
2022年论文导读第二十六期
【论文导读】2022年论文导读第二十六期
CCF多媒体专委会 2022-12-27 09:00 发表于吉林


论文导读
2022年论文导读第二十六期(总第六十六期)
目 录
|
1 |
Deep Domain Adaptation Based Multi-Spectral Salient Object Detection |
|
2 |
Synthetic Data Supervised Salient Object Detection |
|
3 |
Pixel is All You Need: Adversarial Trajectory-Ensemble Active Learning for Salient Object Detection |
|
4 |
Affinity Fusion Graph-Based Framework for Natural Image Segmentation |
|
5 |
Amorphous Region Context Modeling for Scene Recognition |
|
6 |
CrossNet: Detecting Objects as Crosses |
01
Deep Domain Adaptation Based Multi-Spectral Salient Object Detection
作者:宋邵乐,苗振江,余洪凯,房建武,郑康,马聪,王松
单位:北京交通大学,克利夫兰州立大学,长安大学,南卡罗来纳大学
邮箱:
14112060@bjtu.edu.cn
zjmiao@bjtu.edu.cn
h.yu19@csuohio.edu
j.w.fangit@gmail.com
zheng37@email.sc.edu
13112063@bjtu.edu.cn
songwang@cec.sc.edu
论文:
https://ieeexplore.ieee.org/abstract/document/9308922
基于RGB图像的显著目标检测,利用可见光谱段下采集的RGB图像作为任务的输入,可能无法较好处理如阴影影响、前景背景相似、较强或者较弱光照影响等复杂情况下的显著目标检测问题。本文中的多光谱显著目标检测,旨在利用可见光和近红外光谱下获取的图像共同完成显著目标检测,提升复杂图像情况下的性能。
本文将多光谱显著目标检测建模为无监督领域自适应问题,利用源域有标注RGB数据和目标域无标注多光谱数据的信息来提升多光谱显著目标检测任务性能。首先利用数据生成模型合成源域缺乏的图像模态数据,缓解数据不对应问题引入的领域差异;然后针对多光谱显著目标检测任务,提出基于生成对抗领域自适应网络的框架,利用已有常规RGB显著目标检测数据集,辅助多光谱数据集上显著目标检测任务的实现。

图1 多光谱显著目标检测网络框架
本文采集了一个包含780组可见光-近红外(RGB-NIR)图像对的数据集,用于多光谱显著目标检测。数据集中,除了采集常见的显著目标检测场景图像,还特别考虑了一些单一RGB图像不能提供较好的显著性分辨率的复杂情况下的图像。

