
2022年论文导读第二十二期
【论文导读】2022年论文导读第二十二期
CCF多媒体专委会 2022-11-01 11:23 发表于北京


论文导读
2022年论文导读第二十二期(总第六十二期)
目 录
|
1 |
AutoCFR: Learning to Design Counterfactual Regret Minimization Algorithms |
|
2 |
Feature Distillation Interaction Weighting Network for Lightweight Image Super-Resolution |
|
3 |
Robust Heterogeneous Graph Neural Networks against Adversarial Attacks |
|
4 |
Structured Semantic Transfer for Multi-Label Recognition with Partial Labels |
|
5 |
DeepThermal: Combustion Optimization for Thermal Power Generating Units Using Offline Reinforcement Learning Smoothing Advantage Learning |
01
AutoCFR: Learning to Design Counterfactual Regret Minimization Algorithms
作者:徐航1*,李凯1*,傅浩波2,付强2,兴军亮3#
单位:1中国科学院自动化研究所,2腾讯AI实验室,3清华大学
邮箱:
xuhang2020@ia.ac.cn
kai.li@ia.ac.cn
haobofu@tencent.com
leonfu@tencent.com
jlxing@tsinghua.edu.cn
论文:
https://ojs.aaai.org/index.php/AAAI/article/view/20460/20219
代码:
https://github.com/rpSebastian/AutoCFR
*共同一作,#通讯作者
不完美信息博弈具有重要的科学研究价值,在交通规划、商业谈判、量化交易等场景下都有着广泛的应用前景。反事实后悔值最小化(Counterfactual Regret Minimization,CFR)算法是该领域的经典算法,以迭代的方式计算纳什均衡策略。近年来,CFR算法及其变体在不完美信息博弈求解中取得了一系列进展,然而在CFR算法的设计中有诸多选择,很难进行全面系统地考虑。为了减轻人工设计算法的负担和局限性,本文基于元学习提出了一种新型的CFR算法搜索框架AutoCFR,整体框架如图1所示。AutoCFR构建了一种高度灵活并且表达力丰富的搜索语言体系来表示CFR类算法所在的空间,采用一种可扩展的正则化演化算法以及一系列精心设计的加速技术,来高效搜索该语言定义的组合空间,最终目标是探索这个庞大的算法空间,找到一个高性能可推广的算法,不仅在一系列训练环境中表现优异,也可以推广到没见过的测试环境下。
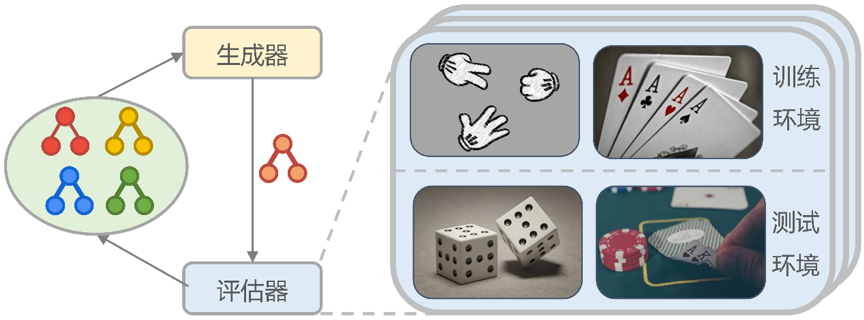
图1 新型的CFR算法搜索框架AutoCFR
