
【论文导读】2025年论文导读第一期
【论文导读】2025年论文导读第一期
CCF多媒体专委会 2025年01月14日 09:01 北京


论文导读
2025年论文导读第一期(总第一百一十八期)
目 录
|
1 |
Optimus-1: Hybrid Multimodal Memory Empowered Agents Excel in Long-Horizon Tasks |
|
2 |
MultiDAN: Unsupervised, Multistage, Multisource and Multitarget Domain Adaptation for Semantic Segmentation of Remote Sensing Images |
|
3 |
Cross-Modal Alternating Learning with Task-Aware Representations for Continual Learning |
|
4 |
Cross-Modal Alternating Learning with Task-Aware Representations for Continual Learning |
|
5 |
Geometry-Guided Diffusion Model with Masked Transformer for Robust Multi-View 3D Human Pose Estimation |
01
Optimus-1: Hybrid Multimodal Memory Empowered Agents Excel in Long-Horizon Tasks
作者:
李在京1,2,谢毓佺1,邵睿1,*,陈恭巍1,蒋冬梅2,聂礼强1,*
单位:
1哈尔滨工业大学(深圳),2鹏城实验室
邮箱:
Lzj14011@gmail.com,
nieliqiang@gmail.com
论文:
https://arxiv.org/abs/2408.03615
项目主页:
https://cybertronagent.github.io/Optimus-1.github.io/
代码仓库:
https://github.com/JiuTian-VL/Optimus-1
发表会议:NeurIPS 2024
*通讯作者
1.研究背景和动机
在开放世界环境中,构建一个能够规划,反思,执行动作以完成长序列任务的智能体,是AI领域的长久愿景。目前,已有许多工作在Minecraft环境中构建了多模态智能体,但这些智能体仍存在以下局限性:(1)缺乏对结构化知识的探索。Minecraft中充满了丰富的结构化知识,例如工具的合成规则(一根木棍和两块铁锭可以合成一把铁剑),以及不同层级的科技树(木材 → 石器 → 铁器 → 金器 → 钻石)等。