
2022年论文导读第二十一期
【论文导读】2022年论文导读第二十一期
CCF多媒体专委会 2022-10-18 09:00 发表于北京


论文导读
2022年论文导读第二十一期(总第六十一期)
目 录
|
1 |
Promoting Single-Modal Optical Flow Network for Diverse Cross-modal Flow Estimation |
|
2 |
GeomGCL: Geometric Graph Contrastive Learning for Molecular Property Prediction |
|
3 |
Multi-Modal Perception Attention Network with Self-Supervised Learning for Audio-Visual Speaker Tracking |
|
4 |
Probing Word Syntactic Representations in the Brain by a Feature Elimination Method |
|
5 |
Online Enhanced Semantic Hashing Towards Effective and Efficient Retrieval for Streaming Multi-Modal Data |
|
6 |
TA2N: Two-Stage Action Alignment Network for Few-Shot Action Recognition |
01
Promoting Single-Modal Optical Flow Network for Diverse Cross-modal Flow Estimation
作者:周诗力, 谭伟敏, 颜波
单位:复旦大学计算机学院,上海市智能信息处理重点实验室
邮箱:
slzhou19@fudan.edu.cn,
wmtan@fudan.edu.cn,
byan@fudan.edu.cn
论文:
https://www.aaai.org/AAAI22Papers/AAAI-4785.ZhouS.pdf
代码:
https://github.com/zslzx/CrossModalFlow
背景与挑战
在当前工业、生活场景中,存在着不同的图像传感器捕捉物体的多种模态信息,而由于采集设备限制,多模态图像间差异大,往往是非对齐的,因此需要进行跨模态图像匹配以便更好地融合不同模态。现已存在多种跨模态匹配方法,但这些方法存在一些局限性:1)只能获得稀疏匹配;2)仅针对特定的跨模态场景;3)一些传统方法实现复杂且性能低。
我们的目标是提出一种新的跨模态匹配模型,它兼具两方面优势:1)基于深度学习,高性能的同时实现简单易部署;2)具有良好的泛化性,不需要针对新的跨模态场景单独训练。这一目标的难点在于,由于深度学习的数据驱动特性,需要收集大量不同跨模态场景下的图片对,并且进行精确的匹配标注。显然,这是一项艰巨的任务,难以实现。
方法简述
通过引入高性能光流模型的先验知识和自监督训练框架,较好地绕过了训练数据短缺的限制。
