
【论文导读】2025年论文导读第二期
【论文导读】2025年论文导读第二期
CCF多媒体专委会 2025年02月11日 11:39 北京


论文导读
2025年论文导读第二期(总第一百一十九期)
目 录
|
1 |
GenView: Enhancing View Quality with Pretrained Generative Model for Self-Supervised Learning |
|
2 |
Rethinking the Architecture Design for Efficient Generic Event Boundary Detection |
|
3 |
See or Guess: Counterfactually Regularized Image Captioning |
|
4 |
KNN Transformer with Pyramid Prompts for Few-Shot Learning |
|
5 |
Caption-Aware Multimodal Relation Extraction with Mutual Information Maximization |
01
GenView: Enhancing View Quality with Pretrained Generative Model for Self-Supervised Learning
作者:
李潇婕12,杨一博3,李祥泰4,吴建龙1,余跃2,Bernard Ghanem3,张民1
单位:
哈尔滨工业大学(深圳)1,鹏城实验室2,阿卜杜拉国王科技大学3,南洋理工大学4
邮箱:
{xiaojieli0903,yibo.yang93,xiangtai94}@gmail.com,wujianlong@hit.edu.cn,yuy@pcl.ac.cn,bernard.ghanem@kaust.edu.sa,zhangmin2021@hit.edu.cn
论文:
https://link.springer.com/chapter/10.1007/978-3-031-73113-6_18
发表会议:ECCV 2024
1.研究背景
在自监督学习(Self-Supervised Learning, SSL)中,生成高质量的正视图对是学习鲁棒且通用视觉表征的核心。然而,现有对比学习框架主要依赖于人工设计的数据增强方法(如随机裁剪、颜色抖动和高斯模糊)来构建正样本对。尽管这些方法简单且有效,但存在以下局限:(1)视图多样性不足:无法引入如主体视角变换、纹理变化等高级语义变化;(2)假正样本风险:过于激进的增强可能破坏语义信息,甚至引入语义不一致的假正样本对,干扰模型学习。针对这些问题,我们提出了GenView框架,通过利用预训练生成模型动态生成高质量正视图对,并结合质量驱动的对比损失函数,优先引导模型关注高质量样本对,从而进一步提升对比学习效果。
