
【论文导读】2025年论文导读第三期
【论文导读】2025年论文导读第三期
CCF多媒体专委会 2025年02月25日 20:06 北京


论文导读
2025年论文导读第三期(总第一百二十期)
目 录
|
1 |
Semantic Editing Increment Benefits Zero-Shot Composed Image Retrieval |
|
2 |
ResVG: Enhancing Relation and Semantic Understanding in Multiple Instances for Visual Grounding |
|
3 |
CIEASR: Contextual Image-Enhanced Automatic Speech Recognition for Improved Homophone Discrimination |
|
4 |
AbsGS: Recovering Fine Details in 3D Gaussian Splatting |
|
5 |
CREAM: Coarse-to-Fine Retrieval and Multi-modal Efficient Tuning for Document VQA |
01
Semantic Editing Increment Benefits Zero-Shot Composed Image Retrieval
基于语义编辑增量的零样本组合图像检索
作者:
杨振宇1,钱胜胜1,薛迪展1,吴佳洪2,杨帆2,董未名1,徐常胜1
单位:
中国科学院自动化研究所1
快手科技有限公司2
邮箱:
yangzhenyu2022@ia.ac.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681649
作者主页:
https://github.com/yzy-bupt
发表会议:ACM MM2024
1.背景与动机
零样本组合图像检索(Composed Image Retrieval, CIR)任务旨在无需训练样本,仅根据参考图像和相对文本检索目标图像(相对文本提供指令更改参考图像)。传统方法假设目标图像与组合文本(参考图像描述+相对文本)在CLIP空间中最相似,依赖I2T模型和文本融合方法(仅使用相似度确定目标)。然而,这种假设在实际应用中存在问题,因为参考图像的信息常含噪声,而相对文本提供高质量、严格相关的信息。因此尽管参考图像或其文本描述与目标图像的相似度可能不高,但结合相对文本后的编辑文本与目标图像的相似度或排名的增量一定是最高的。因此,(1)如何表示和结合相对文本所贡献的语义编辑增量到检索过程中,是一个重要的挑战。
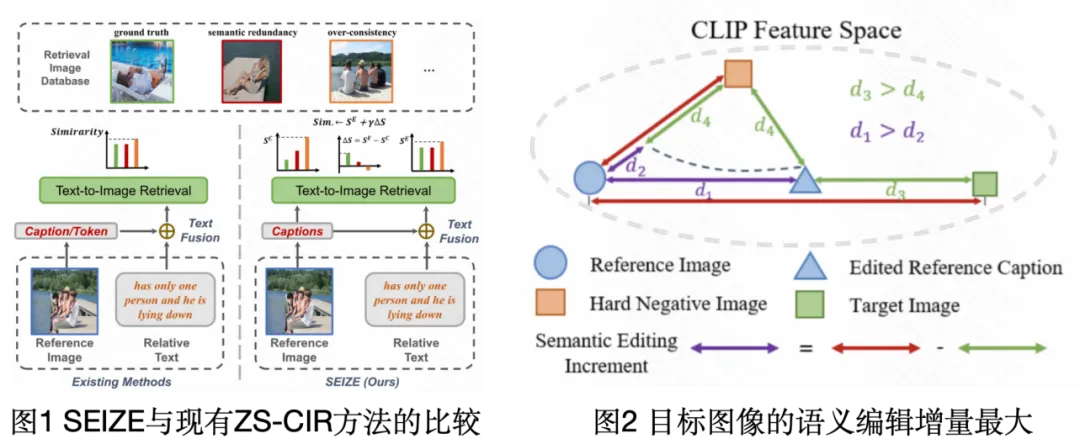
此外,目标图像的语义并不严格由参考图像和相对文本决定。相对文本旨在修改参考图像的语义,但查询并未明确指定要修改、保留或省略哪些视觉对象/属性。这种语义模糊性导致检索目标的语义范围广泛。因此,生成单一的编辑描述可能无法充分捕获组合结果的多种潜在语义,导致检索性能不佳。因此,(2)如何有效生成涵盖组合结果多种潜在语义的多样化编辑描述,是另一个关键挑战。
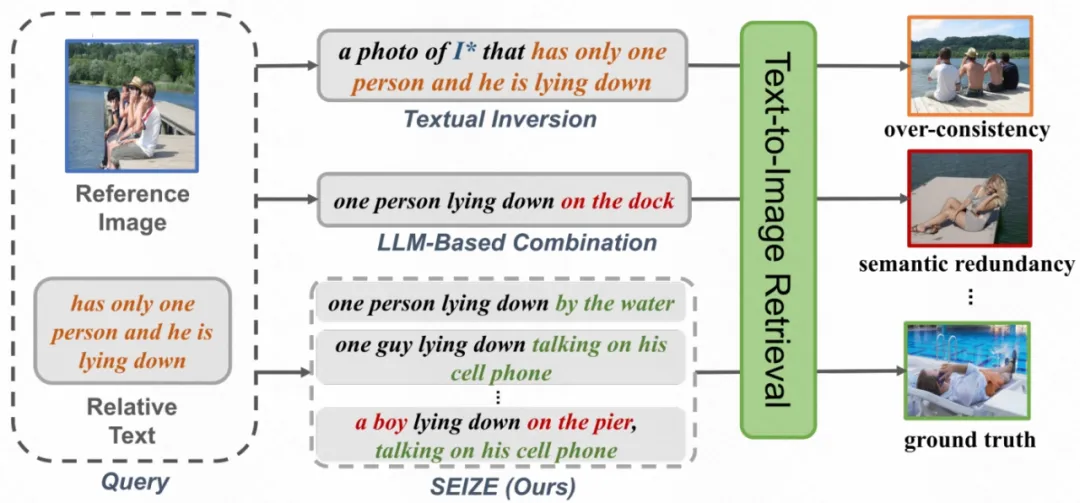
2.方法概述
本文提出了一种新的零样本组合图像检索方法,称为SEIZE(Semantic Editing Increment for ZEro-shot composed image retrieval)。该方法无需训练即可准确检索,并且可以无缝插入到各种CIR方法中,VLM和LLM模块可任意替换,即插即用。SEIZE方法通过以下两个主要模块来解决ZS-CIR中的挑战:
1.语义编辑搜索:综合考虑语义编辑增量和最终相似度,将相对文本所贡献的语义编辑增量结合到检索过程中,从而提高检索准确性。具体来说,我们分别计算组合文本和内容文本与检索图像之间的余弦相似度。然后,我们将相似度或排名的差异作为语义编辑增量,并将其添加到绝对相似度中以获得最终调整后的得分,最后在CLIP特征空间中基于该得分进行组合图像的检索。
2.广度组合推理:生成多样化的编辑描述,涵盖组合结果的多种潜在语义,克服ZS-CIR任务的模糊性。为实现这一目标,我们为参考图像生成多样化的描述,侧重于不同的语义视角。然后,我们提示大型语言模型(LLM)根据相对文本推断广度编辑描述,描述可能的多样化语义的组合图像。最后,用语义编辑搜索模块检索到最终的目标图像。

