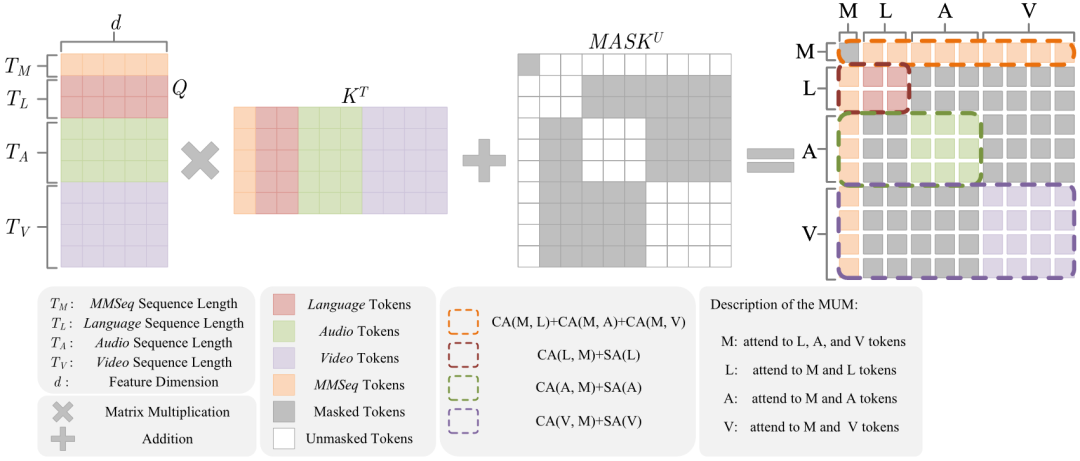
图4 MUM
3.实验分析
本文在CMU-MOSI、CMU-MOSEI等多个MSA数据集上进行了大量的实验测试和评估。
1)定量分析
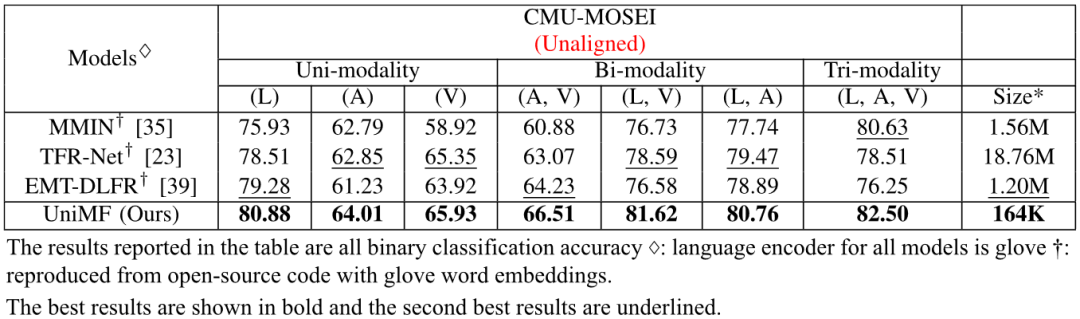
如表1和表2所示,本文所提出的方法UniMF在CMU-MOSI和CMU-MOSEI未对齐的数据集上均能以较少的参数量在各种模态缺失的情形下展现出优异的性能。
表1 CMU-MOSI数据集上的定量结果

表2 CMU-MOSEI数据集上的定量结果
2)定性分析
如图5所示,自上而下分别为UniMF、TFR-Net和EMT-DLFR的多模态联合表征可视化结果。从图中可以看出,本文所提出的UniMF在各类缺失模态的情形下所得到的联合表征都更加鲁棒。
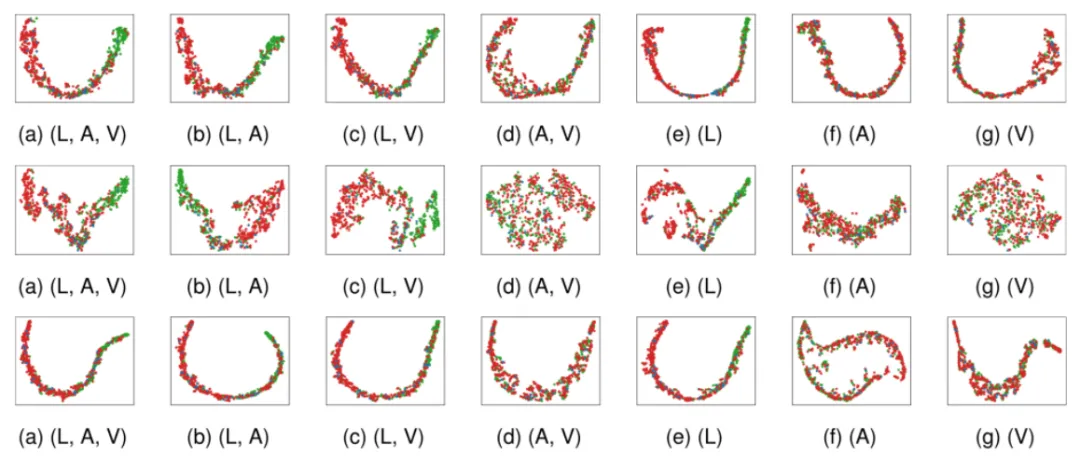
图5 多模态联合表征的可视化散点图
05
Online Handwritten Chinese Character Recognition Based on 1-D Convolution and Two-Streams Transformers
作者:
陈毅红1,郑浩1,李艳春2*,欧阳万里3,朱江2
单位:
西华师范大学,湘潭大学,悉尼大学
邮箱:
cyhswpi@126.com,
zhenghao9812@gmail.com,
ycli@xtu.edu.cn,
zhu_jiang@xtu.edu.cn,
wanli.ouyang@sydney.edu.au
论文:
https://ieeexplore.ieee.org/document/10342828
发表期刊:TMM2023
*通讯作者
1.研究背景
手写字符识别(HCR)是通过将手写字符映射到机器可输入文本的过程,从而实现自动文本识别。HCR已在许多场景中得到应用,如智能手机手写输入、邮件分拣和表单处理。在过去的二十年中,HCR 取得了显著的进展。然而,HCR仍然面临诸多挑战,主要源于类别数量庞大、许多相似汉字(如“日”和“曰”、“士”和“土”)以及不正确的笔画顺序。根据收集和存储方法,HCR可分为两种:联机手写汉字和脱机手写汉字。