
【论文导读】2024年论文导读第二十六期
【论文导读】2024年论文导读第二十六期
CCF多媒体专委会 2024年12月31日 22:33 江苏


论文导读
2024年论文导读第二十六期(总第一百一十七期)
目 录
|
1 |
Attribute-Guided Collaborative Learning for Partial Person Re-Identification |
|
2 |
Deep Unrestricted Document Image Rectification |
|
3 |
Text-to-Image Person Re-identification Based on Multimodal Graph Convolutional Network |
|
4 |
Test-Time Linear Out-of-Distribution Detection |
|
5 |
Learning Context with Priors for 3D Interacting Hand-Object Pose Estimation |
01
Attribute-Guided Collaborative Learning for Partial Person Re-Identification
作者:
张昊宇1,2,刘萌3,*,李裕宏4,严明4,高赞5,常晓军6,聂礼强1,*
单位:
1哈尔滨工业大学(深圳),2鹏城实验室,3山东建筑大学,4阿里巴巴,5齐鲁工业大学,6悉尼科技大学
邮箱:
zhang.hy.2019@gmail.com,
mengliu.sdu@gmail.com,
nieliqiang@gmail.com
论文:
https://ieeexplore.ieee.org/document/10239469
发表期刊:TPAMI 2023
*通讯作者
1.研究背景和动机
在现实场景中,行人往往会受到物体或其他行人的遮挡,导致无法获取完整的行人信息。这一问题催生了局部行人重识别(Partial Person Re-identification)任务,其目标是根据给定的局部查询图像,检索在不同摄像头下拍摄的与之身份匹配的全身行人图像。尽管现有研究在这一领域取得了显著进展,但仍存在以下局限性:(1)部分方法引入了人体关键点作为辅助信息,但忽视了噪声关键点对模型性能的负面影响,如图1(b)所示,噪声关键点的存在会干扰模型的学习过程。(2)现有方法学习到的视觉表征对人体姿态和周围环境变化非常敏感,难以有效提取身份的本质特征,表现出较差的鲁棒性。例如,同一行人在不同姿态下(如行走与骑行)所产生的身份表征差异较大,如图1(c)所示。(3)目前的方法主要侧重于图像级约束(如图像分类)来促进模型学习,但此类约束难以支持更为细粒度的局部表征(如关键点)的学习。
