
【论文导读】2025年论文导读第九期
【论文导读】2025年论文导读第九期
2025年05月27日 15:58 北京


论文导读
2025年论文导读第九期(总第一百二十六期)
目 录
|
1 |
Unifying Spike Perception and Prediction: A Compact Spike Representation Model Using Multi-scale Correlation |
|
2 |
Shape-Guided Clothing Warping for Virtual Try-On |
|
3 |
SCPSN: Spectral Clustering-based Pyramid Super-resolution Network for Hyperspectral Images |
|
4 |
Cross-View Contrastive Unification Guides Generative Pretraining for Molecular Property Prediction |
|
5 |
CP-Prompt: Composition-Based Cross-modal Prompting for Domain-Incremental Continual Learning |
01
Unifying Spike Perception and Prediction: A Compact Spike Representation Model Using Multi-scale Correlation
基于多尺度相关性紧凑脉冲表示模型的脉冲感知预测方法
作者:
冯柯翔1, 2,贾川民3,马思伟3,高文3
单位:
中国科学院大学1,中国科学院计算技术研究所2,北京大学3
邮箱:
fengkexiang21@mails.ucas.ac.cn,
cmjia@pku.edu.cn,
swma@pku.edu.cn,
wgao@pku.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681448
代码:
https://github.com/Lucas-Von/MSTAU
发表会议:
ACM MM2024
1.论文简介
生物启发式摄像头的广泛应用推动了基于脉冲的智能视觉技术的发展,但脉冲信号的复杂性带来了处理挑战。本文分析了脉冲信号在不同时间尺度下的时空相关性,并提出了一种新的脉冲处理方法。该方法利用尺度内相关性提升预测精度,同时引入多尺度时空聚合单元(MSTAU),进一步利用尺度间相关性以实现高效感知与精准预测。实验结果表明,该方法在场景重建与目标分类任务上均取得了显著提升,且该方法可通过切换分析模型适应不同视觉应用,为脉冲信号处理提供了新的视角。
2.研究背景
