
【论文导读】2024年论文导读第二十四期
【论文导读】2024年论文导读第二十四期
CCF多媒体专委会 2024年12月03日 17:56 北京


论文导读
2024年论文导读第二十四期(总第一百一十五期)
目 录
|
1 |
HCL: Hierarchical Consistency Learning for Webly Supervised Fine-Grained Recognition |
|
2 |
Enhancing Pre-trained ViTs for Downstream Task Adaptation: A Locality-Aware Prompt Learning Method |
|
3 |
Progressive Graph Reasoning-Based Social Relation Recognition |
|
4 |
Blind Quality Enhancement for Compressed Video |
|
5 |
Geometry-Guided Diffusion Model with Masked Transformer for Robust Multi-View 3D Human Pose Estimation |
01
HCL: Hierarchical Consistency Learning for Webly Supervised Fine-Grained Recognition
作者:
孙宏博,何相腾,彭宇新*
单位:
北京大学王选计算机研究所
邮箱:
sunhongbo@pku.edu.cn, hexiangteng@pku.edu.cn,
pengyuxin@pku.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10308611/
代码:
https://github.com/PKU-ICST-MIPL/HCL_TMM2023
课题组主页:
http://www.wict.pku.edu.cn/mipl
课题组Github主页:
https://github.com/PKU-ICST-MIPL
发表期刊:TMM 2023
*通讯作者
1.引言
细粒度图像分类旨在对粗粒度的大类进行细粒度的子类划分,如区分不同的鸟类、车型等,在生物物种保护、智能零售等领域都具有重要的研究和应用价值。但细粒度数据需要具有领域专业知识的专家花费大量时间进行标注,这导致细分类模型的训练数据成本极其昂贵。因此,近期研究者们尝试通过引入免费可获得的海量网络数据,降细粒度数据标注成本。然而,网络数据通常由自动标注程序或普通标注者进行标注,因此数据中通常含有噪声,使得细分类模型难以拟合真实数据导致识别性能退化。
针对上述问题,本文提出了基于层级语义一致性学习的含噪细粒度图像分类方法(HCL),通过模拟人类注意力逐渐聚焦关键区域的识别机制(如图1所示),利用正确标注样本在图像、对象、部件层级下语义预测保持一致的特性,实现噪声数据自动检测和细粒度辨识性信息提取,提高模型在含噪场景下的细粒度图像分类性能。
