
【论文导读】2025年论文导读第四期
【论文导读】2025年论文导读第四期
2025年03月11日 14:02 吉林


论文导读
2025年论文导读第四期(总第一百二十一期)
目 录
|
1 |
MLP Embedded Inverse Tone Mapping |
|
2 |
FakingRecipe: Detecting Fake News on Short Video Platforms from the Perspective of Creative Process |
|
3 |
FakingRecipe: Detecting Fake News on Short Video Platforms from the Perspective of Creative Process |
|
4 |
Style-conditional Prompt Token Learning for Generalizable Face Anti-spoofing |
|
5 |
2M-AF: A Strong Multi-Modality Framework For Human Action Quality Assessment with Self-supervised Representation Learning |
01
MLP Embedded Inverse Tone Mapping
基于嵌入式多层感知机的逆色调映射
作者:
柳攀军1,李家丞1,王立志2,查正军1,熊志伟1
单位:
1中国科学技术大学,2北京理工大学
邮箱:
panjun_liu@mail.ustc.edu.cn,
jclee@mail.ustc.edu.cn,
wanglizhi@bit.edu.cn,
zhazj@ustc.edu.cn,
zwxiong@ustc.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3680937
作者主页:
https://github.com/pjliu3/MLP_iTM
发表会议:ACM MM2024
1.背景
高动态范围(HDR)和宽色域(WCG)媒体技术近年来快速发展,能够显著提升显示设备的亮度范围和色彩丰富度。然而,HDR/WCG 媒体的广泛应用受到存储和带宽限制和设备兼容性问题的限制。 现有的逆色调映射方法大致分为规则驱动和学习驱动两类。规则驱动的方法对曝光不足区域的细节重建效果较差,而学习驱动的方法依赖外部数据集进行域级映射,通常假设固定的色调映射操作,在适应不同场景时表现有限。此外,由于逆色调映射本质上是一个病态问题,这些方法往往需要大量计算资源,难以满足实时性要求。针对上述问题,本文提出了一种基于元迁移学习的逆向色调映射框架,创新性地将图像级逆色调映射模型嵌入为 SDR 图像的元数据,显著提高 HDR/WCG 媒体的传输和重建效率。
