
2022年论文导读第二十三期
【论文导读】2022年论文导读第二十三期
CCF多媒体专委会 2022-11-15 10:20 发表于北京


论文导读
2022年论文导读第二十三期(总第六十三期)
目 录
|
1 |
Correlation Field for Boosting 3D Object Detection in Structured Scenes |
|
2 |
Contrastive Learning from Extremely Augmented Skeleton Sequences for Self-Supervised Action Recognition |
|
3 |
Efficient Dialog Policy Learning by Reasoning with Contextual Knowledge |
|
4 |
Text Is No More Enough! A Benchmark for Profile-Based Spoken Language Understanding |
|
5
6
|
Deep Graph Clustering via Dual Correlation Reduction Federated Learning for Face Recognition with Gradient Correction |
01
Correlation Field for Boosting 3D Object Detection in Structured Scenes
作者:孙健华,方浩树,朱祥辉,李杰锋,卢策吾
单位:上海交通大学
邮箱:
gothic@sjtu.edu.cn,
lucewu@sjtu.edu.cn
论文:
https://www.aaai.org/AAAI22Papers/AAAI-4991.SunJ.pdf
准确的大规模标注数据能够为三维物体检测模型性能带来巨大提升,但是大量数据的获取与标注需要很高成本。因而借助于数据增强算法合成高质量的训练数据是提升三维物体检测性能的有效途径。在本文中,我们针对结构化的三维点云场景提出了一个简单而有效的在线“裁剪和粘贴”数据增强流程,名为CorrelaBoost。由于物体之间存在功能性和自然的交互关系,三维物体在结构化的场景中应该有合理的相对位置,我们将这种相关性表达为一种interactive force。基于这个力,一个叫做 Correlation Field的能量场可以在整个三维空间中被相应地建模出来,如下图所示。

我们首先定义物体间的interactive force,以确保功能物体对之间处于适当的相对位置。考虑到物体在原始训练数据集中出现的位置是最自然的,我们检索了两个类别中所有的物体之间的相对距离,并将其表示为一组点,命名为Correlation Origin Set。通过在原点集的每个点上定义对相应类别的物体的吸引力,我们可以在力的基础上计算出Correlation Field能量场。而物体在稳定状态下(低能量位置)即处于适当的功能性距离,整个场景是合理的。Correlation Field有三个重要的属性,1)可叠加,2)最佳初始状态,3)类别导向。