3.实验分析
我们在三个公共数据集上对SEIZE进行了评估:CIRCO、CIRR和FashionIQ,并均取得了SoTA的表现。尤其在CIRCO上,在mAP@5、mAP@10、mAP@25和mAP@50指标上,SEIZE分别比第二好的CIReVL方法高出34.52%、35.82%、35.18%和34.63%,证明了SEIZE在组合图像检索中的有效性。
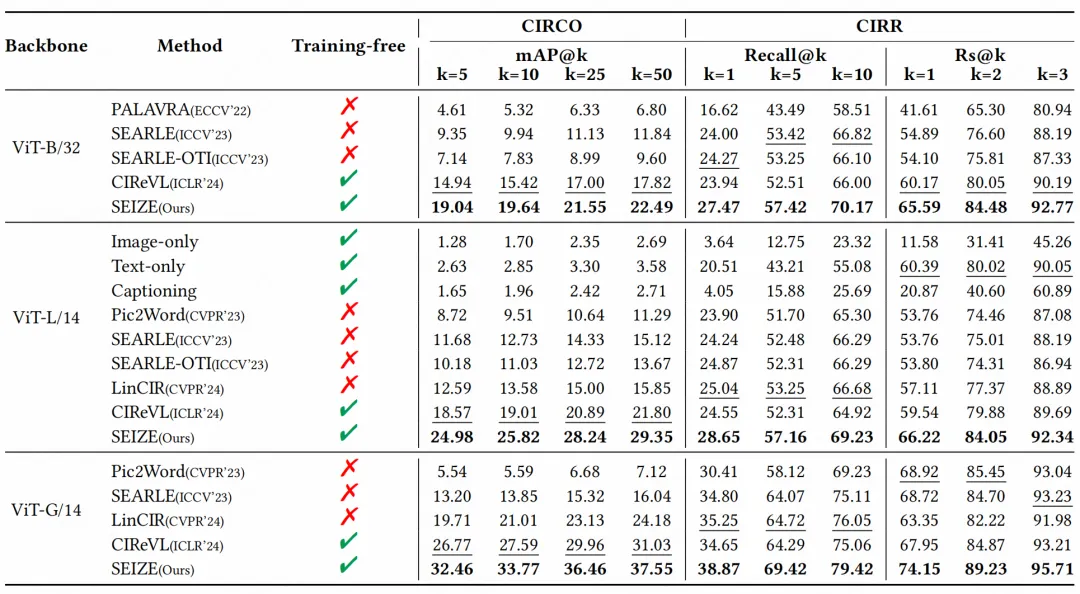
实验结果表明,语义编辑搜索(SES)模块显著提高了所有ZS-CIR方法的性能,特别是文本反转方法,平均提升了21.66%。这证明了SES模块的即插即用性、简单性和有效性。此外,VLM和LLM模块可任意替换,即插即用,针对不同的应用场景,我们可以考虑必要的计算开销和效率,选择最合适的VLM和LLM进行组合。

