
【论文导读】2025年论文导读第八期
【论文导读】2025年论文导读第八期
2025年05月13日 11:51 北京


论文导读
2025年论文导读第八期(总第一百二十五期)
目 录
|
1 |
A Novel Federated Multi-View Clustering Method for Unaligned and Incomplete Data Fusion |
|
2 |
“Special Relativity” of Image Aesthetics Assessment: a Preliminary Empirical Perspective |
|
3 |
Attribute-Driven Multimodal Hierarchical Prompts for Image Aesthetic Quality Assessment |
|
4 |
Semantic-aware Representation Learning for Homography Estimation |
|
5 |
Joint Homophily and Heterophily Relational Knowledge Distillation for Efficient and Compact 3D Object Detection |
01
A Novel Federated Multi-View Clustering Method for Unaligned and Incomplete Data Fusion
作者:
任亚洲1,*,陈新越1,*,徐杰1,普敬誉1,黄咏皓1,蒲晓蓉1,朱策1,朱晓峰1,郝志峰2,何丽芳3
单位:
电子科技大学1,汕头大学2,里海大学3
邮箱:
yazhou.ren@uestc.edu.cn,
martinachen2580@gmail.com,
jiexuwork@outlook.com,
pujingyu0105@163.com,
yonghao.h@foxmail.com,
puxiaor@uestc.edu.cn,
eczhu@uestc.edu.cn,
seanzhuxf@gmail.com,
haozhifeng@stu.edu.cn,
lih319@lehigh.edu
论文:
https://www.sciencedirect.com/science/article/pii/S1566253524001350
代码:
https://github.com/5Martina5/FCUIF
发表会议/期刊:
ACM MM 2023,Information Fusion 2024
*通讯作者
1.研究背景和动机
