
【论文导读】2024年论文导读第二十三期
【论文导读】2024年论文导读第二十三期
CCF多媒体专委会 2024年11月19日 20:02 北京


论文导读
2024年论文导读第二十三期(总第一百一十四期)
目 录
|
1 |
Highly Transferable Diffusion-based Unrestricted Adversarial Attack on Pre-trained Vision-Language Models |
|
2 |
Dual Noise Elimination and Dynamic Label Correlation Guided Partial Multi-Label Learning |
|
3 |
AdaFPP: Adapt-Focused Bi-Propagating Prototype Learning for Panoramic Activity Recognition |
|
4 |
Dual Masked Modeling for Weakly-Supervised Temporal Boundary Discovery |
|
5 |
Reason Generation for Point of Interest Recommendation via Hierarchical Attention-based Transformer Model |
01
Highly Transferable Diffusion-based Unrestricted Adversarial Attack on Pre-trained Vision-Language Models
基于扩散模型的多模态迁移攻击
作者:
徐文卓1#,陈凯1#,高子怡1,魏志鹏1,陈静静1*,姜育刚1
单位:
1复旦大学视觉与学习实验室
邮箱:
21210240381@m.fudan.edu.cn,
kchen22@m.fudan.edu.cn,
ziyigao23@m.fudan.edu.cn,
zpwei21@m.fudan.edu.cn,
chenjingjing@fudan.edu.cn,
ygj@fudan.edu.cn
论文:
https://dl.acm.org/doi/pdf/10.1145/3664647.3681538
发表会议:ACM MM 2024
#共同作者
*通讯作者
1.引言