一方面,提出了跨模态推广框架(Modality Promotion Framework,简记为MPF,如图1)。这一框架结合了自监督与知识蒸馏,只需要单模态、无标注的视频连续帧作为训练数据,通过数据增强来构造跨模态图片对,同时将光流模型作为教师模型进行模型蒸馏,从而得到跨模态流模型。
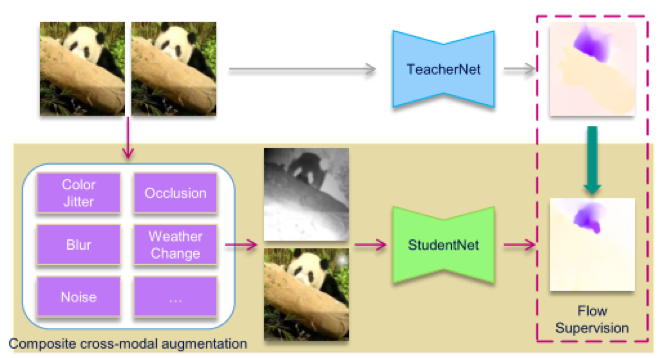
图1 跨模态推广框架
另一方面,还在光流模型RAFT的基础上,添加跨模态适配模块(Cross-Modal Adapter,简记为CMA,如图2),让模型获得针对不同跨模态输入进行自适应的特征提取的能力,进一步增强模型的泛化性和精度。我们将修改后的模型其命名为CrossRAFT。
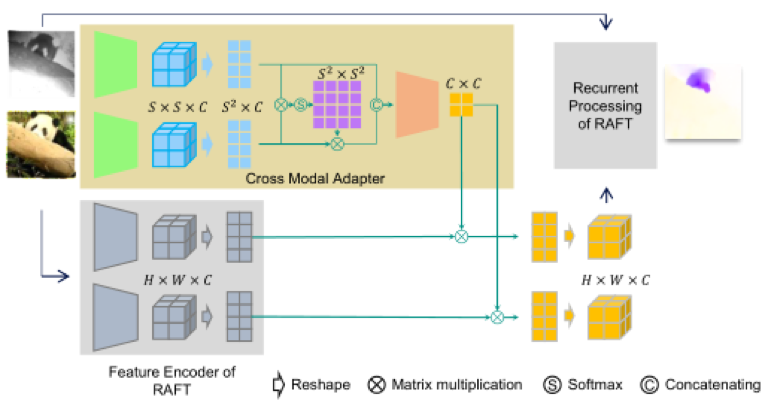
图2 带有跨模态适配模块的CrossRAFT
实验与结果
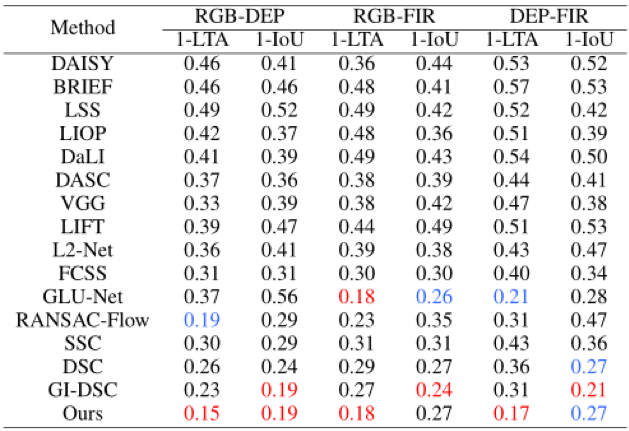
首先在RGBNIR-Stereo以及合成的CrossKITTI数据集上进行了消融实验,如表1、2。实验中,分别尝试了两种不同的光流模型baseline(PWC-Net与RAFT),实验中各项指标都是越低越好。实验结果展示了所提的MPF及CMA的有效性。我们在图3中提供了可视化样例。可以看到,对于跨模态输入,单模态光流模型不能产生正确的运动估计,而所提模型在多个跨模态场景下都有较好表现。
表1 RGBNIR-Stereo数据集上的消融实验

表2 CrossKITTI数据集上的消融实验
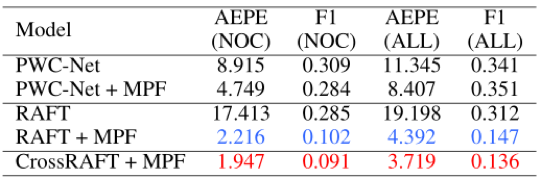

图3 单模态光流模型与跨模态流模型效果对比
此外,在RGBNIR-Stereo和TriModalHuman数据集上对比了所提方法与SOTA方法(见表3和表4)。结果表明,即使是与针对单一场景训练的专用模型相比,所提模型也具有很强的竞争力。值得注意的是,两张表中,我们的模型使用的是同一套参数,这证明了它的泛化能力。图4提供了一组可视化结果。
表3 在RGBNIR-Stereo数据集上与SOTA方法的对比
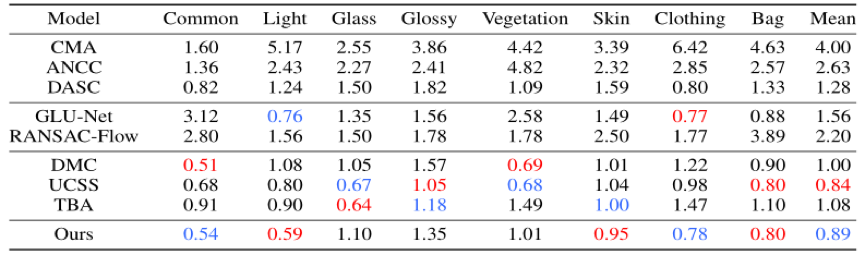

图4 不同方法在FIR-RGB和DEP-RGB场景下的对齐结果。
表4 在TriModalHuman数据集上与SOTA方法的对比。
02
GeomGCL: Geometric Graph Contrastive Learning for Molecular Property Prediction
基于二维和三维几何图对比学习的的分子性质预测
作者:李双利,周景博,徐童,窦德景,熊辉
单位:中国科学技术大学,百度研究院,香港科技大学(广州)
邮箱:
lsl1997@mail.ustc.edu.cn
zhoujingbo@baidu.com
tongxu@ustc.edu.cn
doudejing@baidu.com
xionghui@ust.hk
论文及补充材料:
https://ojs.aaai.org/index.php/AAAI/article/view/20377
代码:
