
【论文导读】2025年论文导读第十期
【论文导读】2025年论文导读第十期


论文导读
2025年论文导读第十期(总第一百二十七期)
目 录
|
1 |
Deconfounded Emotion Guidance Sticker Selection with Causal Inference |
|
2 |
ANFluid: Animate Natural Fluid Photos base on Physics-Aware Simulation and Dual-Flow Texture Learning |
|
3 |
Rainmer: Learning Multi-view Representations for Comprehensive Image Deraining and Beyond |
|
4 |
ScaleTraversal: Creating Multi-Scale Biomedical Animation with Limited Hardware Resources |
|
5 |
Serial Section Microscopy Image Inpainting Guided by Axial Optical Flow |
01
Deconfounded Emotion Guidance Sticker Selection with Causal Inference
基于因果去偏与情感驱动的表情包推荐
作者:
陈嘉力1、蔡毅1、徐若航1、王杰新1、谢嘉元2 *、李青2
单位:
1华南理工大学、 2香港理工大学
邮箱:
segarychen@mail.scut.edu.cn,
ycai@scut.edu.cn,
202030482249@mail.scut.edu.cn,
jiexinwang@scut.edu.cn,
jiayuan.xie@polyu.edu.hk,
csqli@comp.polyu.edu.hk
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3681522
发表会议:
ACM MM2024
*通讯作者
1.研究背景与动机
在社交平台上,表情包已成为用户传达情绪、增进互动的重要手段。已有的推荐方法往往依赖于训练集中表情图像、情绪词汇与情绪标签之间的共现关系,容易学习到“虚假关联”,导致推荐结果偏离用户真实情感。为解决这一问题,我们从因果推理的角度出发,系统分析表情包推荐中的偏见来源,并设计因果建模方法,帮助模型挖掘对话中的真实情绪信号,从而提升推荐的准确性和泛化能力。

图1 表情包推荐过程中存在的偏见
2.方法介绍
我们首先基于因果图(Causal Graph)形式化表情包推荐中的关键变量及其因果关系,刻画训练过程中的潜在偏见来源。具体包括:U(对话上下文)影响用户当前的情绪 Y;I(表情包图像)由内容变量 Mc和风格变量 Ms共同构成;W(情绪倾向词)作为混淆变量,同时影响视觉知识 V 和情绪 Y,形成典型的后门路径 W → V → Y,易引发模型学习“图像风格与词语”的虚假关联。