脉冲摄像头采用异步脉冲发射机制,实现40k FPS视觉信号捕获,提升高速场景下的视觉感知与实时处理能力。然而脉冲信号的稀疏性和非均匀时间分布限制了传统视觉方法的适用性,难以兼顾多任务感知与时空预测。本文提出多尺度时空聚集单元,融合尺度内和尺度间相关性,实现高效感知与精准预测。实验表明,该方法显著提升了感知与预测精度,并在不同视觉任务中展现优异适应性与高效性。
3.方法概述
本文提出的多尺度时空聚集单元包含时域回归模块、时空聚集模块和时空互注入模块,如图1所示。通过层级堆叠,实现高效感知与精准预测。
1)时域回归模块:利用各尺度的时间相关性,回归历史状态至当前时刻,并生成多个回归结果。该模块计算上层单元历史与当前时刻的空间状态相似性,以指导各尺度的时域状态回归,从而得到各尺度的时域状态子估计。
2)时空聚集模块:将不同尺度的空间相关性映射至时间状态。该模块计算当前时刻上层单元各尺度的空域状态与当前尺度空域状态的相关性,以聚合各尺度的时域状态子估计。随后将聚合后的时域状态估计与前一时刻当前尺度的时域状态融合,生成更精准的时域状态联合估计。
3)时空互注入模块:确保时空状态传播过程中的一致性。受双门控机制启发,该模块引入两个门控单元,分别计算注入比率,以引导时空信息的双向交互,从而增强时空特征表达能力,提高预测的稳定性与准确性。
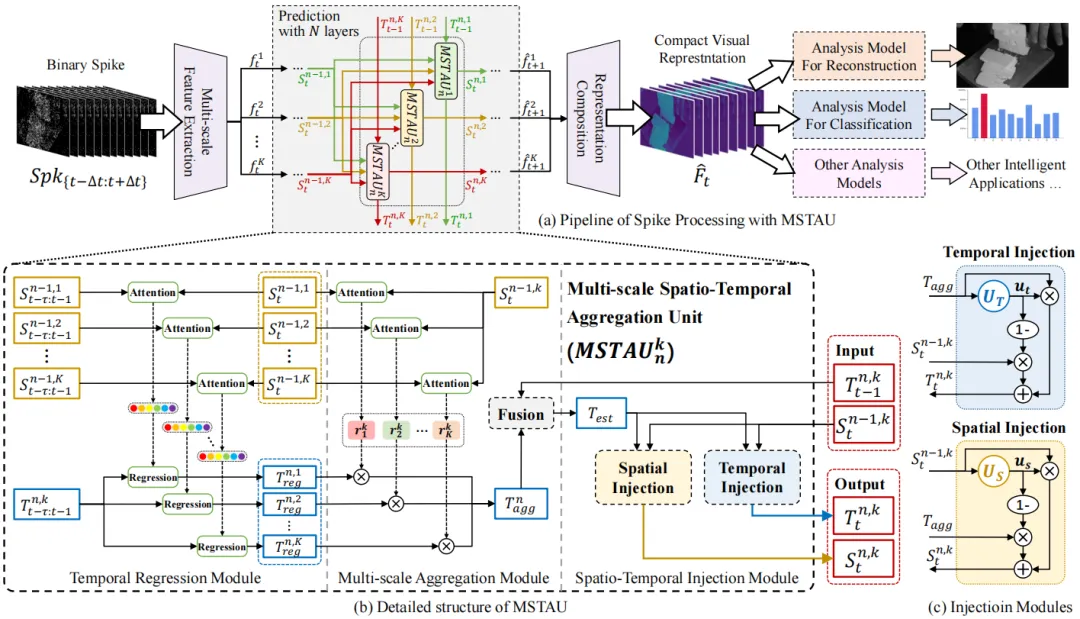
图1 多尺度时空聚集单元
4.实验结果
1)场景重建:引入尺度间相关性后,各尺度特征序列的预测准确率分别提升 4.9%、7.5%、8.6% 和 7.0%。由于不同尺度的时空特性存在差异,内容相关性随时间降低,导致基于先验知识的时间估计失真,削弱准确性提升幅度。图2中的可视化结果表明,该方法在短期预测中生成更高质量画面。随预测间隔延长,重建质量下降,表现为局部对比度过高和明暗网格效应,源于尺度间特征相关性减弱,导致内容不一致与错位。
2)目标分类:引入尺度间相关性后,S-MNIST、S-CIFAR 和 S-CALTECH 数据集的分类准确率分别提升 0.70%、2.20% 和 1.47%,表明跨尺度相关性可增强视觉表示的语义保真度,支持脉冲智能感知与理解任务。图 3 展示了重建与分类网络的预测结果,尽管随预测时间间隔增加,重建失真加剧,分类准确率仍保持较高水平,表明不同语义层次的视觉任务对时间变化的敏感度不同,证明该方法可适配不同分析模型,以满足智能应用对粒度与精度的需求。

图2 重建场景预测结果的可视化对比
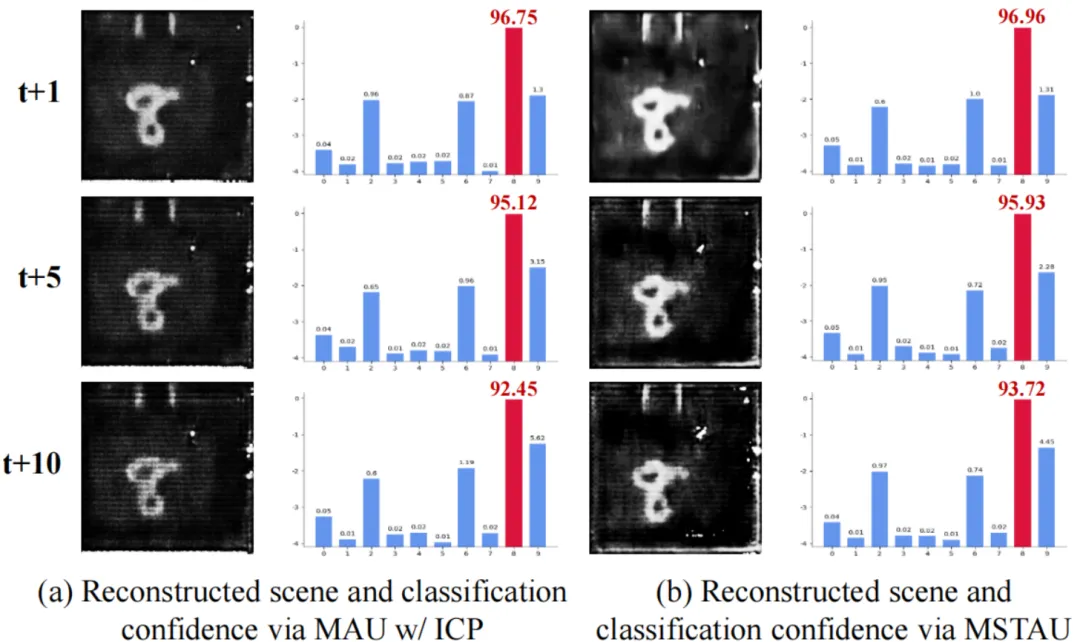
图3 多尺度时空聚集单元面向场景重建和目标分类的鲁棒性测试结果
02
Shape-Guided Clothing Warping for Virtual Try-On
作者:
韩潇宇,郑顺源,李宗霖,王晨阳,孙鑫,孟权令
单位:
哈尔滨工业大学
邮箱:
xyhan@stu.hit.edu.cn,
sawyer0503@hit.edu.cn,
zonglin.li@hit.edu.cn,
c.wang@stu.hit.edu.cn,
sunxintyc@hit.edu.cn,