这些知识有助于智能体做出合理的规划,一步一步获取完成任务所需的材料和工具。然而,现有的智能体缺乏必要的知识,导致他们做出长序列规划的能力受限。(2)缺乏充足的多模态经验。过往的经验对帮助人类完成未曾遇见的任务具有重要作用,同样,智能体也能借助历史经验在面对新任务时作出更加精准的判断与决策。然而,现有的智能体在多模态经验的积累与总结上存在缺陷,未能有效整合视觉、语言、动作等多方面的经验,限制了其在复杂任务中的决策能力和适应性。
2.方法介绍
为了解决上述挑战,我们设计了一个混合多模态记忆模块,它由摘要化多模态经验池和层次化有向知识图构成。类似于知识与经验在指导人类完成复杂任务中的重要作用,智能体在规划阶段借助结构化知识生成可行的任务计划,而在反思阶段则利用多模态经验对当前状态进行判断,并做出更加合理的决策。
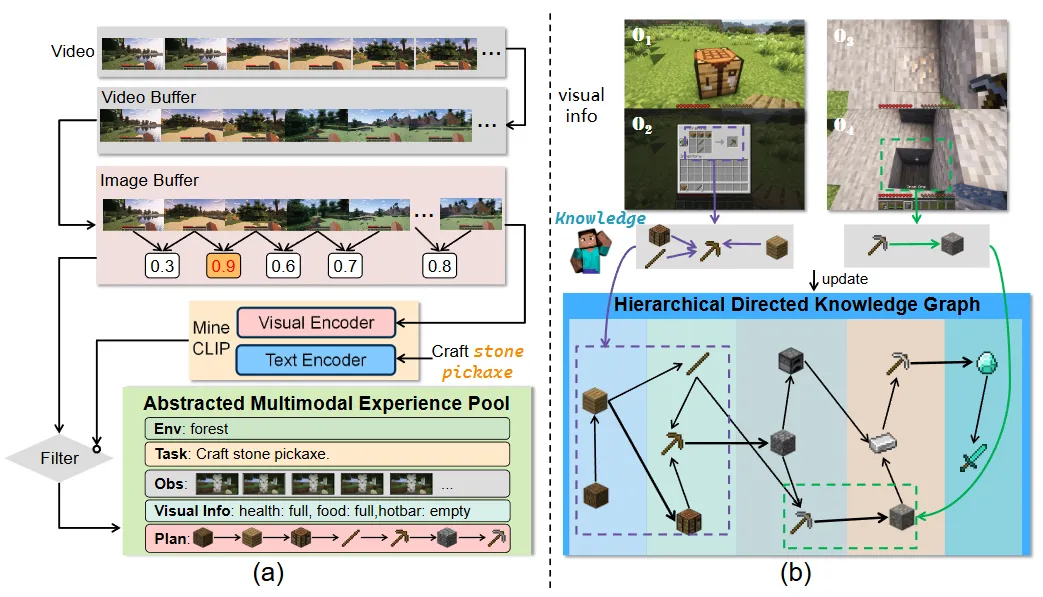
图1 摘要化多模态经验池和层次化有向知识图的构建流程
在此基础上,我们提出了智能体框架Optimus-1。它由混合多模态记忆模块,知识引导的规划器,经验驱动的反思器,以及行动控制器组成。给定一个长序列任务,知识引导的规划器首先从混合多模态记忆中检索任务相关的知识,并基于这些知识生成一系列可执行的子目标。这些子目标依次输入到行动控制器中,生成行动信号以完成任务。在执行任务过程中,经验驱动反思器会定期激活,检索与当前子目标相关的多模态经验作为参考,以此判断智能体当前状态,从而做出更为合理的决策。
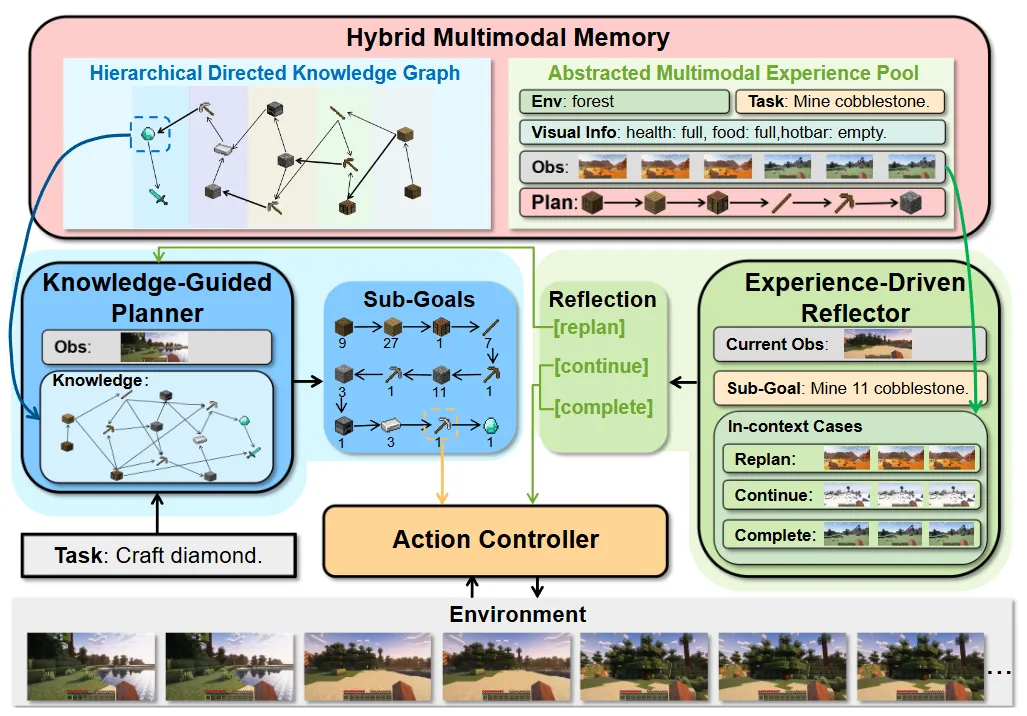
图2 智能体Optimus-1整体框架图
3.实验结果
本文在Minecraft中选取了67个长序列任务进行评估,涵盖木材,石器 ,铁器,金器,钻石,红石,装备七个任务组。每次执行任务,智能体都随机在任意环境中,初始装备为空,这显著增加了任务的挑战性。此外,本文还构建了一个人类水平的基线,以评估现有的智能体与人类水平之间的差距。表1的实验结果表明,,Optimus-1在所有任务组的成功率都显著高于先前的方法。广泛的消融实验也证明了知识和经验对智能体执行长序列任务的重要性。
表1 Optimus-1在7个任务组上的平均成功率
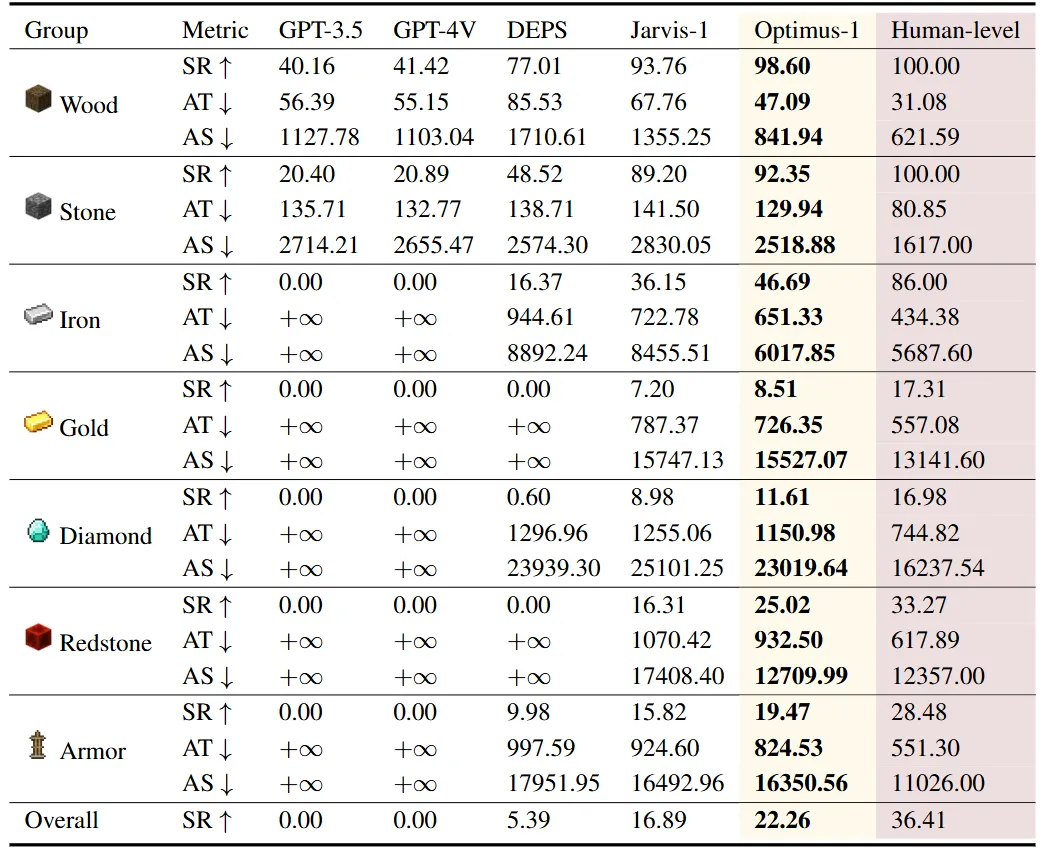
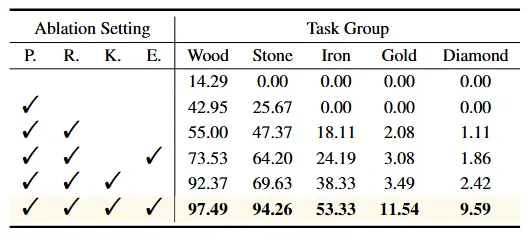
表2 消融实验结果。其中,P,R,K,E分别代表规划,反思,知识,以及经验
此外,本文使用现有的开源多模态大模型构建Optimus-1,以证明混合多模态记忆模块的通用性。如图3所示,在没有混合多模态记忆模块的情况下,各种多模态大模型在长序列任务上的表现较差,尤其是在具有挑战性的钻石任务组中,成功率接近0。而在混合多模态记忆模块赋能下,开源多模态大模型也和GPT-4V有了可比的性能。