因此,我们提出 Causal Knowledge-Enhanced Sticker Selection(CKS)模型,从因果视角出发模拟人类“理解情绪—推荐表情包”的认知过程,由以下三大模块组成:
(1)知识增强情绪话语提取器(KEUE):利用 ATOMIC 常识知识库识别对话中真正承载情绪的有效话语,过滤冗余干扰句,形成情绪语义表示;
(2)干预式视觉特征提取器(IVE):包含视觉知识去混淆模块(VKD),通过因果干预(do-操作)控制情绪倾向词 W,阻断 W → V → Y 的偏置路径;同时引入内容不变模块(CIM),通过图像频域扰动实现图像内容与风格的解耦,增强模型在不同风格表情包下的鲁棒性;
(3)多模态编码器:融合情绪话语、对话上下文、OCR文本及图像特征,通过Transformer结构进行统一建模,用于情绪识别与最终的表情包推荐。
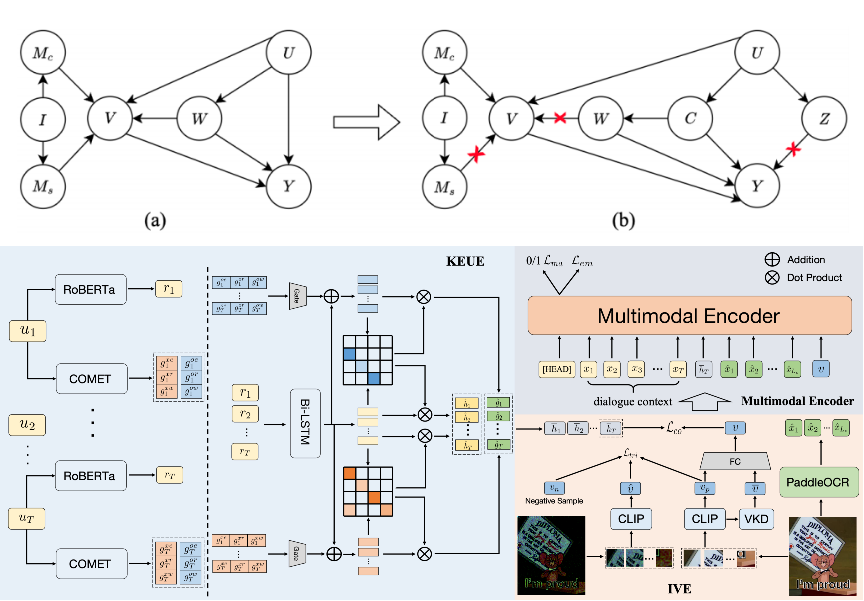
图2 因果图与CKS模型示意图
3.实验结果
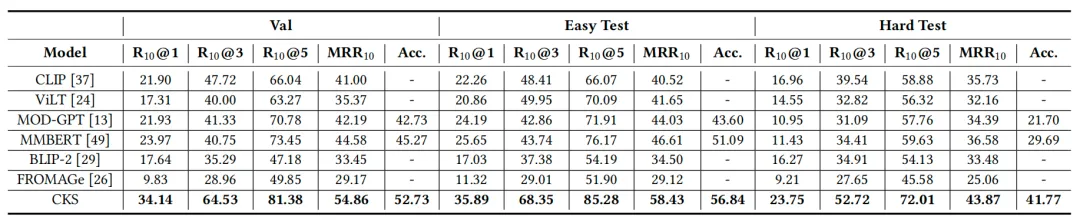
在 MOD 数据集上的实验表明,CKS 模型在验证集和多个测试集均大幅优于现有主流方法。在困难测试集上,情绪识别准确率提升 12.08%,MRR 提升 7.29%,体现了模型出色的情感理解与推荐泛化能力,有效缓解数据偏见带来的推荐误导问题。
表1 MOD数据集的实验结果
02
ANFluid: Animate Natural Fluid Photos base on Physics-Aware Simulation and Dual-Flow Texture Learning
作者:
翟相程1,* ,介应奇2,* ,谢雪光4,郝爱民3,姜那1,†,高阳3,†
单位:
首都师范大学1,北京理工大学2,北京航空航天大学3,北京科技大学4
邮箱:
1201004021@cnu.edu.cn,
yingqi.jie@bit.edu.cn,
xgxie0107@gmail.com,
ham@buaa.edu.cn,
jiangna@cnu.edu.cn,
gaoyangvr@buaa.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3680950
发表会议:ACM MM 2024
*共同一作
†通讯作者
1.论文简介
