
【论文导读】2025年论文导读第五期
【论文导读】2025年论文导读第五期
2025年03月25日 19:06 天津


论文导读
2025年论文导读第五期(总第一百二十二期)
目 录
|
1 |
Maskable Retentive Network for Video Moment Retrieval |
|
2 |
Blind Face Video Restoration with Temporal Consistent Generative Prior and Degradation-Aware Prompt |
|
3 |
VrdONE: One-stage Video Visual Relation Detection |
|
4 |
One-Stage Fair Multi-View Spectral Clustering |
|
5 |
Wave-Mamba: Wavelet State Space Model for Ultra-High-Definition Low-Light Image Enhancement |
01
Maskable Retentive Network for Video Moment Retrieval
作者:
胡晶晶1,郭丹12,李坤3,司展4,杨勋5,汪萌12
单位:
合肥工业大学1,
合肥综合性国家科学中心人工智能研究所2,
浙江大学3,
安徽大学4,
中国科技大学教育部脑启发智能感知与认知教育部重点实验室5
邮箱:
xianhjj623@gmail.com,
guodan@hfut.edu.cn,
kunli.hfut@gmail.com,
naa0528@stu.ahu.edu.cn,
xyang21@ustc.edu.cn,
eric.mengwang@gmail.com
论文:
https://openreview.net/pdf?id=pIHHAUa500
代码:
https://github.com/xian-sh/MRNet
发表会议:ACM MM2024
1.引言
视频时刻检索(Video Moment Retrieval, VMR)的核心任务是从未剪辑视频中精准定位与查询语义一致的时间片段。如图1所示,这一任务面临两个关键挑战:(1)视觉上下文关联建模中存在时序复杂性与冗余干扰。视频片段之间存在双向的、非线性且逐渐衰减的时间关联,这种复杂的时序关系对于目标事件的理解至关重要,但现有方法往往难以充分捕捉。此外,长视频中充斥着大量冗余背景信息,这些信息会干扰目标事件的识别,进一步导致与查询相关的关键信息稀疏难提取。
(2)在文本/语音和视频的交互中,跨模态语义引导不足。作为一种典型的跨模态任务,视频时刻检索需要语言或语音查询对视频进行精准引导。然而,现有方法通常在注意力机制中对不同模态一视同仁,未能针对模态特性设计专门的引导策略,导致语言指导能力未能最大化,进而影响检索精度。
针对上述挑战,本文设计了一种全新的可学习掩码方法:对于挑战一,提出通过引入保留机制显式建模视频片段间的时序关联,同时,采用可学习的掩码机制,去除视频模态中的冗余背景干扰;对于挑战二,跨模态交互中设计了模态特定的注意力优化策略,充分发挥语言或语音查询的引导能力,提升视频语义理解与目标定位的精度。
