
【论文导读】2024年论文导读第二十五期
【论文导读】2024年论文导读第二十五期
CCF多媒体专委会 2024年12月17日 19:46 北京


论文导读
2024年论文导读第二十五期(总第一百一十六期)
目 录
|
1 |
Continuous Emotion-Based Image-to-Music Generation |
|
2 |
From Observation to Concept: A Flexible Multi-view Paradigm for Medical Report Generation |
|
3 |
Q-MoE: Connector for MLLMs with Text-Driven Routing |
|
4 |
CartoonNet: Cartoon Parsing with Semantic Consistency and Structure Correlation |
|
5 |
Deep Neighborhood-Preserving Hashing with Quadratic Spherical Mutual Information for Cross-Modal Retrieval |
01
Continuous Emotion-Based Image-to-Music Generation
作者:
王亚杰,陈穆林,李学龙
单位:
西北工业大学,中国电信人工智能研究院
邮箱:
chenmulin@nwpu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10345728/
发表期刊:TMM 2023
1.引言
图像到音乐生成的任务旨在根据给定的图像创作动人的音乐旋律。先前的研究致力于图像与音乐之间基于内容的跨模态匹配,例如将圣诞歌曲与包含圣诞树的图像进行关联。相比之下,图像到音乐生成的任务因其本身的模糊性和主观性而更加具有挑战。具体而言,图像内容与音乐旋律之间并无明确关联,且不涉及歌词、人声等内容媒介。此外,生成音乐的感知因个体差异而异。受到联觉现象的启发,我们认为,如果一幅图像能够引发特定情感,那么生成的音乐也应当传达类似的情感印象。因此,本文提出了一种基于情感的连续图像到音乐生成框架,以情感作为跨模态生成的核心要素。
2.方法