2.方法概述
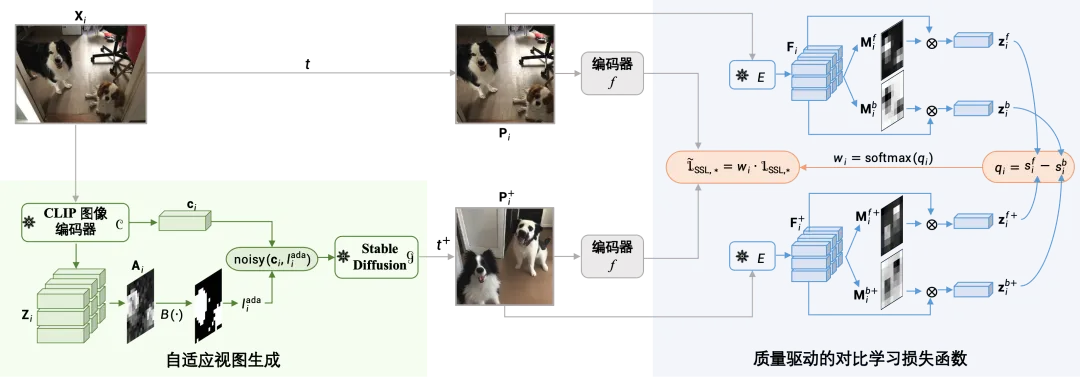
图1 GenView算法框架
GenView 提出了一个结合生成模型与对比学习的创新框架,如图1所示,包含以下核心模块:
1.框架整体设计:GenView 通过结合预训练生成模型(如 Stable Diffusion)与传统数据增强方法,自适应地为每张图像生成高质量的正视图。与仅依赖生成图像的增强方法不同,GenView 将生成视图与原始图像结合,构建正样本对,从而有效减少生成模型与当前数据集分布差异引起的特征漂移问题。此外,自适应视图生成过程可离线完成,每张原始图片仅生成一个高质量视图,既提升了正视图的多样性与质量,又不会增加训练时间。

图2 自适应视图生成机制
2.自适应视图生成方法:GenView 根据图像的前景比例,自适应地平衡生成视图的多样性与语义一致性。当前景比例较低、主体不明显时,降低条件扰动强度以保证生成视图的语义一致性;当前景比例较高、主体清晰可辨时,则增加扰动强度,以生成更多样化的视图和背景变化(如图2所示)。这种机制不仅能为模型提供丰富多样的正视图对,还能有效避免生成语义不一致的样本。
3.质量驱动的对比损失:为缓解低质量或假正样本对对训练的负面影响,GenView 设计了一种基于前景相似性和背景多样性的质量评分机制。通过评估正样本对的质量,为前景相似性高、背景多样性强的样本对分配更高权重,同时弱化低质量样本对的影响。基于该评分的重新加权对比损失机制,显著增强了高质量样本对在模型训练中的贡献,减弱了低质量或语义不一致样本的干扰,从而提升了模型学习的稳健性与准确性。
3.实验结果
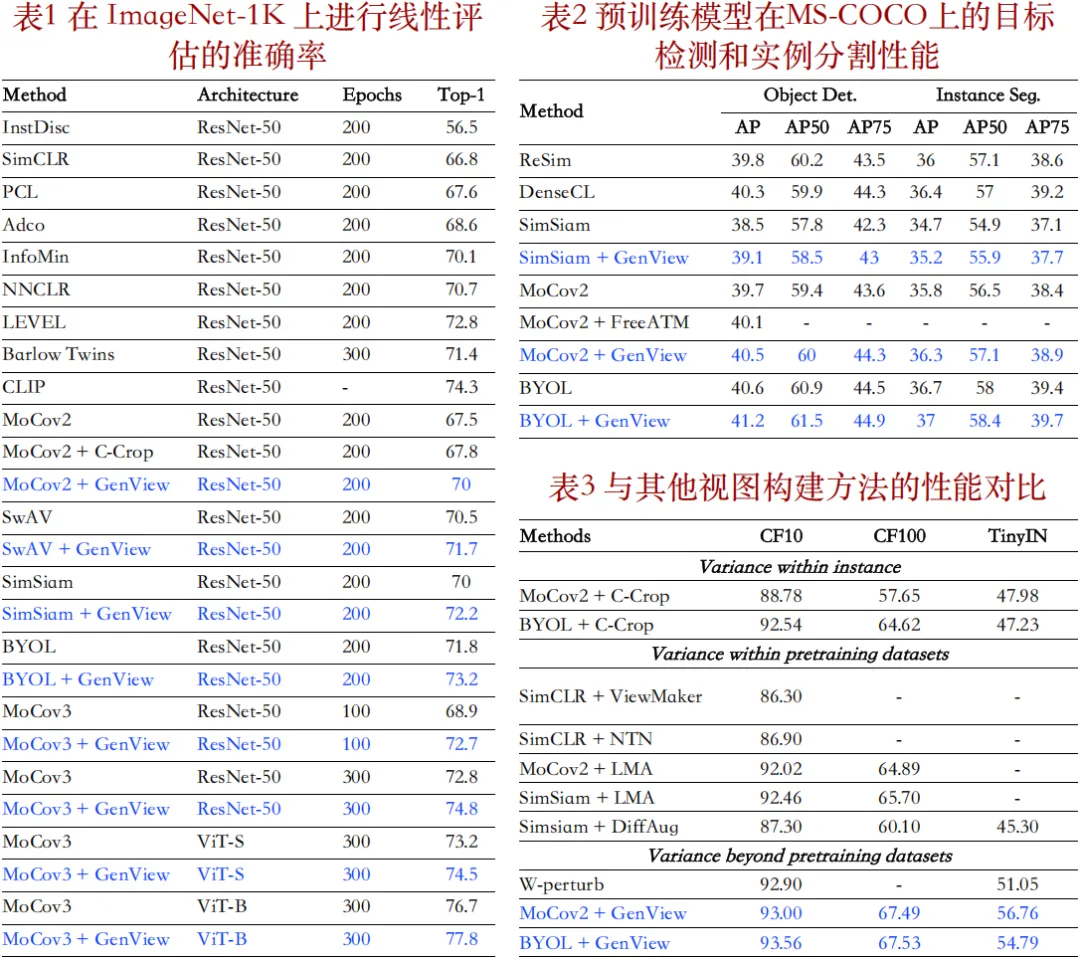
GenView 在多个数据集和任务上展现出了卓越的性能。
1. 线性分类(表1):在 ImageNet-1K 数据集上,GenView 显著提升了多种对比学习框架的线性分类性能。例如,MoCov2、SwAV、SimSiam、BYOL 和 MoCov3(300 epochs)的 Top-1 准确率分别提升了 2.5%、1.2%、2.2%、1.4% 和 1.1%。此外,GenView 在不同网络架构(如 ResNet-50 和 ViT-B)以及不同训练周期(100、300 epochs)下均表现出稳定的性能提升,展现了其在多种环境中的通用性和鲁棒性。
2. 目标检测与实例分割(表2):在 MS-COCO 数据集上,将 GenView 集成到 SimSiam、MoCov2 和 BYOL 框架后,目标检测和实例分割任务的平均精度显著超越了基线方法,进一步验证了 GenView 在更复杂下游任务中的有效性。