https://github.com/agave233/GeomGCL
一、研究背景
在计算生物和计算化学领域,分子各种生化性质的准确预测对于药物研发等应用领域至关重要。然而在真实场景下,大部分数据往往是缺少标签的,传统的有监督学习算法不能利用这些数量巨大的缺失标签的分子进行学习。当前自监督的分子性质预测方法基本都是基于二维分子图设计预训练任务或者进行分子图的增强,一方面有效的预训练任务往往需要生物化学领域的专家知识进行精心设计,而分子图增强策略基本都会破坏分子本身的结构性质。另一方面,分子本质上是一个由多种类型原子相互作用构成的网络结构图,除了拓扑结构信息还包含关键的空间结构信息。当前大多数无监督的分子性质预测方法只考虑了二维视角的分子信息,没有将三维空间的分子图加入无监督学习框架进行有效学习。我们提出了一种新的二维-三维分子图对比学习框架,通过设计的双通道几何信息传递神经网络来充分捕获二维和三维视图下的距离和角度信息,然后提出了分子几何对比学习策略提升分子表征学习能力,多个分子数据集的实验结果证明了所提出的提出方法的有效性。
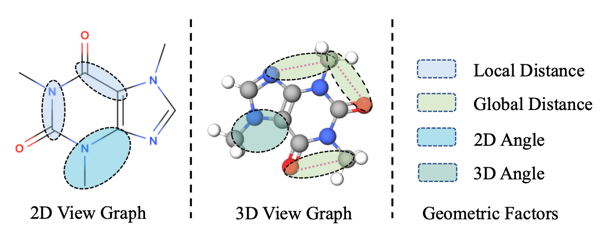
图1 二维视图和三维视图中的空间几何信息
二、方法概述

图2 二维-三维分子图对比学习的模型框架
如图2 所示,我们提出了一个全新的分子图对比学习框架,可以对大量无标签的分子数据进行自监督的学习,同时考虑了二维和三维结构下的分子图的拓扑信息和空间信息,基于图神经网络有效融合不同维度的空间特性对分子表征进行有效学习。给定一个SMILES形式的分子化学式,可以转换得到二维和三维两种视图的分子图。接着我们基于空间信息表征向量提出了自适应的几何消息传递框架来通过“节点—边”(Node-Edge)的交互方式实现同时高效学习分子的拓扑结构和空间几何信息。
尽管三维视图包含了更加丰富的空间信息,但由于构象生成的随机性导致三维视图可能与真实的空间分布相比存在噪声,为了充分提取有价值的空间信息,我们提出了二维和三维视图相互监督学习的双视图对比框架。对于每一个批次(batch)的输入,我们把同一分子生成的二维和三维视图作为一对正样本{zi2d,zi3d},而同批次其他分子的视图表征则都作为负样本。模型的学习目标则是最大化正样本之间的相对一致性,使得负样本之间尽可能差距变大。给定一个有N个分子的批次,二维—三维视图进行对比学习的损失函数为:
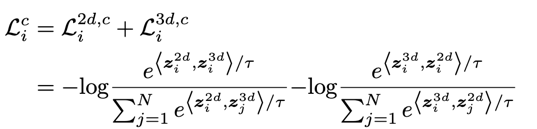
三、实验
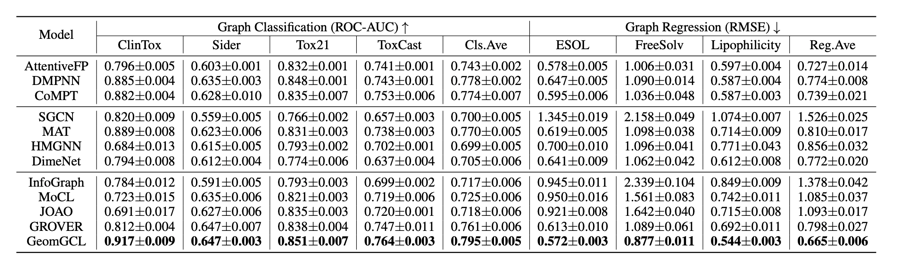
我们在多个分子数据集上的实验证明了所提出的对比学习框架可以显著提升分子性质的预测效果,表1表明了融合二维和三维分子视图不仅比有监督方法效果更佳,而且预测效果优于最新的无监督预训练模型和图对比学习方法。
表1 分子性质预测方法对比
此外,我们通过对二维和三维视图学习模块进行消融实验证明了充分融合两个维度的分子信息才能达到模型最优的预测效果,并且利用对比学习策略可以进一步提升效果。
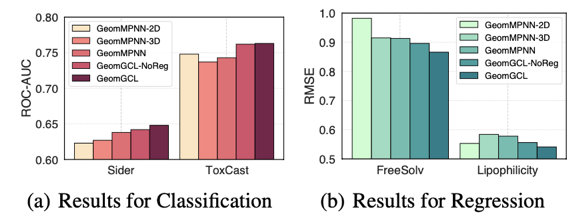
图4 消融实验
03