从单张静态图像生成逼真动画对多媒体编辑与艺术创作具有重要意义。现有AIGC方法基于扩散模型并在大规模数据集上训练,已能生成较为流畅的动画效果,但由于缺乏物理模型,难以精确还原现实世界中复杂的自然流体现象。针对这一问题,本文提出一种融合物理模拟与数据驱动策略的耦合生成框架,命名为ANFluid。它结合物理感知模拟(PAS)与双流纹理学习(DFTL),实现对自然流体现象的高保真动画生成。PAS模块通过感知驱动选择适配的物理解算器,使流体运动符合物理规律并适应多样化场景;DFTL模块引入双向自监督光流估计与多尺度翘曲机制,以增强纹理建模的时序一致性与视觉逼真度。
2.方法概述
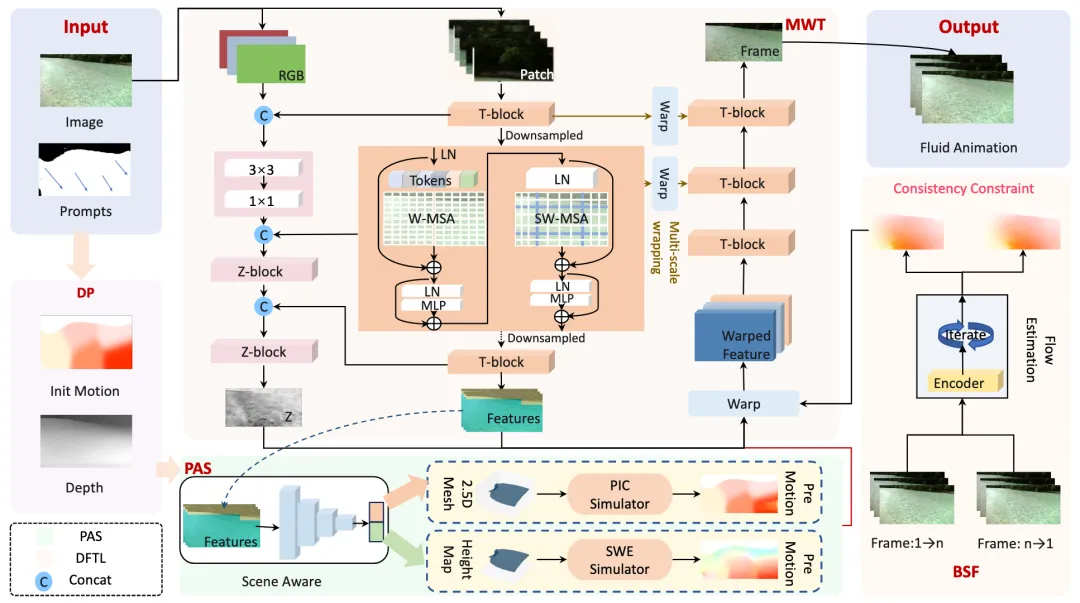
图1 模型框架图
现有方法多以数据驱动为主,具有较为流畅的视觉效果,但缺乏显式物理建模,难以保证物理一致性;相反,物理模型驱动的则可以保证物理合理性,却在纹理细节和感知质量上表现不足,二者优势互补。为此,本文提出一种融合物理模拟与数据驱动策略的耦合生成框架,如图1所示。首先,数据预处理(DP)阶段提取图像深度与初始运动信息,为后续建模提供支持。PAS模块根据图像特征进行场景感知,选择匹配的物理求解器模拟流体运动,确保物理合理性,其中高落差场景采用质点网格法(PIC),低落差场景采用浅水方程法(SWE)。DFTL模块融合运动场与图像特征,执行特征变形与解码,生成兼具纹理一致性与动态连贯性的自然动画。DFTL由多尺度翘曲图像纹理特征学习网络(MWT)与双向自监督光流估计网络(BSF)构成,训练过程中,BSF提供双向流体约束的运动信息,增强MWT对特征细节与纹理关联的建模能力,在测试时,则使用PAS求解运动信息。ANFluid通过PAS与DFTL协同建模,实现了真实、自然且物理一致的流体动画生成。
3.实验结果
为验证所提方法在自然流水动画生成中的有效性,本文在Holynski和CLAW数据集上开展了对比实验,如下表1所示。所提方法在感知一致性(LPIPS指标)和整体视觉效果上均优于现有方法,充分验证了其在野外透明流体动画生成任务中的卓越性能,尤其在复杂场景下展现出更强的适应能力。与基线模型相比,本方法在性能提升的同时显著降低了参数量,体现了更高的建模效率。
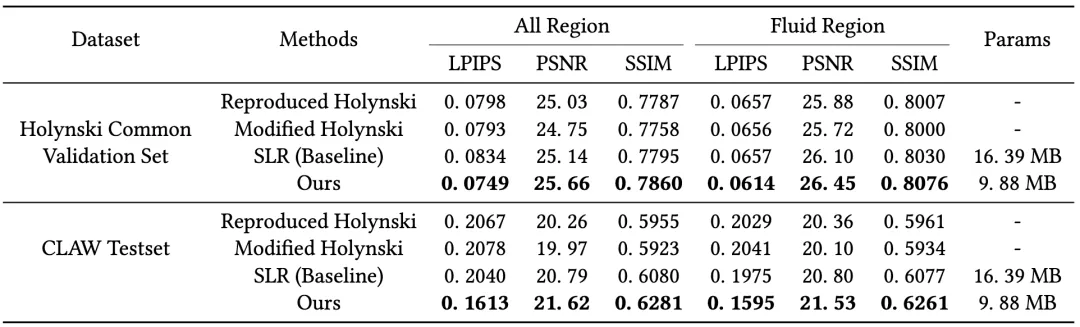
表1 模型在Holynski和CLAW数据集上的表现
为进一步验证物理一致性与纹理真实性,本文进行了可视化分析,如下图2所示,相较以往方法,本方法有效缓解了高速流区域的纹理孔洞问题。通过融合物理模拟与多尺度翘曲技术,增强了动态流体纹理的真实感和静态物体的细节表现。综合实验结果表明,所提方法在物理合理性与语义一致性方面更契合真实世界与原始图像。

图2 不同方法生成效果对比
03
Rainmer: Learning Multi-view Representations for Comprehensive Image Deraining and Beyond
基于多元表示提示学习的综合图像去雨方法
作者:
冉武1,马培荣1,何值全1,路红1*
单位:
复旦大学1