3. 与其他视图构建方法的对比(表3):在 CIFAR-10、CIFAR-100 和 Tiny ImageNet 数据集上,GenView 相较于其他视图构建方法(如 C-Crop 和 ViewMaker),始终保持更高的准确率,验证了 GenView 在生成高质量视图方面具备独特优势,并能显著提升模型性能。
02
Rethinking the Architecture Design for Efficient Generic Event Boundary Detection
对高效通用事件边界检测体系结构设计的再思考
作者:
郑子维1,张泽川1,王语霖2,宋士吉2,黄高2,杨乐1*
单位:
1西安交通大学,2清华大学
邮箱:
ziwei.zheng@stu.xjtu.edu.cn
zhangz.c2024@stu.xjtu.edu.cn
wang-yl19@mails.tsinghua.edu.cn
shijis@mail.tsinghua.edu.cn
gaohuang@tsinghua.edu.cn
yangle15@xjtu.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681513
发表会议:ACM MM 2024
*通讯作者
1.论文简介
受到人类视觉认知中将视频划分为有意义时间段的习惯启发,通用事件边界检测(Generic Event Boundary Detection, GEBD)在视频编辑和内容摘要等多个领域具有广泛应用。然而,我们注意到,现有最先进的模型往往片面追求性能提升,而忽视了模型的复杂性。这种做法导致推理速度较慢,从而限制了其在实际场景中的高效部署。
在本文中,我们通过实验重新审视了GEBD模型的架构设计,并提出了一系列令人意外的发现以应对这一挑战。首先,我们揭示了一个简单的基线模型,即使不依赖复杂设计,也能实现令人满意的性能表现。其次,我们发现,基于图像域主干的GEBD模型设计普遍存在大量架构冗余,因此我们对模型组件进行逐步优化,显著提升了模型效率。此外,我们观察到,现有基于图像域主干的GEBD模型通常采用以空间为主、时间为辅的贪婪式时空学习策略,这可能导致注意力分散问题,成为GEBD效率低下的重要原因。为此,我们提出了一种基于视频域主干网络的联合时空建模策略,并证明这一方法能够有效提升效率。
基于上述研究,我们提出了一个名为EfficientGEBD的GEBD模型家族。在相同主干网络的条件下,EfficientGEBD实现了性能提升1.7%,推理速度提升280%,显著超越了此前的SOTA方法。我们的研究强调,在设计现代GEBD算法时,应特别关注模型复杂性,尤其是在资源敏感型应用中。相关代码已开源,详见:https://github.com/Ziwei-Zheng/EfficientGEBD。
2. 方法概述