本文首先构建了一个图像-音乐数据集,该数据集采用了连续的效价-唤醒(Valence-Arousal, VA)情感模型来标注情感。这一模型能够更精细地捕捉图像中情感的细微差别。接着,本文提出了一个即插即用的模型,将图像转换为具有相似情感的音乐。该模型通过将情感投影到连续值标签上,并利用对比学习探索模态内外的情感一致性,从而实现了图像到音乐的转换。此外,本文还设计了一种新的对比学习策略,用于处理连续标签,这有助于在跨模态潜在空间中学习情感的一致性。
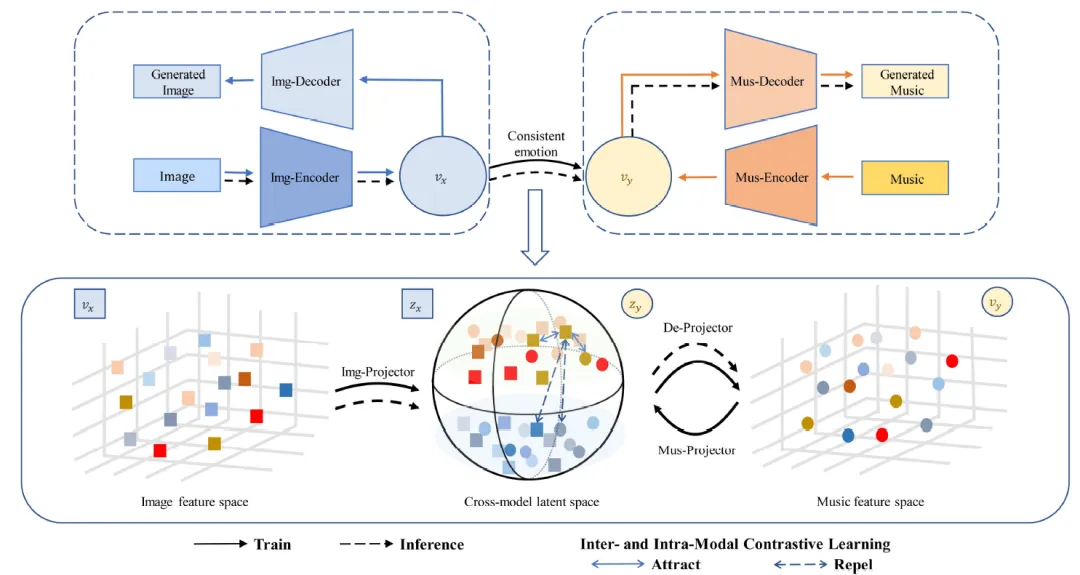
图1 基于连续情感的图像到音乐生成算法框架
3.实验
本文使用了多种图像和音乐自编码器来测试模型的即插即用特性,并与基于Transformer和生成对抗网络(GAN)的基线模型进行了比较。从表1中可以观察到,本文提出的方法在音乐质量和情感匹配度方面均优于上述比较算法。
表1 与其他方法的对比实验定量结果

此外,本文还进行了消融实验,以验证所提出的模态内和模态间对比学习的必要性。从表 2可以看出,采用本文提出的对比学习算法能够进一步提升基线模型的性能。
表2 对比学习算法的消融实验

02
From Observation to Concept: A Flexible Multi-view Paradigm for Medical Report Generation
从观察到概念: 面向医学报告生成的灵活的多视角生成范式
作者:
刘志哲1,朱振峰1*,郑帅1,赵亚威2,何昆仑2,赵耀1
单位:
北京交通大学,中国人民解放军总医院医学大数据研究中心
邮箱:
zhzliu@bjtu.edu.cn,
zhfzhu@bjtu.edu.cn,
zs1997@bjtu.edu.cn,
csyawei.zhao@gmail.com,
kunlunhe@plagh.org,
yzhao@bjtu.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10356722
发表期刊:TMM 2023
*通讯作者
1.论文简介