Multi-Modal Perception Attention Network with Self-Supervised Learning for Audio-Visual Speaker Tracking
作者:李一迪1,刘宏1,唐浩2
单位:1北京大学,2苏黎世联邦理工学院
邮箱:
yidili@pku.edu.cn,
hongliu@pku.edu.cn,
hao.tang@vision.ee.ethz.ch
论文:
https://www.aaai.org/AAAI22Papers/AAAI-4283.LiY.pdf
多模态融合被证明是一种能有效提高说话人跟踪的准确性和稳健性的方法,尤其是在复杂的场景中。然而,如何结合异构信息并利用多模态信号的互补性仍然是一个具有挑战性的问题。本文中,我们提出了一种多模态感知跟踪器(MPT),用于联合使用音频和视觉模态进行说话人跟踪。首先构建了一个基于空间-时间全局相干场(stGCF)的声学图谱,用于异构信号融合。它采用相机模型将音频线索映射到与视觉线索一致的定位空间。然后,引入一个多模态感知注意力网络来推导出感知权重,衡量受噪声干扰的间歇性音频和视频流的可靠性和有效性。此外,还提出了一种跨模态自监督学习方法,通过利用不同模态之间的互补性和一致性对音频和视觉观测的置信度进行建模。图1展示了本文提出的多模态感知跟踪器框架。
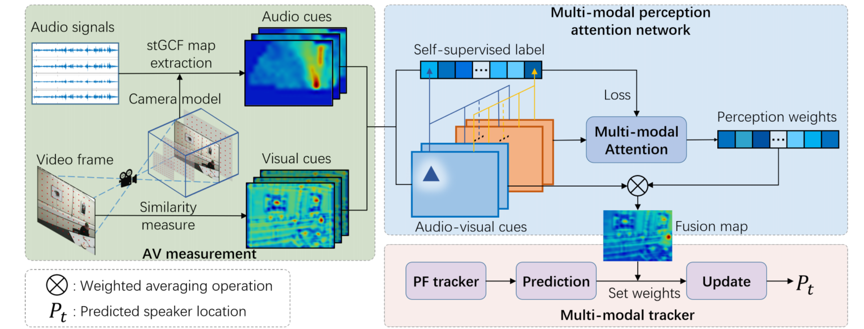
图1 本文提出的多模态感知跟踪器框架
1) 空间-时间全局相干场(stGCF):突出声源位置的声学图谱可以通过基于交叉功率谱相位的相干度量来完成。在此基础上,我们引入stGCF方法来提取音频线索。GCF值被定义为属于麦克风阵列的每个麦克风对的GCC-PHAT的平均值。给定一个具有潜在声源位置的空间网格,GCF值代表每个位置上存在声源的概率。为了构建空间网格,利用针孔摄像机模型,将图像平面上的二维点投射到一系列具有不同深度的三维世界坐标的三维点上。由于语音的间歇性和说话人动作的连续性,一个时期内的语音信号为当前时刻的音频线索提供了参考。考虑[t-m1,t]时间间隔内的信号,在其中选择GCF峰值最大的m2帧作为stGCF图。其中,第k个深度处的GCF图谱的计算如下:


2) 多模态感知注意力网络:基于提取的音频和视觉线索,多模态感知注意网络生成一个分数图作为说话人的位置表示。大脑的注意力机制能够有选择地改善吸引人类注意力的信息的传输,从丰富的信息中权衡出对当前任务目标更关键的具体信息。受这种信号处理机制的启发,本模块中利用神经注意力机制来学习衡量多种模态的置信度。为了整合音频和视觉线索,stGCF图谱和视觉响应图被归一化并重塑为三维矩阵形式。通过一个基于通道注意力模块的网络对视听线索进行处理,其通道对应于从音频或视觉模态中提取的观测信号。对于每个通道,注意力机制产生一个正分数,以衡量第i个通道上观测的可靠性。该得分称为感知权重,反映了根据视听度量获得的多模态线索的置信度水平。在可靠的观测中得分较高,而在受背景噪声、房间混响、视觉遮挡、混乱背景等干扰的模糊观测中得分较低。
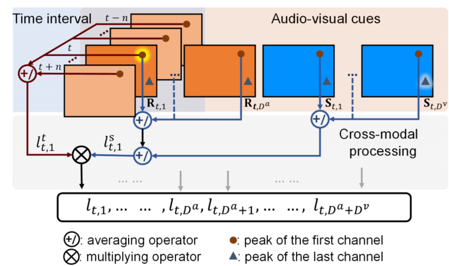
