
【论文导读】2025年论文导读第六期
【论文导读】2025年论文导读第六期
2025年04月08日 13:15 北京


论文导读
2025年论文导读第六期(总第一百二十三期)
目 录
|
1 |
Few-Shot Multimodal Explanation for Visual Question Answering |
|
2 |
HiVG: Hierarchical Multimodal Fine-grained Modulation for Visual Grounding |
|
3 |
Autogenic Language Embedding for Coherent Point Tracking |
|
4 |
FiLo: Zero-Shot Anomaly Detection by Fine-Grained Description and High-Quality Localization |
|
5 |
Dual Advancement of Representation Learning and Clustering for Sparse and Noisy Images |
01
Few-Shot Multimodal Explanation for Visual Question Answering
面向视觉问答的少样本多模态解释
作者:
薛迪展,钱胜胜,徐常胜
单位:
中国科学院自动化研究所
邮箱:
xuedizhan17@mails.ucas.ac.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3681597
代码:
https://github.com/LivXue/FS-MEVQA
作者主页:
https://scholar.google.com/citations?user=V5Aeh_oAAAAJ
发表会议:ACM MM2024
1.背景与动机
可解释人工智能 (XAI) 的一个关键目标是构建能够推理和解释现实世界数据的智能系统,以促进可靠的决策。目前研究者开始关注用户友好且可验证的解释,以促进值得信赖的视觉问答 (VQA) 系统。本文旨在从数据和方法角度促进可解释的视觉问答。在数据方面,当前的视觉问答多模态解释数据集利用定制化的格式构建解释,无法与标准的自然语言对齐。另外,现有数据集利用预训练的Faster R-CNN标注视觉目标,仅仅包含81个类别。以上数据缺陷制约了多模态可解释视觉问答领域的发展。在方法方面,现有的生成式方法依赖于大量训练数据,这消耗了大量资源并且在一些垂直领域可能是不实用的。当在少量数据上进行训练时,尽管基于预训练的视觉-语言模型,但现有最先进的方法的性能依然会显著下降。特别是考虑到开放世界学习的最新进展(例如大语言模型),更精简和实用的学习框架可能才是未来发展的方向。受上述多模态可解释视觉问答领域当前进展的启发,本文尝试从数据和模型两个角度推动面向视觉问答的少样本多模态解释(MEVQA),提出了一个新的多模态解释数据集和一个新的基于大语言模型智能体的免训练推理与解释方法。
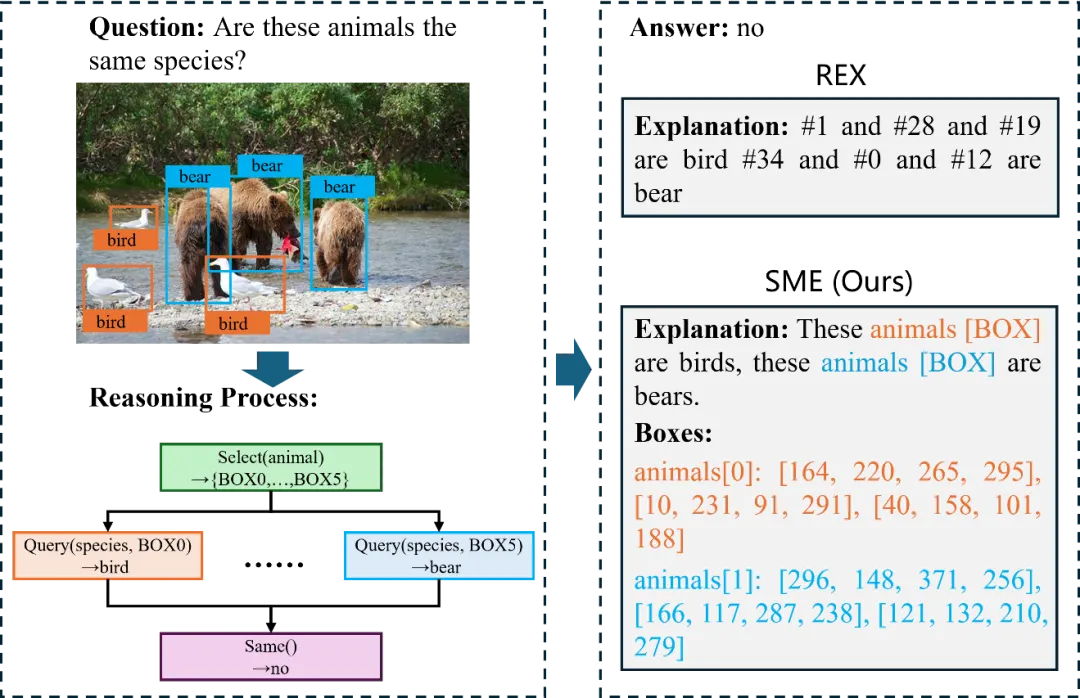
图1 所提出SME数据集与现有REX数据集的对比