医学报告生成旨在为患者的医学影像自动生成类似于放射科医生的准确的医学描述,从而减轻临床医生的日常工作量。然而,由于数据偏差和长报告等问题,医学报告生成一直是一项非常具有挑战的任务。具体来说,如图1所示,本文研究发现当前医学报告生成范式主要存在以下局限:1)忽略临床医生先阅读影像再撰写报告的整体过程;2)忽略了图像-报告间的显式对齐;3)提供给解码器的信息不充分。为解决上述问题,本文提出了一种灵活的多视角生成范式(FMVP),以一种新颖的从观察到概念的生成范式自动生成医学报告。具体地,正如放射科医生在临床中所遵循的先阅读影像再疾病诊断的流程,该方法首先自动或在放射科医生的帮助下从患者的图像中获得与患者疾病相关的先验知识。此外,为了缓解预训练阶段和生成阶段之间的差距,该工作提出层次化对齐模块,通过图像区域-疾病标签间的局部隐式信息交互和图像-报告对的显式全局对比实现有效的跨模态对齐。最后,该工作提出了一种兼容的多视角知识引导的解码机制,为报告生成捕获更多的互补信息,打破了传统以视觉信息为主导的解码机制。通过在公开数据集MIMIC-CXR和IU-Xray进行相应的定量和定性实验,我们验证了FMVP模型在医学报告生成任务上的优越性能。
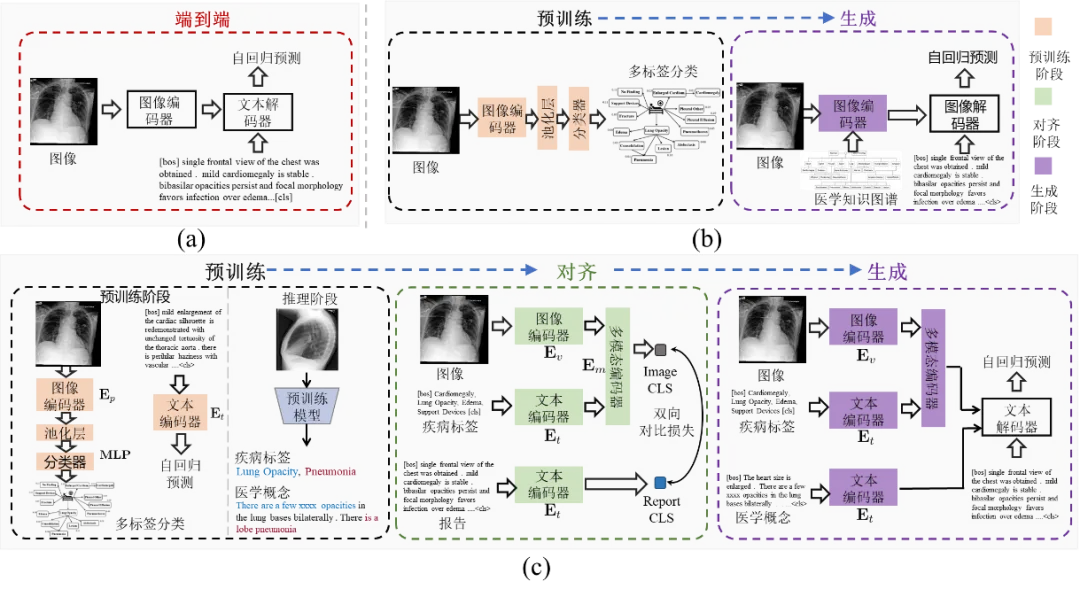
图1 本工作提出的预训练-对齐-生成范式(c)与端到端(a)和预训练-生成(b)范式之间的比较
2.方法概述
本章提出的灵活的多视角信息引导的医学报告生成(FMVP)框架如图2所示。具体地,该框架首先自动或在放射科医生的帮助下,对患者的图像进行医学观察,以获取疾病信息和相关医学概念。然后,经视觉编码器提取的视觉特征和疾病标签的语义嵌入被输入到多模态编码器中,以建立图像局部区域-疾病标签之间的关联。进一步,为了给解码器提供多样且互补的患者信息,视觉特征、疾病标签、医学概念以及待预测词之前的文本序列嵌入等多样化先验知识将被输入到提出的兼容解码器中,从而完成对下一个单词的预测。
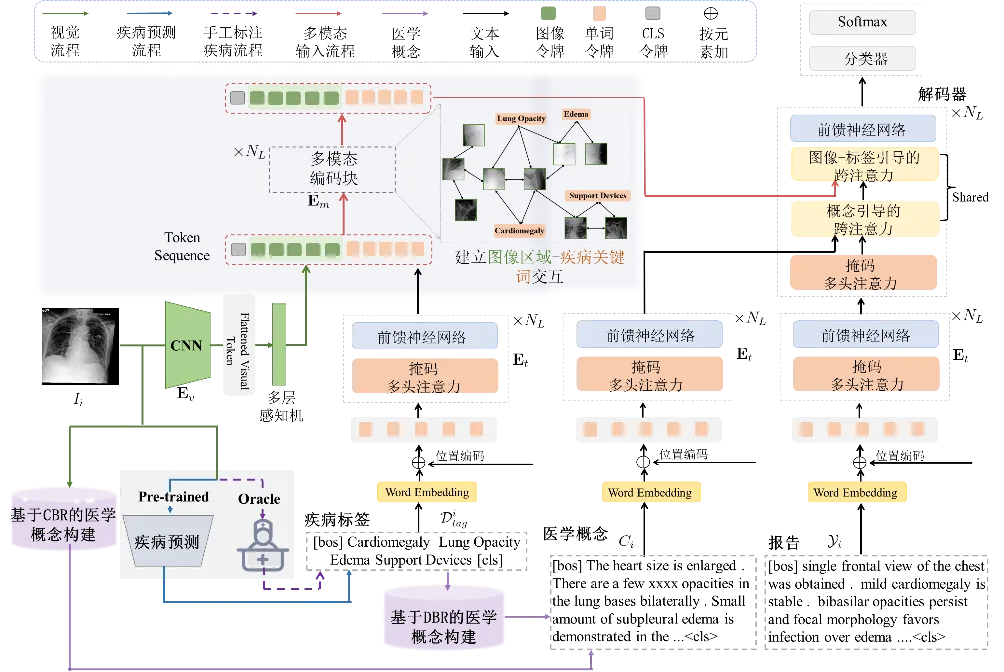
图2 FMVP模型的整体框架图
特别地,医学概念的构建是受临床医生撰写报告过程的启发。在临床场景中,利用X射线设备完成患者影像信息采集后,放射医生首先对患者图像进行初步观察,并依据经验构建患者疾病的粗略描述。本工作将上述粗略描述称为医学概念,它可以为撰写医学报告提供参考信息,防止遗漏关键放射学信息。