2.方法
本文提出的框架包含元训练阶段、迁移阶段和重建阶段 三个步骤,如图1所示:
1. 元训练阶段:域级逆色调映射模型的预训练
基于外部 HDR/WCG 数据集,本文训练了一个轻量级多层感知机(MLP)模型,用于将 SDR 像素映射到 HDR/WCG 像素。这一阶段采用了 元学习策略,这一策略显著提高了模型的泛化能力,为后续的图像级优化奠定了基础。
2. 迁移阶段:图像级逆色调映射模型的在线优化
在接收到 HDR/WCG 和其对应的 SDR 图像对后,本文利用预训练的MLP模型,对每张图像进行在线迁移优化。为此设计了一种 基于空间感知的在线困难样本挖掘(OHEM)机制:根据误差图的反馈,有选择性地采样困难像素对进行训练,使模型更关注图像中的复杂区域。最终得到一个专门适配当前图像的轻量级逆色调映射模型,该模型的参数(约 40KB)被嵌入到 SDR 图像中作为元数据。
3. 重建阶段:嵌入式 MLP 模型的高效解码
对 SDR 显示设备,模型保持了与原始 SDR 图像的兼容性;对 HDR 显示设备,模型以高效方式(约 2 毫秒)完成 HDR/WCG 重建,且额外数据开销仅为 40KB(占 SDR 图像大小的 2%)。

图1 总体框架
3.实验结果
在定量分析上,如图表2所示,相较于现有的方法,我们在感知均匀 PSNR 指标上提高了 3dB,并在色度精度(ΔEITP)上显著降低误差。在效率上,我们的框架在 4K 分辨率的图像上仅需 1.22 秒完成迁移,重建延迟仅为 2 毫秒,额外的元数据开销仅为 40KB,远低于其他元数据方法。
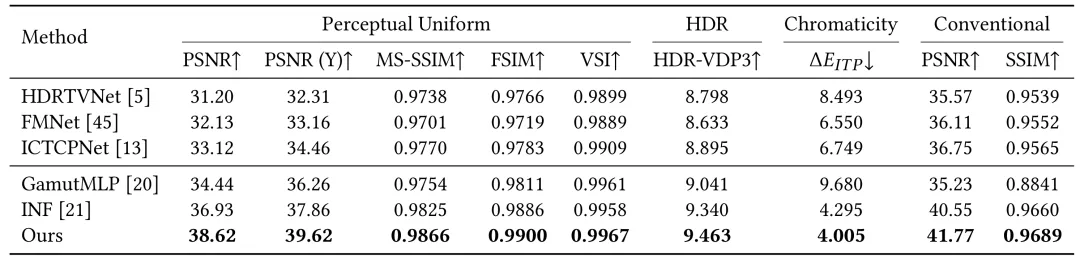
图2 定量实验结果
在定性分析上,如图表3所示,在相较于现有的方法,本文方法展现了显著的细节还原能力,尤其是在高亮区域和复杂纹理区域。
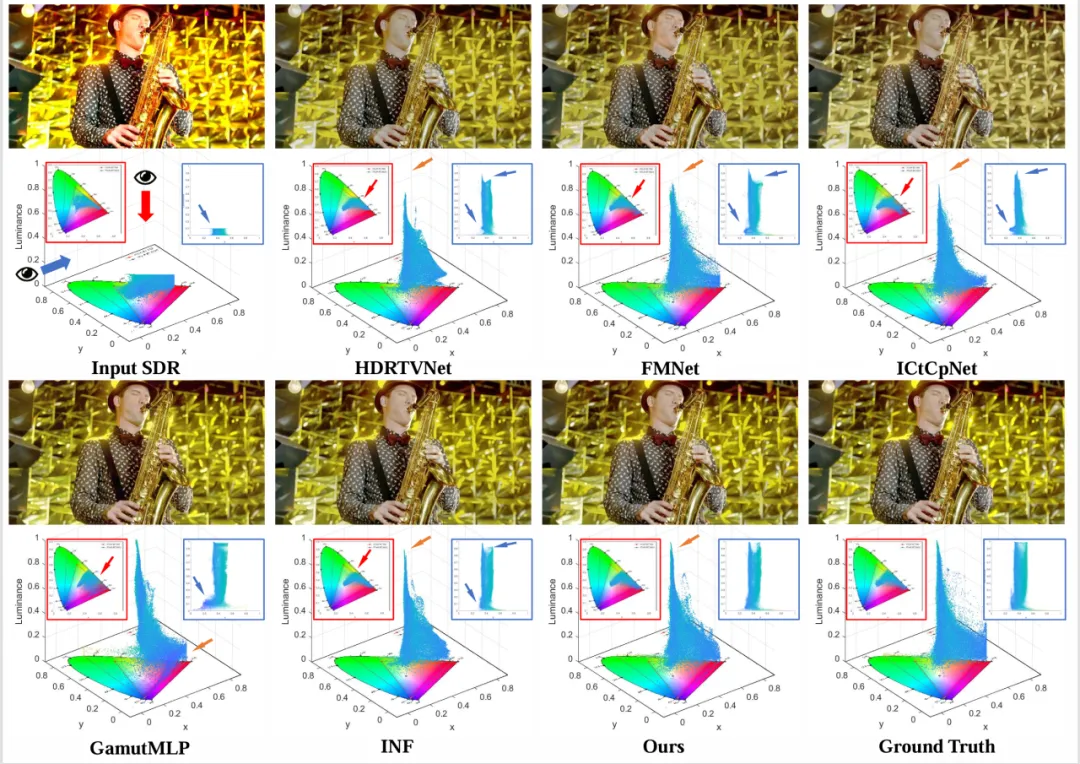
图3 定性实验结果
02
FakingRecipe: Detecting Fake News on Short Video Platforms from the Perspective of Creative Process