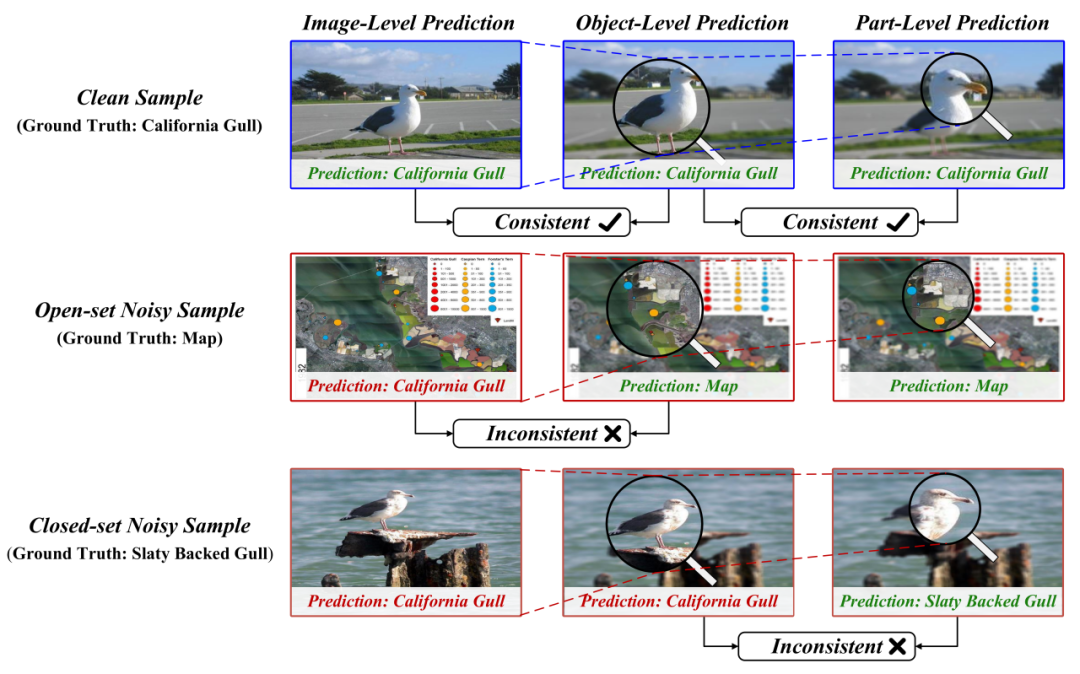
图1 人类识别物体过程示意图
2.方法
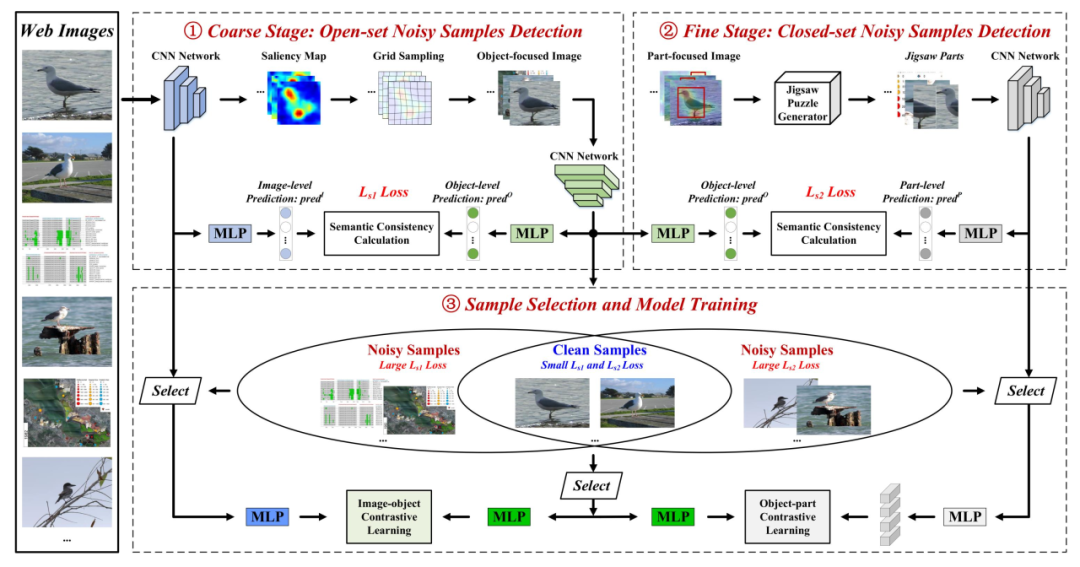
图2 基于层级语义一致性学习的含噪细粒度图像分类方法(HCL)
在含噪细粒度图像分类任务中,噪声数据可以分为两种类型,即开集噪声和闭集噪声。如图1所示,开集噪声是指不属于任何细粒度子类别的样本,即不在领域数据分布内。例如,鸟类栖息地的“地图”图像由于图像中存在“California Gull”字样的文本而被错误标记为“加州鸥”。闭集噪声是指被错误标记为其他细粒度子类别的样本。例如,“灰背鸥”的图像被错误标记为“加州鸥”,这是领域数据分布内的噪声样本,是由于极小的类间差异而导致的标注错误。开集噪声样本和闭集噪声样本的存在,会导致模型在训练中难以收敛或者过拟合,大大削弱了模型的细粒度图像分类能力。
本文HCL方法通过分析输入样本在图像层级、对象层级、部件层级的语义一致性检测滤除噪声数据,并通过构建多层级对比学习进一步增强细粒度表征,提高含噪场景下细粒度图像分类的准确率。方法包含三个部分:开集噪声样本自动检测、闭集噪声样本自动检测、干净样本选择与模型训练。具体而言,本文方法以一个关注视角由粗到细的顺序模仿人类识别过程,首先计算图像-对象语义预测一致性检测开集噪声样本,然后计算对象-部件语义预测一致性检测闭集噪声样本,最后得到干净样本进行模型训练,并使用多层级对比学习来增强模型的细粒度表征能力。(1)开集噪声样本自动检测:首先,将图像输入骨干神经网络进行特征提取和映射,得到图像层级的语义预测向量;其次,基于特征图响应分析提取图像显著性图,并进一步使用网格抽样算法放大图像中的视觉对象后进行对象层级的语义预测;最后,通过计算图像层级和对象层级语义预测的分类损失和两者间的Jensen–Shannon分布差异损失,得到图像层级和对象层级语义预测间的差异程度,实现开集噪声的自动检测。(2)闭集噪声样本自动检测:基于图像显著性图使用连通域分析得到图像中包含关键部件的显著区域;其次,采用拼图数据增强方法将得到的显著区域进行切分并随机打乱顺序,促使模型自动提取局部辨识性部件特征并输入到神经网络得到部件层级的语义预测向量;最后,使用与步骤一类似的方式计算对象层级和部件层级语义预测间的差异,实现闭集噪声的自动检测。(3)干净样本选择与模型训练:通过取交集的方式得到干净样本用于模型训练,并提出多层级对比学习提高模型在不同层级下的细粒度表征能力。如图2所示,首先,将原图像和视觉对象图像组成正样本对,将原图像与含噪图像组成负样本对;其次,通过在图像层级、对象层级以及部件层级分别进行对比学习,逐步增强模型对视觉对象和关键部件的学习能力,同时提高模型对噪声数据的辨识能力,最终实现含噪场景下的准确细粒度图像分类。
3.实验