为了模拟上述放射科医生形成医学概念的过程,本工作提出了以下两种构建方式,如图3所示,即基于病例的检索(Case-based retrieval, CBR)和基于疾病的检索(Disease-based retrieval, DBR)。 特别地,CBR构建方式是基于患者图像,通过相似度度量从预先收集的图像-报告数据对中检索出最相似的案例,并将其医学报告作为患者特定的医学概念。DBR方法则面向大规模图像-报告对的医学概念构建,利用获得的疾病标签集作为查询从模板库中检索患者疾病的通用描述。
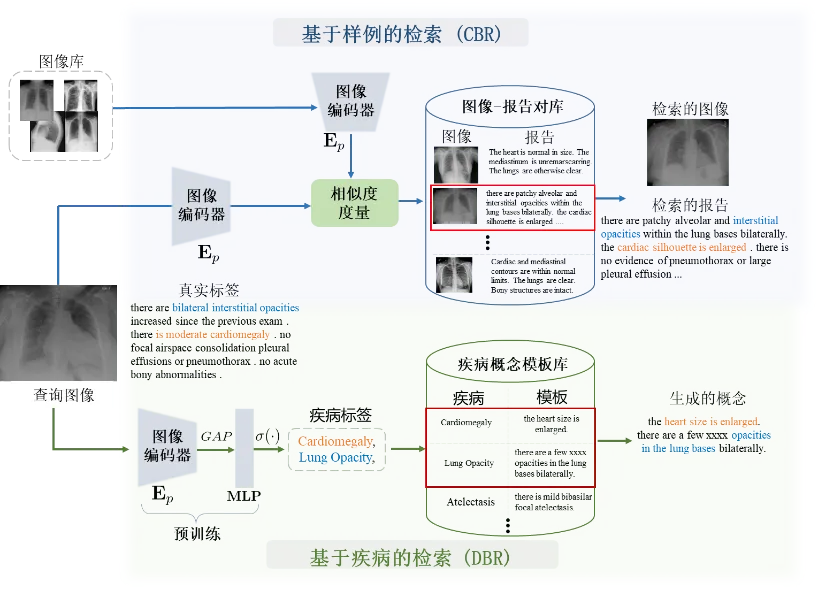
图3 基于样例/疾病检索的医学概念构建示意图
3.实验对比
为了评估提出的FMVP模型的性能,我们选择了两个广泛使用的医学报告生成数据集:IU-Xray和MIMIC-CXR。其中,IU-Xray包含7,470张X光图像和相应的3,955份放射学报告,MIMIC-CXR包括来自65,379名患者的377,110张X光图像和相应的227,827份放射学报告。表1和表2分别展示了FMVP方法与其他方法在IU-Xray数据集和MIMIC-CXR数据集上的性能比较,图4展示了FMVP模型在MIMIC-CXR数据集生成结果的定性分析,其中,相同的疾病和描述采用同一种颜色进行了标注。从定量和定性实验结果中可以看出,所提出的FMVP方法展现出了优异的性能,有效提升了生成报告的质量和准确度。
表1 不同方法在IU-Xray数据集上的性能比较
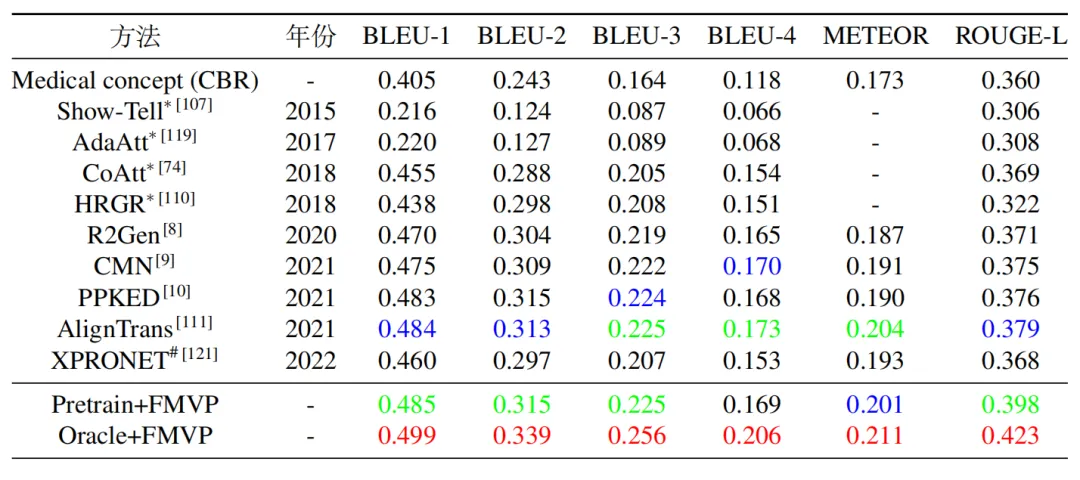
表2 不同方法在MIMIC-CXR数据集上的性能比较
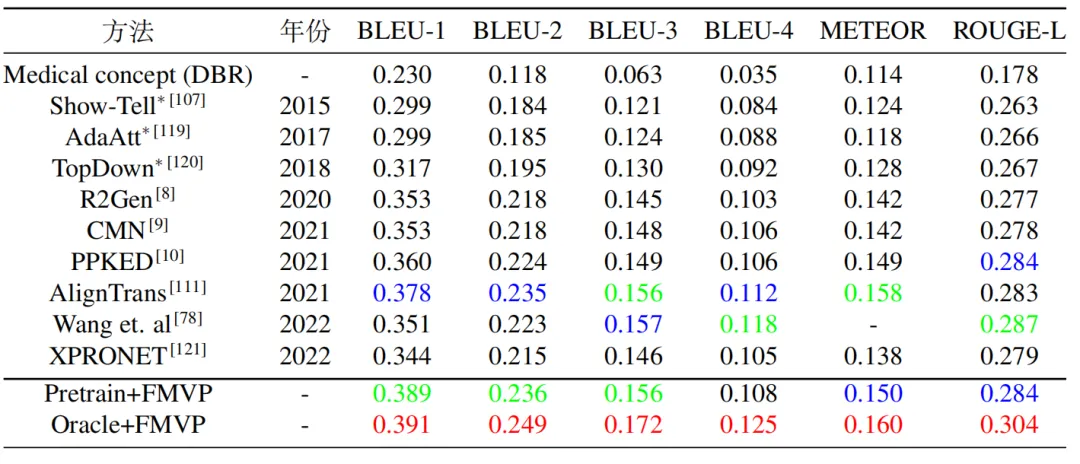
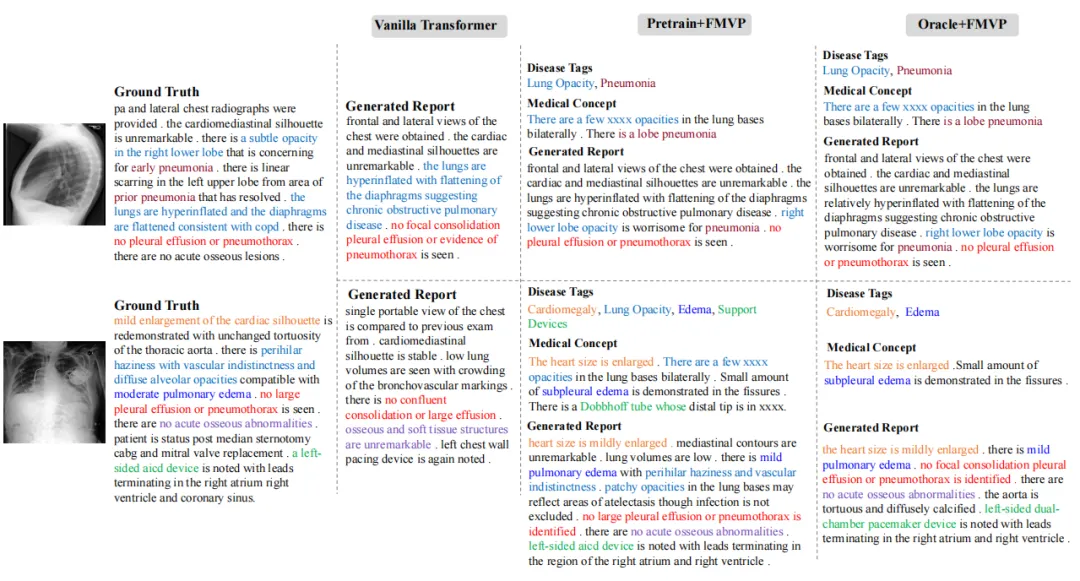
图4 不同方法在MIMIC-CXR数据集上的定性比较
03
Q-MoE: Connector for MLLMs with Text-Driven Routing
作者:
王瀚紫1,2,任佳敏1,丁一峰2,任磊2,江会星2,陈伟2,冯方向1,王小捷1*
单位:
1北京邮电大学,2理想汽车
邮箱:
{wanghanzi, jasmine_ren, fxfeng, xjwang}@bupt.edu.cn,