预训练的视觉语言模型(VLM)已经在各种视觉语言任务中表现出卓越的性能。然而,最近的工作表明,VLM极易受到可迁移多模态对抗样本的攻击,这对VLM在现实世界的部署构成了严重的安全风险。图像和文本模态之间的交互已被证明是提高多模态对抗样本迁移性的关键因素,但在现有的多模态迁移攻击中,图像和文本模态之间的交互相当有限。具体来说,这些方法仅仅利用来自文本模态的配对信息作为监督来指导图像模态的对抗方向的优化,并没有充分地建模图像与其对应文本之间的对应关系,这限制了多模态对抗样本的迁移性。考虑到扩散模型中的交叉注意力模块能够促进模态之间的交互,这激发了我们利用扩散模型来丰富图像和文本模态之间信息交互的想法。为解决上述问题,本文提出了一种高度可迁移的无限制攻击框架,称为基于扩散模型的多模态攻击(MDA),通过考虑更多的图像和文本模态之间的融合信息来进一步提高可迁移攻击的性能。具体来说,MDA攻击除了利用对抗文本计算对抗损失之外,还在去噪过程中将对抗文本作为对抗图像生成的指导提示,从而提高多模态对抗样本对不同目标VLM的迁移攻击性能。实验结果表明,MDA生成的多模态对抗样本在不同下游任务的不同VLM之间具有很高的对抗迁移性,大幅超越了之前的方法。
2.方法概述
本文提出的基于扩散模型的多模态攻击(MDA)框架如图1所示,主要由文本模态攻击和图像模态攻击两个过程组成。具体来说,在文本模态攻击中,MDA采用Bert攻击算法生成对抗文本;在图像模态攻击中,MDA首先采用DDIM反演将良性图像映射到扩散模型的潜在空间中,然后迭代优化良性图像对应的潜在空间,使得在对抗文本的指导下去噪重构出的图像能够误导替代VLM。除了利用对抗文本计算对抗损失之外,MDA在去噪过程中还将其作为对抗图像生成的指导提示,丰富了图像和文本模态之间交互的方式,从而增强了对抗迁移性。与现有的多模态迁移攻击方法相比,MDA在扩散模型的潜在空间中进行扰动,而不是直接扰动图像的像素空间,这会导致对抗图像的高层语义失真。为了避免对抗图像的内容结构改变程度太大,MDA还考虑了对扩散模型的自注意力图施加约束。
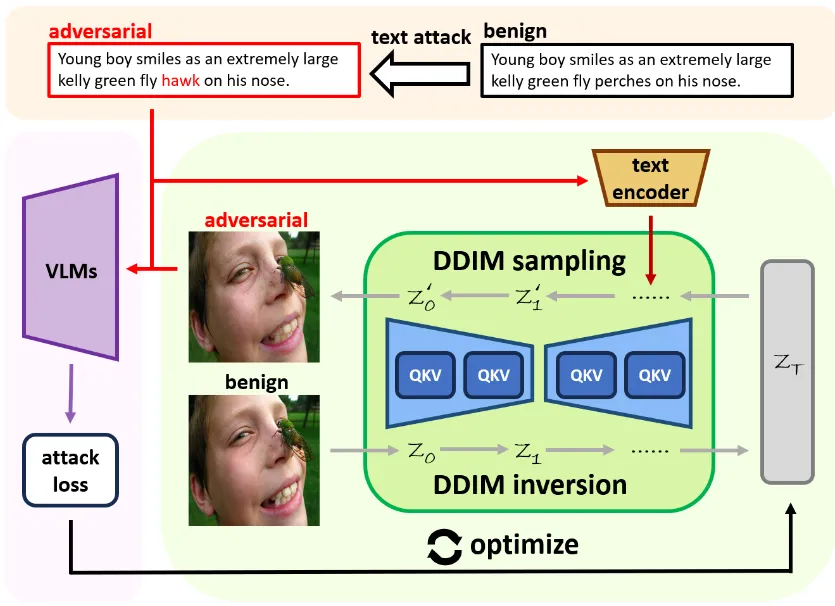
图1 MDA算法框架图
3.实验对比
我们在图像-文本检索、文本-图像检索和视觉蕴含三种下游的视觉-语言任务,Flickr30K和SNLI-VE两个数据集,ALBEF、TCL和CLIP三种不同架构的VLM上将MDA与此前先进的多模态迁移攻击进行了全面的对比,实验结果如表1、表2和图2所示。观察实验数据,我们可以发现MDA在三种视觉-语言任务和两个数据集上均取得了最佳的跨模型架构迁移攻击性能。其中MDA的白盒攻击成功率略低,我们将其归因于MDA较少过拟合于替代模型,从而导致白盒攻击性能较差。