本文方法在3个含噪细粒度图像分类数据集上进行对比实验(如表1所示),分别达到86.1%,91.6%和92.5%的识别准确率,平均识别准确率达到90.1%,相比次优方法取得3.2%性能增益,并得到以下结论:(1)通过使用图像级、对象级和部件级语义预测分布之间的一致性进行干净样本选择,具有更强的噪声去除能力。同时通过使用多层级对比学习,提高了模型的细粒度表征能力;(2)通过挖掘视觉对象和关键部件信息,能够促使模型得到辨识性视觉特征,提高了模型的细粒度图像分类性能。
表1 与现有先进方法在Web-Bird, Web-Car, Web-Aircraft上的对比实验
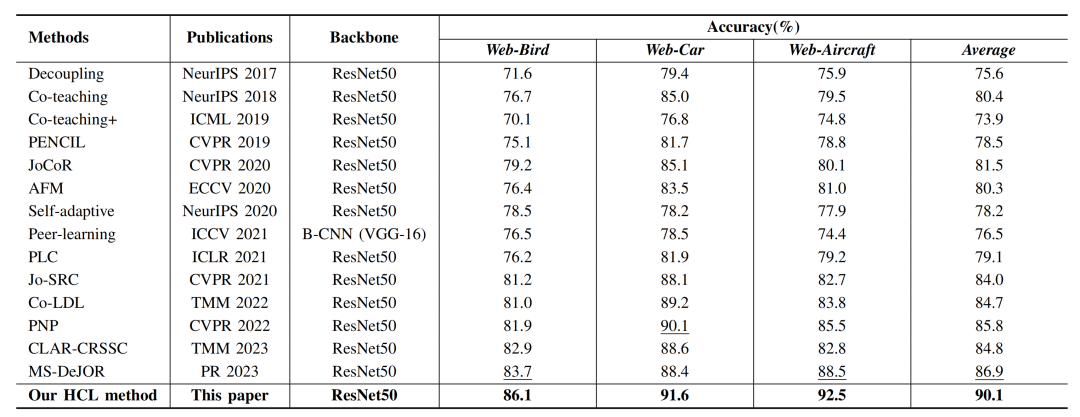
图3展示了本文方法检测出的干净样本和噪声样本,前4列为检测得到的干净样本,第5列和第6列是检测得到的开集噪声样本,第7列是检测得到的闭集噪声样本。可以看出,本文方法能够准确地过滤开集噪声样本和闭集噪声样本,因此能在含噪场景下取得更好的细粒度图像分类性能。

图3 本文HCL方法检测出的干净样本与噪声样本
02
Enhancing Pre-trained ViTs for Downstream Task Adaptation: A Locality-Aware Prompt Learning Method
作者:
王少鲲,郁一帆,贺宇航,龚怡宏*
单位:
西安交通大学
邮箱:
shaokunwang.xjtu@gmail.com
论文:
https://dl.acm.org/doi/10.1145/3664647.3680983
代码:
https://github.com/Mysteriousplayer/KGPT
发表会议:ACM MM2024
*通讯作者
1.研究背景
视觉Transformers(ViTs)具有出色的从图像中提取全局信息的能力。然而,其固有局限性在于难以高效提取局部区域的信息。特别是像Vanilla ViT和CLIP这样的全监督预训练ViTs,在陌生的下游任务上面临局部信息消失问题(locality vanishing problem),如图1所示。

图1 局部信息消失问题:在下游任务中,预训练的ViT倾向于关注全局信息,而忽略了关键区域的局部信息。
为此,本文的研究目标是提升预训练ViTs在局部信息整合方面的能力,以增强预训练ViTs在下游任务的适应能力。近期关于黑白盒模型理论方面的研究进展表明,结合黑盒模型和白盒模型构建一个统一的黑白盒模型,为提升黑盒模型的性能和可解释性提供了一种有前景的技术路线。受黑白盒模型理论启发,我们提出了一种局部信息感知提示学习(LORE)方法,如图2所示。
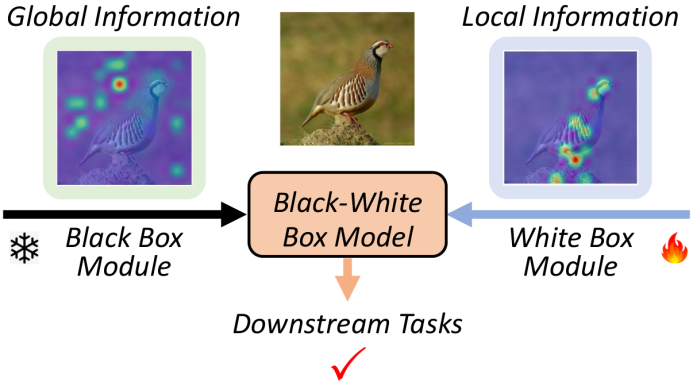
图2 黑白盒模型的工作逻辑:白盒模块弥补了黑盒模块(即预训练ViT)在局部信息整合能力上的不足,从而更好地适应下游任务。
2.方法介绍
如图3所示,我们的方法由一个数据驱动的黑盒模块和一个知识驱动的白盒模块组成。白盒模块包括一个局部交互网络(LIN)、知识-局部注意力(KLA)和提示生成器(PG)。
(1)LIN增强了图像局部区域内的信息交互。