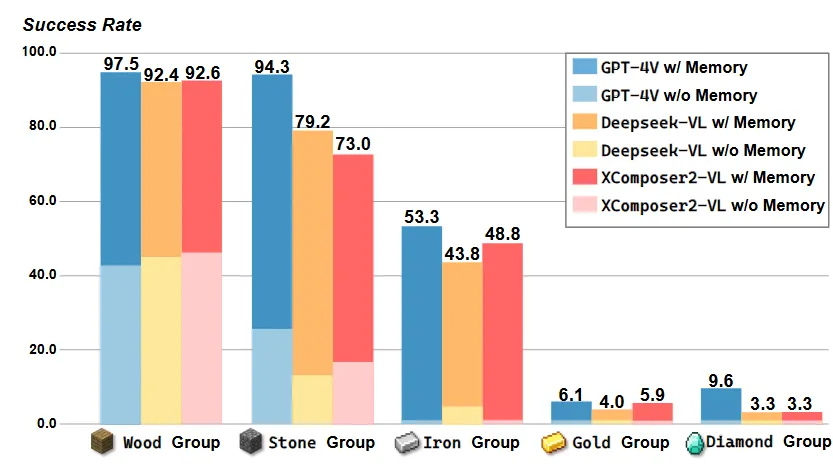
图3 不同多模态大模型作为backbone的性能对比
02
MultiDAN: Unsupervised, Multistage, Multisource and Multitarget Domain Adaptation for Semantic Segmentation of Remote Sensing Images
作者:
蔡钰祥,尚永衡,尹建伟*
单位:
浙江大学
邮箱:
caiyuxiang@zju.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681494
发表会议:ACM MM 2024
*通讯作者
1.论文简介
无监督领域自适应(Unsupervised Domain Adaptation,UDA)是提高跨域遥感图像语义分割模型泛化性能的关键技术,目前已经取得了显著的进展。然而,大多数现有工作集中于解决单一源领域和单一目标领域之间的领域自适应问题,并没有明确考虑实际应用中多个源领域和目标领域之间更复杂的领域偏移问题,尤其是多级域偏移问题——不同目标领域之间的领域间偏移问题以及每个目标领域内部的领域内偏移问题。
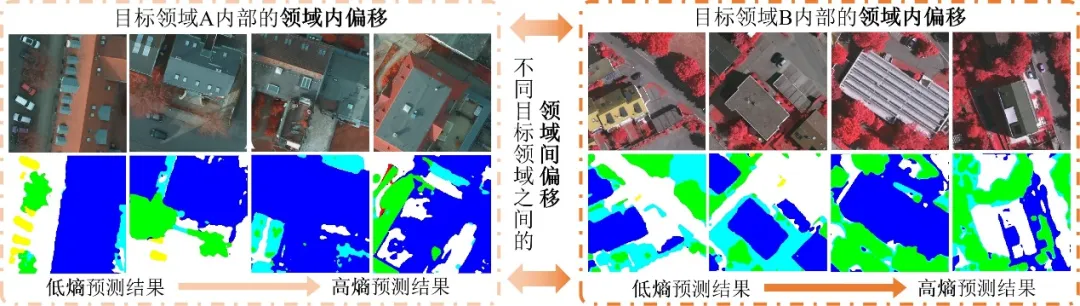
图1 多级域偏移问题示例
为了同时解决多个目标领域的领域间偏移和领域内偏移问题,我们提出了一种新颖的无监督、多阶段、多源和多目标领域自适应网络(Multistage,Multisource and Multitarget Domain Adaptation Network,MultiDANet)。MultiDANet包括多源多目标领域自适应(Multisource and multitarget domain adaptation,MSMTDA)、基于熵的聚类(Entropy-based clustering,EC)和多阶段领域自适应(Multistage domain adaptation,
MDA)。具体来说,MSMTDA学习特征级别的多重对抗策略,以减小多个目标领域和多个源领域之间复杂的领域偏移。然后,EC根据MSMTDA的目标领域预测结果的熵将不同的目标领域聚类为多个子域。此外,我们提出了一种新的伪标签更新策略(PLUS)来动态生成更准确的伪标签。最后,MDA通过我们所提出的多阶段自适应算法(MAA)来逐步对齐多个低熵子域(包括PLUS生成的伪标签)和其他高熵子域。此外,在训练过程中,我们采用自适应加权策略自动地学习各个损失函数的最优权重,以减少人工调参的工作量并提高MultiDANet 的实用性。我们在公开的基准遥感数据集上进行了广泛的实验,实验结果突出了MultiDANet相对于最近最先进的UDA方法的有效性和优越性。