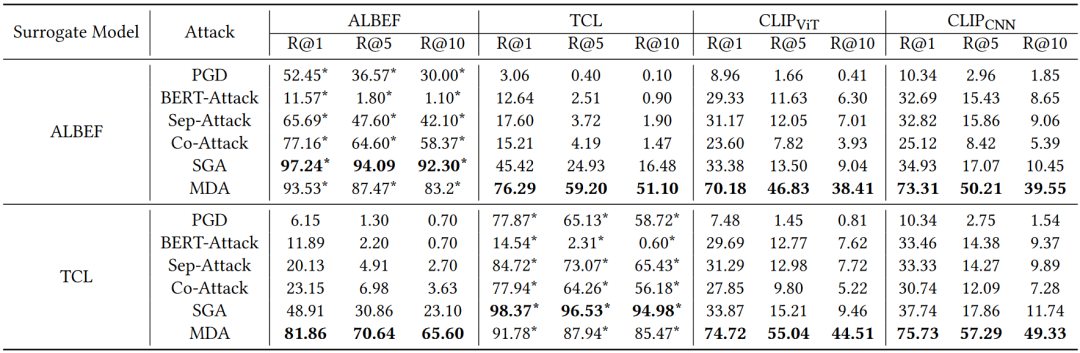
表1 在图像-文本检索任务上Flickr30K数据集的攻击成功率
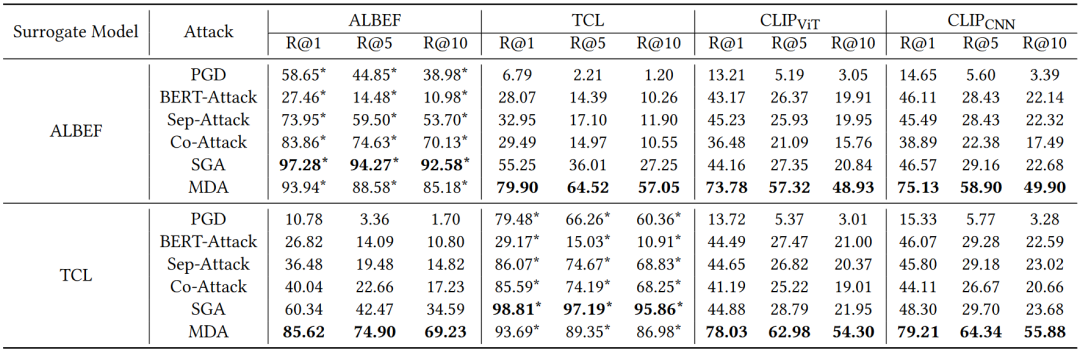
表2 在文本-图像检索任务上Flickr30K数据集的攻击成功率
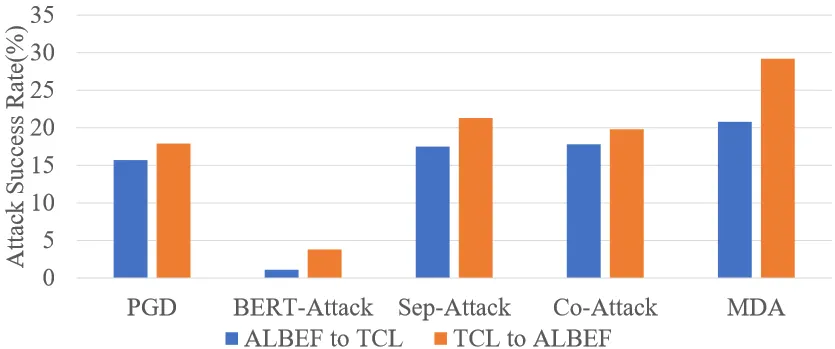
图2 在视觉蕴含任务上SNLI-VE数据集的攻击成功率
02
Dual Noise Elimination and Dynamic Label Correlation Guided Partial Multi-Label Learning
作者:
胡妍,房小兆,康培培,陈永灏,谢胜利
单位:
广东工业大学
邮箱:
huyan515601@163.com,
ppkanggdut@126.com,
xzhfang168@126.com,
yhchengdut@126.com,
shlxie@gdut.edu.cn
论文:
https://ieeexplore.ieee.org/document/10336552
代码:
https://github.com/huyan1998/PML-DNDC.git
发表期刊:TMM2023
1.研究背景
部分多标签学习是一种典型的弱监督学习。每个实例的真实标签都隐藏在候选标签中,无法直接访问。PML的目标是通过使用带有噪声信息的多标签数据集来训练一个模型来预测未知实例的标签。例如在图1中,由于噪声标注器操作粗糙,在候选标签中,“建筑”、“河流”、“云”、“树”与图片相关,而其他标签都是噪声。
尽管部分多标签学习近年来取得了令人鼓舞的进展。然而,在真实场景中,噪声产生的原因是不确定的。标注器可能会产生随机误差,也可能会被实例中的模糊内容误导。这些场景中的任何一种都可能影响模型的性能。因此我们没有只考虑单一噪声源,而是提出了新颖部分多标签新型双噪声消除方法,即同时消除标签噪声和特征噪声。动态标签相关性指导旨在通过动态探索潜在的标签相关性来帮助分类器训练,从而鼓励相关标签获得相似的分类器。在21个合成PML数据集和3个真实PML数据集上进行的大量实验和分析表明,所提出的PML-DNDC优于目前最先进的方法。