最近,联邦多视图聚类(Federated Multi-View Clustering,FedMVC)已成为发现分布式客户端互补聚类结构的有力工具,其在数据融合领域备受关注。虽然联邦多视图聚类方法能很好地解决不同客户端之间特征异质性的挑战,并在受控环境中取得了显著的成功。但它们的适用性往往取决于多视图客户端之间严格对齐和数据完整性的假设。遗憾的是,这些假设并不总是符合实际情况。具体来说,实际应用中经常会出现以下情况:(1)多视图数据未对齐;(2)多视图数据不完整。目前的联邦多视图聚类方法难以有效解决这些难题。为了跨越这一差距,本文提出了一种针对不对齐和不完整数据融合的联邦多视角聚类方法(Federated multi-view Clustering method for Unaligned and Incomplete data Fusion,FCUIF)。
这篇论文是我们之前发表在ACM MM 2023的研究成果(Federated Deep Multi-View Clustering with Global Self-Supervision)的期刊拓展版本,相比于原会议版本解决了分散在分布式客户端的多视图数据集中存在的对齐难题,并且针对不完整问题的解决方案更加有效。为了解决数据不对齐的问题,FCUIF方法利用样本的共性和视图的通用性自适应生成对齐矩阵,确保有效的跨视图对齐。针对缺失数据的挑战,FCUIF方法采用无监督技术来评估和改进插补质量,从而有效地处理各类不完整多视图数据。我们在四个公开多视图数据集上进行了大量实验,证明 FCUIF方法在处理未对齐和不完整的多视图数据时性能优越。
2.方法概述
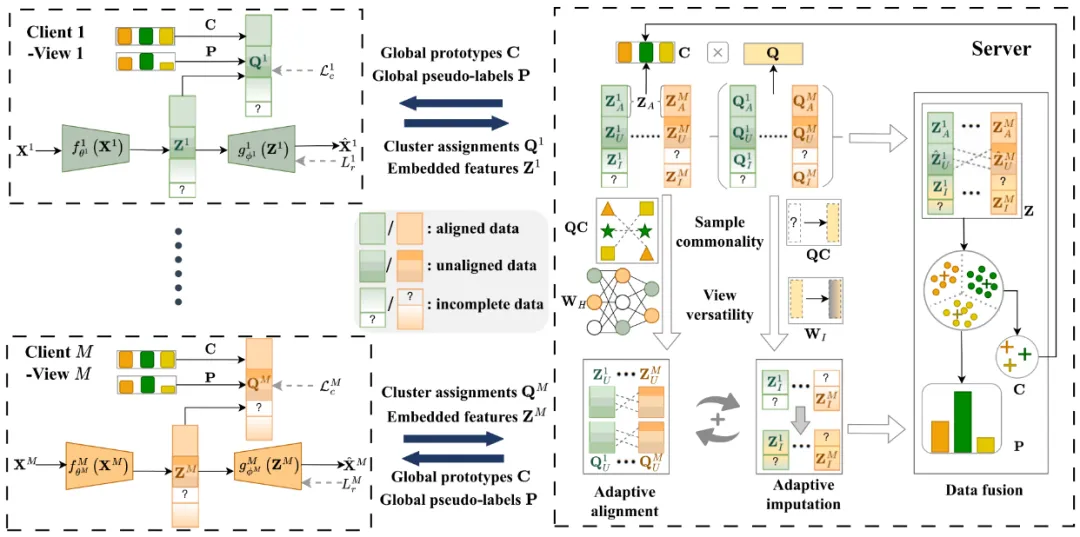
图1 模型框架图
本文提出的FCUIF方法包含M个客户端和服务器端。(1) 客户端:多个客户端整合全局自监督信息,从其本地私有数据中提取特定视图的嵌入式特征和聚类分配。(2) 服务器端:服务器采用自适应对齐和插补模块重建样本间的跨视图关系,并利用数据融合策略挖掘全局聚类结构。
具体来说,在每个客户端中,本地客户端使用深度自动编码器和全局自监督信息从本地私有数据中提取特定视图的嵌入特征和聚类分配,然后上传到服务器。在服务器中,服务器从每个客户端上传的数据中提取样本共性和视图通用性,并利用自适应对齐模块和自适应插补模块重建样本之间的跨视图关系。自适应对齐模块利用提取的样本共性特征来捕捉跨客户端的数据相似性,从而自适应地计算对齐矩阵并协助获得对齐的全局特征。自适应插补模块以无监督方式有效评估插补质量,在服务器上实现自适应插补,以解决跨客户端多视图数据不完整的问题。该模块利用样本共性和视图通用性,自适应地对跨客户端的不可用部分进行插补,有效地处理了分布式环境中的各种不完整数据情况,包括点、块和不平衡不完整数据情况。此外,服务器还提供全局自监督信息,帮助每个客户端进行本地训练,并促进高质量全局聚类结构的挖掘。
3.实验结果
为了评估所提出方法的有效性,我们在BDGP、Reuters、Scene和HW四个常用多视图数据集上进行实验。我们分别与五种多视图对齐方法以及八种不完整多视图聚类方法进行比较。我们选择准确率(ACC)、归一化互信息(NMI)和调整兰德指数(ARI)作为评价指标,并在数据未对齐和不完整情景下进行实验分析。