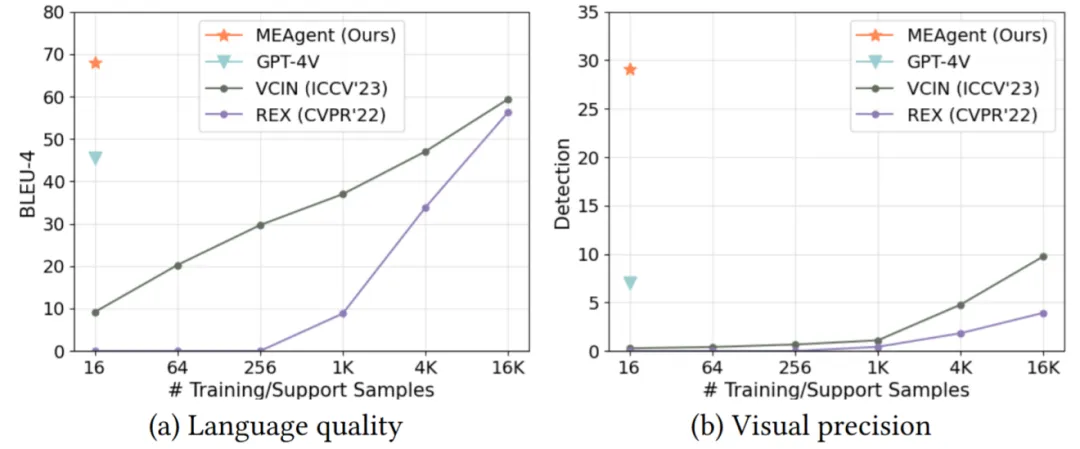
图2 所提出MEAgent方法与现有方法在少样本训练时的生成解释质量对比
2.方法概述
为了提高多模式解释的可读性和用户友好性,本文提出了标准多模态解释(SME)数据集,其中解释基于标准英语,并带有其他 [box] 符号来关联视觉区域。所构造的解释基于解决视觉问题的推理步骤,以及包含1,703类视觉目标的视觉场景图。在将结构化的推理步骤转换为具有视觉目标注释的自然语言式解释之后,本文利用GPT-3.5将不带 [box] 符号的解释校正为标准英语。为了对多模态解释中的视觉目标进行有效评估,本文标注了关键的视觉目标检测框,并对其在解释中提到的相应名称添加了特殊的 [box] 符号来表示。
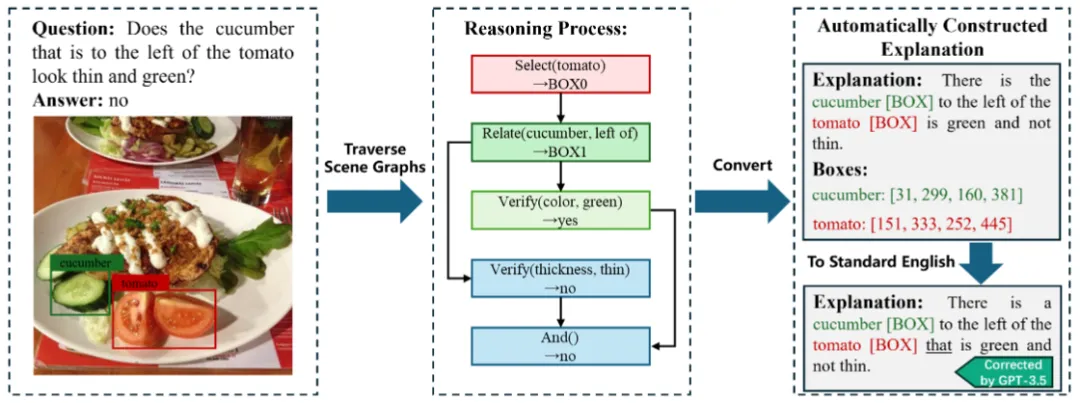
图3 SME数据集的多模态解释标注过程
为了克服对大规模训练数据的依赖,本文提出了一种基于具有多模态开放世界工具和大语言模型智能体的无训练多模态解释智能体(MEAgent)方法,能够在仅给定16个训练样本的情况下推理答案并为视觉问题生成多模式解释。在这样的少样本设置下,训练样本的价值主要在于定义MEVQA任务,而模型需要训练之外的知识和开放世界工具来解决测试问题。借助基于少量上下文样本的程序提示和解释提示,MEAgent可以生成用于解决输入问题的多模式程序,通过开放世界工具来推理答案,并将执行过程转换为多模态推理过程的多模态解释。
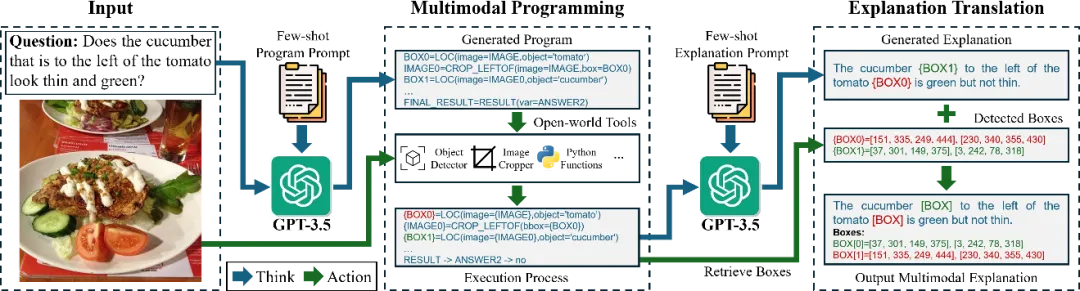
图4 多模态解释智能体方法框架
3.实验分析
本文在所提出的SME数据集上对MEAgent进行了评估,并均取得了SOTA的表现。尤其在CIRCO上,在解释的文本质量(BLEU-4、METEOR、ROUGE-L、CIDEr、SPICE)和视觉精度(Detection),以及问答准确率指标上,MEAgent相比多模态可解释视觉问答的SOTA方法和多模态大模型均取得了显著提升,证明了所提出方法的有效性。
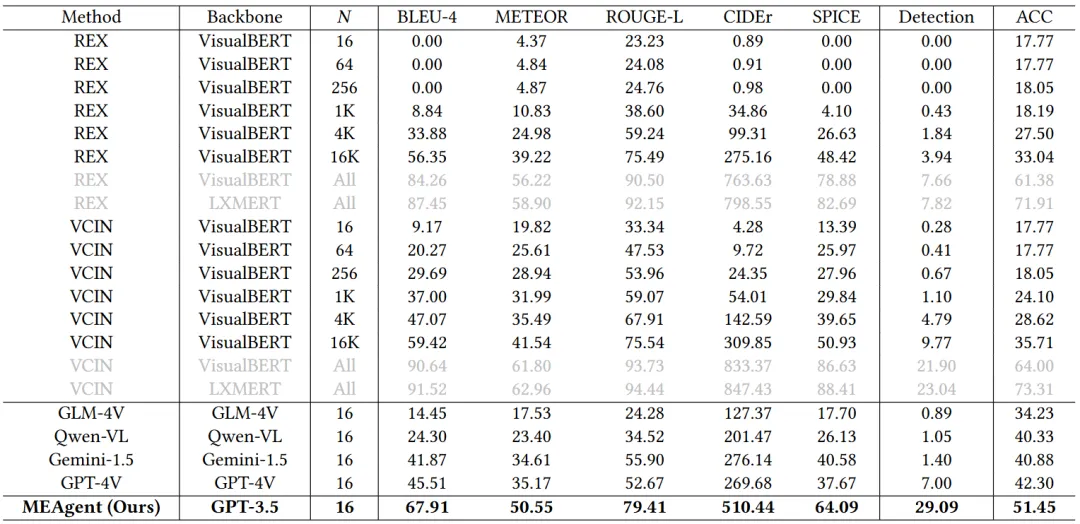
表1 面向视觉问答的多模态解释实验结果
实验结果表明,MEAgent在多模态解释生成中各类视觉目标的召回率均超过SOTA方法,显示了对物理视觉更强的推理和解释能力。

表2 多模态解释生成中各类视觉目标召回率
02
HiVG: Hierarchical Multimodal Fine-grained Modulation for Visual Grounding
作者:
肖麟慧1,2,3,杨小汕1,2,3,彭芳1,2,3,王耀威2,4,徐常胜1,2,3,*
单位:
1中国科学院自动化研究所多模态人工智能系统全国重点实验室,
2鹏城实验室,
3中国科学院大学人工智能学院,
4哈工大深圳
邮箱:
xiaolinhui16@mails.ucas.ac.cn, xiaoshan.yang@nlpr.ia.ac.cn,
wangyw@pcl.ac.cn,
csxu@nlpr.ia.ac.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681071
代码:
https://github.com/linhuixiao/HiVG
