
2022年论文导读第二十期
【论文导读】2022年论文导读第二十期
CCF多媒体专委会 2022-10-04 12:32 发表于吉林


论文导读
2022年论文导读第二十期(总第六十期)
目 录
|
1 |
Neural Points: Point Cloud Representation with Neural Fields for Arbitrary Upsampling |
|
2 |
NeRF-Editing: Geometry Editing of Neural Radiance Fields |
|
3 |
Divide and Conquer: Compositional Experts for Generalized Novel Class Discovery |
|
4 |
Reliable Inlier Evaluation for Unsupervised Point Cloud Registration |
|
5 |
Salvage of Supervision in Weakly Supervised Object Detection |
01
Neural Points: Point Cloud Representation with Neural Fields for Arbitrary Upsampling
作者:冯万泉1,李金2, 蔡泓锐1, 罗笑南2, 张举勇1
单位:1中国科学技术大学,2桂林电子科技大学
邮箱:
lcfwq@mail.ustc.edu.cn,
20032201014@mails.guet.edu.cn,
hrcai@mail.ustc.edu.cn,
luoxn@guet.edu.cn,
juyong@ustc.edu.cn
论文:
https://arxiv.org/abs/2112.04148
代码:
https://github.com/WanquanF/NeuralPoints
1. 论文动机

图1 不同于现有点云表示每个顶点仅表示一个空间位置,神经点云表示中每个顶点表示一个复杂的局部几何曲面
点云是三维场景的基本表示形式,被广泛应用于场景重建,虚拟/增强现实和自动驾驶等诸多应用中。在传统的点云表示中,每个点只表示三维空间中的一个位置,如果配合其法向量,也仅表示为一个局部平面区域。因此,点云的表达能力受其分辨率的限制。针对输入的低分辨率点云,研究者提出对其进行上采样以获得高分辨率点云,该方式提高了点云的表达能力,但这一类方法仍然采用的是“离散到离散”的方式,无法克服现有点云表示离散的本质与缺陷。
针对上述问题,中国科学技术大学和桂林电子科技大学提出了神经点云(Neural Points),一种基于局部神经隐式场的点云表示方式,该工作发表于CVPR 2022。不同于传统点云表示,Neural Points 的每个点通过神经场表示了一个局部连续曲面。具体来说,每个局部曲面都表示为二维参数域和三维局部曲面之间的局部同构,该同构通过神经场隐式表示。相比传统离散点云表示,Neural Points具有如下优势:
(1) 不受有限分辨率的限制,所采用的连续表示使其本质上表达了一个连续曲面;
(2) 所构建的局部神经场可以表示复杂的几何形状
(3)所有局部曲面共享同一个神经场模型,因此Neural Points的存储开销小;
(4) 有较强的泛化能力,预训练模型可以直接使用在未见过的模型上。
图1展示了Neural Points在每个点处所构建的神经场。网络从局部点云中提取特征并通过神经场生成局部面片。可以看到所生成面片(第二行)很好地拟合了潜在曲面(第一行)的形状,这也体现了Neural Points表示对点云潜在曲面的良好表达能力。图2展示了Neural Points的连续上采样效果。可以看到,Neural Points可以产生高质量的连续曲面,并很好地克服了分辨率的限制。
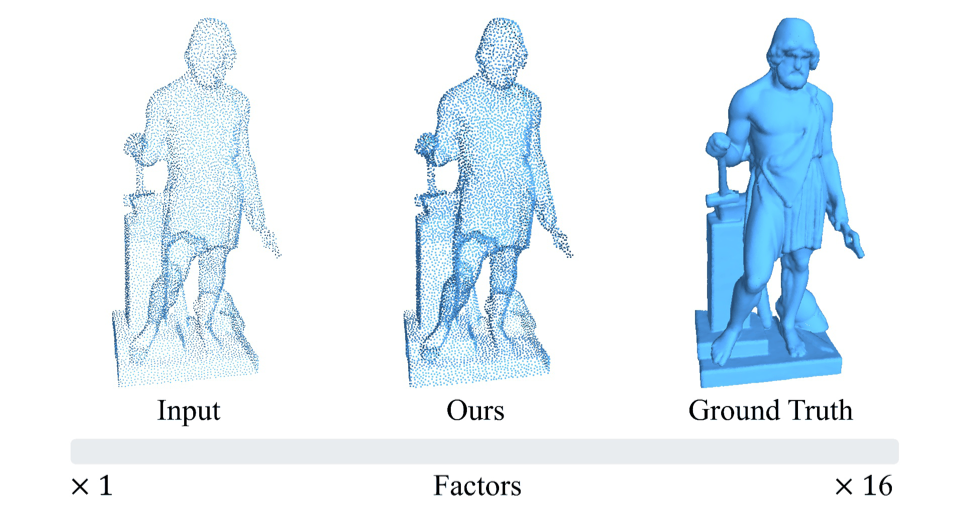
图2 所提出的Neural Points方法对输入的稀疏离散点云进行连续上采样,横轴表示渐变的上采样
2. 创新点
(1) 提出Neural Points,一种新颖的点云表示,可以应用于点云重采样等任务,表达能力优于传统点云表示,且存储开销低;
(2) 使用神经隐函数与局部曲面的深层局部特征来表示局部神经场,并设计了一种聚合策略来形成最终的全局几何形状;
评估结果表明,Neural Points表示对各种输入具有出色的鲁棒性和泛化能力。将Neural Points应用于点云重采样等任务上展示了惊艳的性能。
3. 方法描述
图3展示了本文的算法管线:(1) 给定输入点云,首先为每个局部面片构建局部神经隐式场; (2) 将局部神经场聚合在一起形成全局形状; (3) 通过构建的连续神经表示,可以重采样任意数量的点。