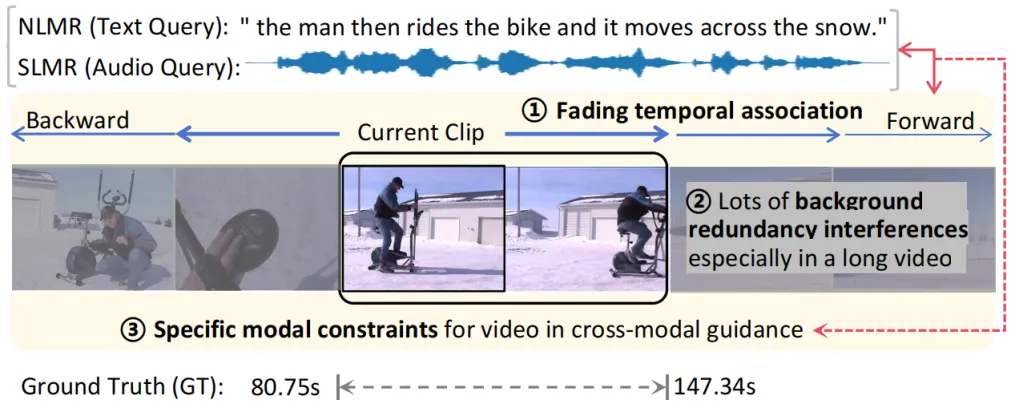
图1 视频时刻检索的关键挑战与解决方案示意图
2.方法概述
如图2所示,本文提出了一种新颖的可掩模保留网络(Maskable Retentive Network, MRNet),包含以下技术特点:
(1)结合Transformer框架的高效保留机制。在Transformer框架中引入Retention机制,既保留了Transformer的并行训练高效性,又实现了类似递归神经网络的时间序列推理能力,强化对视频上下文的深度理解。
(2)模态特定的注意力设计,提升跨模态引导能力。在跨模态交互中,针对视频模态引入了可掩模保留机制(Maskable Retention),优化视频序列建模:
双向保留Mask机制:显式建模视频片段间的双向、非线性、逐渐衰减的时间依赖性,增强模型对视频时间上下文的理解。
可学习的稀疏Mask:自适应捕捉与查询语义强相关的关键视频片段,同时抑制冗余背景信息干扰,优化视频模态的语义表达。
自监督稀疏约束损失:设计了自监督稀疏约束损失,通过强制稀疏化注意力响应,进一步去除视频中的冗余信息,突出与目标事件相关的关键特征。
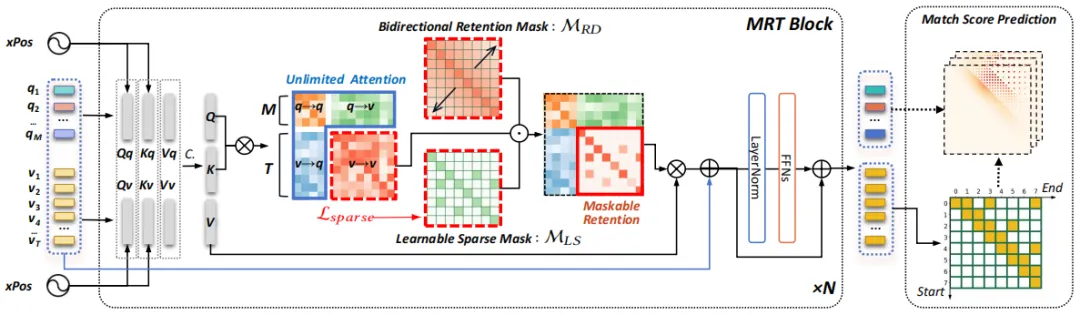
图2 我们提出的可掩蔽保留网络(MRNet)体系结构的概述
(3)广泛适用的任务支持:MRNet框架不仅适用于自然语言时刻检索(Natural Language Moment Retrieval)和语音时刻检索(Spoken Language Moment Retrieval),还支持联合任务如时刻检索和高光检测的多任务学习。
3.实验结果
我们在五个主流视频时刻检索相关数据集(ActivityNet Captions、TACoS、Charades-STA、ActivityNet Speech和QVHighlights)上进行实验验证。如表3所示,实验结果表明MRNet在不同任务场景中均取得了显著的性能提升和良好的应用适应性。
(1)自然语言时刻检索(NLMR)。在开放领域ActivityNet Captions数据集中,MRNet在单查询模式下的R@1,IoU@0.5指标较现有最佳方法提升了2.51%,而在多查询模式下提升了12.86%。在长视频的复杂场景TACoS中,MRNet展现了卓越的时间关联建模能力,R@1,IoU@0.5指标较现有最佳方法提升了3.66%,证明了其对非线性、长时序依赖关系的建模能力。在短视频Charades-STA场景中,MRNet在R@1,IoU@0.5指标上达到了60.30,成功捕捉了细粒度的动作特征和语义信息,表现出对短视频片段精准定位的优越性。
(2)语音时刻检索(SLMR)与联合任务(MR+HD)。在语音查询检索任务ActivityNet Speech数据集上,MRNet在mIoU指标上比现有方法提升了13.5%,验证了其在跨模态语义对齐方面的强适应性和鲁棒性。在时刻检索与逐帧高亮检测的多任务场景QVHighlights数据集中,MRNet表现出了与现有最佳方法相当的性能,同时在任务间切换的泛化能力上展现了优势,证明了其在多任务学习中的广泛适用性。