邮箱:
bonjourlemonde@sjtu.edu.cn,
prma20@fudan.edu.cn,
22210240019@m.fudan.edu.cn,
honglu@fudan.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681342
代码:
https://github.com/Schizophreni/Rainmer
发表会议:ACM MM 2024
*通讯作者
1.研究背景
图像去雨 (Image deraining) 旨在去除雨天拍摄图像的雨效应 (雨滴、雨雾等),为下游计算机视觉任务提供高质量的图像输入。当前深度学习方法通常在合成数据集上训练模型,训练数据集的退化类型以及光照条件比较单一。在真实场景下,面对复杂的雨退化和光照条件,现有方法的泛化性不足。因此,研究多种雨退化和光照条件下的综合性图像去雨方法至关重要。其主要面临以下关键挑战:
训练数据集缺乏。在多种雨天类型及多种光照条件下采集像素级对齐的干净/带雨图像难度极高;
复杂雨天下模型对退化图像的感知粒度不足。现有方法难以同时感知雨天图像中的雨线、雨雾、模糊、遮挡、色彩偏移等多种退化,以及不同光照的差异;
多类型数据导致模型训练的优化冲突。模型在不同雨类型(雨滴、雨线、雨雾)以及光照条件(自然光/暗光)的图像上训练时,难以同时处理不同退化和光照的影响,导致模型去雨能力不足。
2.方法概述
如图一所示,论文提出了一种综合性图像去雨框架,主要包括三个部分:
包含合成、真实以及夜晚场景的数据集构建以及数据分布对齐,如图二所示,论文提出一种雨强度/光照度量来均衡各类数据集;
基于对比学习的雨图细节、退化以及色彩性相关表示的提取;
融合多元表示的提示学习图像修复框架(如图三所示)
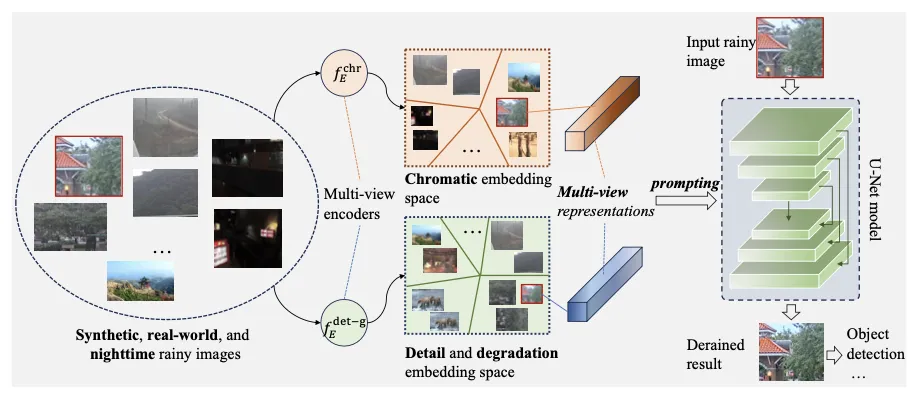
图1 论文提出的综合性图像去雨框架
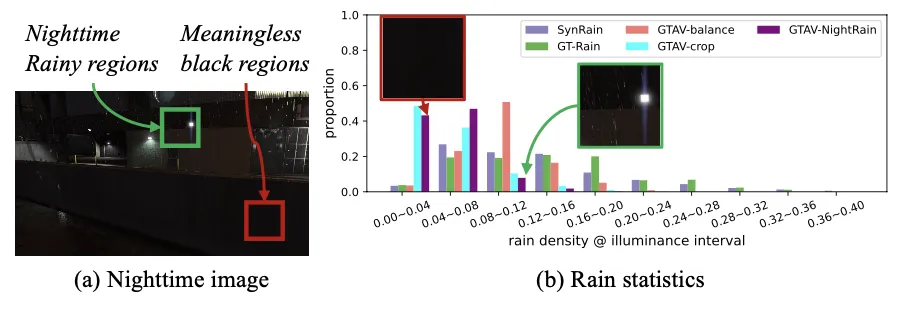
图2 多类型雨数据集统计分布
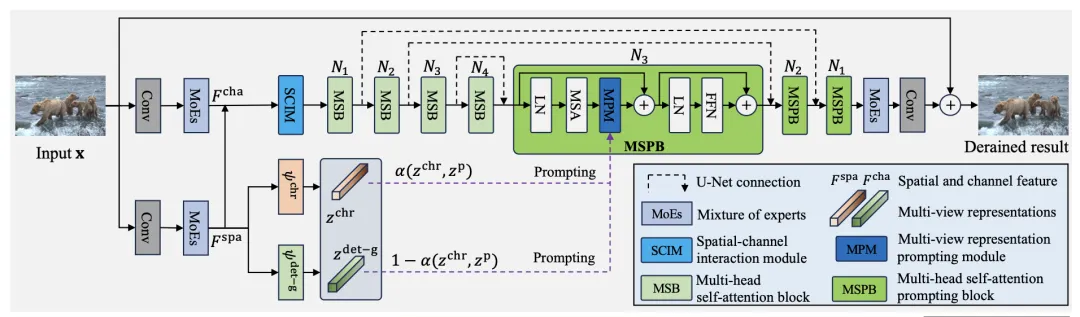
图3 融合多元表示的提示学习框架
3.实验结果
论文在五个合成数据集 (Rain100L、Rain100H、Test100、Test1200、Test2800)、真实雨数据集GT-Rain以及夜晚雨数据集GTAV-balance上对现有方法进行了比较。
图像去雨定量比较。如表一所示,论文提出的Rainmer方法在所有数据集上取得了最高的综合PSNR/SSIM指标;
图像去雨定性比较。图四进一步展示了不同方法在合成、真实、以及夜晚雨图像的恢复结果,论文方法在不同图像上实现了最好的修复效果。图五则比较了不同方法在真实网络雨天图像上的泛化性,论文方法取得了了最佳效果;