(2)KLA在语义知识的指导下捕捉关键局部区域。
(3)PG基于K-L原型约束来生成局部信息感知提示。
图中绿色线条所示的工作流程在推理阶段并非必需。
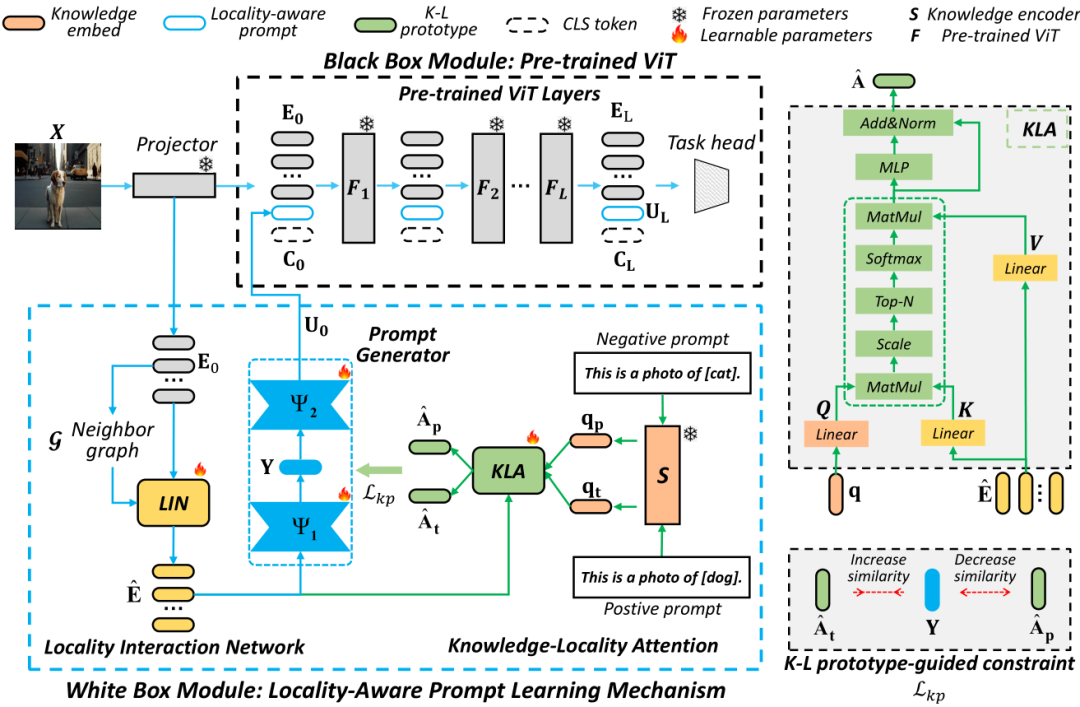
图3 整体架构图
3.实验结果
在四个下游任务上共16个数据集的实验证明了我们提出的LORE方法的有效性。
(1) 图像分类任务
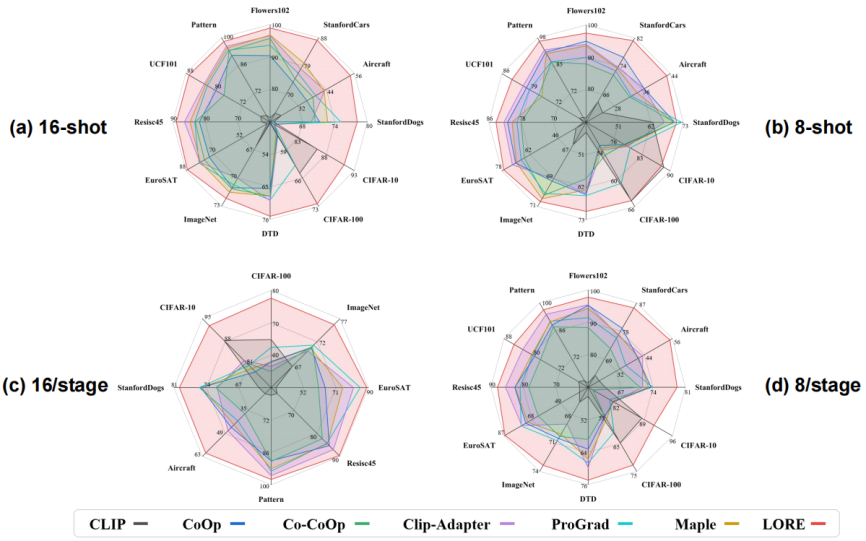
图4 小样本和两阶段课程学习下游任务上的性能比较
(2) 其他下游任务

图5 在其他下游任务上的评估,包括图像检索、点对应和视频物体分割。
(3) 可视化

图5 在ImageNet分类任务下,我们的黑盒模块(B-B)、KLA机制和LORE的注意力图可视化展示了LORE对全局信息和局部信息的平衡能力。
03
Progressive Graph Reasoning-Based Social Relation Recognition
作者:
唐旺,卿粼波,李林东,王昱晨,朱策
单位:
四川大学,电子科技大学
邮箱:
tangwang@stu.scu.edu.cn,
qing_lb@scu.edu.cn,
lilindong@stu.scu.edu.cn,
wangyuchen98@stu.scu.edu.cn,
eczhu@uestc.edu.cn
论文:
https://ieeexplore.ieee.org/document/10365242
代码:
https://github.com/tw-repository/PGR-SRR
发表期刊:TMM 2023
1.引言
随着多媒体和视觉技术的快速发展,越来越多的研究者开始关注图像中人与人之间的社会关系。现有研究通过构建不同的图神经网络来推理人物的社交关系。然而,目前鲜有研究探索个体、二元、群组的多级交互结构,导致模型难以纠正推理过程中可能出现的错误。例如,在图1中,如果错误地将A和B的关系分类为夫妻,将C和D的关系分类为同事,那么推理过程可能会出现混乱。总的来说,如果图中包含了错误的逻辑线索,那么单阶段的社会关系推理就很容易出错。
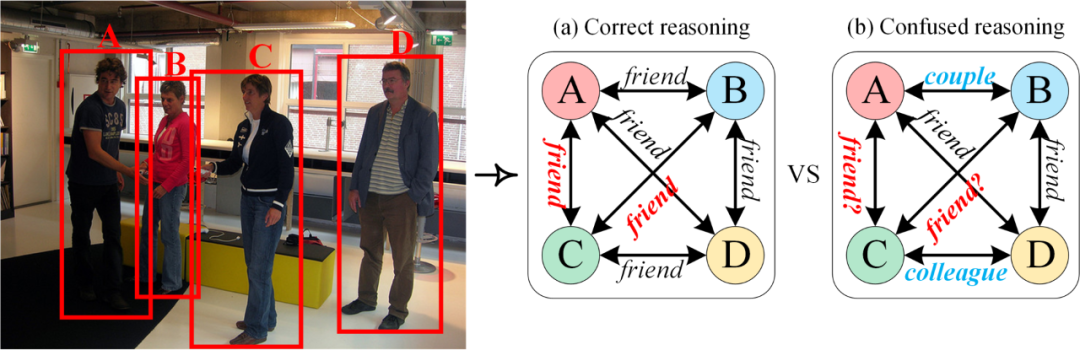
图1 基于图的单阶段社交关系推理:(a) 正确的推理,(b) 产生错误的推理
在社会心理学中,多层次信息被广泛用于推断社会关系。心理学家如Bond、Malloy等人在个体、二元和群体层面对社会关系进行了广泛的研究。在个体层面,研究集中在个人外观和吸引力等方面。在二元层面,研究者利用个体特征来探索人与人之间的互动。在群体层面,研究则关注群体内部和群体间的互动,以及群体与整个社会的关系。
受这些研究的启发,我们提出了一种基于渐进图推理(PGR-SRR)框架。我们首先从个体层面出发,探索人际互动、外观属性、位置等因素,并推断出个体间的关系。然后,我们将这些关系线索输入到一个群体推理模块中进行综合处理。最后,通过转换器将视觉信号与渐进推理的交互逻辑线索融合,最终实现更准确的社交关系识别。