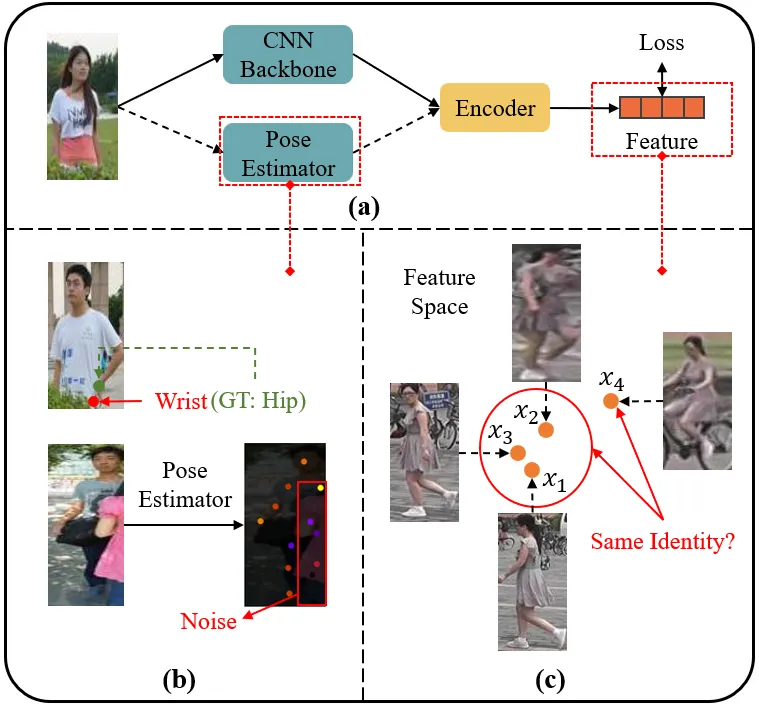
图1 (a)局部行人重识别方法的一般流程;(b)错误的关键点识别;(c)不同姿态对同一行人视觉表征的影响。
2.方法介绍
为了解决上述问题,本文提出了一种属性引导的协同学习框架(AGCL),如图2所示。具体来说,我们首先利用特征提取模块来获取行人的多样化信息,包括全局视觉特征、局部视觉特征以及文本属性特征。接下来,为解决局限(1),我们引入了一种自适应阈值引导的掩码图卷积算法。该算法能够基于全局和局部视觉特征构建人体骨架图,动态地根据节点的置信度删除不可信的连接边,从而抑制噪声关键点的传播。为应对局限(2),我们结合了人体的固有属性,并考虑人体关键点与属性之间的匹配关系,如图3所示,设计了一种循环异构图卷积网络。该网络通过图内聚合、图间交互和图内传播三个阶段,能够有效地融合跨模态的行人信息,生成更加鲁棒的行人身份表征,显著提高了模型对不同行人姿态和环境变化的适应性。为解决局限(3),我们基于人体的轴对称特性,设计了一种新颖的基于人体部位的相似性约束,从而有效提升了关键点之间的相似性度量和局部特征的判别能力。
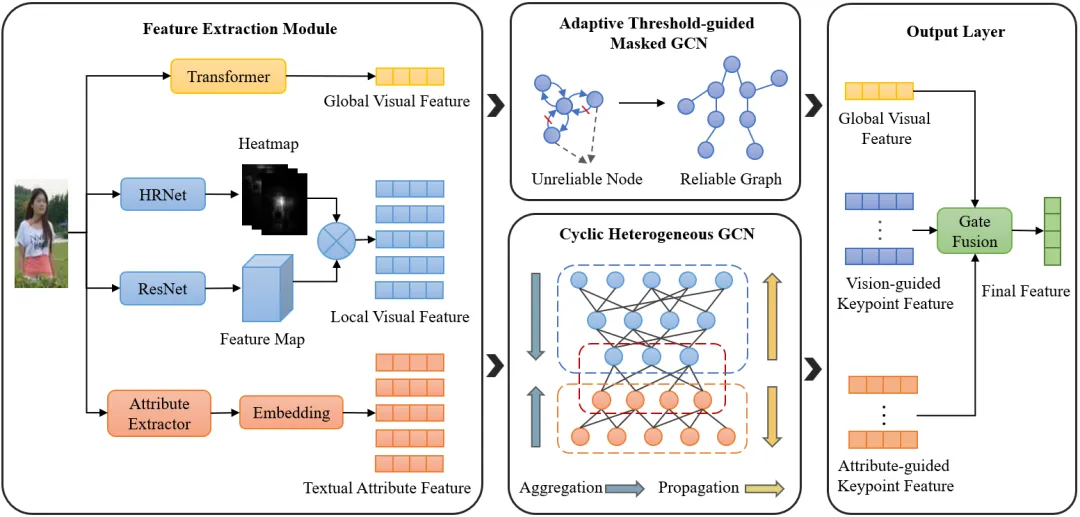
图2 整体框架图
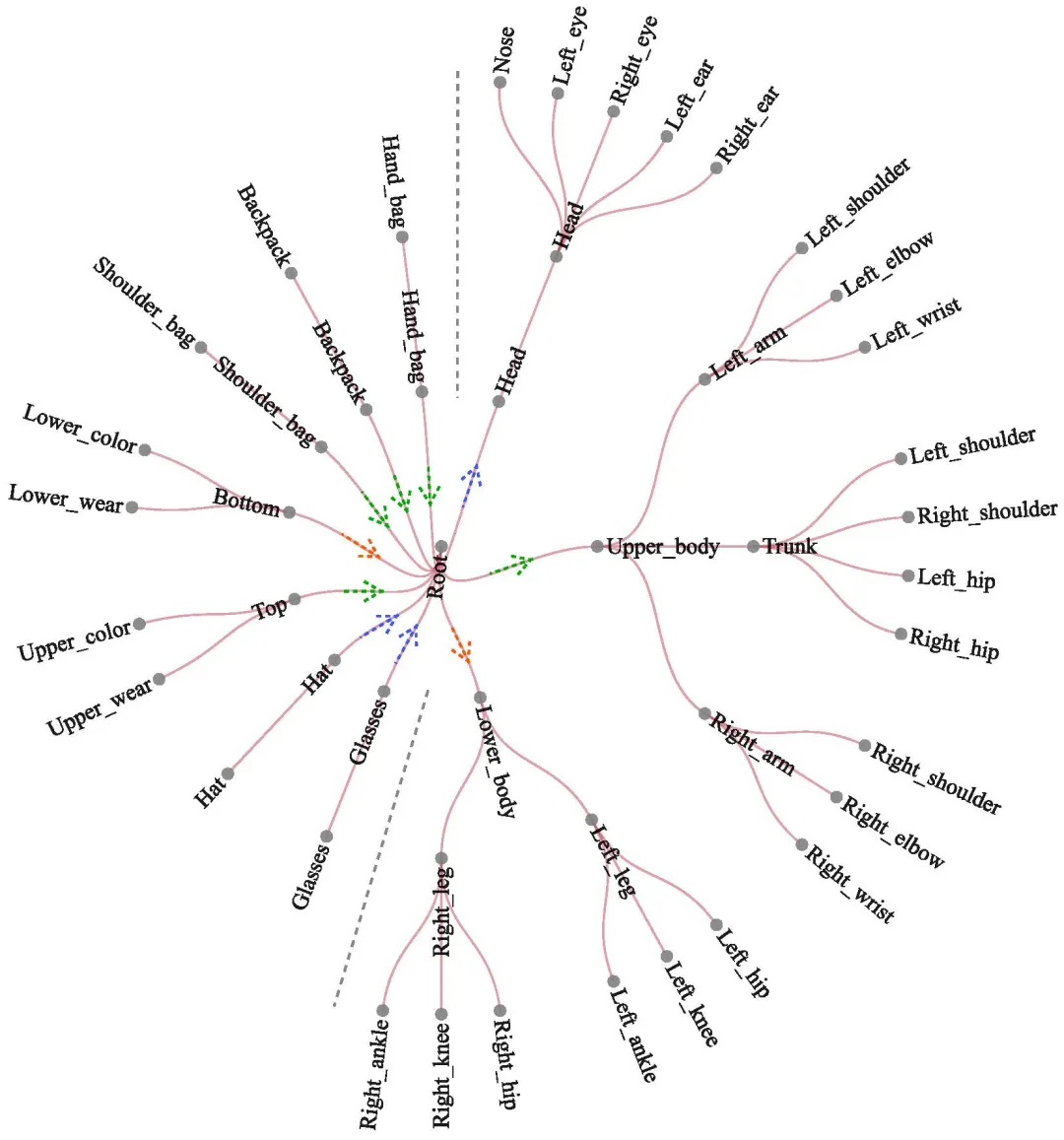
图3 循环异构图卷积网络中的节点信息流
3.实验结果
为了评估所提出的AGCL方法的有效性,我们在五个基准数据集上进行了广泛实验。表1展示了AGCL与其他先进方法在两个局部行人重识别数据集上的比较结果。从结果中可以看到,我们的方法在多个指标上取得了显著提升,验证了AGCL在局部行人重识别任务中的有效性。为了验证行人表征的有效性,我们利用t-SNE对其进行了可视化,如图4所示。结果表明,query和gallery图像在特征空间是十分接近的,充分证明了AGCL方法可以获得鲁棒且一致的行人表征。图5展示了AGCL在不同数据集上的Top-10排序结果,进一步验证了整体方法的优越性。
表1 在Partial-REID和Partial-iLIDS数据集上的性能比较
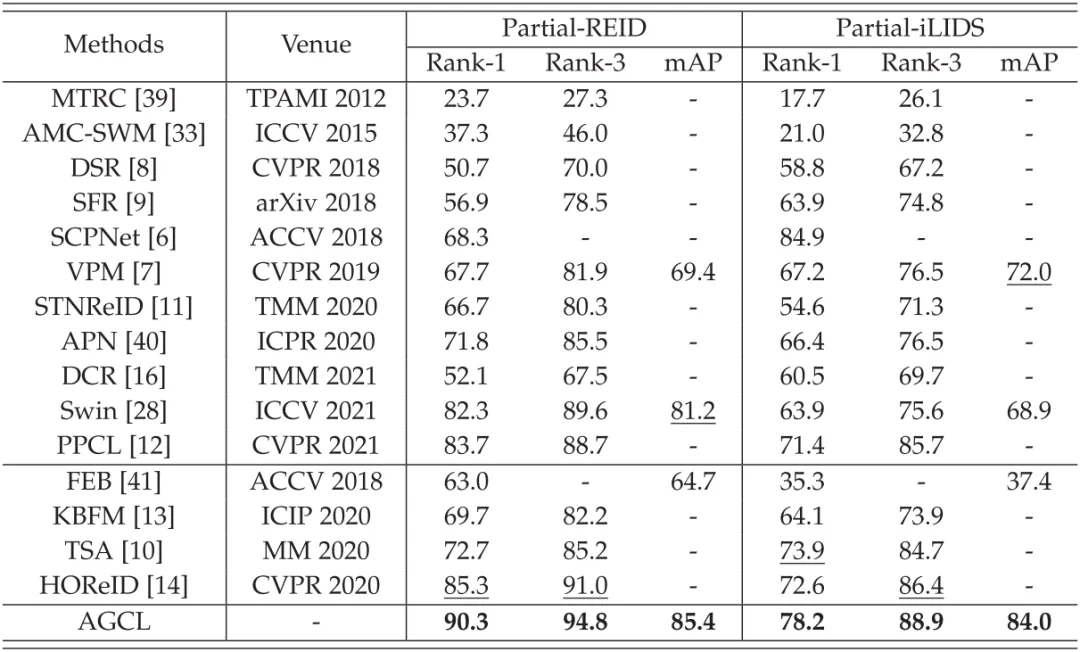
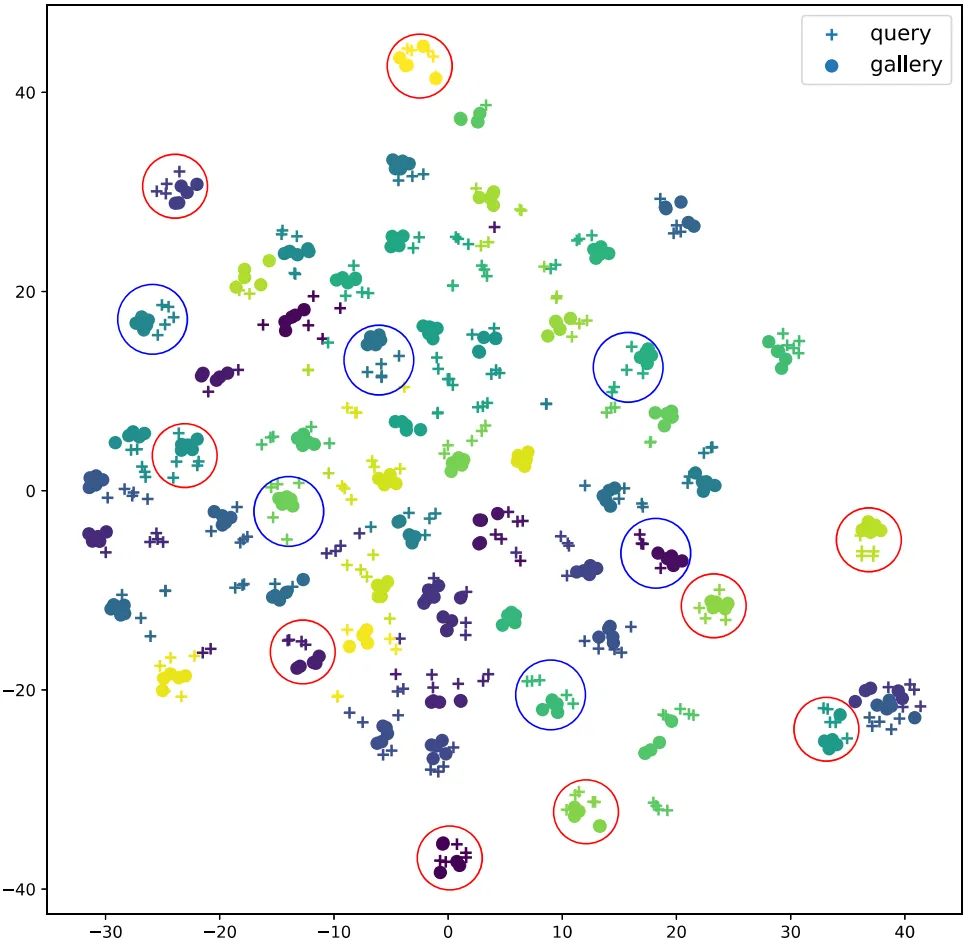
图4 t-SNE可视化

图5 在不同数据集上Top-10结果的对比
02