脱机手写汉字识别(OFHCCR)是通过相机或扫描仪获取手写字符的图片并进行识别,而联机手写汉字识别(OLHCCR)则是通过采样书写过程中笔尖位置获得轨迹坐标来进行识别。由于笔画顺序的优势,OLHCCR 能够取得更好的识别效果。现有的联机手写汉字识别方法仅依赖于书写汉字的时间特征或空间特征,然而在处理笔画顺序不正确的字符时识别准确率较低。具体来说,图1展示了同一个汉字“七”的两种不同笔画顺序。两个红色圆圈分别表示两条轨迹的起始位置,而箭头则表示书写轨迹的方向。尽管这两个字的空间特征相似,但它们的笔画顺序却存在显著不同。笔画顺序作为时间特征的一部分,如果仅依赖笔画顺序提取字符特征,将难以准确识别笔画顺序不正确的字符。因此,本文提出了基于一维卷积和Two-Streams Transformers的识别模型(C-TST),C-TST 通过并行计算的双流架构,从预处理后的字符轨迹序列和字符图像中提取丰富的时间特征和空间特征,从而实现快速的识别速度和高准确率。

图1 标准字符和非标准字符的比较 (a)笔画顺序正确的字符 (b)笔画顺序不正确的字符
2.方法概述
在图2中展示了C-TST结构。C-TST由1-D Transformer和一个Vision Transformer组成,其中1-D Transformer包含一个一维卷积层和Transformers。C-TST通过1-D Transformer和Vision Transformer分别从字符轨迹和字符图像中提取时间特征和空间特征,实现了显著的识别精度与速度提升,兼具联机和脱机手写汉字识别的优势。对于1-D Transformer,首先,将手写轨迹序列的每个二维坐标预处理为一个八维特征向量,以提高输入数据的信息密度。然后,通过一维卷积层获得字符的浅层时空特征。将浅层时空特征进行分组,并嵌入位置,以满足Transformer的多头注意力计算条件。然后,通过使用Transformers从这些嵌入位置的浅层时空特征中进一步捕获时空特征。对于Vision Transformer,我们首先将原始的手写轨迹序列转换为灰度字符图像作为其输入。灰度字符图像不仅具有旋转不变性的优势,还包含字符的空间特征。Vision Transformer直接将灰度字符图像作为其输入,无需经过2-D CNN复杂的特征捕获过程。