作者:
卜语嫣1,2,盛强1,曹娟*1,2,亓鹏3,汪旦丁1,李锦涛1
单位:
1中国科学院计算技术研究所
2中国科学院大学
3新加坡国立大学
邮箱:
buyuyan22s@ict.ac.cn,
shengqiang18z@ict.ac.cn,
caojuan@ict.ac.cn,
peng.qi@nus.edu.sg,
wangdanding@ict.ac.cn,
jtli@ict.ac.cn
论文:
https://dl.acm.org/doi/pdf/10.1145/3664647.3680663
代码数据仓库:
https://github.com/ICTMCG/FakingRecipe
领域进展仓库:
https://github.com/ICTMCG/Awesome-Misinfo-Video-Detection
发表会议:ACM MM 2024
*通讯作者
1.研究背景
近年来,假新闻视频的大量出现给互联网内容生态带来极大威胁。短视频虚假新闻检测问题关注度也与日俱增。现有的假新闻视频检测方法大多遵循针对文本或图像新闻的检测思路,侧重于通过分析新闻呈现了什么(What)来挖掘真实性判断线索,包括单一模态内的内容真实性(例如检测深度伪造)和多模态间的内容相关性(例如语义、情感一致性)等。这些方法往往忽视了短视频平台独有特性带来的挑战和潜在线索:a)短视频平台的开放性使得历史上存在的真实新闻视频有可能被下载下来重新编辑上传,用于假新闻制作。这一特性弱化了传统的基于内容一致性的检测方法,但带来的高度自由的选材行为可以为真实性判断提供潜在线索。b)便捷的视频剪辑工具的普及降低了视频编辑门槛,导致对视频的编辑行为普遍存在。这一特性使传统的基于编辑行为取证的检测方法不再适用,但普遍存在的高度自由的二次创作行为同样可以提供重要的真实性判断线索。短视频平台上的假新闻创作者通常缺乏第一手的真实新闻素材和专业的新闻制作能力、且往往是为了某种利益故意制作假新闻。因此,受主客观因素影响,真新闻和假新闻视频创作过程不同,导致最终呈现的新闻视频的特性也会不同,这些具有独特性的痕迹可以作为假新闻检测的重要线索。因此,本工作提出从创作过程视角出发,即通过分析新闻是如何呈现的(How)来挖掘指示新闻视频可信程度的有效线索,并通过多角度实证分析验证了这一思路的可行性。
2.研究方法