Deep Unrestricted Document Image Rectification
作者:
冯浩1,刘绍锴1,邓家俊2,周文罡1,李厚强1
单位:
1中国科学技术大学,2阿德莱德大学
邮箱:
haof@mail.ustc.edu.cn,
liushaokai@mail.ustc.edu.cn,
jiajun.deng@adelaide.edu.au,
zhwg@ustc.edu.cn,
lihq@ustc.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10374269
代码:
https://github.com/fh2019ustc/DocTr-Plus
Demo:
https://demo.doctrp.top/
发表期刊:TMM 2023
1.研究背景与动机
文档图像校正技术在当今数字化转型中扮演着越来越重要的角色,其应用场景涵盖从办公自动化到移动文档扫描等多个领域。然而,现有的基于深度学习的解决方案存在明显的局限性,即要求输入图像包含完整的文档边界。这种局限性与实际应用场景形成了显著的鸿沟,因为在日常拍摄环境中,用户往往会遇到三种不同情况:(a)完整边界、(b)部分边界缺失,或(c)完全不含边界的文档图像。当现有方法面对后两种情况时,其矫正质量会出现明显的性能下降,有时甚至会导致完全失效。这种实际应用中的痛点严重制约了文档图像校正技术的普及和推广,也凸显出开发更具通用性的解决方案的迫切需求。

图1 常见的三类形变文档图像
2.技术方法与创新
针对这一核心问题,本文提出了一个创新的通用文档图像校正框架DocTr++,重新定义了各类形变文档图像与无形变文档图像之间的像素映射关系。方法框架图如图所示。

图2 DocTr++网络框架
该方法的核心在于其精心设计的多尺度编码器-解码器架构。在特征提取端,编码器采用了三个级联的子模块,每个子模块包含两个标准的Transformer编码层,通过自注意力机制高效捕获文档的结构特征。这种设计使得模型能够同时获取两个层面的信息:高分辨率层面的精细纹理细节,以及低分辨率层面的高级语义特征。在解码端,DocTr++引入了一个创新性的设计-可学习的矫正提示向量序列。这些向量经过训练,每个向量都能够精确定位并关注输入形变图像的特定区域,从而实现了对形变文档图像的结构理解和精确矫正。
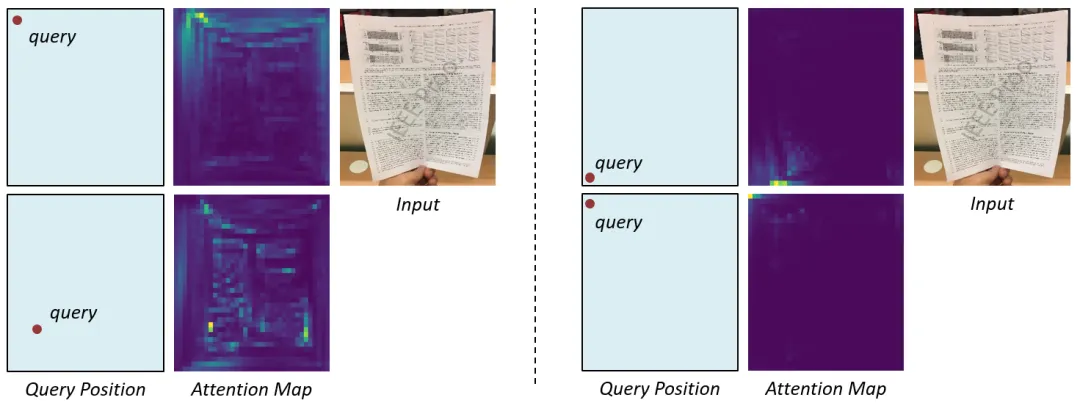
图3 DocTr++中encoder和decoder的attention机制可视化

图4 DocTr++中encoder和decoder的attention机制可视化