为了模拟未对齐和不完整的多视图数据,先随机缺失部分数据,然后在每个客户端内随机打乱不完整多视图数据的完整部分。分别考虑三种情况:(a)部分未对齐(未对齐率为0.5)、(b)部分缺失(缺失率为0.5)、(c)部分未对齐和缺失(未对齐率和缺失率都为0.5)。实验结果如表1所示。
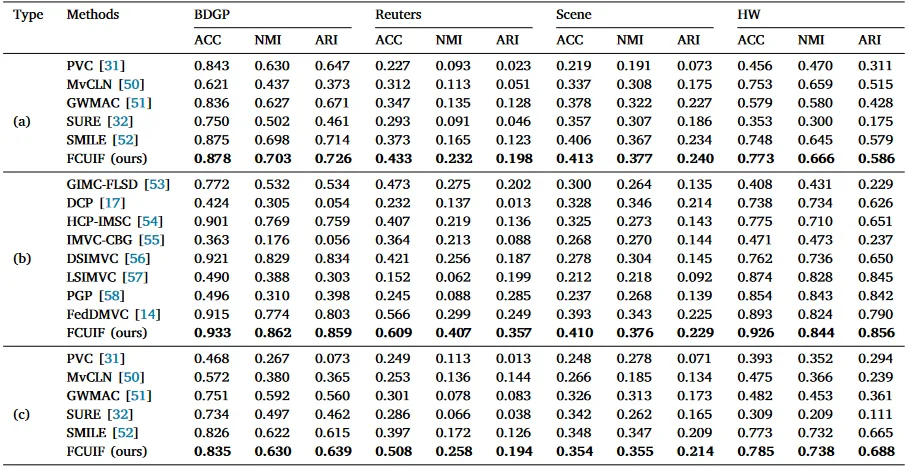
表1 三种未对齐且缺失情况下的实验结果
此外,为了测试自适应对齐模块和自适应插补模块的有效性,分别在对齐率和缺失率为0.1、0.3、0.5、0.7情况下进行实验,结果分别如图2和图3所示。表1、图2和图3的实验结果都证明了FCUIF方法能有效应对各种未对齐和缺失数据情景。
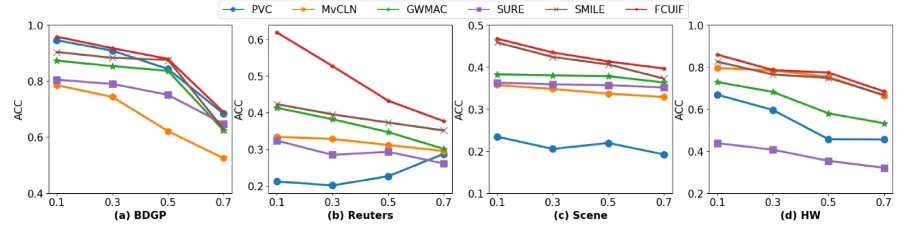
图2 不同未对齐率下的实验结果
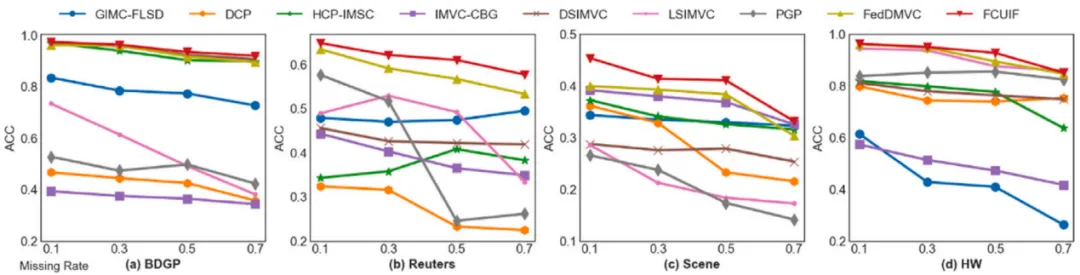
图3 不同缺失率下的实验结果
02
“Special Relativity” of Image Aesthetics Assessment: a Preliminary Empirical Perspective
作者:
谢睿†,明安龙†,∗,何帅†,肖毅,马华东
单位:
北京邮电大学
邮箱:
chenke771@bupt.edu.cn,
mal@bupt.edu.cn,
hs19951021@bupt.edu.cn,
xiaoyi123@bupt.edu.cn,
mhd@bupt.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681172
代码:
https://github.com/woshidandan/SR-IAA-image-aesthetics-and-quality-assessment
课题组主页:
http://www.mrobotit.cn/
发表会议:ACM MM 2024
†共同一作
*通讯作者
1.论文简介
图像美学评估(Image Aesthetic Assessment, IAA)旨在通过算法量化人类对图像美感的感知,是计算机视觉与计算美学领域的核心挑战之一。现代计算美学理论倾向于认为,人类对美的感知根植于对事物间普遍联系的分析与对比之中。例如,当个体面对一颗苹果时,其会自然而然地调动过往经验,将当前苹果与记忆中历次见过的苹果,进行快速的比较,从而迅速形成关于该苹果美感和口感的预判。这一过程虽往往潜移默化、瞬息完成,却深刻揭示了人类审美认知的运作机制,即审美是基于比较进行的。
反观当前将孤立的图像个体与单一标量评分直接对应的方式,一方面,显然忽视了审美过程中的比较过程,另一方面,忽视了比较的过程中需要对诸多美学因素进行考量。这一做法在逻辑上或许简洁明了,却难以全面捕捉并反映人类审美经验的丰富性与动态性,同时缺乏可解释性。
基于上述的分析,本文将对涉及IAA的三个核心点做出重新思考:
I.美学可以量化吗?美学作为一个高度抽象且内在因素多变的概念,其本质特征在于其主观性与非确定性:审美体验因人而异,且同一主体的审美偏好亦可能随时间流转而变迁。进一步而言,图像美学的评估过程常伴随机性因素,这使得以客观性与理性著称的传统科学方法的在美学量化中存在不足。因此,确定性若无法立足,量化美学似乎是不切实际的。
II. 美学量化的本质是什么?当前量化美学的实践主要聚焦于通过评分机制对图像进行量化处理,其目标有二:一是在整个样本空间中定位单个样本的位置(例如,在 0 到 10 分数区间的某一个分值);二是衡量不同样本间的美学差异,这种美学差异更具体的表现是美感在多因素上存在的差异。然而,现存的评分体系往往依赖于标量数值及其差异来量化美学,却忽视了审美判断中的非传递性特征,这一特征在数学逻辑中表现为不等式的非传递性悖论。具体而言,即便存在 A>B 且 B>C 的审美判断,亦不能直接推导出 A>C 的结论。
III. 如何进行美学量化?现有的标注方法显然不足以实现这一量化,因为它们混淆了量化的两个基本目的。为孤立图像分配一个确切的数值评分(如 0 至 10 的区间内),不仅考验着个体的主观判断能力,更因评分标准的模糊性而难以达成广泛共识。此外,将美学评分限定于固定范围的做法,在逻辑上亦显不妥,因为理论上总存在超越现有最高评分的可能,例如,即使是一个满分图像(10分),也总能遇到一个比其更美的图像,但却仍然只能是10分。从而质疑了评分体系的完备性。
鉴于上述分析,本文基于对比的思想,提出了美学相对性(Special Relativity of IAA,SR-IAA)法则。
2.理论和方法介绍
针对无激励环境下的审美主体:
I. 图像美学可以通过在给定时间内,一致且明确地确定两幅感知图像之间的相对偏好来量化。然而,这种美学上的不等式并不遵循数学中严格的传递性规律。 其中,时间跨度因个体神经元受到的充分刺激程度而异,进而影响其美学偏好的形成;同时,两幅图像在对比过程中,若时间跨度极短且并未产生额外刺激,则可视为两幅图像在美学上呈现相似性。此外,任何两幅图像的审美可比性都无法保证,例如人像类和自然风光类这两个主题则不一定满足可比性。
II. 量化图像美学的本质在于模拟人类的两种基本美学感知能力:无参考美学感知与有参考美学感知。前者聚焦于在“经验样本”构成的空间中,精确定位输入样本的美学位置(坐标);而后者则侧重于精确计算并比较两个输入样本之间的美学多因素差异。
III. 对于精准量化美学而言,无参考可以通过建立 N 个样本之间的成对相对关系来表示,而有参考的量化则涉及识别两个样本间,多个美学因素的差异。其中,N的值应足够大,样本集应在美学上均匀分布;同时美学多因素的选择,可根据个体的美学价值定义,或摄影的关键阶段来决定(例如第二章中所述的三个角色:相机、摄像者和浏览者)。
本文开发了一个多因素图像美学评估框架(MAINet,图1),作为SR-IAA在现有数据集上的初步验证,并在AADB、PARA和SPAQ多因素数据集上实现了当前最优性能。
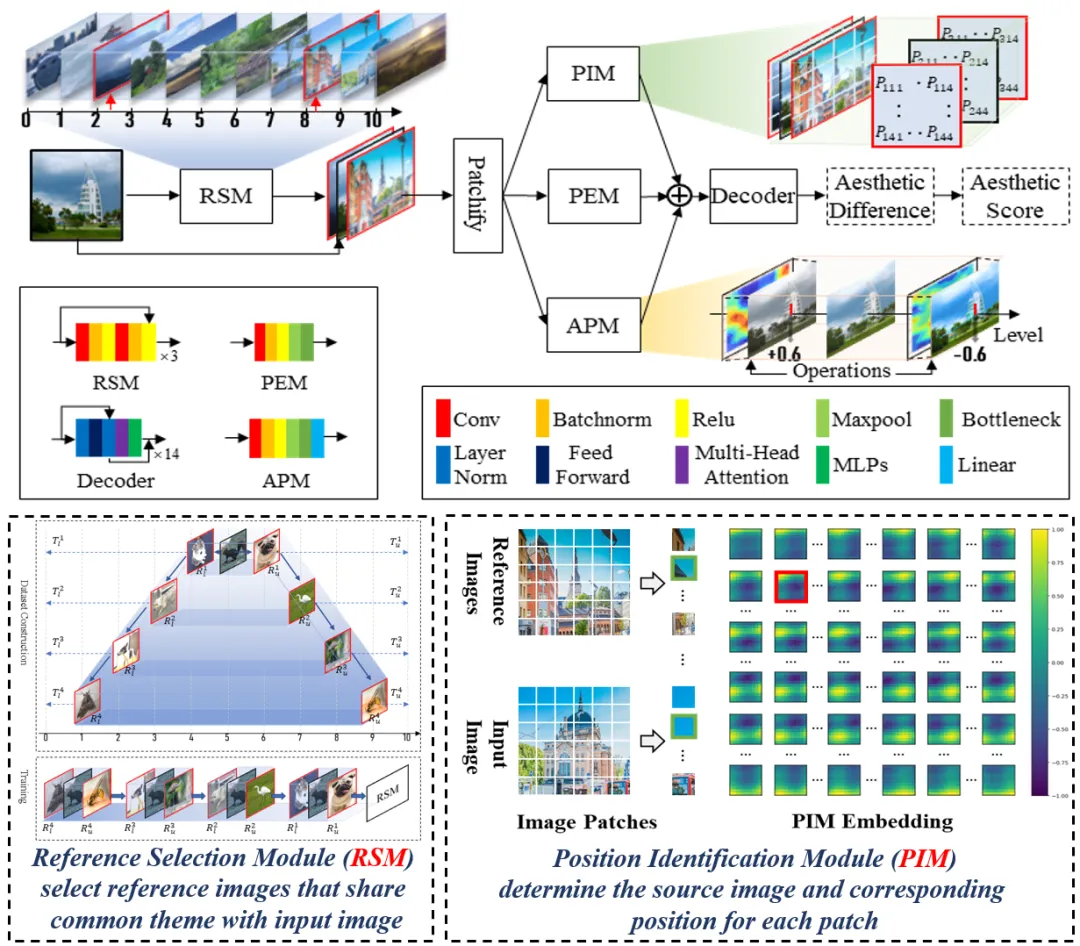
图1 HMAI的结构
3.实验结果