多种天气类型扩展性。论文进一步将Rainmer扩展到雨雪多种天气条件下。图六结果表明论文方法优于现有方法;
下游任务验证。论文比较了不同去雨方法提升雨天目标检测效果的能力。如表二所示,论文方法能最大程度提升不同雨场景下的目标检测指标。图七对不同方法检测结果进行了可视化。图八进一步研究了去雨指标PSNR/SSIM与检测性能mAP之间的相关性(二者为阶梯式正相关性)。
表1 模型在合成数据集、真实数据集GT-Rain以及夜晚数据集GTAV-balance上的表现
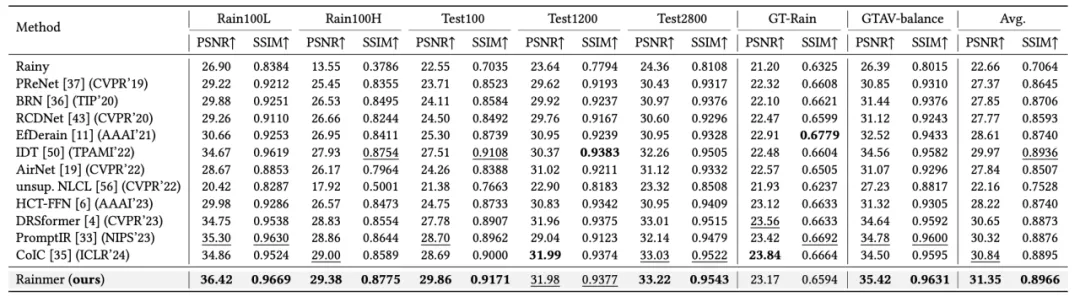

图4 模型在合成、真实以及夜晚雨场景下的去雨结果可视化

图5 模型在真实雨场景下的泛化性比较

图6 模型在多种天气条件下的扩展性
表2 图像去雨模型在目标检测下游任务上的性能比较
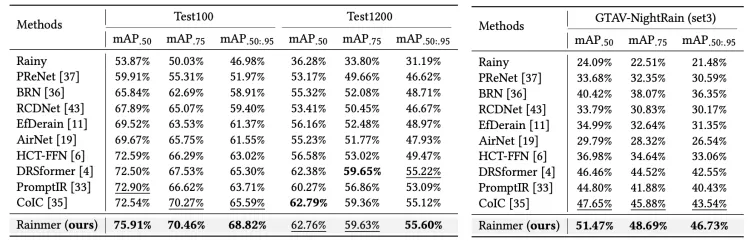
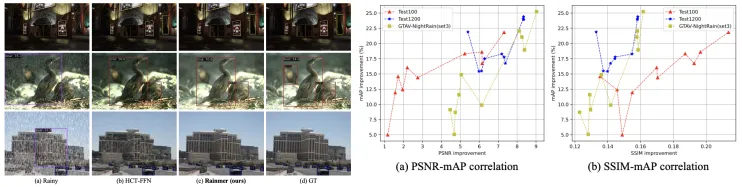
图7 a)目标检测比较可视化结果 ; b)去雨指标PSNR/SSIM与目标检测性能 mAP的相关性
04
ScaleTraversal: Creating Multi-Scale Biomedical Animation with Limited Hardware Resources
作者:
刘日晨1,王晗圣1,王海龙1,陈思儒1,赖楚凡2*,Ayush Kumar3,陈思明4*
单位:
1南京师范大学计算机与电子信息学院/人工智能学院,
2中国科学院空间应用工程与技术中心,
3哈佛医学院,
4复旦大学
邮箱:
richen@pku.edu.cn,
laichufan@csu.ac.cn,
aykumar@cs.stonybrook.edu,
simingchen3@gmail.com
论文:
https://dl.acm.org/doi/10.1145/3664647.3681191
发表会议:
ACM MM 2024
*通信作者:赖楚凡,陈思明
1.背景动机
生物医学多尺度数据包括组织层(10-1m)、纤维层(10-2m)、细胞层(10-4-10-5m)、神经元层(10-5m)、染色体层(10-7m)、DNA与RNA层(10-9m)等,如图 1所示。此外,多尺度概念也可以用在物理学上,比如银河系(1021m)、恒星系(1013m)、恒星(109m)、行星(106m)、人造卫星(101m)、人类(100m)、细胞(10-4-10-5m)、原子(10-10m)、电子(10-15m)、夸克(10-18m)等。多尺度数据跨越了许多不同的长度尺寸,如何在渲染中既能消除尺寸差异的负面影响,又能形成效果良好的渲染结果成为大家深入研究的难题。在虚拟摄像机从高层级聚焦到低层级时,高层级物体会快速从虚拟摄像机的视野中消失,并使过渡画面撕裂。当虚拟摄像机聚焦到物理尺寸足够小的层级时,虚拟摄像机的平移很有可能由于浮点数的精度错误导致画面产生剧烈的扰动。高低层级之间指数级的尺寸差距要求数据动画应当有平滑的过渡,而不是跳跃式的画面。