3) 跨模态自监督学习:网络所表现出的多模态感知能力是一个抽象的过程,这使得我们无法人为地数据进行必要的监督。为此,我们提出了一种跨模态自监督学习策略来训练网络。自监督包括一个时间因子lt和一个空间因子ls,分别考虑移动目标的时间连续性和多模态观测中的空间一致性。一个通道上的空间因子被定义为多模态和跨模态特征图峰值的平均算子。时间因子是通过对以时间t为中心的时间区间进行平均计算而得到的。其公式如下:
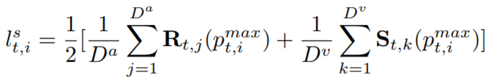
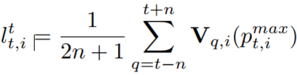
自监督标签整合了一个时间间隔内来自不同模态的评价。当目标在一个观察点上发生漂移时,根据各模态之间的互补性和目标运动的连续性,较低的数值由另一个具有更精确观测的通道提供。此外,当所有观测的峰值位于同一区域时,该值会相应增加。采用L2损失来评估生成的标签和注意力模块的输出。
4) 多模态跟踪器:注意力网络通过改进的PF算法来支持多模态跟踪。网络输出的注意力度量被用来对视听线索进行加权。与传统的加性似然和乘性似然相比,基于注意力机制的加权方法在本质上更接近于人类的感官选择性注意机制。不同模态的感知注意力值在加权图中被融合,并在PF的更新步骤中被用于更新粒子。扩散之后,粒子位置处融合图的值被设定为新的粒子权重。
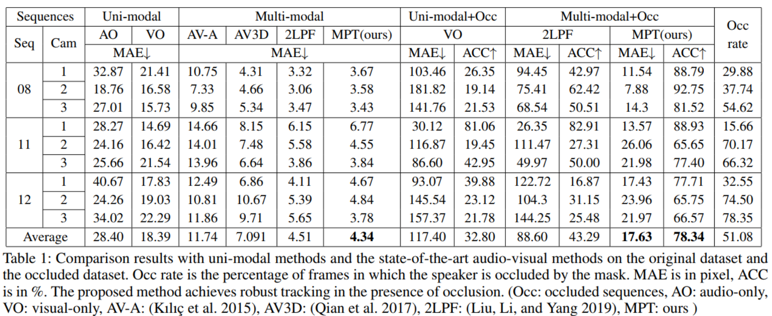
5) 实验结果:所提出的MPT与单模态方法和最先进的视听方法在AV16.3数据集上进行了比较。为了验证跟踪器在干扰条件下的鲁棒性,我们设置了遮挡数据集。遮挡区被人为地覆盖在图像的中间(1/3帧),用来模拟视野受限或相机取景器被遮挡的情况。结果显示,音频和视觉模态的结合使得说话者跟踪效果有了巨大提升。MPT的MAE为4.34像素,优于最先进的方法。MPT在平均遮挡率为51.08%的序列上实现了78.34%的跟踪精度。

图2 音频线索、视觉线索、融合图的可视化
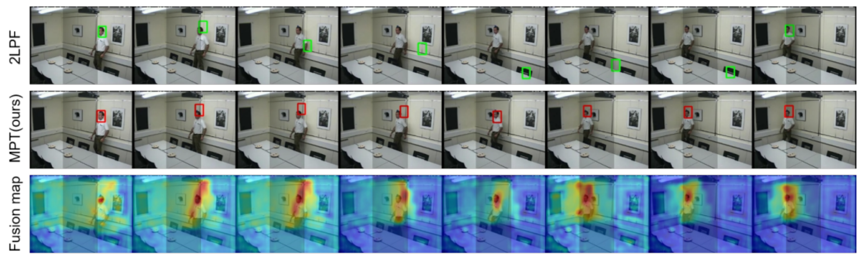
图3 遮挡序列的跟踪结果可视化
04
Probing Word Syntactic Representations in the Brain by a Feature Elimination Method
作者:张肖寒1,2, 王少楠1,2, 林楠3,4, 张家俊1,2, 宗成庆1,2,5
单位:
1中国科学院自动化研究所,模式识别国家重点实验室,
2中国科学院大学人工智能学院,
3中国科学院心理研究所,
4中国科学院大学心理学系,
5中国科学院脑科学与智能技术卓越创新中心
邮箱:
xiaohan.zhang@nlpr.ia.ac.cn
论文:
https://ojs.aaai.org/index.php/AAAI/article/view/21427
代码:
https://github.com/xhzhang-1/probing-syntactic-representation