图3 本论文的算法管线。对于输入的点云,对每个顶点构造器局部神经隐私场,对局部神经隐式场进行拼接整合,获得完整的模型。由于其连续曲面表示的本质,可以对其进行任意分辨率采样。
3.1 局部神经场
将输入点云表示为X={xi}Ii=1。本文以为中心点将曲面划分为重叠的局部块{Pi}Ii=1⊂R3。 在每个点xi,3D局部面片Pi同构于2D参数域D⊂R2(本文使用D=[-1,1]2),这意味着可以在它们之间构造一个双射映射:

其中ψi|Pi=φ-1i。局部神经场的示意图如图4所示。
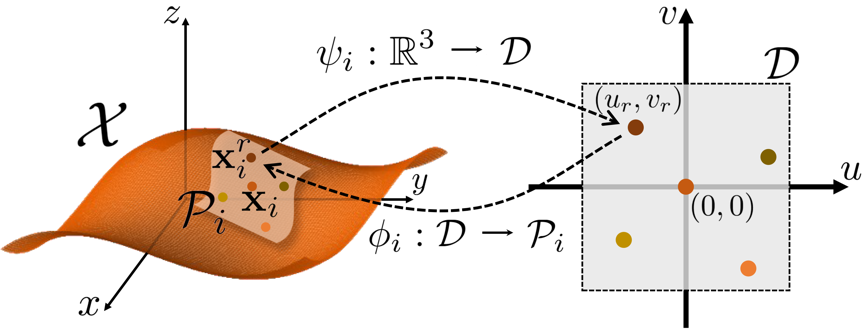
图4 局部神经场的示意图
给定任意二维采样点(ur,vr)∈D,可以计算xri=φi(ur,vr)∈Pi作为其对应的 3D采样点。 类似地,对于任何3D点xri∈Pi,本文计算其对应的2D坐标(ur,vr)=ψi(xi)∈D。 此外,可以计算点xri处的法向:

然后将其标准化为单位长度。
3.2 神经场聚合。
进一步地,本文将不同的曲面块聚合在一起以获得全局连续隐式表示,其公式形如:

其中x为任意三维点, wk的计算依赖于x到各个局部面片的距离。法向可以类似计算。这样就获得了全局连续隐式表示。
3.3 点云采样。
之后是具体的点云采样环节。本文在2D参数域 中均匀地采样点,并将2D采样点映射到3D局部面片上。 具体来说,对于在每个中心点xi的附近采样{(ur,vr)∈D}Rr=1,然后将它们映射3D为{xri∈Pi}Rr=1。之后,本文从所有局部面片采样点的并集中进行均匀采样以获得所需的结果。
3.4 网络及损失函数。
本文方法在每个中心点xi的附近邻居点云上提取深度特征,使其代表局部的几何形状;局部的神经场则用MLP来实现,其输入包括二维查询点和局部形状特征两方面。至于Loss,本文设计了形状约束,法向约束,还有使得聚合效果得到保证的聚合项。
4. 实验结果
本文首先在Sketchfab数据集上进行训练和测试,一些对比结果如图5所示。可以看到之前的方法会造成一些分布混乱、噪声和异常值,而本文可得到最平滑、最接近真实值的结果。