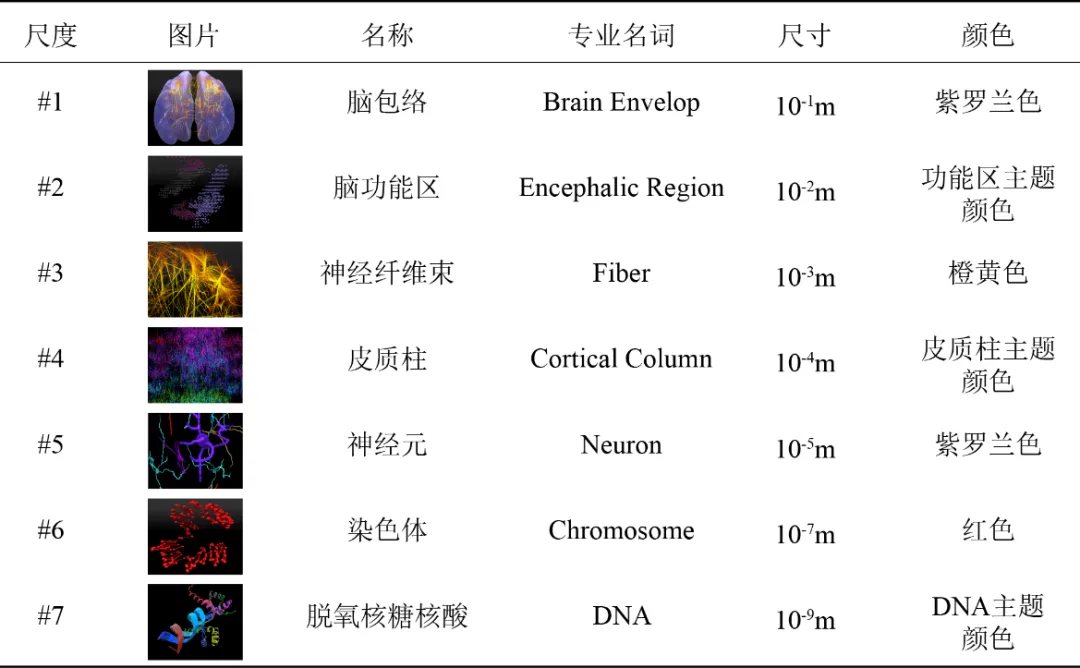
图1 脑部生物医学多尺度数据集(七个尺度)
2.方法概述
鉴于沉浸式设备的内存和处理器中GPU的性能有限,在此计算资源有限情况下,我们设计了三种存储管理策略,具体如下:(1)首先,我们提出了多尺度数据逐级加载并绘制的算法。在数据逐级加载的过程中,可降低GPU的渲染压力,有效提升数据演示动画的性能,如图 2所示。(2)其次,我们提出了基于多尺度数据的预加载和资源释放策略。它使得处理器只会保留前一个尺度、当前演示尺度和即将渲染的两个尺度的渲染对象,如图 3所示。当数据演示动画进入到下一个尺度时,会自动释放掉原本保留的前一个尺度渲染对象,以降低GPU的占用率,从而提升演示数据动画时的性能。(3)我们还设计了图形合并和GPU加速策略。
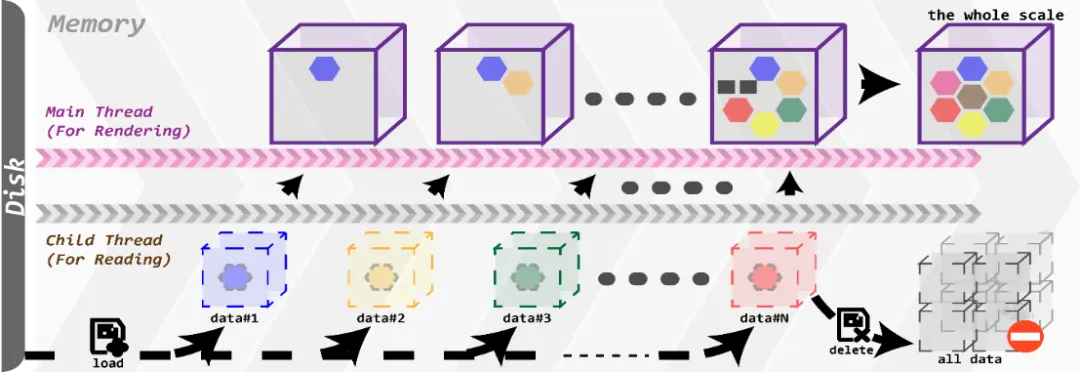
图2 流式数据加载策略设计图
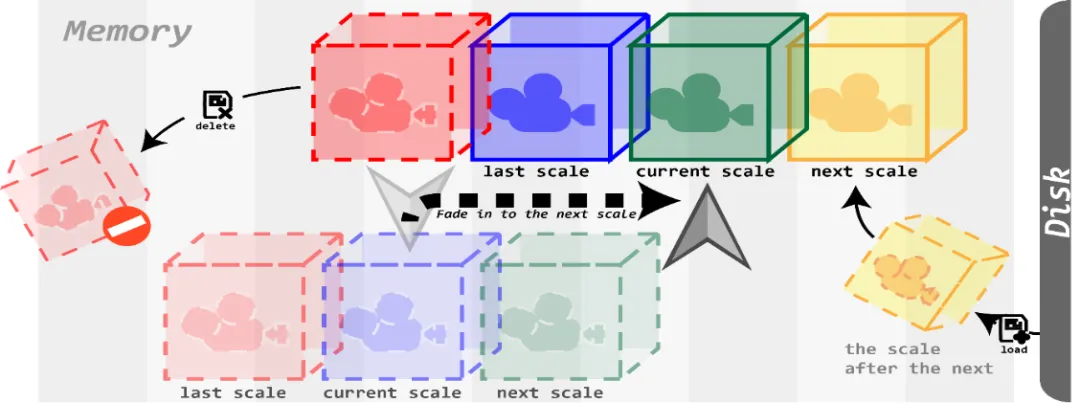
图3 预加载和动态释放策略设计图
传统的数据渲染创作的学习曲线复杂、复用性差。为了减少用户编写大量的代码,数据动画定制时可以采用用户友好型的图形化界面。用户可以通过简单地点击创建领域自定义语言动画执行单元,并在提供的文本框中修改该动画执行单元的参数。同时,界面采用瀑布式流程图设计,用户可以通过拖拽移动动画执行单元在动画轨道中的相对位置来修改数据动画的演示流程,如图4左侧图所示。
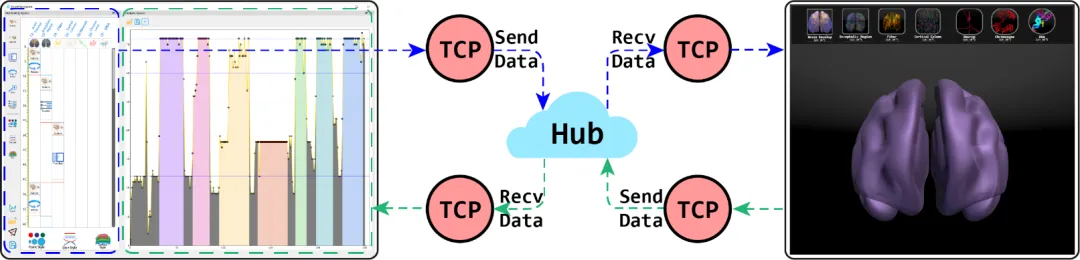
图4 远程服务器转发模块的数据传输图:蓝色虚线表示编译结果的发送,绿色虚线表示的是实时帧率的回传
3.实验结果
在论文中我们展示了三段自动构建的生物医学多尺度动画。分别使用了大脑包络(#1),脑功能区(#2),神经纤维束(#3),皮质柱(#4),神经元(#5),染色体(#6)和DNA(#7)等尺度的数据用于多媒体动画构建,如图5和图6所示。
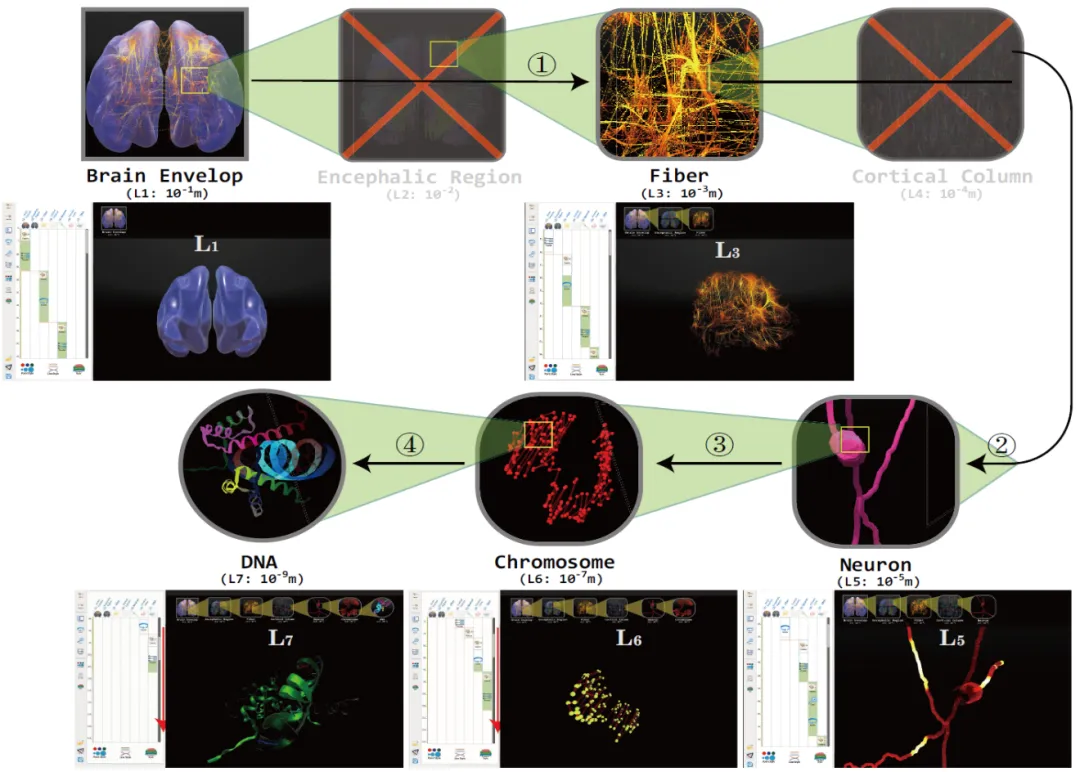
图5 第一段自动构建的多媒体演示动画包含五个数据尺度,即脑包膜尺度(L1)、纤维束尺度3)、神经元尺度(L5)、染色体尺度(L6)和DNA尺度(L7)
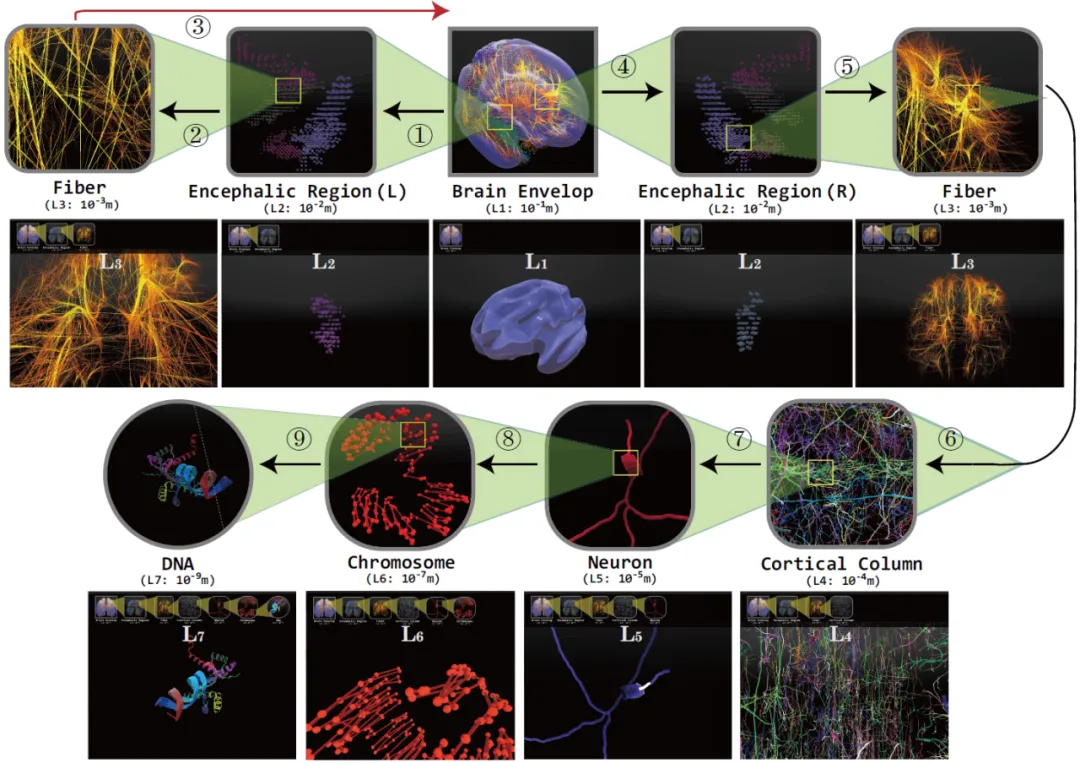
图6 第二段自动构建的多媒体演示动画是通过使用“Scale-Return”的方式在支持领域自定义语言开发的界面中定制的。动画包括对“左脑”和“右脑”的多个尺度动画的演示