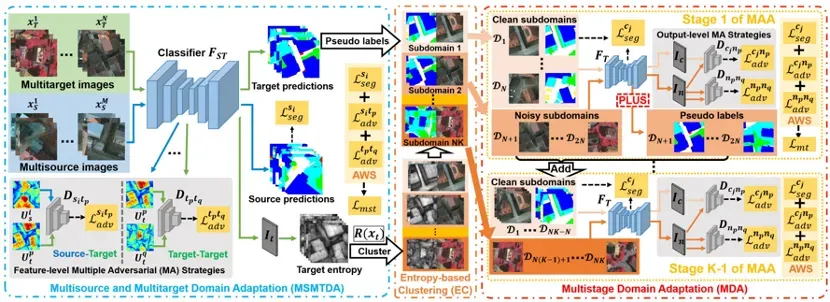
图2 多阶段多源多目标领域自适应网络 MultiDANet 的模型结构示意图
03
Cross-Modal Alternating Learning with Task-Aware Representations for Continual Learning
用于持续学习的模态交替学习与任务感知表征
作者:
李武津*1,高斌斌*2,夏必忠1,王金宝3,刘俊2,刘永2,汪铖杰2,郑锋3
单位:
1清华大学深圳国际研究生院,
2腾讯优图实验室,
3南方科技大学计算机科学与工程系
邮箱:
李武津:vijaylee10@163.com
高斌斌:csgaobb@gmail.com
夏必忠:xiabz@sz.tsinghua.edu.cn
王金宝:linkingring@163.com
刘俊:junsenselee@gmail.com
刘永:choasliu@tencent.com
汪铖杰:jasoncjwang@tencent.com
郑锋:f.zheng@ieee.org
论文:
https://ieeexplore.ieee.org/document/10347466
发表期刊:
TMM 2023
*共同第一作者
1.引言
持续学习是人工神经网络模拟人类终身学习能力的一个研究领域。 尽管当前大量的研究取得了可观的成果,但大多数仅依靠图像模态进行增量图像识别任务。在本文中,我们提出了一个新颖而有效的框架,即跨模态交替学习与任务感知表征(cross-modal Alternating Learning with Task-Aware representations,ALTA),以充分利用视觉和语言模态信息,实现更有效的持续学习。图1说明了我们的方法与典型的基于重放的持续学习方法的不同。传统方法仅依靠图像模态进行视觉识别任务,忽略了文本输入的自然语言形式能包含更多有用信息并提供额外的监督。
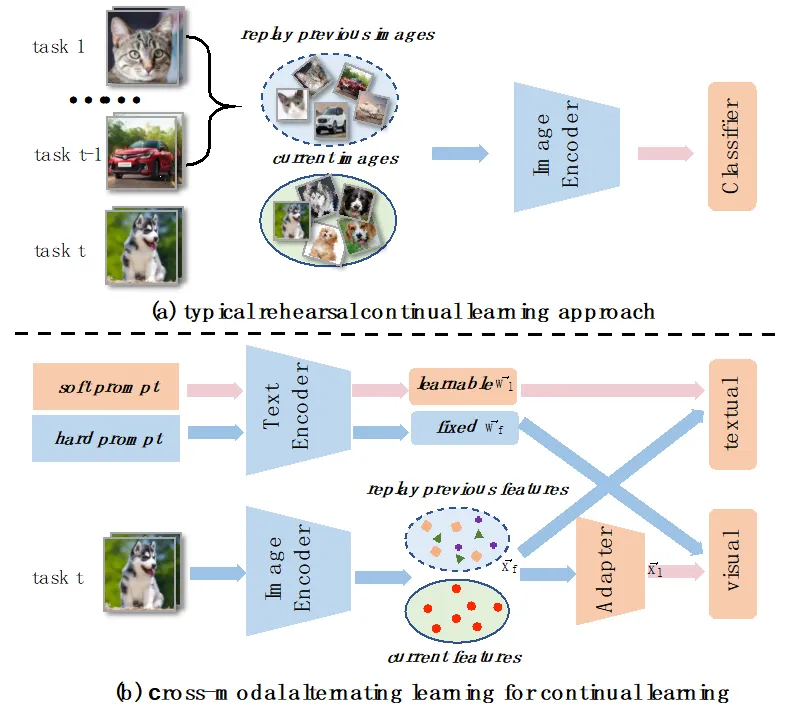
图1 我们的方法与当前基于重放的方法的对比
因此,我们提出了一种跨模态联合学习机制,通过同时学习任务感知的图像和文本表示来获得新知识,同时通过融合任务不变的图像表示和重放过去的跨模态表示来保持先前的知识。该方法不仅充分利用了跨模态信息来进一步缓解遗忘,而且还有效地缓解了基于图像重放的方法对固有的记忆容量敏感性。同时,考虑到稳定性和可塑性的困境,ALTA提出了一种跨模态交替学习策略,该策略交替学习任务感知的跨模态表示以更好地匹配任务之间的图像-文本对,进一步增强了持续学习的能力。为了验证我们方法的优越性,我们在常用基准上将其与各种经典和当前最先进的持续学习方法进行了全面的比较。实验结果表明,我们的方法在任务增量和类别增量任务上都实现了最先进的性能。同时,精心设计的消融研究和分析揭示了单一模态重放方法的固有问题,进一步证明了我们方法的有效性和合理性。