AutoCFR将CFR类算法描述为特定领域语言体系的通用计算机程序,以有向无环计算图的形式呈现,一共包含3种节点:1)输入节点表示算法的输入,包含当前策略��T、累积后悔值RT-1、常数等;2)操作节点定义了基本数学、线性代数、概率等数学运算,根据父节点的输入信息计算输出; 3)输出节点表示算法的输出,包含新策略��T+1,更新后的累积后悔值RT和更新后的累积策略CT。图2可视化了CFR、CFR+、DCFR算法的计算图。高度灵活的搜索语言体系既可以表示现有的CFR变体,同时也为发现性能更好的CFR变体奠定了基础。
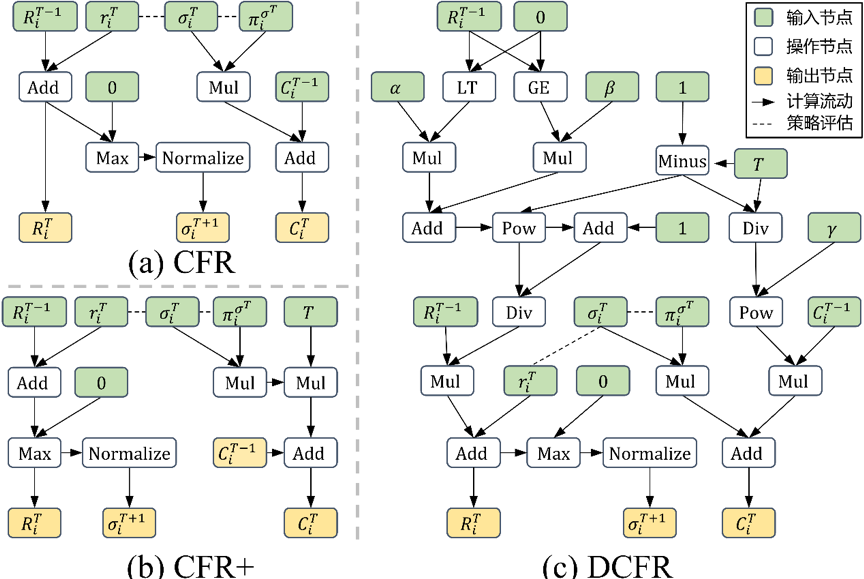
图2 高度灵活并且表达力丰富的搜索语言体系
AutoCFR采用正则式演化算法在庞大的算法空间中高效搜索性能优异的算法。正则式演化算法维护了一个大小为的种群,每次从中挑选出个个体,变异得分最高的个体,将新个体加入种群,同时移除种群中年龄最老的个体。此外,AutoCFR精心设计了5种加速算法:1)程序合法性验证,使用简单的验证来避免评估不合法的新算法; 2)函数等价测试,如果新算法和之前已评估算法的哈希编码是相同的,直接使用已评估算法的分数; 3)及时终止,如果新算法在简单环境下表现很差,则不继续在复杂环境下进行评估; 4)自举学习,使用已有的CFR变体初始化种群; 5)并行加速,将算法生成模块和算法评估模块分布到若干机器的若干进程上。AutoCFR的完整搜索算法如图3所示。

图3 一系列加速技术扩展的正则式演化搜索算法
AutoCFR通过学习自动设计了一种新颖的CFR变体DCFR+。DCFR+有两个核心改进点:1)最大值函数。当最佳动作突然改变时,DCFR+ DCFR+使用最大值函数来重置负累积遗憾值,从而立即执行最佳动作。2) 新的衰减方法。DCFR+衰减之前的迭代轮次,并给予后面的迭代轮次更高的权重。如图4、5所示,DCFR+具有较强的性能和泛化能力。
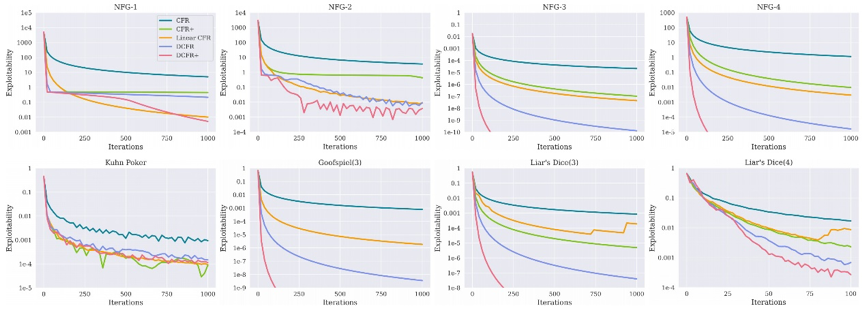
图4 DCFR+与4个CFR变体在8个训练环境中的比较

图5 DCFR+与4个CFR变体在4个测试环境中的比较
02
Feature Distillation Interaction Weighting Network for Lightweight Image Super-Resolution
用于轻量级图像超分辨率的特征蒸馏交互加权网络
作者:高广谓1†, 李文杰1†, 李俊诚2*, 吴飞1, 陆慧敏3, 于漪4
单位:1南京邮电大学, 2香港中文大学, 3日本九州工业大学, 4日本国立情报学研究所
邮箱:
csggao@gmail.com,
liwj0824@163.com,
cvjunchengli@gmail.com,
wufei_8888@126.com,
luhuimin@ieee.org,
yiyu@nii.ac.jp
论文:
https://ojs.aaai.org/index.php/AAAI/article/view/19946
代码:
https://github.com/24wenjie-li/FDIWN
数据集:
https://data.vision.ee.ethz.ch/cvl/DIV2K/
介绍网页:
https://guangweigao.github.io/AAAI22/FDIWN.html
†共同一作 *通讯作者
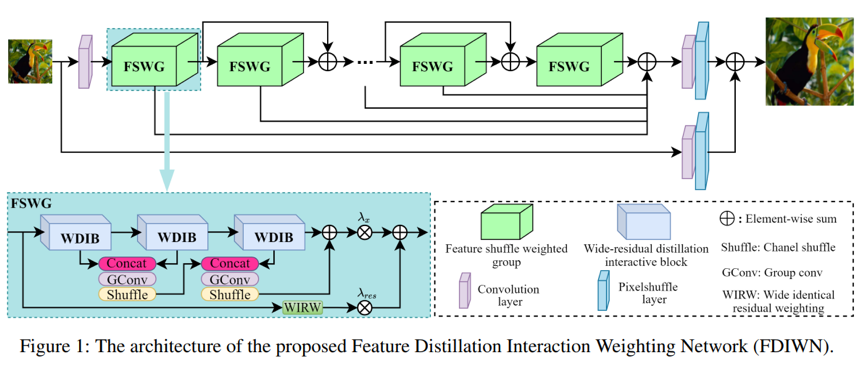
基于卷积神经网络的单幅图像超分辨率(SISR)近年来取得了长足的进步。然而,这些方法很难应用于现实世界。由于计算和内存成本的限制;同时,如何在有限的参数和计算的约束下,充分利用中间特征也是一个巨大的挑战。为了缓解这些问题,我们提出了一种轻量且高效的特征蒸馏交互加权网络(FDIWN)。具体来说,FDIWN 利用了一系列专门设计的特征混洗加权组 (FSWG) 作为骨干,并且FSWG由几个新颖的宽残差蒸馏交互块 (WDIB) 经过混洗加权后组成。
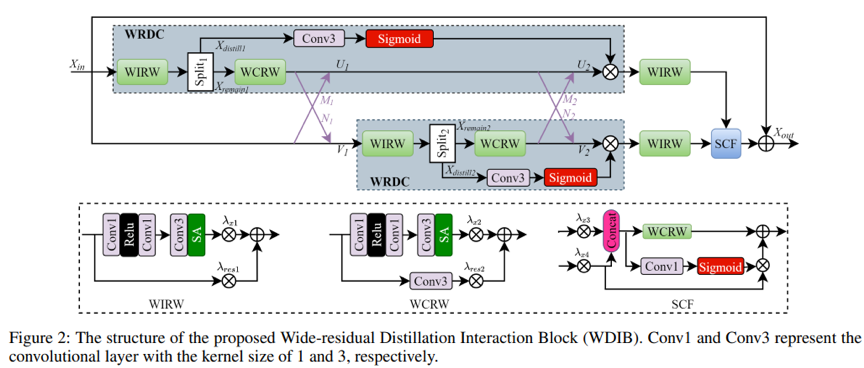
我们在 WDIB 中引入了几个宽恒等残差加权 (WIRW) 单元和宽卷积残差加权 (WCRW) 单元,以实现更好的特征蒸馏。此外,宽残差蒸馏连接 (WRDC) 框架和自校准融合 (SCF) 单元被提出来与不同的特征实现更灵活、更高效地扩展交互。
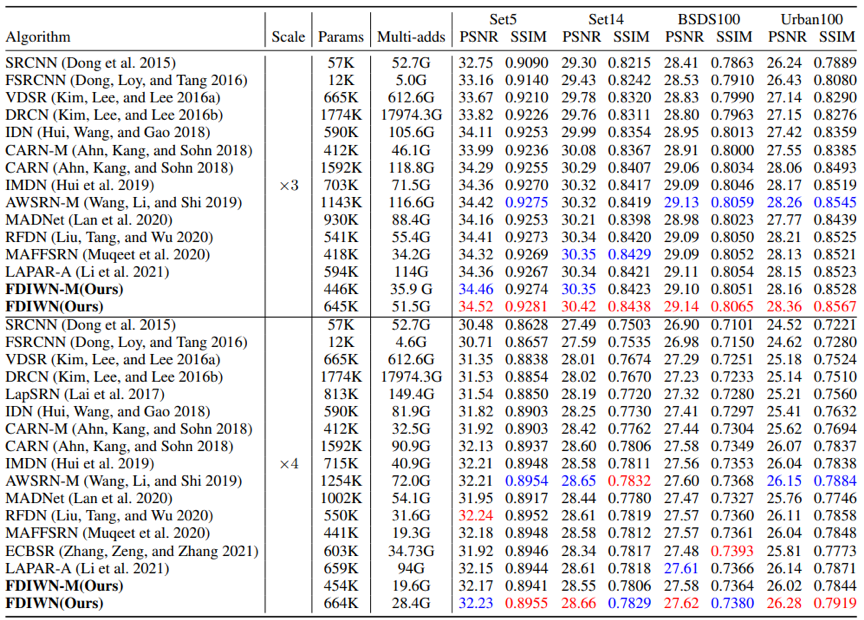
根据表格的定量对比,我们可以观察到 i)具有相似参数量的模型比我们的模型表现更差;ii) 具有相同表现效果的模型比我们的模型拥有更多参数量。

由图中的对比我们可以得出结论:我们的方法FDIWN在模型大小、性能表现、推理速度和计算量等方面达到了较好的平衡。

通过一个SR结果的定性比较,可以看到我们提出的方法的有效性:我们的方法可以得到较好的视觉细节效果,同时还具有更高的PSNR与SSIM。
通过广泛的实验,表明我们的 FDIWN 优于其他模型,并且在模型性能和模型效率之间形成了较好的平衡。
03
Robust Heterogeneous Graph Neural Networks against Adversarial Attacks
作者:张梦玫1,王啸1,朱美琪1,石川1,*,张志强2,周俊2
单位:1北京邮电大学,2蚂蚁集团
邮箱:
zhangmm@bupt.edu.cn,
xiaowang@bupt.edu.cn
zhumeiqi@bupt.edu.cn
shichuan@bupt.edu.cn
lingyao.zzq@antfin.com
jun.zhoujun@antfin.com
论文:
https://ojs.aaai.org/index.php/AAAI/article/view/20357/20116
代码:
https://github.com/BUPT-GAMMA/RoHe
许多真实世界的数据集都可以用异质图建模,异质图包含了不同类型的对象和关系,以图1(a) 的异质引文网络为例,网络由三种类型的对象(作者(A)、论文(P)、主题(S))和两种类型的关系(P-A和P-S)组成。为了充分挖掘异质图中包含丰富的高阶结构信息,元路径作为基础工具被广泛应用,如P-A-P刻画了同一作者写的论文,P-S-P描述的是属于同一主题的论文。近年来,随着深度学习技术的应用,异质图神经网络(Heterogeneous Graph Neural Networks, HGNNs)逐渐兴起,HGNNs通常采用层次聚合(包括节点级和语义级),从基于元路径的邻居中获取信息,并在许多任务中取得了突出的性能。然而,我们发现HGNNs对于对抗攻击并不鲁棒。