2.方法概述
在介绍我们提出的模型之前,有必要解释一下渐进式推理,它是我们模型框架的基础。图 2 展示了渐进式推理过程。在第一阶段,提取人类特征(图 2(a))。在第二阶段,在图像中找到六种二元关系(图 2(b))。根据图 2(b),可以做出初步的关系式推断。在第三阶段,所有二元组和群体将被嵌入一个更复杂和高阶的图结构中(图 2(c))。在这个例子中,很容易判断出成员之间存在家族关系。
证据的逐步积累可以使推断模型降低出错的风险。例如,如果我们假设 B 和 C 之间的关系在第二阶段被错误地分类为朋友关系(图 2(b) 中的红色字体)。我们可以利用群体中其他人的关系和整个群体的关系作为线索,例如母子、父子、夫妻和家人,将 B 和 C 的关系修改为兄弟关系(图 2(c)中的蓝色字体)。
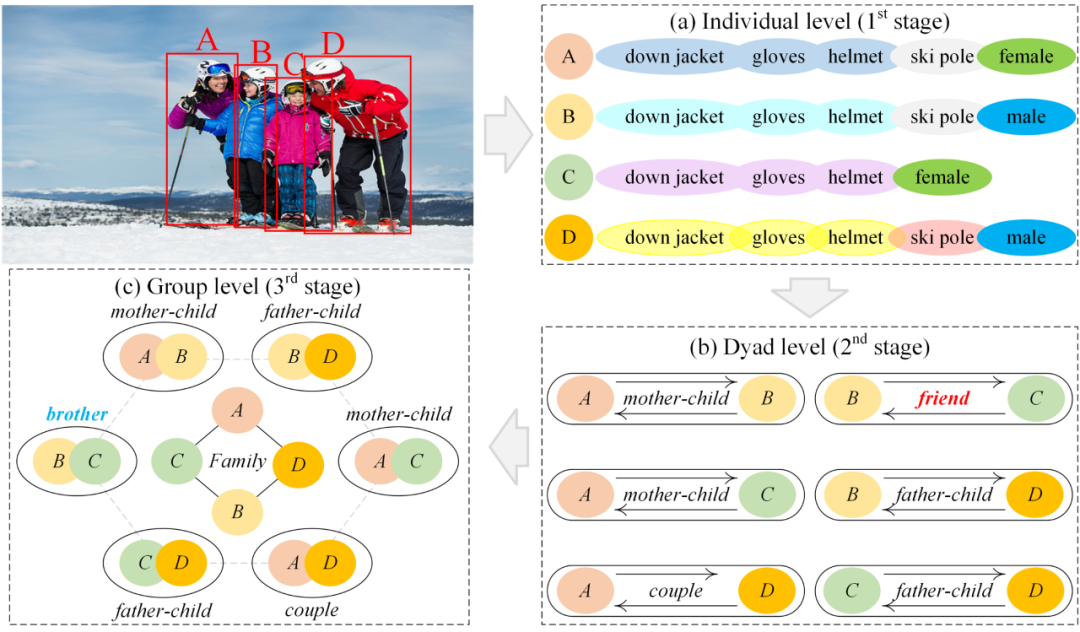
图2 渐进式推理的本质。左上方的图像是模型输入。三个阶段分别是:(a) 第一阶段从图像中提取单个特征;(b) 第二阶段对每一配对关系进行初步推理;(c) 综合证据网络,用于消除错误的线索和混淆。
根据上述理论框架,我们构建了如图3所示的深度学习模型。首先,使用三个通道提取图像中 (a) 个人、(b) 二元组和 (c) 群体的视觉特征。前两个通道使用 ViT,第三个通道使用 ResNet-50。然后,分四个阶段进行渐进推理。在第一阶段,融合位置和吸引力特征来探索人际互动。第二阶段,使用 INs 和配对视觉特征构建第一个推理图,即 IDG。第三,利用 IDG 和群体视觉特征构建第二个推理图,即 DGG。最后,通过transformer来融合图推理的知识和视觉特征。
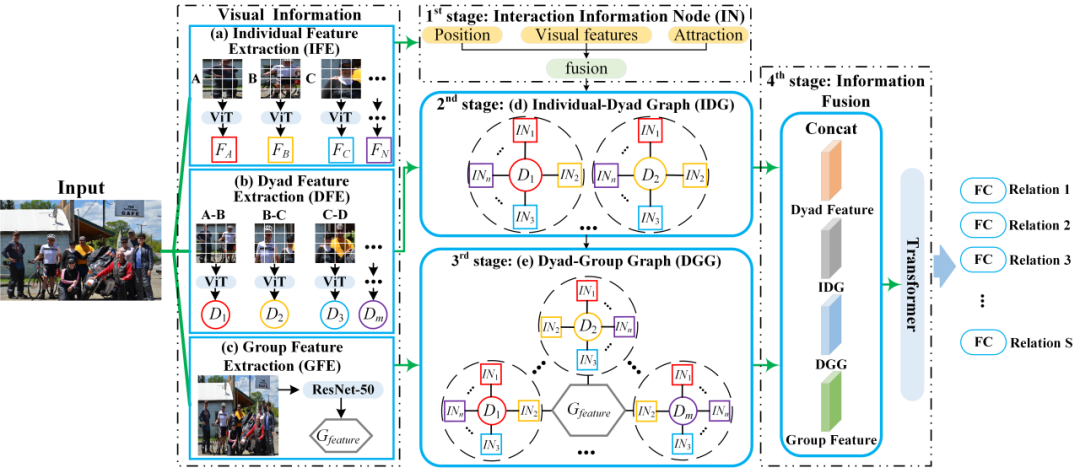
图3 PGR-SRR的整体结构
3.实验结果
本文在两个社交关系的公开数据集(PISC和PIPA)上进行了对比试验,结果见表1。图4展示了和最近的方法的可视化对比的例子。图5展示了渐进式推理逐渐纠正错误和降低混淆概率的过程。
表1 我们的模型与现有方法的比较
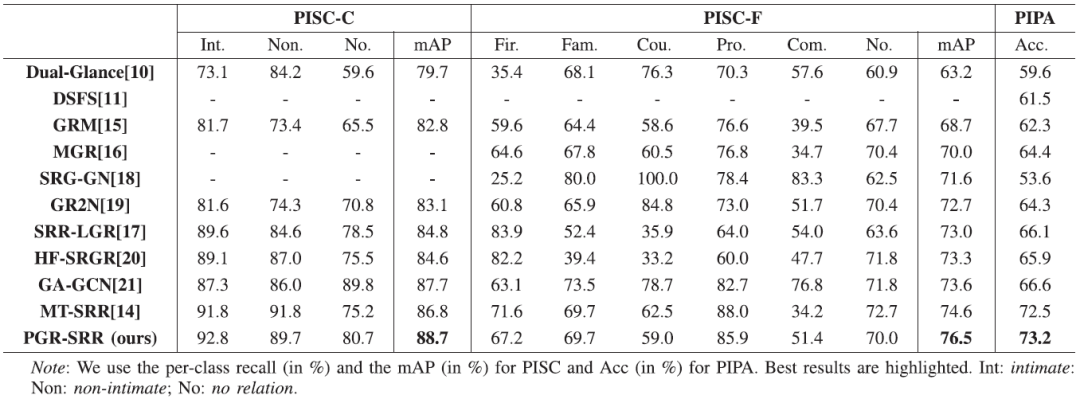

图4 不同模型推理错误和混淆的例子。(错误的为红色字体)
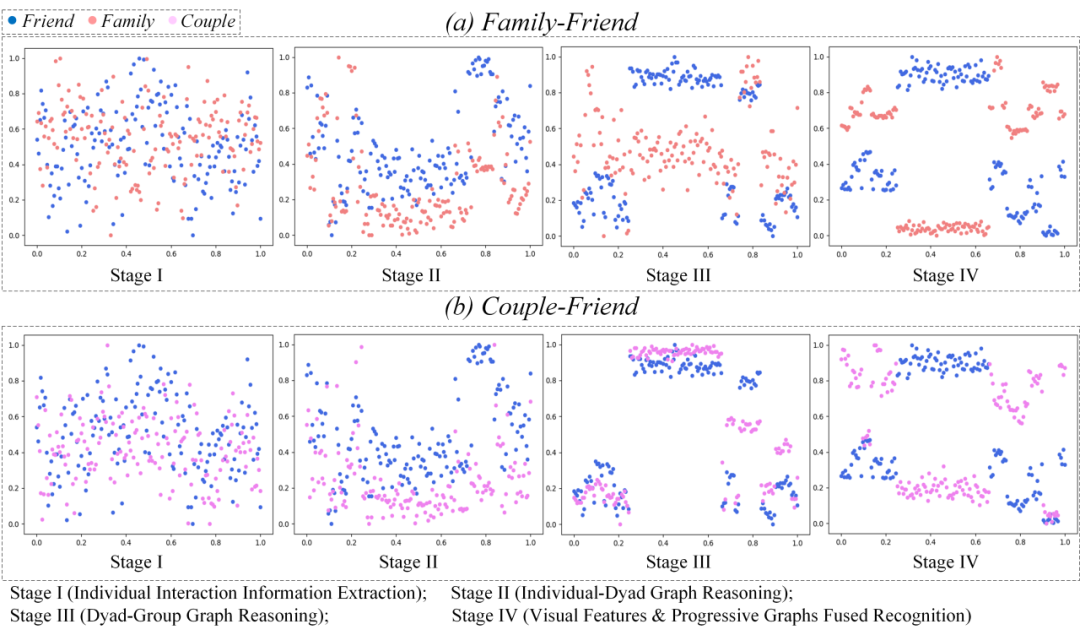
图5 通过T-SNE将每个推理阶段的深度嵌入可视化。(a) 家庭和朋友的可视化,(b) 夫妻和朋友的可视化。
04
Blind Quality Enhancement for Compressed Video
作者:
丁青1,沈礼权1,虞良伟1,杨浩1,徐迈2
单位:
1上海大学,2北京航空航天大学
邮箱:
dingqing@shu.edu.cn,
jsslq@163.com,
leoyu800@shu.edu.cn,
aidoneus@shu.edu.cn,
maixu@buaa.edu.cn
论文:
https://ieeexplore.ieee.org/document/10343127
发表期刊:TMM2023
1.研究背景和动机
解码端视频增强旨在去除有损压缩算法引入的伪影,提升编码后视频质量。过去的研究中,基于深度学习的图像和视频增强方法取得了显著进展,但大多数方法依赖预先已知的噪声水平,并为不同的量化参数(QP)训练多个相同架构的模型。这种做法虽然在训练过的QP下可有效增强,但导致了更多的资源消耗。此外,转码和传输过程的复杂性使得噪声水平往往不完全已知,限制了这些“非盲”增强算法的应用。
不同QP压缩的视频存在相似的变换候选模式和熵编码以及不同的量化步长,这使得不同QP的压缩视频之间具有特征相似性和差异性。这些特性可用来指导盲增强算法的方法设计。
目前的盲图像增强方法在去除压缩伪影方面表现出潜力,但在视频增强上仍存在局限性:一是现有方法孤立地处理不同QP的编码视频,未能有效融合多个QP的特征,无法在未训练过的QP上实现有效增强;二是这些算法仅关注单帧图像的处理,无法利用视频帧间的时间相关性。由于连续帧间的内容相似性和质量波动,邻近高质量帧可以为当前帧的增强提供重要信息。因此,充分利用时间信息和多帧特征是提升视频质量的关键。为此,本文提出了一种新颖的盲质量增强网络(BQEV),旨在利用波动的时间信息、不同QP间的特征相似性和差异性,以实现更优的压缩视频增强效果。BQEV网络的核心思想是将连续帧作为输入,渐进提取特征并进行QP自适应特征融合,图1详细展示了BQEV算法和其他盲图像增强算法的差异。
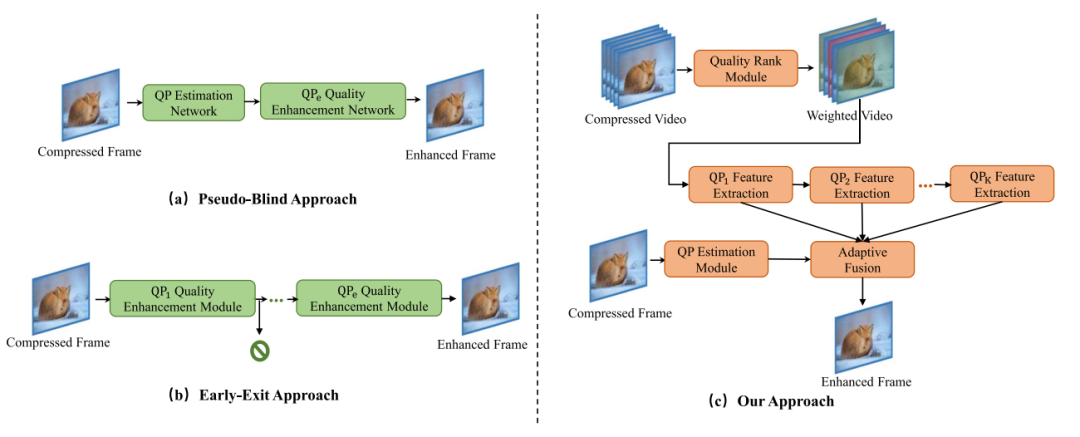
图1 盲图像/视频增强算法
2.方法介绍
BQEV整体框架主要包含渐进特征提取子网络和QP自适应融合子网络,如图2所示。
1)渐进特征提取子网络
该子网络由多层堆叠的卷积层组成,逐步提取不同QP的特征。为利用视频的时域信息,采用连续帧作为输入,并设计了质量排序模块,根据多帧质量进行排序,对高质量帧进行加权,以提取高效特征。
2)QP自适应融合子网络
该子网络包含自适应融合模块,针对渐进特征提取子网获取的不同QP特征进行自适应融合和质量增强。具体地,设计了一个质量估计模块,预测输入单帧的质量,用于引导自适应特征融合。
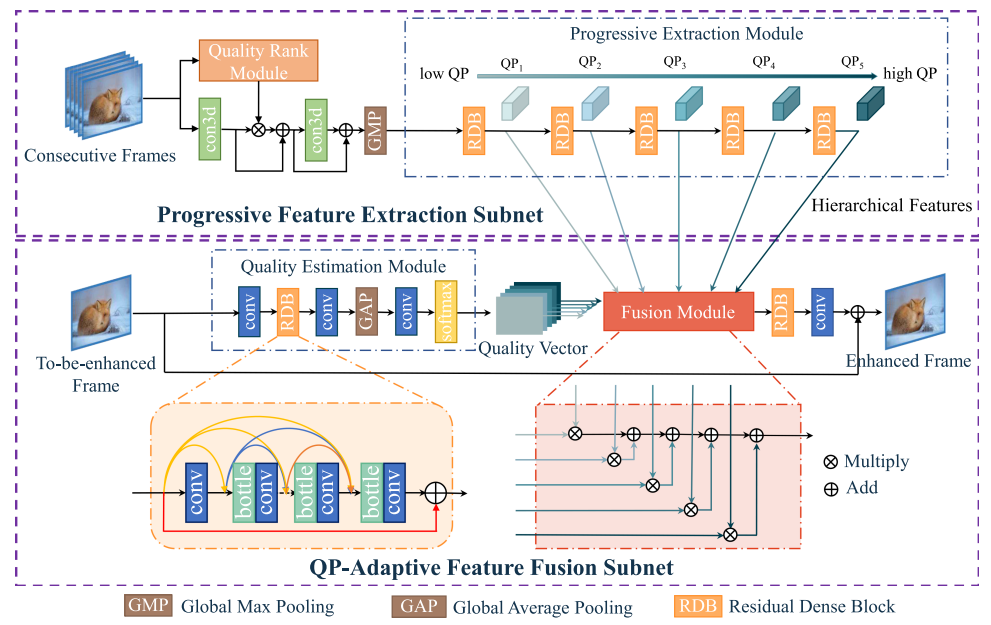
图2 BQEV算法框架图
3.实验分析
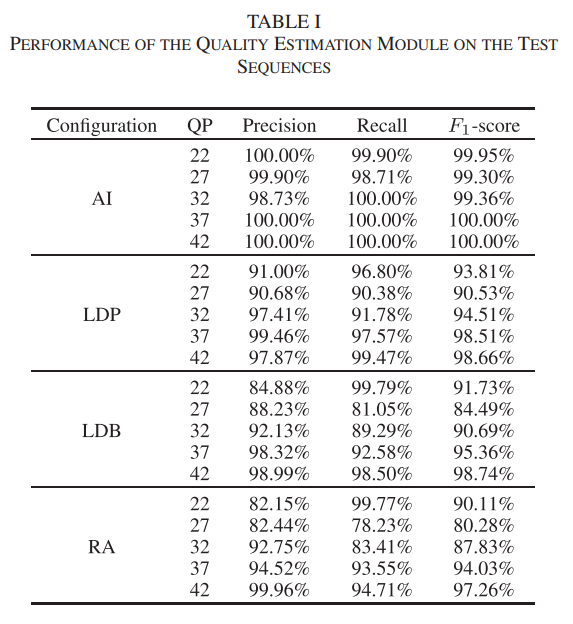
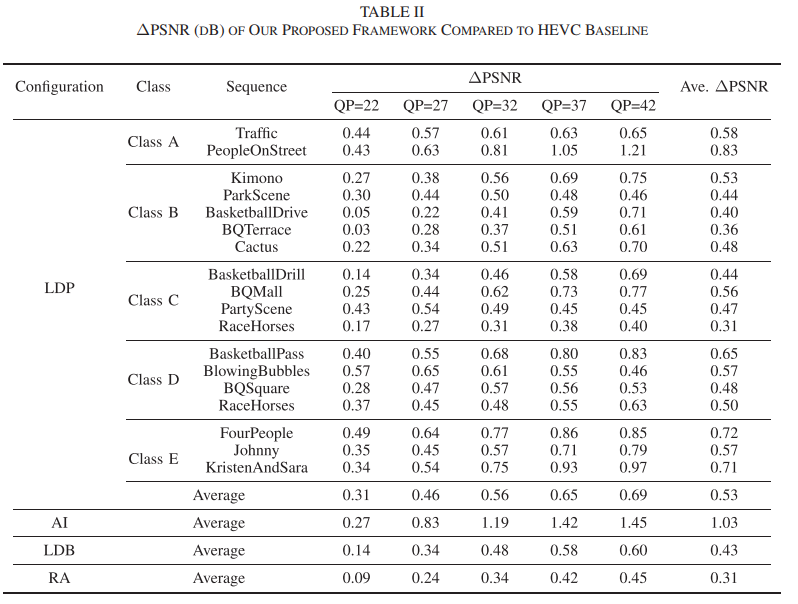
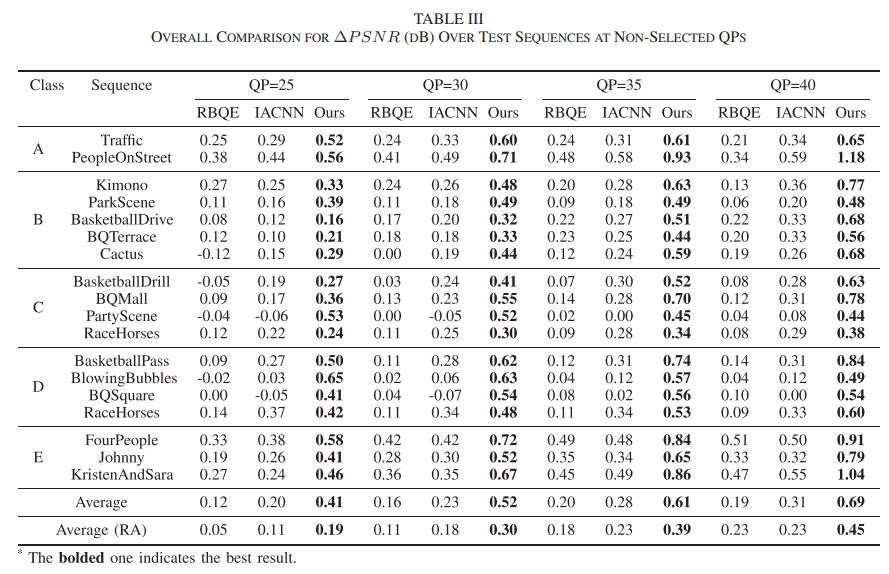
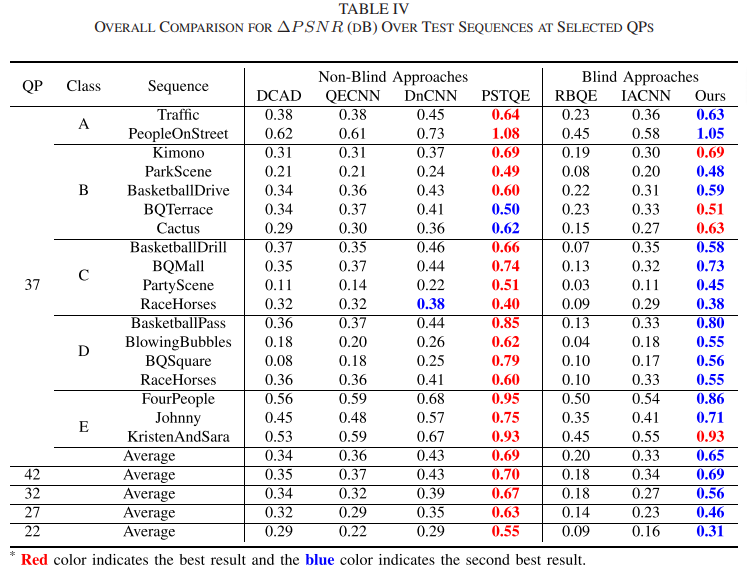
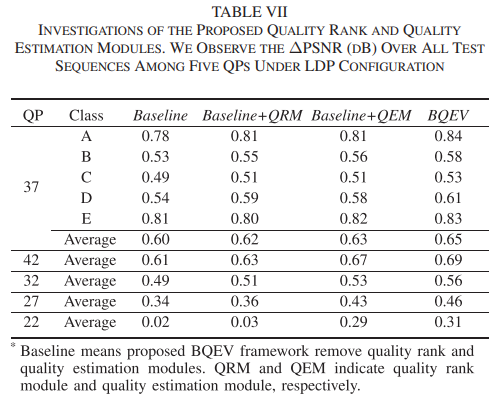