我们首先通过抽象现有流行的GEBD方法建立一个基线模型,命名为BasicGEBD作为起点。作为基线模型,我们对每个组件都使用了最简洁的设计,如下图所示:
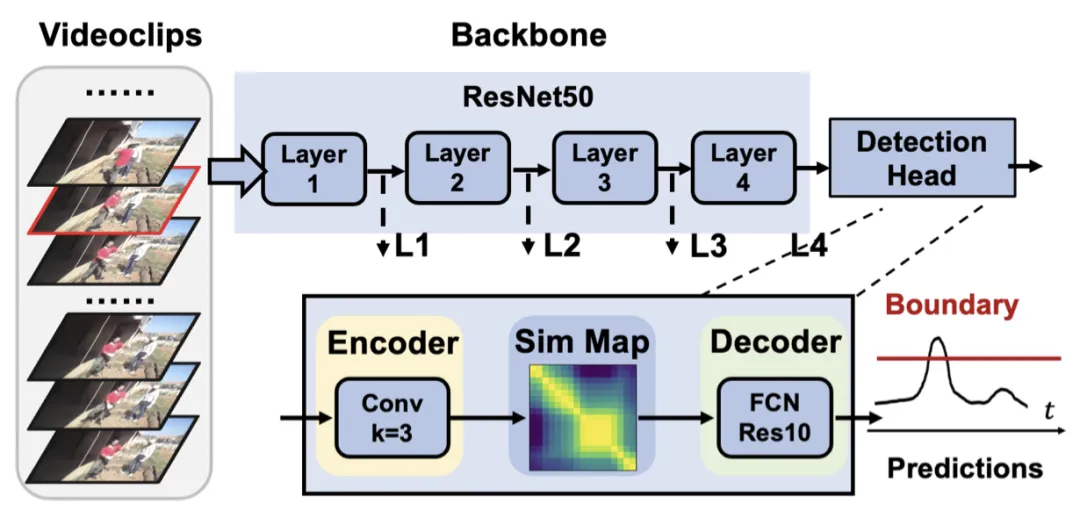
令人惊讶的是,所提出的BasicGEBD的性能在F1@0.05项下可高达77.1%。已经优于大多数现有的GEBD方法。通过重新审视BasicGEBD的各个组成部分,我们提出减少多余的计算成本并提高模型效率,从而形成一个新的高效GEBD模型族,命名为EfficientGEBD。此外,通过研究为什么较大尺寸的主干模型只会增加剩余成本而不会提高GEBD性能的可能原因,我们在构建GEBD模型时,利用视频域深度网络在主干中共同进行时空建模。在下图中,我们展示了对BasicGEBD结构每一步优化后我们能够取得的实验结果,为通用事件边界检测框架的重设计提供了指导和线索。

3. 实验结果
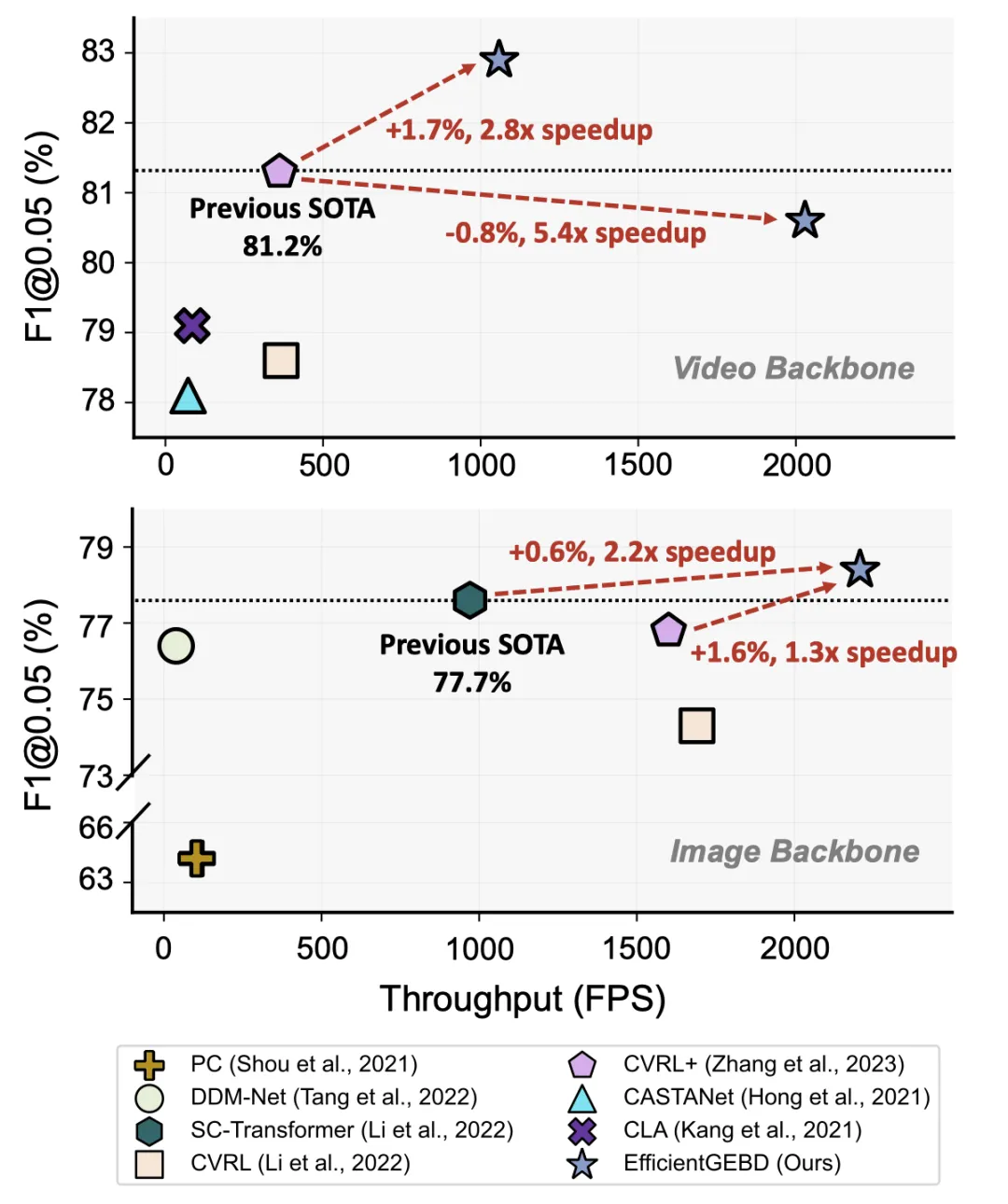
我们的方法在Kinetics-GEBD与TAPOS两个大型通用时间边界检测数据集上验证了其高效性与有效性。具体结果如下图所示,总的来说,我们发现EfficientGEBD优于所有以往的方法,特别是在最严格的检测阈值约束下(Rel.dis=0.05),表明我们的方法具有更强的边界检测能力。举例来看,当使用ResNet50作为主干时,EfficientGEBD与当前sota方法竞争,性能提高0.6% (78.3% vs 77.7%),实际推理加速220% (2208 FPS vs 971 FPS)。当使用CSN作为骨干模型时,EfficientGEBD性能达到82.9%,比现有sota方法提高了1.7%以上,速度提高了280%。
03
See or Guess: Counterfactually Regularized Image Captioning
反事实正则化的图像描述生成
作者:
曹乾1,陈旭1*,宋睿华1*,王希廷1*,黄昕庭2,任羽辰1
单位:
1中国人民大学高瓴人工智能学院 2Tencent AI Lab
邮箱:
caoqian4real@ruc.edu.cn
xu.chen@ruc.edu.cn
rsong@ruc.edu.cn
xitingwang@ruc.edu.cn
siriusren@ruc.edu.cn
timxinhuang@tencent.com
论文:
https://arxiv.org/pdf/2408.16809
https://dl.acm.org/doi/10.1145/3664647.3681458
代码:
https://github.com/Aman-4-Real/See-or-Guess
发表会议:ACM MM 2024
*通讯作者
1.引言