图1 背景知识与方法动机
本研究首次测试了HGNNs的对抗鲁棒性,我们分析了其在拓扑攻击下的性能,结果如图1(b)所示。令人惊讶的是,HGNNs(即HAN、MAGNN和GTN)与同质图神经网络GCN的对抗鲁棒性存在显著差异,这促使我们进一步研究他们在模型设计上的差异。研究发现HGNNs对抗脆弱的两个关键原因:一是扰动放大效应,HGNNs没有编码转移概率,因此会放大对抗中心邻居(即hub节点)的影响,例如只加一条对抗边(p1,a3)就可以注入大量恶意邻居直接被p1融合,如图1(d)所示;二是软注意机制会给明显不可靠的邻居赋予恒正的注意力值,因此大量的恶意邻居p4....p66可以累积较小但恒正的权重,最终控制HGNNs的接受域,误导的分类,如图1(c)所示。
为此,我们提出了拓扑对抗攻击鲁棒的HGNNs框架 (Robust Heterogeneous GNNs,RoHe)。HGNNs通常采用分层聚合,包括节点级和语义级,我们的RoHe在节点级聚合时用注意力净化器来移除被污染的邻居以进行防御,框架如图2所示。具体来说,为了减少扰动的放大效应,RoHe引入了转移概率作为我们净化器的先验,降低了对抗中心邻居的置信度。然后,基于转移概率和特征相似性对感受域进行收缩,遮蔽掉置信度低的邻居,解决了软注意力机制不能彻底消除对抗边的问题。最后,利用净化后的权重聚合所有元路径的邻居信息,将这些元路径进行语义级聚合,最终生成下游任务的节点嵌入。

图2 RoHe模型框架
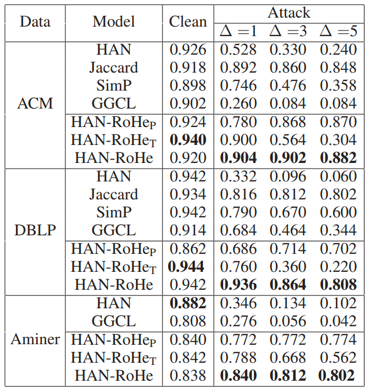
我们在三个数据集上对HAN进行了不同程度的攻击实验,表1的实验结果证明了我们方法的防御能力。由于没有现成的 HGNNs 防御框架, 我们直接将同质图神经网络的防御策略Jaccard、GGCL和SimP简单适应到HGNNs中。同时提出两个RoHe的变种方法 (只保留转移概率) 和 (只保留遮蔽操作用于剪枝)。发现我们的对抗防御效果最好,同时在干净的数据集中也获得了很好的效果。
表1 防御实验结果
04
Structured Semantic Transfer for Multi-Label Recognition with Partial Labels
作者:陈添水1,蒲韬2,吴贺丰2,谢圆2,林倞2
单位:1广东工业大学,2中山大学
邮箱:
tianshuichen@gmail.com,
putao537@gmail.com,
wuhefeng@gmail.com,
phoenixsysu@gmail.com,
linliang@ieee.org
论文链接:
https://arxiv.org/pdf/2112.10941.pdf
代码链接:
https://github.com/HCPLab-SYSU/HCP-MLR-PL