quanling.meng@hit.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3680756
代码:
https://github.com/xyhanHIT/SCW-VTON
发表会议:ACM MM 2024
1.论文简介
基于图像的虚拟试穿技术旨在实现目标服装与人物图像之间的几何对齐和视觉融合,同时严格保持人体姿态一致性。尽管现有方法在整体试穿效果上取得了一定进展,但在细节控制方面仍存在不足,常出现服装与人体形状不匹配、肢体区域纹理失真等问题。为应对上述挑战,我们提出了一种形状引导的服装形变方法——SCW-VTON。该方法通过引入全局形状约束与肢体纹理信息增强,提升了目标服装形变后的真实感与试穿结果的一致性。实验结果在多个评估指标上表现优异,充分验证了SCW-VTON在服装形变匹配和细节保真方面的优势。
2.方法概述
如图1所示,SCW-VTON由三个模块组成:双分支服装形变模块(DCW)、布局估计模块(SLE)和试穿合成模块(LTS)。其中,双分支服装形变模块用于预测与人体对齐后的目标服装形变结果及其对应的服装掩膜,布局估计模块用于估计目标服装条件下的人体解析结果,而试穿合成模块则基于上述信息,利用扩散模型生成最终的试穿图像。
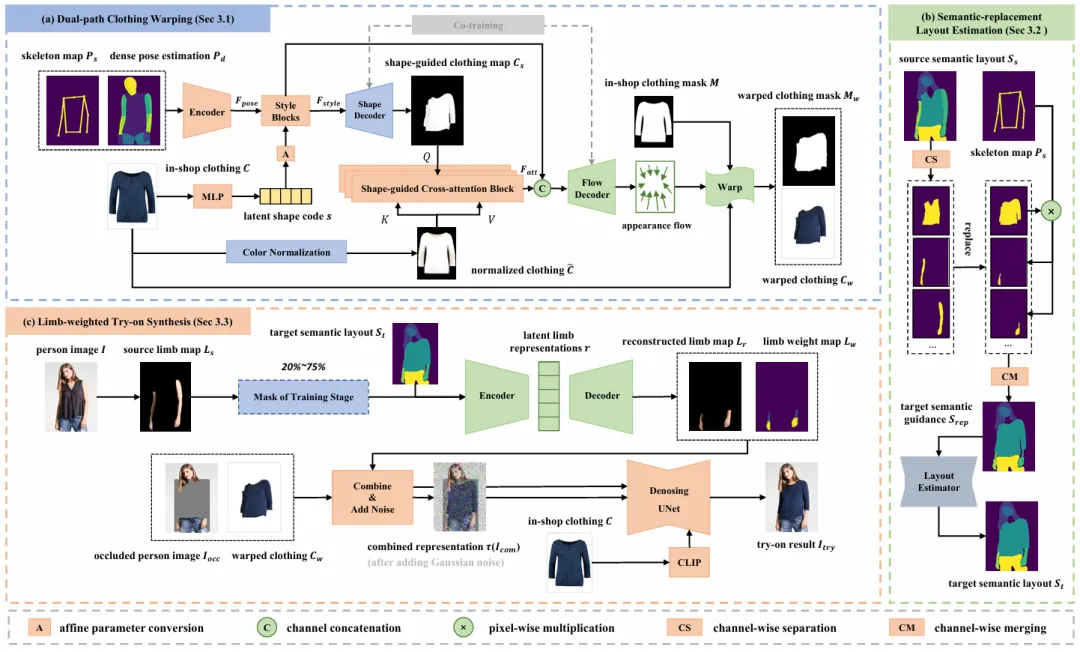
图1 SCW-VTON整体框架图
具体而言,双分支服装形变模块(DCW)包括一个形状分支和一个流分支。形状分支首先预测目标服装的整体形状,并通过一组基于形状引导的交叉注意力模块,捕捉服装形变前后之间的形状映射关系。其结果随后作为全局形状约束注入流分支,用于指导外观流的估计。所得到的外观流将作用于目标服装图像上,以生成与人体对齐的形变结果。此外,两个分支在训练过程中采用联合训练策略,以进一步提升稳定性与精度。在试穿合成阶段,为缓解肢体区域的失真问题,我们提出了一个基于掩码图像建模(MIM)的肢体重建网络。该网络首先从人物图像中提取肢体纹理,并将掩码处理后的结果输入自动编码器,以学习其潜在表征,并据此在指定位置重建肢体纹理。最终,我们将外观流作用下的目标服装与重建的肢体纹理一同输入扩散模型,生成在姿态保持一致的同时,细节纹理自然逼真的虚拟试穿结果。
3.实验结果
图2展示了在VITON数据集上的定性对比结果。一方面,现有大多数方法在处理纹理密集或结构复杂的服装时表现不佳,常出现logo区域纹理扭曲或模糊不清的现象(图2左侧)。相比之下,得益于所提出的形状约束机制,SCW-VTON能够更好地保持服装整体形状与人体姿态的一致性,从而呈现出更加真实自然的视觉效果。另一方面,在人物姿态复杂,尤其存在肢体遮挡的情况下,现有方法容易生成不自然的肢体区域,或无法保持纹理的连续性(图2右侧)。相对而言,SCW-VTON在肢体区域呈现出更合理的结构与细节表现,这得益于我们在服装形状匹配与肢体纹理增强方面的联合构建。

图2 在VITON数据集上的定性结果