2.方法概述
ALTA包含一个视觉引导的语言学习器(上方支流)和一个语言引导的视觉学习器(下方支流)。视觉引导的语言学习器学习软提示以获取任务感知的文本表征,然后通过与任务不变的图像表征(由过去的部分特征和当前特征组成)进行相似性计算 。而语言引导的视觉学习器则交替学习适配器输出的任务感知图像表征,然后计算与从硬提示输入获得的任务不变文本表征的相似度。最后,我们将两个学习器的输出直接相加以计算最终的损失函数。上述策略避免了任务演化过程中由于跨模态联合学习而导致的两个可学习分支之间的冲突,保证了模型在多任务持续学习下仍能保持满意的性能。更多有关方法的细节请参考论文。
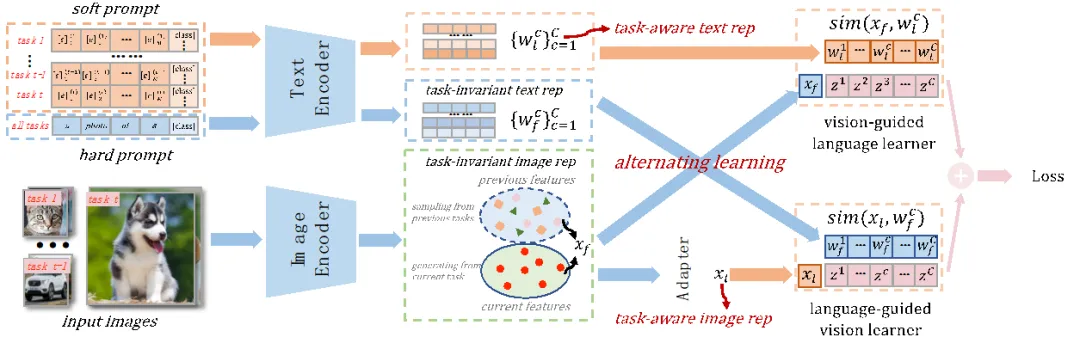
图2 ALTA方法流程图
3. 实验对比
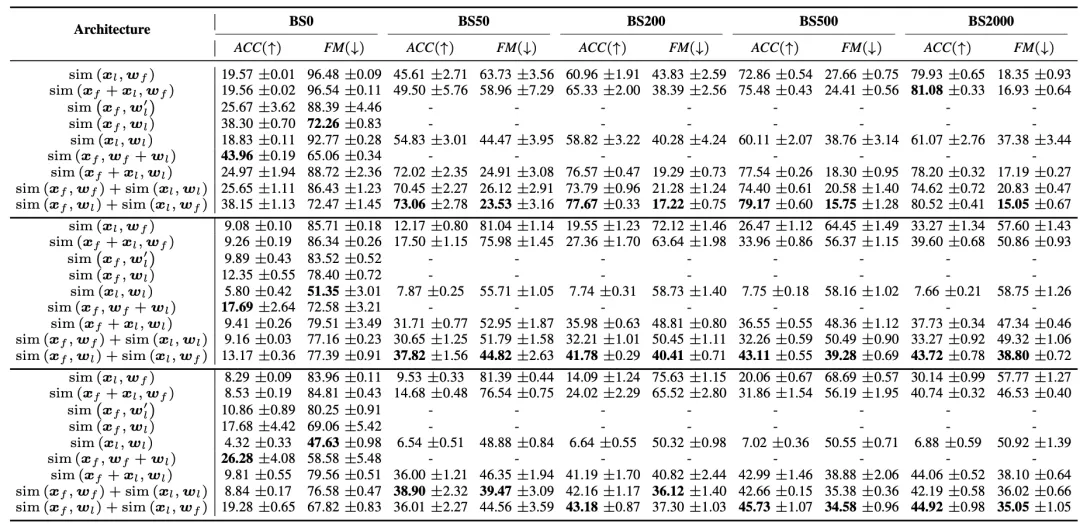
我们在持续学习中常用的几个公共基准(CIFAR-10, CIFAR-100, Tiny-ImageNet)和标准设置(包括任务增量和类别增量)上与各种经典的和当前最先进的方法进行了全面的对比,实验结果如表1所示。为了全面验证ALTA的内部工作原理,我们进行了一系列详尽的实验来分析其关键组成部分(见表2), 实验结果进一步证明了我们方法的有效性和合理性。
表1 类别增量和任务增量设置上的性能表现,结果(准确率 %)是通过使用不同随机种子计算的五次试验的平均值和标准差来衡量的。最好的表现用粗体高亮显示。“-”表示实验在当前计算资源下无法运行。
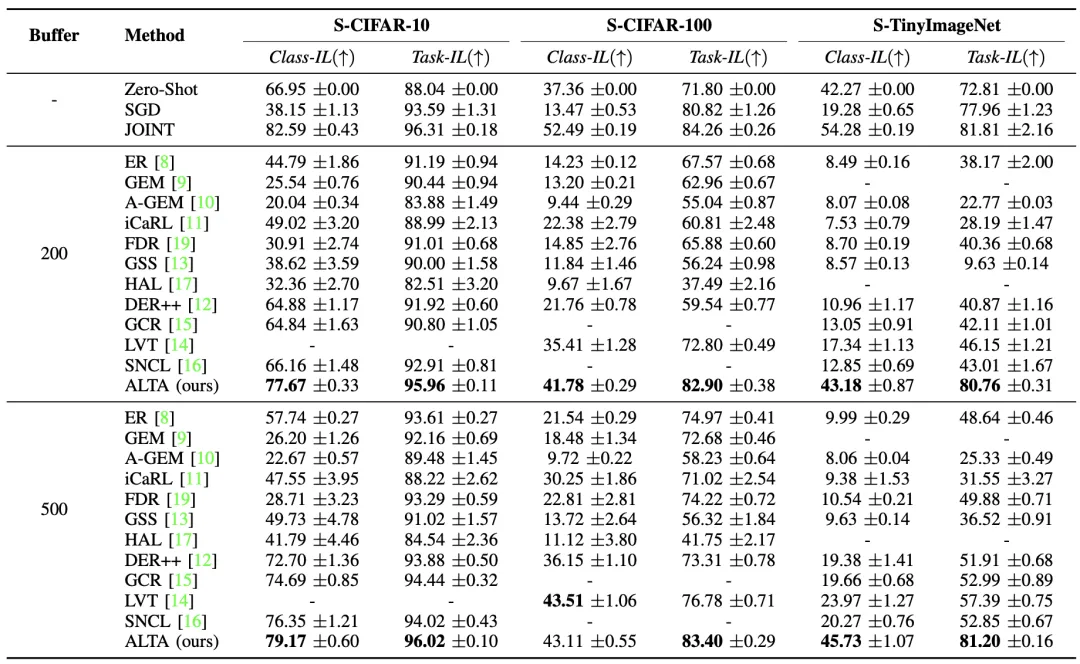
表2 不同模型架构在S-CIFAR -10(上)、S- CIFAR -100(中)和S- TinyImageNet(下)上的消融研究。
04
DP-RAE: A Dual-Phase Merging Reversible Adversarial Example for Image Privacy Protection
作者:
诸佳杰1、杜侠1,2 *、周吉喆2、潘治文3、许奇臻1、留晓源1
单位:
1厦门理工学院计算机与信息工程学院
2四川大学计算机科学学院机器学习与产业智能工程研究中心
3澳门大学计算机与信息科学系
邮箱:
cosmics36@163.com
duxia@xmut.edu.cn
yb87409@um.edu.mo