图5 Sketchfab数据集上的结果与对比实验。
图6展示了一些将模型未经重训练直接泛化到PU- GAN数据集上的结果:

图6 直接泛化到PU-GAN数据集上的结果与对比实验。
图7展示了在非常大的采样因子下,各种方法的结果和对比:
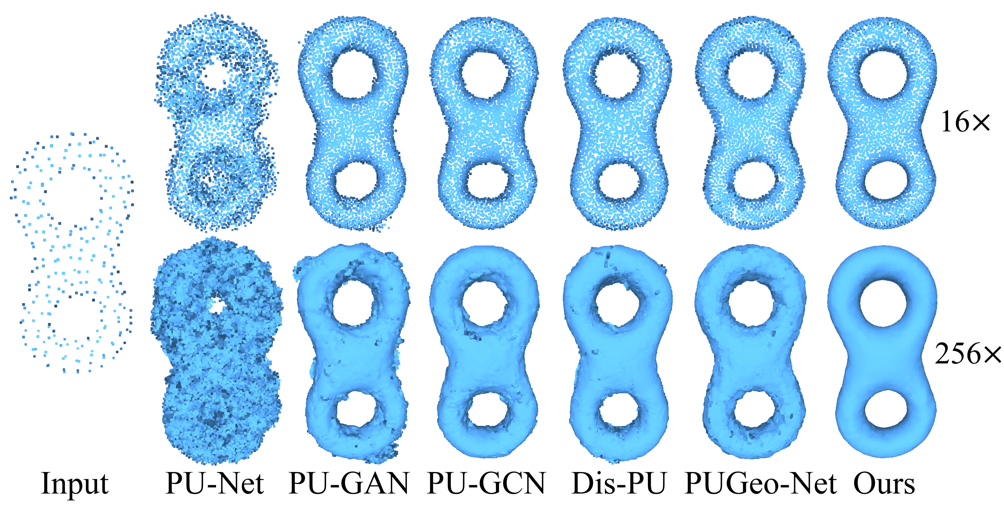
图7 在稀疏点云输入下,极大采样因子的上采样结果。
图8展示了在真实扫描的数据上的结果和对比:

图8 在iPhone X手机所采集的真实点云数据上的测试结果。
02
NeRF-Editing: Geometry Editing of Neural Radiance Fields
作者:袁宇杰1,2, †,孙阳天1,2, †,来煜坤3,马岳文4,贾荣飞4,高林1,2,*
单位:1中科院计算技术研究所,2中国科学院大学,3卡迪夫大学,4阿里巴巴集团
邮箱:
gaolin@ict.ac.cn
yuanyujie@ict.ac.cn
论文及补充材料:
https://openaccess.thecvf.com/content/CVPR2022/html/Yuan_NeRF-Editing_Geometry_Editing_of_Neural_Radiance_Fields_CVPR_2022_paper.html
项目主页:
http://geometrylearning.com/NeRFEditing/
代码:
https://github.com/IGLICT/NeRF-Editing
论文详解:
https://mp.weixin.qq.com/s/GowqzalR25Tx_5sar82y9A
†共同作者,*通讯作者
研究背景
神经辐射场(NeRF)作为一种隐式建模场景几何和外观的方法,因其简单的结构和令人振奋的渲染结果,受到了广泛关注。不同于传统的网格表示,用户无法直观地改变神经辐射场建模的几何形状。现有的神经辐射场编辑工作Editing Conditional Radiance Fields只能局限于颜色编辑和简单地添加/删除局部的几何模块,无法实现对几何形状的变形。为了解决神经辐射场的几何变形问题,我们在CVPR 2022上提出了一种能够变形编辑神经辐射场几何内容的方法,效果如图1所示。

