
2022年论文导读第十九期
【论文导读】2022年论文导读第十九期
CCF多媒体专委会 2022-09-20 09:29 发表于北京


论文导读
2022年论文导读第十九期(总第五十九期)
目 录
|
1 |
XYLayoutLM: Towards Layout-Aware Multimodal Networks for Visually-Rich Document Understanding |
|
2 |
CLIMS: Cross Language Image Matching for Weakly Supervised Semantic Segmentation |
|
3 |
Make It Move: Controllable Image-to-Video Generation with Text Descriptions |
|
4 |
DF-GAN: A Simple and Effective Baseline for Text-to-Image Synthesis |
|
5 |
Multi-Scale Spatial and Temporal Speech Associations to Swallowing for Dysphagia Screening |
|
6 |
Remember Intentions: Retrospective-Memory-based Trajectory Prediction |
01
XYLayoutLM: Towards Layout-Aware Multimodal Networks for Visually-Rich Document Understanding
作者:顾章轩1,2,孟昌华1,王可1,兰钧1,王维强1,顾鸣1,张丽清2
单位:1蚂蚁集团,2上海交通大学
邮箱:
guzhangxuan.gzx@antgroup.com
论文:
https://openaccess.thecvf.com/content/CVPR2022/html/Gu_XYLayoutLM_Towards_Layout-Aware_Multimodal_Networks_for_Visually-Rich_Document_Understanding_CVPR_2022_paper.html
1. 多模态文档理解技术背景
近年来,多模态文档理解在各类场景得到了广泛的应用。它要求我们结合图像,文本和布局信息对扫描件或者pdf文件进行理解。目前学术界的模型方案,通常都需要先经过对图像进行ocr扫描,解析出图中的文本和文本框位置,再将得到的文本框坐标,按照ocr解析出的默认顺序,输入给模型。然而,和普通的文档图像不同,诸如票据、表单、卡证等数据,其文本位置通常无法按照传统的“从左至右”或者“从上到下”进行简单排序,而是存在丰富的层次结构。另一个局限性是许多现有的模型使用了长度固定的位置编码,这会导致模型在训练完成后无法处理更长的输入序列。针对上述两个缺陷,我们提出了XYLayoutLM模型,希望改善文档自动化读取过程中,表单结构复杂、文本过长等导致的错误理解问题,提高内容读取的准确率。
2. 方法介绍
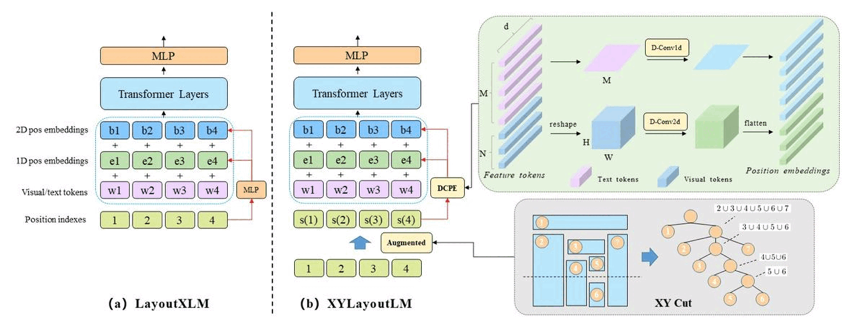
图1 模型总览
图1展示了基准模型LayoutXLM和我们的XYLayoutLM的区别。我们的模型输入是图像视觉特征,文本特征和文本位置特征。同时,两个位置编码生成器把输入文本框编码成pos embeddings和box embeddings。在此之后,我们将embeddings都拼接起来,输入transformer层,输出的视觉/文本token表征被用于文档理解任务。
2.1 Augment XY Cut

算法1 Augmented XY Cut 算法
以水平方向的映射为例子,我们先将所有的文本框boxes映射到Y轴形成相应的一堆映射区间,得到
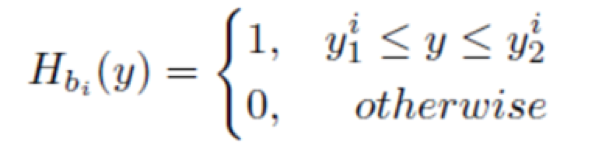
这个指示函数代表第i个box映射到Y轴形成的区间。我们遍历所有的i求和,得到