发表会议:ACM MM 2024
*通讯作者
1.论文简介
视觉定位,旨在通过自然语言定位一个视觉区域,是一项严重依赖于跨模态对齐的任务。现有的工作利用单模态预训练模型分别迁移视觉或语言知识,而忽略了相应的多模态信息。受对比语言图像预训练(CLIP)和低秩自适应(LoRA)方法最新进展的启发,我们旨在解决基于多模态预训练的定位任务。然而,在预训练和定位之间存在着显著的任务差距。因此,为了解决这些差距,我们提出一种简洁高效的层级多模态细粒度调制框架,即HiVG。具体来说,HiVG由多层自适应跨模态桥和层级多模态低秩自适应(HiLoRA)范式组成。跨模态桥可以解决视觉特征与定位要求之间的不一致,并在多层级的视觉特征和文本特征之间建立联系。HiLoRA通过层级方式将跨模态特征从浅层调整到深层来防止感知错误的积累。在五个数据集上的实验结果证明了我们的方法的有效性,并展示了显著的定位能力以及有前景的能效优势。本文的数据集、代码和模型均已开源。
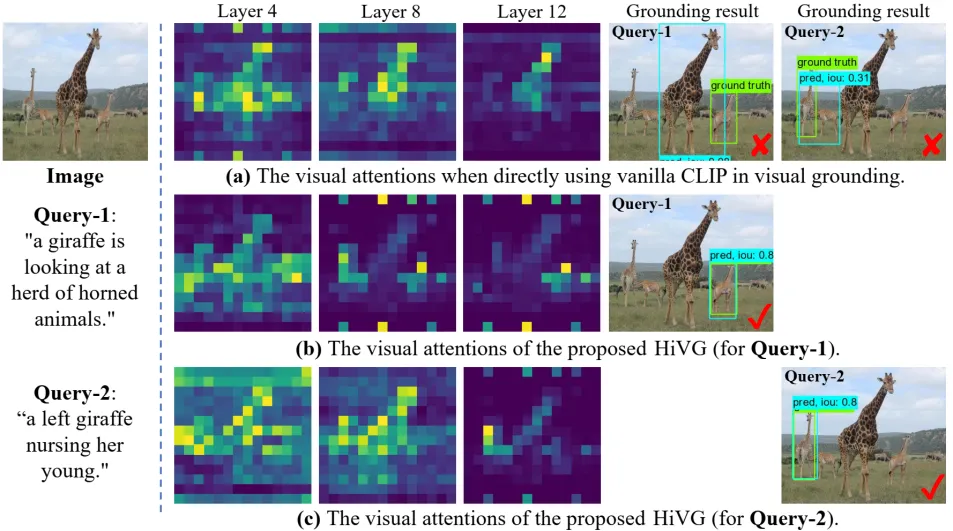
图1 原始CLIP和HiVG在不同指代查询文本下的视觉注意力和定位结果比较
2.方法摘要
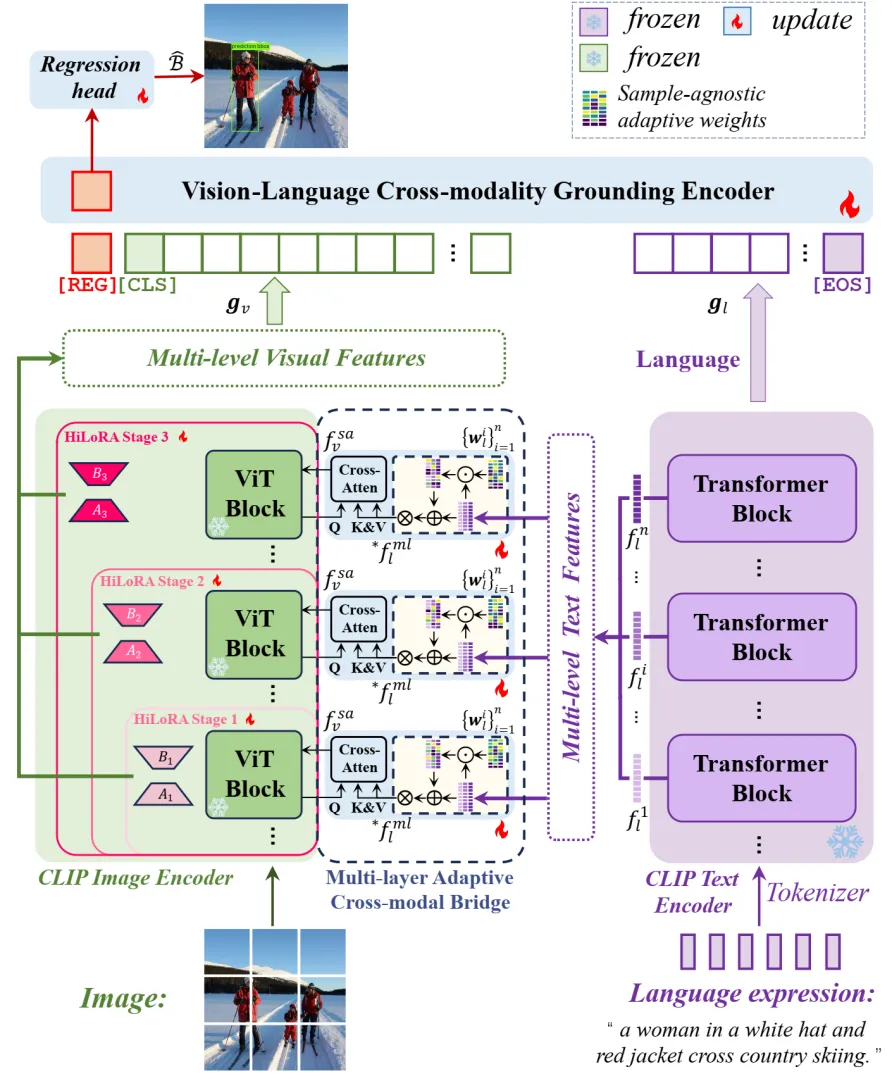
图2 层级多模态细粒度调制框架(HiVG)的模型结构
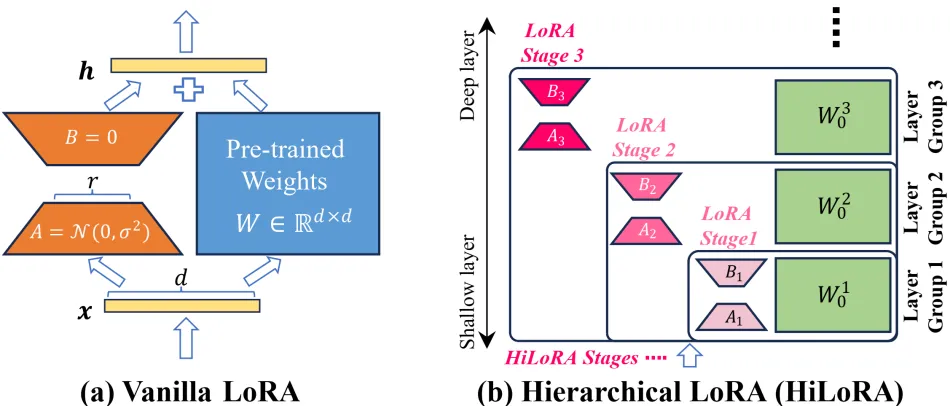
图3 原始LoRA和层级LoRA的对比
在本文中,我们提出一种层级的多模态细粒度调制框架,以更有效地使预训练的CLIP模型适应定位任务,我们将这一框架命名为HiVG。HiVG是一个简洁高效的端到端框架,它通过多层级自适应跨模态桥和层级低秩自适应范式,以缓解已介绍的两种任务差异(即数据偏差和学习目标)所带来的问题。
具体来说,首先,为了解决预训练CLIP的视觉特征与定位所需的视觉特征不一致的问题,并建立多层级视觉特征与文本特征之间的联系,我们设计了一个多层自适应跨模态桥(Multi-layer Adaptive Cross-modal Bridge,MACB)。具体来说,跨模态桥包括一个样本不可知的语义加权模块(sample-agnostic semantic weighting module)和一个多头交叉注意模块(multi-head cross-attention module)。加权模块采用可学习的多层样本无关的自适应权重,通过残差运算的方式选择合适的语言特征。多头交叉注意力利用所选择的多层级文本特征来指导定位所需的视觉特征的学习。样本不可知的语义加权方案受到其他工作的启发,即预训练模型的特定层可能对某些概念或语义有不同的响应,而这些这些响应与输入无关而与网络层级本身有关。
其次,为防止预训练模型在下游自适应过程中的误差逐层累积,我们提出了层级低秩自适应(Hierarchical Low-rank Adaptation,HiLoRA)范式。具体来说,现有的方法主要是利用传统LoRA作为参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)的方法对整个模型进行单轮学习。与之前的方法不同,我们将预训练的CLIP的网络层分为多个层组(Layer Group)。同时,低秩自适应被分为多个阶段,每个阶段与几个层组进行关联。随后,在自适应的过程中,将以层级的方式从浅层到深层递归式和层级式地适应视觉特征。同时,在多层跨模态桥的辅助下,HiLoRA不仅可以实现细粒度的层级自适应,还可以对低秩矩阵实现基于视觉和语言跨模态信息的感知。