{wanghanzi, dingyifeng, renlei3, jianghuixing, chenwei10}@lixiang.com
论文:
https://dl.acm.org/doi/10.1145/3664647.3681369
发表期刊:ACMMM 2024
*通讯作者
1.论文简介
当前主流的多模态大模型(MLLM)主要基于大语言模型(LLM)进行模态对齐训练,将其他模态的信息对齐到大语言模型的语义空间,以利用语言模型的强大能力提升多模态场景能力。多模态大语言模型通常包括多模态编码器、多模态连接器、大语言模型三个部分,其中多模态连接器起到了连接各模态和语言模态的桥梁作用。然而,之前的大多数模态连接器,都是统一处理不同任务的各模态信息,缺乏针对特定任务的模态信息提取能力。
为了解决上述问题,我们创新性的提出了一种高效的混合专家模态连接器Q-MoE,从结构上引入文本信息的监督,进行面向任务的模态信息特征提取。模型架构主要创新点是将混合专家架构设计为通用专家、多任务专家,其中通用专家负责提取通用视觉信息,多任务专家负责提取任务相关视觉信息。通过Cross-Router路由结构实现对多任务专家激活筛选,进而达成对任务相关的视觉信息提取与转化。
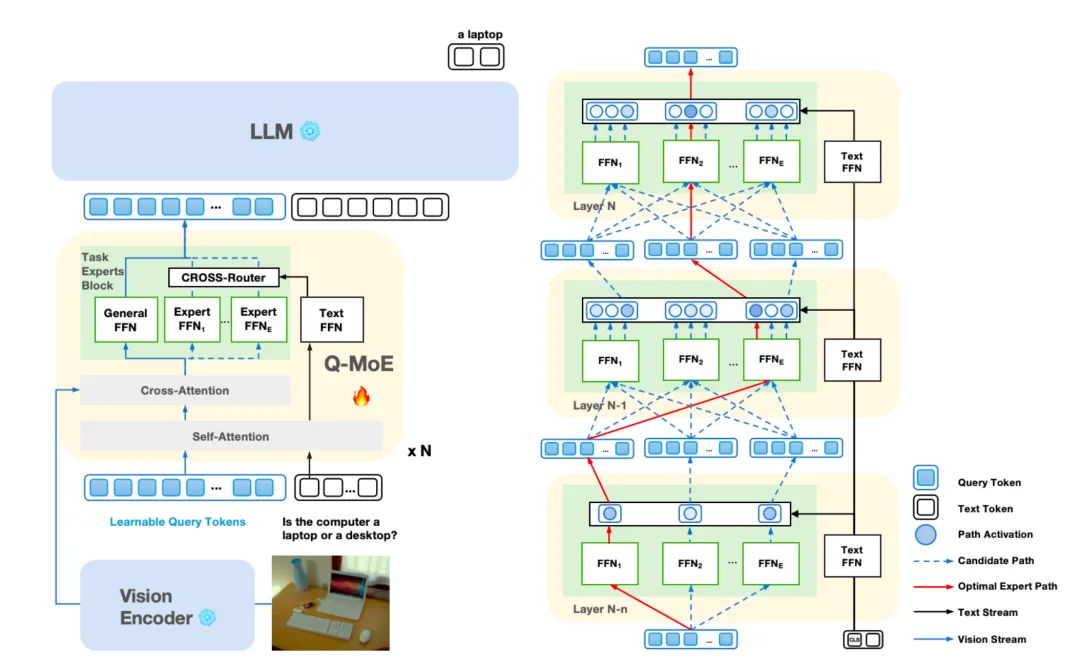
图1 Q-MoE结构和基于最优专家路径的训练策略
此外,为了更好的面向任务进行模态信息特征提取,我们同时提出了一种基于最优路径决策的混合专家路由策略。传统的MoE路由策略主要是每层的TopK路由策略,不会考虑前面层的路由结果,本质是一种局部最优策略(贪心搜索策略)。本文提出的最优路径策略,是一种全局路径最优策略,会结合前面层数路由结果决策本层的路由策略。最终寻找到的一条最优路径可以视为一种专家。
Q-MoE在模型结构和算法策略的双重创新下,使得其在跨模态多任务学习中性能显著超越已有SOTA多模态连接器Q-former。
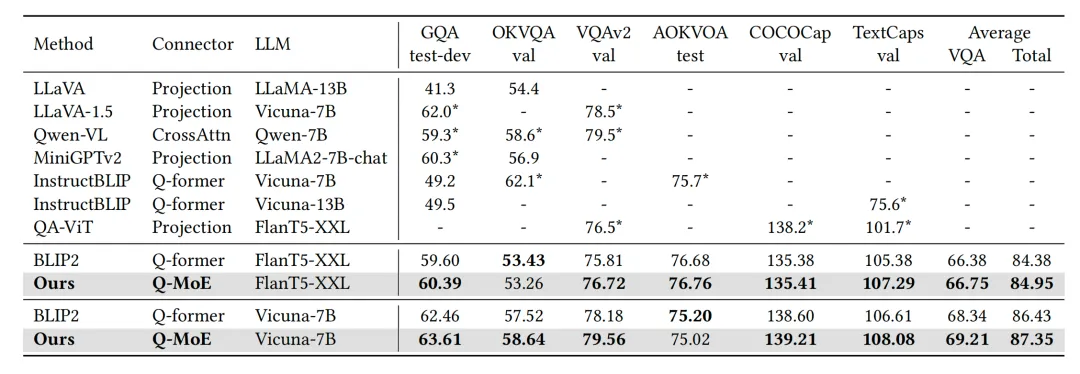
图2 多任务设定下的微调结果
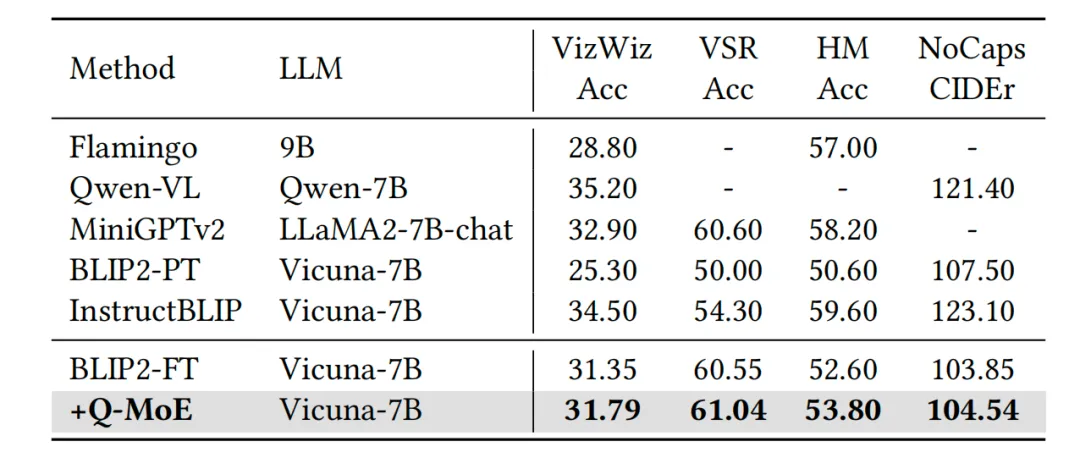
图3 域外数据集上zero-shot效果
04
CartoonNet: Cartoon Parsing with Semantic Consistency and Structure Correlation