基于这三个属性,我们在Correlation Field上通过维持整个系统的低能量状态,得出了两种不同的数据增强策略:1)类别一致性互换,2)能量最优变换。类别一致性互换是指,以适当的形状和方向交换同一类别的物体对。由于同一类别的物体通常表现出相似的出现频率,并具有相似的功能,这种方法能够使这个系统的能量仍然保持在较低水平。能量最优变换是指,根据对某一物体低能量的位置进行采样,然后将该物体从原位置剪切下来粘贴到采样的新位置。通过这两个策略得到的合成数据能够确保很强的视觉合理性和真实性。
我们在各种流行的基准数据集上用不同的三维检测框架进行了详尽的实验,结果表明,我们的方法能够为检测精度带来了很大的提升,并在数据增强方面明显优于之前的方法,如下图所示。
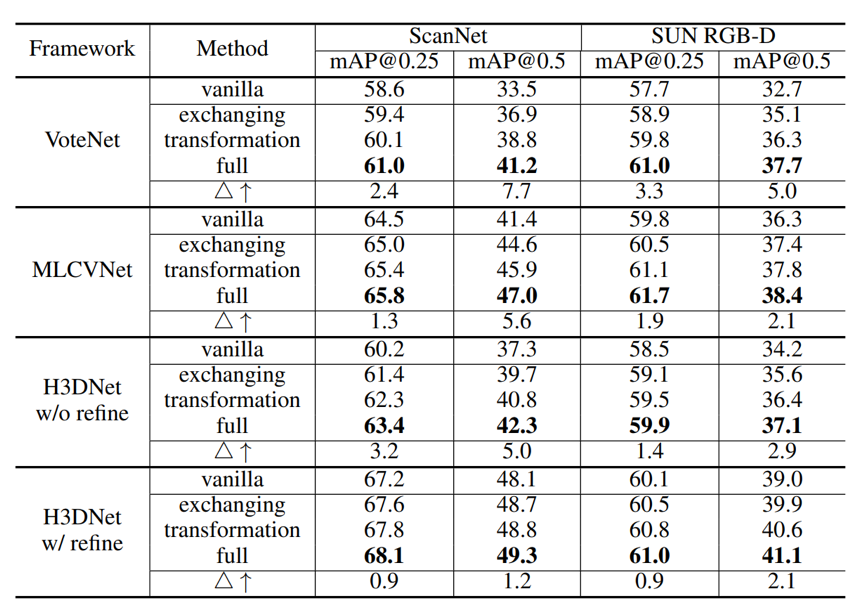
例如,以mAP@0.5为指标,VoteNet框架在ScanNetV2数据集上的性能提高了7.7,在SUN RGB-D数据集上提高了5.0。同时我们的方法实现起来简单,增加的计算时间开销更少。
02
Contrastive Learning from Extremely Augmented Skeleton Sequences for Self-Supervised Action Recognition
作者:郭天宇1,刘宏1*,陈湛1,刘梦源2,王韬1,丁润伟1
单位:1北京大学,2中山大学
邮箱:
levigty@stu.pku.edu.cn
hongliu@pku.edu.cn
zhanchen_cz@pku.edu.cn
nkliuyifang@gmail.com
taowang@stu.pku.edu.cn
dingrunwei@pku.edu.cn
论文:
https://ojs.aaai.org/index.php/AAAI/article/view/19957
代码:
https://github.com/Levigty/AimCLR
*通讯作者
引言:人体行为识别是计算机视觉领域的研究热点之一,而骨架数据相比于RGB数据而言对于光照、遮挡、外观变化等较为鲁棒,这也使得很多研究者聚焦于基于骨架序列的人体行为识别。目前,大多数骨架行为识别方法遵循全监督学习范式,依赖于含有人工标注的大规模数据集。基于自监督学习的骨架行为识别可以在代理任务中只使用行为数据,不依赖行为标签,从而学习到更加通用的特征表示,更符合实际应用场景的需求。
研究动机:现有的基于对比学习的自监督骨架行为识别方法使用常规增强来构建相似的正样本,所引入的时空信息有限,这限制了模型探索新运动模式的能力。在本文中,为了学习到更好的特征表示,我们提出了AimCLR框架,通过强数据增强引入丰富的运动模式,进而提出一系列策略来更好地使用这些时空运动信息。