图2 数据集图像示例
02
Synthetic Data Supervised Salient Object Detection
作者:吴振宇1,王琳1,王玮2,史腾飞1,陈程立诏3,郝爱民1,李硕4
单位:1北京航空航天大学,2哈尔滨工业大学,3中国石油大学,4凯斯西储大学
邮箱:
wuzhenyu_961@126.com
论文:
https://arxiv.org/abs/2210.13835
代码:
https://github.com/wuzhenyubuaa/SODGAN
引言:最近,由于基于深度模型的显著性物体检测取得了重大进展。然而,基于深度模型的方法通常需要依赖于像素级的人注释数据集实现高性能。标记大规模像素级数据集是非常耗时。 为了减轻对逐像素注释的依赖,大量的弱监督的显著物体检测方法被提出。典型的语义级弱监督使用图像级标签进行显著物体定位,然后使用预测的显著性图迭代微调其模型。此外,张等人最近还提出了涂鸦监督以减少图像级标签的不确定性。尽管这些方法缓解了对像素级注释的依赖,但它们存在很多缺点,包括低预测精度、复杂的训练策略、专用网络架构和额外的边缘信息等。
方法:在本文中,我们为显著性物件检测提出了一种新的范式,命名为SODGAN(见图1),它可以用少量标记数据生成无限高质量的图像和标签对,以取代人工标记的DUTS-TR数据集。具体来说,我们的SODGAN有三个阶段:阶段一:利用现有的生成对抗网络BigGAN来生成真实的图像,同时提出个轻量级的显著性掩模生成器来合成掩模。阶段二:从合成数据池中选择高质量图像和标注对,如图2。阶段三:使用那些高质量的图像和标注对训练显著性网络。我们的方法是首次提出使用合成数据来训练显著性物体深度模型,并且取得突出的性能。
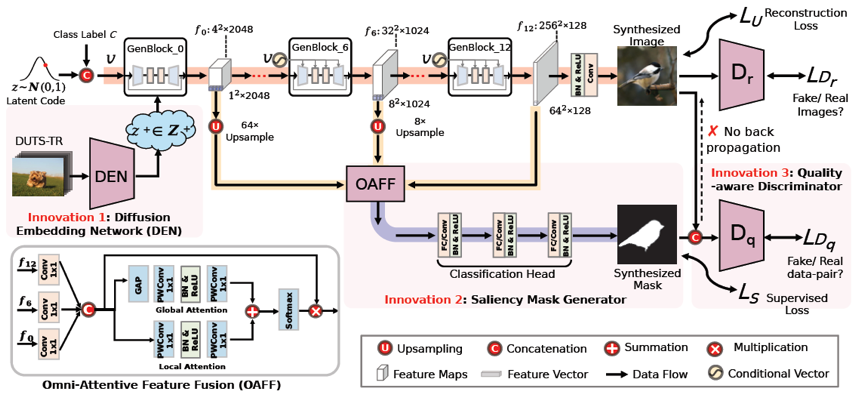
图1 方法流程图

图2 合成数据结果图
实验结果:如下表所示,我们使用合成数据集训练的模型性能能达到真实数据集训练模型的98%的性能,并且显著超过了当前最先进的半监督和弱监督方法,我们的方法大大减少了对逐像素标注的依赖。

03
Pixel is All You Need: Adversarial Trajectory-Ensemble Active Learning for Salient Object Detection
点标记数据是你所需要的:基于对抗路径集成主动学习的显著性物体检测
作者:吴振宇1,5,王琳1,王玮2,夏清3,陈程立诏4,郝爱民1,5,李硕6
单位:1北京航空航天大学,2哈尔滨工业大学(深圳),3商汤集团,4中国石油大学(华东),5鹏城实验室,6凯斯西储大学
邮箱:
wuzhenyu_961@126.com
论文:
https://arxiv.org/pdf/2212.06493.pdf
问题与分析:最近,由于基于深度模型的显著性物体检测取得了重大进展。然而,基于深度模型的方法通常需要依赖于像素级的人注释数据集实现高性能。标记大规模像素级数据集是非常耗时。为了减轻对逐像素注释的依赖,大量的弱监督的显著物体检测方法被提出。典型的语义级弱监督使用图像级标签进行显著物体定位,然后使用预测的显著性图迭代微调其模型。此外,张等人最近还提出了涂鸦监督以减少图像级标签的不确定性。尽管这些方法缓解了对像素级注释的依赖,但目前并不清楚使用弱监督的数据集训练得到的模型是否能取得与强监督数据训练的模型相当的性能?
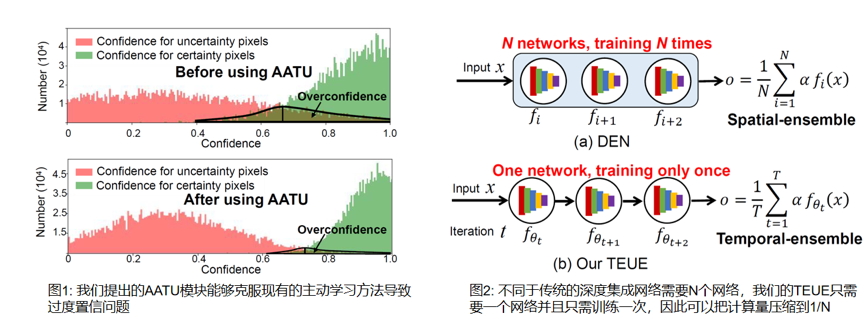
解决方案:在本文中,我们首次回答了这个问题通过证明一个假设:存在一个点标注数据集训练的模型能取得与逐像素标注数据集训练的模型相当的性能。这个假设如果成立,它的意义是重大的,这表明逐像素标注数据集不是必须的,这将使人们从繁重的标注数据中解放出来。然而找到这样一个点标注数据集并不是简单的事情,这里存在两个挑战: 1) 在标准的主动学习范式中,不确定像素点通常定义为那些置信度较低的像素点。然而,我们的实验表明,如图1所示,现有的主动学习方法通常会过度置信预测,导致不准确的估计; 2) 尽管深度集成网络是不确定性估计方法中最有效的一种,但是它的计算开销非常大。例如,相比于基准模型,Zaidi 等人提出的NES模型将计算量增加了10倍。
为了解决上述挑战,我们提出一种新的且非常高效的对抗路径集成主动学习方法,该方法能够准确定位不确定像素点并且计算开销与基准模型相当。具体的,首先,我们不再聚焦于开发一种新的正则方法去弥补softmax函数导致的过度置信问题,而是我们从一个全新的视觉解决这个问题,即我们提出一种对抗攻击置信估计方法,该方法能让我们全面评估像素点的不确定性;其次,我们提出一种路径集成模型,该方法通过集成优化路径上的预训练模型以达到集成学习的目的,该方法可以将计算开销降低至1/N。