本文的主要贡献可以简要概括为三个方面:
本文提出了一个简洁的层级多模态调制框架,该框架利用层级结构渐进式地将CLIP在定位任务上进行迁移。HiVG实现了多层级的视觉表征与语言语义之间的细粒度交互,显著地缓解了CLIP与定位之间的任务鸿沟。
本文首先提出了层级多模态低秩自适应结构HiLoRA。它是一个基础的、简洁的层级自适应范式,它是任务不可知的,具有广阔的应用前景。
本文进行了大量的实验来验证HiVG方法的有效性。结果表明,我们的方法取得了令人满意的结果,在相同设置下明显优于SoTA方法。此外,我们的模型也具有显著的计算效率优势。
3. 实验分析
如下表1和图2所示,我们在五个广泛使用的数据集上与最新的SOTA工作进行了比较,包括CLIP-VG、Dynamic-MDETR、TransVG++、grounding-DINO和OFA等。 (1) 与基于CLIP的微调SoTA工作,即Dynamic-MDETR相比,我们的方法在所有五个数据集上均表现出色,在五个数据集上分别提高了3.15%(testB)、2.11%(testA)、4.30%(test)、4.85%(test)、0.22%(test)。 (2) 与基于检测器的微调SoTA工作,即TransVG++相比,我们的方法在所有五个数据集上均展现出更优的性能,分别提高了2.30%(testB)、3.36%(testA)、2.49%(test)、0.52%(test)、0.62%(test))。在RefCOCO+/g数据集上的改进尤为显著,表明我们的模型在复杂句子的语义理解方面具有更强的能力。 (3) 与数据集混合预训练的工作相比,我们工作的Base模型在RefCOCO/+/g数据集上分别比Grounding-DINO高出1.24%(testB)、1.81%(testA)和0.68%(test),并且也比OFA高出3.93%(testB)、2.06%(testA)和3.31%(test)。在数据集混合预训练之后,我们的性能有了显著提升,进一步证明了我们方法的有效性。
表1 在RefCOCO/+/g/ReferIt/Flickr五个数据集两种设置上的SoTA对比分析实验
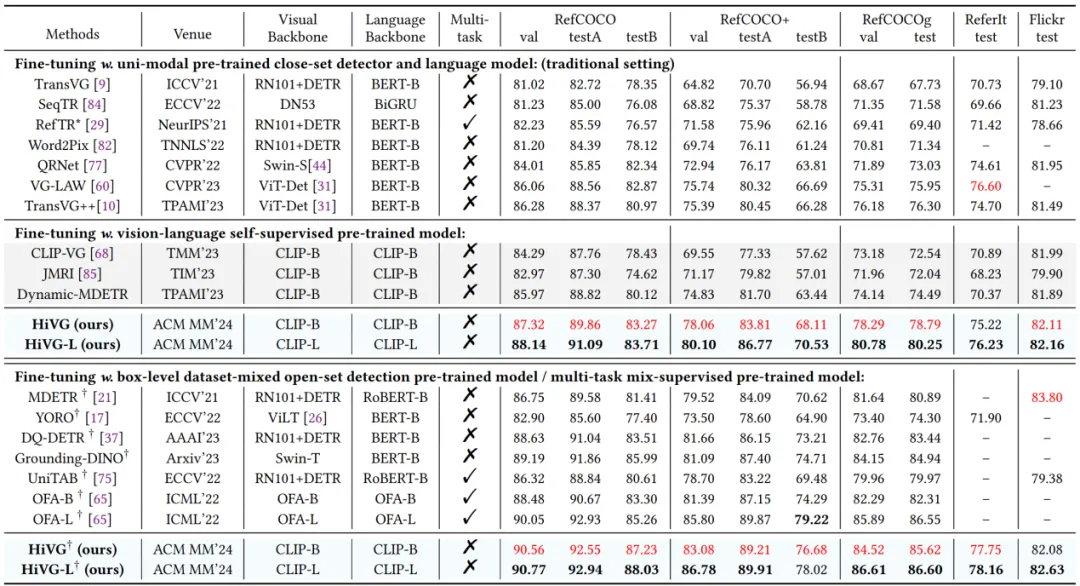
在图2当中,我们可以看到,(a) HiVG具有显著的能效优势,比TransVG++快8.2倍,同时在RefCOCO-val上优于TransVG。 (b) 与TransVG++相比,HiVG的计算复杂度仅为13.0%。 (c) 在RefCOCOg测试集中,HiVG在不同表达文本长度下优于SoTA模型。(d) HiLoRA方法为HiVG模型带来了显著的性能提升。
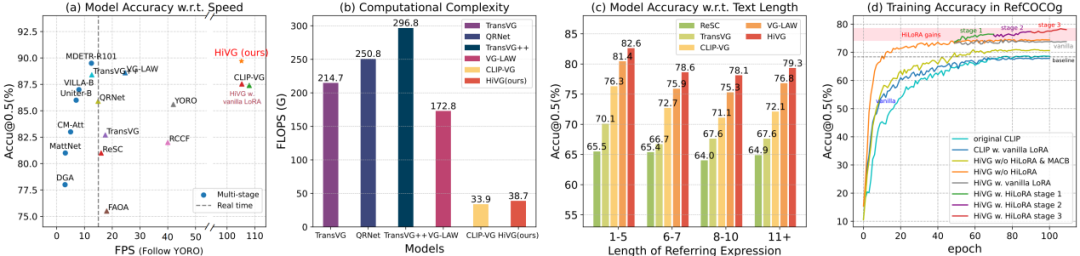
表2 HiVG和主要的SoTA模型在能效、计算复杂度、指代表达长度等方面的消融实验
03
Autogenic Language Embedding for Coherent Point Tracking