方法概述:首先,本文提出了一系列强数据增强和基于能量注意力引导的丢弃机制(EADM)来获得多样化的正样本,这带来了新颖的运动模式,以提高学习到的特征表示的普适性。其次,由于强数据增强引入的剧烈运动变化,直接使用InfoNCE损失不再合适,因此本文提出了对偶分布最小化损失(D3M损失),以更温和的方式最小化分布散度。最后,本文提出了最近邻挖掘(NNM),进一步挖掘潜在的正样本,使正负样本的选择更加合理。
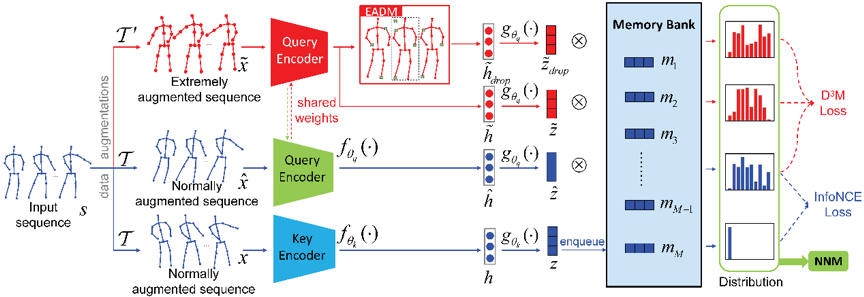
图1 AimCLR方法概述
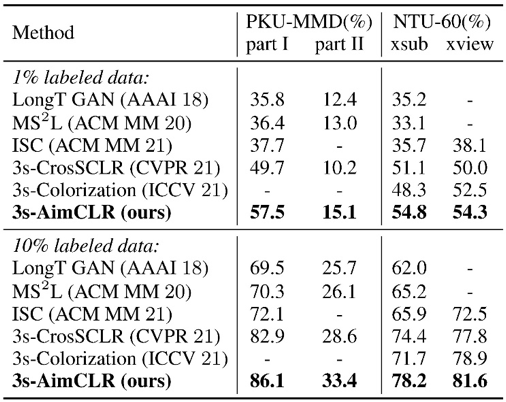
实验结果:本文在三个主流数据集,即NTU RGB+D、PKU-MMD、NTU RGB+D 120数据集上验证了方法的有效性。所提出的3s-AimCLR在多个下游评价协议下都取得了SOTA性能。
表1 线性评价结果
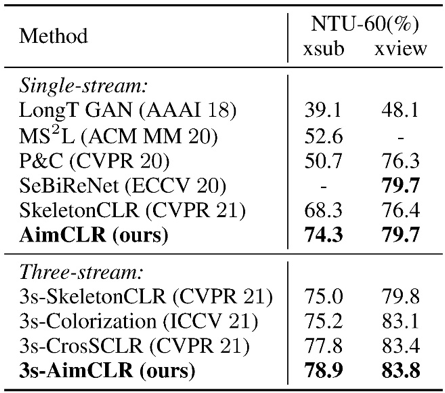
表2 半监督评价结果
可视化结果:如图2所示的T-SNE结果也显示了本文提出的方法的有效性,无论从定量还是定性的结果,本文的方法在单流和多流结果上都优于基线模型。
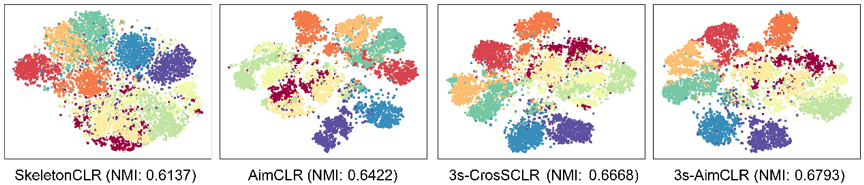
图2 T-SNE可视化结果
03
Efficient Dialog Policy Learning by Reasoning with Contextual Knowledge
作者:张昊迪1,曾志超1,鲁科汀2,伍楷舜1,张世琦3
单位:1深圳大学计算机与软件学院,2百度,3纽约州立大学宾汉姆顿分校计算机系
邮箱:
zhanghd.ustc@gmail.com,
cengzhichao2019@szu.edu.cn
ktlu@mail.ustc.edu.cn
wu@szu.edu.cn
zhangs@binghamton.edu
论文:
https://www.aaai.org/AAAI22Papers/AAAI-10623.ZhangH.pdf
代码:
https://github.com/ResearchGroupHdZhang/DPL_AAAI22
导读
该论文由深圳大学计算机软件学院张昊迪课题组与纽约州立大学宾汉姆顿分校张世琦课题组合作完成。作者提出了一个面向任务的对话策略学习框架,将显式知识推理与深度强化算法结合,利用用户偏好和显式常识等语境知识,有效提高了对话策略学习的效果。
引言
面向任务的多轮对话系统通常由语音识别、语音合成与对话管理等模块构成。其中对话管理作为核心决策模块,控制着多轮对话的总体进程与走向,也决定了对话的质量。传统的基于深度强化学习的对话管理往往存在奖励稀疏、缺乏可解释性等问题,并且难以利用显式表示的知识进行推理。该论文作者提出了一种将显式知识推理与深度强化学习结合的方法,把丰富的语境知识用于对话策略训练,以提升智能体的对话任务表现。
该论文的主要技术贡献如下:
首个在面向任务的多轮对话系统中将显式知识非单调推理和深度强化学习结合的工作,为知识与数据双驱动系统提供了新方法。
整合知识与数据,在多个对话应用领域、多个深度强化学习算法上均表现出性能提升,具有良好的泛化能力,同时提高了对话系统的可解释性。
方法介绍
该框架结合了知识驱动方法与数据驱动模型,并在开源对话平台PyDial上部署实现,总体设计如图1所示。

图1 对话策略学习框架
首先,通过历史数据训练马尔科夫逻辑网络,以生成该任务型对话系统的内部知识;并由回答集编程刻画相关的外部知识。其次,初始化深度模型权重,根据内部知识更新每个批次的对话状态值,开始智能体的训练。在对话的每轮训练中,由深度强化学习模型决定下一个动作,执行它并计算奖励值,历史决策及奖励被智能体记录。对话中止前使用回答集程序推理,得到优化决策。最后,每一轮对话结束后,根据智能体追踪的决策状态以及奖励更新深度强化学习模型,直到模型收敛。
实验结果
该论文在PyDial平台进行了一系列的实验,验证了以下三点结论。
首先,显式的语境知识推理可以有效地提高多轮对话系统的训练效率与模型表现。
如图2所示,对于A2C, DQN, ACER, BBQN等深度强化学习算法,马尔科夫逻辑网络推理出的内部知识(MLN)和回答集编程的外部知识(ASP),显著提高了对话系统的学习效率与效果。

图2 由左上至右下:A2C、DQN、ACER、BBQN中的语境推理表现
其次,马尔科夫逻辑网的训练数据数量与模型表现正相关。
如图3所示,训练的用户历史数据越多,马尔可夫逻辑网就能够更准确地刻画世界状态,因此其推理效果也越好。

图3 不同体量数据训练下的马尔可夫逻辑网对模型表现的影响
最后,该方法在不完整、不准确的知识下具有鲁棒性。
如图4所示,在准确的、不准确的、不完整的、无知识这四种设置下,外部知识质量对于模型提升正相关。而且即使领域知识不完整或是不准确,仍然对对话系统性能产生了提升效果。
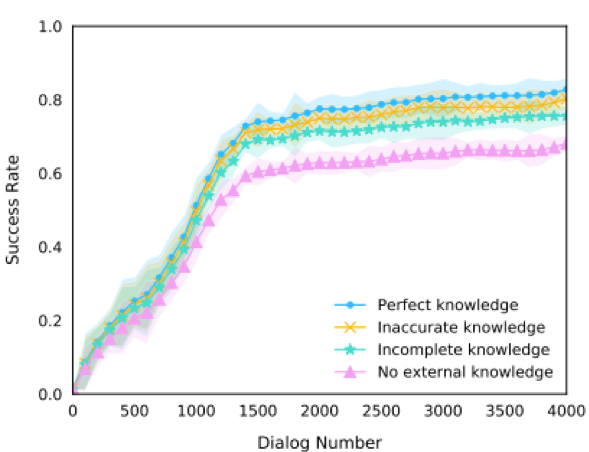
图4 在不同质量的知识下方法的鲁棒性实验
总结展望
本文将两种知识表示和推理范式(MLN和ASP)集成到深度强化学习算法框架中,并将其应用于面向任务的对话策略学习,使用答案集编程进行非单调的确定性推理,并使用马尔可夫逻辑网络进行概率性推理。在真实对话模拟平台上的实验结果表明,语境知识推理可以显著提高代理在对话策略学习中的性能。这是第一个在对话策略学习环境中将显式知识推理与深度强化学习结合的工作,为知识与数据双驱动的人工智能提供了新的思路与框架。
04
Text Is No More Enough! A Benchmark for Profile-Based Spoken Language Understanding
作者:徐啸1*,覃立波1*,陈开济2,吴国兴2,李林琳2,车万翔1#
单位:1哈尔滨工业大学社会计算与信息检索研究中心,2华为
邮箱:
xxu@ir.hit.edu.cn
lbqin@ir.hit.edu.cn
chenkaiji@huawei.com