(3)Mask模块消融实验。实验表明,双向保留Mask增强了时间上下文建模能力,可学习稀疏Mask去除了冗余背景信息,提升了关键信息捕捉能力,并通过稀疏性约束优化注意力分布、抑制冗余响应(表4)。模态特定注意力机制有效对齐语言与视频语义,提升跨模态交互效果,仅对视频模态引入Mask能减少冗余并突出关键信息(表6)。超参数分析显示,稀疏性约束权重和稀疏比例设置合理时模型性能最优且具鲁棒性(图7)。
(4)单查询与多查询训练模式分析与模型效率。如图5所示,本文提出的多查询训练模式能进一步利用语言查询的语义指导能力,在所有数据集上性能均显著提升,例如在ActivityNet Captions数据集中,R@1, IoU@0.5提升了10.79%,展现了MRNet在复杂跨模态任务中的优势。此外,MRNet在参数规模适中的情况下推理速度比现有方法快1.65倍,实现了性能与效率的平衡。图8~10展示了本文方法在不同任务场景中的可视化实例。
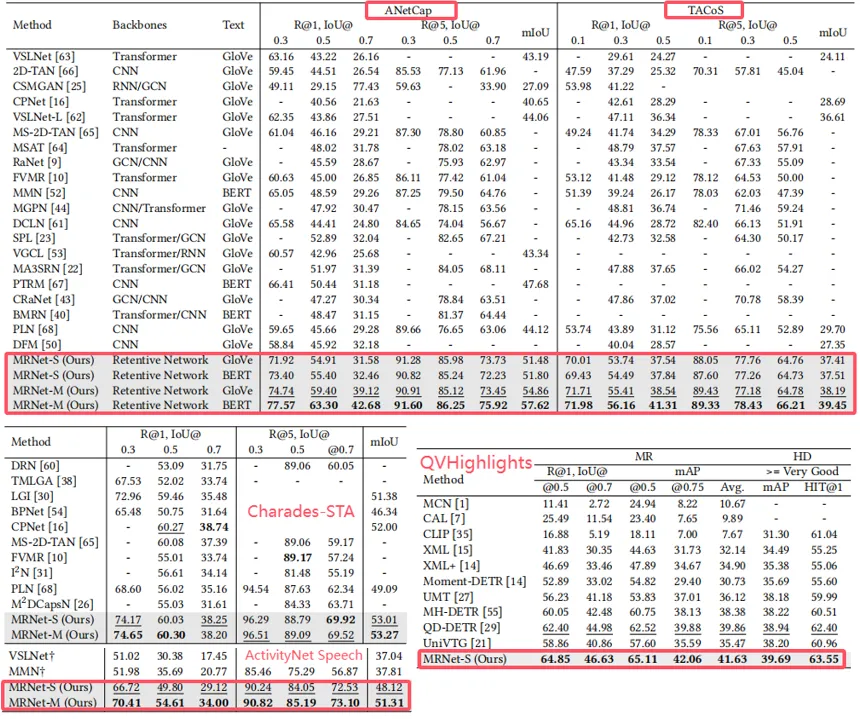
表3 模型在5个主流的视频时刻检索数据集上的表现

表4 主要提出的模块的消融实验:双向保留Mask机制MRD,可学习的稀疏Mask机制MLS,以及稀疏性约束损失Lsparse

图5 单查询与多查询训练设置方法比较分析结果

表6 跨模态引导模式分析(左)。跨模态的Masking区域分析(右)
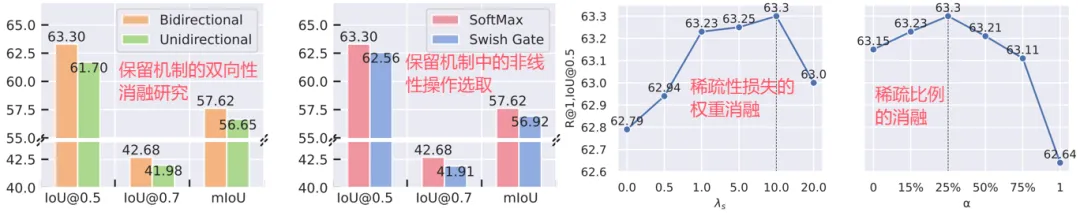
图7 模型细节与超参数消融分析
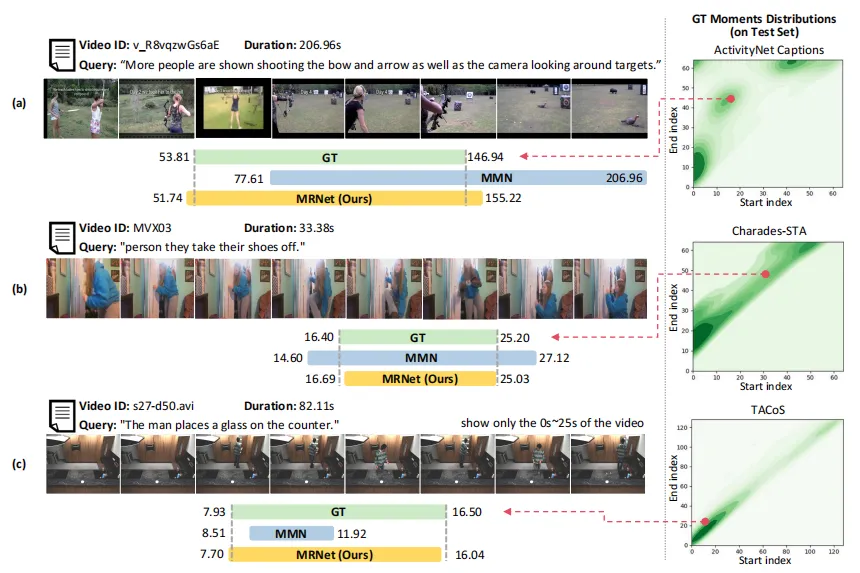
图8 在三个自然语言时刻检索任务(NLMR)数据集上的案例展示

图9 在语音时刻检索任务(SLMR)任务数据集上的案例展示
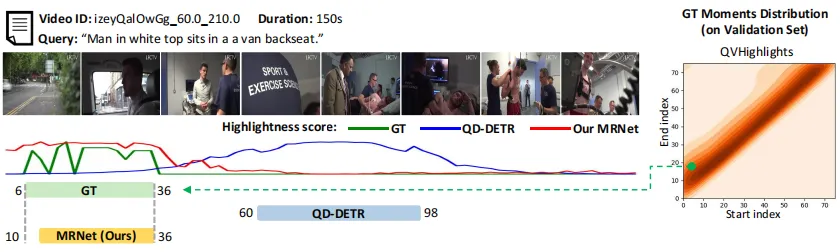
图10 在多任务场景(MR+HD)数据集上的案例展示
02
Blind Face Video Restoration with Temporal Consistent Generative Prior and Degradation-Aware Prompt
使用时间一致的生成先验和退化感知提示进行人脸视频盲修复
作者:
谭靖凡1,Hyunhee Park2,张颖3,王涛4,张凯皓5,孔祥宇3,代朋纹1,刘子坤3,罗文寒6*
单位:
中山大学(深圳)1,
三星电子2,
三星电子中国研究院(北京)3,
南京大学4,
哈尔滨工业大学(深圳)5,
香港科技大学6
邮箱:
tjfky2001@gmail.com, inextg.park@samsung.com,
ying09.zhang@samsung.com,
taowangzj@gmail.com,
super.khzhang@gmail.com,
xiangyu.kong@samsung.com,
daipw@mail.sysu.edu.cn,
zikun.liu@samsung.com,