cmpun@umac.mo
qzxu@xmut.edu.cn
2322071027@stu.xmut.edu.cn
论文:
https://dl.acm.org/doi/pdf/10.1145/3664647.3681291
发表会议:
ACM MM 2024
*通讯作者
1.论文简介
在数字安全领域中,可逆对抗攻击通过将对抗攻击与可逆数据隐藏技术相结合阻止了未经授权的模型对图片的恶意访问。然而,传统的可逆对抗攻击方法通常在扰动隐藏的效果和对抗性能之间做出妥协,从而削弱了可见扰动的保护能力,限制了白盒场景的应用。本文提出了一种新颖的双阶段合并可逆对抗攻击样本生成框架(DP-RAE),结合了启发式黑盒攻击和具有灰度不变性的RDH技术。这种双重策略不仅能更有效地评估和利用过去扰动的对抗潜力,还保证了扰动信息的完美嵌入以及原始图像的完整恢复。
2.方法概述
本文提出的DP-RAE框架(如图1所示)包含三个关键模块:梯度量化白盒噪声生成器(GQBE)、阈值超像素黑盒攻击(TISA)、以及基于灰度不变性的图像隐写术(RDH-GI)。DP-RAE旨在解决黑盒查询开销大和迁移性差的问题。首先,GQBE对图像进行预处理,生成高迁移性的白盒对抗样本,以降低后续黑盒攻击的查询成本并增强攻击的鲁棒性。其次,TISA在GQBE的基础上逐步调整扰动并对目标黑盒模型进行查询,以提高攻击效果,同时利用历史数据评估扰动的影响,从而提升攻击效率。一旦攻击成功,扰动将被压缩并形成扰动矩阵。GQBE与TISA可以独立应用,以适应不同的攻击场景。最后,RDH-GI将扰动矩阵和附加数据嵌入到对抗样本中,生成DP-RAE。在恢复阶段,RDH-GI从DP-RAE中提取隐藏信息,从而恢复扰动矩阵并还原原始图像。
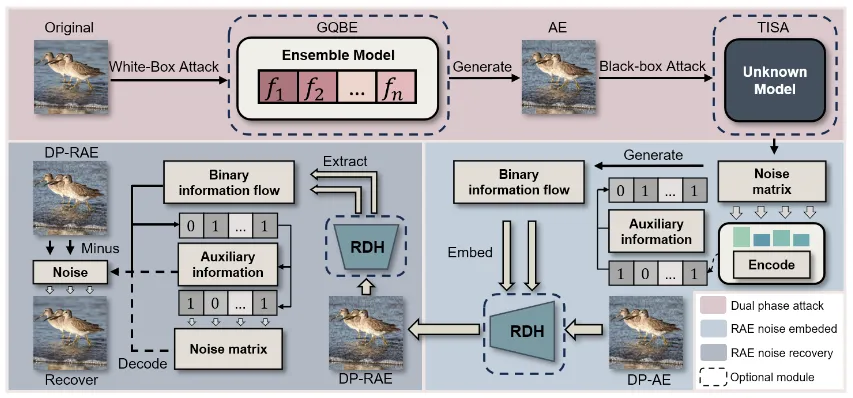
图1 双阶段可逆对抗攻击框架
3.实验结果
我们在ImageNet数据集上进行了全面实验,以评估DP-RAE的有效性。实验结果如表1所示,DP-RAE方法在多个先进模型上展现了卓越的攻击成功率和稳健性,特别是在对未知黑盒模型的攻击表现尤为突出,相较于传统黑盒攻击显示出更强的鲁棒性。此外,在查询次数受限的条件下,我们对商用模型的攻击成功率高达90%。如图2所示,DP-RAE成功的误导了未知的商用黑盒模型的预测结果,这标志着可逆对抗攻击样本首次成功应用于黑盒商用系统。
表1 DP-RAE在多个模型上的攻击测试结果
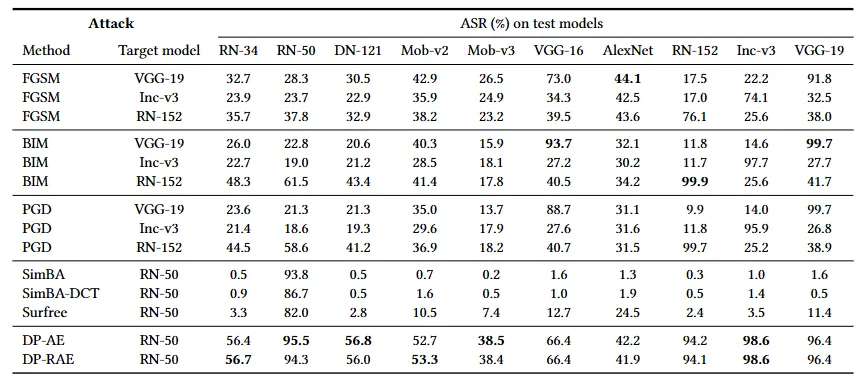

图3 商用黑盒模型误导
05
Geometry-Guided Diffusion Model with Masked Transformer for Robust Multi-View 3D Human Pose Estimation