对创作过程的分析关键是建模典型的创作行为。本工作聚焦对两类主要创作行为的分析,包括挑选素材行为和编辑素材行为。在实证分析部分,本文得到了一些观察发现,包括假新闻挑选的音频素材相对更情绪化、假新闻挑选的视觉素材与其搭配的文本素材语义一致性相对更低、假新闻在进行往视觉画面上叠加文字、剪辑拼接多段素材等操作时会倾向于使用更简单的设计。基于上述的观察,本工作设计了创作过程视角引导的检测模型FakingRecipe,综合素材挑选行为启发的特征建模和素材编辑行为启发的特征建模,实现对短视频新闻的真实性判断。素材挑选行为启发的特征建模从情感和语义两方面进行分析,并采用分层融合机制对多视角下的多模态特征进行融合。素材编辑行为启发的特征建模从空间编辑和时间编辑两方面进行分析,空间编辑行为特征分支利用双向注意力模块引导模型关注到视觉画面的文本区域,实现对叠加文字图层的视觉特征建模;时间编辑行为特征分支利用层级化时序结构提取网络捕捉不同素材片段曝光时长和时序位置设计传达的微妙信息,实现对视频时序结构的特征建模。
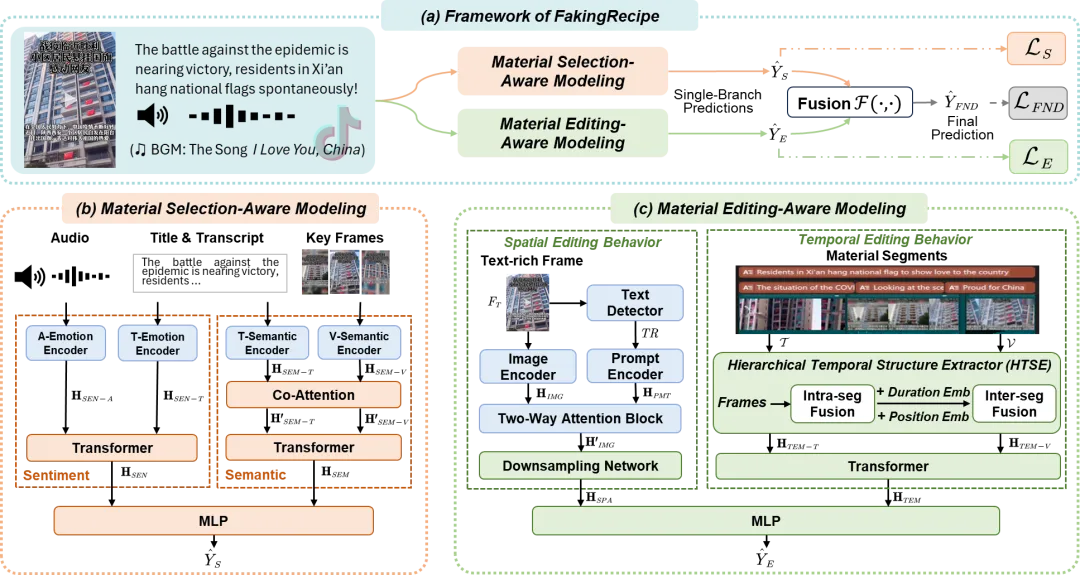
图1 FakingRecipe模型整体架构
3. 实验评估
为使实验测评覆盖更丰富的语种和新闻话题,本工作参照中文基准数据集FakeSV的采集标注方式构建了英文数据集FakeTT。FakeTT数据集采集自TikTok平台,由1,172条假新闻短视频和819条真新闻短视频构成,样本发布时间范围为2019-2024年,提供了包括标题文本、视频、音频等在内的多模态信息。我们在中英文两个短视频虚假新闻数据集上进行了性能评估验证,实验结果表明,FakingRecipe的表现优于七种已有方法,显著提升了短视频虚假新闻检测的准确性。
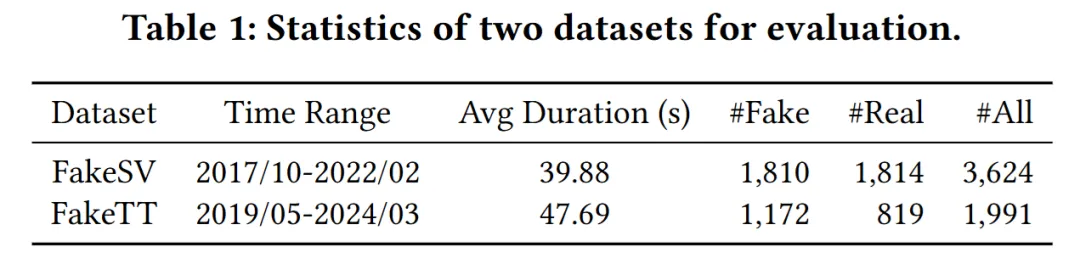
表1 本文使用的评测数据集
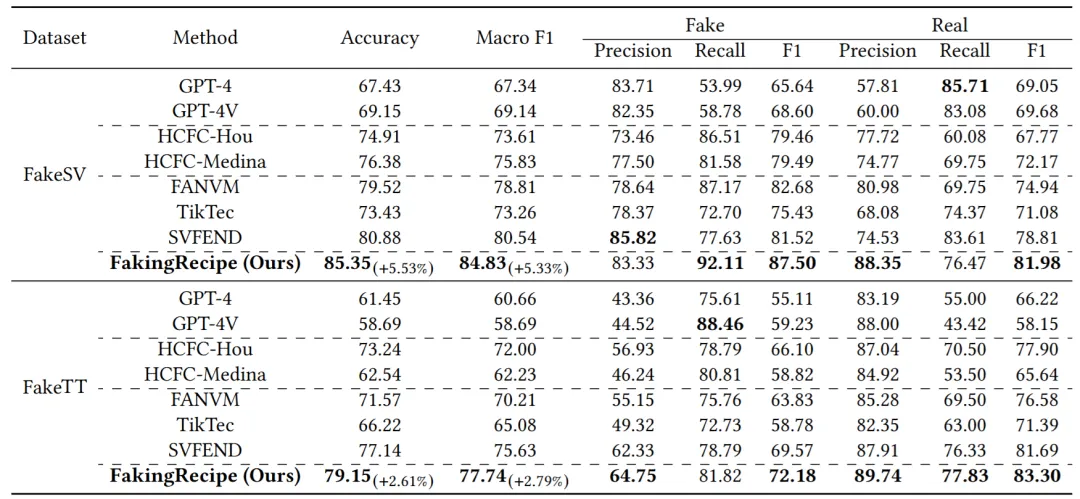
表2 中英数据集上FakingRecipe与基线方法的性能对比
03
FewVS: A Vision-Semantics Integration Framework for Few-Shot Image Classification
作者:
李卓岭,王勇,李凯通
单位:
中南大学
邮箱:
zhuolinglicn@gmail.com,
ywang@csu.edu.cn,
likaitong1008@gmail.com
论文:
https://dl.acm.org/doi/10.1145/3664647.3681427
代码:
https://github.com/zhuolingli/FewVS