图3方法流
实验结果:如下表所示,我们首次证明了使用点标注数据训练的模型性能取得逐像素标注数据训练模型的97%—99%的性能,并且显著超过了当前最先进的半监督和弱监督方法,这对于理解弱监督学习具有指导意义。
表1 主体实验结果


图4 可视化结果对比
04
Affinity Fusion Graph-Based Framework for Natural Image Segmentation
作者:张杨1,2, 刘默耘3, 贺敬武1, 潘飞1, 郭延文1
单位:1南京大学, 2湖北工业大学, 3华中科技大学
邮箱:
yzhangcst@smail.nju.edu.cn
ywguo@nju.edu.cn
论文:
https://ieeexplore.ieee.org/document/9334427
代码:
https://github.com/Yangzhangcst/AF-graph
自然图像分割:
https://github.com/Yangzhangcst/Natural-color-image-segmentation
面向场景理解的图像分割是计算机视觉中一项基础而又富有挑战性的任务,在许多实际应用中发挥着重要的作用。当难以获得大量精确标注的数据时,有监督的方法无法提供可靠的解决方案,传统的无监督方法则更合适解决此类问题。目前,基于图的无监督方法既能体现图像像素间的空间信息,又能体现其特征信息,已经成为一种主流算法。其中,最具有代表性的方法则更多地依赖于借助多尺度超像素建立关联图,其分割性能很大程度上取决于图的拓扑结构和图上节点间的关联性。
如图1所示, 邻接图(adjacency-graph)通常无法捕捉超像素的全局关联性,当分割对象在图像中的占比较大时,易导致错误的分割结果。l0图利用邻域超像素的线性组合近似每个超像素,以稀疏的方式捕捉全局关联,但这种关联性往往不强调相邻性,因此容易在分割中产生孤立的区域。GL图(global/local-graph)和AASP图(adaptive affinity graph with subspace pursuit)结合上述邻接图和l0图,实现了比单个图更好的分割性能。其中,GL图根据超像素的面积,AASP图根据超像素的相似度对超像素的关联节点进行分类。然而,基于关联图的图像分割中仍然存在三个难点:1)混合关联图通常依据超像素的面积和相似度等经验论;2)如图2所示,由于超像素特征在不同的尺度上变化很大,根据一些简单的特征定义出的局部和全局节点并不准确;3)上述l0图等线性图,不能充分利用多尺度超像素间非线性的结构信息。