3.主要实验结果及可视化结果
DocTr++在多个维度的实验评估中都展现出了卓越的性能。在传统的完整边界文档测试集上,该方法不仅保持了与现有最优方法相当的性能,更在处理更具挑战性的部分边界和无边界场景时展现出明显优势。实验表明,DocTr++能够有效处理多种类型的文档变形,包括试卷、文本段落、书页和手写文档等,展示出强大的泛化能力和实用价值。
表1 在有边界(左)和无边界(右)测试基准上的定量结果
下图展示了各类形变文档图像的矫正结果,包括试卷、文本段落、书页、手写文档等。


图5 DocTr++矫正结果可视化
下图展示了DocTr++的文档矫正能力对于多模态大模型的提升。所用的模型为Qwen-VL。左图为形变文档图的问答结果,右图为矫正图的问答结果。

图6 DocTr++的文档矫正能力对于Qwen-VL的提升示例
03
Text-to-Image Person Re-identification Based on Multimodal Graph Convolutional Network
作者:
韩光1,林敏1,李紫阳1,赵海涛1,Sam Kwong2
单位:
1南京邮电大学,
2香港岭南大学
邮箱:
hanguang8848@njupt.edu.cn,
1221014328@njupt.edu.cn,
1222014523@njupt.edu.cn,
zhaoht@njupt.edu.cn,
samkwong@ln.edu.hk
论文:
https://ieeexplore.ieee.org/document/10365330
发表期刊:
TMM 2023
1.论文简介
文本到图像的行人重识别(ReID)是一个图文跨模态检索的子任务,近年来的方法大都遵循双流网络结构(图1(a)),将提取的图像和文本特征映射到一个潜在的公共空间中,直接计算两者相似度,这种方法中图像和文本是没有进行交互的,这导致网络很难学习到高质量高语义的特征表示。因此需要一种更简洁有效的结构(图1(b))来实现多模态特征之间的交互。此外,对于图像和文本数据,在特征抽取的过程中,都分别以一种非常规则的方式被建模,例如,图像数据可以通过CNN抽取图像网格嵌入,或是通过Transformer抽取图像补丁嵌入,文本数据可以通过Bert抽取文本嵌入。但这样的建模方式在一开始就会忽略输入嵌入之间的固有关系。本文提出一种更加灵活的方式来处理多模态数据,将数据视为图表示(图1(c)),这样就可以通过网络节点之间的消息传递方式完成多模态信息的提取和交互。在三个公共数据集:CUHK-PEDES、ICFG-PEDES和RSTPReID上的测试结果表明,其可以达到SOTA级别的性能。