图像描述生成,即对图像中视觉信息生成自然语言描述,是视觉-语言研究中的一项重要任务。之前的模型通常通过统计拟合现有数据集,将机器的生成能力与人类智能对齐来解决这一任务。虽然这些模型在描述正常图像的内容方面表现出色,但它们可能在准确描述某些部分被遮挡或编辑过的图像时表现不佳。相反,人类在这种情况下却能轻松应对。这些模型表现出的弱点,包括幻觉和有限的可解释性,往往在应用于关联模式发生变化的场景时会导致性能下降。在本文中,我们提出了一个通用的图像描述生成框架,通过因果推理使现有模型更具干预任务能力,并能进行反事实解释。具体而言,我们的方法包括利用总效应或自然直接效应的两种变体。我们将这些概念融入训练过程中,使模型能够处理反事实场景,从而变得更具普遍性。在各种数据集上进行的大量实验表明,我们的方法可以有效减少幻觉,并提高模型对图像的忠实度,具有很高的小规模和大规模图像到文本模型的可移植性。
2.方法概述
本文的方法将负对数似然 (NLL) 损失 与 因果推理中的总效应Total Effect 或自然直接效应 Natural Direct Effect 结合起来,提出两种分别的正则化损失(即 TE 或 NDE)。添加的反事实正则化损失使模型可以与 NLL 损失一起学习,整体框架如图1所示。整个优化包括两个阶段:(1) 使用普通 NLL 损失训练模型;(2) 使用构建的反事实图像及其对应的生成的反事实标题,结合反事实正则化损失训练模型。本文的方法包含两种变体:
·总效应正则化 Total Effect (TE):TE希望通过对图像中的局部区域进行遮盖,使得这个遮盖给图像描述中对应文本带来的改变最大,从而减小在这种情况下生成的描述中出现遮盖区域物体的概率。
·自然直接效应正则方法 NDE :由于TE还包含了影响前序词序列而对当前词产生的影响,为了排除这种前序词的影响,使得当前词的产生只受到图片视觉信息的影响,我们进一步提出了基于NDE 效应的方法。NDE效应的反事实正则化方法只衡量该部分图像对生成词的影响。这种方法下,整个生成的图像描述中,遮盖区域对应的词的生成概率被抑制,从而能更好地减少幻觉。
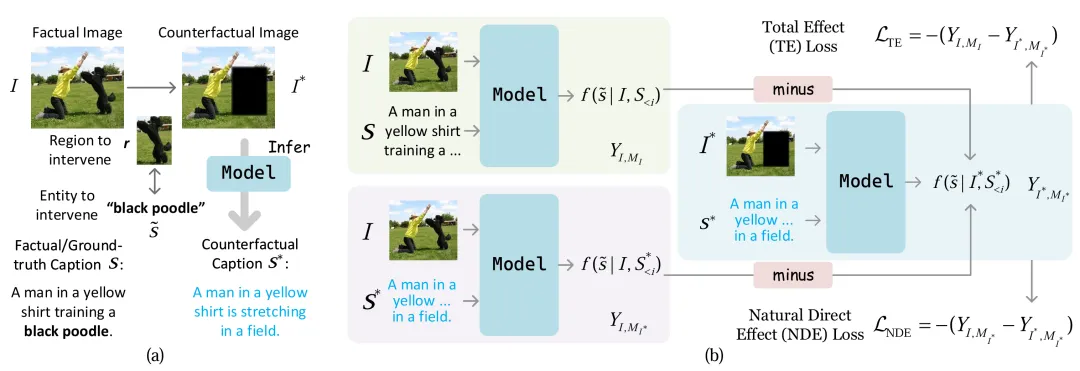
图1 反事实正则化算法流程
3. 实验对比
我们在Flickr30K Entities和MSCOCO两个图像描述数据集上进行了实验,并在ClipCap、BLIP和BLIP2三种不同的模型架构上与此前先进的方法进行了全面的对比,实验结果如表1和表2所示。实验结果显示,我们的方法在所有三种模型和两个数据集的反事实测试集上无论是自动或是人工指标都能够显著降低模型的物体幻觉;同时,我们的方法还能在事实(正常)测试集上提高模型的图像描述的性能,在自动和人工指标上都得到了普遍更好的结果。我们的观察发现,NDE的正则方法具备更优的降低幻觉的能力,而TE的方法能够在降低幻觉的同时更加兼顾生成的性能,这也符合我们方法设计的理论直觉。