图1 基于关联图的不同分割方法的比较结果。基于关联图的不同分割方法的比较结果。虽然超像素在不同的尺度上有很大的不同,但是本文提出的方法可以获得最好的结果。
要解决上述问题,首先需要从原理上讨论不同关联图间的关系。对于基于关联图的分割,通常使用相邻超像素的线性组合来近似每个超像素的特征。这种近似被认为是相邻超像素之间的子空间保持(subspace-preserving representation, SR)。由于子空间保持的稀疏性,其在不同尺度超像素下的变化并不明显,也可以利用这种子空间保持进行关联图融合。现给出每个尺度下超像素的子空间保持,再对超像素(节点)建立关联矩阵,并应用谱聚类选择关联节点。然而,由于子空间保持只能表征超像素的线性关系,用线性图对图像进行分割时,容易产生孤立的区域。如图3所示,为了丰富混合图的特性,利用超像素之间的非线性关系,进一步提高分割性能。因此,在邻接图的基础上,本文在核空间中构造了一个基于谱聚类的近邻图(KSC图),旨在发现超像素的非线性结构信息。在BSD300,BSD500和MSRC数据集上,将AF图与其他自然图像分割算法进行比较,结果表明AF图具有良好的分割性能和较高的效率。

图2 不同尺度下,由超像素计算出的子空间保持和面积。多尺度超像素的子空间保持特性总是稀疏的。随着超像素数目的减少,子空间保持特性的变化明显小于超像素区域面积的变化。与面积相比,子空间保持表示能更好地揭示超像素的隶属关系。