由于现实世界中绝大多数图像都会自然地包含多种类别的语义物体,因此多标签图像识别(Multi-label Image Recognition)任务比单标签图像识别任务更为基础且更具有挑战性。然而,受限于多标签图像本身的复杂场景以及其标签空间的复杂性,我们在现实情况下很难收集大规模的多标签图像注释数据,这也加大了多标签图像识别算法在实际场景的应用难度。为了降低注释成本并提高多标签图像识别算法的易用性,研究者们提出了部分标签情况下的多标签图像识别任务(Multi-label Image Recognition with Partial Labels),如图1所示。相对于传统的多标签图像识别任务而言,部分标签情况下的多标签图像识别任务专注于如何在丢失部分标签的情况下利用已知标签充分训练模型,这使得该任务更加具有实际意义且更具有挑战性。

图1. 多标签图像识别任务中完整标签与部分标签的对比。其中,√ 表示对应类别存在,× 表示对应类别不存在,?表示对应标签未知。
目前大多数相关算法将多标签图像识别任务视为多个二分类任务的变体,并直接将未知标签视为缺失或修改为负类标签从而将之前的传统多标签图像识别算法进行迁移以供使用。但是,这样简单粗暴的做法不仅会丢失部分数据,甚至还会产生大量的噪音数据,因此这些算法往往存在明显的性能下降。幸运的是,在同一张多标签图像内部以及不同多标签图像之间都存在着显著的语义相关性,而这些语义相关性可以有效地帮助我们利用已知标签的语义知识来对未知标签进行补全:1)在现实世界的日常图像中,不同类别标签的共现广泛存在。例如,桌子倾向于与椅子共同出现,而汽车倾向于与道路共同出现。 2)不同图像中同一类别的对象可能具有相似的视觉外观,因此具有相似视觉特征的图像可能具有相同的标签。
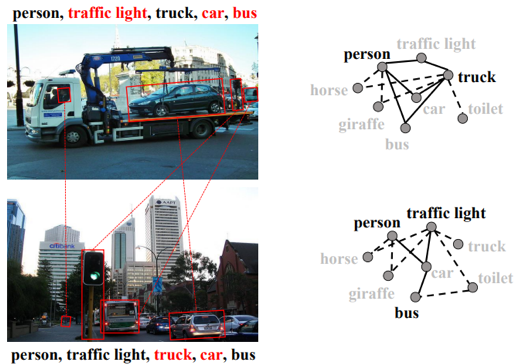
图2 两个具有部分标签的多标签图像示例(红色表示未知标签)。
基于上述的观察,我们提出了一个结构化语义转移(Structured Semantic Transfer,缩写为SST)框架,该框架通过挖掘多标签图像内部各个类别之间的语义关联以及不同多标签图像之间相同类别的语义关联,对未知标签进行相应的补全,从而使得模型在部分标签的情况下依然取得目前最好的性能。 如下图所示,我们所提出的结构化语义转移框架利用语义表示学习模块(Semantic-aware Representation Learning,缩写为 SARL)提取各个类别对应的语义特征,再分别输入到 图像内语义迁移 (Intra-image Semantic Transfer,缩写为 IST)模块 和 跨图像语义迁移(Cross-image Semantic Transfer,缩写为 CST)模块以此分别挖掘图像内部不同类别之间的语义关联和不同图像之间相同类别的语义关联。具体而言,我们在 IST 模块中将同一图像内的不同类别语义特征两两组合,以此对其共现概率进行预测,从而结合已知标签对未知标签进行补全。与此同时,我们在 CST 模块内部对各个类别维护其正类样本队列(即不同图像中该类别存在时的语义特征),并通过相似度衡量以此为未知标签生成对应的伪标签。

图3 结构化语义转移框架总览
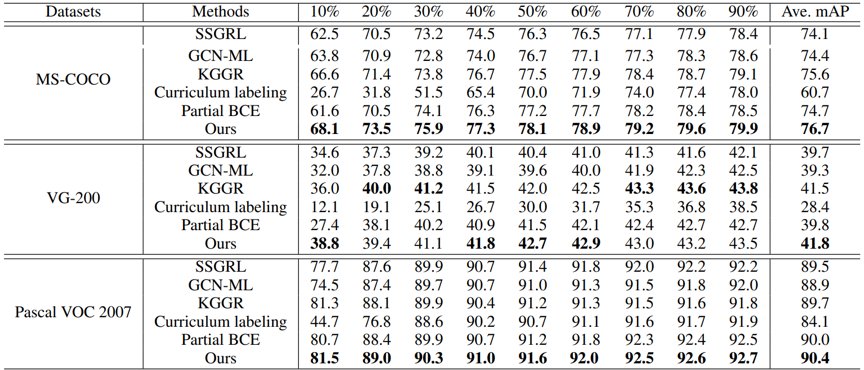
为了衡量我们所提出的结构化语义转移框架的有效性,我们将其与目前表现最好的其他方法进行对比。其中,对比方法包括 SSGRL (发表于 ICCV 2019)、GCN-ML (发表于 CVPR 2019)、KGGR (发表于 TPAMI 2022)、Partial BCE (CVPR 2019)。从详细的对比实验结果可以发现,我们所提出的结构化语义转移框架在绝大多数情况下都取得了目前最好的效果,具体对比结果如下所示。