本文在HEVC的标准测试序列上进行了大量的实验,验证了BQEV算法的有效性,具体结果如下。Table I是质量估计模块在不同配置下的预测准确率;Table II是BQEV算法在不同编码配置下训练过的QP上实现的增强效果;Table III是BQEV算法以及其他盲增强算法在没有训练过的QP上的对比结果;Table IV是BQEV算法以及其他非盲和盲增强算法在训练过的QP上的对比结果;Table VII是BQEV算法各模块的消融结果。
05
Geometry-Guided Diffusion Model with Masked Transformer for Robust Multi-View 3D Human Pose Estimation
作者:
张馨怡1,崔钦鹏1,鲍琦琦2,杨文明1,廖庆敏*1
单位:
清华大学深圳国际研究生院1,浙江科技大学2
邮箱:
xinyi-zh22@mails.tsinghua.edu.cn,
cqp22@mails.tsinghua.edu.cn,
nora919530829@163.com,
yang.wenming@sz.tsinghua.edu.cn,
liaoqm@tsinghua.edu.cn
论文:
https://dl.acm.org/doi/pdf/10.1145/3664647.3681265
发表会议:ACM MM2024
*通讯作者
1.研究背景
三维人体姿态估计旨在通过解析图像、视频等多媒体数据,高效、精准地捕捉人体骨架上稀疏的关键点在三维空间中的位置。这些人体几何和位置信息可以服务于诸多下游任务,如动作识别、动作教学与纠正、影视特效中的角色重建、虚拟现实等。
近年来,Transformer和扩散模型的研究为三维人体姿态估计带来了显著进展。例如,一些方法利用Transformer强大的远程依赖性和交互建模能力,在几何知识的引导下实现多视图信息融合,从而最小化重投影误差。然而,这些方法对输入视图的数量和相机空间排布有着严格的限制,不能很好地泛化到具有任意数量的看不见的视图。此外,这些方法通常是确定性的,即直接从给定输入中推断出最可能的单个姿态,在复杂和具有挑战性的场景中容易陷入局部最优解。
概率性方法通过生成多个可信的姿态假设来缓解姿态估计的不确定性。这类方法在单视角中得到了广泛研究,但是多视角情况下仍然存在不确定性,这可能来自于严重的物体遮挡或自遮挡、有噪的二维姿态检测等。因此,多视角概率模型值得进一步研究。现有方法直接利用扩散模型的概率本质,生成多个假设。但由于缺乏几何信息引导,其高精度潜力仍未得到充分挖掘。
综上,现有的基于Transformer和扩散模型的方法无法同时解决准确性和泛化性的问题。
2.研究方法
本文提出了一种基于几何引导的扩散模型与掩码Transformer相结合的鲁棒多视角三维姿态估计方法(Masked Gifformer)。如图1所示,我们在扩散模型的框架下训练了一个基于Transformer的分层多视角去噪器,系统地整合关节和视角信息以拟合3D姿态分布。为了解决长期存在的泛化能力差的问题,我们提出了一种完全随机的掩码策略,以一定概率随机遮挡注意力矩阵中的元素(包含对角线元素)。这一策略能使我们的模型泛化到不同相机数目、空间布局和跨数据集,而不引入额外的可学习模块或参数。在推理过程中,我们将几何信息引入扩散模型,以提高模型的精度。具体来说,我们将条件引导分布建模为重投影误差的负指数形式,引导采样过程朝着最小化重投影误差的方向进行。最后,通过聚合所有假设,获得一个准确且鲁棒的三维姿态。