wuguoxing1@huawei.com
lynn.lilinlin@huawei.com
car@ir.hit.edu.cn
论文链接:
https://ojs.aaai.org/index.php/AAAI/article/view/21411
代码链接:
https://github.com/LooperXX/ProSLU
*共同一作,#通讯作者
1. 背景与动机
口语语言理解(SLU)任务的目的是获取用户询问语句的语义框架表示信息,进而将这些信息为对话管理模块以及自然语言生成模块所使用。SLU任务通常包含意图识别任务和槽位填充任务。以句子 watch comedy movies 为例,SLU系统需要分别输出意图 WatchMovie 和槽位名称 movie_type 以及槽值 comedy movies。
SLU的研究目前主要局限于传统的基于纯文本的SLU任务,该任务假设,简单的基于纯文本就能够正确识别用户的意图和槽位。但在真实的业务场景中,经常由于用户的口语化输入,而面临具有语义歧义的用户话语。现有的基于纯文本的SLU系统难以应对这一现实场景下的复杂问题。以 Play Monkey King 为例,Monkey King,也就是孙悟空,是一个具有歧义的名称,可以对应视频、音乐以及有声书三种类型的实体,因此难以基于纯文本确定其意图和槽位。
为了解决这一问题,本文提出了一个重要的新任务——基于Profile的口语语言理解任务(ProSLU),通过引入Profile信息,来辅助模型在歧义场景下完成意图和槽位的预测。
2. 任务定义
Profile信息的引入是为了帮助SLU系统,消除用户话语中的歧义。我们定义了以下三种Profile信息,分别是知识图谱信息、用户配置信息和环境感知信息。
知识图谱信息包括收集到的大量不同类型的实体及其丰富的属性信息,每个实体都会被展平为纯文本序列。
用户配置信息包括用户的个人设置和其他信息,例如用户对音频、视频和有声书这三类APP的使用偏好。
环境感知信息包括用户的当前状态和环境信息,例如移动状态和当前位置
我们将基于Profile的SLU任务简称为ProSLU,任务要求模型不仅依赖于输入语句,还要利用对应的Profile信息,来预测意图和槽位信息。

如上图所示,KG信息表明Monkey King可能是视频、音乐或有声书实体,UP信息表示当前用户更喜欢听音乐,CA信息表示用户当前正在跑步,结合上述三种Profile信息和用户话语,最终判断出用户的意图为听音乐,槽位为songName。
3. 数据集的构建
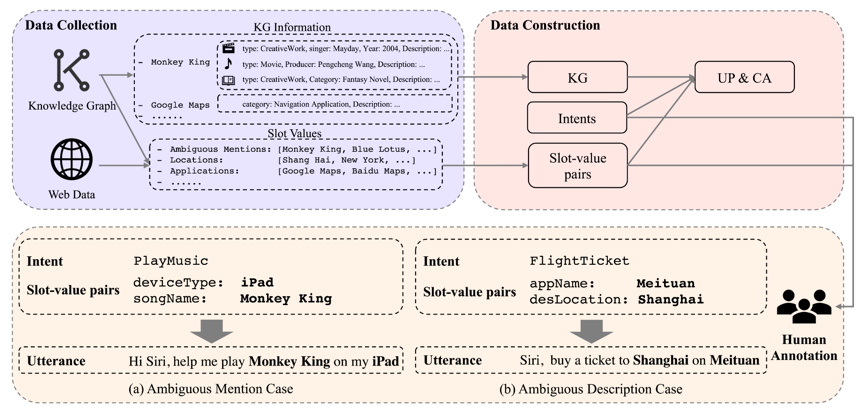
数据集的构建流程如上图所示:我们通过开源知识图谱和互联网数据完成了初步的数据收集,并设计了数据构建流程,完成了意图、槽值对以及Profile信息的初步构建,最后由标注者完成用户话语的编写。关于数据集的更多详细内容,请参考我们的论文。
4. 实验