2.研究方法
在第一部分中,我们通过矩阵分解将隐藏的真实标签矩阵分解为两个低维矩阵,分别作为实例的压缩矩阵和理想分类器。然后,用这两个分解矩阵来近似候选标签矩阵。这样,通过低重构误差消除了候选矩阵中的噪声标签。在第二部分中,为了探索有助于分类器训练的真值标签,我们同时构造了对偶拉普拉斯矩阵。压缩后的实例矩阵用实例级拉普拉斯矩阵正则化。它保持了与原始特征的局部一致性,同时降低了特征中噪声的影响。设计了动态标签级拉普拉斯矩阵来探索标签之间潜在的相关性,并通过迭代对其进行更新,以保证标签相关性的质量。它使得相关标签对应的分类器是相似的,而不相关的标签将它们的分类器推向相反的方向。最后,我们将这两个压缩矩阵的乘积看作是一个更精确的基真矩阵来训练分类器。
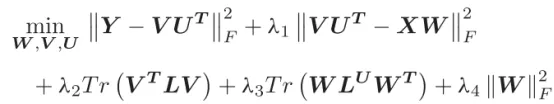
3.实验结果
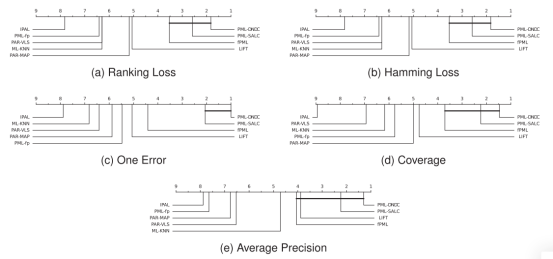
本文共使用了3个真实部分多标签数据集和6个公共多标签数据集。为了更全面地评估模型,我们使用了多标签分类模型常用的五个评估指标:排名损失、汉明损失、一次错误、覆盖率和平均精度。我们进行了120例((21个合成数据集+3个数据集)x 5个指标=120例)的实验,所提出的PML-DNDC在77例中表现最佳,换句话说,PML-DNDC在大多数情况下表现最好。为了进一步显示所提出的PML-DNDC与所有其他方法之间的性能差距,采用了流行的Friedman检验,绘制CD图。从图中可以看出,PML-DNDC在5个评价指标中表现出最好(最低)的平均排名,且PML-DNDC显著优于IPAL、PML-fp、PAR-VLS、ML-KNN、PAR-MAP和LIFT。
03
AdaFPP: Adapt-Focused Bi-Propagating Prototype Learning for Panoramic Activity Recognition
基于适应性双向传播原型学习的全景活动识别方法
作者:
曹美琦,严锐,舒祥波,代广昭,姚亚洲,谢国森
单位:
南京理工大学
邮箱:
cmq123@njust.edu.cn,
ruiyan@nju.edu.cn,
shuxb@njust.edu.cn,
guangzhaodai@njust.edu.cn,
yazhou.yao@njust.edu.cn,