图1 编辑前后神经辐射场渲染结果
方法概述
我们的算法流程如图2所示。在训练好的神经辐射场网络中提取显式的三角网格表示后,用户在显式网格表示上指定控制点,并通过移动控制点进行变形编辑。我们提出了一个两步传播框架,利用变形前后网格的对应关系,将离散表面网格上的变形编辑传播到整个连续空间。通过弯曲体渲染投射的光线,即可让神经辐射场渲染出符合用户编辑预期的结果。
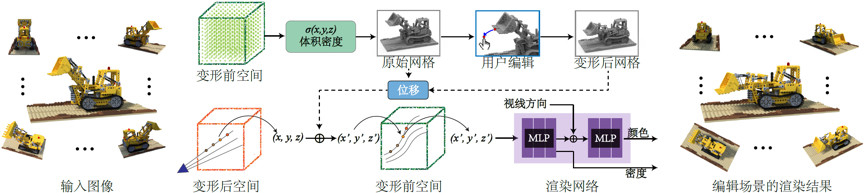
图2 神经辐射场变形方法示意图
我们使用ARAP (as-rigid-as-possible) 变形方法来实现对网格的交互式编辑。提出的变形传播框架如图3所示。先生成一个包裹三角网格的笼状网格,并进一步将笼状网格四面体化得到空间的离散体表示。利用三角形网格顶点的位移来驱动四面体网格的变形,得到变形后的四面体网格。在渲染的过程中,对于光线上的每个采样点,都可以找到它在变形四面体网格中对应的四面体。利用变形前后的对应关系,可以插值出采样点相对于标准神经辐射场空间的位移值,将采样点变换回标准神经辐射场空间,实现对光线的弯曲。

图3 将离散的网格顶点变形传播到连续空间
实验结果
图4展示了提出方法在合成场景上的编辑结果。用户可以将乐高推土机的铲子放下,或者拉伸椅子的靠背和腿,实现对物体局部部件的编辑。

图4 合成数据上编辑结果
图5展示了在多个真实和合成物体上的编辑结果。我们的方法可以通过插值编辑前后的状态,实现静态神经辐射场动态化,用户拍摄的静态物体将变得栩栩如生。

图5 将静态神经辐射场动态化,使物体栩栩如生
提出方法还能做一些有趣的应用,比如将视频中人的头部运动迁移到一个人脸雕塑上,如图6所示。

图6 利用人脸视频驱动人脸雕塑
综上,我们提出了一种能让用户直观编辑神经辐射场的几何形状的方法,编辑后的结果仍支持自由视角浏览。
03
Divide and Conquer: Compositional Experts for Generalized Novel Class Discovery
分而治之:用于广义新类发现的组合专家模型
作者:杨木李,朱跃华,于佳平,武阿明,邓成
单位:西安电子科技大学
邮箱:
mlyang@stu.xidian.edu.cn
yuehuazhu@stu.xidian.edu.cn
jpyu@stu.xidian.edu.cn
amwu@xidian.edu.cn
chdeng@mail.xidian.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2022/html/Yang_Divide_and_Conquer_Compositional_Experts_for_Generalized_Novel_Class_Discovery_CVPR_2022_paper.html
代码:
https://github.com/muliyangm/ComEx
随着海量无标签数据的爆炸式增长,数据标注的成本也越发高昂。新类发现[1]旨在训练数据给定的已知类别之外,发现测试数据中的全新未知类别,为充分利用无标签数据提供了新的思路。新类发现通常依赖两阶段的训练过程:(1)在训练数据上训练一个基础的已知类别分类模型;(2)在测试数据上进行模型微调,并以无监督聚类的方式实现新类发现。
由此可见,新类发现的一大挑战在于如何将已知类的知识迁移到未知类中。以[2]为代表的早期方法通常利用第一阶段训练得到的基础模型挖掘测试数据的成对相似信息,并以此作为监督信号指导新类发现。近来,[3]提出了一个统一的新类发现框架,使用同一个分类损失来同时优化已知类和未知类的数据(其中未知类的监督信息采用最优传输[4,5]打伪标签的方案获得),隐式而高效地实现了知识迁移的目标。
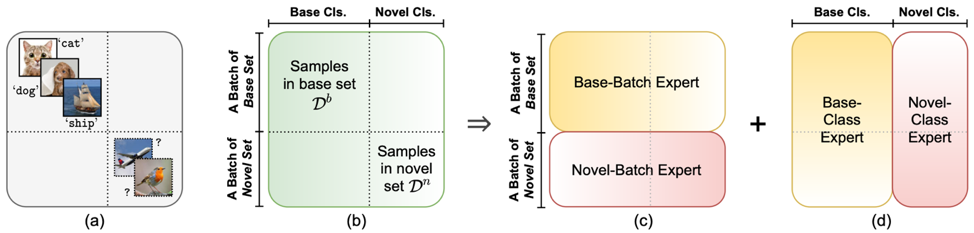
图1 任务设定与方法动机
本文以此为基础,并针对前作不重视已知类分类性能的问题,着重研究了广义新类发现,要求最终的模型同时在已知类和未知类上表现出色。为了实现这一目标,如图1(a),我们以批次-类别(batch-class)的视角重新分析了新类发现的训练方式。以已知和未知为划分准则,我们发现,训练数据在四象限中占据对角线区域,如图1(b)。从[3]的成功经验可知,同时优化已知类和未知类是实现知识迁移的关键;为了进一步促进这一目标,我们在图1(b)的基础上设计两组专家模型,分别针对批次维度(batch-wise,图1(c))和类别维度(class-wise,图1(d))进行知识迁移,提升了广义新类发现的性能。
除此之外,我们还重新审视了利用最优传输[4,5]获得伪标签的缺陷,并提出一种简单而高效的改进策略,进一步提升了新类发现的性能。具体而言,我们认为传统的最优传输方法仅建立了样本与聚类中心的全局关系,忽略了样本与样本之间的局部关系,因此获得的伪标签并不鲁棒,影响模型在新类上的表现。我们提出维护一个小尺寸的队列,以先进先出的方式存储新类数据的特征-伪标签字典,并以此确保后续的伪标签生成满足“相似的特征对应一致的伪标签”这一准则。