神经影像研究发现大脑在理解语言时,多个脑区与语义和语法处理相关。然而,现有的方法大多使用人工设计对照语料的方法研究语法的大脑机制,难以探索词性和依存关系等细粒度词汇语法特征的神经基础。本文提出了一种新的框架,在自然语言刺激的神经影像数据上,结合预训练语言模型来研究不同词汇语法特征在大脑中的表征。
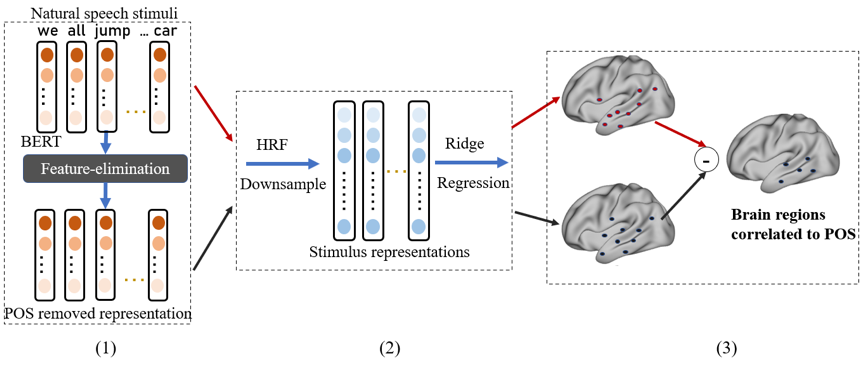
我们提出的框架可分为三个部分,1). 特征消除模块,2). 脑活动编码模块,3). 显著性检验模块。其核心思想是,从预训练语言模型生成的词向量中分离出不同的语法信息,并使用脑活动编码模型建立语法信息表征与脑活动的关系,进而分析该信息在大脑中的表征。
具体来说,为了分离不同句法特征,我们提出了一种特征消除方法——均值向量零空间投影(MVNP),来消除词向量中的某一特征。然后,我们分别将消除某一特征的词向量和原始词向量与大脑成像数据联系起来,以探索大脑如何表示被消除的特征。最后,我们使用显著性检验找出特征消除后预测准确率显著下降的大脑体素,从而得到该特征的大脑表征。实验结果如下:
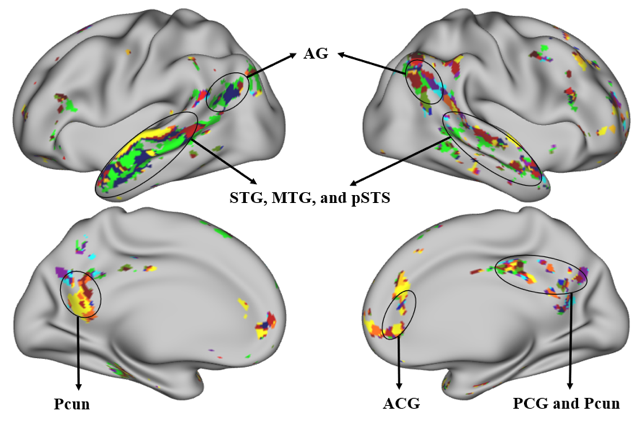
我们的实验结果显示,词汇级别的句法特征在大脑中为分布式表征,句法脑网络和传统语义脑网络很大程度上重合,而且不同句法特征在大脑中表示为层次系统,部分脑区仅表示一种特征,而颞上回等脑区则表示了多种特征。
本文首次在同一实验中同时研究了多个细粒度语法特征的皮层表征,并提出了多个脑区在语法处理分工中的可能贡献。这些发现表明,语法信息处理的大脑基础可能比经典研究所涉及的更为广泛。
05
Online Enhanced Semantic Hashing Towards Effective and Efficient Retrieval for Streaming Multi-Modal Data
作者:伍晓鸣,罗昕,詹雨薇,丁陈璐,陈振铎,许信顺
单位:山东大学软件学院
邮箱:
wuxiaoming.alg@gmail.com
luoxin.lxin@gmail.com
zhanyuweilif@gmail.com
dingchenlu200103@gmail.com
chenzd.sdu@gmail.com
xuxinshun@sdu.edu.cn
论文:
https://ojs.aaai.org/index.php/AAAI/article/view/20346
代码:
https://github.com/DravenALG/OASIS
1. 引言
如今,随着多媒体设备的急剧增加,对多媒体数据进行检索的需求愈发强烈。考虑到哈希学习的高检索效率、低存储消耗等特点,基于哈希学习的数据快速相似性检索方法逐渐受到了重视。我们的论文主要关注于多模态数据检索领域。目前该领域中大多数的方法都是批处理(batch-based)的训练模式,这样的训练模式在面对流式数据的时候,需要在每轮次新数据到来时都对模型进行重新训练,这会造成较大的消耗。为了更好地适应流式数据,少量的在线多模态哈希学习的研究工作被提出。但是,现有的方法忽略了在线场景中可能存在的类别增量问题,即新轮次的数据可能携带一些模型没有见过的类别。考虑到上述挑战,我们提出了名为OASIS的方法,解决了在线多模态哈希中的类别增量问题,并在面向多模态流式数据的快速检索任务上提高了检索效果。