gsxiehm@gmail.com
论文:
https://dl.acm.org/doi/10.1145/3664647.3680755
发表会议:ACM MM 2024
1.论文简介
本文主要聚焦于全景活动识别(PAR)任务。该任务旨在识别全景场景中多人的多粒度行为,包括个体活动、群体活动和全局活动。目前该任务主要面临两个挑战:一是现有方法在训练和推理中过度依赖手动标注的检测框,不利于实际部署;二是直接使用普通探测器检测全景场景中不同大小和存在空间遮挡的多人时,性能受限。具体的,本文 1)提出一个全景自适应聚焦器(PAF),通过对原始检测识别出的物体密集子区域进行综合选择和精细检测,实现对不同大小个体的自适应检测;2)设计一个双向传播原型器(BPP),通过促进个体、群体和全局层面之间的双向信息传播,减轻因个体定位不准确导致的信息损失。本文提出的 AdaFPP 框架通过端到端的方式学习自适应聚焦探测器和多粒度原型,能够联合识别全景活动场景中的个体、群体和全局活动。
2.方法概述
所提出的 AdaFPP 框架如图1所示,它由两个关键组件组成,即全景自适应聚焦器(PAF)和双向传播原型器(BPP)。PAF 旨在解决全景场景中个体的尺寸变化和空间遮挡问题。其实现包括自适应调整原始检测框大小(通过自适应对象调整大小策略 AOR)、选择密集子区域(通过密集区域合并策略 DRM)、对所选子区域进行裁剪并输入检测网络获得细粒度检测以及融合原始检测和细粒度检测得到最终尺寸自适应检测等四个阶段。为减轻 PAF 中不准确定位导致的信息损失,BPP促进不同粒度间的闭环交互和信息一致性,通过个体、群体和全局层面的双向信息传播实现。BPP包含三个统一双向编码(UBE)块,每个 UBE 块包括自底向上编码(UME)和自顶向下编码(CME)两部分。首先进行前向信息传播(个体到群体到全局),然后进行反向信息传播(全局到群体到个体),通过这种双向传播来学习多粒度原型。
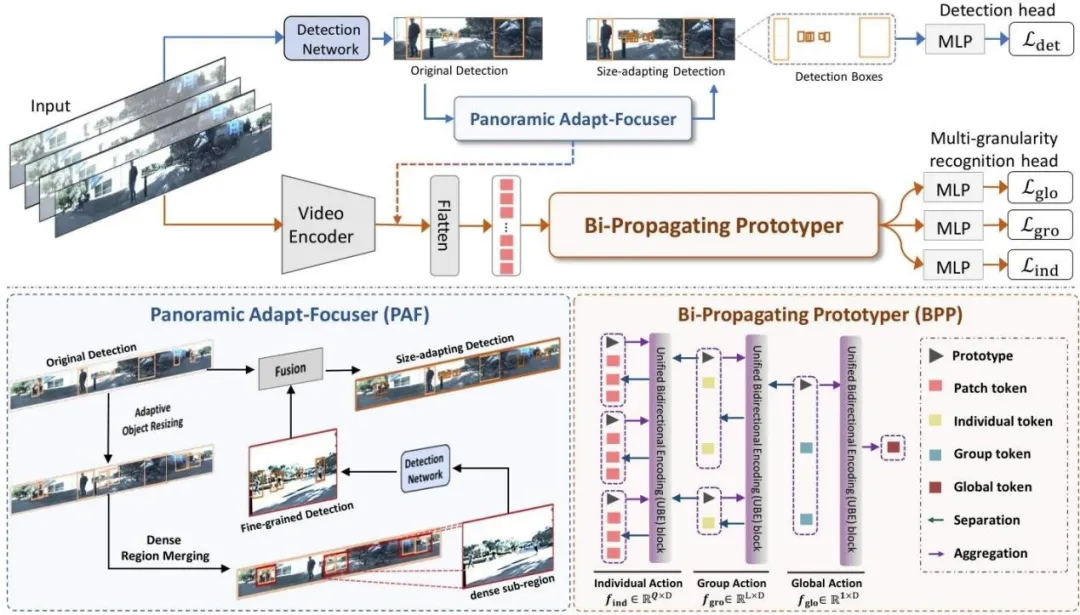
图1 所提出的 AdaFPP 框架
3.实验结果
为综合评估所提方法的性能,在具有挑战性的全景活动识别基准 JRDB - PAR 数据集上进行了实验,实验结果如表1所示。在训练和推理中借助真实标签检测信息得到的结果(标记为灰色)仅作为参考。上标 * 表示我们通过使用真实标签的群体检测而非群体层级检测重现结果。从图中可以看出,与当前在个体和群体活动识别方面的先进方法比较,AdaFPP 不使用真实检测时的为 42.8%,与使用真实检测的 SOTA 方法的(45.6%)相当。使用额外探测器时,AdaFPP 在整体分数上取得了先进性能(为 42.8%),在个体、群体和全局的大部分指标上表现最佳。在三个粒度活动识别上的可视化比较如图2所示。