whluo.china@gmail.com
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3680917
发表会议:ACM MM 2024
*通讯作者
1.研究背景
在真实场景中,人脸图像和视频常因模糊、噪声、压缩等复杂退化问题导致质量下降。人脸盲修复旨在无需预知退化类型的情况下恢复高质量人脸内容,是计算机视觉领域的重要挑战。现有方法多基于生成式先验(如StyleGAN、Stable Diffusion)提升细节真实性,但这些方法主要针对单张图像设计,直接应用于视频时会导致时间不一致性(如面部属性突变、背景与面部细节清晰度不协调)。而传统视频修复方法虽能保持时间一致性,却因缺乏人脸先验知识导致结果过于平滑、细节丢失。如何结合生成式先验的优势与视频时序建模能力,成为盲人脸视频修复的关键问题。
2.方法概述
方法如图1,2所示,在时序层的设计上我们在扩散模型中分别插入了长短期信息聚合模块。在U-Net中堆叠的多个Shift-ResBlock模块,通过前向与后向时序位移交替操作,隐式捕获全局时序信息,实现双向长距离时间特征融合。同时提出邻近帧注意力(NFA):利用相邻帧的互补细节优化当前帧,增强短距离时间特征缓解闪烁伪影。针对混合退化场景,提出退化感知提示模块通过提取输入帧的退化特征,动态预测不同退化类型(模糊、噪声等)的权重,生成自适应提示向量,指导扩散模型灵活应对复杂退化。
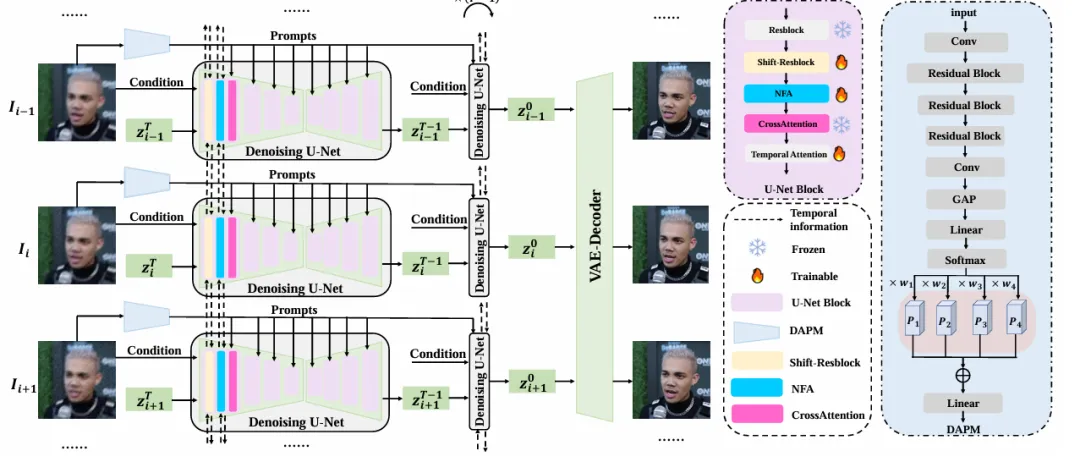
图1 整体框架图
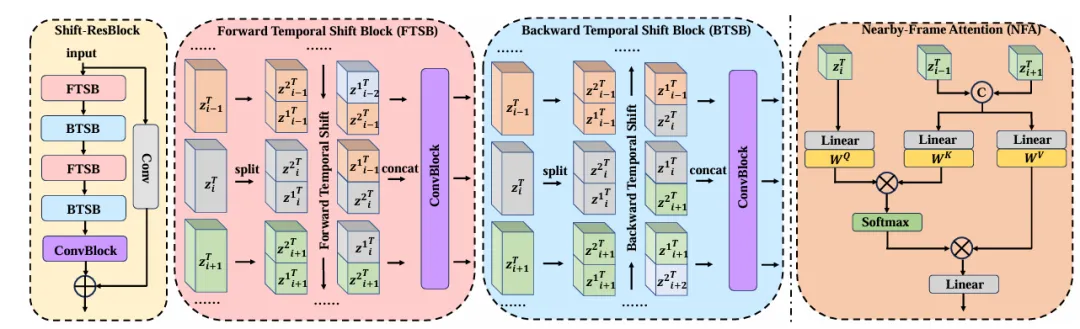
图2 Shift-Resblock模块与邻近帧注意力(NFA)模块
3. 实验结果
如下表1所示,我们的方法在合成数据集VFHQ-Test上的感知类指标LPIPS、NIQE、MUSIQ与CLIP-IQA上均达到 SOTA,证明恢复结果更接近真实数据,符合人类的感知。同样在真实数据集WebVideo-Test上NIQE、MUSIQ 与 CLIP-IQA 指标全面领先,验证了模型对未知退化场景的强适应性。表明在真实复杂退化条件下,采用生成式先验相比传统视频修复方法更具优势。
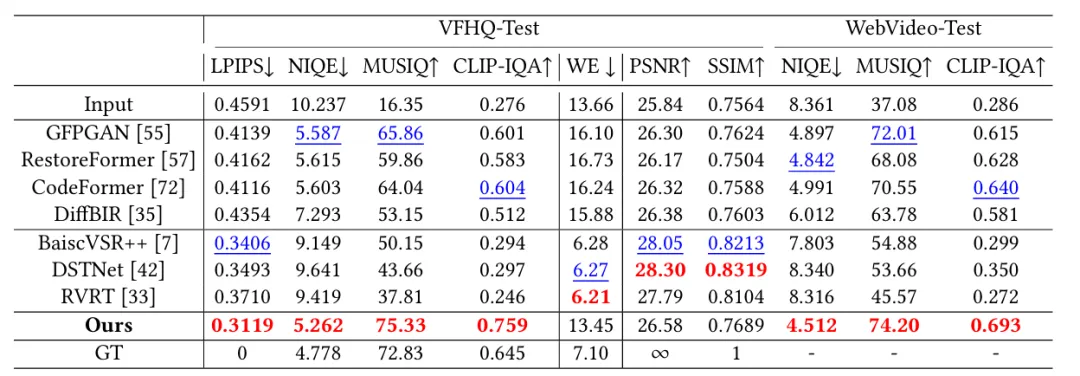
表1 在VFHQ-Test和WebVideo-Test数据集的性能比较
定性实验结果如下图3所示,在细节恢复能力上,凭借生成式面部先验,我们的方法恢复了眼睛、嘴唇、胡须等高频细节,而传统视频修复方法结果过平滑,丢失面部纹理。在区域一致性上,人脸图像盲修复方法仅修复人脸区域,背景依赖RealESRGAN处理,导致人脸与背景视觉不一致,我们的方法整体修复输入视频帧,面部与背景过渡自然。此外通过聚合多帧信息,在人脸图像盲修复方法失效场景仍能生成高质量细节。如图4所示人脸图像盲修复方法生成单帧纹理真实,但连续帧间纹理差异显著,传统视频修复方法时序一致性优秀,但结果过平滑,丢失高频细节,我们的方法在增强细节的同时,保持帧间过渡自然,实现了感知效果与时间一致性的均衡。

图3 不同模型修复结果的视觉比较