图3展示了在VITON-HD数据集上的定性对比结果。与前述分析一致,多数现有方法难以在保持服装结构完整性的同时实现与人体的准确对齐。例如,在图3左侧第一个样例中,大多数方法未能准确估计腰带位置,甚至在服装形变过程中出现纹理丢失的问题。相比之下,SCW-VTON不仅完整保留了腰带结构,还能根据人物姿态将其自然地形变至合理位置。这些结果表明,在较高分辨率设定下,SCW-VTON依然展现出稳定且优越的性能表现。更多定性结果见图4。

图3 在VITON-HD数据集上的定性结果

图4 更多定性结果展示
最后,表1展示了在VITON和VITON-HD数据集上的定量对比结果。为实现更全面的评估,我们分别对服装形变结果与最终试穿图像计算了相关指标。结果表明,无论在服装形变阶段,还是在试穿合成阶段,SCW-VTON相较于现有方法均取得了更优的性能表现,进一步验证了其在精度与一致性方面的优势。
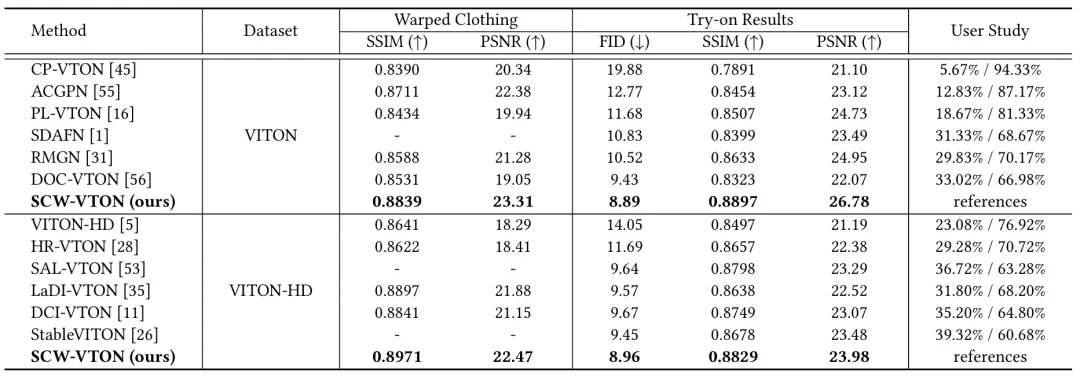
表1 在VITON和VITON-HD数据集上的定量结果
03
SCPSN: Spectral Clustering-based Pyramid Super-resolution Network for Hyperspectral Images
作者:
杨勇,赵敖琦,黄淑英*,王晓争,范雅静
单位:
天津工业大学
邮箱:
greatyangy@126.com,
aoqizhao927@163.com,
huangshuying@tiangong.edu.cn,
xiaozhengwang95@gmail.com,
fyj15037232663@163.com
论文:
https://doi.org/10.1145/3664647.3681687
代码:
https://github.com/ZAQ9271219/SCPSN
发表会议:ACM MM 2024
*通讯作者
1.引言
单幅高光谱图像(HSI)超分辨率任务旨在不借助其它的参考图像将观测到的低分辨率高光谱图像(LRHSI)重建成高分辨率高光谱图像。目前大多数方法直接提取LRHSI中各通道的特征进行图像重建,但没有考虑相邻波段冗余信息的干扰。导致重建结果出现光谱和空间畸变,增加了模型的计算复杂度。为了解决这一问题,我们提出的方法在光谱通道内筛选出超通道进行重构,大大降低了模型复杂度。
2.方法概述
如图1所示,我们设计了基于光谱聚类的金字塔超分辨率网络(SCPSN),它通过构建不同尺度的图像重建层来逐步实现图像重建。在每个图像重建层中,构建一个聚类超分辨率模块(CSRB)和一个残差块,以生成当前层的重建图像。CSRB由光谱聚类模块(SCB),块非局部注意模块(PNAB)和动态融合模块(DFB)组成,旨在实现细节特征的重建。在CSRB中,SCB用于实现光谱通道的聚类和超通道的筛选,以减少冗余光谱信息的干扰和模型的计算复杂度。图2展示了PNAB模块的结构,PNAB的提出是为了利用超通道内特征的非局部相似性重建具有更多细节特征的超通道。图3展示了DFB模块的结构,DFB的设计目的是为LRHSI中的每个通道动态选择最相关的超通道进行融合,从而重建LRHSI的所有通道。