图3 KSC图和l0图的可视化比较结果。从左到右分别给出了超像素图像、KSC图、KSC图得到的分割结果、l0图、由l0图得到的分割结果。KSC图为稠密图,而l0图比KSC图稀疏,但KSC图的分割性能略高于l0图。
05
Amorphous Region Context Modeling for Scene Recognition
作者:曾海涛、宋新航、陈恭巍、蒋树强
单位:中国科学院计算技术研究所
邮箱:
haitao.zeng@vipl.ict.ac.cn;
xinhang.song@vipl.ict.ac.cn;
gongwei.chen@vipl.ict.ac.cn;
sqjiang@ict.ac.cn
论文:
https://ieeexplore.ieee.org/abstract/document/9305712
1.论文动机
场景识别的目的是预测图像对应的场景标签。场景图像通常由前景和背景区域内容组成,一般前景是指物体,而背景则是除物体外的区域(如沙滩、天空)。由于场景中语义内容复杂多样,难以从整体高精度识别。早期的工作试图通过用密集网格划分场景,提取patch级别的特征来表示局部内容,这样的网格可以将某个物体区域分成几个离散的部分,使得区域块中的语义含义并不明确。此外,有些提取显著性物体的方法可能只关注场景图像中的前景内容,使得背景内容和空间结构信息不能被有效建模。因此,本文面向因固定区域划分导致的语义模糊问题,提出了一种基于不定形区域提取的场景识别方法。该方法利用语义分割技术提取无定形的语义区域,然后通过图神经网络对区域特征建模,来探索区域之间的上下文关系,得到可以用于场景识别的具有可区分性的场景特征。
2.方法概述
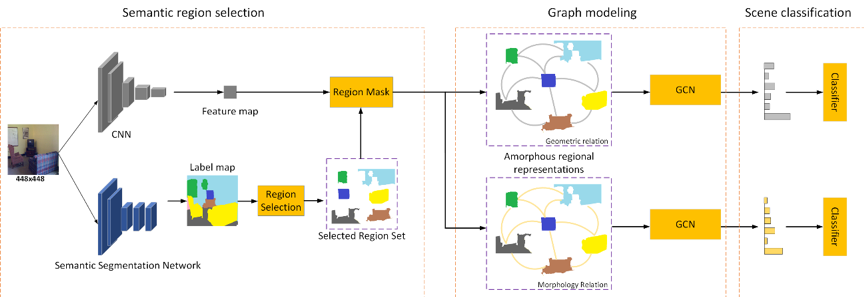
图1 ARG模型框架
针对以上问题,我们提出了无定形区域的上下文图模型场景识别方法(ARG),如图1所示。方法包含三个模块,无定形区域提取模块,图卷积网络建模模块和场景分类模块。在第一个模块中,首先使用语义分割模型检测区域内容本身的边界,其中图像的每个像素都使用显式标签进行标注,将具有相同标签的相邻像素聚集获得无定形区域特征。通过语义分割检测区域可以帮助我们获得更丰富的区域内容(包括前景和背景)。而这种多样性的区域内容的可以提供丰富的上下文信息,更加全面地表示场景。在第二个模块中,为了探索区域之间的上下文关系,我们使用了图卷积网络(GCN)对其进行建模。在这里,区域特征被定义为GCN的节点,区域之间的几何和形态关系被定义为边。这个模块的优势在于,可以从两个独立的方面探索区域之间的上下文关系,优化来自不同方向的特征并生成具有可区分性的场景特征。这些优化后的特征被输入到场景分类器中,用于在最后一个模块中预测场景标签。
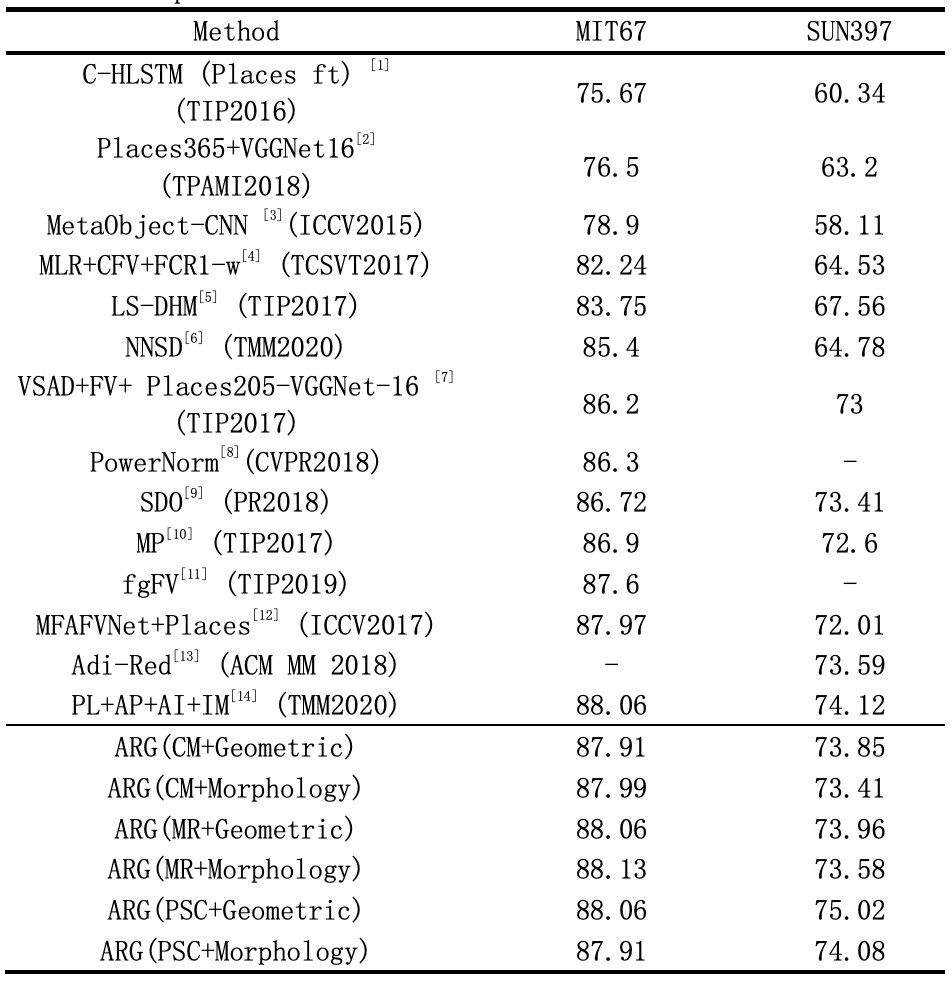
3. 实验结果
为了衡量提出的无定形区域的上下文图模型方法(ARG)的性能,我们将其和现有的方法进行了对比。从实验结果可以发现,提出的方法在两个常用的场景识别数据集MIT67和SUN397上均取得不错的性能,具体结果如下表所示。和目前的基于固定区域的方法[1,5,7,10,13]相比,ARG的表现更优异,这证明了基于无定形的区域建模的方法是有效的。此外,和基于前景物体的方法[4,9]相比,ARG的性能增益是明显的,这表明建模前景和背景之间的上下文关系有助于场景识别。此外,与多尺度、多特征方法相比[1,4,5,7,8,9,10,12,13,14],ARG只使用了单特征、单比例特征图作为输入且取得更优异的结果。这些优异的性能证明了提出方法的通用性和有效性。
表1 与相关工作的结果对比
06
CrossNet: Detecting Objects as Crosses
作者:冷佳旭1,刘莹2,王智慧3,胡海波4,高新波1
单位:1重庆邮电大学、2中国科学院大学、3山东科技大学、4重庆大学
邮箱:
lengjx@cqupt.edu.cn,
yingliu@ucas.ac.cn,
zh_wang@sdust.edu.cn
haibo.hu@cqu.edu.cn,
gaoxb@cqupt.edu.cn
论文:
https://ieeexplore.ieee.org/document/9357941
引言:目标检测是计算视觉领域的一个研究热点,也是其他视觉任务(如目标跟踪、可视关系检测、场景图生成等)的基础,受到了广大研究学者的关注。目前,目标检测框架大致可以分为anchor-based和anchor-free两大类。Anchor-based的方法通过人工设计恰当的anchor尺寸和数量来实现目标的检测,而anchor-free的方法则通过关键点预测来替代了anchor机制。由于anchor-based方法的性能严重依赖于anchor的质量,因此所得到的的模型泛化性较差,并且稠密的anchor带来了巨大计算量。为此,最新的研究主要聚焦于anchor-free的方法,并提出了一系列优秀的算法,如CornerNet、ExtremeNet、CenterNet等。
研究动机:尽管当前基于关键点预测的anchor-free方法已经取得了较大的突破,但是其检测性能仍然是差强人意的,其性能在一些固定场景下还无法超越anchor-based 的方法。其主要原因在于,这些方法缺乏对目标关键点和尺寸预测模块的定制化设计,从而导致难以对目标进行精准定位。如图1所示,CenterNet会存在对小目标漏检的情况,并且对中心和宽高的预测也不够精准。