表1 反事实测试集上的实验结果
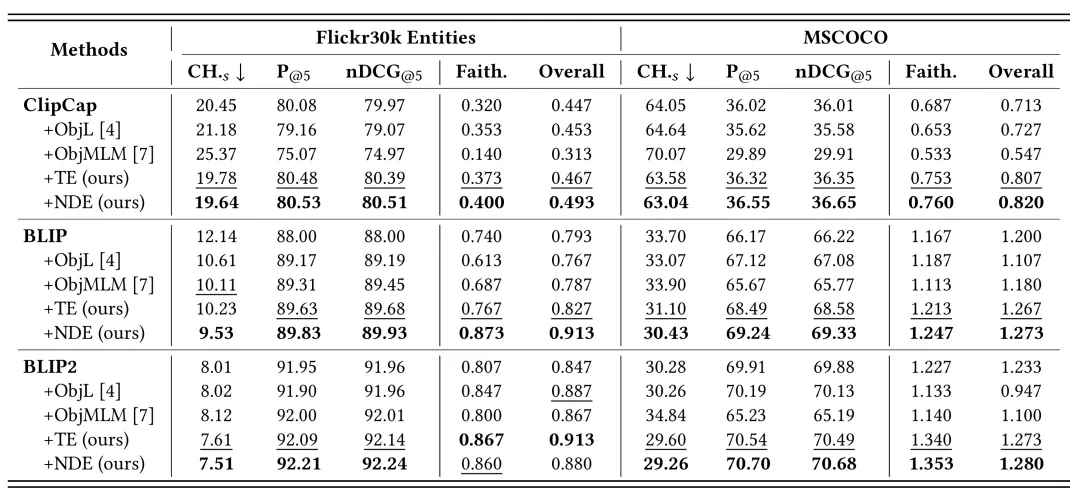
表2 事实测试集上的实验结果
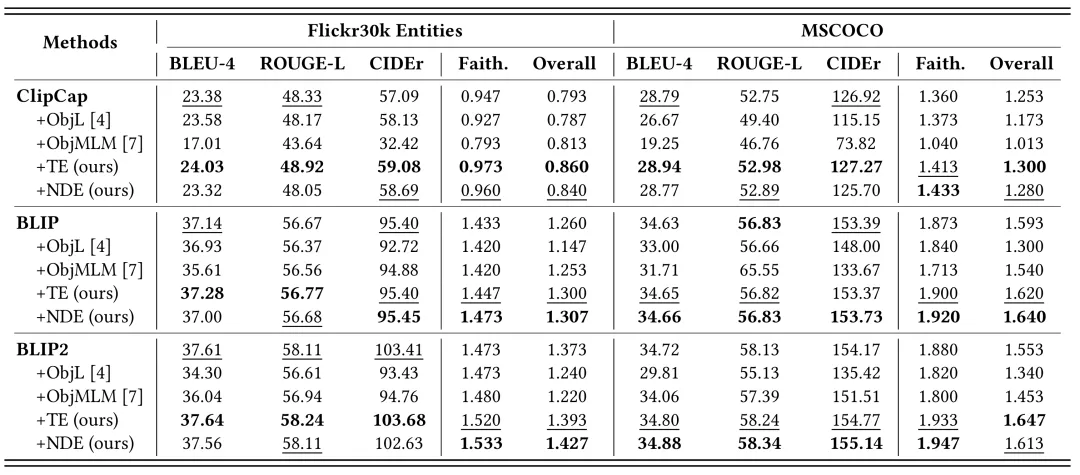
图2呈现了在反事实图像(遮盖)、性别有偏数据集的事实图像、以及反事实图像(模型填充)三种场景下的部分生成样例对比。模型生成的描述中的幻觉被红色标记出,可以看出,我们的方法在三种场景下都能够比原模型具备更低的幻觉。

图2 不同模型在三种场景下的生成结果示例
04
KNN Transformer with Pyramid Prompts for Few-Shot Learning
作者:
李文浩,王强昌*,赵鹏,尹义龙*
单位:
山东大学
邮箱:
wenhao.li@mail.sdu.edu.cn,
qiangchang.wang@gmail.com,
202115225@mail.sdu.edu.cn,
ylyin@sdu.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3680601
课题组主页:
https://time.sdu.edu.cn/
发表会议:
ACM MM 2024
*通讯作者
1.研究背景和动机
小样本学习(Few-Shot Learning, FSL)的目标是通过少量标注数据实现新类别的识别。然而,有限的标注样本使得学习具有判别性的特征变得极具挑战,容易在生成特定于类别的原型时出现语义偏差。近期的一些研究尝试利用额外的语义信息(如类别描述)与视觉原型进行相结合。然而,这些基于语义的方法通常是在较高层次(如原型和分类器)上进行跨模态整合,缺乏底层特征交互并且忽略了模态之间的分布差异,难以捕捉模态之间复杂的语义关系。此外,在视觉变换器(Vision Transformers, ViTs)中,传统的自注意力机制易受到图像中无关信息的干扰即在交互过程中大量无关tokens的混淆,严重限制了语义先验在FSL中的潜力,尤其是在复杂背景的场景下,如图1所示。
为了解决这些问题,本文提出了一种结合金字塔提示(Pyramid Prompts)的K-NN Transformer模型(KTPP),用于小样本学习,旨在充分利用跨模态信息并提取具有判别性的视觉特征。如图1所示,我们的 KTPP 实现了从粗到细的噪声过滤、对空间变化的自适应以及由基于提示引导的特定于类别的视觉特征提取。

图1 注释为 “狗 ”的图像包含大量虚假相关信息(如人物、苹果、墙壁等),不同图像之间还存在空间尺度差异,这些问题限制了 ViTs 在FSL的性能。
2.方法介绍