表1 与其他方法的结果比较
05
DeepThermal: Combustion Optimization for Thermal Power Generating Units Using Offline Reinforcement Learning
作者:1詹仙园,2徐浩然,2张玥,1朱翔宇,2殷宏磊,2郑宇
单位:1清华大学智能产业研究院(AIR),2京东科技
邮箱:
zhanxianyuan@gmail.com
ryanxhr@gmail.com
zhangyuezjx@gmail.com
zackxiangyu@gmail.com
yinhonglei93@gmail.com
msyuzheng@outlook.com
论文链接:
https://ojs.aaai.org/index.php/AAAI/article/view/20346
项目网页:
http://zhanxianyuan.xyz/project/2018-thermalOpt
TalkRL Podcast:
https://www.talkrl.com/episodes/xianyuan-zhan
一、概述
火力发电在世界能源供给领域占有重要地位。在中国超过60%的电力来源于火力发电,每年消耗大量的不可再生煤炭资源,并产生大量的温室气体排放及污染。优化火力发电机组的燃烧效率是能源行业中一项极具挑战性和关键的任务,同时具有重要的经济及环境保护价值。如果可仅帮助一个600MW火电机组提升0.5%的燃烧效率,就可每年节省超过4000吨煤炭。然而火电机组本身高度复杂,包含大量的组成设备、海量的传感器、复杂的运行机理以及多样的安全约束条件,传统基于PID、MPC等控制优化手段已存在瓶颈。同时,因为系统本身的复杂性,导致无法构建高精度系统仿真,在AI领域取得较大成功的在线强化学习 (online RL)方法也无法适用于此类场景。然而,真实火电机组因为安全性要求普遍存储着大量历史运行数据,这使得纯数据驱动的离线强化学习(offline RL)方法解决此问题成为了一条可行的路径。本文提出了一项全新的基于模型的离线强化学习(model-based offline RL)框架MORE以及基于此构建的数据驱动的AI控制系统DeepThermal(中文名:“深燧”)。该算法框架首先从离线数据集中学习数据驱动的燃烧过程模拟器,接着提出了一种针对不完美模拟器的限制性探索策略,给予不同置信度的仿真样本不同的奖励惩罚权重。最后将真实样本和仿真样本通过混合训练的方式进行策略学习。DeepThermal目前已经成功部署在中国多家大型燃煤火力发电厂中。现场实验表明,该系统有效地提高了火电机组的燃烧效率。
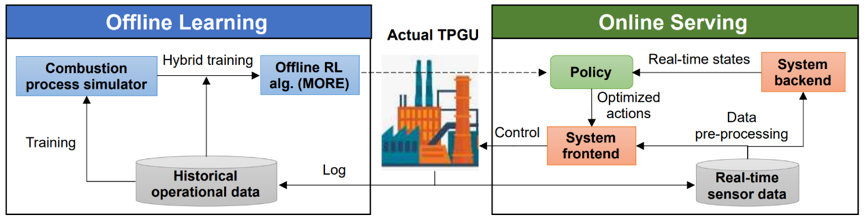
图1:DeepThermal系统设计
二、方法
DeepThermal在建模上主要有两个组成部分,一个数据驱动的RNN燃烧过程仿真模型(下图左),用来提供生成数据弥补离线数据的不足;以及一项全新的基于模型的离线强化学习框架MORE(下图右),用来解决安全约束条件下的离线策略寻优问题。
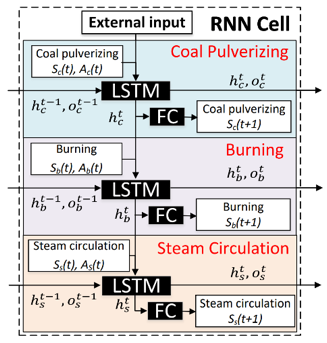