发表会议:ACM MM 2024
1.论文简介
最近的方法从类别名称中提取语义信息并设计模态对齐机制,以整合视觉与语义模态的信息,从而解决小样本图像分类问题。然而,类别名称提供的信息十分有限,难以捕捉图像中的视觉细节。这种局限性导致视觉-语义对齐存在偏差,进而限制了整合效果。为此,本文提出了一种名为 FewVS 的框架,通过引入 CLIP 作为连接视觉和语义模态的桥梁,避免了有偏差的视觉-语义对齐,从而为更好的视觉-语义整合奠定了基础。此外,为了在推理阶段进一步提升视觉-语义整合性能,FewVS利用大型语言模型为类别名称挖掘潜在的细粒度语义属性,并通过一个在线优化模块,以自适应地将这些语义属性与图像中提取的视觉信息相结合。实验结果表明,FewVS有效提升了基线方法的性能,并在四个具有挑战性的数据集上超越了当前的最新方法。
2.方法概述
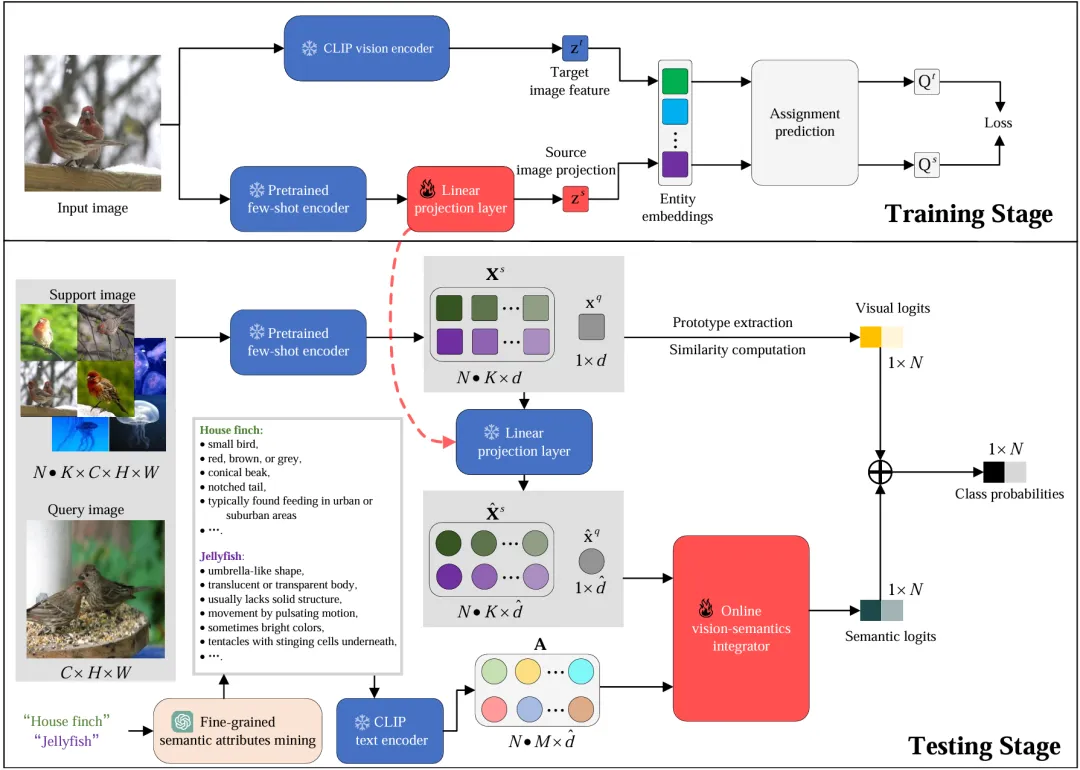
图1 FewVS的训练和测试管线
FewVS 的训练和测试管线如图1所示。在训练阶段,FewVS 通过将视觉-视觉对齐作为代理任务,避免了有偏差的视觉-语义对齐。具体而言,FewVS 在小样本编码器之后接入了一个线性投影层,用于将小样本编码器提取的特征映射为 CLIP 视觉编码器的特征。为提高对齐质量,FewVS 借鉴了最优传输的思想,分别计算小样本编码器和 CLIP 视觉编码器特征的分配预测,并通过最大化这两种分配预测之间的一致性来训练线性投影层。在测试阶段,为进一步提高视觉-语义整合效果,FewVS利用大语言模型为类别名称挖掘潜在的细粒度语义属性,并使用在线视觉-语义整合器(结构如图2所示)来自适应地将这些语义属性与图像中提取的视觉信息相结合。具体而言,在线视觉-语义整合器在推理过程中通过内部优化循环来学习一个权重向量,以动态调整各语义属性对分类结果的贡献。
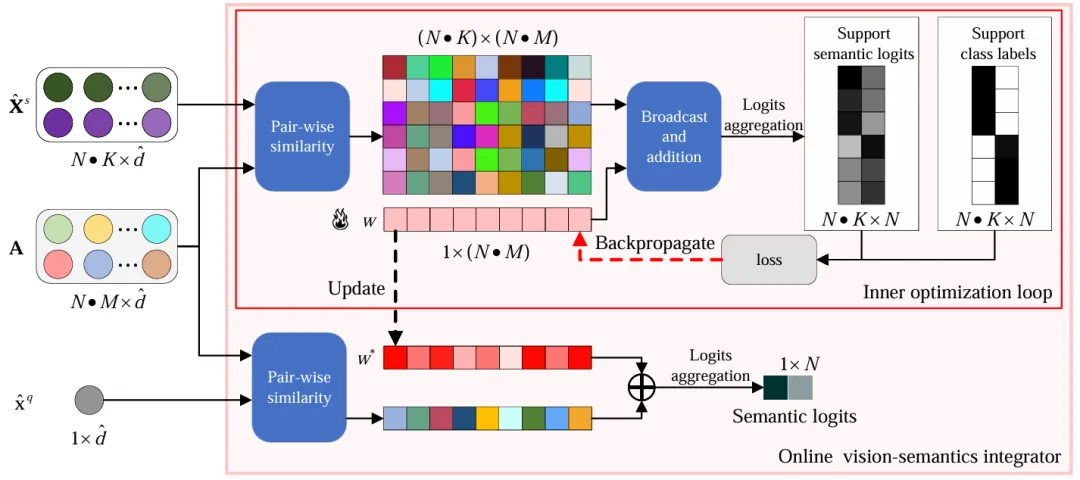
图2 在线视觉-语义整合器
3.实验对比
为评估所提方法的性能,本文在四个具有挑战性的小样本图像分类基准数据集(miniImageNet,tieredImageNet,FC100,CIFAR-100)上进行了实验。实验结果如表1和表2所示,FewVS有效提升了基线方法的性能,并优于现有方法。
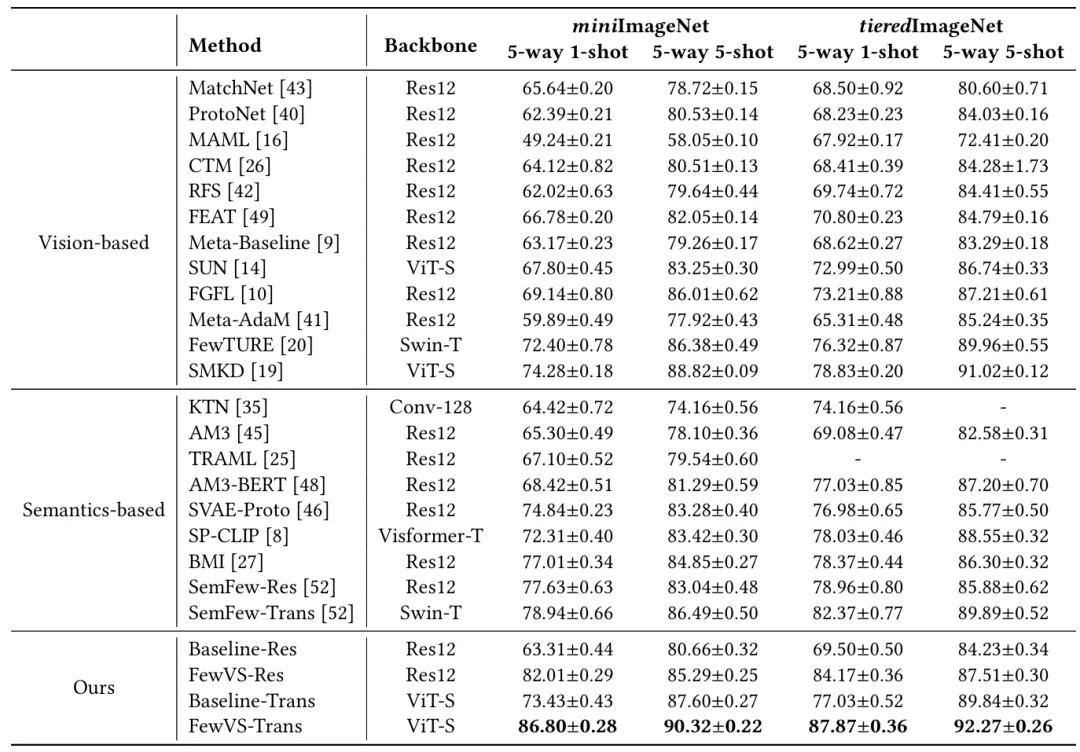
表1 miniImageNet和tieredImageNet上的实验结果