02
ResVG: Enhancing Relation and Semantic Understanding in Multiple Instances for Visual Grounding
作者:
郑明航,张家华,陈庆超,彭宇新,刘洋*
单位:
北京大学王选计算机研究所多媒体信息处理研究室
邮箱:
minghang@pku.edu.cn
zhangjiahua@stu.pku.edu.cn
qingchao.chen@pku.edu.cn
pengyuxin@pku.edu.cn
yangliu@pku.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681660
代码:
https://github.com/minghangz/ResVG
实验室主页:
http://www.wict.pku.edu.cn/mipl/
发表会议:ACM MM 2024
*通讯作者
1.研究背景
视觉定位任务旨在根据自然语言查询在图像中定位被查询提及的对象。然而,如图1所示,当图像中存在大量与目标对象相同类别的干扰对象时,准确定位目标对象仍然是一个重要挑战。这种情况下,查询文本往往会描述目标对象和其他对象的空间关系(如最左边、最大等),或是描述目标对象的细粒度属性(如颜色、形状等)。然而,本文通过实验发现,在图像中存在多个干扰对象时,现有方法的性能出现了明显下降。这表明现有方法对查询文本中所描述的目标对象细粒度属性和对象间的空间关系理解不足。

图1现有方法存在的问题
2.本文方法
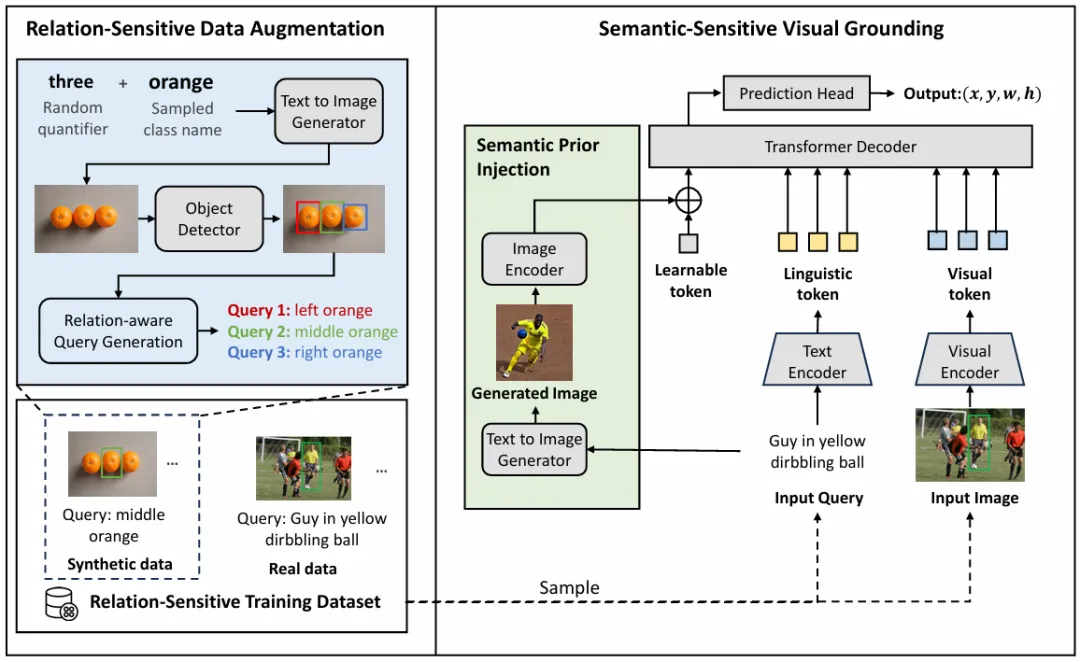
图2多实例关系与语义理解增强的视觉定位模型
如图2所示,本文提出了多实例关系与语义理解增强的视觉定位模型(ResVG),通过文生图模型分别生成包含多实例的图像用于训练,并生成符合目标细粒度属性的图像用于引导模型定位,从而显著提升模型对目标对象空间关系和细粒度属性的理解。具体而言,本文提出关系敏感的数据增强方法,利用文生图模型生成包含多个同类别对象的图像,并基于图像中检测到的物体空间关系生成伪查询,将伪查询和生成图像作为额外训练数据以增强模型对物体空间位置关系的理解能力。本文进一步提出语义敏感的语义先验注入,利用文生图模型以查询文本作为提示词,生成与目标对象细粒度外观属性(例如颜色、形状、纹理等)相匹配的参考图像,引导模型关注与文本查询视觉相似性更高的区域特征,从而增强模型对目标对象细粒度属性的理解。
3. 实验结果
本文在RefCOCO、RefCOCO+、RefCOCOg、ReferItGame和Flickr30K五个数据集上进行验证。表1、2的结果表明ResVG在多个数据集上超越了现有方法。表3的消融实验表明,语义敏感模块和关系敏感模块均对性能提升有重要贡献。表4的实验还展示了模型在跨数据集任务中的鲁棒性,例如在RefCOCO训练并在RefCOCO+测试时,ResVG的性能显著高于基线方法。图3展示了部分可视化结果。可以观察到,本文所提出方法能合成依赖物体间空间位置关系的训练样本;准确理解目标物体的细粒度属性。
表1在RefCOCO、RefCOCO+、RefCOCOg上性能对比