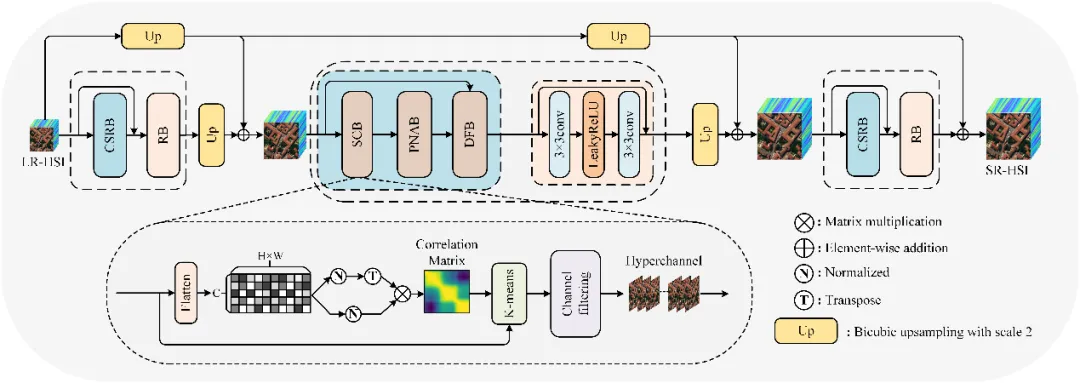
图1 4倍超分尺度下的 SCPSN 框架
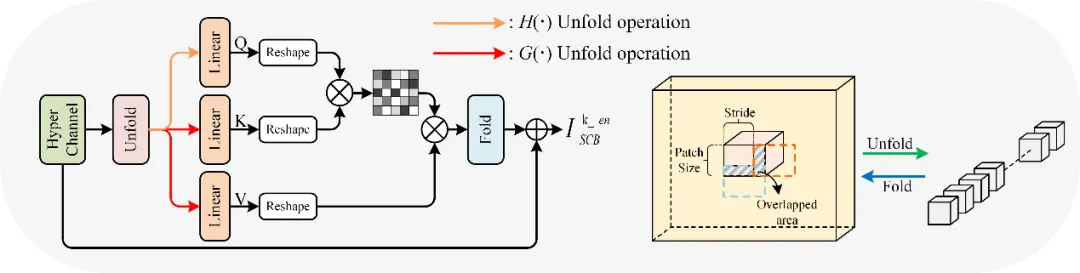
图2 PNAB模块结构
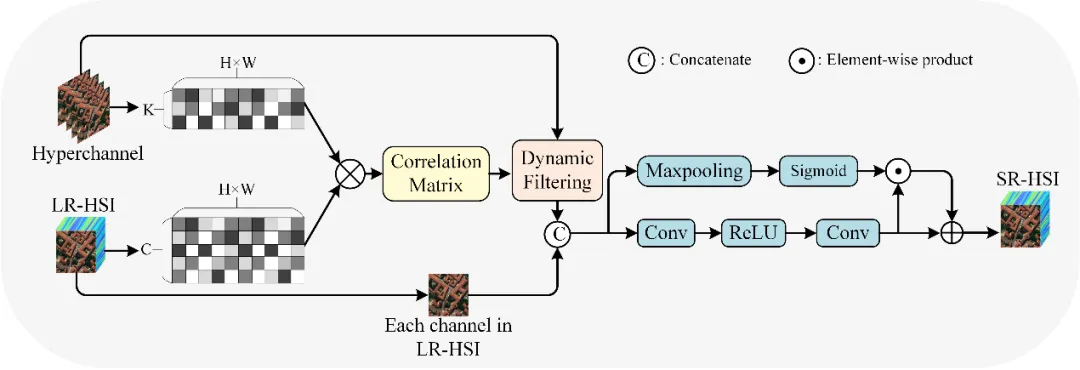
图3 DFB模块结构
3.实验结果
表1展示了在Pavia University和Botswana数据集上的测量指标。从表中可以看出,本文提出的SCPSN在三个超分尺度因子的所有指标上都优于其他方法,这也证明了我们模型的有效性。与三个数据集上的次优结果相比,我们的方法在尺度因子为8的情况下,PSNR值分别提高了0.25dB和0.84dB。其中,ERGAS能够客观地反映高光谱图像的空间质量,而SAM能够测量光谱失真的程度。与其他方法相比,我们提出的SCPSN获得了更好的ERGAS和SAM值。图4显示了不同方法在Pavia University数据集上获得的尺度因子为4的超分结果的可视化。从图中可以清楚地看到,我们的结果边缘更清晰,颜色更接近GT图像,说明我们的方法重建了更多的空间细节和光谱信息。
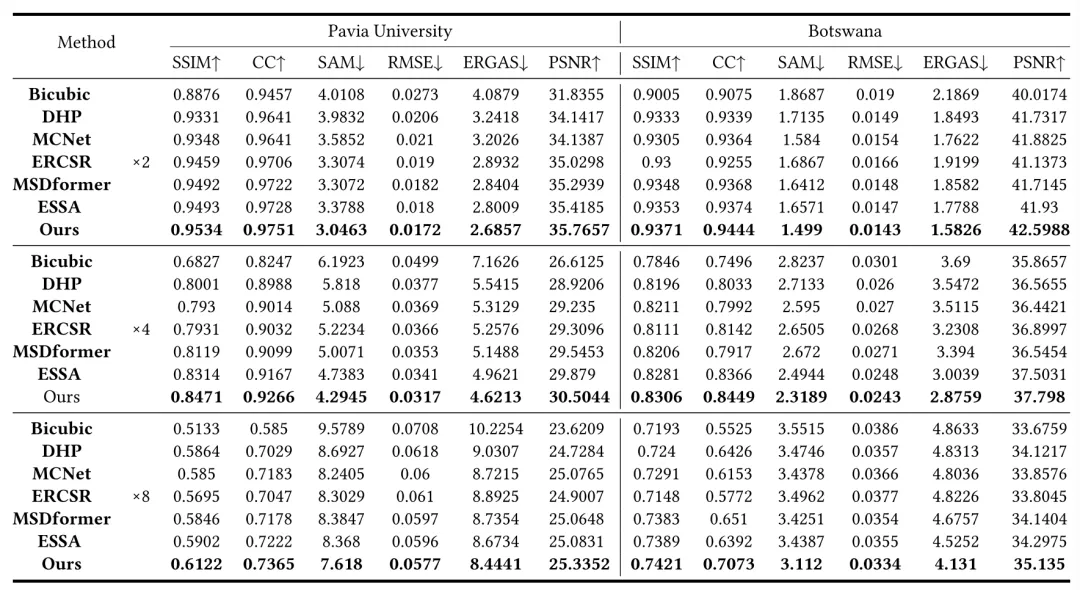
表1 不同方法在Pavia University和Botswana数据集上的定量比较。最好的结果以粗体突出显示

图4 来自Pavia University数据集的4倍超分结果的视觉比较
04
Cross-View Contrastive Unification Guides Generative Pretraining for Molecular Property Prediction
作者:
林俊宇2,郑妍1,陈新越1,任亚洲1,2,蒲晓容1,2,何静3
单位:
1电子科技大学(深圳)高等研究院
2电子科技大学计算机科学与工程学院
3Faculty of Medicine Biomedical Sciences, The University of Queensland
邮箱:
linjunyuxx@gmail.com,
yan9zheng9@gmail.com,
martinachen2580@gmail.com,
yazhou.ren@uestc.edu.cn,
puxiaor@uestc.edu.cn,
Jing.he@uq.edu.au
论文:
https://dl.acm.org/doi/10.1145/3664647.3681193
发表会议:
ACM MM 2024
1.背景与动机