该函数在y点的值代表了有多少个本文框box在y点上有交集。
我们寻找使得HB(y)函数值为0的一些点y*,以它们为基础进行cut。此时,寻找所有文本框的阅读顺序被分解成了一些子问题,因此我们可以进行递归调用求解。另外,水平映射和竖直映射是交替进行的。
2.2 Dilated Conditional Position Encoding
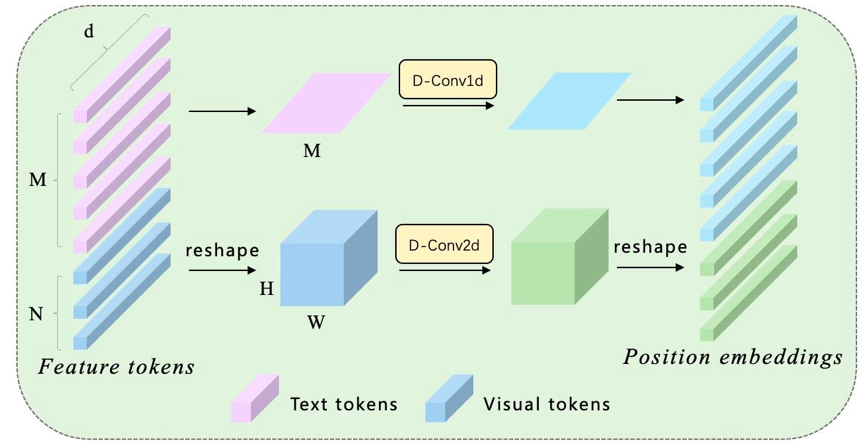
图2 DCPE模块
现有模型的第二个局限性是position embedding的长度固定。对于这一点,我们基于CPE提出了DCPE,如图2所示。主要有2点改进:一是将text和image的tokens分开处理,text过1D卷积,image过2D卷积,最后再合并起来。二是我们观察到多模态模型往往需要更大的感受野, CPE中的普通卷积可能捕捉不到这种长距离的信息,因此我们使用了空洞卷积替代了标准卷积,使得在不额外增加计算量的前提增加了模型的感受野,进一步提升模型性能。
3. 实验结果
表1 在XFUN上XYLayoutLM与其余baseline的结果比较