2. 方法概述
如图 1所示,我们的方法可以分为三个部分,语义增强表示的生成,语义增强哈希码学习以及哈希函数学习。对于语义增强表示,在第t轮训练时,我们使用语义模型word2vec生成新的类别名字的语义向量,然后对于新的实例数据,我们根据其拥有的标签相对应的语义向量进行求和并单位化,构造出新的实例数据的语义表示。从而,实例数据的语义表示的维度只与语义向量的维度有关,与类别数量无关,这样的策略避免了模型后续对新旧实例数据进行相似性计算时,可能出现的维度不一致的问题,从而保证模型不仅可以在新类别到来时学到新类别的知识,同时还可以保留旧数据的知识。在学习语义增强的哈希码时,我们通过语义向量构建了新实例之间、新旧实例之间的相似性,从而学习出哈希码。哈希函数学习部分根据哈希码学习出映射函数,且同时让映射函数适配于新旧数据。可以证明,我们的模型的训练时间只与每轮次新来的数据的数量线性相关。在测试时,我们通过学习到的哈希函数对测试数据生成哈希码,和数据库中的数据的哈希码进行相似度计算,从而检索出合适的数据。

图1 OASIS第t轮训练时的模型框架图
3. 实验结果
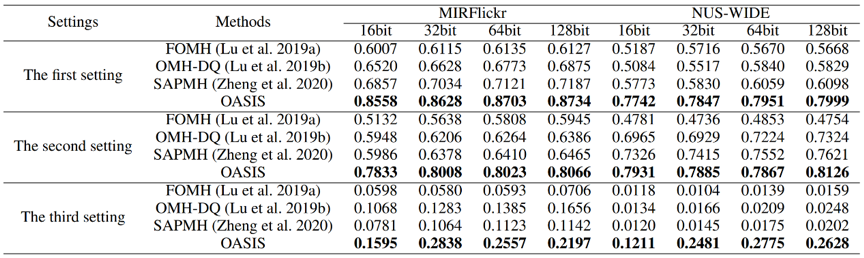
在实验中,我们构造了三种适应于流式数据的实验设定。第一个实验设定是每个轮次的数据满足独立同分布假设;第二个实验设定是流式数据存在类别增量的情况,此时假设新旧数据携带的类别有部分重合;第三个实验设定也是类别增量的场景,假设新旧数据之间的类别没有重合。实验结果如表1所示,可以看到我们的模型具有很好的检索性能。我们认为原因主要有以下两点,第一点是我们的方法在哈希码生成和哈希函数的学习过程中均进行了新旧数据之间相似性关系的保持,第二点是方法利用了丰富的语义信息来促进哈希学习的性能。
表1 在两个基准数据集上的检索效果(MAP)对比
07
TA2N: Two-Stage Action Alignment Network for Few-Shot Action Recognition
作者:李书源†1, 刘华斌†1,钱锐1,李昱希1,John See2,费梦娟3,喻晓源3,林巍峣1
单位:1上海交通大学,2Heriot-Watt University,3华为云
邮箱:
shuyuanli@sjtu.edu.cn,
huabinliu@sjtu.edu.cn,
qrui9911@sjtu.edu.cn,
lyxok1@sjtu.edu.cn,
wylin@sjtu.edu.cn,
J.See@hw.ac.uk,
feimengjuan1@huawei.com,
yuxiaoyuan@huawei.com
论文:
https://arxiv.org/pdf/2107.04782
代码:
https://github.com/R00Kie-Liu/TA2N
†共同一作
引言
主流的少样本学习方法都是基于度量学习范式,即通过学习衡量两个样本间的相似度或距离来进行分类。然而,在少样本视频识别任务中,直接比较两个视频序列样本的相似度是非常困难的。这是因为对于不同种类甚至相同类别的视频,其中的行为并不是严格对齐的。 我们从两个不同的方面对行为不对齐现象展开了分析和研究:
1. 由于不同的行为开始和持续时间,不同的视频之间行为的相对时间位置通常是不一致的。我们将这种时域位置上的不对齐定义为 action duration misalignment, 即行为时域位置的不对齐。
2. 因为动作的时空进展是非线性的,所以即使是在相同的动作持续时间内,最具辨识度的动作在时空进展也是不同的。我们将这种动作实例时空进展之间的不对齐称为 action evolution misalignment, 即时空动作进展不对齐。

图1 视频间行为不对齐示例
方法概论
为了解决少样本行为识别任务中这两种不对齐问题,我们提出了一个新的二阶段时域对齐网络。
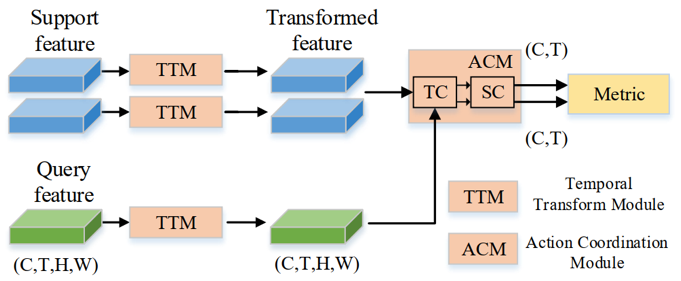
图2 TA2N网络流程图
第一阶段,针对行为时域位置的不对齐,我们设计了时域变换模块TTM (Temporal Transformation Module),它由两部分组成:定位网络和仿射变换器。 定位网络接收帧级特征作为输入,学习并生成变换参数;仿射变换器根据生成的变换参数对输入的视频序列特征进行变换。由于时域位置不对齐现象在帧序列之间具有典型的线性特征,因此我们使用线性的时域插值来对特征进行重采样,以确保变换后的输出特征的时域分辨率不变。
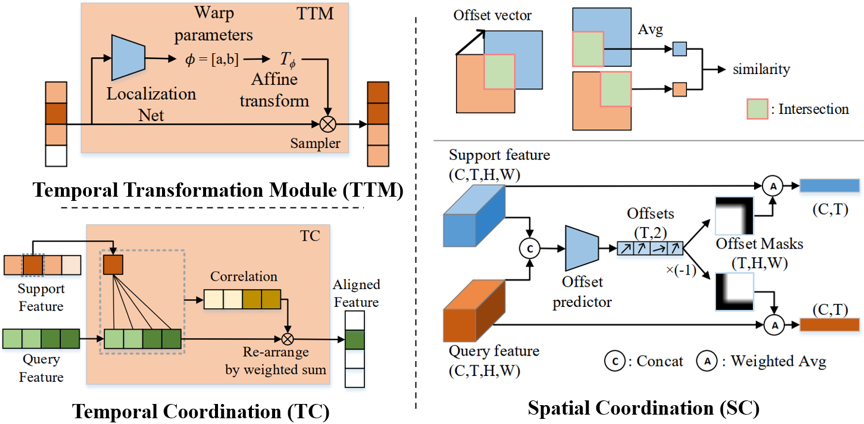
图3 各模块实现细节
第二阶段,针对行为时空进展不对齐,我们设计了行为调制模块ACM (Action Coordination Module),如图3所示,它包含TC和SC两个部分,分别从时域和空域对行为进展进行对齐。 具体而言,TC首先使用注意力机制来建模support和query视频的行为时序演化关系,得到二者的时序关联矩阵。基于关联矩阵,将query样本的特征进行时序重排,使得query视频样本的动作演化特征向support视频样本进行时域对齐。 接下来进行空间配准SC,它包括两个步骤:轻量级的偏移预测和偏移掩码生成。首先,给定时域已经对齐的两个视频特征,将它们输入偏移预测器以预测空间偏移,该偏移表示两个视频对应帧之间对应的动作区域的位移向量。据此,对应帧之间的交叠区域便可通过其相应的空间偏移量来定位。根据交叠区域,我们生成对应的偏移掩码作用于帧级特征以得到空间相互配准后的特征。
实验结果
广泛的实验证明,我们的方法能在各视频行为数据集上达到最优的效果。t-SNE特征可视化(图4)和视频间对齐结果(图5)也进一步证明我们的方法能够有效处理少样本视频识别中的不对齐现象。
表1 少样本视频行为识别结果
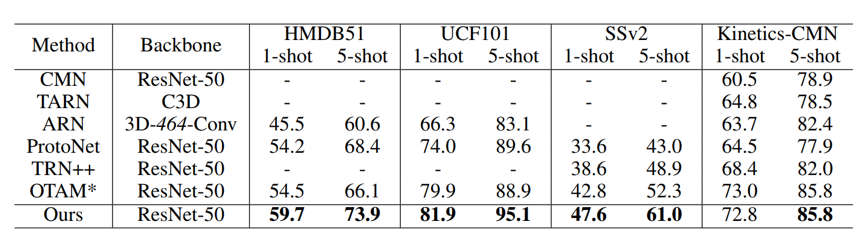
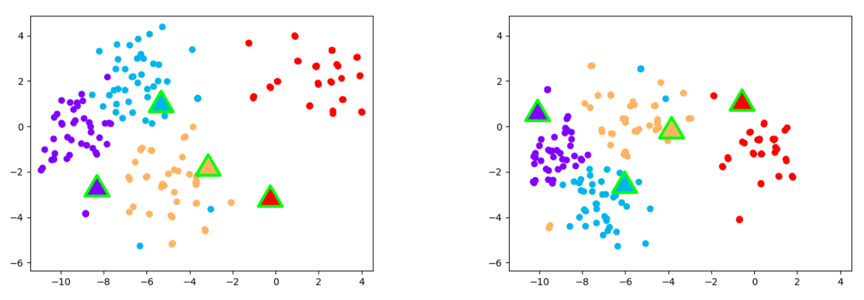
图4 对齐前后视频特征可视化图
表2 各模块消融实验
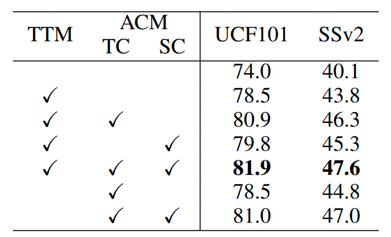

图5 视频间时空对齐结果可视化

 京公网安备11010802017125号
京公网安备11010802017125号