图4 不同模型修复结果的时间一致性比较(a)GFP-GAN,(b)CodeFormer,(c)DiffBIR,(d)RestoreFormer,(e)BaiscVSR++,(f)RVRT,(g)DSTNet,(h)Ours
03
VrdONE: One-stage Video Visual Relation Detection
作者:
蒋昕杰1,*,郑辰熙1,*,徐雪妙1, †,刘邦镇1, †,郑炜颖1,张怀东1,何盛烽2
单位:
1华南理工大学,2新加坡管理大学
邮箱:
jiangxinjie512@gmail.com,
chansey0529@gmail.com,
xuemx@scut.edu.cn,
liubz.scut@gmail.com,
arisezheng21@gmail.com,
huaidongz@scut.edu.cn,
shengfenghe@smu.edu.sg
论文:
https://dl.acm.org/doi/10.1145/3664647.3680833
代码:
https://github.com/lucaspk512/vrdone
发表会议:ACM MM 2024
*共同一作,†通讯作者
1.背景与动机
视频视觉关系检测(Video Visual Relation Detection, VidVRD)任务旨在精确感知并理解视频中实体间的时空交互,如主语对宾语的动作、主语与宾语间的位置关系等,从而推动视频字幕生成、视频问答等视频理解任务的发展。视频关系检测的核心是学习实体间关系的类别和时间定位。然而,现有方法普遍将这两者视为独立的任务,使用两阶段范式先进行局部的关系分类,再通过时间维度上的组合,形成关系的完整时间区间。这样的做法存在以下几个问题:(1)忽略了关系分类和时间定位之间的内生联系,导致分类和定位结果只能达到次优水平;(2)过度依赖局部特征,导致在关系边界处的定位模糊,引发错误的拆分与合并;(3)没有充分考虑实体间时空交互的多样性,未能有效捕捉关系的动态变化,导致模型在特征提取和对关系的理解能力方面不足。
针对两阶段方法的缺陷,本文提出了一阶段的关系检测网络——VrdONE。该方法通过时空协同学习,同时捕获整个视频中实体间的关系,突破了传统方法的局限。通过时间维度上的分割框架,VrdONE实现了关系分类与定位的联合学习,从而提高了模型对实体间关系动态变化的理解和对关系进行精确的时间定位的能力。
2.方法概述
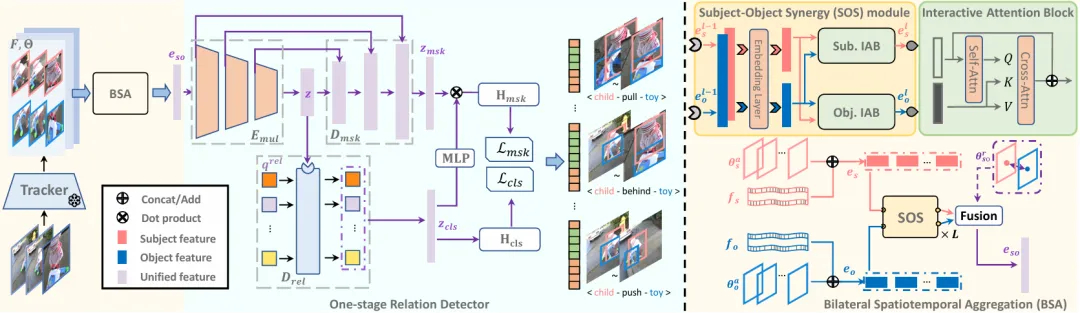
图1 模型框架图
该方法的框架如图1所示。视频帧首先通过预训练的视频目标追踪模型提取实体的空间定位和特征序列。对于每对主语-宾语,双向时空聚合(BSA)模块充分进行特征间的时空交互,并最终融合为统一的关系特征嵌入。其中,主语-宾语协同(SOS)模块通过自注意力机制提取实体自身的时空特征,再通过交叉注意力机制融合对方特征,增强关系提示。在特征融合阶段,将主语和宾语的特征统一生成融合表示。为更好地捕捉实体间的时空关系,BSA在SOS之前注入实体各自的绝对位置变化,在融合阶段则加入相对位置特征,最终生成表示关系的统一时空特征嵌入。