基于语义一致性和结构关联的卡通解析
作者:
乔建军,段梦宇,吴晓*,宋雨佩
单位:
西南交通大学计算机与人工智能学院
邮箱:
qjjai56@gmail.com,
duanmengyu369@gmail.com,
wuxiaohk@gmail.com,
yupei-song@my.swjtu.edu.cn
论文:
https://dl.acm.org/doi/pdf/10.1145/3664647.3680879
发表会议:ACMMM 2024
*通讯作者
1.引言
卡通解析是面向卡通相关应用的重要任务,旨在对卡通图像的身体部位进行分割。如图1所示,由于卡通角色具有复杂的外观、抽象的绘画风格以及不规则的结构,卡通解析依然是一项具有挑战性的任务。本文提出了一种新颖的方法,名为 CartoonNet,旨在通过语义一致性学习和结构关联建模解决卡通解析中的视觉多样性和结构复杂性问题。所提出的方法设计了基于记忆结构的语义一致性学习模块,用于学习卡通角色展示的多样化外观。记忆结构存储了不同样本的特征,并根据与新样本的相关性检索存储的样本,然后采用自注意力机制对检索的样本和新样本中具有多样视觉外观的身体部位的语义进行一致性学习,旨在提高网络的语义推理能力。为了捕捉卡通图像中复杂的结构信息,提出了一个结构关联模块。该模块通过利用图注意力网络和主体感知机制实现了结构关联,使网络能够解析具有复杂结构的卡通图像。在卡通解析和人体解析数据集上的实验表明,所提出的方法在卡通解析任务中优于现有的方法,并且在人体解析任务中也取得了具有竞争力的结果。

图1 卡通图像示例
2.方法
论文提出了一种解决卡通解析的方法,名为CartoonNet,旨在应对卡通角色视觉多样性和结构复杂性带来的挑战。所提出的方法集成了外观学习和结构建模方法,旨在捕捉多样化视觉外观的特征并建模复杂的结构表示。方法框架如图2所示,所提出的方法使用 ConvNet骨干网络来编码和提取卡通图像的特征。然后,构建具有三列结构的记忆库,将其用于存储多样化样本的特征。在每次迭代时,测量特征相似性,根据相似性将存储的特征与当前图像进行匹配,以此来回忆先前的有用经验并将其用于辅助解析当前样本。为实现不同样本的一致性学习,采用自注意力机制将先前的经验整合到当前样本中,实现不同样本之间的关联和一致性学习。为了学习复杂身体部位之间的关联,设计了主体感知结构关联策略。该策略结合了图注意力网络和主体感知机制,以促进身体部位之间的关联。图注意力网络建模了结构表示并捕捉了不同身体部位之间的重要关系,主体感知机制学习了反映卡通图像复杂结构特性的关键身体部位。