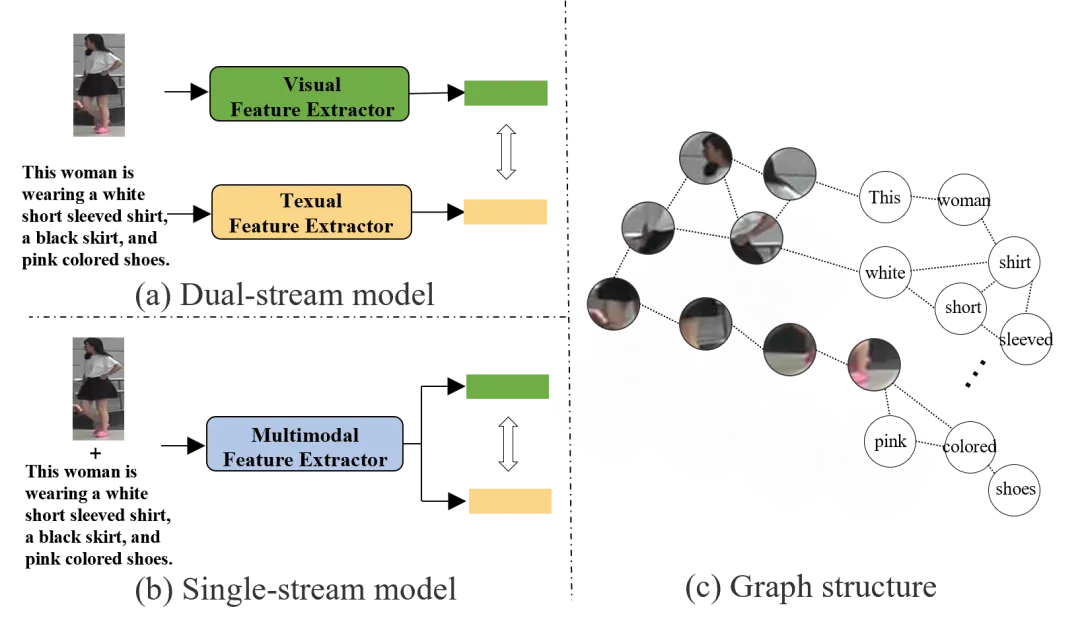
图1 常见的两种模型结构以及图结构建模方式
2.论文方法
本文提出的算法整体框架如图2所示,主要由图的构建、基于图的多模态特征提取器和不对称多级特征对齐模块等部分组成。输入一个图像-文本对,将图像分割成补丁,文本分割成词块,将其当作是一个个图节点。对每个图节点构建它的K-最近邻图,边特征表示中心节点和它的相邻节点之间的关系。首先,基于图的多模态特征提取器是一个单流网络,通过堆叠12个多模态图卷积(MMGCN)模块来实现两种模态特征提取和特征融合的统一。然后,为了实现图像和文本之间更为细粒度的特征对齐,设计了一个不对称多级特征对齐模块,该模块分为视觉分支和文本分支。在视觉分支上引入图池化,通过对图节点的分类来渐进式划分图像的局部特征具体;在文本分支上引入文本自适应模块,由多个GCN层组成。最后,提出基于相似度分布和互信息的跨模态表征匹配策略来实现跨模态对齐。
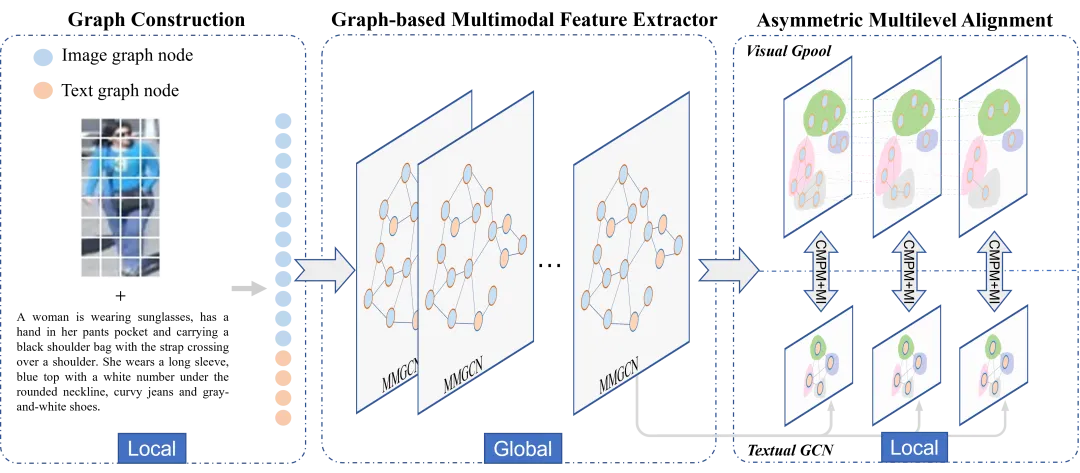
图2 基于多模态图卷积神经网络的文本行人重识别的整体框架图
3. 实验分析
本文所提出的算法在CUHK-PEDES、ICFG-PEDES和RSTPReid数据集上与几种先进方法进行了比较,实验结果分别如表1、2和3所示。在最流行的CUHK-PEDES数据集上,本文算法大大超过了现有方法,在Rank-1、Rank-5和 Rank-10上分别达到了69.40%、87.07%
和90.82%。在Rank-1指标上,本文算法比之前最好的双流特征提取网络TIPCB提高了5.14%,比最新的单流特征提取网络IVT提高了3.81%。在ICFG-PEDES和RSTPReid数据集上,与IVT算法相比,本文算法也实现了相同的性能提升,分别为4.16%和6.25%。
表1 所提出的算法与其他先进算法在CUHK-PEDES数据集上的实验结果比较
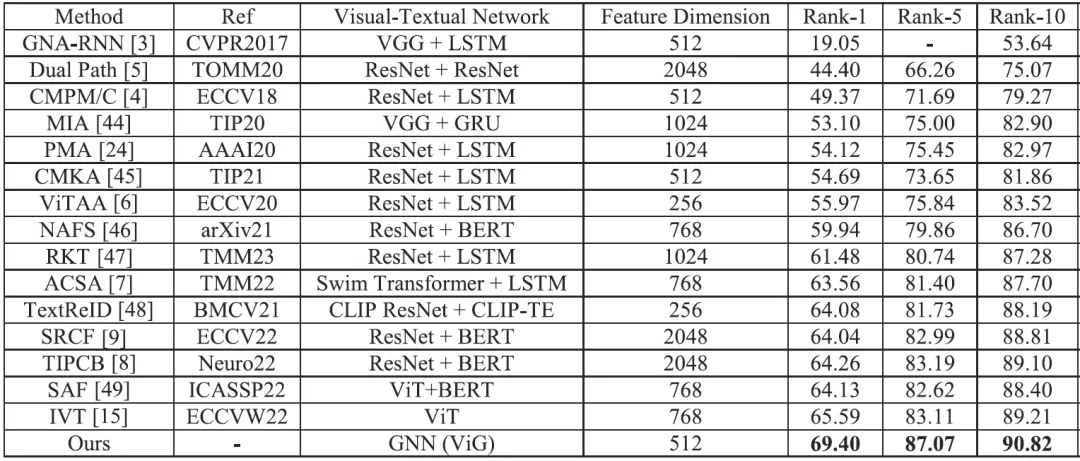
表2 本文提出的算法与其他最先进的算法在ICFG-PEDES数据集上的比较
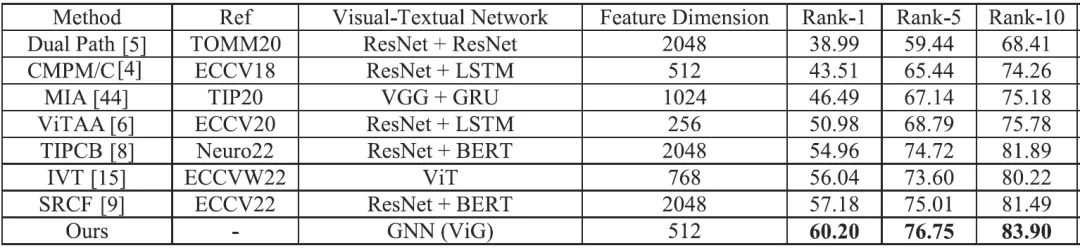
表3 本文提出的算法与其他最先进的算法在RSTPReid数据集上的比较

为了更好地探讨多模态特征提取的有效性和Visual Gpool对局部特征的划分能力,图3展示了MMGCN经过特征提取和融合后图节点之间的关系。五角星代表中心节点,与五角星颜色相同的圆代表中心节点的邻近节点。从可视化结果来看,图像的中心节点聚合了其相邻的图像节点和部分文本节点,表明了本文多模态特征提取的有效性。图4展示了图像节点的聚类结果。从可视化结果来看,Visual Gpool对所有图像节点进行了软聚类,不同颜色的圆圈代表不同的节点聚类,区域边缘的划分非常准确,表明了其对局部特征的分割效果。