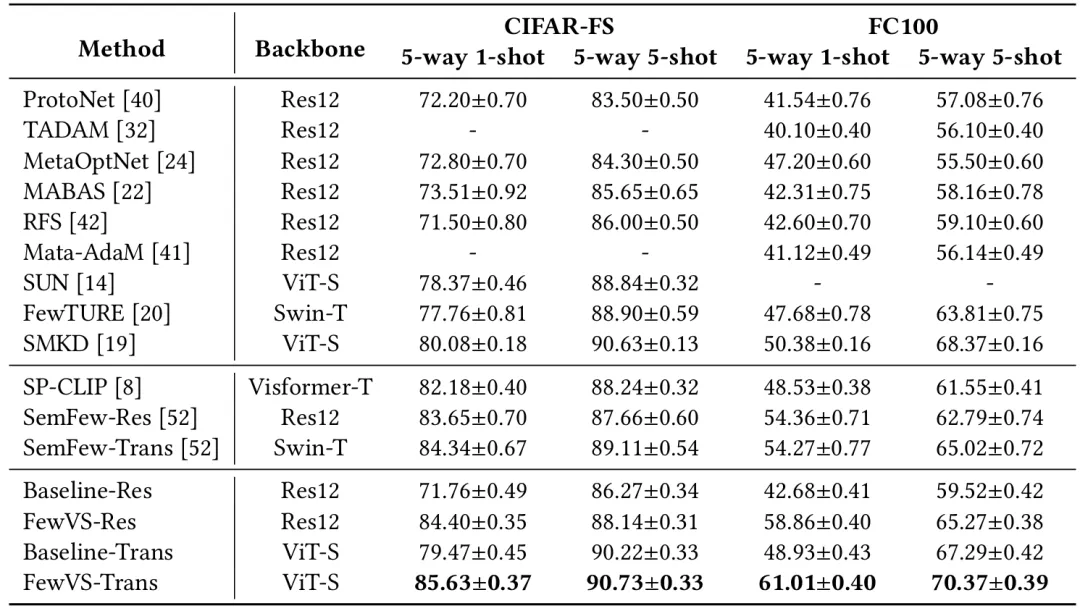
表2 CIFAR-FS和FC100上的实验结果
04
Style-conditional Prompt Token Learning for Generalizable Face Anti-spoofing
作者:
郭嘉宝,刘欢,罗易智,胡雪莉,邹航,张园,刘会,赵波
单位:
武汉大学
邮箱:
garbo_guo@whu.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3680857
发表会议:
ACM MM 2024
1.论文简介
近年来,实现人脸活体检测领域泛化的研究日益受到重视。模型过度拟合于与活体无关的显著信号是导致泛化性能差的主要原因。以往的方法试图通过将来自多个领域的图像映射到共同的特征空间,或促进图像特征中领域特定特征和任务相关特征的分离,从而缓解过拟合问题。利用视觉-语言预训练模型(如CLIP)的文本特征,动态调整图像特征以提高泛化能力,不仅能够探索更广泛的特征空间,还能避免潜在的语义信息降解。具体而言,本文提出了一种基于风格条件提示令牌学习(S-CPTL)的人脸活体检测方法,旨在通过训练引入的提示令牌来生成通用的文本特征,使其承载视觉风格,并用作分类器的权重,从而提升模型的泛化能力。与固有的静态提示令牌相比,本文提出了动态提示令牌,这些令牌可以自适应地捕捉实例特定风格中的与活体无关的信号,并通过混合特征统计来增加多样性,进一步减少模型的过拟合。实验在多个跨域协议中验证了该方法的先进性。
2.方法概述
本文提出了S-CPTL框架(如图1所示)来解决人脸活体检测任务。S-CPTL基于CLIP模型,包含一个固定的图像编码器和一个具有K个transformer层的文本编码器。它通过引入可学习的提示令牌和风格条件模块(SCM),来适应人脸活体检测任务,从而减弱特征对实例特定风格的敏感性。在文本分支中,前J层transformer层引入了可学习的提示令牌。当J=1时,可学习令牌与固定模板嵌入一起作为第一个transformer层的输入。之后,新的可学习令牌依次被引入到文本编码器的后续transformer层中,直到第J层。为了自适应地捕获来自实例特定风格的与活体无关的信号,本文提出了风格条件模块(SCM)。SCM通过动态地将特征统计与文本表示相结合,进一步减少了模型的过拟合风险。SCM由旁路卷积适配器和混合风格增强模块(HSAM)组成。在视觉分支中,旁路卷积适配器与多头自注意力和MLP模块并行放置。