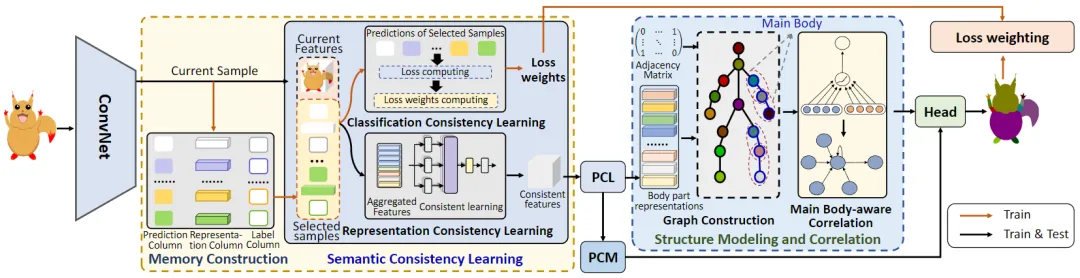
图2 CartoonNet网络框架图
3.实验分析
所提出的CartoonNet在CartoonSet和Cartoon Dog两个卡通解析基准数据集上进行了测试,实验性能结果比较分别见表1和表2。从表中可以看出,所提出的方法性能优于现有的方法,在卡通解析任务上达到了最优性能。此外,所提出的方法还在人体解析数据集LIP上进行了测试,以验证其泛化性能。从表3的实验结果中可以看出,CartoonNet虽然为卡通解析任务提出,但其在人体解析任务上也实现了具有竞争性的结果。图3展示了所提出的方法与主流方法的卡通解析可视化比较,从图中可以看出,所提出的方法在多样和复杂卡通图像上的解析性能更好。
表1 在CartoonSet数据集上的性能比较
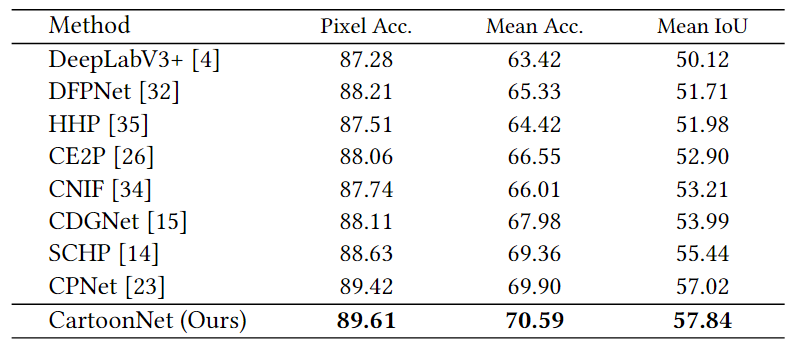
表2 在Cartoon Dog数据集上的性能比较
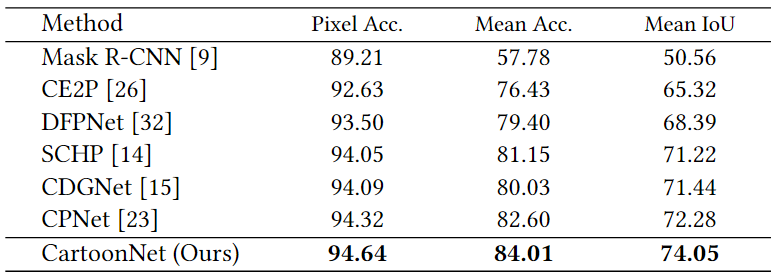
表3 在人体解析数据集LIP上的性能比较
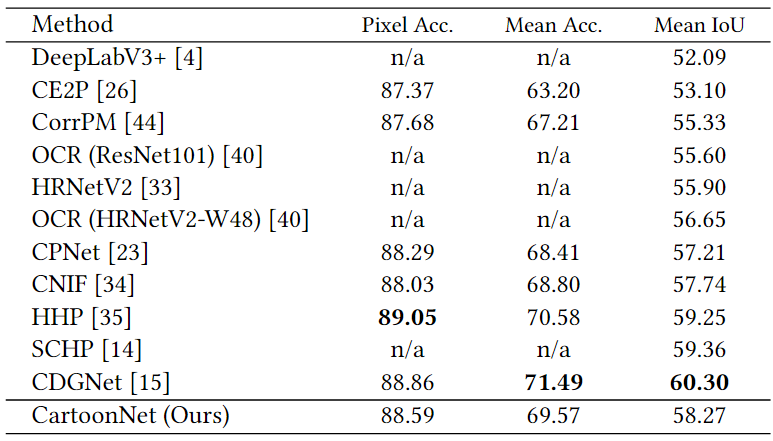

图3 CartoonNet与主流方法的可视化比较
05
Deep Neighborhood-Preserving Hashing with Quadratic Spherical Mutual Information for Cross-Modal Retrieval
作者:
秦琦冰1,3,霍亚东2,黄磊3,代江艳1,张辉辉1,*,张文峰4,*
单位:
1潍坊学院,2曲阜师范大学,3中国海洋大学,4重庆师范大学
邮箱:
qinbing@wfu.edu.cn,itzhangwf@cqnu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10379137
代码:
https://github.com/QinLab-WFU/DNpH