方法的框架图如图2所示,KTPP 主要由K-NN上下文注意力(KCA)和金字塔跨模态提示(PCP)组成。首先,对于每个token,KCA 仅选择K最相关的tokens来计算注意力矩阵,而不是所有标记,从而有效排除不相关信息并减轻计算负担。通过三个级联阶段,以由粗到细的方式逐步抑制不相关的tokens。为了避免在 top-K操作中过于关注局部上下文而忽视全局特征的判别信息的问题,所有tokens的平均值被视为上下文提示,并纳入其中以增强每个token的全局上下文信息。其次,预训练的 CLIP 模型具有出色的跨模态特征对齐能力,可提取丰富且无偏差的语义嵌入。因此,我们通过CLIP对类名编码得到类感知提示。PCP 使类感知提示能够与多尺度支持特征通过跨模态增强模块交互,学习金字塔提示,以捕获文本和视觉特征之间的复杂语义关系。金字塔结构允许 ViT 动态地关注与语义信息最相关的支持特征,并使其对空间变化具有鲁棒性。最后,增强的视觉特征和类感知提示通过 KCA 进行交互以提取特定于类的特征。因此,我们的模型通过深度跨模态交互进一步增强了无噪声视觉表征,在只有少量标记样本的场景中提取通用和判别性的视觉表征。
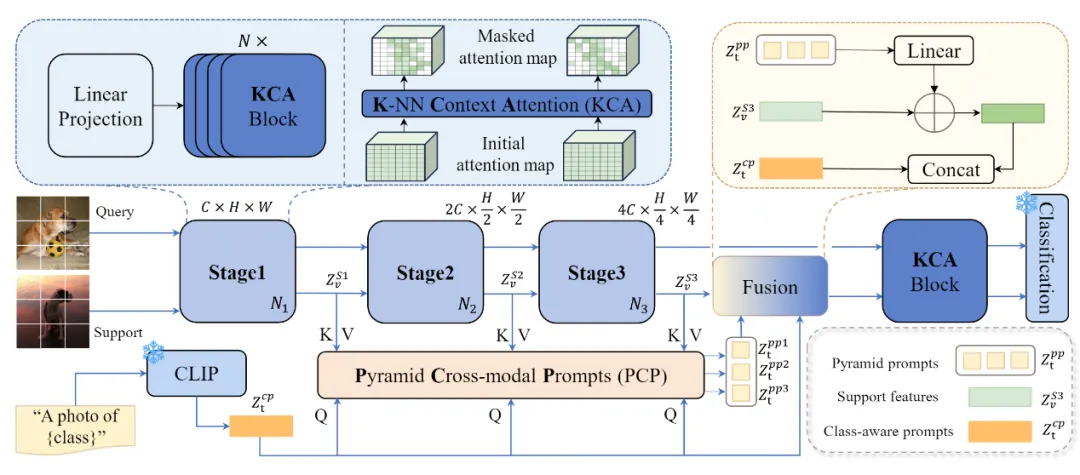
图2 整体框架图
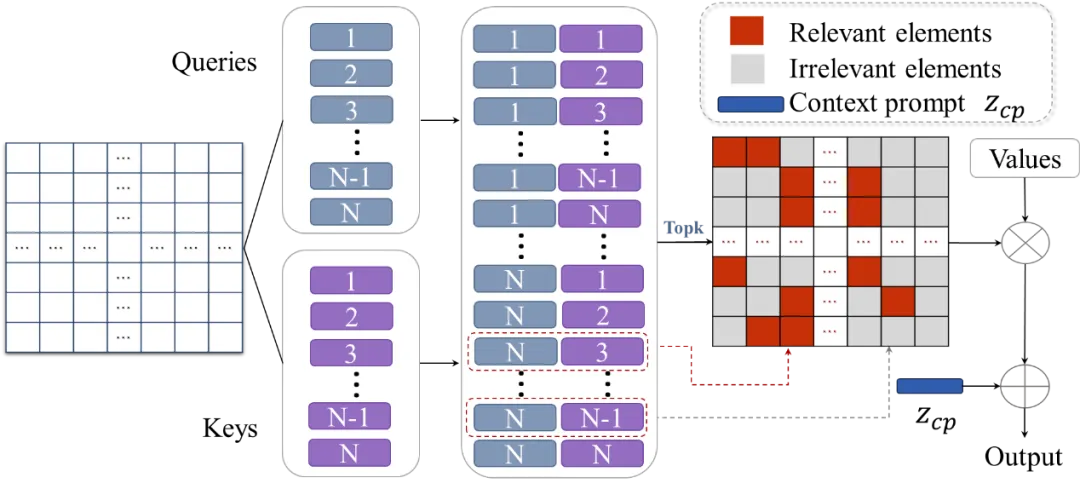
图3 K-NN上下文注意力(KCA)方法
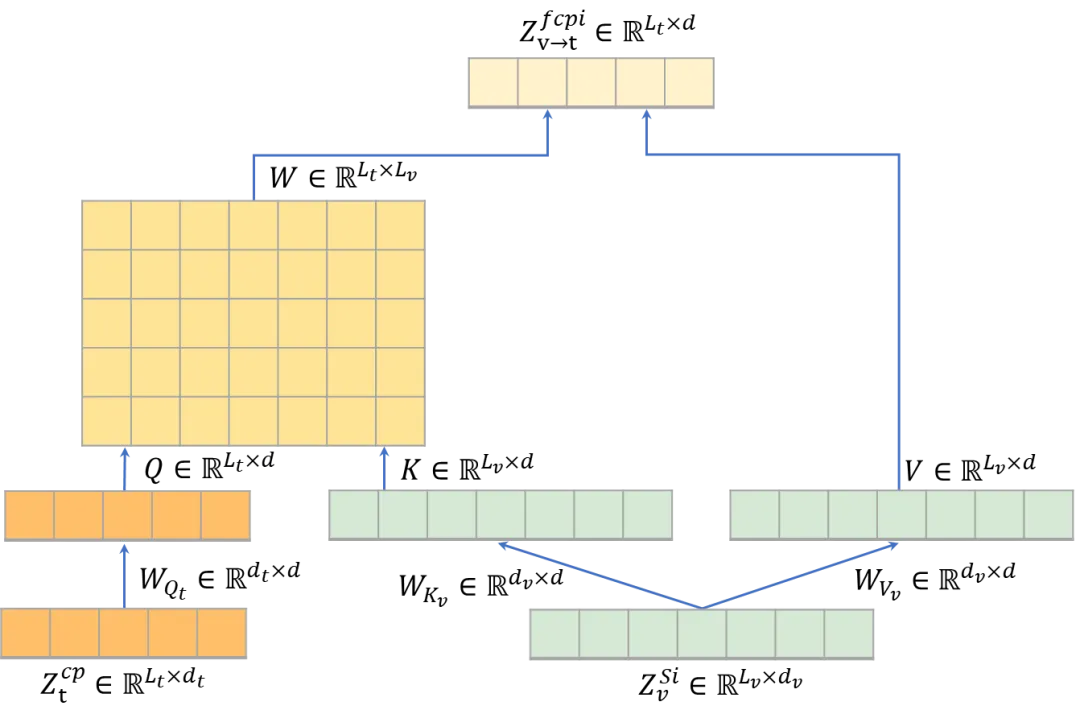
图4 金字塔跨模态提示(PCP)的跨模态增强模块
3.实验结果
为了评估我们提出的 KTPP 的有效性,我们在四个基准数据集上进行了大量实验。图5和图6展示了 KTPP 与在5-way 1-shot 和 5-way 5-shot 设置下与最先进方法的比较结果。实验结果表明与最先进的方法相比,KTPP取得了显著的性能,尤其是对于 1-shot 任务,由于语义增强的视觉表征,平均提高了 2.28%。为了定性分析其有效性,图6展示了注意力图和t-SNE的可视化。KTPP能够更有效地选择判别区域并在嵌入空间中的类别分布更加分离。
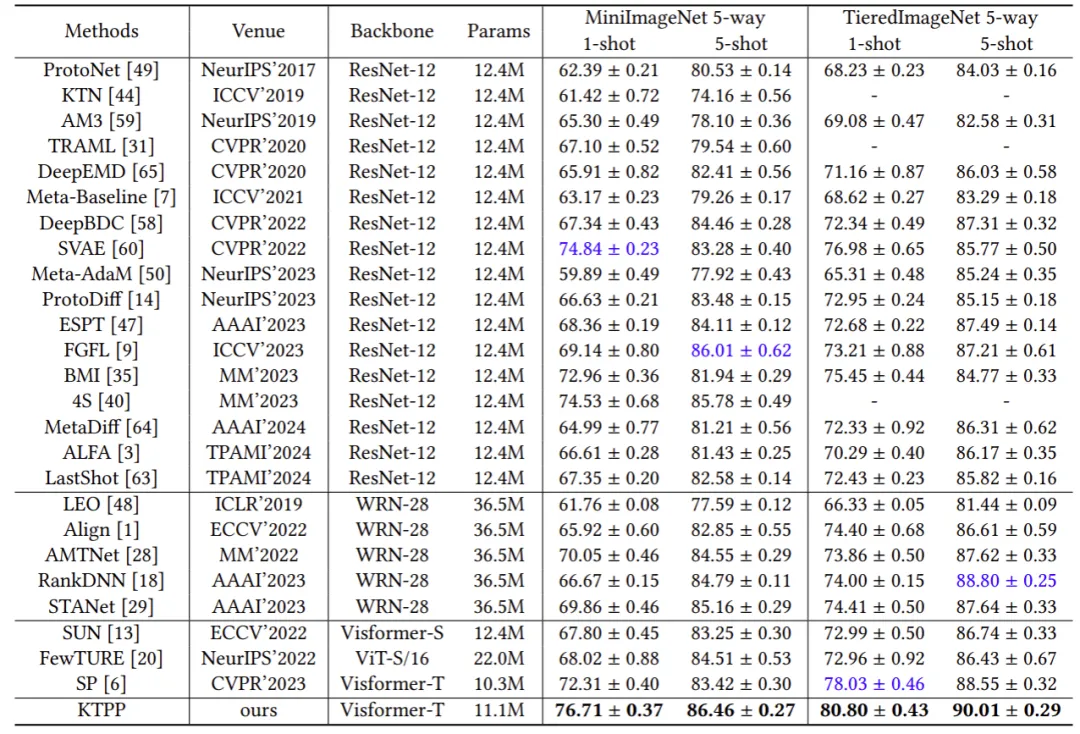
图5 在miniIMageNet和tieredImageNet数据集的性能比较
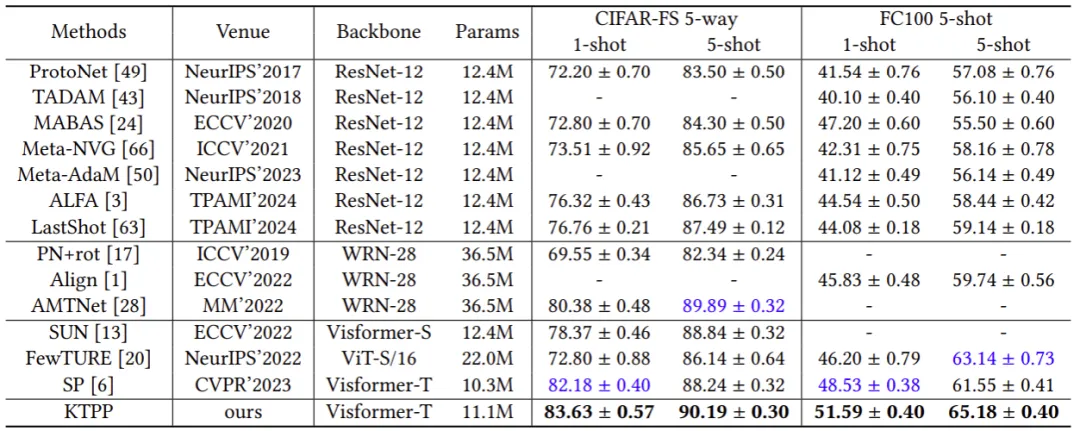
图6 在CIFAR-FS和FC100数据集的性能比较
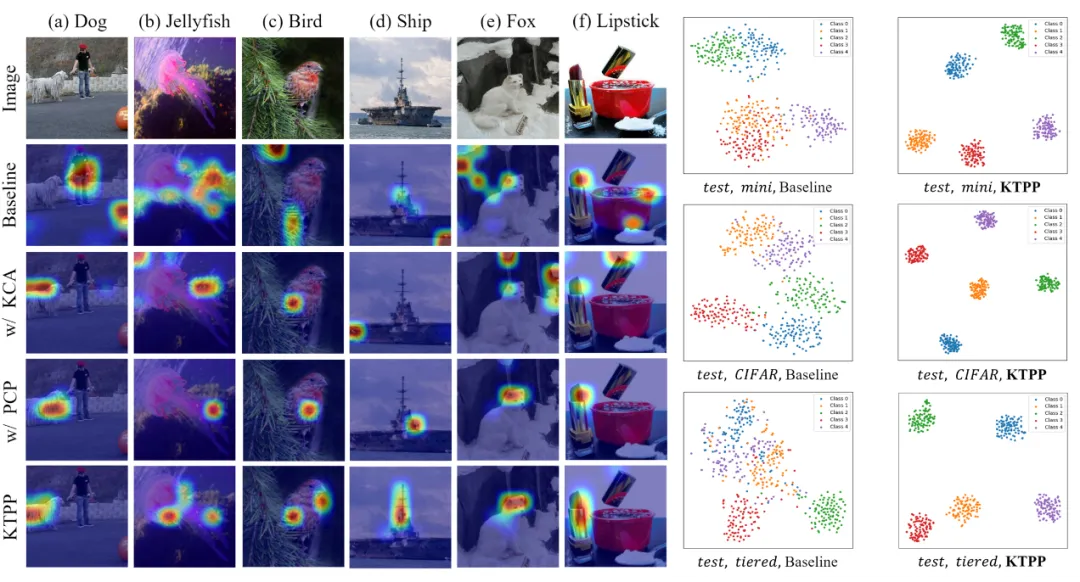
图7 注意力图和t-SNE可视化
05
Caption-Aware Multimodal Relation Extraction with Mutual Information Maximization
作者:
张泽帆,张伟琦,李延辉,白天
单位:
吉林大学计算机科学与技术学院