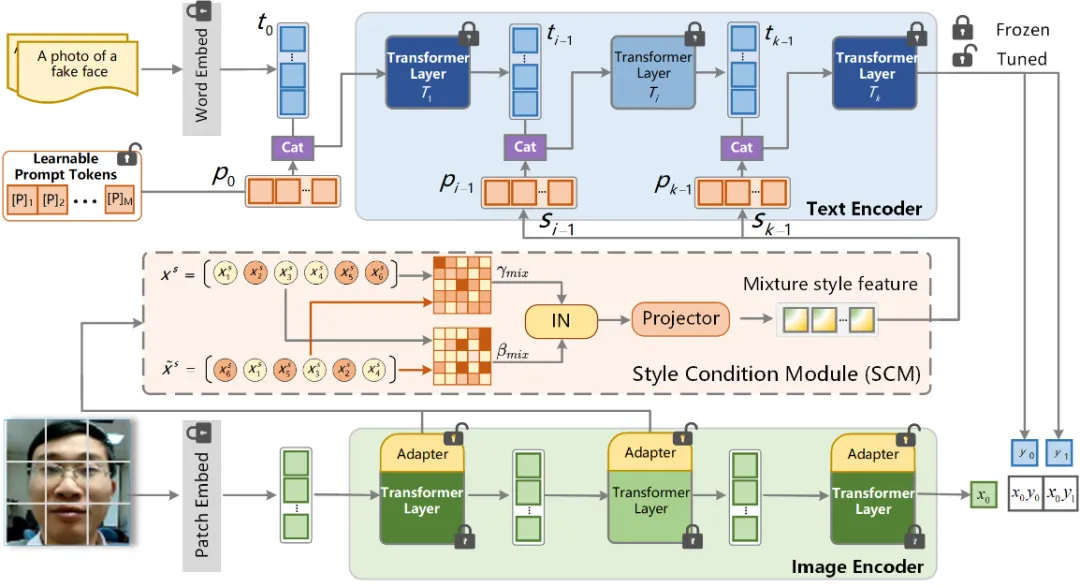
图1 所提出的S-CPTL框架
05
2M-AF: A Strong Multi-Modality Framework For Human Action Quality Assessment with Self-supervised Representation Learning
作者:
丁宇宁1,张思凡1,刘胜蓝1,张津榕1,陈文玥1,段海飞1,董炳成1,孙焘1
单位:
大连理工大学1
邮箱:
rookie233@mail.dlut.edu.cn,
201981131@mail.dlut.edu.cn,
liusl@dlut.edu.cn,
zhangjinrong731@gmail.com,
20121212@mail.dlut.edu.cn,
201882035@mail.dlut.edu.cn,
18352203288@mail.dlut.edu.cn,
dlutst@dlut.edu.cn
论文:
https://openreview.net/pdf?id=oEhi4pd0e1
发表会议:ACM MM 2024
1.论文简介
动作质量评估(AQA)因应用价值受到关注,但其面临动作同背景高完成度差异的挑战,导致传统网络判别力不足。RGB模态虽含丰富环境信息,却因空间表征有限和对细微变化敏感,难以有效捕捉关键动作特征。为此,本文引入骨架模态弥补RGB缺陷。骨架数据具有高效空间表征和低计算成本优势,但缺乏环境感知能力。针对此,我们提出自监督掩码编码图卷积网络(SME-GCN),通过动态/时间双重掩码策略强化运动特征学习,结合对比学习生成高质量序列。实验表明,该方法通过简单回归结构即显著提升骨架模型性能,为构建多模态轻量AQA框架奠定基础。
2. 方法概述
针对多模态方法的特征回归,传统思路是通过单/多层信息共享实现特征融合。这类方法往往在多模态计算中引入额外开销。在AQA任务中,由于多数动作至少存在一种优势模态,我们探索新的融合思路:训练样本自动选择更适合的模态结果。为此设计偏好融合模块(Preference Fusion Module, PFM),通过样本级选择机制实现模态优选。结合SME-GCN、PFM及基础RGB流(I3D),构建双模态评估框架(Two-Modality Assessment Framework, 2M-AF)。值得注意的是,模块化设计的2M-AF支持配置多组骨干网络和回归损失,展现出良好的可扩展性。