作者:
宋子恺1,唐颖1,罗润2,马林涛1,于俊清1*,Yi-Ping Phoebe Chen3,杨卫1*
单位:
华中科技大学1,中国科学院深圳先进技术研究院2,乐卓博大学3
邮箱:
skyesong@hust.edu.cn,
t_ying@hust.edu.cn,
r.luo@siat.ac.cn,
mltdml@hust.edu.cn,
yjqing@hust.edu.cn,
phoebe.chen@latrobe.edu.cn,
weiyangcs@hust.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681104
发表会议:ACM MM 2024
*通讯作者
1.研究背景
点跟踪(Point tracking)是视觉追踪领域的一项前沿技术,它的核心目标是在连续的视频帧之间建立精确到像素级的对应关系。这项任务面临巨大挑战,因为它需要同时理解场景的静态结构和动态变化,才能实现高精度追踪。点跟踪与光流法(Optical flow)有一定相似性,但它能追踪像素点在更长时间跨度内的对应关系,如跨越几十甚至上百帧。过去对点跟踪的研究主要集中在改进对时间信息的建模,例如: 通过学习时间先验知识来预测像素位置,在遮挡场景中找出稳定的长期运动轨迹,同步追踪多个连续帧中的像素点等等。然而这些方法主要依赖相邻帧之间局部特征的相似性,如颜色、纹理等,一旦目标外观发生明显变化,如发生光线变化或物体变形等,追踪效果就容易受到影响。因此我们提出了一种全新思路——关注被追踪点的语义连贯性,我们认为跨帧的对应点的语义含义在时间维度上应该保持一致。
2.方法介绍
我们提出一种名为ALTracker的方法,如图2所示。我们的方法通过一个专门的映射网络,直接从视觉特征中自动生成对应的文本特征,无需依赖人工标注的文本数据。此外,我们设计了一个轻量化的语义一致性解码器,它包含了一个文本增强模块和一个文本-图像整合模块,文本增强模块通过将图像嵌入整合到注意力机制中来丰富文本嵌入,文本-图像集成模块将增强的文本嵌入与图像特征相结合,从而获得一致性特征。一致性解码器能将生成的文本特征无缝融合到视觉特征中,增强追踪的稳定性,通过这种融合,即使在目标外观剧烈变化(比如光线变化、物体变形)的长视频中,我们的方法也能生成更连贯的追踪轨迹。
该方法包含三个核心组件:
自动化文本提示生成模块:通过视觉-语言映射网络(Mapping network),从图像特征中无监督生成语义对齐的文本标记(Mapped tokens),实现跨模态特征的自动化转换;
文本嵌入增强模块(Text enhancement):基于层级注意力机制,将图像特征与文本嵌入融合,生成具有空间感知的精细化文本描述,确保语义表征的精确性;
文本-图像整合模块(Text-image integration):设计动态门控网络,通过自适应权重分配策略将增强后的文本语义信息注入视觉特征流,强化跨模态特征的一致性表达。
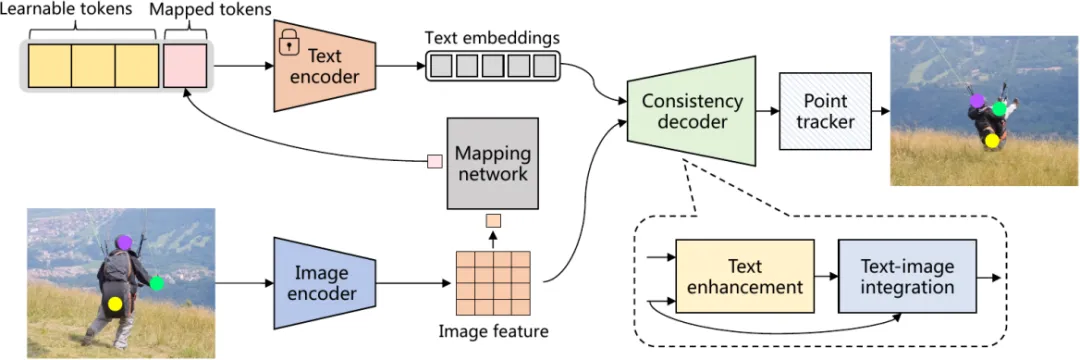
图2 整体框架图
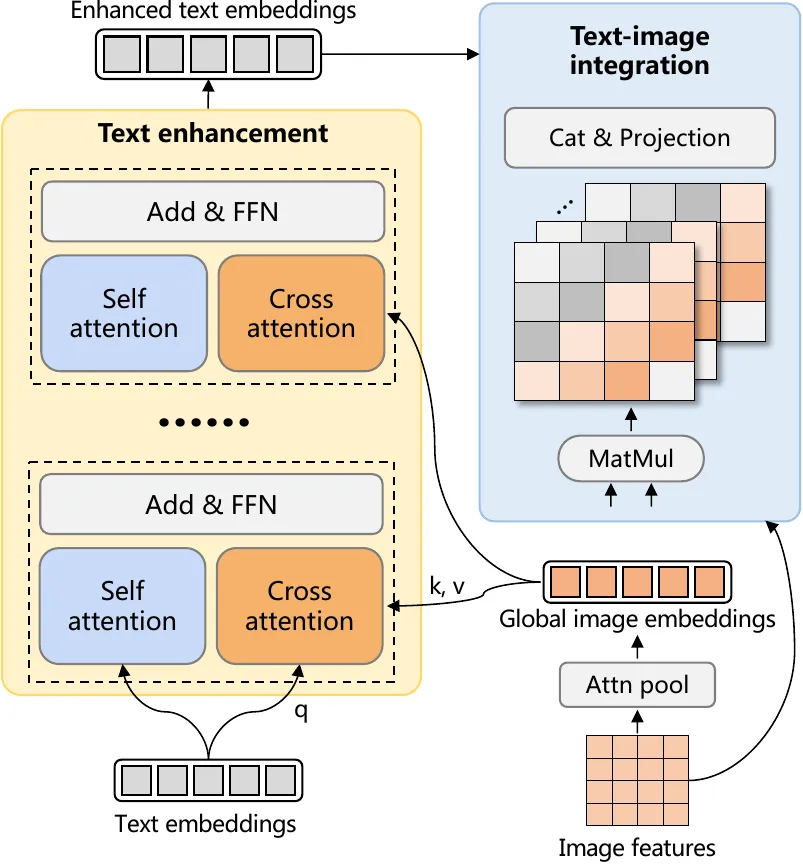
图3 一致性解码器
3.实验结果