表2在ReferItGame和Flickr30K上性能对比
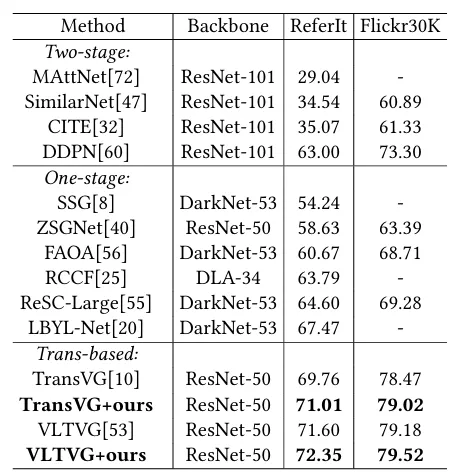
表3消融实验

表4跨数据集泛化性


图3可视化结果
03
CIEASR: Contextual Image-Enhanced Automatic Speech Recognition for Improved Homophone Discrimination
作者:
王子翼、戎奕名、江德扬、吴浩然、周世玉、徐波
单位:
中国科学院自动化研究所
邮箱:
wangziyi2022@ia.ac.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681665
发表会议:ACM MM 2024
1.引言
自动语音识别(ASR)近年来取得了显著突破,特别是在大规模预训练语音模型(如Wav2Vec 2.0和Whisper)的推动下。然而,这些模型在同音词的区分上依然面临挑战。同音词具有相同或接近的发音,仅依靠语音或传统的语言模型解码器难以正确区分。引入视觉辅助信息如唇部动作或手势,需要严格的时间同步。此外,基于场景图像的信息融合仍处于初步探索阶段,其性能尚无法与先进的语音预训练模型匹敌。本论文是第一个将场景图像线索引入预训练语音模型whisper的工作。

2.方法概述