图3 MMGCN后图形节点关系的可视化

图4 Visual Gpool 实现图像节点聚类结果的可视化
04
Test-Time Linear Out-of-Distribution Detection
作者:
樊可1*, 刘童2*, 裘星宇1, 王艺楷1,怀莲2†,上官泽钰2,苟爽2,刘凤剑2,傅雨倩1, 付彦伟1, 姜幸群2
单位:
1复旦大学,2京东方科技集团股份有限公司
邮箱:
kfan21@m.fudan.edu.cn,
liutongcto@boe.com.cn,
xyqiu20@fudan.edu.cn,
yikaiwang19@fudan.edu.cn,
huailian@boe.com.cn,
shangguanzeyu@boe.com.cn,
goushuang@boe.com.cn,
liufengjian@boe.com.cn,
fuyq20@fudan.edu.cn,
yanweifu@fudan.edu.cn,
jiangxingqun@boe.com.cn
论文:
https://openaccess.thecvf.com/content/CVPR2024/papers/Fan_Test-Time_Linear_Out-of-Distribution_Detection_CVPR_2024_paper.pdf
发表会议:CVPR 2024
*共同一作 †通讯作者
1.问题背景
在深度学习领域,分布外检测(Out-of-Distribution Detection, OOD)问题的目标是识别那些不属于模型训练数据分布的输入样本。神经网络通常在处理与训练数据分布相似的样本(称为分布内数据)时表现良好,但在遇到分布外数据时,可能会产生过高的置信度,并错误地将这些数据归为分布内类别。分布外检测的核心目标是准确识别这些分布外样本,并发出警示,表明模型的预测可能不可靠。
在实际应用中,OOD检测对深度学习模型的安全性和可靠性至关重要。典型的OOD检测方法会在特征空间、logit空间、梯度空间或原始图像空间中,寻找不符合训练数据分布的样本。我们观察到,分布外数据与分布内数据在特征空间中呈现出接近线性可分的特性。此外,当前OOD检测算法生成的评分与神经网络特征在多个数据集上显示出线性相关性。
2.实验方法