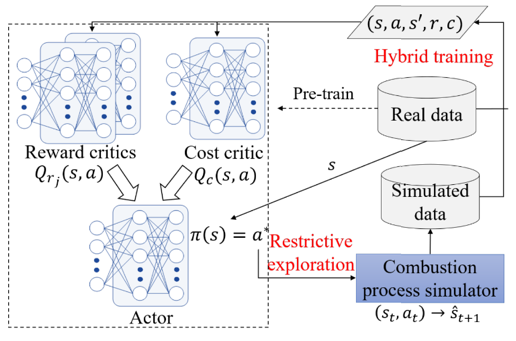
左图: 基于深度RNN网络的数据驱动燃烧过程仿真器;右图:MORE算法框架示意
其中,数据驱动的燃烧过程仿真模型采用了深度RNN网络架构,同时在设计过程中融合了火电机组的信息,将燃烧过程中的磨煤、炉膛燃烧、水热蒸汽循环分层进行建模,将数据中的依赖关系结构化的建模到深度神经网络中。同时,在训练中使用seq2seq,scheduled sampling以及状态加噪音训练等方法提升模型的鲁棒性。
基于模型的离线强化学习框架MORE主要用于解决不完美仿真下的带约束离线强化学习问题,它采用了TD3中的Clipped Double-Q方法学习2个reward critic Qr减轻价值高估影响,并引入了一个cost critic Qc来实现安全风险的满足。此问题可通过拉格朗日松弛法转化为一个无约束优化问题进行求解。
为解决离线策略学习中的分布漂移问题以及不完美仿真器对RL训练不利影响,MORE提出了一项新的限制性探索(restrictive exploration)机制,从模型预测可靠性(测量模型在输入样本上对扰动噪音的敏感性)以及是否为数据分布外样本(通过离线数据中的数据密度来衡量)两个层面进行设计。具体来讲,MORE 仅在数据驱动仿真模型对输出有把握时才信任生成样本,并基于其对离线数据分布的偏差对仿真样本施加针对性奖励惩罚,引导离线策略的高数据密度区域进行探索与学习。最后,MORE巧妙地结合了真实数据和仔细筛选的仿真生成数据来学习通过混合训练的方式实现可靠的离线策略寻优。
三、实验
DeepThermal系统在国内多家大型电厂进行了现场部署实测,下图为国电南宁电厂的实际部署情况以及三个负荷段(270MW, 290MW, 310MW)的现场实验结果。结果表明,DeepThermal在约一个小时的调整过程中实现了三个负荷段燃烧效率0.52%,0.31%,0.48%的提升。同时,本文还在D4RL离线基准数据集上对MORE及其他主流offline RL算法进行了仿真环境对比测试,结果表明,MORE实现了相较已有方法同一水平或更好的表现。
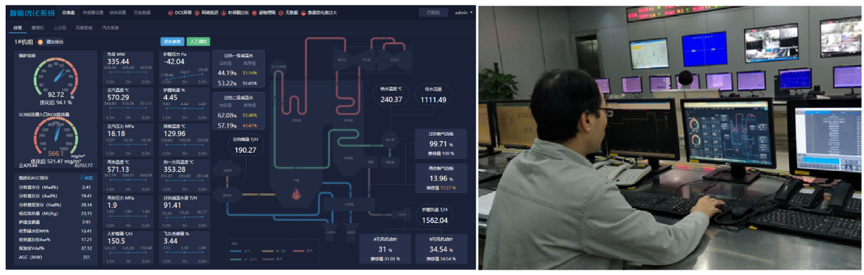
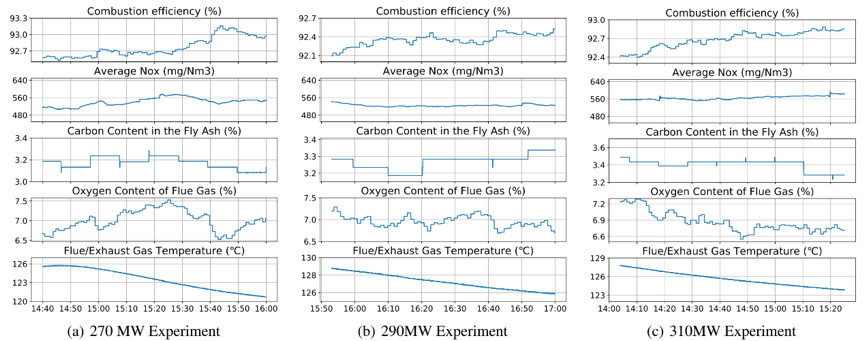
图2 DeepThermal系统现场部署情况及实验结果

图3 MORE在仿真基准数据集的对比结果
四、总结
本文针对火电机组燃烧控制优化问题研发了一个全新的AI数据驱动控制优化系统DeepThermal,同时实现了现场落地验证。本文是目前将离线强化学习方法应用于真实工业复杂系统的首个落地案例,对未来应用离线强化学习解决真实世界决策优化问题提供了有益的启示。
06
Smoothing Advantage Learning
作者:甘耀中、张哲、谭晓阳
单位:南京航空航天大学
邮箱:
yzgancn@nuaa.edu.cn,
zhangzhe@nuaa.edu.cn,
x.tan@nuaa.edu.cn
论文链接:
https://ojs.aaai.org/index.php/AAAI/article/view/20620
1. 论文动机