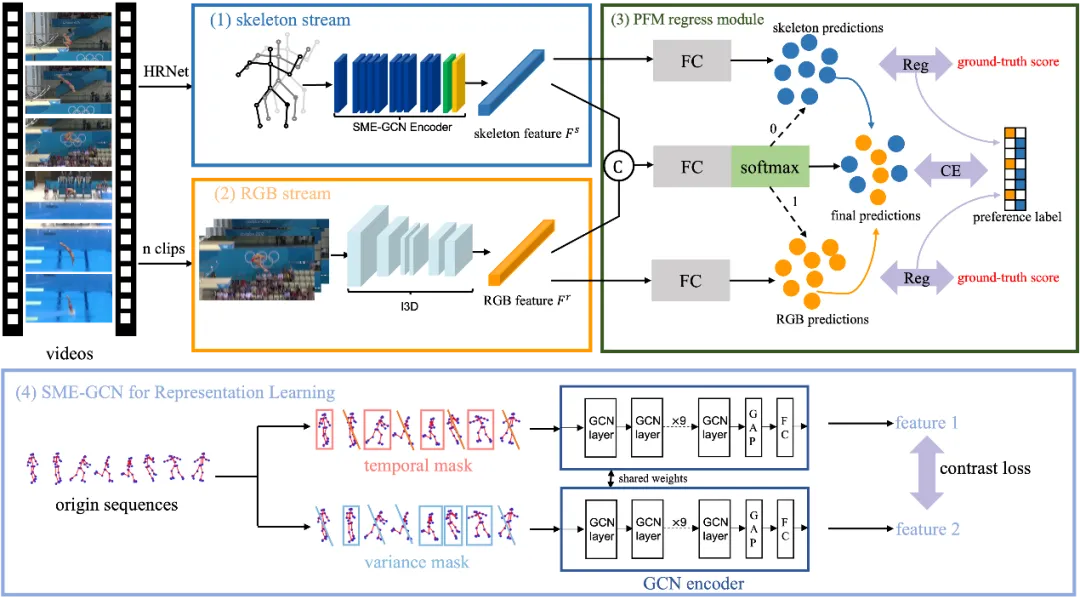
图1 2M-AF整体架构示意图。(1)骨架流:采用HRNet进行骨架数据估计;(2)RGB流;(3)PFM回归模块示意图。其中C表示特征拼接操作,圆点代表样本预测值,Reg表示回归损失函数(本工作采用MSE+MAE组合)。中央分类器通过优化使预测值逼近真实分数,推理时直接根据分类结果从双流输出中选取最终预测。(4)SME-GCN表征学习结构:斜线网格表示被掩码帧序列,GCN编码器中GAP代表全局平均池化操作。
3.实验对比
我们在上述三个数据集上与当前最优AQA方法进行对比实验。如表1所示,在AQA-7数据集六个单项类别中,我们的方法在五项取得优势,即使在未取得最优的"跳水"单项中仍与最佳结果差距微小。表1、2、3的综合数据显示,2M-AF框架在三个数据集上均以显著优势刷新最优性能。这些结果充分验证了2M-AF框架对数据类型、规模及视频时长具有优异的鲁棒性。
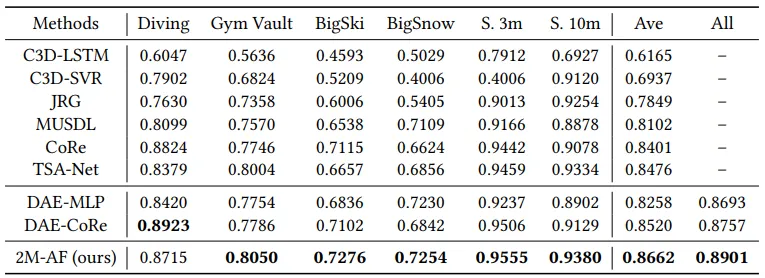
表1 在AQA-7数据集上与现有方法的精度对比结果,其中"Ave"表示基于Fisher’s z值计算的综合性能指标,"All"代表与AQA-7全部六个动作类别的整体对比结果。
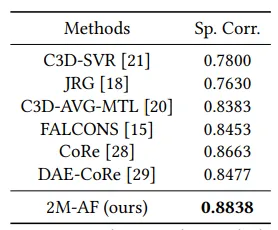
表2 在UNLV潜水数据集上与现有方法的准确性比较。
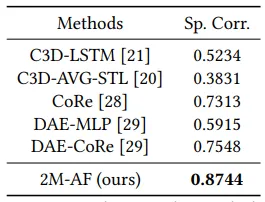
表3 与MMFS-63数据集上现有方法的准确性比较。
为直观呈现骨架单流、RGB单流与2M-AF的预测差异,我们在图2中通过散点图可视化预测结果。从图中可观察到AQA-7预测呈现以下特点:(1)骨架流存在较多离群点(如黑圈标注点),表明该模型虽在多数样本表现良好,但在部分样本(可能因骨架数据质量不佳)出现明显偏差;(2)RGB流红圈区域样本普遍偏离理想预测线,显示其对密集样本的回归能力受限;(3)2M-AF有效解决上述问题,印证PFM模块能从双流中优选更准确预测结果的有效性。
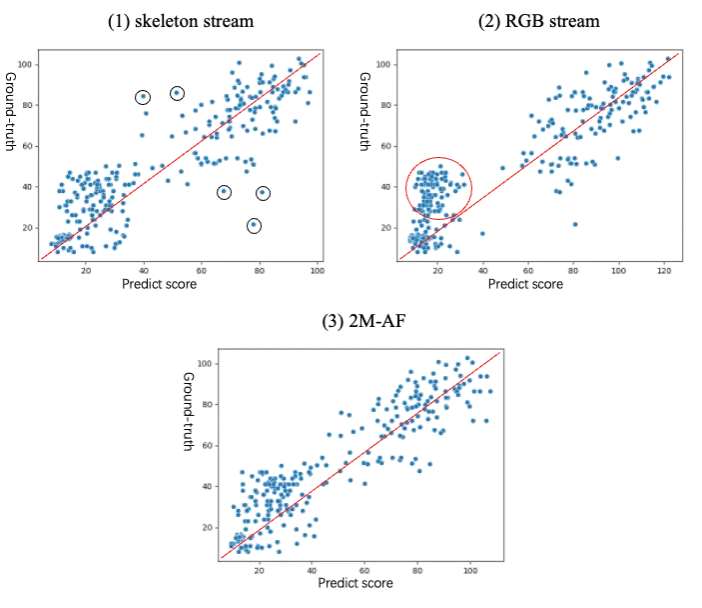
图2 不同方法在散点图中的对比结果示意图。图中每个散点代表AQA-7测试数据集中的样本,红色基准线表示理想预测值。

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号