最后,我们对比性测试(图 7)并绘制了多尺度数据动画自动构建中使用的优化策略的帧率曲线(图 8),在使用普通PC机作为远程服务器,头显作为客户端时(Intel i7,内存为16GB,显卡为NVIDIA RTX 3050Ti,沉浸式设备为Oculus Quest 2),数据加载时平均帧率为22帧/秒,尺度过渡时帧率接近24帧/秒,动画演示时,帧率为72帧/秒,其中皮质柱尺度因为包含的神经元数量过多,帧率为36帧/秒左右。
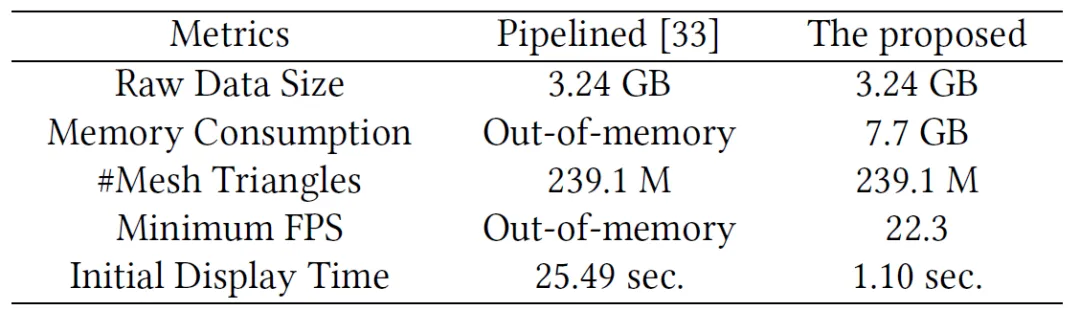
图7 整体性能与最新的流水线方法[33]对比结果,后者通常会因内存不足而导致应用程序崩溃。由于将生成和渲染大量对象,动画期间实际使用的内存大小远大于原始数据大小
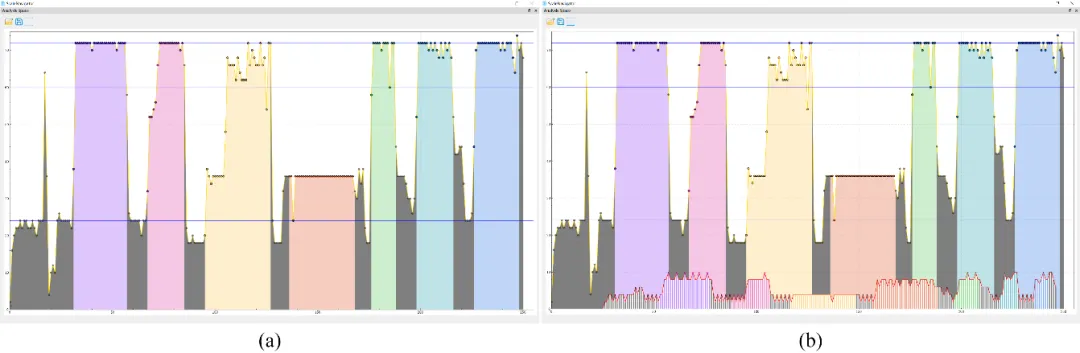
图8 性能帧率曲线:彩色填充线为使用优化策略的帧率曲线,图(b)中前置的脉冲线为不使用对应优化策略的对比帧率结果
05
Serial Section Microscopy Image Inpainting Guided by Axial Optical Flow
基于轴向光流引导的连续切片显微图像修复
作者:
程怡然*1,何彬涛*1,张法2,韩仁敏†1
单位:
1山东大学,2北京理工大学
邮箱:
chengyiran@mail.sdu.edu.cn,
hebintao@mail.sdu.edu.cn,
zhangfa@bit.edu.cn,
hanrenmin@sdu.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681023
代码:
https://github.com/chengyr1999/FlowInpaint
发表会议:ACM MM 2024
*共同一作
†通讯作者
1.研究背景
体电子显微技术(Volume electron microscopy, vEM)作为细胞超微结构三维可视化的重要技术手段,通过采集连续的二维切片图像并结合相邻截面间的轴向插值处理,能够在纳米尺度上实现生物样本的三维重建。然而,该技术在样品制备和成像过程中存在显著的技术挑战:一方面,人工操作的不稳定性可能导致切片损伤;另一方面,仪器设备的机械故障也可能引发结构信息的丢失。这些问题往往造成切片中关键区域的结构信息模糊化,甚至形成局部数据缺失。值得注意的是,尽管当前单张图像的修复技术已取得显著进展,但在连续切片图像的实际应用场景中,如何在恢复缺失的生物结构的同时满足切片间的轴向结构连续性,仍然是一个巨大的挑战。
2.方法概述