所述方法,在有监督的三个多因素数据集超越已有模型,并具备在无监督条件下完成IAA任务的能力,甚至超过部分有监督方法性能(表1)。同时,其评估过程基于多因素对比,具备较强的可解释性(图2)。
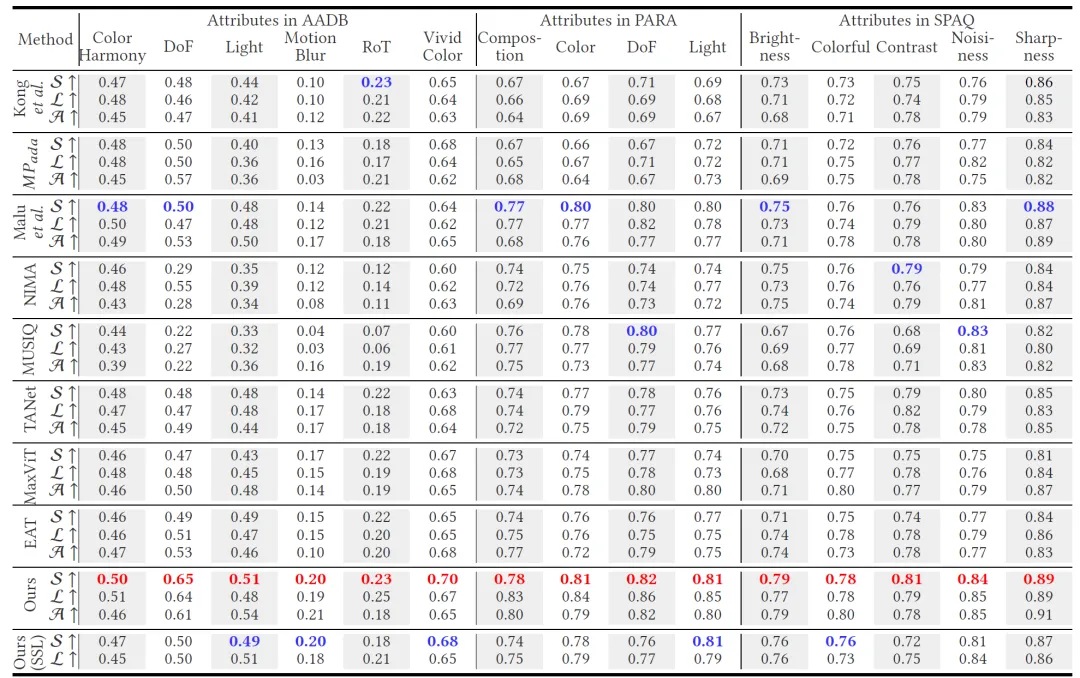
表1 多因素数据集的有监督和无监督性能
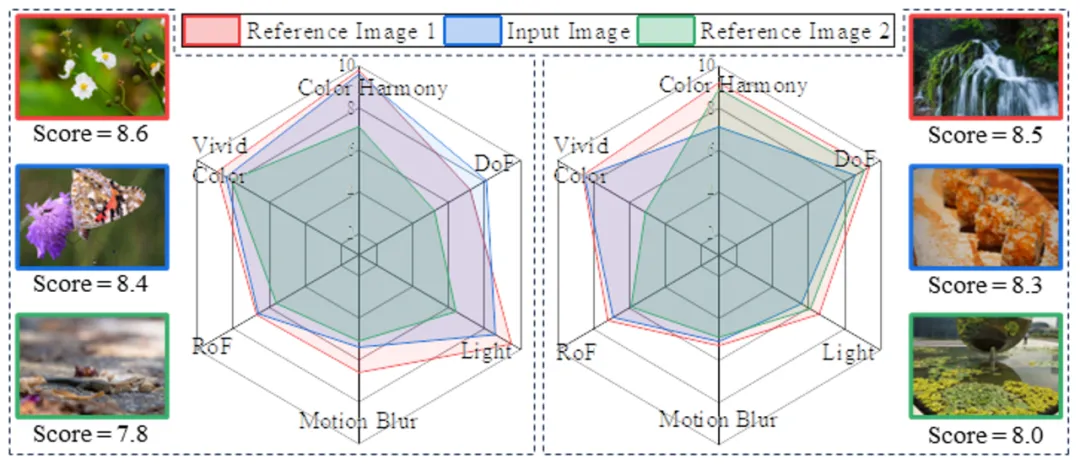
图2 基于多因素对比的评估实例
03
Attribute-Driven Multimodal Hierarchical Prompts for Image Aesthetic Quality Assessment
属性驱动的多模态分层提示用于图像美学质量评估
作者:
祝汉城1,时聚1,邵志文1,姚睿1,周勇1,赵佳琦1,李雷达2
单位:
1中国矿业大学,2西安电子科技大学
邮箱:
zhuhancheng@cumt.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681175
代码:
https://github.com/GitHub-Ju/AMHP
发表会议:ACM MM 2024
1.研究动机
近些年,由于能够学习丰富的语义信息,多模态学习方法在各种视觉领域得到了广泛的应用。大型预训练视觉语言模型,CLIP,已经获得了越来越多的关注,基于多模态提示学习的IAQA模型已经被提出。一种方法是直接从多模态学习中获得预训练模型,并在IAQA任务中对其进行微调;另一种方法是使用简单的质量提示来构建IAQA模型。尽管这些多模态学习方法在IAQA任务中表现出有希望的结果,但这些方法并未从根本上揭示影响用户对图像美学判断的关键因素。一般来说,用户对图像审美质量的判断可能是一个渐进的过程,可以分为两个阶段。例如,图 1 展示了 AVA 数据库中从社交媒体收集的两张图像,以及用户相应的审美评论和质量。从这张图中可以看出,用户首先通过文本注释来评价图像的审美属性,然后可以利用这些属性信息来显式地判断图像的审美质量。因此,要准确衡量图像的审美质量,需要设计上述两步提示来模拟用户对图像的审美判断过程。

图1 动机图
2.本文方法
在图2中,我们展示了所提出的AMHP模型,该模型由两部分组成,即多模态特征提取模块和分层提示学习模块。在第一部分,我们首先根据与图像审美属性相关的关键词(如颜色、光照、构图)获取属性注释,然后根据图像审美质量的不同层次,设计相应的文本模板进行审美判断。最后,我们利用CLIP模型中的图像编码器和文本编码器来提取上述多模态特征。在第二个部分中,我们首先利用属性注释的文本特征对图像特征进行提示学习,然后将它们融合以获得属性驱动的多模态特征。最后,进一步利用不同质量水平审美判断的文本模板特征对属性驱动的多模态特征进行提示学习。
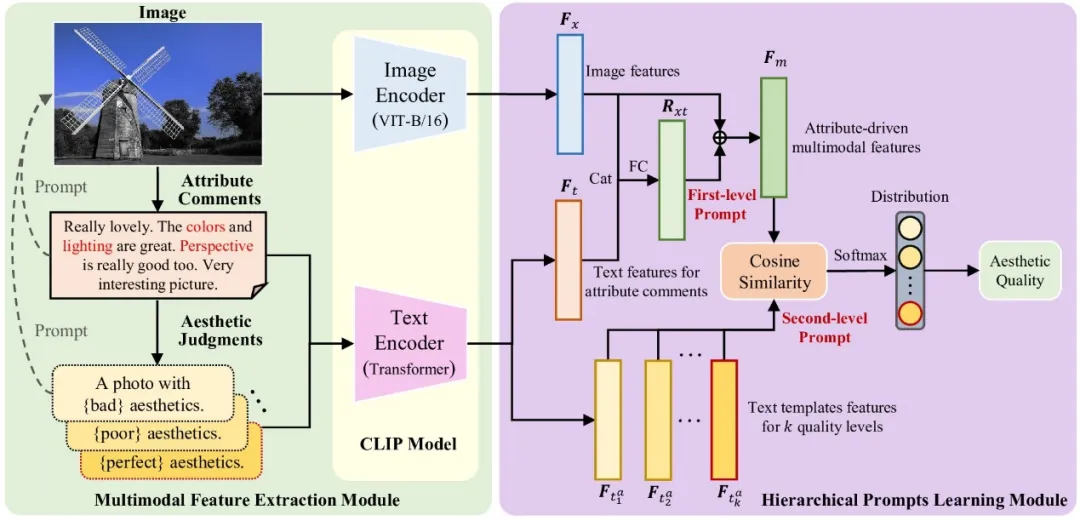
图2 方法图
3.实验结果
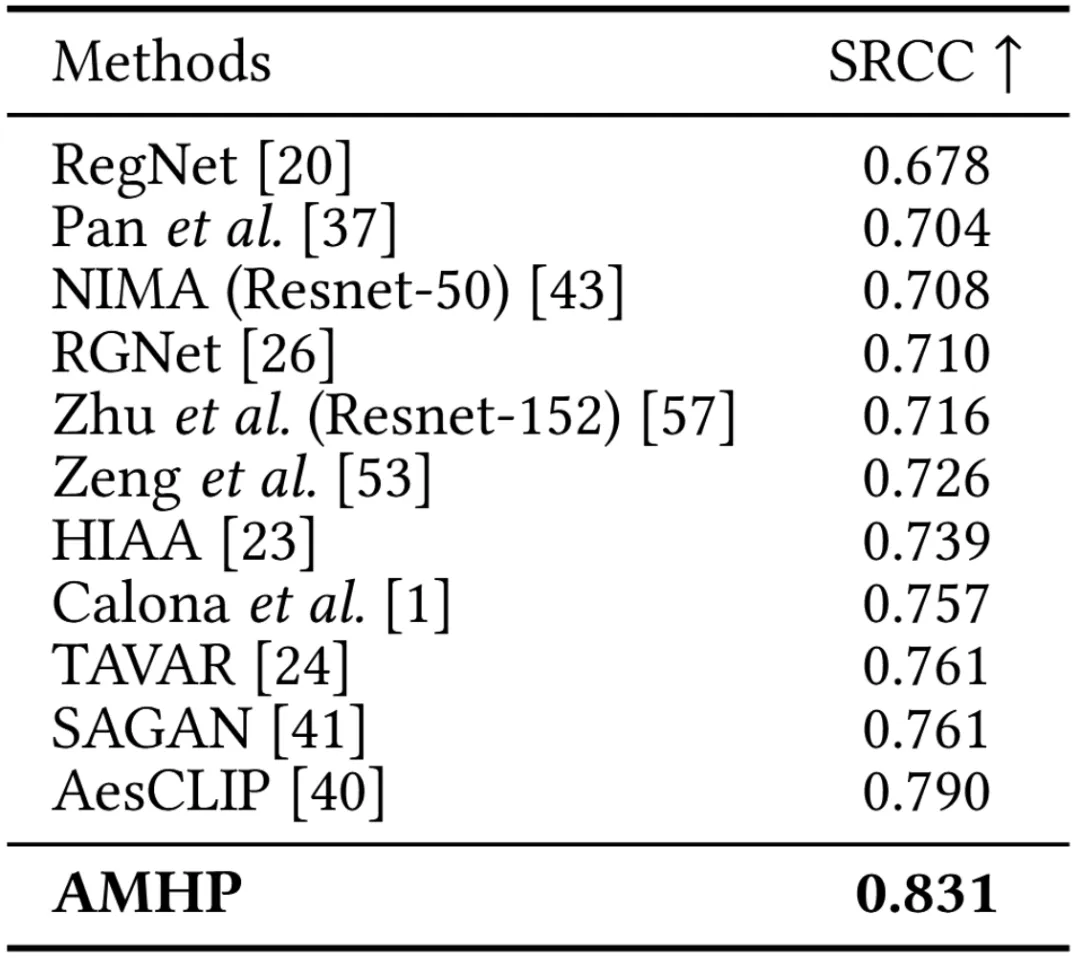