发表期刊:TMM 2023
*通讯作者
1.引言
得益于低存储成本与高查询效率,深度跨模态哈希已成为当前处理大规模跨模态图文检索的有力工具。其核心目标是通过学习鲁棒的哈希映射,精准捕获原始的邻居关系,从而构建一个高度可分离的离散空间,如图1中所示。然而,现有基于亲和匹配或局部排序的深度跨模态哈希方法仅构建简单的局部语义关系,导致较高的邻居模糊性,如图1中所示。为进一步提高相似性检索的性能,相关工作通常引入额外的正则化项或边缘阈值,不可避免地增加超参数调整的额外开销。

图1 基于邻居保持的深度跨模态哈希框架研究动机
2.方法概述
本文通过信息理论的扩展来量化邻居模糊性,提出了一种基于邻居保持的深度跨模态哈希框架,以学习区分性的哈希编码。该方法主要包括两部分,如图2所示:(1)基于信息理论,设计了跨模态二元球面互信息损失,以最小化邻居模糊性,有效捕捉原始邻居关系。与其他方法相比,该损失函数无需调整任何超参数。(2)为避免模型陷入局部最优,提出了一种平方夹紧优化方法,显著提高了模型优化的稳定性。
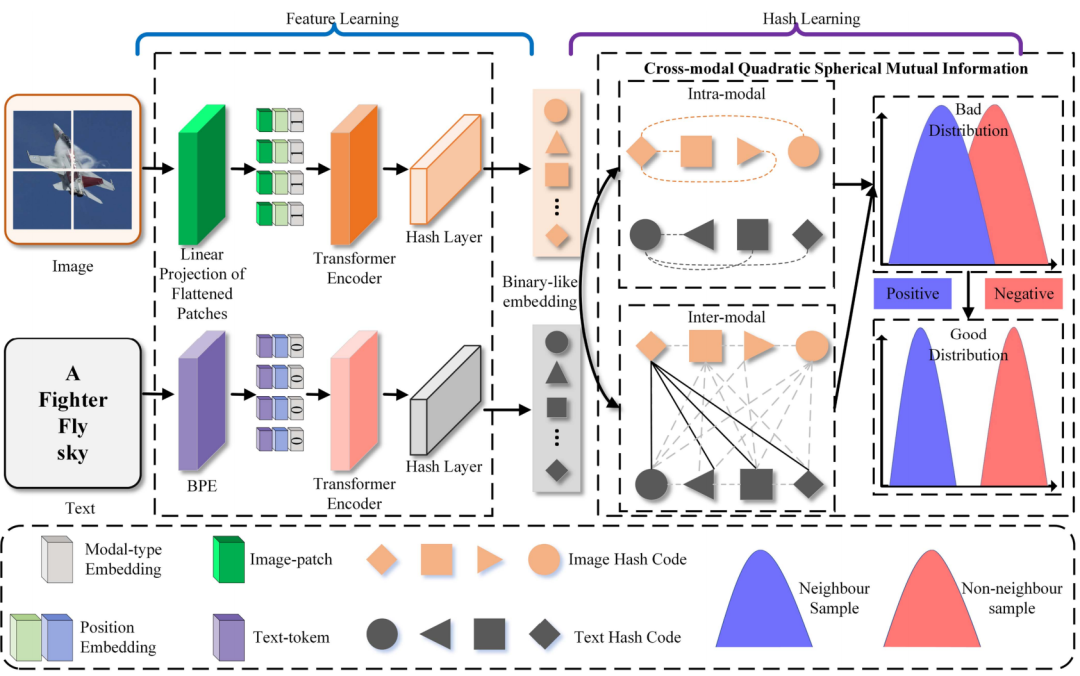
图2 本文方法的框架图
3.实验结果
在多个公开数据集上的实验验证了本文方法的有效性。表1列出了本文方法与其他对比方法在MIRFLICKR-25K、NUS-WIDE、MS COCO和IAPR TC-12数据集上的mAP结果,图11展示了基于t-SNE技术的哈希编码可视化结果,表5展示了主要模块的消融实验结果。实验结果表明,本文方法显著提升了深度跨模态哈希的性能。
表1 MIRFLICKR-25K、NUS-WIDE、MS COCO以及 IAPR TC-12数据集上基于16bits、32bits和64bits的mAP结果
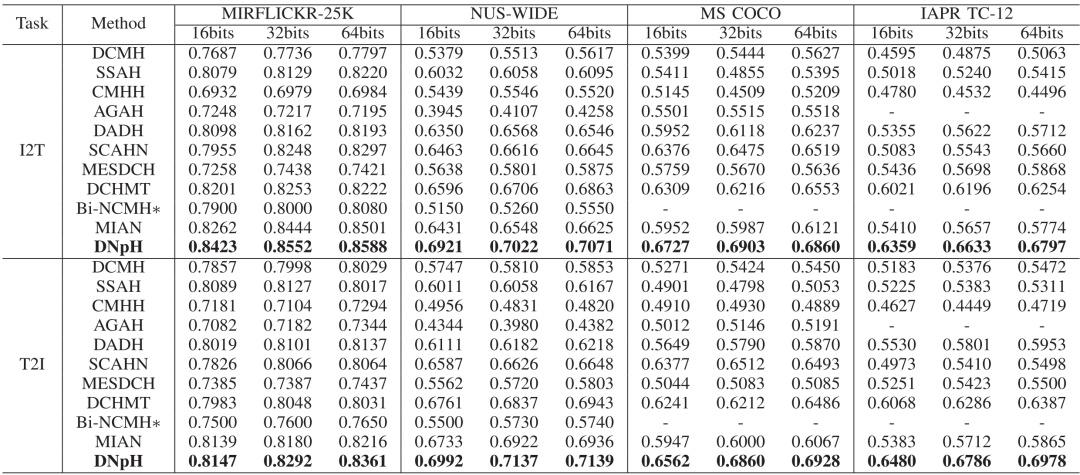
表2 消融实验
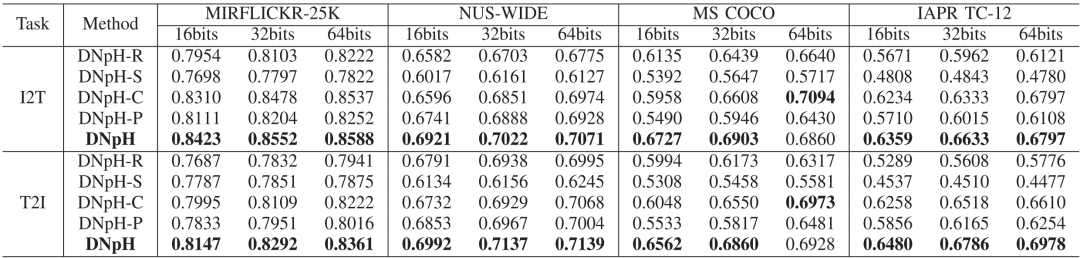
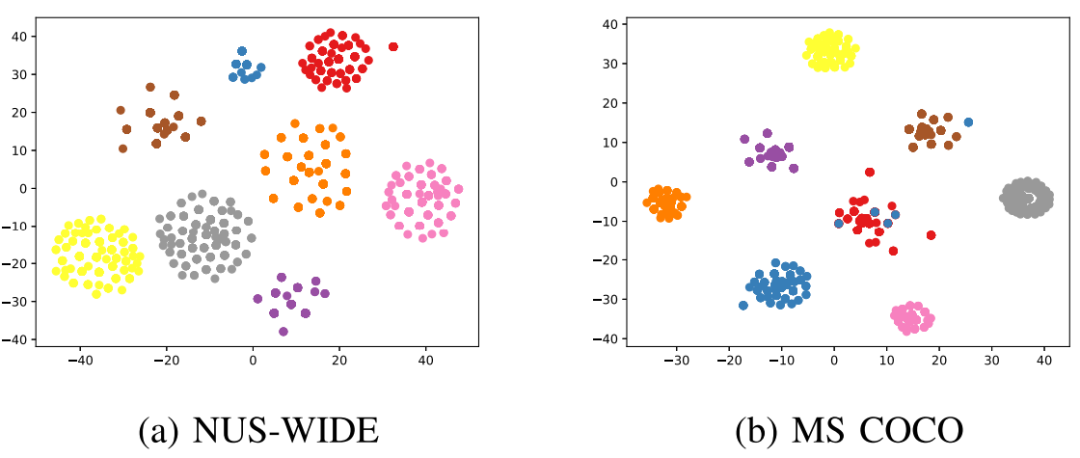
图3 NUS-WIDE和MS COCO数据集上哈希编码的t-SNE可视化结果

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号