作者:
张馨怡1,崔钦鹏1,鲍琦琦2,杨文明1,廖庆敏*1
单位:
清华大学深圳国际研究生院1,浙江科技大学2
邮箱:
xinyi-zh22@mails.tsinghua.edu.cn
cqp22@mails.tsinghua.edu.cn
nora919530829@163.com
yang.wenming@sz.tsinghua.edu.cn
liaoqm@tsinghua.edu.cn
论文:
https://dl.acm.org/doi/pdf/10.1145/3664647.3681265
发表会议:ACM MM 2024
*通讯作者
1.研究背景
三维人体姿态估计旨在通过解析图像、视频等多媒体数据,高效、精准地捕捉人体骨架上稀疏的关键点在三维空间中的位置。这些人体几何和位置信息可以服务于诸多下游任务,如动作识别、动作教学与纠正、影视特效中的角色重建、虚拟现实等。
近年来,Transformer和扩散模型的研究为三维人体姿态估计带来了显著进展。例如,一些方法利用Transformer强大的远程依赖性和交互建模能力,在几何知识的引导下实现多视图信息融合,从而最小化重投影误差。然而,这些方法对输入视图的数量和相机空间排布有着严格的限制,不能很好地泛化到具有任意数量的看不见的视图。此外,这些方法通常是确定性的,即直接从给定输入中推断出最可能的单个姿态,在复杂和具有挑战性的场景中容易陷入局部最优解。
概率性方法通过生成多个可信的姿态假设来缓解姿态估计的不确定性。这类方法在单视角中得到了广泛研究,但是多视角情况下仍然存在不确定性,这可能来自于严重的物体遮挡或自遮挡、有噪的二维姿态检测等。因此,多视角概率模型值得进一步研究。现有方法直接利用扩散模型的概率本质,生成多个假设。但由于缺乏几何信息引导,其高精度潜力仍未得到充分挖掘。
综上,现有的基于Transformer和扩散模型的方法无法同时解决准确性和泛化性的问题。
2.研究方法
本文提出了一种基于几何引导的扩散模型与掩码Transformer相结合的鲁棒多视角三维姿态估计方法(Masked Gifformer)。如图1所示,我们在扩散模型的框架下训练了一个基于Transformer的分层多视角去噪器,系统地整合关节和视角信息以拟合3D姿态分布。为了解决长期存在的泛化能力差的问题,我们提出了一种完全随机的掩码策略,以一定概率随机遮挡注意力矩阵中的元素(包含对角线元素)。这一策略能使我们的模型泛化到不同相机数目、空间布局和跨数据集,而不引入额外的可学习模块或参数。在推理过程中,我们将几何信息引入扩散模型,以提高模型的精度。具体来说,我们将条件引导分布建模为重投影误差的负指数形式,引导采样过程朝着最小化重投影误差的方向进行。最后,通过聚合所有假设,获得一个准确且鲁棒的三维姿态。