表2 在FUNSD上XYLayoutLM与其余baseline的结果比较
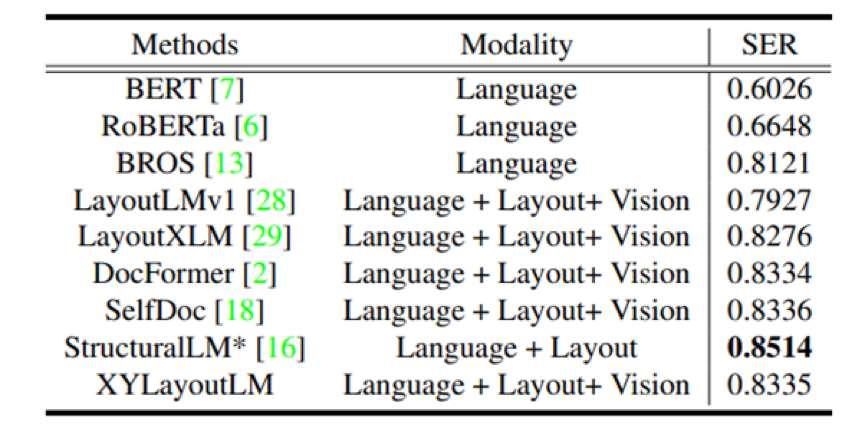
表1和表2是XYLayoutLM在两个学术数据集XFUN和FUNSD上的结果。从中可以看出我们的方案在模型参数量相当的情况下,F1 score达到了SOTA。
4. 可视化
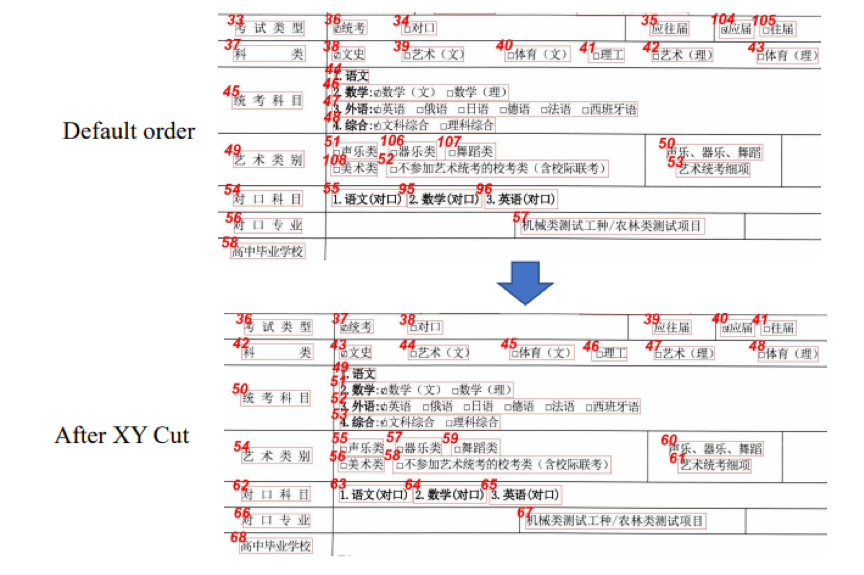
图4 Augmented XY Cut 算法对文本排序的结果
图4是利用Augmented XY Cut对文本框顺序排序后输出的一个结果。其阅读顺序比默认顺序更加合理。
02
CLIMS: Cross Language Image Matching for Weakly Supervised Semantic Segmentation
作者:谢金衡、侯贤旭、叶凯、沈琳琳
单位:深圳大学计算机与软件学院
邮箱:
;
llshen@szu.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2022/html/Xie_CLIMS_Cross_Language_Image_Matching_for_Weakly_Supervised_Semantic_Segmentation_CVPR_2022_paper.html
代码:
https://github.com/CVI-SZU/CLIMS
关于作者:
https://sierkinhane.github.io/
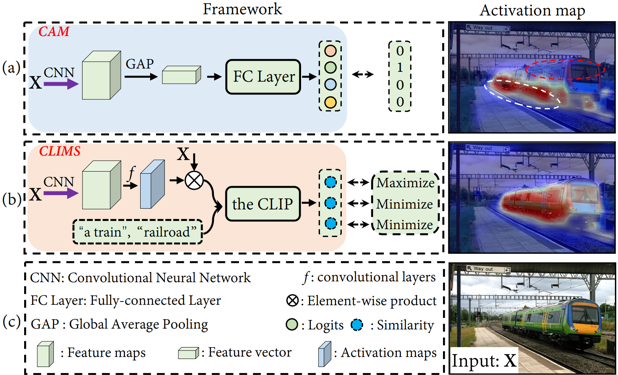
图1 CAM与CLIMS的对比图
摘要:众所周知,类别激活图(Class Activation Map, CAM) 通常只激活物体的判别性区域并且包含了许多与物体相关的背景误激活。仅利用图像级标注信息的弱监督语义分割(Weakly Supervised Semantic Segmentation, WSSS)模型很难抑制那些多样化的背景区域。因此,基于文本图像对比的预训练模型(Contrastive Language Image Pretraining, CLIP),本文提出了一个新颖的跨语言图像匹配的弱监督语义分割框架(Cross Language Image Matching for WSSS, CLIMS)。框架的核心思想是引入自然语言监督和设计物体、背景区域和文本标签匹配损失来获得更完整的类别激活图。并设计了区域正则化和背景抑制损失,以防止模型在CAM图中激活与类别相关的背景区域。这些设计使CLIMS 为目标对象生成更完整和紧凑的激活图,以生成更高质量的伪标签用于语义分割网络的训练。
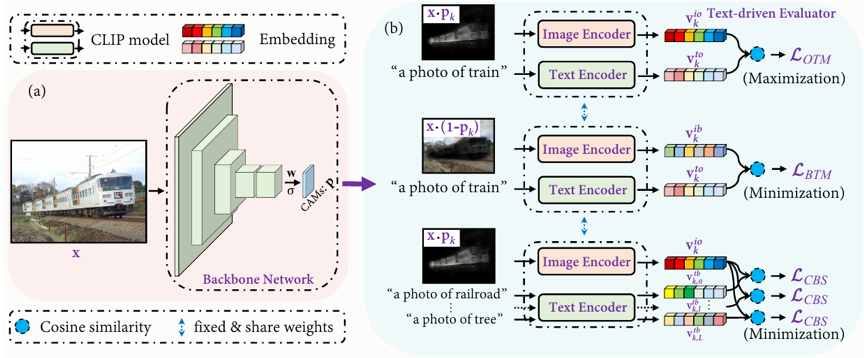
图2 CLIMS的网络结构图
图2 展示了本文提出的基于跨文本图像匹配CLIMS框架。它由一个骨干网络和一个文本驱动的评估器组成,其中评估器包括三个基于大型文本图像匹配预训练模型CLIP的损失函数,即对象区域和文本标签匹配损失 (LOTM)、背景区域和文本标签匹配损失(LBTM)、共现背景抑制损失(LCBS)和区域正则化损失(LREG)。核心思想是通过文本驱动评估器的监督来学习初始CAM图的生成。首先,给定一张图像,主干网络预测初始 CAM图p,它表示每个像素属于一个类别的概率,如图5(a)所示。然后将p与输入图像X相乘后的结果,作为文本驱动评估器的输入,如图5(b) 所示。将掩码后的结果及其对应的文本类别标签分别输入到 CLIP 模型的图像编码器提取特征向量vkio以及文本编码器提取特征向量vkto并计算它们之间的余弦相似度。我们可以根据数据集定义前景对象的文本标签,例如“train”、“cat”和“person”等。在训练期间,L_OTM 旨在最大化前景对象区域和给定文本标签之间的相似性:
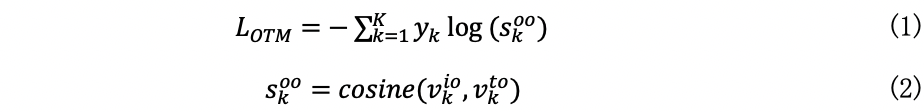
L_OTM虽然能使CAM图可以逐渐接近图像中的目标对象,但不能保证物体激活区域的完整性。例如,即使只有鸟的头部可见,图像仍然可以被CLIP模型识别成一只鸟。因此,我们提出L_BTM来最小化掩码前景区域后的X*(1-p) 和给定文本标签之间的相似性:

这可以去除 1-p中激活的物体区域,即在p中激活更多可能的物体区域。然而,当物体区域被激活时,与物体密切相关的背景,例如火车和铁路、船和河流等,通常也会被激活,因为没有可用像素级标签。为了解决这个问题,我们额外定义了一组与类相关的背景文本标签,例如“railroad”(火车的共现背景)和“river”(船的共现背景)等。基于这些文本标签,我们设计了L_CBS以最小化X*p和这些同时出现的背景文本标签提取的特征向量vkio和vktb的相似性:

这使得CLIMS 能够抑制CAM中与类别相关的背景,例如“railroad”。最后,为了保证类别激活图的紧凑性,我们设计了区域正则化损失LREG:
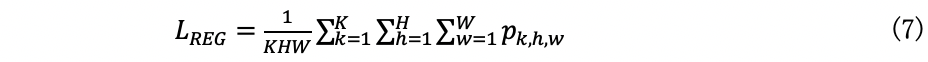
最终,整体损失如下:


图3 损失函数的消融实验效果图

图4 类别激活图和伪标签质量比较

图5 在PASCAL VOC2012数据集上的语义分割结果比较

图6 类别激活图的可视化比较
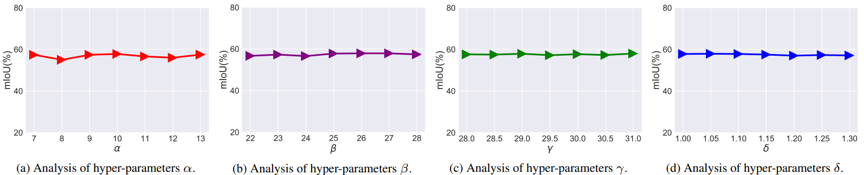
图7 损失函数超参数的敏感度分析
03
Make It Move: Controllable Image-to-Video Generation with Text Descriptions
作者:胡姚姒1,罗翀2,陈震中1
单位:1武汉大学, 2微软亚洲研究院
邮箱:
ys_hu@whu.edu.cn
cluo@microsoft.com
zzchen@whu.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2022/html/Hu_Make_It_Move_Controllable_Image-to-Video_Generation_With_Text_Descriptions_CVPR_2022_paper.html
数据集及代码:
https:// github.com/Youncy-Hu/MAGE
视频生成是计算机视觉中一个有吸引力但极具挑战性的课题。目前可控视频生成可分为图像到视频(I2V),视频到视频(V2V)以及文本到视频(T2V)三个分支,其对于视频外观和动作的控制分别有不同程度的侧重。为了实现更可控且细粒度的视频生成,本文提出了一种新颖的文本图像驱动的视频生成任务(Text-Image-to-Video generation, TI2V),旨在从一张静态图像和文本描述中生成相应的视频。
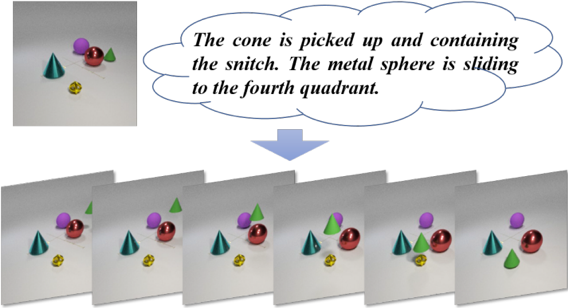
图1 TI2V任务示例
TI2V任务的关键挑战在于对齐来自不同模态的外观和运动信息以及处理由模糊文本所带来的视频不确定性。为了应对这些挑战,本文提出了一个基于运动锚点的视频自回归生成模型(MAGE),如图2所示,通过运动锚点实现图像与文本的语义对齐,并以时空对齐的方式驱动视频生成。同时,该模型通过引入显式条件以及隐式随机性,分别实现对视频速度的控制以及模糊文本下的多样化视频生成。
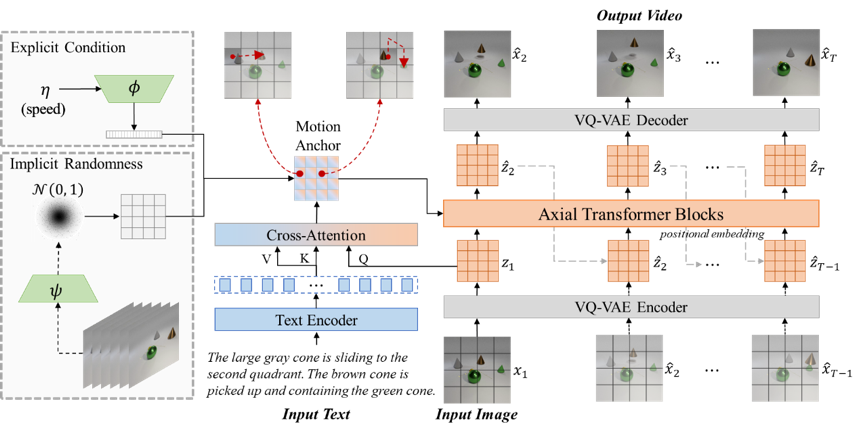
图2 Motion Anchor-based video Generator (MAGE) 网络框架
此外,本文针对TI2V任务基于MNIST和CATER构建了如图3所示的视频-文本对数据集,其中CATER-GENs数据集除提供精确文本外,同时提供了模糊文本用以模拟文本中对指称表达和动作表达的不确定性。实验结果表明MAGE在确定性视频生成和多样化视频生成中均能取得令人满意的效果,同时也可实现对视频速度的有效控制,验证了MAGE模型的有效性,同时也表现了TI2V任务的巨大潜力。