在计算机辅助药物发现和开发领域,分子性质预测起着至关重要的作用。有效学习和整合不同表达形式的分子对于构建准确和全面的分子特征至关重要。在探索多视图分子性质预测方法的局限性时,存在以下问题:(1)忽视视角特异性和信息过滤。较少的研究集中于同时提取分子的多个视图的公共信息和视图特定的私有信息,这可能导致不能充分利用视图之间的互补性以及有效地过滤掉无关的噪声。不同的视图可能包含自己独特的生物或化学信号,这些信号对特定属性的预测至关重要,简单地合并视图可能会压倒这些信号,导致模型受到不相关或误导性信息的影响。(2)过度依赖全局对比和重建。目前的方法通常侧重于在图级表示上实现对比学习和相互重建策略,强调全局尺度特征对齐和跨模态信息的一致匹配。这种方法本质上是假设不同视图下的全局信息可以直接对应,在高层次抽象上执行相似性推理。在这种方法中,局部细节可能被忽略。
我们提出了一种新的跨视图对比统一指导生成式分子预训练模型MolCVG。本文首先从分子的二维图形视图和三维几何视图中提取公共信息和私有信息,最大限度地减少私有信息中的噪声对后续策略的影响。为了更精细地利用这两类信息,提出了一种跨视图对比统一策略,学习跨视图全局信息,指导屏蔽节点的重构,从而有效地优化全局特征和局部描述。
2.方法概述
MolCVG利用跨视图学习来指导图形自动编码器进行生成预训练。其概要如图1所示,我们考虑分子的2D拓扑视图和3D几何视图。这两个视图提供了平面化学结构的信息和分子的3D空间信息。MolCVG在随机掩蔽节点之后通过编码器对这两个视图进行编码。然后,我们提出了公共和私人信息分离策略,专门学习和分离不同分子视图的公共和私有信息。弱化不同视图间共同信息与私人信息间的相互依赖关系,以解决问题(1)。此外,分子表示是由MolCVG通过图自动编码器策略学习。与以前的工作不同,我们提出了跨视图对比统一来指导掩码节点的重建,以解决问题(2)。通过深入挖掘和融合视图的核心公共特征,不仅有助于更准确地重构节点特征,而且有效地防止了视图特定信息对跨视图融合过程的潜在误导。
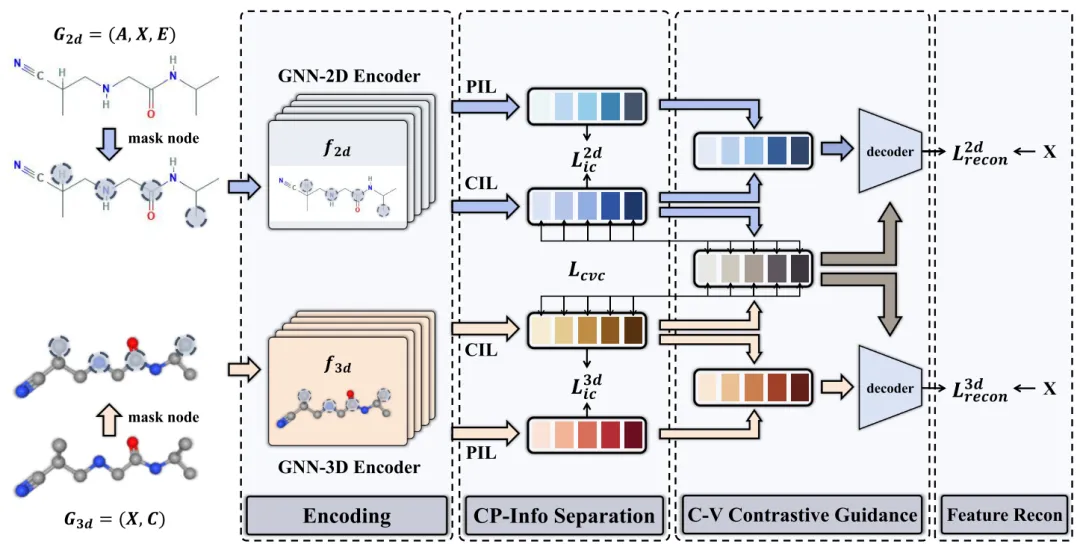
图1 MolCVG的总体概述。
3.实验结果
如下表1所示,总结了8个分子性质预测比较方法的性能。实验结果表明,该模型在所有8个下游任务集上都表现出了良好的性能,与现有方法相比,平均性能至少提高了1.9%。实验验证了该算法的优越性。与单视图分子性质预测的基线相比,MolCVG优于几乎所有基线。平均获得2.3%的绝对改善。单视图分子性质预测方法强调对单视图的深度挖掘和学习,它无法利用多视角互补信息。MolCVG具有很好的隐藏表示学习能力,可以有效地处理分子性质预测任务下的多视图信息的协调。与多视角分子性质预测基线相比,MolCVG也优于几乎所有的多视角MPP基线,获得了1.9%的总体平均改善。GraphMVP和3D Infomax都利用2D和3D视图进行自监督方法,MolCVG均胜过两种算法。这与我们的动机相一致,即基于多视图信息可以一对一匹配的假设,在全局对比度和重建中存在性能瓶颈,这可能会忽略重要的局部细节。
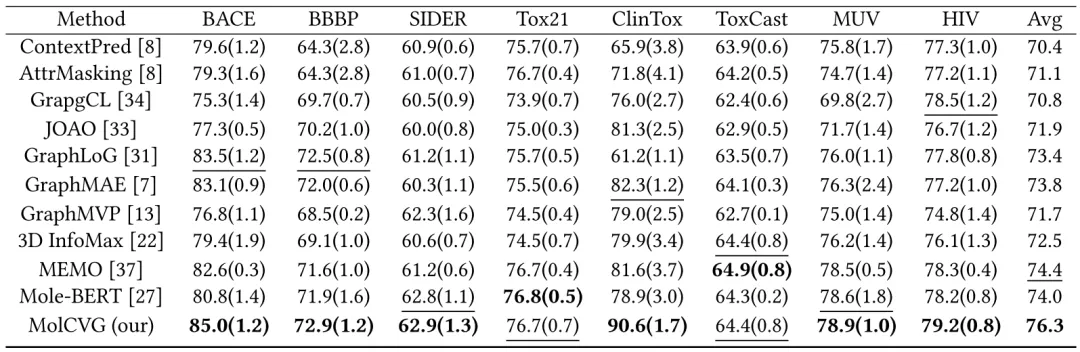
表1 在MoleculeNet基准上的八个分子性质预测任务的比较
05