图1 CenterNet在MS COCO数据集上的一些检测结果。其中,红色框为由于中心点预测失败而导致漏检的目标。此外,一些预测框与目标真实的位置也是存在偏差的。
方法概述:提出了一种新的基于关键点的检测框架,称为CrossNet。具体地,我们首先设计了一种级联中心预测方法,该方法引入了从粗到细的思想来提升中心预测。此外,由于中心预测性比较于尺寸预测是更容易的,因此我们设计了一种基于中心注意的尺寸回归模块,该模块使用中心的检测结果来辅助目标尺寸的预测。图2展示了CrossNet的整体框架结构。整个检测过程主要包括以下几个步骤: 1)基于卷积神经网络的特征提取,将图像输入到特征提取网络,得到不同分辨率的卷积特征图; 2)单一分辨率下的中心点和宽高预测,通过卷积操作预测出中心点位置,然后联合卷积特征图和中心预测结果来实现目标宽高的回归; 3)级联的中心点和宽高预测,通过由粗到细的方式逐步逼近目标的真实边界框; 4)在得到中心图、尺寸图和中心偏移图后,对中心图中的预测中心点按照得分进行排序,并选出排名前 100的中心点,然后将其与尺寸图和中心偏移图中对应位置的宽高和偏移量进行组合,从而得到最终的目标边界框。

图2 CrossNet的整体框架结构
实验结果:为了验证所提出方法的有效性,我们在MS COCO和KITTI等公开数据集上进行了实验验证。实验结果表明,无论是定量还是定性的结果,我们的方法均优于基线模型。
表1 定量检测结果对比


图3 可视化结果对比:CenterNet VS CrossNet

 京公网安备11010802017125号
京公网安备11010802017125号