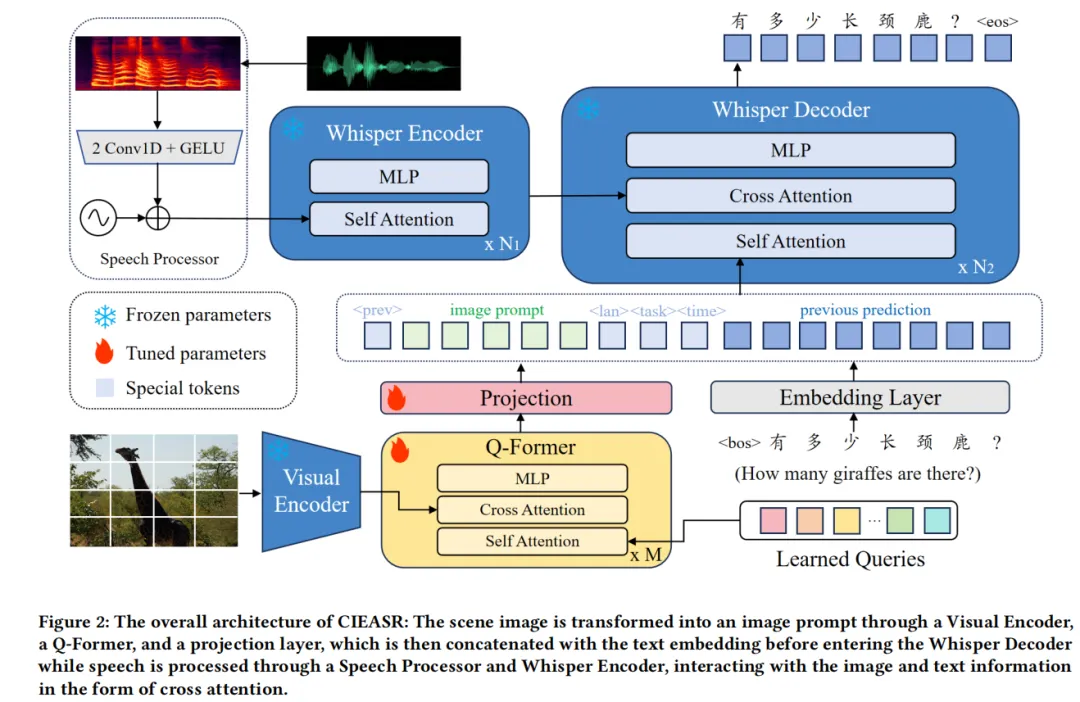
为了解决上述问题,我们提出了场景图像增强语音识别系统(CIEASR),这是一种新颖的多模态语音识别模型。CIEASR通过将场景图像作为软提示(soft prompt)集成到Whisper模型中,以辅助纠正同音词识别错误。具体来说:
1. 我们采用Q-Former模型从场景图像中提取语义信息,将其嵌入到Whisper模型的文本空间中,无需对Whisper模型进行微调,从而保留其强大的多语言和鲁棒性能力。
2. 在数据层面上,扩展和优化了VSDial数据集,以实现图像、语音和文本的三模态对齐,用于全面实验。
3. 提出了基于跨模态提示的融合方法,充分利用图像的上下文语义信息,提高了对实体名词和人称代词的识别能力。
3. 关键实验与结果
CIEASR的性能在多个数据集上均达到了新的水平:
1. 在VSDial中文语音数据集上,字符错误率(CER)由3.61%降低至0.92%。
2. 在Flickr8K英文语音数据集上,词错误率(WER)从2.42%降低至2.05%。
实验表明,场景图像有效提升了同音词的识别性能,例如纠正中文第三人称代词(他/她/它)以及特定场景中实体名词的识别错误。这种改进得益于图像提供的丰富上下文信息,例如背景、纹理和空间以及语义信息。
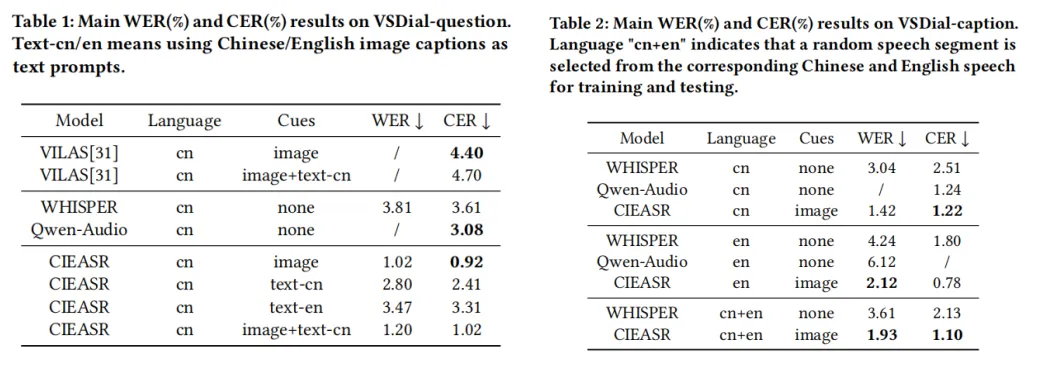