本文提出的视觉一致性增强框架具有即插即用特性,可兼容现有各类点追踪方法(如TAPIR、CoTracker),在仅引入约3%额外计算开销的条件下显著提升性能。在TAP-Vid、PointOdyssey 等复杂数据集上的对比实验表明,本方法在平均追踪精度(MOTA)及长时序稳定性(≥500帧)指标上均达到当前最优水平,如表1和表2所示。
表1 在TAP-Vid-DAVIS 和 TAP-Vid-Kinetics 数据集上的性能比较
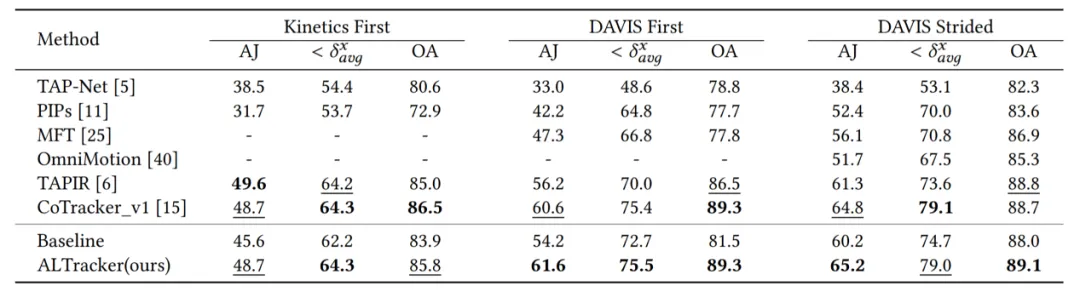
表2 在PointOdyssey 数据集上的性能比较
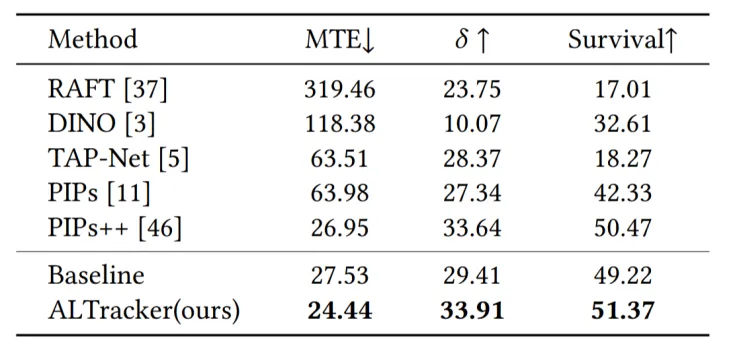
在图4中我们将物体的运动轨迹可视化,并比较了完全依赖视觉特征的基线方法(无语言嵌入)和我们的方法(有语言嵌入)的跟踪轨迹,我们的方法与基线方法保持了相同的结构框架。可以看出,在具有大量外观变化的冗长视频序列中,我们的方法显示出更强大的语义对应性。

(a) 完全依赖视觉特征

(b) 我们的方法
图4 跟踪点轨迹可视化
04
FiLo: Zero-Shot Anomaly Detection by Fine-Grained Description and High-Quality Localization
作者:
古兆鹏1,2,朱炳科1,3,朱贵波1,2,陈盈盈1,3,李浩4,唐明1,2,王金桥1,2,3
单位:
1中国科学院自动化研究所紫东太初大模型中心,
2中国科学院大学人工智能学院,
3中科视语(北京)科技有限公司,
4中南大学
邮箱:
guzhaopeng2023@ia.ac.cn,
{bingke.zhu,gbzhu,yingying.chen,tangm,jqwang}@nlpr.ia.ac.cn,
8209210109@csu.edu.cn,
论文:
https://dl.acm.org/doi/10.1145/3664647.3681162
代码:
https://github.com/CASIA-IVA-Lab/FiLo
发表会议:
ACM MM 2024
1.研究背景
异常检测是工业生产和质量控制领域的一大重要任务,传统异常检测方法通常依赖大量的正常样本进行训练,但在新生产线的“冷启动”场景中,这些方法往往不适用。零样本异常检测在这种情况下应运而生,其目标是在没有目标类别物体训练数据的情况下,直接进行异常检测。现有的零样本异常检测方法通常依赖于多模态预训练模型的强大泛化能力,通过计算图像特征与手工编写的表示“正常”或“异常”语义的文本特征之间的相似度来判断图像中是否含有异常,并根据文本特征和每个图像子块特征的相似度来定位异常区域。然而,通用的“异常”描述往往无法精确匹配不同物体类别中的各种异常类型,文本特征与孤立图像子块特征的相似性计算也难以准确定位具有不同大小和尺度的异常区域。
为了分别解决这两个问题,本文设计了FiLo方法,其包括自适应学习的细粒度描述(FG-Des)和位置增强的高质量定位(HQ-Loc)两个有机结合的模块,在异常检测和异常定位两个方面取得了显著的性能提升,在零样本异常检测工业场景中取得了业内最好性能。
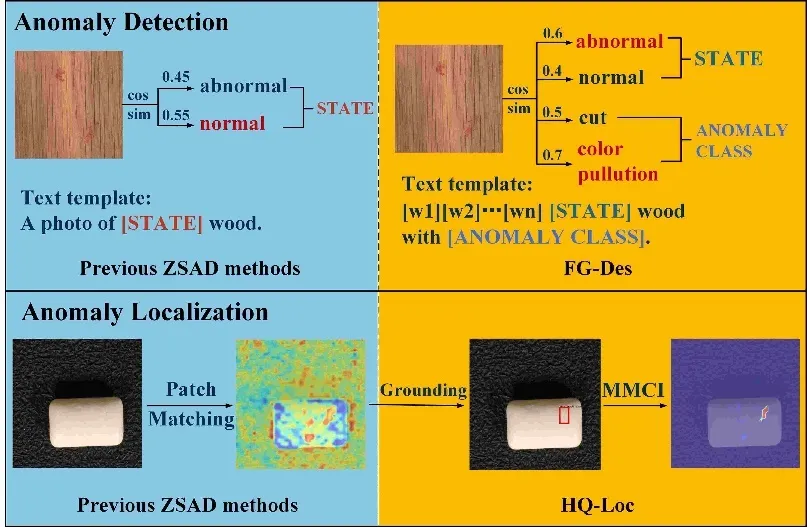
图1 FiLo 与现有零样本异常检测方法对比
2.方法概述