本文从测试时学习(Test-time Learning)的角度出发,提出了一种基于线性模型的算法——RTL(Robust Test-time Linear method)。该方法充分利用数据特征及其打分分布信息,对批量样本同时进行OOD评分,从而提高分布外检测精度。
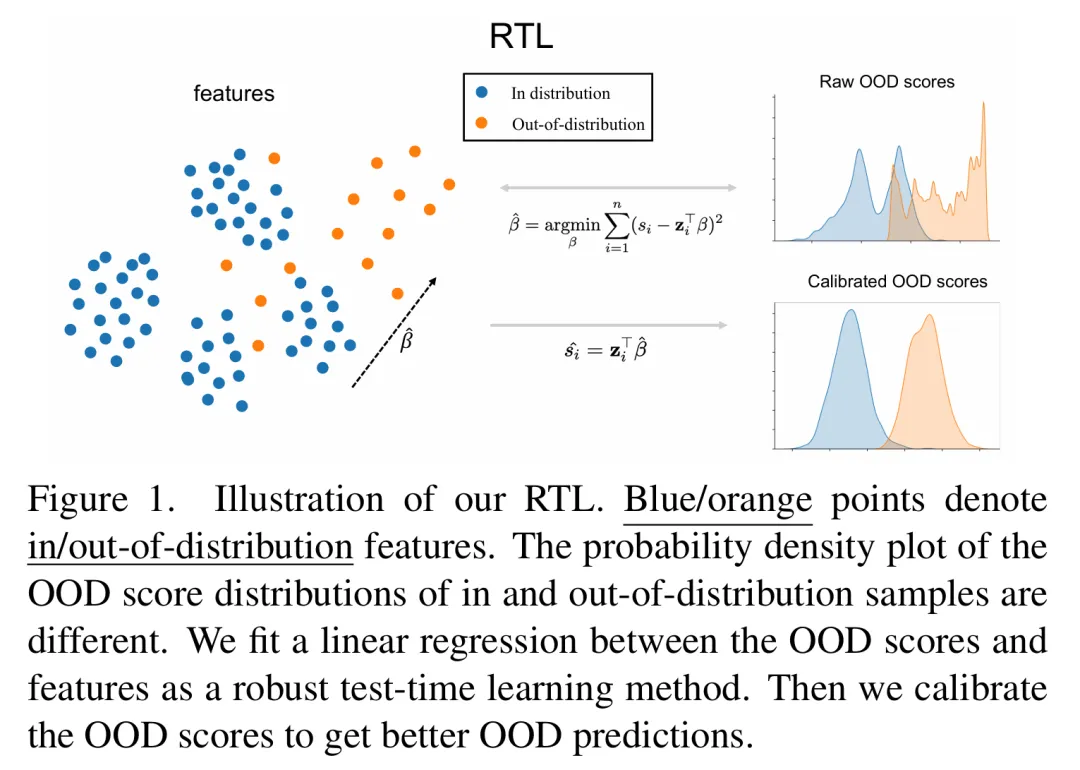
我们的基本思想如上图所示。该方法适用于任意基准OOD检测算法,包括 MSP(Maximum Softmax Probability)、Energy(Helmholtz 自由能)等。基准OOD检测算法通过神经网络处理输入并生成OOD评分。我们存储每个数据的OOD分数以及神经网络倒数第二层的输出作为特征。基于观察到的线性关系,采用线性回归对OOD分数进行拟合与修正,从而实现更高效的OOD检测。
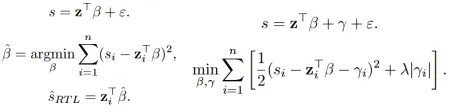
图2 RTL和RTL++的线性模型。其中左侧为RTL,右侧为RTL++
此外,RTL++进一步引入了附带参数(incidental parameter)进行建模。这种扩展可以被转化为标准的LASSO形式,能够高效求解,为OOD检测带来了额外的精度提升。
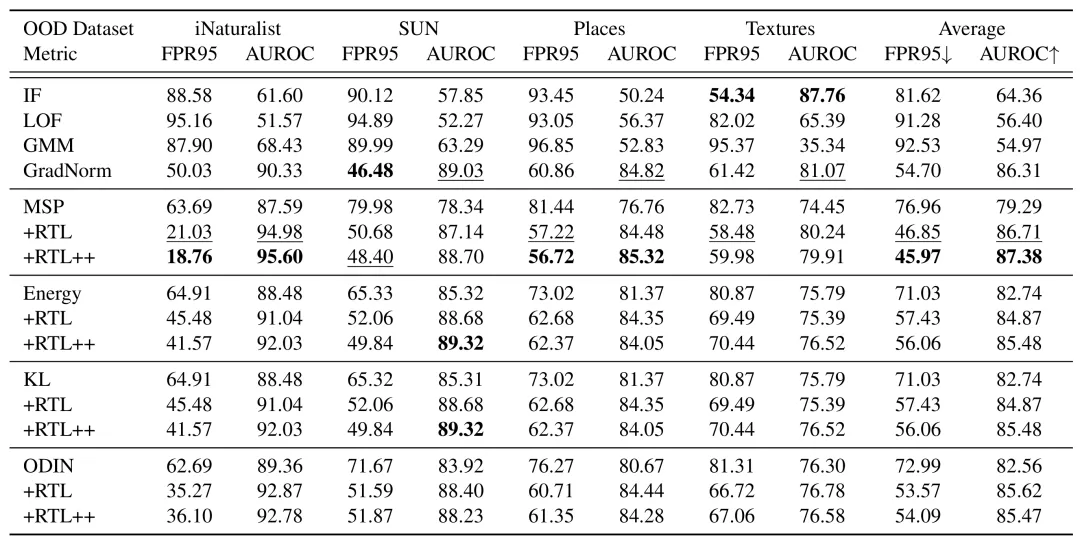
3.实验结果
我们在 CIFAR-10、CIFAR-100 和 ImageNet-1k 等多个 OOD 检测基准数据集上对 RTL 算法进行了测试。与 MSP、Energy等基准算法相比,RTL 在几乎所有情况下都能显著降低 FPR95 并提高 AUROC,从而改善了 OOD 检测的性能
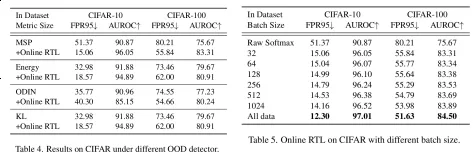
此外,我们基于矩阵分块算法,将 RTL 改进为在线版本,使其能够逐批接收输入并进行实时评分。实验结果表明,在线版本不仅保持了较高的检测性能,还对在线学习过程中批次样本数量的变化表现出良好的鲁棒性。
05
Learning Context with Priors for 3D Interacting Hand-Object Pose Estimation
基于先验上下文学习的3D交互手-物体姿态估计
作者:
匡增晟,丁长兴*,姚欢
单位:
华南理工大学
邮箱:
ftkuangzs@mail.scut.edu.cn,
chxding@scut.edu.cn,
mehuanyao@mail.scut.edu.cn
论文:
https://dl.acm.org/doi/pdf/10.1145/3664647.3681065
代码:
https://github.com/zskuang58/LCP