我们在AVA、PARA和AADB三个主流的IAQA数据集上进行了广泛的实验,由下面三张表可以看出,所提出的AMHP方法在所有的数据集上都超过了当前最优性能,这表明所提出的方法可以从属性评论中捕获更丰富的语义信息,可有效地辅助美学质量评价任务,同时也表明了所提出的属性驱动的分层提示学习策略可以通过模拟用户对图像的美学质量判断过程,来取得更优的性能。
表1 在AVA数据集上的性能对比
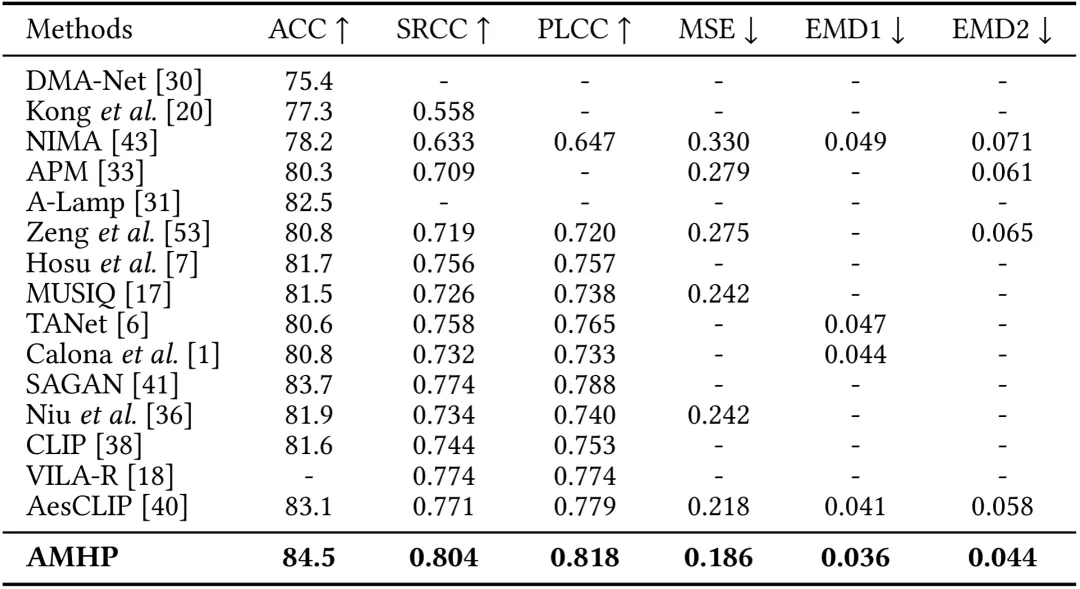
表2 在PARA数据集上的性能对比
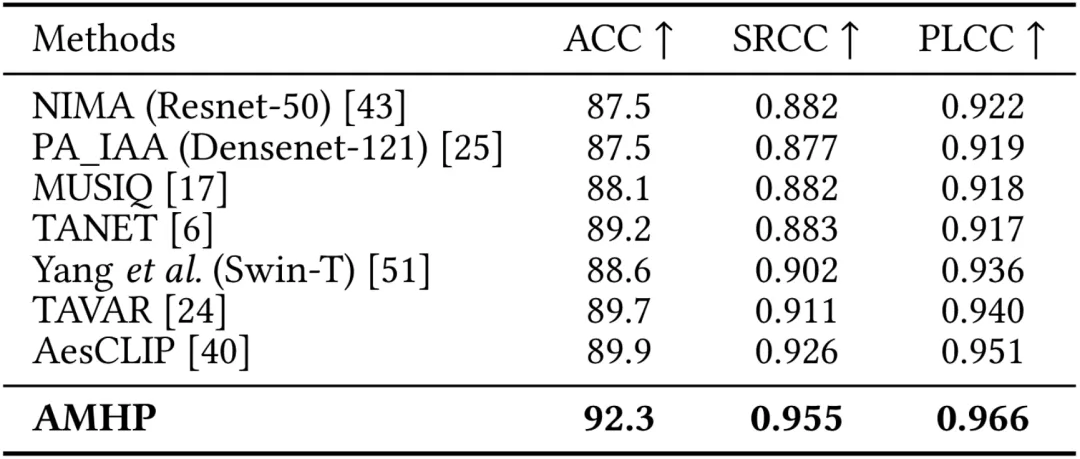
表3 在AADB数据集上的性能对比
04
Semantic-aware Representation Learning for Homography Estimation
作者:
刘雨涵,黄前鑫,惠思奇,付靖文,周三平,吴康翌,李鹏娜,王进军
单位:
西安交通大学人工智能与机器人研究所
邮箱:
liuyuhan200095@stu.xjtu.edu.cn,
huangqianxin@stu.xjtu.edu.cn,
huisiqi@stu.xjtu.edu.cn,
fu1371252069@stu.xjtu.edu.cn,
spzhou@xjtu.edu.cn,
wukangyi747600@stu.xjtu.edu.cn,
sauerfisch@stu.xjtu.edu.cn,
wangjinjun@gmail.com
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3681021
发表会议:
ACM MM 2024
1.研究背景与动机
单应性估计,通常称为透视变换或从源图像到目标图像的平面投影。本文主要采用特征匹配技术通过建立特征点之间的对应关系来解决这一问题。近年来,无检测器的特征匹配方法通过密集像素级匹配取得了显著进展,但这些方法通常忽略语义信息,导致匹配结果缺乏语义一致性。尽管已有研究尝试引入语义信息,但它们仅将语义作为预处理步骤,对语义先验的应用限制在粗粒度场景中,未能充分利用语义提取网络可以提供的知识。同时语义信息和匹配网络的固定交互方式导致在处理不同的任务时缺乏适应性和泛化性。针对这些问题,本文提出了一种新的语义感知表示学习框架SRMatcher,鼓励网络学习集成的语义特征表示,提升匹配的准确性和鲁棒性。
2.方法介绍
SRMatcher的核心创新在于其语义感知表示学习框架,包含两个关键模块:语义提取器(Semantic Extractor)和语义感知融合模块(Semantic-aware Fusion Block, SFB)。首先,语义提取器采用预训练的视觉基础模型DINOv2,从图像中提取丰富的细粒度语义特征。其次,SFB模块通过跨图像的语义特征融合,将语义信息动态整合到特征表示空间中。SFB中的语义引导交互模块(SGIB)通过自注意力与交叉注意力机制,实现图像特征与语义特征的多层次交互,确保匹配点具有语义一致性。SFB中同时提出了跨图像特征融合策略,即图像特征不仅要整合自身的语义信息,还要考虑跨图像的语义。此外,SRMatcher还设计了基于重叠的精细匹配策略,进一步提升亚像素级匹配精度。该方法不仅保留了无检测器匹配的优势,还通过语义感知显著减少了错误匹配。