表1 全景活动识别的性能对比

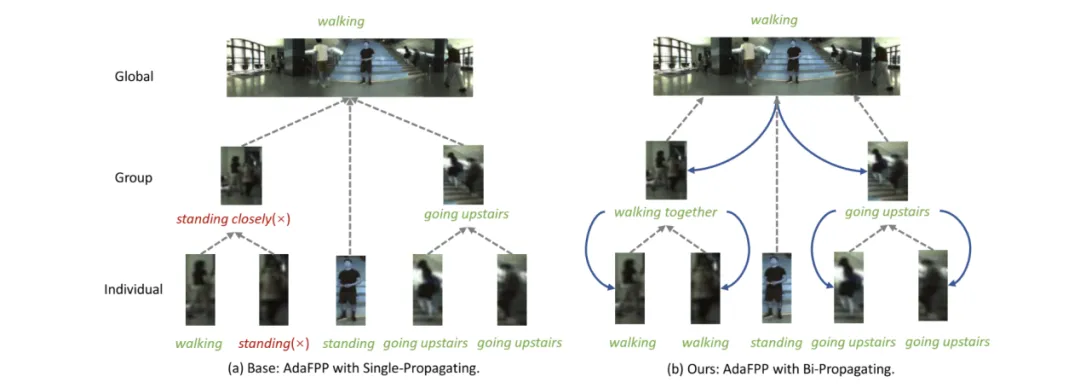
图2 在不同粒度活动识别的可视化结果比较
04
Dual Masked Modeling for Weakly-Supervised Temporal Boundary Discovery
作者:
马钰儿1,刘熠2,王利民3,康文雄1,乔宇4,王亚立2
单位:
1华南理工大学,2中科院深圳先进技术研究院,3南京大学,4上海人工智能实验室
邮箱:
meyuerma@mail.scut.edu.cn,
yi.liu1@siat.ac.cn,
mwang@nju.eud.cn,
auwxkang@scut.edu.cn,
yu.qiao@siat.ac.cn,
yl.wang@siat.ac.cn
论文:
https://ieeexplore.ieee.org/document/10374139
发表期刊:TMM2023
论文简介
从未修剪的视频中检测指定语义的片段是视频理解任务中关于时间定位的基本问题,相关的任务包括时序句子定位和时序动作定位任务等。然而,在各种现实场景中,从这些未修剪的视频中注释时间边界通常是劳动密集型的。因此,近年来,弱监督设置逐渐引起了研究的关注。与全监督的设置不同,弱监督的设置指仅得到未经修剪的视频的文本描述和句子或动作标签,不包括这些语义对应的视频起止时间,这种标签比较容易收集或者标记。由于缺乏时间边界作为监督,大多数现有的弱监督方法首先生成proposals,然后利用句子或动作标签作为训练的监督信号。然而,这种视频级别的监督仅限于匹配clip proposals和text queries,而没有详细的进行视觉和文本信息的语义对齐。为了解决这个问题,我们提出了一个统一而简洁的框架——双掩模模型(Dual mask Modeling, DM2),可以同时用于弱监督时序句子定位和动作定位任务。
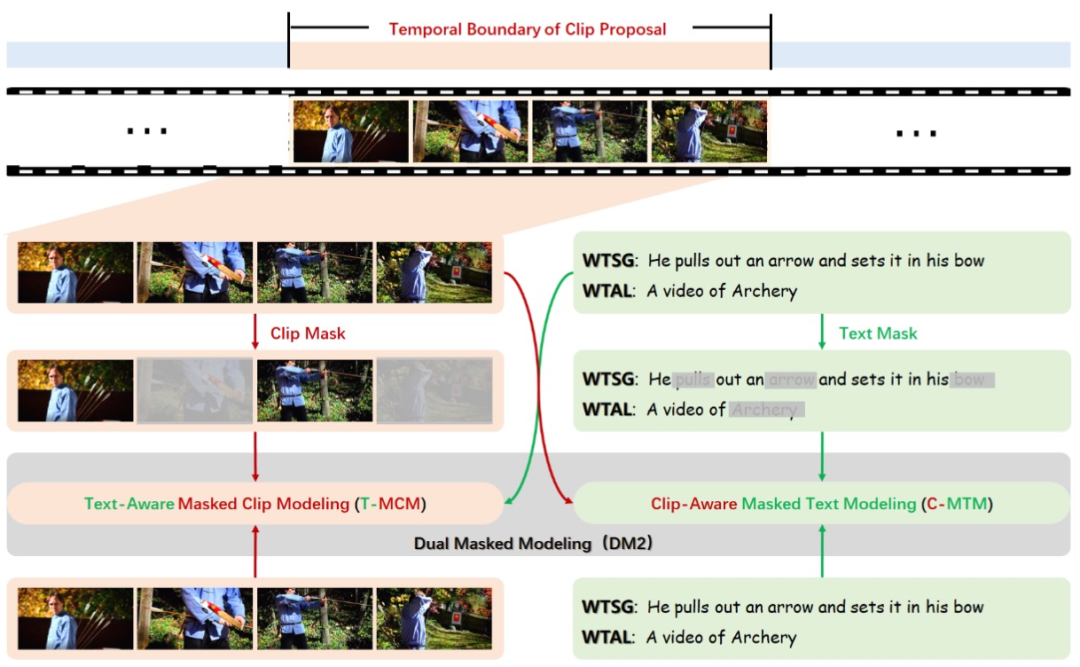