图3 Modified Double Moving MNIST和CATER-GENs数据集示例
04
DF-GAN: A Simple and Effective Baseline for Text-to-Image Synthesis
作者:陶明,唐浩,吴飞,荆晓远,鲍秉坤,徐常胜
单位:南京邮电大学,苏黎世联邦理工学院,武汉大学,中科院自动化所
邮箱:
,
bingkunbao@njupt.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2022/papers/Tao_DF-GAN_A_Simple_and_Effective_Baseline_for_Text-to-Image_Synthesis_CVPR_2022_paper.pdf
代码:
https://github.com/tobran/DF-GAN
根据文本生成图像任务要求计算机能够由文本生成对应的图片,该任务会给定一段文本,要求模型能够充分理解文本中蕴含的语义信息,并将文本中的语义信息映射为图像中对应的视觉信息,从而得到真实且符合文本描述的图像。当前文本到图像的生成模型基于堆叠式架构生成高分辨率图片,采用跨模态注意力机制融合文本与图片学习,引入额外的语义监督网络监督文本与生成图像的语义一致性。然而,堆叠式架构会造成不同尺度特征的纠缠;跨模态注意力机制融合不充分;额外的语义监督网络容易被生成器生成对抗特征。

为此,我们提出了一个简单且有效的一阶段文本到图像生成框架,它可以直接由文本生成高分辨率的图片,避免了堆叠式架构带来的特征纠缠问题。在生成器中,我们提出了一个深度文本-图像融合模块,通过堆叠基于文本的图像仿射变化,加深了文本与图像的特征融合,从而使得文本信息能够更好的表达在图片中。在判别器中,我们提出了一个目标感知判别器,它由两部分组成,包括一个匹配感知梯度惩罚策略和一个单路判别器。这两个模块构造了一个利于收敛到目标图片的判别器损失曲面,使得模型可以更快且稳定地收敛,从而使得模型得到更好的优化。
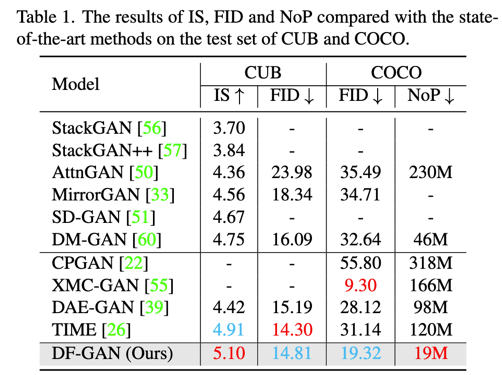
在实验中,我们对比了以往的模型,我们采用了IS和FID来衡量模型生成图片的质量,可以看到我们的模型在CUB数据集和COCO数据集上,都取得了非常好的结果,同时,我们模型的参数量(NoP)也比以往的模型少了很多。实验结果表明我们的DF-GAN是一个简单,轻量且有效的文本到图像生成模型。