因此,空间特征通过Vision Transformer直接从灰度字符图像中捕获。捕获的时间和空间特征融合为时空特征,以实现高识别准确率。此外,C-TST实现了更快的识别速度,因为一维Transformer和Vision Transformer是并行计算的。C-TST通过融合联机手写汉字捕获的时间特征和空间特征,在ICDAR-2013数据集上达到了97.90%的识别准确率,在IAHCC-UCAS2016上达到了97.38%的领先识别准确率。
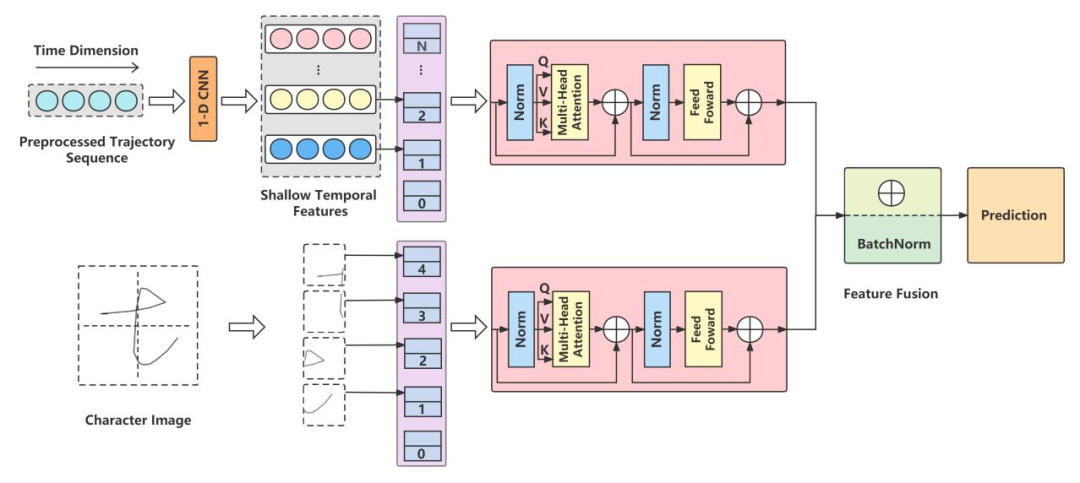
图2 C-TST的整体架构
3.实验结果
为了验证C-TST在识别非标准字符方面的性能,我们将其与1-D CNN和PyGT进行了对比。具体而言,我们从ICDAR-2013数据集中随机选取了300个非标准字符样本作为测试集。在表1中,展示了1-D CNN、PyGT-L和C-TST在这个测试集上的错误率。结果显示,1-D CNN的错误率显著高于C-TST和PyGT-L,而C-TST的错误率略低于PyGT-L。
表 1 PYGT、1-D-CNN和C-TST在非标准字符上的错误率。

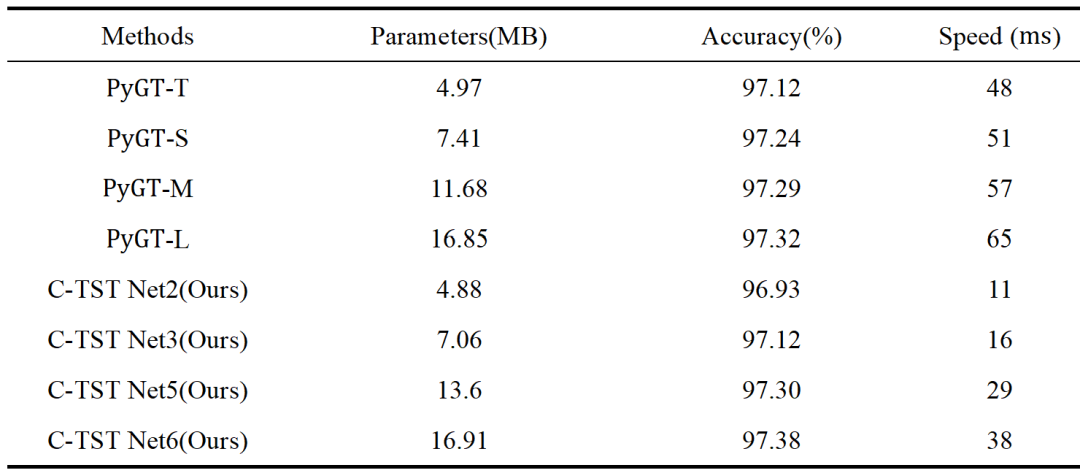
PyGT在OLHCCR领域中被认为是表现最优秀的模型。因此,本研究提出的C-TST模型与PyGT进行了对比,以评估C-TST的性能优势。比较结果如表2所示。当参数较少时,C-TST比PyGT具有更高的识别速度,而当参数较多时,C-TST比PyGT具有更高的识别速度和更高的准确率。
表2 C-TST和PyGT在IAHCC-UCAS2016上的性能比较
为了证实C-TST模型的鲁棒性,本文在SCUT-COUCH2009数据集的五个子集上进行了实验。在表3中,我们展示了C-TST在SCUT-COUCH2009各个子集上的识别准确率。与MQDF模型相比,实验结果显示了C-TST在整个SCUT-COUCH2009数据集上的优越性能,特别是在处理Pinyin和Letter这两个子集时的显著优势。
表3 C-TST在SCUT-COUCH2009上的实验结果


编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号