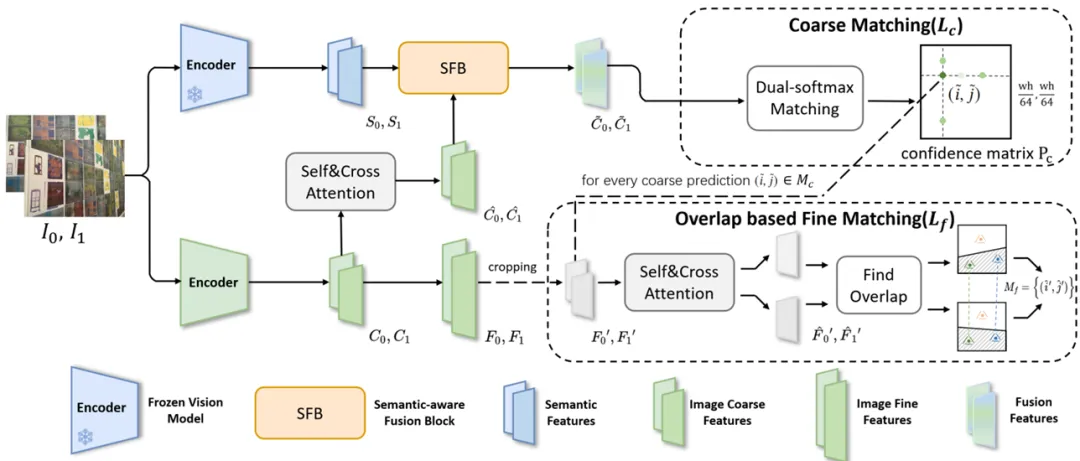
图1 整体框架图
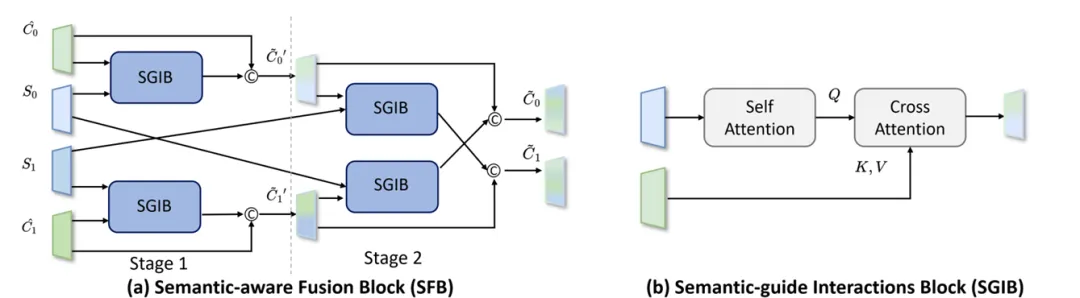
图2 语义感知融合模块(SFB)和语义引导交互模块(SGIB)
3.实验结果
本文在多个真实数据集上验证了SRMatcher的优越性。在HPatches数据集上,SRMatcher的AUC@1px达到49.2,较此前最优方法GeoFormer提升了11%。在具有挑战性的ISC-HE数据集(包含水印、裁剪等复杂编辑)上,SRMatcher同样表现最佳,证明了其对语义干扰的鲁棒性。消融实验表明,SFB模块和跨图像融合策略对性能提升至关重要,而DINOv2作为语义提取器的效果显著优于ResNet-50等替代方案。定性结果显示,SRMatcher生成的匹配点更具语义一致性,单应性变换结果更贴合真实场景。该框架还可作为即插即用的拓展方案,无缝适配LoFTR、ASpanFormer等主流匹配方法。
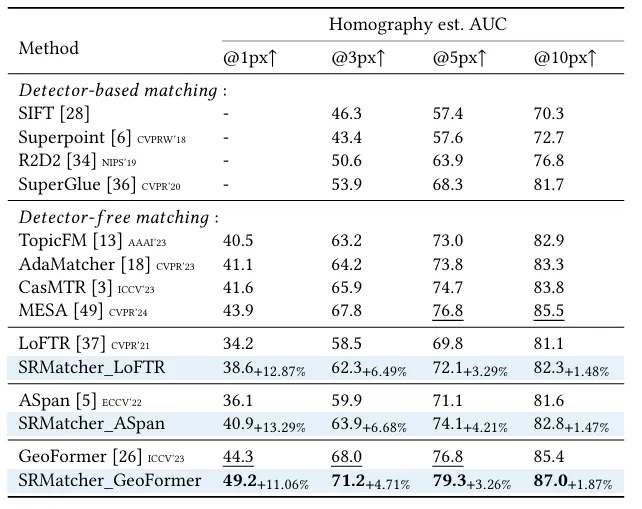
表1 HPatches数据集测试结果
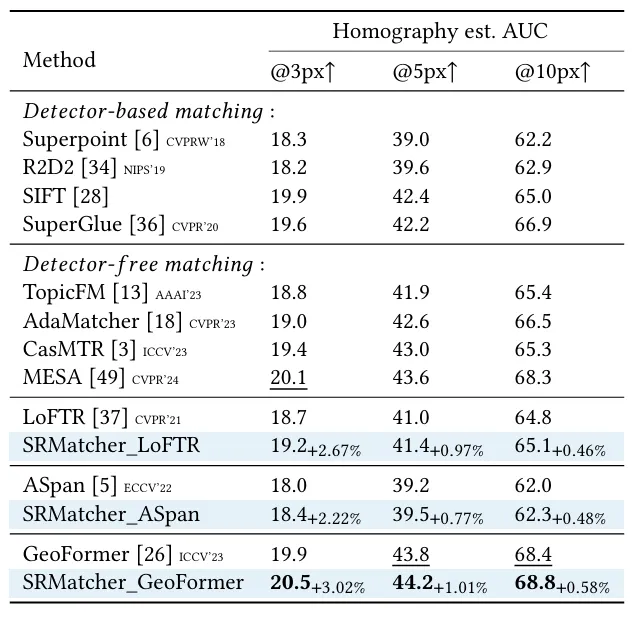
表2 ISC-HE数据集测试结果

图3 可视化结果
05
Joint Homophily and Heterophily Relational Knowledge Distillation for Efficient and Compact 3D Object Detection
联合同质性与异质性关系知识蒸馏的高效轻量 3D 目标检测
作者:
陈诗迪1∗ , 魏莉莉1∗,梁俪倩1,郎丛妍1†
单位:
1北京交通大学
邮箱:
shidichen@bjtu.edu.cn,
20112014@bjtu.edu.cn,
lqliang@bjtu.edu.cn,
cylang@bjtu.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3680656
发表会议:ACM MM 2024
*共同一作
†通讯作者
1.研究背景
3D 目标检测(3DOD)旨在从点云数据中精确定位和识别目标。相较于2D目标检测,点云数据提供了额外的深度信息, 对于机器人、自动驾驶以及增强现实等应用场景具有关键意义。然而,检测能力提高通常伴随着更高的计算成本。为平衡模型性能与计算效率,知识蒸馏作为一种关键的模型压缩方法,通过将复杂的大型模型的知识迁移至轻量化模型,从而提升轻量化模型的检测能力,同时降低计算开销。由于点云数据固有的稀疏性和结构复杂性特点,现有知识蒸馏方法的在3DOD中有效性受到限制。