对比不同模型生成的结果,也可以看出我们的模型生成的图片更加的真实,在COCO这种复杂图像上的表现是物体的形状和布局更加合理,在CUB这种只有单物体的图像上的表现是我们的DF-GAN生成的结果具备更多且更真实的细节。
05
Multi-Scale Spatial and Temporal Speech Associations to Swallowing for Dysphagia Screening
作者:何飞1,胡晓意2,朱策1,李颖2, 刘翼鹏1
单位:1电子科技大学,2四川大学华西医院
邮箱:
feihe@std.uestc.edu.cn;
6913570@qq.com;
eczhu@uestc.edu.cn;
yingli@scu.edu.cn;
yipengliu@uestc.edu.cn
论文及补充材料:
https://ieeexplore.ieee.org/document/9870749
吞咽障碍是指吞咽器官功能减退,食物不能安全顺利的从口进入胃中。流行病学调查显示,吞咽障碍在社区老年人群中的患病率为13.9%,养老机构和医院为26.4%,其易引发误吸、吸入性肺炎和营养不良等并发症,甚至导致窒息、猝死等严重后果。尽早筛查和诊断吞咽障碍,并针对性进行干预,可以明显降低吞咽障碍并发症的发生。临床通过在X光下观察患者吞食不同性状造影剂食品的状态诊断吞咽障碍,这不仅增加老年人误吸的风险,还存在放射暴露风险,只能在特定的医院进行,导致吞咽障碍诊断率很低。临床迫切需要寻找准确、无创的吞咽障碍诊断技术。
本文立足于吞咽与发声联系,使用基于骨传导的喉部振动传感器采集多类型高质量语音信号,包括多元音、简单句及绕口令,致力于探索有效的吞咽障碍语音生物标记。本研究基于元音及长句的声学特点提出了不同的特征提取算法,所提特征覆盖语音信号多尺度时频域信息,综合信号的全局变化及局部时频变化以检测伴随吞咽障碍的特异性发声模式。同时,本文还提出了针对二分类任务的特征筛选方法,以捕捉吞咽障碍患者语音与健康对照组语音之间的特异性特征,辅助模型学习。本文总流程图如下:
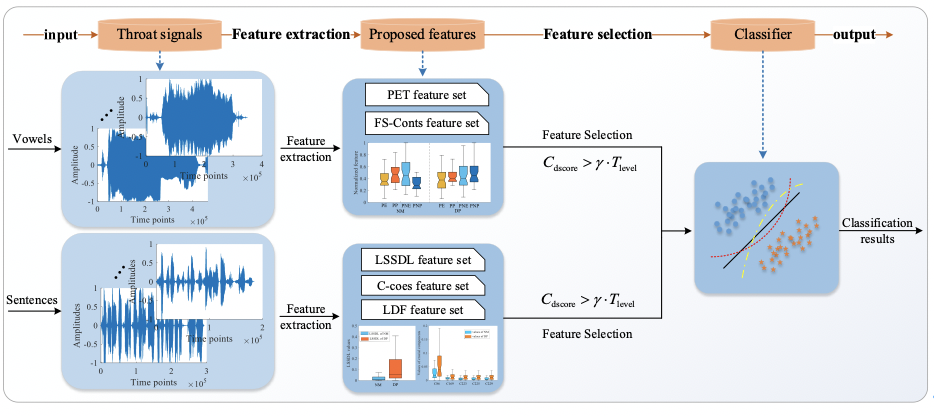
图1 吞咽障碍自动筛查系统实现流程图
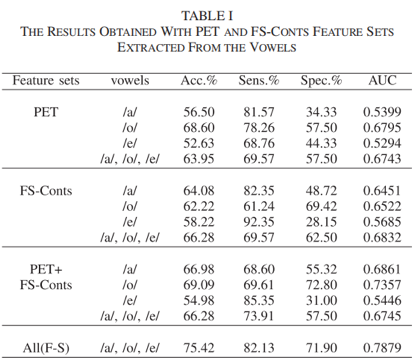
1)基于元音对发音位置敏感、具有基音周期性等特性,本文提出了两个关键特征集。第一个特征集为PET ,该特征集通过语谱图估计基频及定位最大瞬时能量以反映基频及能量变化;第二个特征集为FS-Conts,该特征集创新性地结合了三维等高线提取算法以计算语音的关键成分、估计共振峰等特征信息,具有突出的全局时频特征及局部动态特征提取优势。通过等高线算法计算得到的元音主要频谱成分图如下:


图2 元音/o/语谱的3D等高线信息图
2)基于简单句及绕口令包含语音长时动态信息的特点,提出了三个新的特征集,分别为LSSDL,C-coes和LDF。这三个特征分别立足于整体谱分布特性、局部频段能量分布特性及短时动态分布特征集,实现了语音信号从整体到局部的特征提取。
为了探索具有更优分类性能的特征组合,本文提出了一套新的特征选择方法。该特征选择方法包含两个阶段,第一阶段实现粗筛选,通过T检验以较大的α值筛选具有组间差异的特征;第二阶段通过提出的PMA算法对特征逐一评分,可根据需求输出不同评分的特征集。该特征筛选方法实现框图如下:

图3 吞咽障碍自动筛查系统实现流程图
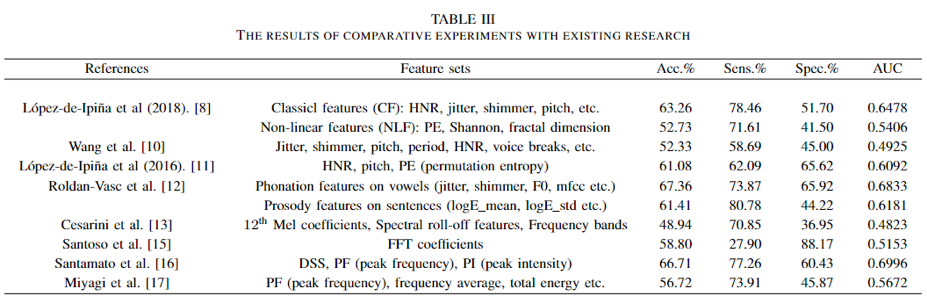
基于所提特征集,结合特征筛选方法,所得实验结果如下表一至表三。结果表明文章所提方法相比现有方法具有更优的吞咽障碍检测性能,且模型具有较优的鲁棒性。