统一的特征嵌入输入到一阶段基于查询的(Query-based)关系检测器后,最终得到关系检测结果。关系检测器包括关系编码器、关系解码器和时间掩膜解码器。长视频中的冗余性可能导致特征的可鉴别性较差,进而影响检测效果和模型收敛速度。为此,BSA和关系编码器均使用局部注意力机制减少冗余,在高层特征中仅保留低层具有较强鉴别性的帧特征,从而有效关注到不同时间尺度的关系。关系解码器通过查询学习所有可能的关系实例,提取高维语义信息;时间掩膜解码器对特征图进行上采样,生成时间维度上细粒度的二进制掩膜,标定关系的时间位置,从而完成一阶段的关系分类和时间定位。
3.实验结果
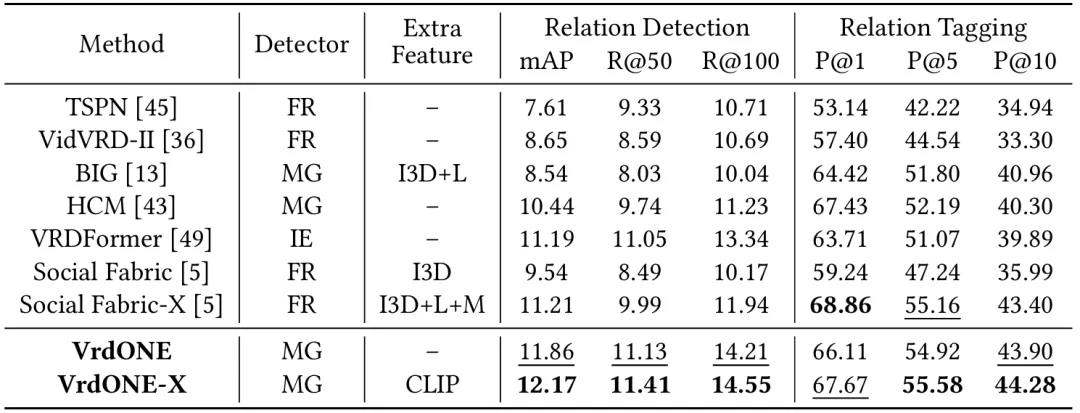
本文在VidOR和ImageNet-VidVRD数据集上进行实验,并将VrdONE与此前的先进方法进行比较,以评估其有效性。在VidOR数据集上,我们的方法在RelDet任务上实现了显著的性能提升(+0.65%的mAP,+0.87%的R@100)。由于此前的方法多使用额外的特征来增强模型能力,我们融合了CLIP提取的视觉特征,实现了一个增强版本VrdONE-X。VrdONE-X在RelDet的mAP、R@50和R@100上分别提升了+0.96%、+0.36%和+1.21%,证明了我们方法的可扩展性和有效性。而受限于两阶段方法的缺陷,此前的先进方法在VidOR这样的长视频数据集上表现不佳。
表1 在VidOR数据集上的实验结果
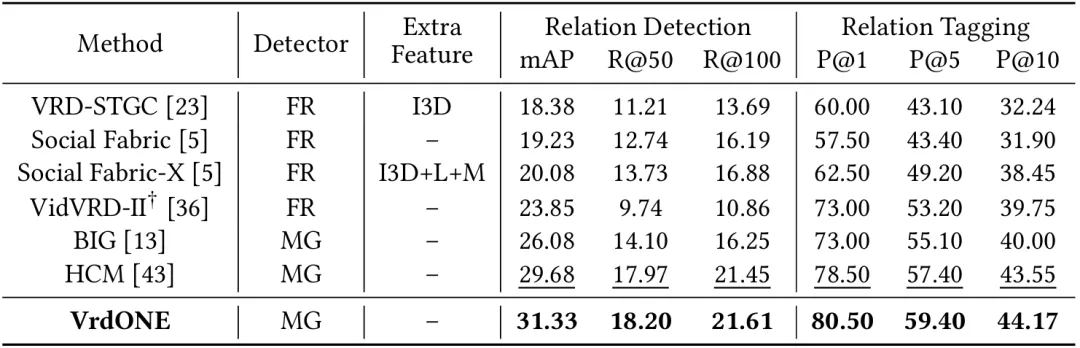
在ImageNet-VidVRD数据集上,VrdONE超越了之前的先进方法,在所有RelDet和RelTag指标上分别提高了+1.65%的mAP、+0.23%的R@50、+0.16%的R@100、+2.00%的P@1、+2.00%的P@5和+0.62%的P@10。结合两个数据集的实验结果,我们的方法在视频关系检测上展现了卓越且稳健的性能,从而验证了时空协同学习和一阶段方法的有效性。
表2 在ImageNet-VidVRD数据集上的实验结果
可视化实验结果如图2所示。

图2 和此前先进方法的可视化比较(左:VidOR数据集;右:ImageNet-VidVRD数据集。√:检测正确;×:检测错误;○:未检测出。)
04
One-Stage Fair Multi-View Spectral Clustering
作者:
李荣文1,胡海洋1,杜亮2,陈家容1,江兵兵3,周芃1
单位:
安徽大学1,山西大学2,杭州师范大学3
邮箱:
e22301284@stu.ahu.edu.cn,
e23301204@stu.ahu.edu.cn,
duliang@sxu.edu.cn,
e23301236@stu.ahu.edu.cn,
jiangbb@hznu.edu.cn,
zhoupeng@ahu.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681162
代码:
https://github.com/rongwenli/MM24-FMSC
发表会议:
ACM MM 2024
1.论文简介
多视图聚类是多媒体和机器学习中的一项重要任务。在多视图聚类中,多视图谱聚类是一类最受欢迎且最有效的方法。然而,现有的多视图谱聚类忽略了聚类结果中的公平性,这可能导致歧视性问题。为了解决这一问题,本文提出了一种创新的公平多视图谱聚类(Fair Multi-view Spectral Clustering,FMSC)方法。首先,我们从图论的视角提出了一种新的公平性观点,将公平性与图论中的平均度数建立了联系。其次,基于这种联系,我们设计了一种新颖的公平性正则化项,该正则化项的形式与谱聚类中的比率割(Ratio Cut)相同。第三,我们将这种公平性正则化项无缝融入多视图谱聚类中,形成了一种单阶段的FMSC方法,该方法能够在无需任何后处理的情况下直接获得最终的聚类结果。我们还进行了大量实验,将我们的方法与当前最先进的公平聚类和多视图聚类方法进行比较,结果表明我们的方法在公平性方面表现更优。
2.方法概述
本文从图论的角度重新审视公平性,建立了公平性与保护属性图中平均度的关系。考虑 10 个人,其中 5 个人属于一个保护群体(例如男性),另外 5 个人属于另一个保护群体(例如女性),其保护群体图如图 1(a) 所示,其中圆圈表示男性,方块表示女性。图1(b)和图1(c)分别表示一种公平以及不公平的划分,公平的划分往往具有更小的平均度数和,因此我们可以假设公平性可能与保护属性图中平均度有关。并且通过理论证明,最小化平均度和确实符合经典公平性定义的结果。基于这一理论,本文设计了一个新的公平性正则项,形式与谱聚类中的Ratio Cut相同。该正则项可以无缝集成到多视图谱聚类中,形成一个统一的框架。目标函数如图2所示。
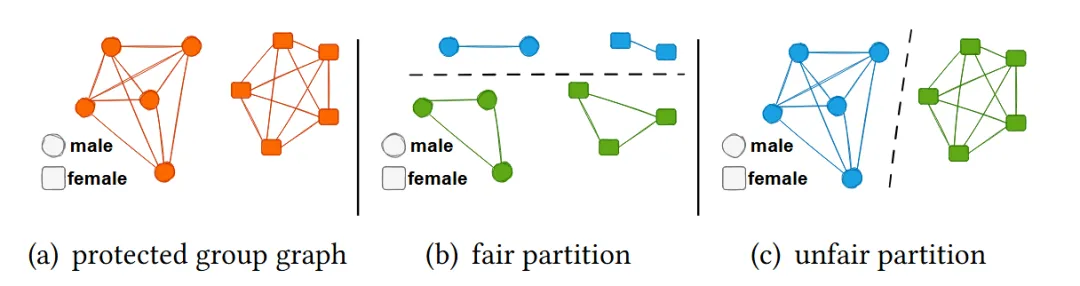
图1 保护属性图以及在保护属性图上的公平/不公平的划分
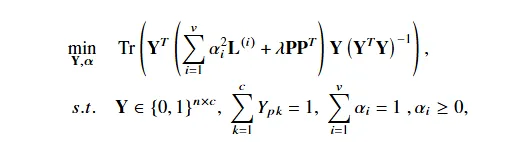
图2 目标函数
3.实验结果
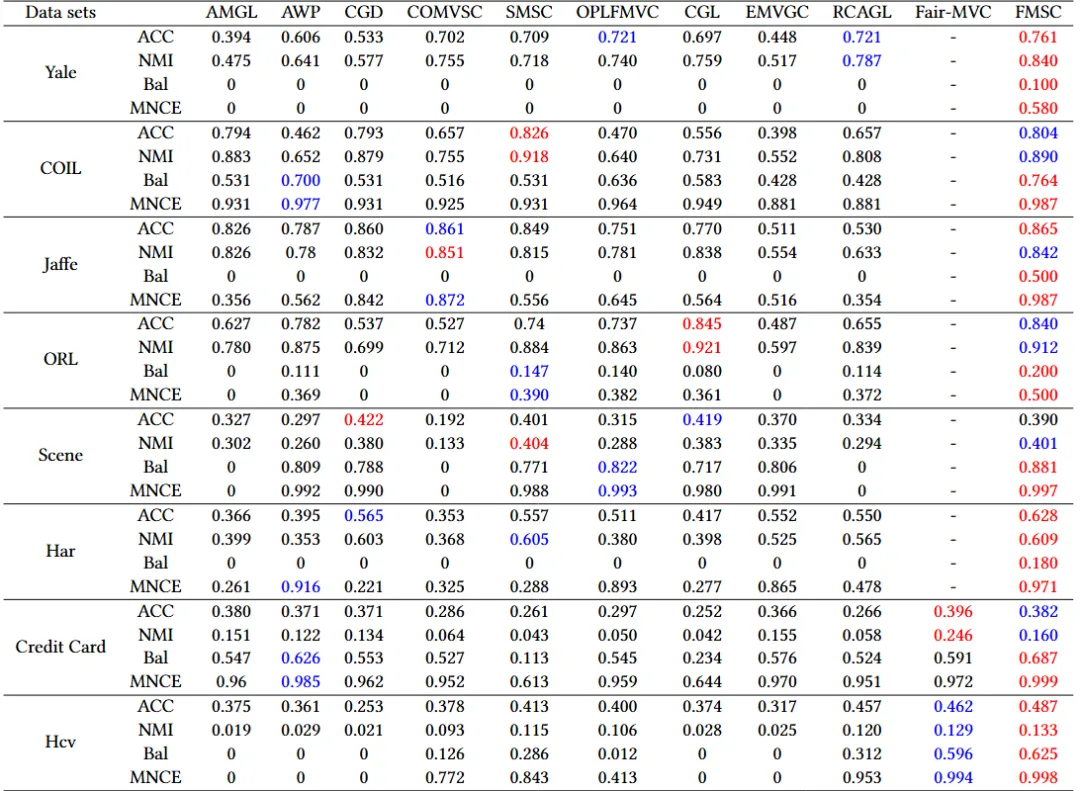
表1显示了多视图聚类方法的结果。结果表明,本文的方法在所有数据集上的公平性指标(即 Bal 和 MNCE)方面均优于其他多视图聚类方法。即使与深度公平多视图聚类方法 Fair-MVC 相比,本文的方法仍然实现了更公平的结果。这充分显示了本文所提出的公平性正则项的优势,证明了在公平性方面的动机。此外,本文的方法在聚类性能指标(即 ACC 和 NMI)方面在大多数数据集上仍然具有可比性,甚至优于其他方法。这个结果充分证明了本文提出的公平性正则项的有效性。
表1 多视图聚类结果
05
Wave-Mamba: Wavelet State Space Model for Ultra-High-Definition Low-Light Image Enhancement
作者:
邹文斌1,2,高红霞1,2,*,杨伟朋1,刘潼潼1
单位:
1华南理工大学,
2琶洲实验室
邮箱:
alexzou14@foxmail.com,
hxgao@scut.edu.cn,
wpyscut@foxmail.com,