本文基于现有SLU模型中的主要组件,构建了通用SLU模型,它由共享的编码器,意图识别解码器和槽位填充解码器构成。接着本文结合层次化注意力融合机制,设计了多层次知识适配器,从而分别在句子级和词级融入Profile信息,并且可以作为插件,轻松集成到现有SLU模型中。
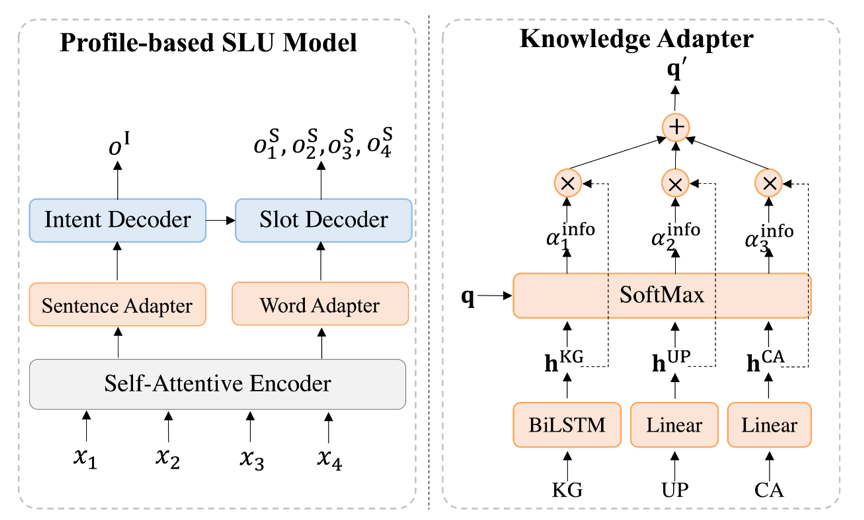
模型架构如上图所示,知识适配器分别在句子级和词级引入Profile信息,从而多层次的引入Profile信息,帮助消除话语中的歧义。
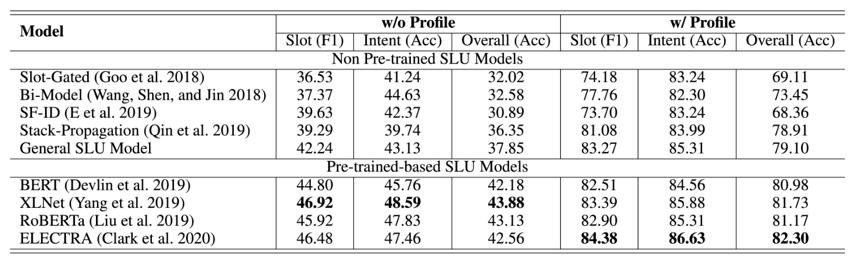
我们对现有的SLU Baseline进行了充分的实验,表中的第二大列和第三大列分别对应基于纯文本的SLU模型和借助我们设计的多层次知识适配器来引入Profile信息的ProSLU模型。在没有Profile信息时,现有的SLU模型都表现的很差;将共享的编码器替换为预训练语言模型后,模型性能得到一定提升,但是其表现还是很不好。而在引入了Profile信息后:
所有的SLU Baseline都取得了显著的效果提升,这充分证明了我们提出的ProSLU任务的重要性,以及Profile信息对解决用户话语中的歧义的有效性
所有的预训练SLU模型在引入了Profile信息后,也同样取得了显著的效果提升,这证明Profile信息和预训练语言模型的结合,能够有效提升效果
5. 未来挑战
ProSLU任务还存在着许多挑战:
KG信息的有效表示:知识图谱实体数量庞大,实体属性信息稀疏且复杂
Profile信息的高效融合:更加高效的信息融合方式,具有可扩展性的Profile信息融合方式
Profile信息的扩展:更多有注意消除语义歧义的Profile信息
05
Deep Graph Clustering via Dual Correlation Reduction
作者:刘悦,涂文轩,周思航,刘新旺,宋琳璇,杨希洪,祝恩
单位:国防科技大学
邮箱:
yueliu@nudt.edu.cn
twx@nudt.edu.cn
sihangjoe@gmail.com
xinwangliu@nudt.edu.cn
yangxihong@nudt.edu.cn
enzhu@nudt.edu.cn
slxnatavidad@163.com
论文链接:
https://ojs.aaai.org/index.php/AAAI/article/view/20726
代码链接:
https://github.com/yueliu1999/DCRN
深度图聚类合集:
https://github.com/yueliu1999/Awesome-Deep-Graph-Clustering
在图数据挖掘领域内,深度图聚类算法受到了研究者们广泛的关注,其目标是利用神经网络学习图中节点的表征嵌入,并将它们通过无监督的聚类层划分为不同的簇,如图1所示。
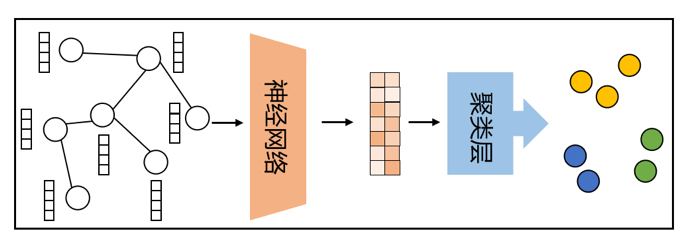
图1 深度图聚类流程