06
Remember Intentions: Retrospective-Memory-based Trajectory Prediction
作者:徐晨鑫† 1,毛伟波† 1,张文军1,陈思衡1,2
单位:1上海交通大学,2上海人工智能实验室
邮箱:
xcxwakaka@sjtu.edu.cn
kirino.mao@sjtu.edu.cn
sihengc@sjtu.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2022/html/Xu_Remember_Intentions_Retrospective-Memory-Based_Trajectory_Prediction_CVPR_2022_paper.html
代码:
https://github.com/MediaBrain-SJTU/MemoNet
论文讲解:
https://zhuanlan.zhihu.com/p/492362530
†共同一作
研究背景
这是一项将记忆机制应用于轨迹预测任务的工作。轨迹预测需要从给定智能体历史位置信息的情况下预测其未来可能会出现的位置。人脑中的回溯记忆机制主要由神经节(ganglia)和前额叶(prefrontal cortex)组成。其中,神经节负责处理当前信息,前额叶则存储了历史以往经验。该工作所提出的MemoNet模仿人类决策过程中的回溯记忆机制,将见过的场景信息即轨迹特征写入memory bank(即回溯记忆中的前额叶)。随后在遇到需要预测的场景时,MemoNet通过查询记忆中的类似场景信息(即回溯记忆中的神经节),并结合当前场景状态给出最终预测结果。
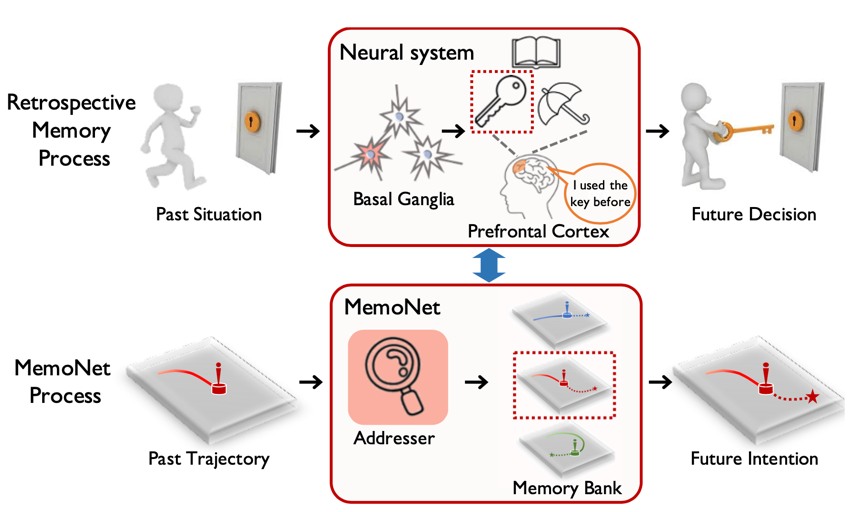
图1 本文提出的方法和回溯记忆机制的类比
本文方法
(1) Memory的生成
MemoNet中采用一对memory bank,分别存储过去轨迹的特征,以及未来意图的特征。因为由一条轨迹所拆分出来,过去和未来意图轨迹特征存在一一对应关系。为了得到这两项特征,我们使用下图所示的联合重建结构,对过去的轨迹和未来的轨迹进行联合重建,以此来得到过去轨迹和未来意图的特征编码器。利用该特征编码器对训练数据进行处理即可得到存储的memory。
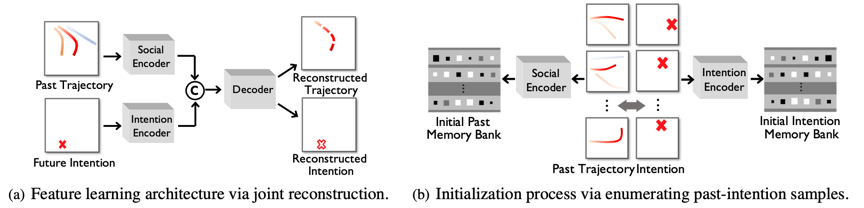
图2 memory的生成过程 (a) 过去-未来意图联合重建结构;(b) 特征编码器对训练数据进行处理
(2) Memory的寻址搜索
传统方法采用计算当前轨迹feature和past memory bank里features的余弦相似度来进行寻址。但是,任何预先定义好的距离函数,例如余弦函数,可能无法完全反映出两个特征向量之间的相似度。因此,我们引入了一个可学习的寻址器,期望能够“学习”出一种相似度衡量方式。其基本思路是使用找到的终点与真实终点的距离生成pseudo-label,作为可学习寻址器的监督信息。
(3) 多样性预测
为了使模型能关注到少量出现在记忆中的运动模态以及保证预测的多样性,我们采用了聚类的思想。我们从memory banks中读取较多数量的相似轨迹的意图,并最终聚类成需要数量的意图终点。
实验结果
(1)数值结果
我们在两个行人数据集SDD和ETH,以及一个NBA运动数据集上进行实验。在SDD数据集上,与之前的SOTA相比,我们取得了终点预测20.3%提升!在NBA和ETH数据集上,我们也取得了不小的提升。尤其是在ETH数据集上,部分研究者认为该数据集上的提升很难再超过5%,但我们取得了10.2%的终点预测提升。
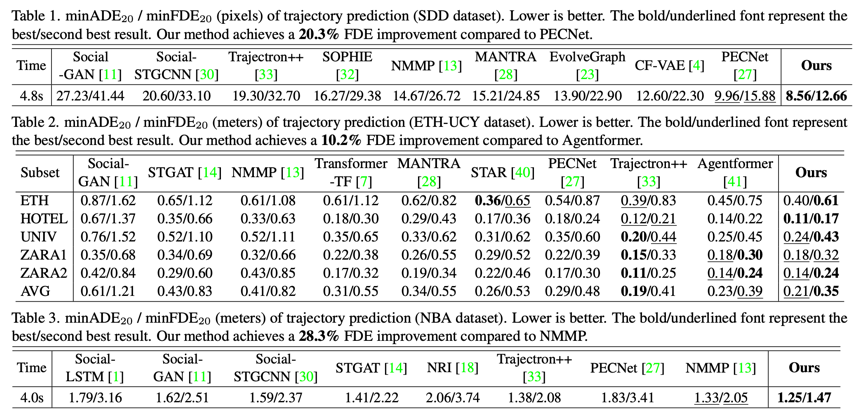
图3 SDD, ETH, NBA数据集预测效果对比
(2)可视化结果
我们展现了三个较难场景下进行预测的可视化示例。可以看到,即使在这些较难的场景下,MemoNet依然能给出一条比较贴合真实未来轨迹的预测。
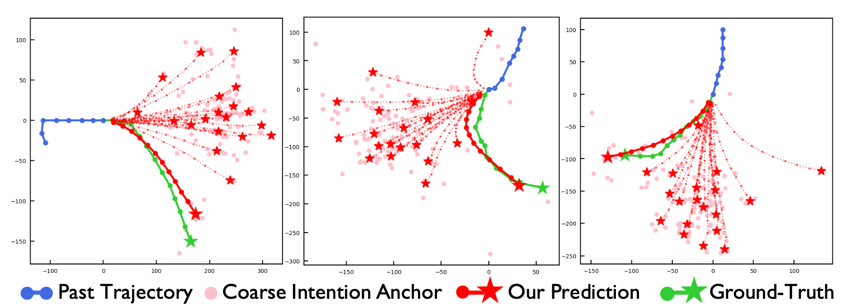
图4 MemoNet的预测实例
下图展现了MemoNet所搭建的当前场景和历史场景的链接,即回溯机制。这种回溯机制也给预测过程增加了可解释性。

图5 MemoNet回溯机制。即其是回忆了何条历史轨迹,才给出当前预测。

 京公网安备11010802017125号
京公网安备11010802017125号