在给定高维离散或连续状态空间的环境中学习最优策略是一项具有挑战性的任务。一种常见的方法是通 函数近似方法,这可能会引入近似误差或者采样带来的估计误差。优势学习(Advantage learning,AL)算法 是最近提出的一种方法,用于减轻近似或估计误差的负面影响。然而,关于 AL 方法的文献中研究较少的一 个问题是,它可能会在训练过程的早期阶段出现过度增加动作差距的问题。图 1 表示的是在 Asterix 环境中, 在每个训练步骤中最优和次优动作之间的动作差距轨迹示意图。从中可以看出 AL 方法在早期阶段过度增加 了动作差距。虽然动作差距在后期得到纠正,但这对算法的性能有非常负面的影响。我们称这个问题是一种不 正确的动作差距现象。这表明直接使用 AL 算法往往既激进又冒险。因此,可能会增加学习的难度。回想一 下,AL 方法包括两个方面,即时间差分 (TD) 目标估计方面和优势学习方面。从函数逼近的角度来看,这两 个方面都严重依赖于底层 Q 神经网络的估计值,该网络可以预测在给定状态下采取的任何动作的动作值。当 近似值函数诱导的最优动作与真正的最优动作不一致时,该方法就会出现问题。这可能会显着增加不正确的 动作差距值的风险。
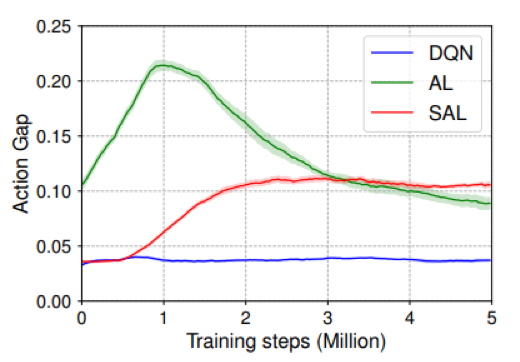
图1 动作差距曲线
2. 方法概述
基于这些观察,本文提出了一种名为光滑优势学习(Smoothing Advantage Learning,SAL)的新方法来 缓解这个问题。所提出方法的关键思想是利用了值平滑技术,可以通过缓慢的更新/迭代使估计的 Q 更准确, 1 论文导读 2 有利于在早期阶段不会增加不正确的动作值,使训练的稳定性,其定义为:

其中V(s)=maaxQ(s,a)和算子��是最优贝尔曼算子。在论文中,分别从精确值迭代和近似值迭代的角度分析了所提出的算子,表明所提出算子的收敛点\hat{Q*}和最优贝尔曼方程的收敛点Q*之间的关系,即
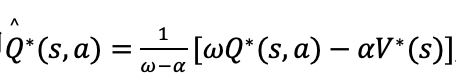
以看出收敛之后好坏动作的顺序保持不变,进一步的扩展了原始算法的理论;所 提出的算法能有效的降低误差上界对算法的影响,即SAL(ε)≤AL(ε)成立。进一步的理论分析表明,所提出 的算法能够取得控制收敛速度和近似误差上界之间的权衡,而且增加最优和次优动作值之间的动作差距有助于稳定训练过程。
3. 实验结果
本文是在 MinAtar 和 Atari 环境中进行训练和测试。一些在 MinAtar 上的对比结果如图2所示。可以看 到与 DQN 相比原始的 AL 算法并没有显著的提高算法的性能,然而所提出的方法受误差的影响比较小,因 此最终在大多数情况下优于比较的算法。
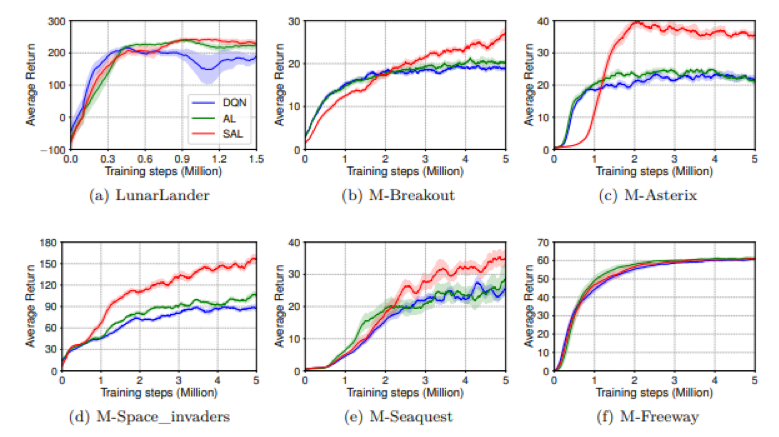
图2 评估 SAL 与 AL 和 DQN 的性能曲线
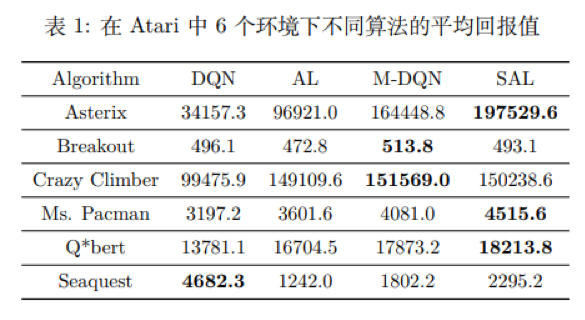
如下表1所示,本文还在复杂的 Atari 环境中进行了一部分实验,可以看出所提出的方法与目前最先进的 Munchausen-DQN(M-DQN)算法是可竞争的。还有一些关于所提出方法的不同参数的性能以及对动作差距 的影响实验请查阅论文。

 京公网安备11010802017125号
京公网安备11010802017125号