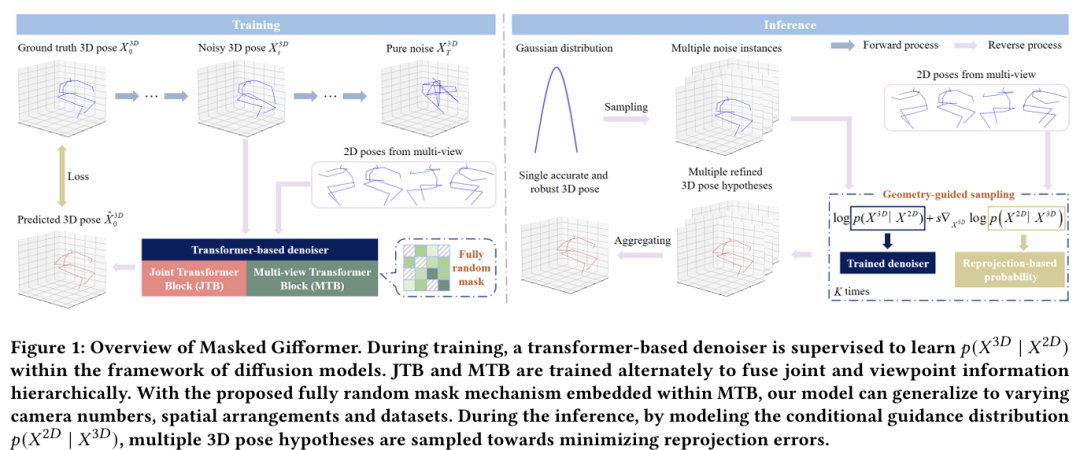
图1 模型架构图
3.实验分析
1)与现有最优方法比较
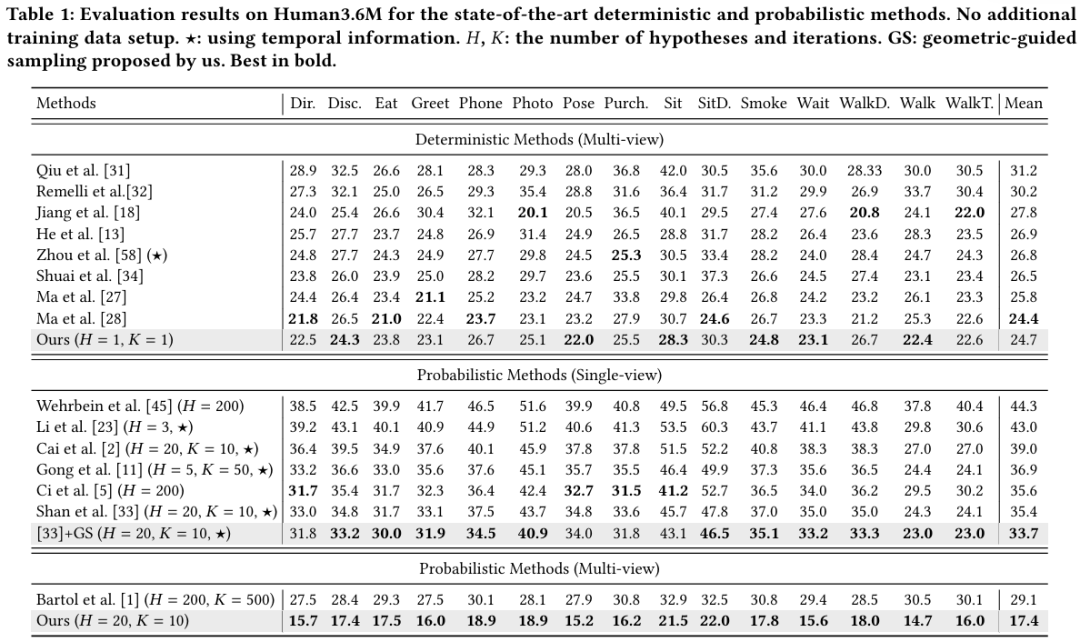
本文在3D人体姿态估计公开数据集Human 3.6M和CMU Panoptic数据集上进行实验。表1给出了在Human 3.6M数据集上的对比结果。可以看到,尽管我们的方法旨在生成多个三维姿态假设,但在单假设场景下,平均每关节点位置误差(MPJPE)仍达到了24.7mm,优于绝大多数确定性方法,并达到了与最先进方法相当的性能。进一步与多视角概率方法进行了比较。当假设数量增加到20时,MPJPE从24.7mm下降到了17.4mm,比Bartol 等人低11.7mm,即使我们使用更少的假设数和迭代次数。为了进一步验证我们提出的几何引导采样(GS)策略的通用性,我们将其应用于单视角概率方法D3DP(Shan等人)中。可以看到,误差降低了1.7mm。
表1 概率性和确定性方法Human3.6M数据集上的对比结果
2)泛化到不同相机数量和空间布局
Masked Gifformer和竞争方法在Human3.6M上的泛化结果如表2所示。Masked Gifformer在训练集的2个/4个相机上进行训练,并在测试集的不同相机数目上进行测试。从横向分析来看,我们的方法以较少的泛化损失(<7.4mm)泛化到任意相机数量的场景中。此外,我们的方法也能泛化到相机数目相同但空间摆放位置有所差异的场景(表2左侧)。从纵向比较来看,我们的方法在不牺牲拟合能力的情况下,泛化性优于Jiang等人和Shuai等人的方法。
表2 Human3.6M 数据集上不同相机数量和空间布局的泛化性能

3)泛化到不同数据集
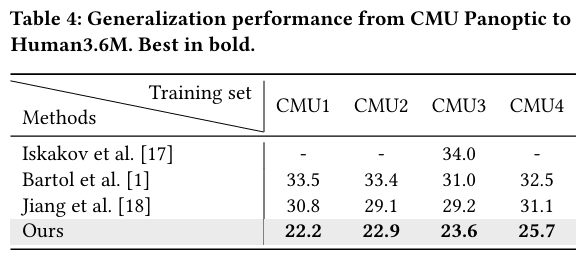
为了测试Masked Gifformer在跨数据集泛化能力上的表现,我们将CMU Panoptic数据集划分为四个子集,记为CMU1~CMU4。表3展示了从这四个子数据集到Human3.6M数据集的泛化结果。从横向分析来看,无论训练集为何,我们的方法均能成功实现跨数据集的泛化。从纵向比较来看,我们的方法展现了更强的泛化能力,超越了对比方法。例如,Iskakov等人、Bartol等人和Jiang等人在CMU3子集上训练时,在Human3.6M测试集上的平均误差分别为34.0mm、31.0mm和29.2mm。而我们的方法则取得了23.6mm,展现了跨数据集泛化方面的显著改进。
表3 CMU Panoptic到Human3.6M的泛化性能

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号