方法的整体框架如图2所示,主要包括自适应学习的细粒度描述(FG-Des)和位置增强的高质量定位(HQ-Loc)两个部分。
在FG-Des模块中,FiLo首先通过具有丰富知识的大语言模型生成每个物品类别可能存在的细粒度异常类型列表,然后设计了自适应学习的文本模板,将细粒度异常描述填入可学习文本模板中,得到能够更加精准匹配图像内容的“正常”与“异常”文本特征。
在HQ-Loc模块中,FiLo首先将待检测图像和细粒度异常描述内容输入到视觉基础模型Grounding DINO中,以获得初步的异常定位框,并将初步定位框的位置信息也额外添加到文本特征中。接下来,FiLo将图像编码器提取的图像特征通过多尺度、多形状的跨模态交互模块(MMCI)与含有位置信息的文本特征交互,并通过 Grounding DINO的定位框过滤以得到异常分数图。
通过上述方法,FiLo能够充分利用大语言模型的强大先验知识和视觉基础模型的泛化能力,再结合MMCI模块的多尺度、多形状特征交互,有效提升了异常检测和定位的准确性。
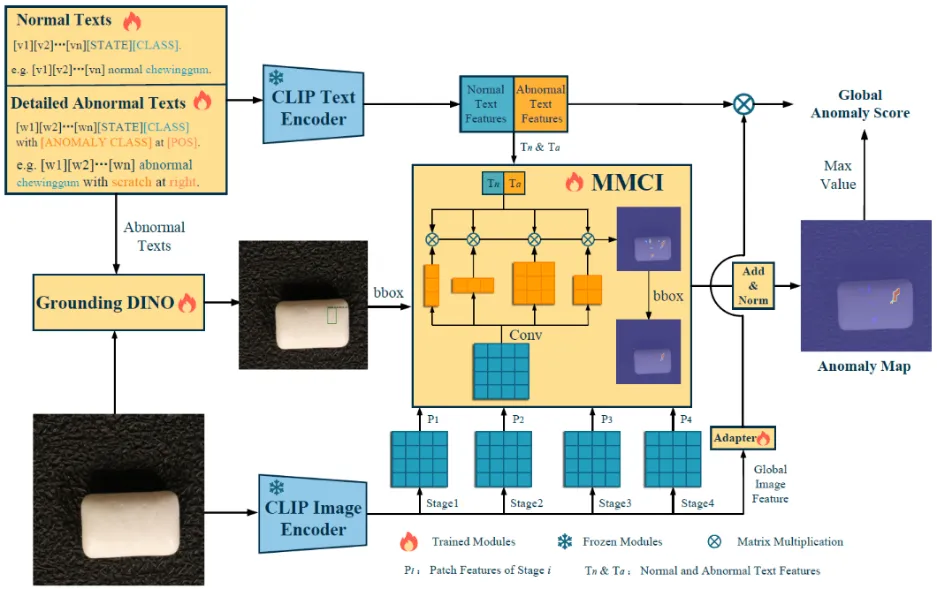
图2 FiLo 整体框架图
3.实验结果
我们在目前流行的 MVTec-AD和VisA两个工业异常检测数据集上进行了实验,与现有零样本异常检测方法相比,FiLo在图像级异常检测和像素级异常定位上取得了总体最先进的性能。
表1 FiLo 与现有零样本异常检测方法性能对比
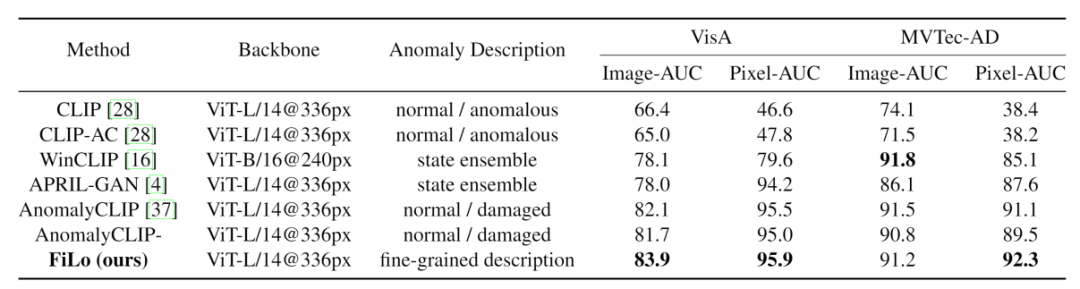
图3展示了FiLo在工业场景下的可视化检测结果。在FG-Des和HQ-Loc模块的协同作用下,FiLo在未经目标类别数据训练的情况即可准确检测异常区域。
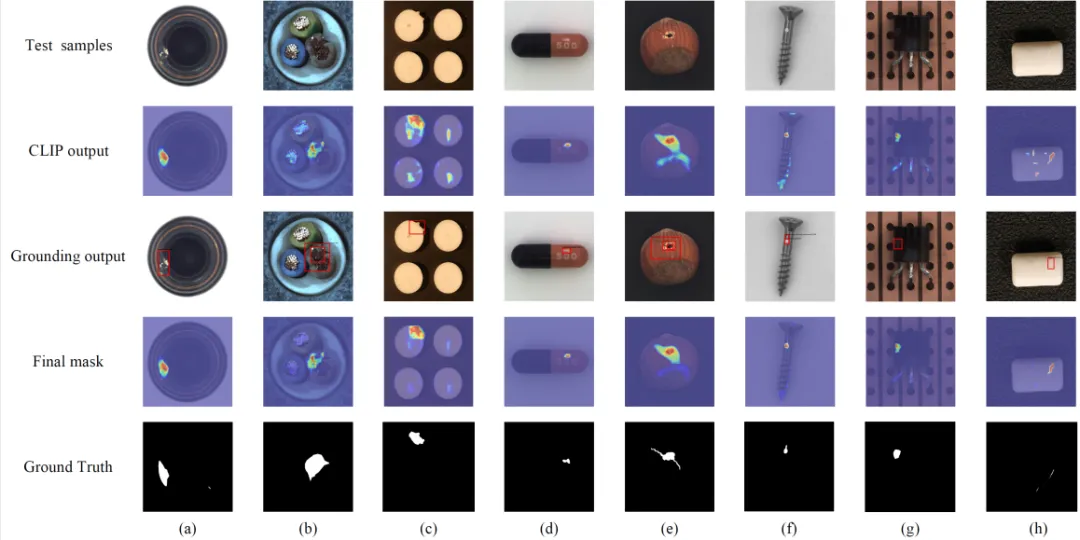
图3 FiLo 的可视化异常检测结果
如图4所示,通过观察与图像特征最相似的细粒度异常描述,我们还可以得知图像中的具体异常种类,为模型的判断提供了依据,提高了模型决策的可信度和可解释性。

图4 具体异常类型判断
05
Dual Advancement of Representation Learning and Clustering for Sparse and Noisy Images
作者:
黎文林,许宇澄,郑笑晴,韩索雅,王俊,孙晓波*
单位:
中南财经政法大学,南开大学,吾道科技
邮箱:
{wenlinli,yuchengxu,xiaoqingzheng,suoyahan,xsun}@stu.zuel.edu.cn,
jwang@iwudao.tech
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3681402
代码:
https://github.com/zipging/DARLC
发表会议:ACM MM 2024
*通讯作者
1.引言
在生物医学、天文学和显微成像等领域,稀疏且噪声较大的图像(Sparse and Noisy Images, SNIs)普遍存在。这些图像通常包含大量无信息区域、较高的噪声水平以及高度碎片化的视觉模式,给数据分析和解释带来了极大挑战。例如,空间基因表达图像(SGEPs)是空间转录组学(ST)技术生成的重要数据类型,如图1,但其高度稀疏和噪声特性使得主要基因表达模式的提取变得困难。