如上图所示,它可以通过两个互补的跨模态掩模分支,即clip感知的屏蔽文本模型(C-MTM)和文本感知的屏蔽clip模型(T-MCM),有效地对齐clip proposals和text queries。在生成clip proposals(即每帧的前景分数)之后,我们使用clip proposals作为视觉指导来预测被遮盖的文本单词。如果clip proposals的时间边界是正确的,它应该具备指导预测相应的文本单词的能力。同样,我们也使用text queries作为语言指导来重建被遮盖的clip proposals。如果clip proposals的时间边界是正确的,相应的text queries应该可以提供信息,以帮助其重建。通过这种交互式掩模重建,我们的DM2可以proposal generator生成有效的clip proposals,可以鲁棒匹配text queries,从而提高弱监督时间定位结果的准确性。
05
Reason Generation for Point of Interest Recommendation via Hierarchical Attention-based Transformer Model
作者:
吴玉霞,赵国帅,李鸣嘀,张倬诚,钱学明
单位:
西安交通大学
邮箱:
wuyuxia@stu.xjtu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10330074
发表期刊:TMM2023
作者主页: https://yuxiawu.github.io/
实验室主页: http://www.smiles-xjtu.com/
1.论文简介
推荐系统自提出以来已经得到了快速发展,旨在帮助用户快速筛选信息做出决策,也助力商家吸引更多的用户。一个好的推荐系统不仅需要个性化地向用户做出推荐,还需要人性化地展示推荐理由,增加系统的可解释性和透明度,提升用户的满意度。目前大多数推荐系统展示的推荐理由千篇一律,较为死板,难以说服用户。因此本文专注于个性化、多样化的推荐理由生成方法的研究,旨在为用户生成符合用户偏好的、生动贴切的推荐理由,改善用户的体验。本文聚焦于旅游领域中的兴趣点(POI)推荐理由生成任务,利用城市名称、POI标签和情感分数等属性,提出基于分层注意力的Transformer的模型,在词级和属性级两个层次学习用户偏好,从而生成符合特定用户兴趣的推荐理由。与传统POI推荐方法不同,本文模型考虑了不同的情感强度和用户偏好的多个主题,生成更具吸引力、类似于人际交流的推荐理由,以提升用户的满意度和系统透明度。本文还基于旅游平台用户评论数据提出了一个新的数据集, 并在Yelp公开数据集上也做了实验,验证了该方法的有效性。