CP-Prompt: Composition-Based Cross-modal Prompting for Domain-Incremental Continual Learning
作者:
冯煜、田震、朱一凡、韩宗甫、罗浩然、张光卫、宋美娜
单位:
北京邮电大学
邮箱:
fydannis@bupt.edu.cn,
tianzhentz@bupt.edu.cn,
yifan_zhu@bupt.edu.cn,
michan325@bupt.edu.cn,
luohaoran@bupt.edu.cn,
gwzhang@bupt.edu.cn,
mnsong@bupt.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681481
代码:
https://github.com/dannis97500/CP_Prompt
发表会议:ACM MM 2024
1.引言
在数字化转型纵深推进的当下,边缘计算节点已从单纯的数据采集终端演进为具备自主决策能力的智能单元。然而,边缘设备数量不断的增加和数据分布的高度异构多样化,每个边缘侧呈现新的和潜在的信息,例如分布漂移问题,重新训练模型是不现实的。导致边侧模型面临严峻挑战:如何在资源受限的边缘侧实现跨领域数据的持续学习与自适应优化?这一问题的核心在于域增量学习(Domain Incremental Learning, DIL)技术——一种能够在分布差异显著的连续领域中逐步学习新知识,同时避免遗忘旧领域能力的任务范式。
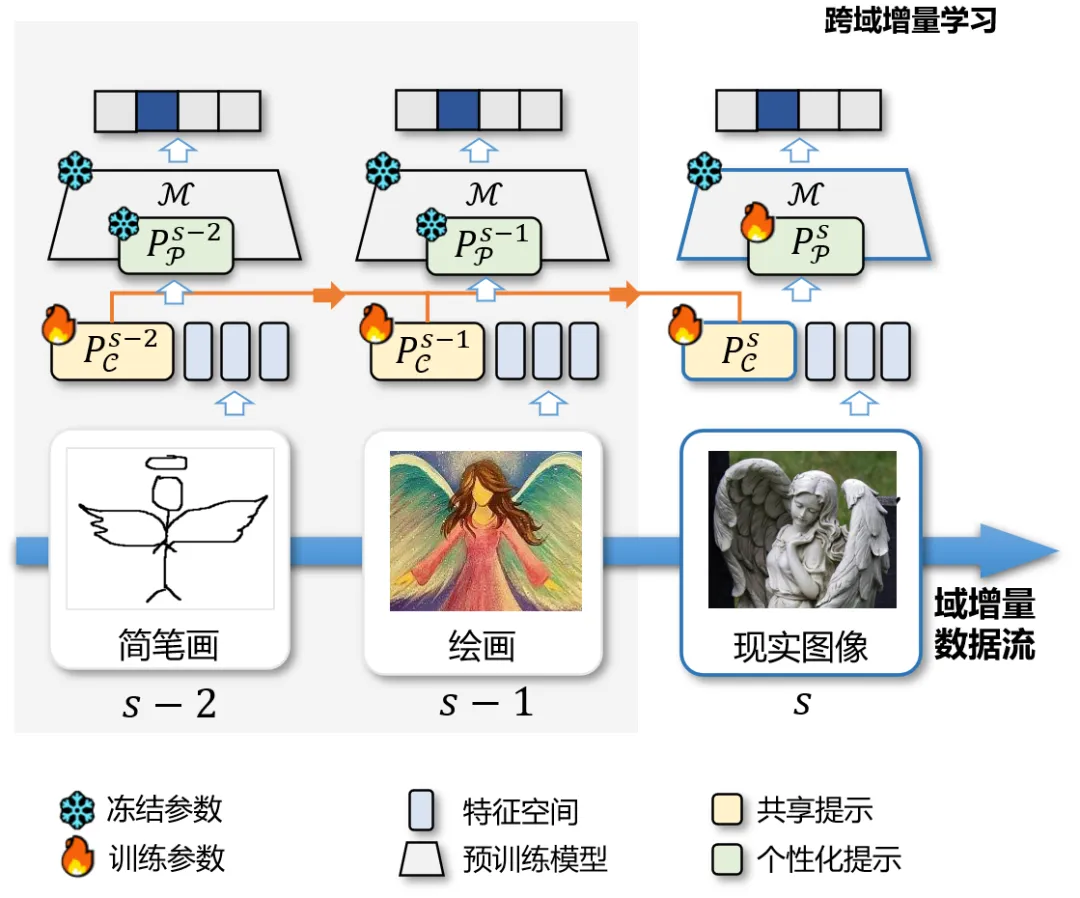
图1 跨域增量学习任务中CP-Prompt的一个简单示例
在此背景下,跨域增量学习的研究尤为重要。例如图1所示,在视觉任务中,模型可能需从简笔画风格数据逐步迁移到信息图、漫画等新风格领域,同时保持对已学习风格的分类能力。这一过程中,灾难性遗忘(Catastrophic Forgetting, CF)[190][191]成为跨域增量学习的关键挑战:模型在适应新领域时可能丢失旧领域的关键特征。
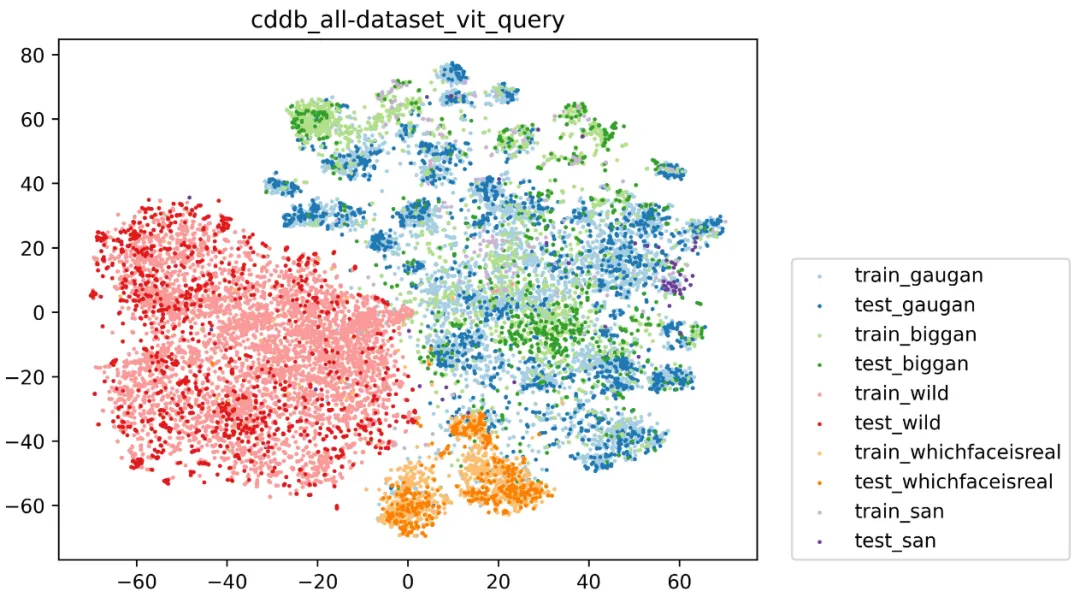
图2 CDDB-Hard数据跨域数据分布图
我们通过实验研究了跨域的数据分布可视化,如图2所示,每个数据域的嵌入空间都表现出一般可区分的模式(个性化知识),但彼此之间存在局部重叠(共享知识)。因此在该领域中存在两个挑战:(1)如何在领域增量过程中保持公共知识和个性化知识之间的权衡?以往的研究表明,提取领域间的共同模式和增强每个领域的个性化知识都有助于跨域增量学习。然而,从另一方面来看,模型增量更新过程中如何平衡域间和域内的特征仍然是一个亟待解决的问题;(2)如何描述领域上下文对嵌入令牌的影响?对于跨域增量学习模型广泛采用的Transformer模型结构,其有效性来自于复杂令牌列表的路由信息,通过自注意力获得相关性。然而,这种结构很难在固定大小的Transformer空间之外学习信息。基于以上分析,我们提出了一种边侧跨域增量大小模型协同进化技术架构CP-Prompt (Common & Personalized),用于指导预训练模型在不同数据风格的增量数据域上学习。