为了缓解上述问题,现有研究试图通过增强区域对之间的互信息来缩小教师模型与学生模型之间的表示差距。为了进一步迁移几何结构信息,部分研究则致力于蒸馏结构关系知识,通过KNN图来蒸馏局部几何结构,以保持邻域关系。然而,这类图的构建严重依赖同质性,导致学习过程聚焦于同类之间的关系学习,难以蒸馏多样化的结构关系。为此,本文提出了一种新颖的方法,称为联合同质性与异质性关系知识蒸馏方法(H2RKD),强调同时蒸馏相似性与差异性关系,从而更有效地模仿教师模型的结构知识。
2.方法介绍
H2RKD从两个层面建模并迁移关系知识:协同全局关系蒸馏模块(Collaborative Global Distillation, CGD)与分离局部关系蒸馏模块(Separate Local Distillation, SLD)。具体而言,CGD建模特征对之间的距离关系以及三元组之间的角度关系,从而隐式融合同质性与异质性于全局关系建模中。通过两种全局关系一致性损失,即距离关系知识蒸馏损失与角度关系知识蒸馏损失,有效提取点云中的长距离语义关联。为更好捕捉细粒度的动态局部关系,SLD将局部结构信息分别嵌入同质图与异质图中,并在动态图中编码和传播类内与类间关系。引入局部关系知识蒸馏损失,以实现从教师模型到学生模型的局部语义关系与几何结构的迁移。通过CGD与SLD的协同作用,学生模型能够全面学习教师模型中的关系知识,有效保留点云的结构关系,从而增强目标内部特征的一致性,并优化不同目标之间的区分能力。
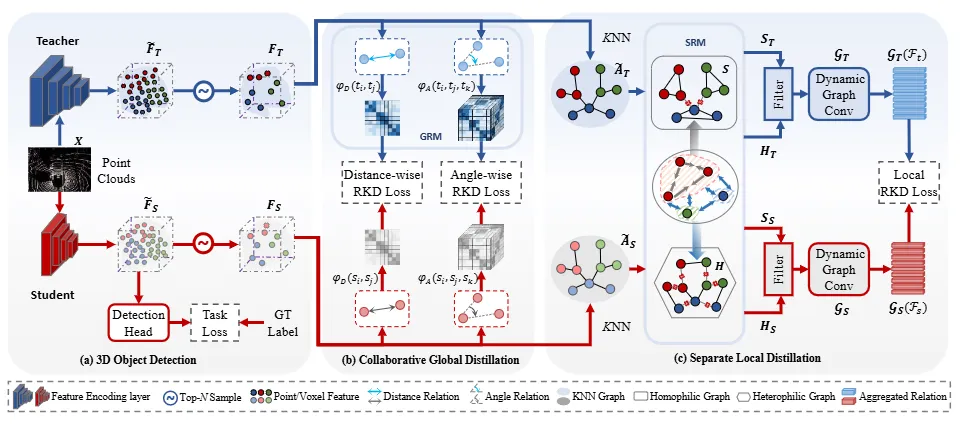
图1 联合同质性与异质性关系知识蒸馏方法(H2RKD)
3.实验结果
我们的实验在KITTI和nuScenes两个数据集上进行,分别在基于体素的目标检测器 PointPillars 与 CenterPoint,以及基于点的目标检测器 PointRCNN 上对所提出的方法进行了评估。实验结果表明,我们的方法能够有效地将教师模型的知识迁移至体素表示和点表示的学生检测器中。在实验中发现,H2RKD中的各个模块均具备独立的有效性,且其优势具有互补性。CGD模块在BEV检测任务中展现出更强的性能提升效果,而SLD模块则在3D检测任务中表现出更优的效果。结果也验证了本方法在提升检测性能的同时,具备高效轻量的三维目标检测器的能力。
表1 KITTI数据集的BEV检测和三维目标检测实验结果
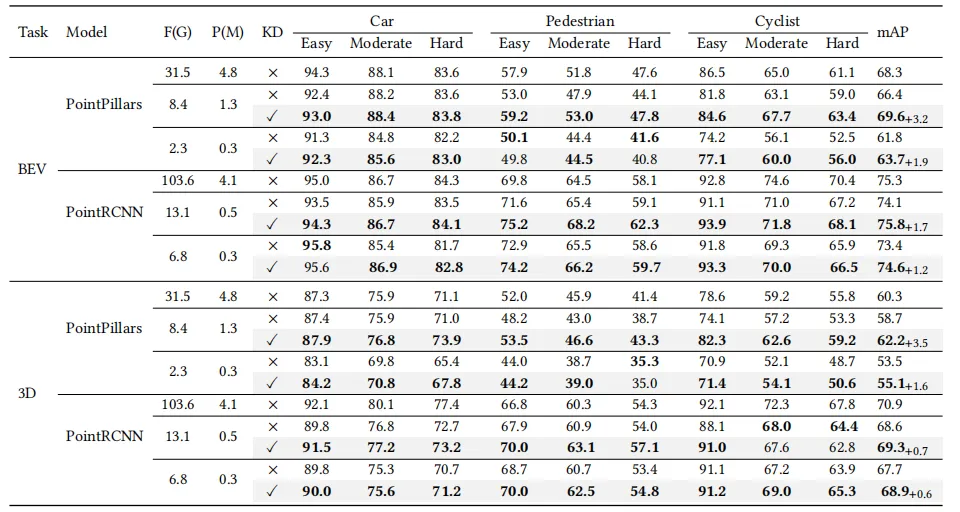
F表示模型的浮点运算量(GFLOPs),衡量计算复杂度;P 表示模型的参数量(百万级,M),反映模型规模;
KD表示是否使用了我们提出的知识蒸馏方法;mAP表示中等难度下的平均精度均值,衡量检测性能。
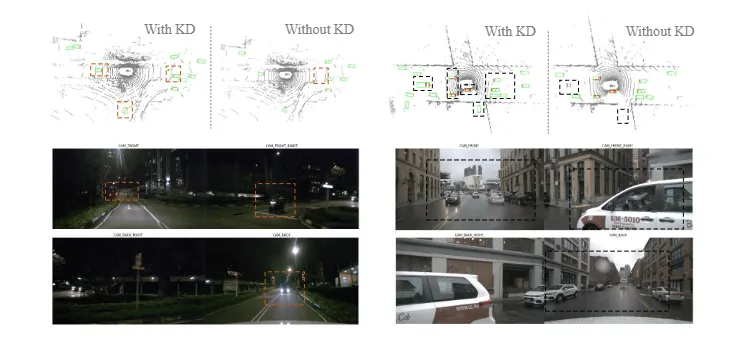
图2 nuScenes数据集上学生模型的检测对比结果

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号