发表会议:ACM MM 2024
*通讯作者
1.背景与动机
背景:三维手-物体姿态估计任务旨在同时预测交互场景中手和物体的三维姿态。该技术已广泛应用于增强现实与虚拟现实、人机交互、机器人操作、机器人辅助手术等领域。尽管近年来在三维手部和物体姿态估计方面取得了显著进展,但联合估计手与物体的三维姿态仍面临诸多挑战,其中最大的难点在于手与物体之间的相互遮挡(如图1所示)。遮挡现象会导致信息丢失和干扰,显著降低姿态估计的精度。对于机器人操作和机器人辅助手术等高要求场景,克服这一挑战尤为重要,因为姿态估计的不准确可能会带来严重的安全隐患。
动机:在抓取过程中,手与物体的姿态是高度耦合的,这种耦合关系为缓解遮挡问题提供了重要线索。例如,当手与物体发生遮挡时,人类往往能够通过利用上下文信息来推断被遮挡的部分。受此启发,我们提出了一种新颖且稳健的方法,通过引入先验信息,有效地学习丰富的上下文信息,如手与手臂之间的姿态关联,以及手与物体在交互区域内的相关性(如图1所示),从而显著提升遮挡条件下的三维姿态估计性能。

图1 展示了基于先验上下文学习(LCP)框架中上下文解码器层生成的注意力图示意图。四列分别为原始图像、手部和物体查询的注意力图以及最终的姿态估计结果。手部注意力图覆盖了手部、物体和前臂,而物体注意力图则突出显示了物体以及与物体接触的手部。
2.贡献
论文的主要贡献有以下几点:
1)提出了一种新颖且鲁棒的框架,通过引入先验学习广泛的图像上下文信息,有效缓解手-物体遮挡问题。
2)为上下文层、手部层和物体解码器层设计了专用的特征映射策略,以降低特征学习的复杂性。
3)通过大量实验验证了所提框架在手-物体及交互手姿态估计任务中的显著性能提升。
3.方法
基于先验上下文学习(LCP)框架的概述。该框架将上下文、手和物体解码器层叠加在主干网络生成的特征映射上。手部和物体姿态估计任务共享相同的上下文解码器层。这隐式地强加了一个前提,即交互中的手和物体是彼此最重要的上下文信息。手解码器层和物体解码器层分别从感兴趣区域(ROI)提取细粒度特征。同时,上下文层和手部解码器层共享手部姿态估计的查询。而上下文层和物体解码器层共享物体姿态估计的查询。
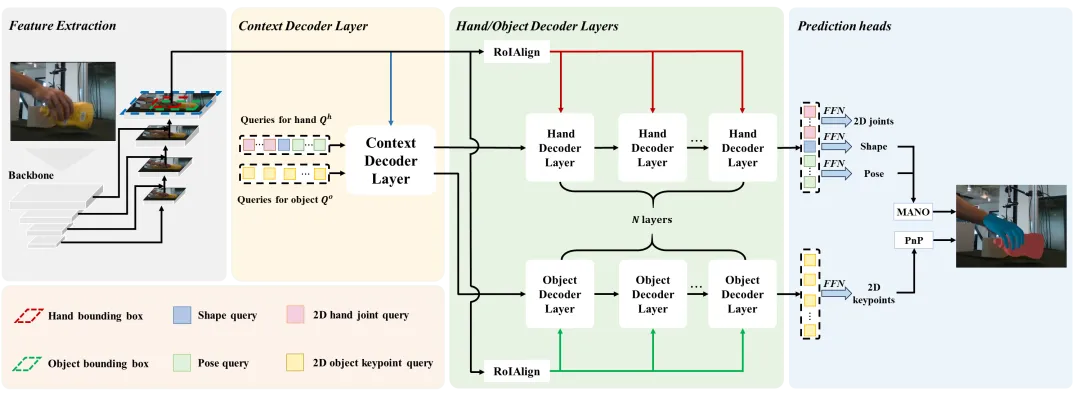
图2 LCP框架图
4. 结果
表1 在Dex-YCB数据集上与最新方法的比较。†表示使用CFM主干
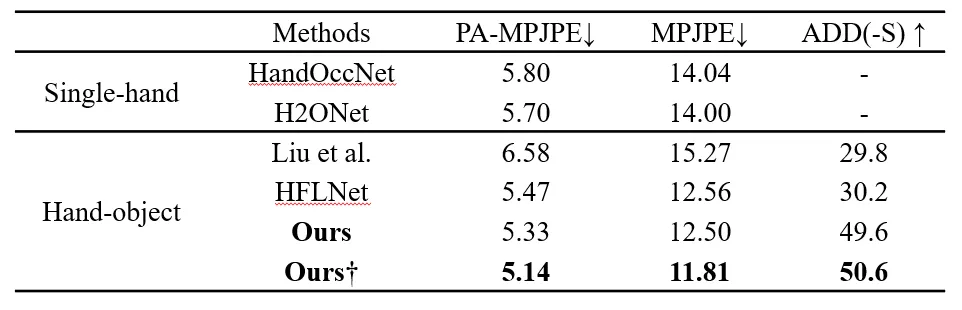

图3 我们的方法与HFLNet的定性比较。

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号