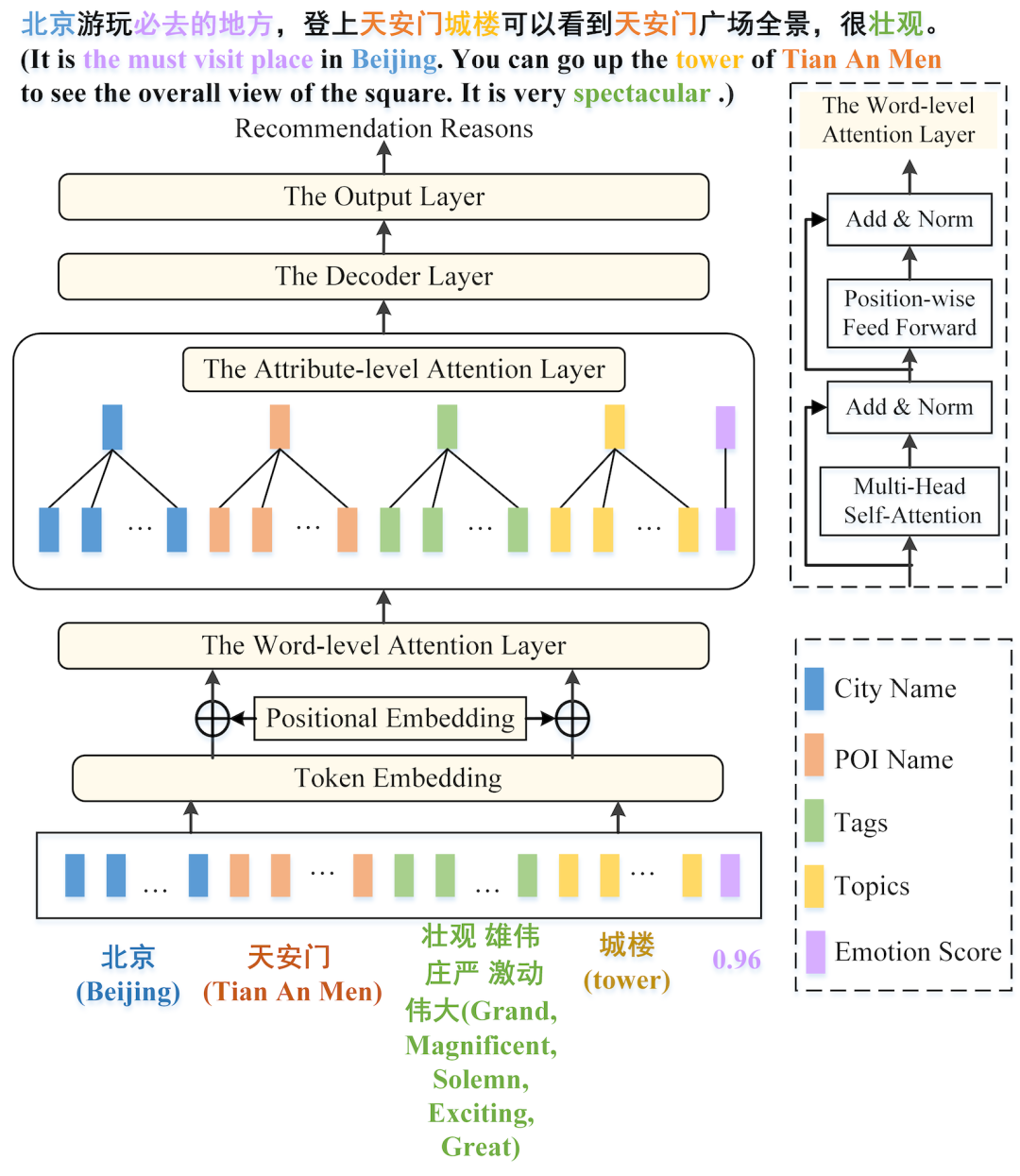
2.方法介绍
本文提出一个名为HAT的模型,包括一个编码器和一个解码器模块,包含以下五个部分:
(1)嵌入层:将所有输入词嵌入到一个固定大小的低维向量中,学习潜在特征,包含词嵌入特征和位置嵌入特征,以整合输入单词的顺序信息。使用预训练模型 Bert 的权重作为词嵌入的初始向量。
(2)词级注意层:是一个层级堆叠结构,通过捕获编码器和解码器模块与其他词的关系来学习每个词的潜在表示。
(3)属性级注意层:学习输入序列中每个属性项的综合信息。在不同的属性内,输入词具有不同的权重,融合信息用于表示每个属性的高级综合信息。
(4)解码器层:从编码器获得的潜在表示生成输出序列。它包含一个编码器-解码器注意模块,类似于编码器层中的单词级注意层。
(5)输出层:学习线性变换和softmax函数,将解码器输出转换为预测下一个单词的概率。
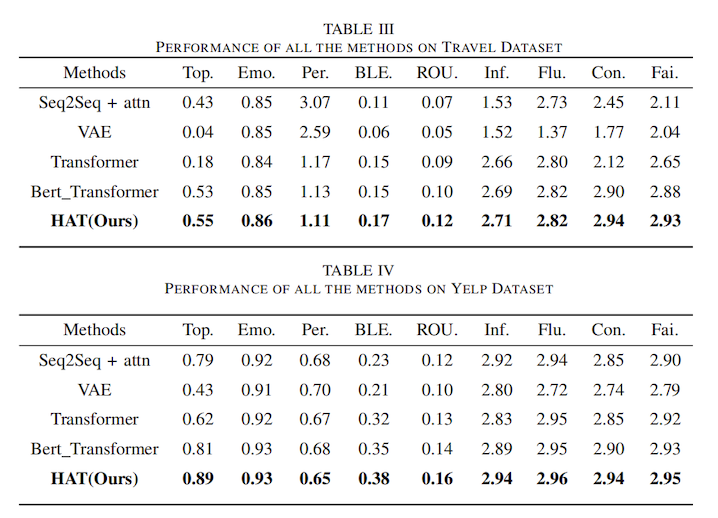
3.实验
我们在Travel (新数据集)和Yelp数据集上进行了全面的实验,以评估本文HAT模型的有效性。评价指标包括客观指标(如主题相似度, 情感准确度,困惑度等)和人工评价指标(如信息度, 流畅度, 可控度等)。实验结果见表2和3,总体而言我们的方法在所有数据集上均优于对比方法。
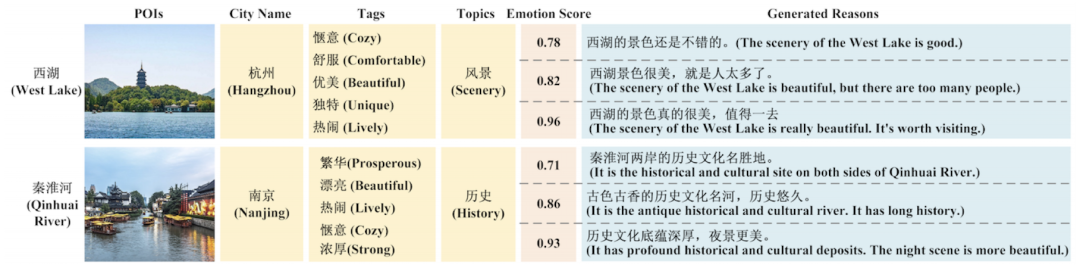
4.示例
下图中展示了相同主题在不同情感分数上的一些示例。比如杭州的西湖,它的标签是惬意,舒服,优美,独特,热闹。目标主题是风景。当情感得分为 0.78 时,模型生成的推荐理由是“西湖的风景还是不错的。”,情感得分为0.82时,生成结果是“西湖景色很美,就是人太多了。”,情感得分为0.92时,生成结果是 “西湖的景色真的很美,值得一去。”。可以从关键词“还不错”、“漂亮,但是”、“真的很漂亮”、“值得一去”等不同的情感评分中感受到差异。生成的推荐理由的情感多样性将有助于为不同的用户生成不同的推荐理由,并帮助用户从不同的角度感知 POI 的特征。

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号