以上为三个主实验实验结果,关于消融实验和实体名词和人称代词的分析实验可见论文)
4.可视化分析
采用Grad-CAM分析了图像信息对语音识别结果的影响。可视化图证明,模型能够准确聚焦于与目标词汇相关的图像区域。例如,在中文句子“有多少长颈鹿?”的场景中,模型借助图像提示正确识别出“长颈鹿”,而非错误的近音词“场景物”。这种可解释性验证了CIEASR在图像信息辅助下的错误纠正能力。在中文第三人称代词上也有极大的准确率提升。这两类词是场景图像线索对于语音识别系统的主要提升所在。

04
AbsGS: Recovering Fine Details in 3D Gaussian Splatting
作者:
叶宗新1,2 #,李问宇1#,刘斯盾1,乔鹏1*,窦勇1*
单位:
国防科技大学,并行与分布计算国家重点实验室
美团
邮箱:
yezongxin21@nudt.edu.cn
wenyu18@nudt.edu.cn
liusidun@nudt.edu.cn
pengqiao@nudt.edu.cn
yongdou@nudt.edu.cn
项目主页:
https://ty424.github.io/AbsGS.github.io/
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3681361
发表会议:
ACM MM 2024
#共同第一作者
*通讯作者
1.引言
3D高斯泼溅(3D Gaussian Splatting, 3DGS)算法通过将3D高斯基元与可微分光栅化技术结合,实现了实时且高质量的新视角合成效果。然而,由于采用的自适应密度控制策略存在缺陷,导致3DGS在应对包含高频细节的复杂场景时,经常遭遇过度重建(over-reconstruction)的问题,致使渲染的图像出现模糊。目前,这一缺陷的根本原因尚未得到充分研究。为此,本文对该缺陷产生的原因进行了深入且全面的分析,并指出是由于“梯度碰撞”现象的存在,抑制了过度重建区域中大高斯基元的分裂,最终导致渲染图像模糊。基于此发现,本文提出了方向一致视图空间位置梯度作为加密指标,借助该指标可以有效识别并分裂过度重建区域的大高斯基元,恢复高频细节。在多个公开数据集上的实验结果表明,本文提出的方法使用更少或者近似的高斯基元数量即可实现最佳的新视图合成质量。
2.方法概述
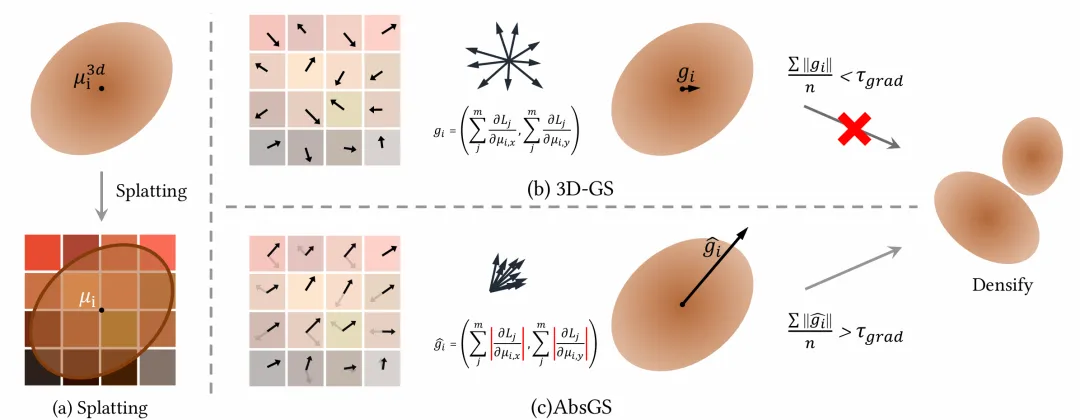
图1 AbsGS与3DGS加密策略整体流程对比
3DGS采用高斯基元(3D高斯分布)表达场景,通常采用运动结构恢复得到的稀疏点云进行初始化,为了充分表达,在优化过程中会对高斯基元进行加密(克隆或分裂)。3DGS采用每100轮迭代的平均视图空间位置梯度作为加密指标:

即高斯基元所覆盖住的像素对其2D投影中心的梯度的和的平均。该指标内在逻辑的合理性在于梯度值越大,说明该区域表达越不好,越应该加密。然而,通过公式推导以及直观感受可以发现,在单次迭代中各个像素对高斯基元的2D投影中心的梯度(后文简称为“像素梯度”)可能方向相反,进而在求和时相互抵消,我们将该现象命名为“梯度碰撞”。由于该现象的存在,即便各个像素梯度都很大(各个像素表达都不佳),求和后梯度依然可能很小(误认为整体表达很好),进而抑制了高斯基元的加密。为此,本文在每一轮中对像素梯度求和前,先对各个像素梯度进行绝对值操作,以此消除梯度碰撞。我们将该指标命名为方向一致视图空间位置梯度。该方法不仅十分有效,且实现极其简单,便于与其他基于3DGS的方法结合。
3.实验对比
本文主要在公开数据集Mip-NeRF360、Tanks&Temples以及DeepBlending上对比了3DGS以及一些NeRF相关方法。表1结果显示,本文提出的AbsGS各项指标都优于3DGS,特别是LPIPS指标,该指标更接近人眼对图像相似度的评判,对图像模糊更敏感。此外,即便使用更少的高斯基元,AbsGS依然有多项指标领先。图2对比了高频细节区域表达能力。AbsGS可以有效对过度重建区域高斯进行分裂,以更好表达细节。图3结果显示AbsGS对需要加密的高斯基元识别更准确。图4展示了AbsGS与其他方法结合的效果,可以有效改善过度重建问题。