图2 t-SNE特征可视化
本文所提方法在多个标准新类发现数据集(尤其是广义新类发现设定)上均取得了优异的表现。图2使用t-SNE的方式可视化了不同专家模型学习得到的特征,可以发现,类别维度(class-wise)的专家模型由于具有类别上的精细分工,因此展现出更优的类间可分性(图2(d),不同类别的簇散得更开),但对外观相似而类别不同的困难样本容易过拟合(如红框所示的dog和horse);而批次维度(batch-wise)的专家模型由于所见类别更全,在分类上显得更为谨慎(less-confident),但反而对图2(c)红框中易混淆的困难样本表现更好。
参考文献
[1] Learning to discover novel visual categories via deep transfer clustering. In Proc. ICCV, 2019
[2] Automatically discovering and learning new visual categories with ranking statistics. In Proc. ICLR, 2020.
[3] A unified objective for novel class discovery. In Proc. ICCV, 2021
[4] Self-labelling via simultaneous clustering and representation learning. In Proc. ICLR, 2020
[5] Unsupervised learning of visual features by contrasting cluster assignments. In Proc. NeurIPS, 2020.
04
Reliable Inlier Evaluation for Unsupervised Point Cloud Registration
作者:沈雅琦,惠乐,蒋豪博, 谢晋*,杨健
单位:南京理工大学
邮箱:
syq@njust.edu.cn;
le.hui@njust.edu.cn;
jiang.hao.bo@njust.edu.cn;
csjxie@njust.edu.cn;
csjyang@njust.edu.cn
论文:
https://www.aaai.org/AAAI22Papers/AAAI-4754.ShenY.pdf
代码:
https://github.com/supersyq/RIENet
*通讯作者
1.研究动机
由于缺乏有效的外点排除机制,无监督点云配准算法在处理部分重叠的点云配准问题时往往精度较差。本文针对鲁棒的无监督点云配准问题,提出了一种基于邻域一致性的可靠内点鉴别方法,其中邻域一致性要求对应点周围的邻居点也应当是匹配关系,外点必然与邻居点的匹配关系不一致,从而在源点云邻域与匹配的目标点云邻域形成很大的几何结构差异(图1)。本文基于邻域一致性实现有效的外点排除,从而实现无监督的点云配准。