本文提出了一种基于GAN架构的连续切片图像修复网络FlowInpaint,如图1所示。该网络通过估计破损切片的相邻切面之间的中间状态来指导信息缺失区域的补全。首先,将破损图像的两张相邻图像送入初始参考模块,得到满足生物结构轴向连续性的中间状态。与原始相邻图像相比,该中间状态具有与受损切面图像更相似的结构,从而显著降低了后续光流估计的复杂度。然后,将破损图像和中间状态联合输入到细化参考模块中,为破损区域提供可靠的参考图像。最后,基于GAN的引导修复模块采用类U-Net结构,从参考图像和相邻图像提取多尺度二维图像特征来共同引导着破损区域的信息恢复,并保证修复结果与破损区域周围已知信息的一致性。此外,该模块还使用鉴别器确保生成内容的像素和噪声值分布均匀,从而在修复区域提供无缝和清晰的结构恢复。
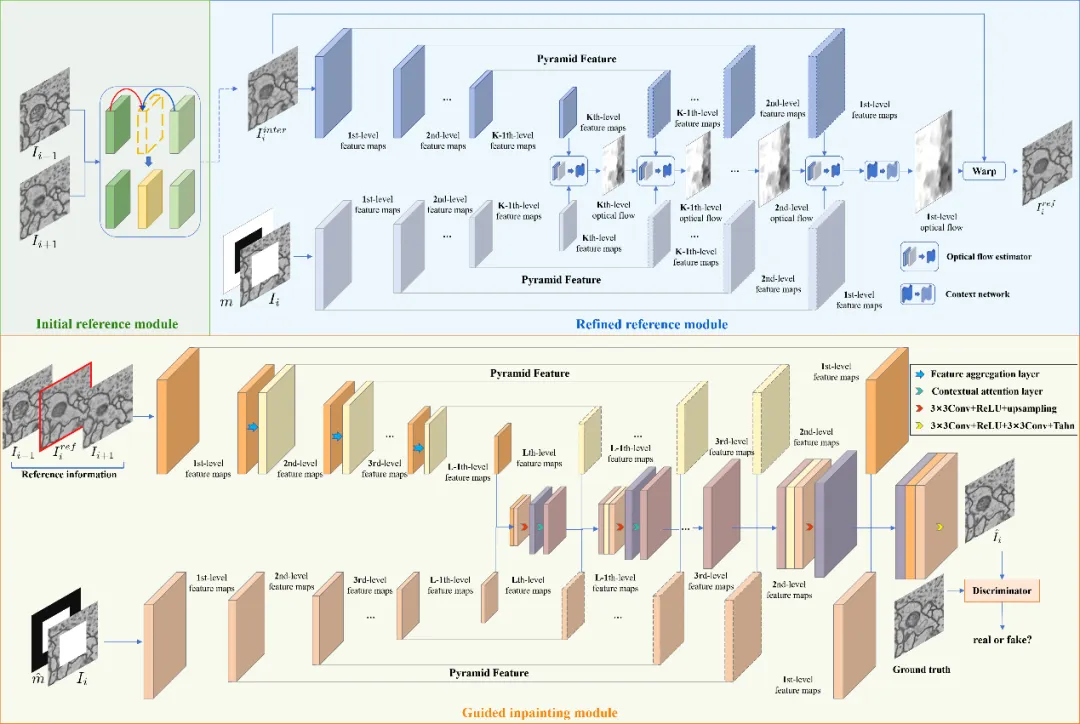
图1 整体模型框架图
3.实验结果
本文将FlowInpaint与两个单张图像修复方法:PEN-Net [26]和AOT-GAN [27], 以及两个连续图像修复方法: CCPGAN [29]和 SSF-Restoration [11]在CREMI和EPFL数据集上进行比较。表1总结了各方法在基于CREMI数据集构建的5个模拟测试数据上的量化评估结果。相比于单张图像修复方法,连续图像修复方法在不同破损比例下都能在内容相关的指标上表现较好,这主要归功于相邻图像引入的不同程度的参考信息。由于FlowInpaint提出了更加全面可靠的参考信息生成策略并采用了GAN架构,从而其在图像内容与真实性的相关指标上都获得了最优量化结果。图2展示了不同方法基于CREMI数据集的约30%不规则损伤区域下可视化比较结果。如图所示,单张图像修复方法的修复结果并不具备合理性,且相邻切片图像间的差异大小也明显影响了连续图像修复方案的效果,而FlowInpain的参考生成模块显然极大削减了轴向结构差异的影响。对于连续图像修复方法在不同轴向分辨率下的修复能力,本文在EPFL数据集开展了稳定性实验,详见补充材料。图3具体展示了不同连续图像修复方法的结果在轴向结构连续性上的差异。如图所示,CCPGAN [29]即使在红色箭头指向的结构简单的区域也无法保证合理结构生成,而SSF-Restoration [11]在蓝色箭头指向的锯齿状轴向结构区域则倾向于生成较为平滑的结构。与之相对应的是FlowInpaint在保证二维切面结构一致性的情况下,也能合理的保证轴向结构的连续性。
表1 现有图像修复方法的量化比较结果。↑代表数值越高越好,↓反之。
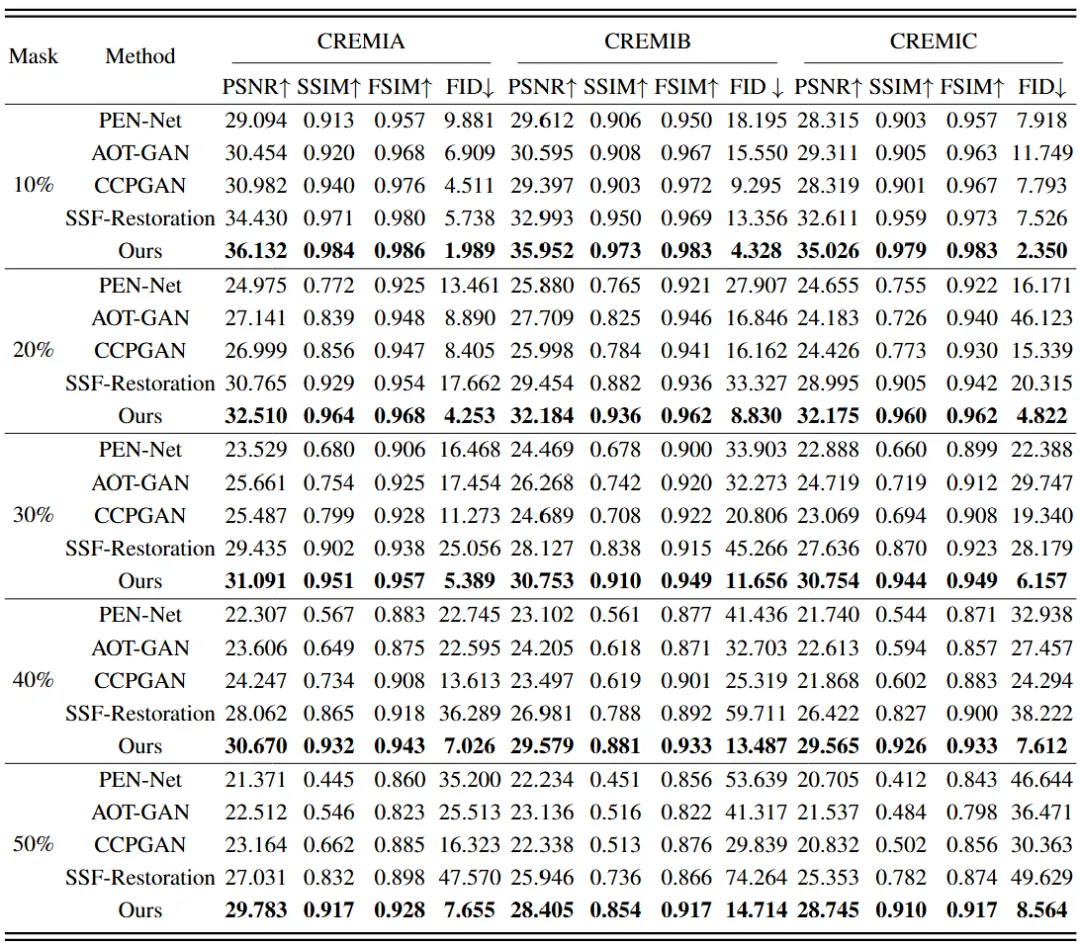

图2 在CREMI数据集上30%掩模下不规则损伤区域的修复结果。(A) PEN-Net, (B) AOT-GAN, (C) CCPGAN, (D) SSF-Restoration, and (E) Ours.

图3 不同图像修复方法的结果在轴向结构上的比较。(A)Ground-truth, (B)Damaged, (C)CCPGAN,(D)SFF-Restoration, and (E)Ours。

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号