202310183310@mail.scut.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3681580
代码:
https://github.com/AlexZou14/Wave-Mamba
发表会议:ACM MM 2024
*通信作者
1.研究背景和动机
超高清(UHD)技术因其卓越的视觉质量在视频监控、医学成像等领域日益普及,但低光照环境下UHD图像增强(LLIE)面临挑战。UHD图像的高分辨率导致计算复杂性增加,传统方法常通过大幅降采样降低成本,却牺牲了图像细节。近年来,基于深度学习的LLIE方法(如Transformer)在全局信息捕捉上表现优异,但计算需求高,难以在普通设备上实现全分辨率推理。状态空间模型(SSMs)以线性复杂度和长序列建模能力受到关注,Mamba模型在视觉任务中尤为突出,然而其对噪声的敏感性限制了在低光场景的应用。小波变换(Wavelet Transform)能无损分解图像并分离噪声,为此提供了解决方案。其中主要根据了以下低光照图像在小波域的两个观察提出Wave-Mamba:1)在小波域中,大部分图像信息存在于低频分量中,只有少量纹理信息存在于高频分量中。2)高频分量对低光增强的结果影响最小。
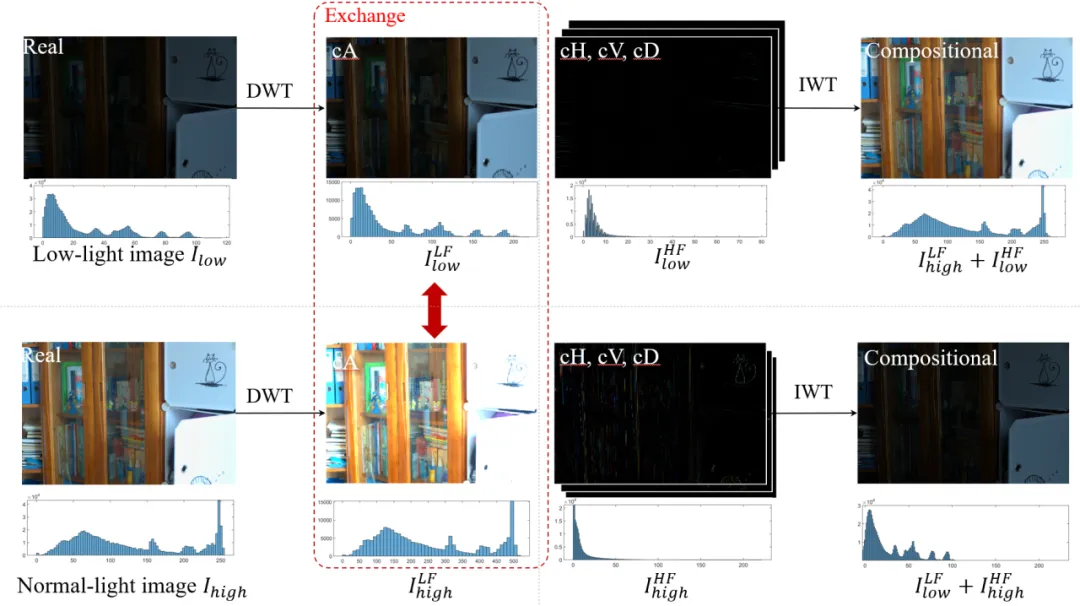
图1 小波域中对低光照图像观察
2. 方法概述
针对传统降采样导致的信息丢失问题,我们采用二维离散小波变换(DWT)将输入图像分解为低频(cA)和高频(cH、cV、cD)子带,避免了传统方法的信息损失,并通过逆小波变换(IWT)实现无损重建。同时,小波变换分离了图像内容与噪声,使SSMs的长序列建模能力得以充分发挥。根据上面的观察,Wave-Mamba结合了小波变换和Mamba状态空间模型的核心优势并设计了两个关键模块:低频状态空间模块(LFSSBlock)和高频增强模块(HFEBlock)。低频状态空间模块改进Mamba模型,专注于低频子带的全局建模与恢复,利用SSMs的线性复杂度高效处理UHD图像的照明和纹理信息。高频增强模块则利用增强后的低频信息,通过频率匹配变换(FMT)校正高频子带,确保细节准确性。网络通过多层低频状态空间模块和高频增强模块逐步提取和增强特征,最终输出高质量增强图像。更多有关方法的细节请参考论文。
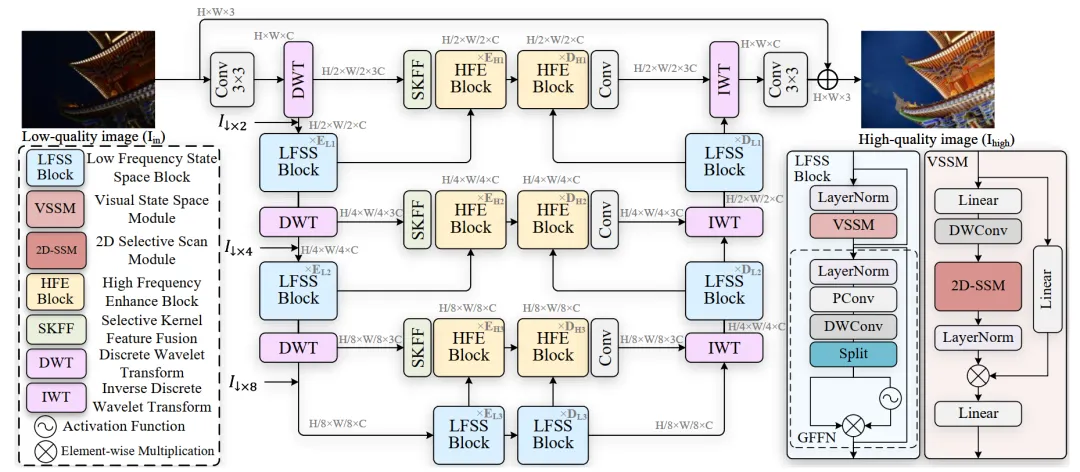
图2. Wave-Mamba:用于超高清低光图像增强的小波状态空间模型结构示意图
3.实验结果
Wave-Mamba在UHD-LL和UHD-LOL4K数据集上的实验表明,其在保持较低计算成本的同时,显著优于现有领先方法,展示了其在UHD LLIE任务中的高效性和优越性。
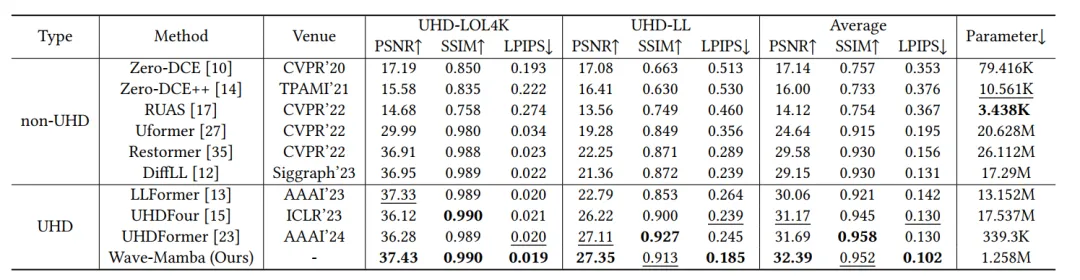
表1 Wave-Mamba在UHD-LL和UHD-LOL4K数据集上的性能比较

图3 Wave-Mamba与其他方法的视觉比较图

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号