现有算法充分挖掘了节点属性信息和图结构信息,取得了较好的性能。但是,由于深度图聚类是完全无监督的,并且现有方法中的一些损失函数具有平凡解,因此容易引发表征坍缩问题,即所有节点都被倾向于编码为同一表征嵌入。在图2中,样本余弦相似度矩阵可视化实验验证了该问题的存在性。
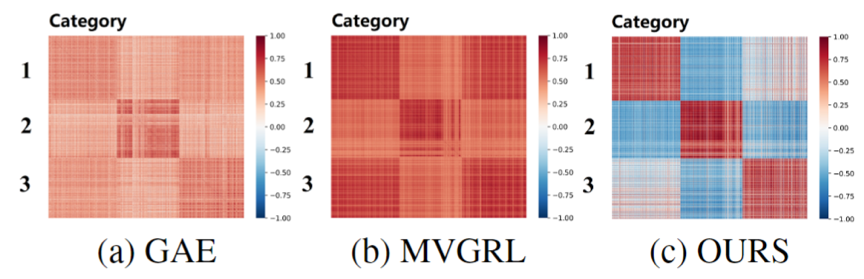
图2 深度图聚类中表征坍缩的问题
为了解决该问题,本文提出了名为dual correlation reduction network (DCRN) 的深度图聚类模型,其模型流程图如图3所示。该模型对症下药,从样本和特征两个层面降低表征的相关性以缓解表征坍缩问题。具体来说,模型首先分别计算了样本和特征的跨视图互相关矩阵,再将这两个矩阵分别对齐两个单位阵。从样本的角度来看,不同视图下的同一个节点具有相似的表征,不同视图下的不同节点具有不用的表征。从特征的角度来看,不同维度的特征需要降低相关性以增强表征的表示能力。因此提高了聚类的性能。

图3 DCRN模型流程图
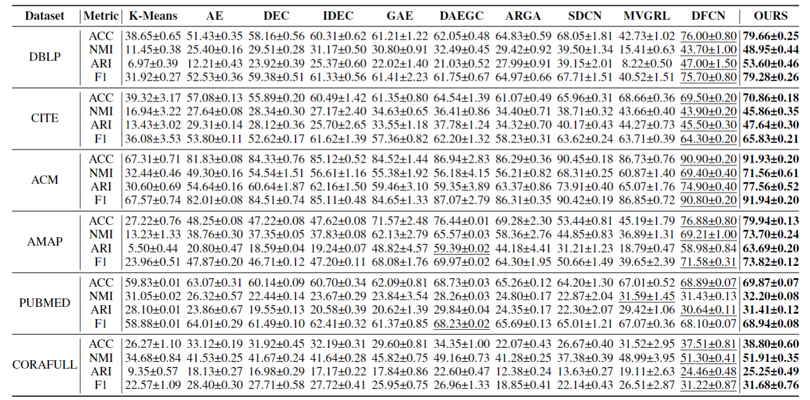
在6个数据集上大量的实验表明DCRN的有效性,其中调兰德指数ARI在DBLP数据集上超越了state-of-the-art方法6.60%,如表1所示。
表1 聚类性能比较表
此外,作者还整理了近年来图深度聚类的论文、代码和数据集于:
https://github.com/yueliu1999/Awesome-Deep-Graph-Clustering。
06
Federated Learning for Face Recognition with Gradient Correction
作者:牛逸凡,邓伟洪
单位:北京邮电大学
邮箱:
nyf@bupt.edu.cn;
whdeng@bupt.edu.cn
论文链接:
https://ojs.aaai.org/index.php/AAAI/article/view/20095/19854
1. 研究背景
人脸识别是生物特征识别技术中的一项重要技术,在许多领域得到了广泛的应用。目前的人脸识别算法一般使用公开人脸数据集作为训练集在一个中央服务器上进行端到端的训练。随着人们对人脸识别中隐私问题的日益关注,越来越多的公开人脸数据集面临着侵犯个人隐私的风险。在不远的未来,现有公开的人脸数据集很可能因为隐私问题而变得违法。更重要是,人脸识别的一个重要研究方向即无约束的人脸识别问题,旨在模型尽可能适用于更加通用变化多样的人脸数据,即大姿态,多种族,丰富的光照变化,人脸图片分辨率变化等。尽管已有的数据集是针对无约束人脸识别问题而建立的,但与真实场景相比,在某些方面仍存在一定的偏差。为了研究无约束的人脸识别问题,需要使用真实世界的人脸数据作为训练集,但是考虑到隐私问题,我们无权访问现实世界中的海量人脸数据。我们需要在保护个人隐私数据的前提下利用真实世界分布的人脸数据训练人脸识别模型。因此,研究人脸识别中的联邦学习算法对于解决实际问题至关重要。