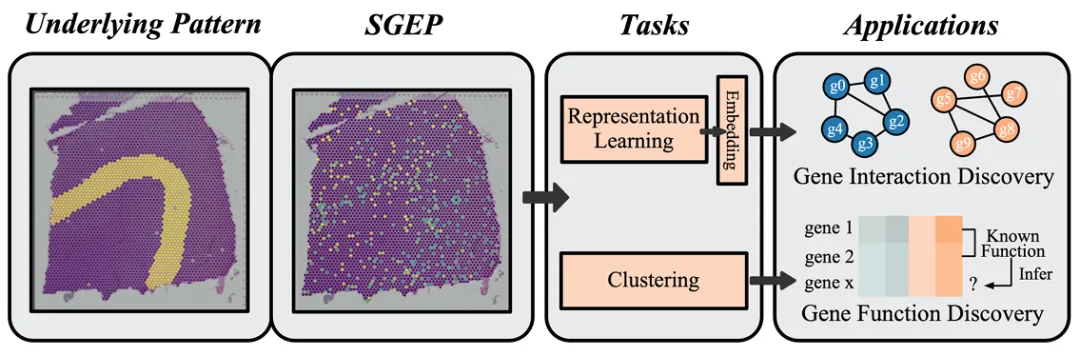
图1 稀疏噪声图像举例
现有的图像聚类方法在处理SNIs时存在局限性,主要表现为:(1) 由于背景区域的干扰和噪声影响,难以学习到具有语义信息的有效特征;(2) 视觉模式的随机变化导致聚类算法容易出现过拟合。此外,现有的自监督学习(SSL)方法,如对比学习(CL)和掩码图像建模(MIM),在处理SNIs时各有优劣,单一方法难以兼顾局部感知能力和全局判别性。
2. 方法概述
为解决SNIs的表示学习和聚类问题,本研究提出了一种新的端到端框架——DARLC(Dual Advancement of Representation Learning and Clustering),如图2,该方法具有以下核心特点:
1). 融合对比学习(CL)和掩码图像建模(MIM),提升表示学习的质量,兼顾局部感知能力和全局判别性。
2). 引入基于图注意力网络(GAT)的数据增强方法,通过聚合邻域信息降低噪声,生成更合理的正样本,以提高对比学习的效果。
3). 采用学生t混合模型(SMM)进行深度聚类,增强对异常值的鲁棒性,同时利用聚类损失优化CL过程,缓解类别冲突问题。
4). 自适应聚类优化策略,通过“热启动”表示学习(warm-up)初始化特征空间,并采用层次化损失函数进行端到端优化,从而加速训练收敛,提高聚类精度。
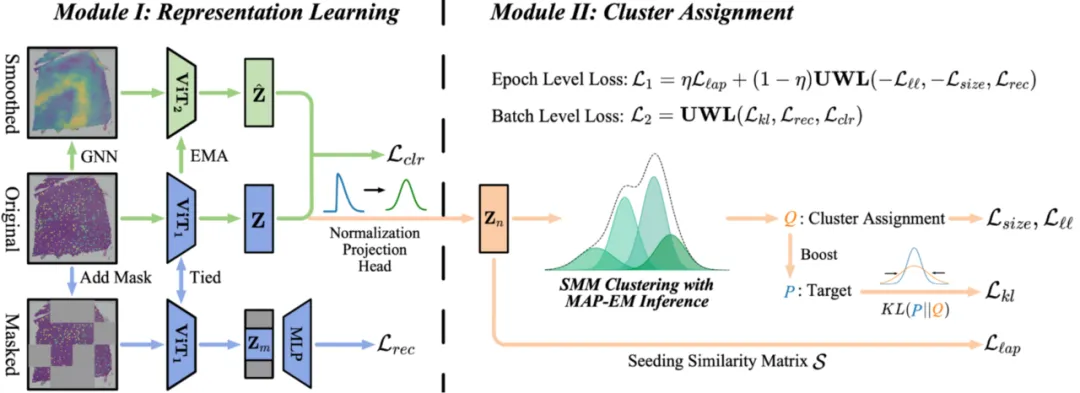
图2 模型架构图
3.实验结果
为了验证DARLC的有效性,研究在12个不同类型的SNIs数据集上进行了大量实验,涵盖空间转录组学(ST)和质谱成像(MSI)等领域的数据。主要实验结果如下:
1). 聚类性能提升:在DBIE、DBIP、NMI和ARI等多个指标上,DARLC均显著优于现有最先进方法,与最佳基线方法相比,DBIE平均降低15.98%,DBIP降低18.44%,显示出卓越的聚类效果,如表1。
2). 基因-基因交互预测:相比iBOT和其他基线模型,DARLC生成的基因图像表示在基因交互预测任务上的准确率提升了约10%,表明其能够更有效地捕捉基因的功能关系,如表2。
3). 空间共功能基因聚类:DARLC能够将同一基因家族的基因正确聚类,其NMI和ARI得分均高于基线方法,进一步验证了其在生物数据分析中的潜力,如表3。
4). 消融实验分析:去除CL模块、GAT数据增强或SMM聚类等组件后,DARLC的聚类性能下降幅度较大,表明这些模块对模型的整体性能具有显著作用,如表4。
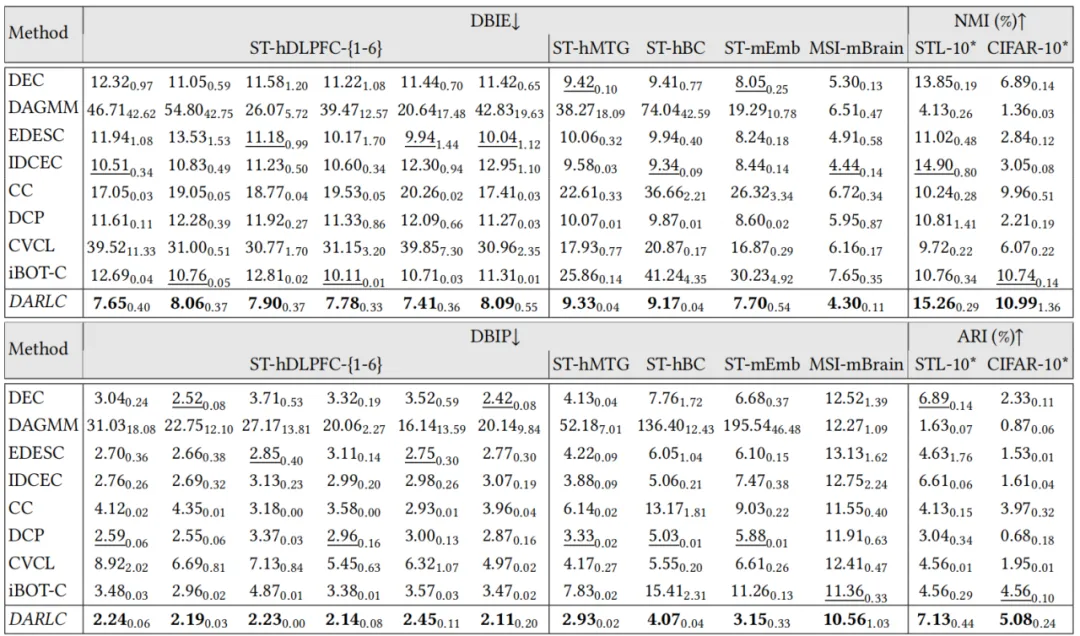
表1 DARLC和基线模型在12个数据集上进行聚类效果比较
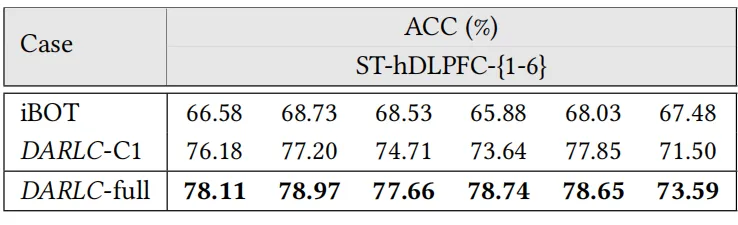
表2 基因-基因相互作用预测
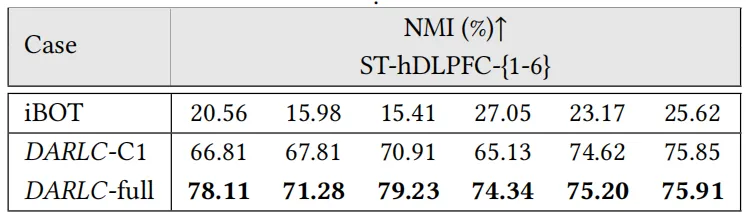
表3 空间共功能基因聚类
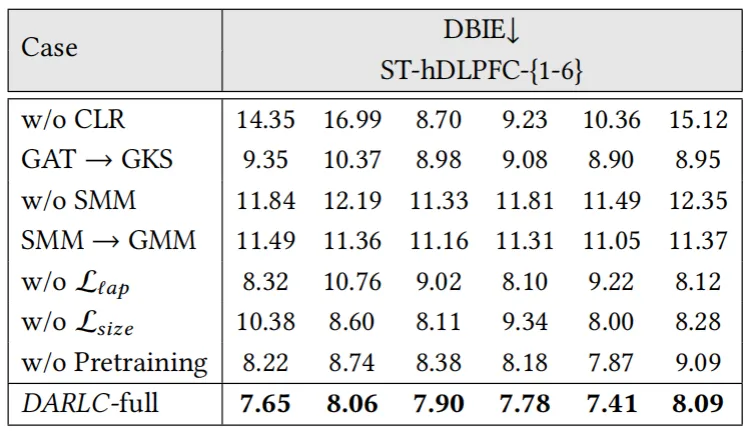
表4 消融实验

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号