表1在公开数据集上的定量结对比

图2可视化结果对比

图3对需要加密的高斯基元的识别能力对比

图4与其他方法结合
05
CREAM: Coarse-to-Fine Retrieval and Multi-modal Efficient Tuning for Document VQA
作者:
张津旭,于泳淇,张宇
单位:
哈尔滨工业大学
邮箱:
jxzhang@ir.hit.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3681361
发表会议:ACM MM 2024
论文简介
这篇工作主要面向多模态领域的多页文档图像问答任务。现有的工作局限于在单个页面内定位信息,缺乏对跨页面问答交互的支持。此外,现有模型输入的token长度限制可能导致与答案相关的部分被截断,导致答案错误。对此,我们提出了一种新颖的方法CREAM,该方法侧重于多页文档的高性能检索,并集成了相关文档页的多模态信息,以有效解决这一关键问题。
为了克服当前文本嵌入相似度方法的局限性,我们首先提出了一种Coarse-to-Fine的检索和排序方法。Coarse-grained阶段使用文本Embedding模型分别提取问题和文档中各个文本块的Embedding向量,并计算它们之间的相似度实现初始化排序,而 Fine-grained阶段我们提出了一个多轮分组排序的算法,具体算法如表1所示,如每次输入8个文本块为一组到排序模型中,每次选择每组的前3个作为候选文本块再次进行分组,以此类推,直到选择出前k个指定的文本块与对应的文档图像。

随后,我们提出能有效处理多页文档图像的多模态大语言模型,其框架如图1所示,即通过文档视觉编码器获得各页表示后,对它们利用attention机制进行集成,并利用多层ViT Transformer层以学习到各页之间的关联以及权重信息,使我们能够有效地合并多页文档的视觉信息,由此多模态大语言模型(multimodal large language model, MLLM)能够同时处理单页和多页文档。最后,我们应用各种参数高效调优方法来提高文档可视化问答性能。实验表明,我们的方法在多个文档视觉问答数据集上实现了较好的效果。
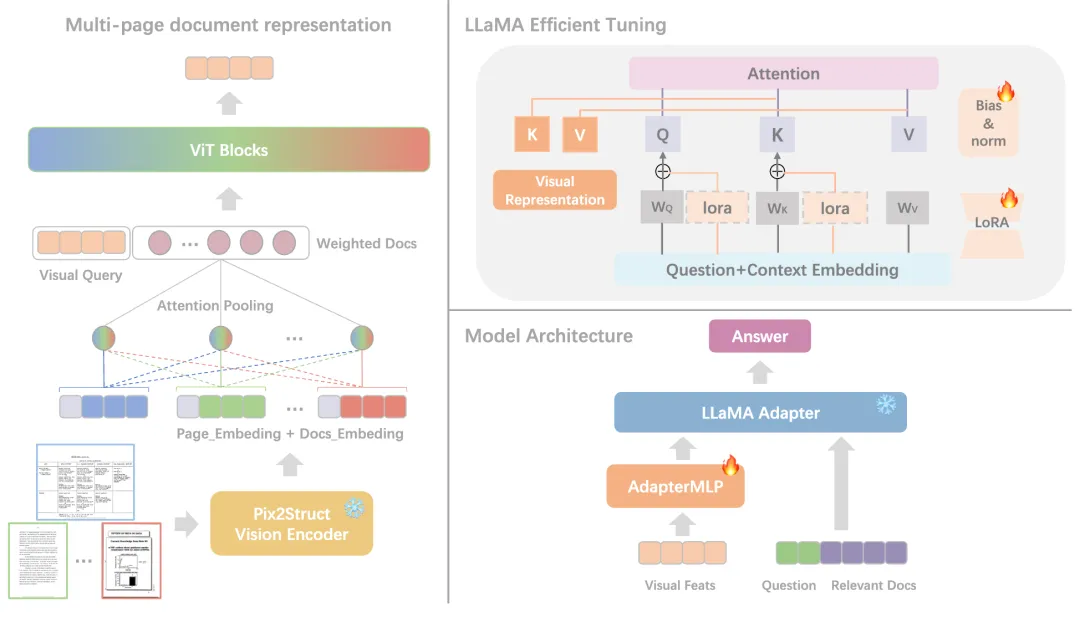
图1多页文档理解模型架构

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
错误!未指定文件名。
 京公网安备11010802017125号
京公网安备11010802017125号