2. 论文动机
联邦学习目前的研究方向主要集中在物体识别方向,目前已经提出了许多基于FedAvg 的变种算法。在传统的联邦学习算法中,整个网络模型的参数被看做一个整体并在众多的客户端与服务器之间分发传送。由于人脸识别存在特殊性,不同于物体识别,人脸识别的类特征向量(最后一层全连接层的参数)对应一个独特的身份。在传统的联邦学习算法中,一个客户端可以轻松获取其他客户端的类特征向量,基于目前已经提出的DeepInversion和一系列基于对抗生成网络(GAN)的人脸生成方法,可以利用类特征向量生成高保真的人脸图片,造成了隐私泄露,使传统的联邦学习算法不能直接应用于人脸识别问题。
3. 方法概述
为了确保类特征向量的隐私性,本文修改了深度卷积神经网络的最后一层全连接层,保证每个客户端拥有一个隐私的全连接层,从而实现了隐私保护。本文保证算法只能共享backbone参数,这就避免了人脸隐私数据的泄露。针对此优化设置,本文提出了本地目标函数的概念,在每个客户端中内使用各自的隐私类特征向量进行优化,即FedPE算法:
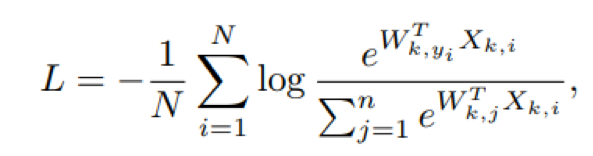
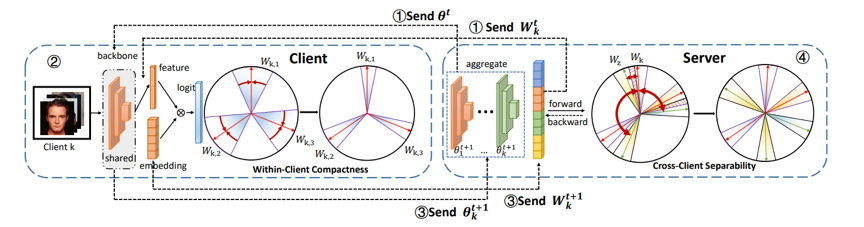
尽管FedPE实现了隐私保护,但是本文首先根据优化目标的差异性分析得知FedPE 缺少跨客户端优化,从而导致算法的最优解与集中式方法有着较大的差距。本文从反向传播的角度来解决这个问题,考虑到 softmax 函数梯度的特殊性质,本文采用了梯度修正的方案。在 FedPE 的基础上,本文在服务器端新增了一个优化步骤,用于修正网络梯度,即FedGC,从而确保网络的更新方向与标准的 Softmax 函数相近。通过理论分析验证了本文提出的 FedGC 的有效性。FedGC的优化步骤如图所示:
其中作者提出的梯度修正项如下,其中(·)'表示不反传梯度:

FedGC的优化过程分为四步:1.服务器将backbone参数分发给各个客户端,并将每个客户端对应的私有类特征向量发给对应客户端2.客户端使用本地数据集和私有类特征向量对网络进行优化3.客户端将backbone参数和私有类特征向量传送给服务器4.服务器对backbone参数进行聚合,对私有类特征向量进行修正。
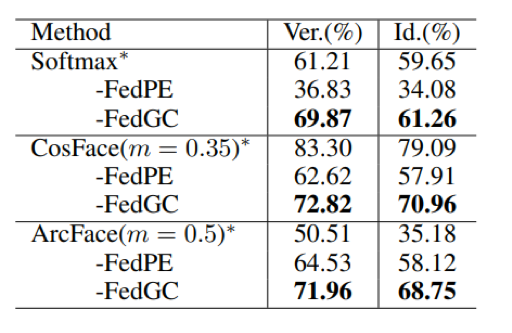
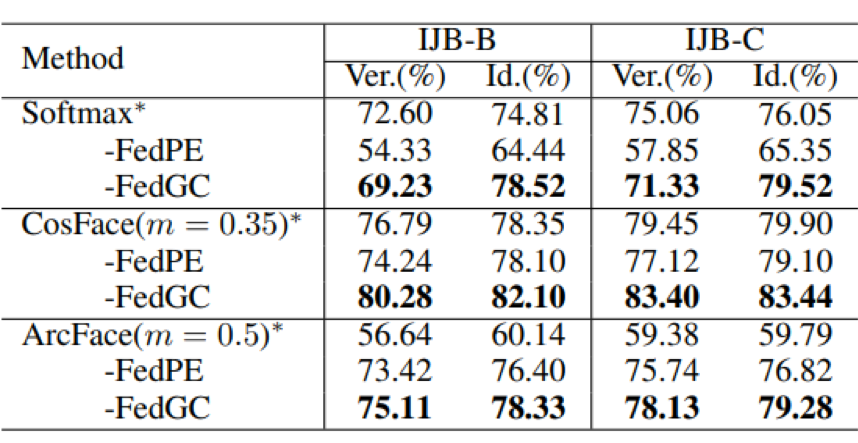
4. 实验结果
下表展示了作者所提出的方法在不同的人脸数据集上均取得了优越的性能,识别精度可以达到与传统集中式训练相当的水平。

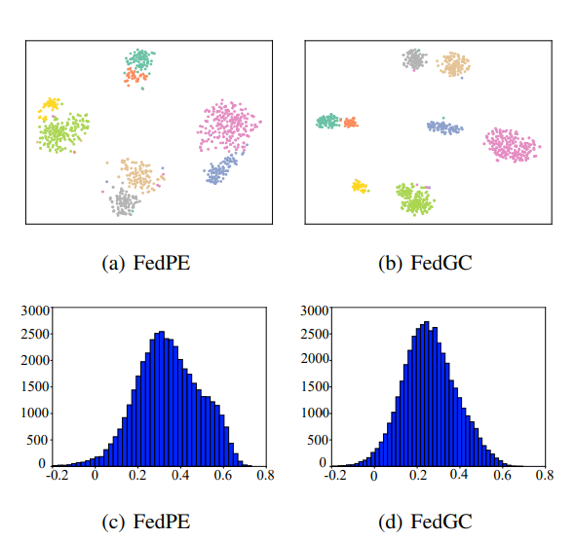
作者还使用了t-SNE作可视化,用来衡量原本在FedPE中相似的不同ID的特征向量,在加入梯度修正后的表现。可以看出,经过梯度修正,类间相似度得到了显著的改善。

 京公网安备11010802017125号
京公网安备11010802017125号