2.方法概述
在CP-Prompt架构的整体流程中,如图3所示,本章提出了一个双提示策略。其基本假设是,学习模型既需要通过域间共享提示来增强对任务公共知识的泛化能力,又要依靠领域内的个性化提示以获取特定领域的知识,从而提升模型在特定任务上的准确性。具体来说,该框架将个性化提示嵌入到不同转换层的键向量和值向量中,以指导模型学习不同粒度的潜在语义。在推理过程中,该架构采用简单的K-Means算法来选择合适的共享和个性化提示,从而指导预训练模型编码新的图像标记进行分类。
为使得模型能够学习领域间的共性和个性知识,并有效缓解模型灾难性遗忘问题,本小节提出一种简单而高效的提示学习范式。其核心思想是在预训练模型中插入共性提示和个性提示参数。共性提示嵌入于模型的浅层,用于顺序学习新领域知识,在冻结该层参数后,再将知识传递至下一个领域;而个性提示则嵌入于预训练模型的自注意力层中,有助于结合数据领域特征进行推理。通过这两种提示参数的相互配合,模型能够在不同的时空分布下持续学习,而无需调整原始预训练模型参数,从而大幅降低训练成本。接下来将详细介绍共性提示与个性提示的相关细节以及如何高效利用这些知识。
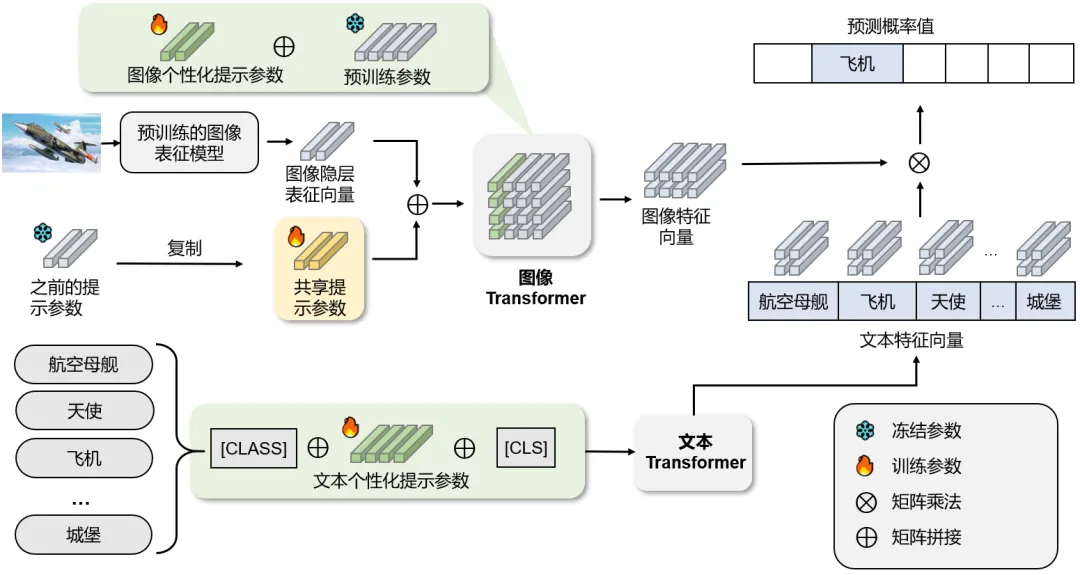
图3 双提示结构的CP-Prompt架构图
3.实验结果
实验测试了三种广泛使用的DIL基准数据集,包括CDDB-Hard、CORe50和DomainNet。为了进行公平的性能比较,实验采用了与以往研究相同的数据集和实验设置。实验通过利用公共数据集进行实验并评估了CP-Prompt的性能。
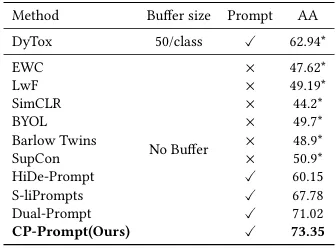
本研究提出的CP-Prompt方法在领域增量学习(DIL)任务中展现出显著优势。相较于S-liPrompt等现有无历史回放方法,CP-Prompt通过以下改进实现了性能突破:首先,在双提示架构基础上引入多层域内提示机制,利用自注意力网络实现提示信息与高维潜在特征的深度融合;其次,针对DIL任务特性优化提示设计,保留细粒度分类特征的同时建立跨领域共享提示机制。实验表明,这种双模块架构能有效平衡领域共性知识和个性化特征,相比Dual-Prompt的基线版本取得最优性能。在2类、50类和345类的多尺度DIL评估中,CP-Prompt以平均3.04%的准确率提升刷新三个基准数据集记录,同时将平均遗忘率控制至最佳的0.25。
表4-1 CDDB-Hard上的DIL实验结果
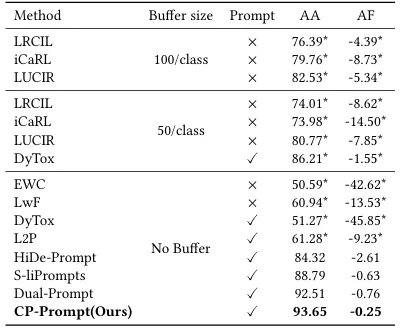
表4-2 CORe50的DIL实验结果
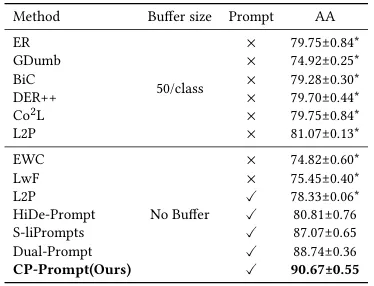
表4-3 DomainNet的DIL实验结果

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号