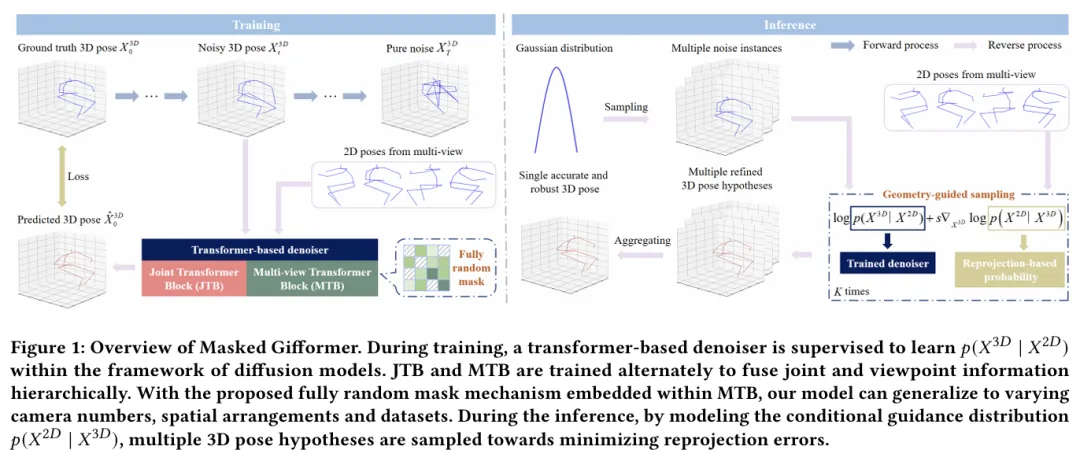
图1 模型架构图
3.实验分析
1)与现有最优方法比较
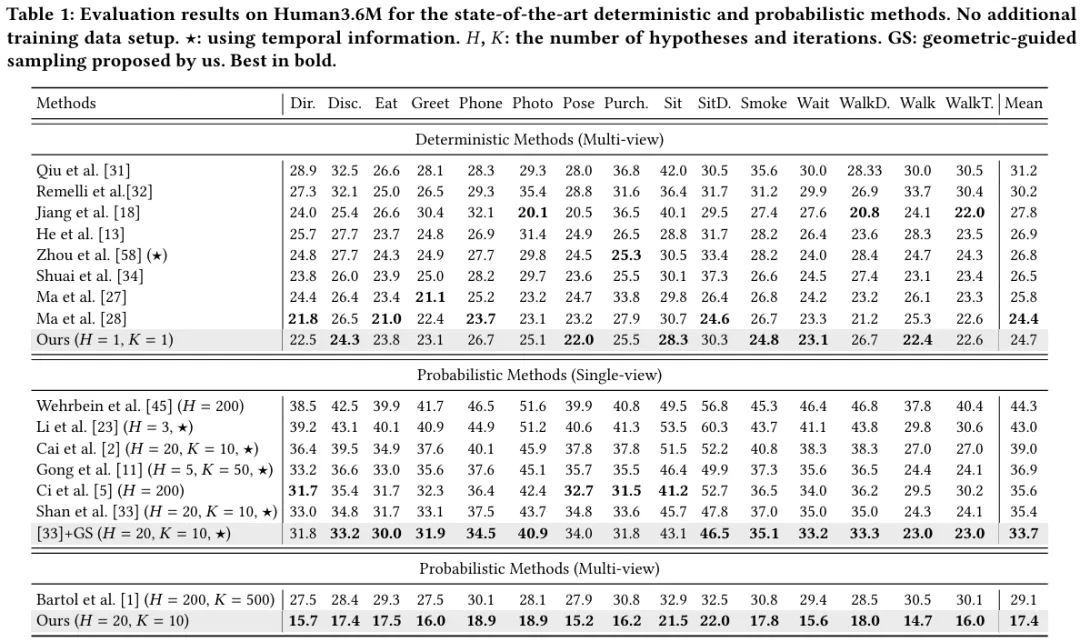
本文在3D人体姿态估计公开数据集Human 3.6M和CMU Panoptic数据集上进行实验。表1给出了在Human 3.6M数据集上的对比结果。可以看到,尽管我们的方法旨在生成多个三维姿态假设,但在单假设场景下,平均每关节点位置误差(MPJPE)仍达到了24.7mm,优于绝大多数确定性方法,并达到了与最先进方法相当的性能。进一步与多视角概率方法进行了比较。当假设数量增加到20时,MPJPE从24.7mm下降到了17.4mm,比Bartol 等人低11.7mm,即使我们使用更少的假设数和迭代次数。为了进一步验证我们提出的几何引导采样(GS)策略的通用性,我们将其应用于单视角概率方法D3DP(Shan等人)中。可以看到,误差降低了1.7mm。
表1 概率性和确定性方法Human3.6M数据集上的对比结果
2)泛化到不同相机数量和空间布局
Masked Gifformer和竞争方法在Human3.6M上的泛化结果如表2所示。Masked Gifformer在训练集的2个/4个相机上进行训练,并在测试集的不同相机数目上进行测试。从横向分析来看,我们的方法以较少的泛化损失(<7.4mm)泛化到任意相机数量的场景中。此外,我们的方法也能泛化到相机数目相同但空间摆放位置有所差异的场景(表2左侧)。从纵向比较来看,我们的方法在不牺牲拟合能力的情况下,泛化性优于Jiang等人和Shuai等人的方法。
表2 Human3.6M 数据集上不同相机数量和空间布局的泛化性能

3)泛化到不同数据集
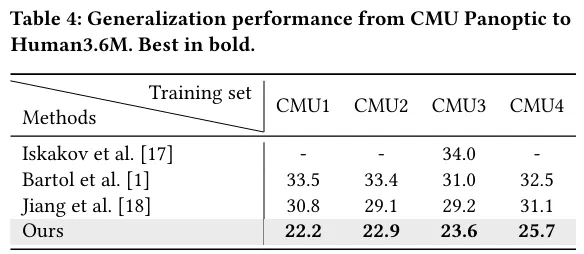
为了测试Masked Gifformer在跨数据集泛化能力上的表现,我们将CMU Panoptic数据集划分为四个子集,记为CMU1~CMU4。表3展示了从这四个子数据集到Human3.6M数据集的泛化结果。从横向分析来看,无论训练集为何,我们的方法均能成功实现跨数据集的泛化。从纵向比较来看,我们的方法展现了更强的泛化能力,超越了对比方法。例如,Iskakov等人、Bartol等人和Jiang等人在CMU3子集上训练时,在Human3.6M测试集上的平均误差分别为34.0mm、31.0mm和29.2mm。而我们的方法则取得了23.6mm,展现了跨数据集泛化方面的显著改进。
表3 CMU Panoptic到Human3.6M的泛化性能

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号