邮箱:
zefan23@mails.jlu.edu.cn,
zwq23@mails.jlu.edu.cn,
yanhui23@mails.jlu.edu.cn,
baitian@jlu.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3681219
代码:
https://github.com/zefanZhang-cn/CAMIM
发表会议:ACM MM 2024
1.研究背景
多模态关系抽取(Multimodal Relation Extraction,MRE)是多模态研究领域中非常关键的研究之一。该任务目标是根据文本输入以及相关的图像输入识别文本中所描述实体之间的关系。然而,现在的MRE模型在多模态对齐过程中很容易受到无关对象的影响,这被称为误差敏感性问题。造成该问题的主要原因是视觉特征与文本特征没有完全对齐,且推理过程可能会受到冗余和嘈杂信息的干扰,从而有丢失关键信息的风险,如图1中的例子所示,在多实体的多模态对齐过程中,会受到杂余信息的干扰,严重影响多模态对齐的过程。
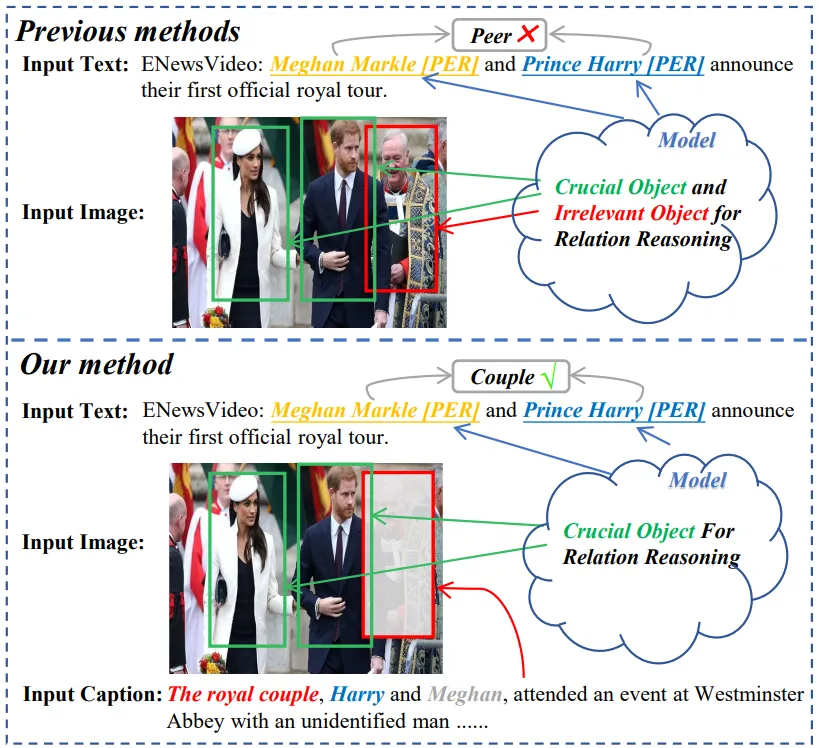
图1 研究现状
2.方法介绍
鉴于此,我们提出了一种基于描述感知和互信息的多模态关系提取网络(CAMIM)。具体来说,我们首先通过多模态大型语言模型(MLLM)生成详细的图像描述。然后,描述感知模块(CAM)进行细粒度的视觉实体和文本实体对齐以及推理,如图2中的具体模型结构设计,我们设计了特殊的注意力结构用于融合描述信息以及图像信息分别从句子级别以及单词级别。此外,为了在不同模态中保存关键信息,我们利用互信息最大化方法来保证各个多模态推理阶段对关键信息的保护。
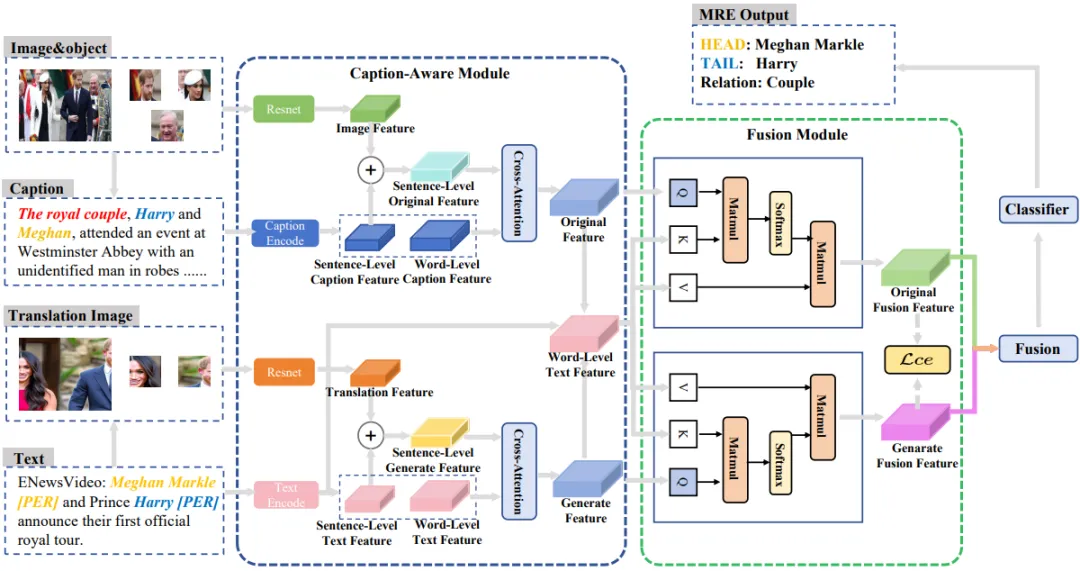
图2 模型框架
3.实验结果
实验表明,在基准数据集MNRE上,我们的模型优于最先进的MRE模型(F1 +1.89%),如下表一所示。此外我们将本文的方法应用到了两个典型的模型上,即HVPNeT以及TMR,结果显示本文的方法在各个模型上均有不错的提升效果(HVPNeT F1 +2.03%),也证明了我们的描述感知模块和互信息最大化方法的可插拔性和有效性。此外我们将大模型生成的描述信息进行了分析,如表二所示,可以发现,越精准(CapAcc越高),内容越详细(CapLen越长)的描述对多模态关系抽取的提升效果越明显,这也证明了本文的方法有效地解决了多模态对齐过程中的杂余信息干扰问题。
表1 对比实验结果
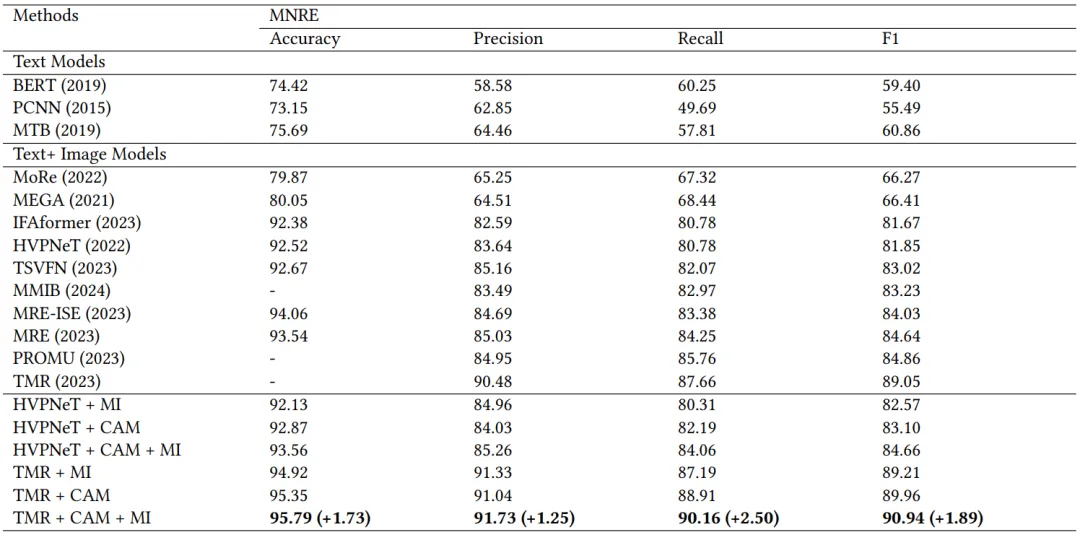
表2 不同大模型的消融实验结果


编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号