图1 内外点示例
2.论文概述

图2 网络框架
该方法通过捕捉源点云的邻域与相应伪目标点云邻域(在目标点云上预测的匹配区域)之间的几何结构差异,以实现有效的内点鉴别。具体地说,我们的模型由一个匹配矩阵的细化模块和一个内点评估模块组成(图2)。
在我们的匹配矩阵细化模块中,我们通过将邻域点的匹配分数集成到匹配矩阵估计中来改进点级别的匹配矩阵的估计。聚合的邻域信息潜在地去除了部分噪声,从而生成更可靠的匹配点对。基于观察到离群值的源邻域和相应的伪目标邻域之间存在显著的结构差异,而内点的这种结构差异很小,因此内点评估模块利用这种差异对每个估计的匹配对进行评分,学习到[0,1]之间的一个置信度,越接近0表示可靠性差,越靠近1表示可靠性高。值得一提的是,我们构造了一个有效的图结构来捕捉邻域之间的几何差异以辅助内外点的评估。最后,利用学习到的匹配对和对应的置信度,使用加权的SVD算法进行刚体变换的估计。
在无监督的条件下,利用基于Huber函数的全局对齐损失、局部邻域一致损失和空间一致性损失进行模型优化。
(1)全局对齐损失:
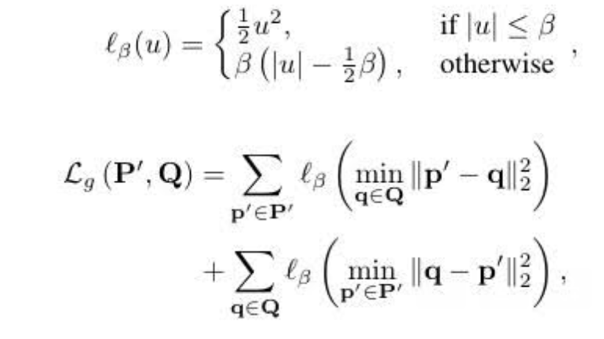
(2)邻域一致性损失:

(3)空间一致性损失:
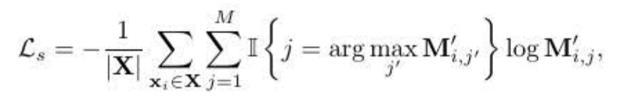
3.实验结果
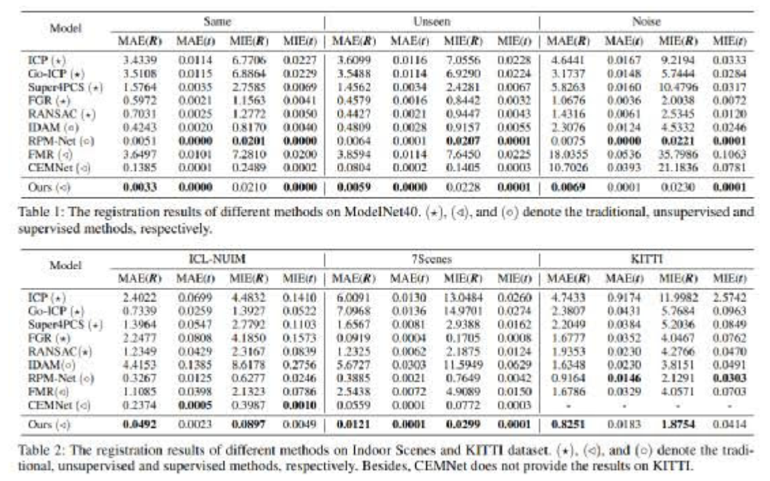
我们在多个数据集上衡量了我们方法的有效性。通过大量的实验证明了我们的无监督点云配准方法可以获得不错的性能。结果如下表所示:
表1 多个数据集上的点云匹配结果
4.可视化结果
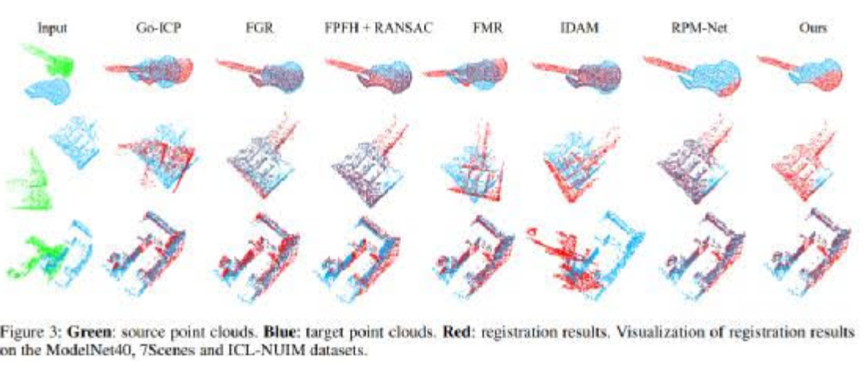
图3 多个数据集上的点云匹配结果可视化
05
Salvage of Supervision in Weakly Supervised Object Detection
作者:隋霖, 张晨麟, 吴建鑫
单位:南京大学计算机软件新技术国家重点实验室
邮箱:
suilin0432@gmail.com,
zclnjucs@gmail.com,
wujx2001@gmail.com
论文链接:
https://openaccess.thecvf.com/content/CVPR2022/html/Sui_Salvage_of_Supervision_in_Weakly_Supervised_Object_Detection_CVPR_2022_paper.html
准确标注的大规模数据集为目标检测领域带来了显著的性能提升, 但是存在获取成本极高的问题. 因此只依赖于图像级别标注的弱监督目标检测(WSOD)受到越来越多的关注. 我们提出的 SoS-WSOD 是一个全新的弱监督目标检测训练框架。
1. SoS-WSOD 强调在利用图像级别标注的基础上, 进一步从数据中去挖掘潜在的有价值的监督信号. 通过利用图像级别标注、挖掘到的伪标记, 以及进一步深度挖掘的高质量的伪标记, 弱监督目标检测器能够从其中分别获得显著的性能提升。
2. 弱监督目标检测与全监督目标检测(通用目标检测)存在着比较大的技术上的差距, 在WSOD中引入使用更新更强的骨干网络(如 ResNet)、模型结构(如 FPN)以及模块设计(如 RoIAlign) 会导致性能的大幅下降. SoS-WSOD 在利用监督信号的过程中能够自然的缩减技术差距, 从而使WSOD 模型也能够享受到先进技术所带来的性能提升, 同时可以在推理阶段摆脱耗时的候选框(proposal)生成过程, 大幅度提升推理速度。
我们在弱监督目标检测主流数据集上进行了详尽的实验, 实验表明, 我们提出的 SoS-WSOD 具有显著的优势. SoS-WSOD 能够在 VOC2007, VOC2012 以及MS-COCO 三个数据集上将最优性能从 此前的56.8, 53.6, 26.4 mAP50 分别提升到 64.4 , 61.9, 32.8 mAP50.受益于技术差距的缩减, 还能够将推理速度从先前的 8.3s/img(候选框生成时间)+0.101s/img(网络推理时间)提升至 0.031s/img。

图1 SoS-WSOD 流程图
SoS-WSOD 是一个三阶段的训练框架, 在第一阶段中可以采取任意的弱监督目标检测模型作为起点去获取检测结果. 在获取检测结果后,通过我们提出的 PGF 算法产生较高质量的伪标记以提供给第二阶段去进行新网络的重新训练. 在第二阶段中, 通过使用同时关注召回率以及准确率的 PGF 产生的高质量伪标记, SoS-WSOD 可以自然地缩减与全监督目标检测的技术差距以享受性能提升. 此外我们关注到受限于弱监督检测器自身存在的问题, 伪标记中包含了大量的噪声. 因此, SoS-WSOD 在三阶段中从噪声学习的角度去看待伪标记数据集, 提出关注前景的划分损失, 将数据集进行划分, 干净的部分作为有标记的数据, 而将包含大量噪声的部分视为无标记的数据. 这样, SoS-WSOD 成功地构建了一个半监督学习问题去进一步的从数据中挖掘有价值的潜在监督信号。
除了在弱监督目标检测主流数据集上验证了 SoS-WSOD 的有效性, 我们同样进行了检测结果的可视化. 可以发现, 即使在复杂的场景下 SoS-WSOD 也能够挖掘到更多的正确检测结果。

图2 PASCAL VOC 数据集上性能比较

图3 MS-COCO 数据集上性能比较

图4 检测结果可视化, 第一行为真实标签, 第2-4行分别为三个阶段的检测结果, 最后一列为失败样例

 京公网安备11010802017125号
京公网安备11010802017125号