
2022年论文导读第二十四期
【论文导读】2022年论文导读第二十四期
CCF多媒体专委会 2022-11-29 09:00 发表于北京


论文导读
2022年论文导读第二十四期(总第六十四期)
目 录
|
1 |
Diaformer: Automatic Diagnosis via Symptoms Sequence Generation |
|
2 |
DarkVisionNet:Low-Light Imaging via RGB-NIR Fusion with Deep Inconsisitency Prior |
|
3 |
SpikeConverter: An Efficient Conversion Framework Zipping the Gap between Artificial Neural Networks and Spiking Neural Networks |
|
4 |
Towards Fully Sparse Training: Information Restoration with Spatial Similarity |
|
5 |
Learning Robust Policy against Disturbance in Transition Dynamics via State-Conservative Policy Optimization |
|
6 |
Resistance Training using Prior Bias: toward Unbiased Scene Graph Generation |
01
Diaformer: Automatic Diagnosis via Symptoms Sequence Generation
作者:陈俊颖1,†,李东方1,†,陈清财1,2,*,周文秀1,刘欣2
单位:1哈尔滨工业大学(深圳),2鹏城实验室
邮箱:
junying.chen.cs@gmail.com
crazyofapple@gmail.com
qingcai.chen@hit.edu.cn
wen.xiu.zhou@outlook.com
hit.liuxin@gmail.com
论文:
https://ojs.aaai.org/index.php/AAAI/article/view/20365
代码:
https://github.com/jymChen/Diaformer
†共同一作,*通讯作者
研究背景

图1 自动诊断数据样例
自动诊断是智能医学应用领域的一个重要方向,其多阶段的症状选择询问和疾病诊断推理的难题依旧是目前的巨大挑战。自动诊断数据样例如图1所示,其主要包括显式症状集Sexp、隐式症状集Simp和目标疾病Dis。,诊断系统需要在仅有用户的显式症状情况下,在有限轮次中问出隐式症状,并最终做出疾病诊断。当前的工作大多使用强化学习方法并将自动诊断视为一个决策优化问题,然而却偏离了医生的问诊逻辑,且存在学习效率低及回馈函数难以确定等问题;在该工作中,我们将自动诊断形式化为序列生成任务,并提出了基于序列生成的自动诊断模型Diaformer。
方法介绍
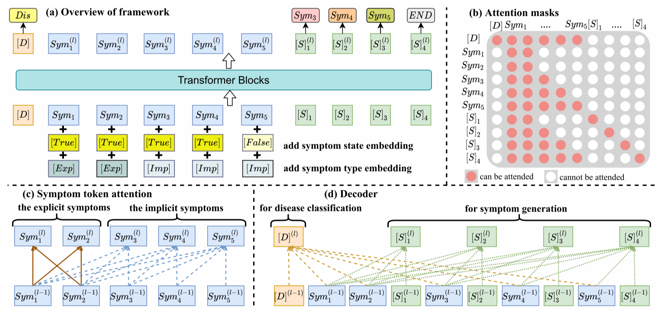
图2 Diaformer模型架构
Diaformer模型结构如图2所示,模型将用户的症状作为输入,训练生成隐性症状序列及疾病诊断。每个症状作为单一的token表示加上两种类型编码,类型编码用标识症状的阴性或阳性以及症状是显性或隐性。图2右侧是注意力掩码,通过控制Transformer中的自注意力实现症状序列生成的自回归学习,在解码器中使用两个特殊符号学习症状预测及疾病推理。
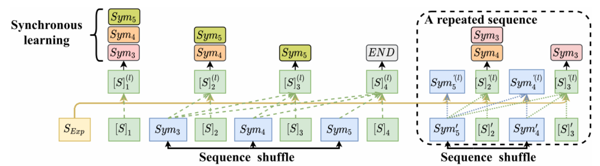
图3 三种无序生成机制
Diaformer基于序列生成方式有次序的学习症状推理,然而在现实生活中患者的隐性症状没有次序关系,所以这导致了序列生成的有序性与隐性症状推理无序性的偏差。对此,提出了三个无序的训练机制,让模型不依赖于特定的症状次序推理。无序的训练机制如图3所示,它们分别为序列打乱、同步学习和重复子序列。
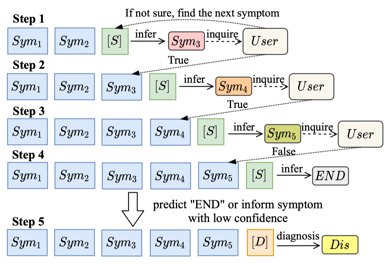
图4 Diaformer生成式自动诊断流程
图4展示了Diaformer的诊断流程,自动诊断中将基于生成症状获取用户回归继续生成的迭代方式,并基于推理的置信度以及生成决策来执行疾病诊断。
实验结果
表1 模型对比结果

实验对比结果如表1所示,Diaformer在三个公开自动诊断数据集上取得了SOTA结果,尤其是在较大规模数据集Synthetic dataset上疾病诊断准确率达到71%(+11%)。此外还设置两个生成诊断baselines,结果上看序列生成模型的表现要都高于强化学习方法,且所需的训练时间明显更少。同时设置了轮次实验,在限定更少询问轮次的情况下,Diaformer也能在三个数据集中达到最好的疾病诊断结果。
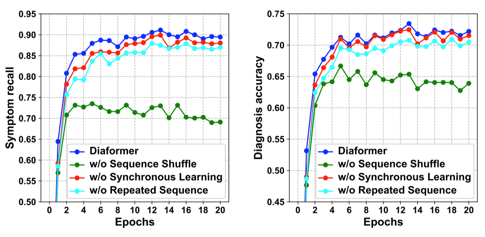
图5 消融实验
采用相同参数的初始化,对比每个的训练轮数下的结果如图5所示,可见无论是症状的召回率或者是疾病预测的准确率上,三个无序训练机制都能有助于提升Diaformer。
02
DarkVisionNet:Low-Light Imaging via RGB-NIR Fusion with Deep Inconsisitency Prior
作者:于冰冰,金双平,井敏皓,周熤,梁嘉骏,戢仁和
单位:北京旷视科技有限公司
邮箱:
jirenhe@megvii.com
论文:
https://ojs.aaai.org/index.php/AAAI/article/view/19995
摘要
RGB-NIR融合技术可用在极暗环境下增强可见光成像效果。然而现存的融合算法无法处理RGB-NIR图像之间的结构不一致问题,从而难以生成高质量的融合结果。本文中,我们对这个难题进行分析,并提出Dark Vision Net (DVN)来处理结构不一致问题,通过巧妙的网络设计,DVN将传统算法的核心思想融合进CNN框架之中,从而取得了很好的效果。
1. 导论
对于近红外(Near Infrared,NIR)图像来说, 在人眼不可感知的NIR补光灯的帮助下,即使在极端暗光的情况,依然能够保持较高的信噪比。
RGB-NIR融合技术,正是通过高信噪比的NIR图像来大幅提升RGB图像信噪比的技术,其能够在使用低成本模组的前提下,取得高成本暗光成像模组才能清晰成像。也正是因此,RGB-NIR融合技术对很多暗光下的应用有重要意义。
然而,目前的市面上还很少出现利用RGB-NIR融合来改善暗光下成像质量的产品。究其原因,我们通过调研发现,目前RGB-NIR技术在实际使用中存在的最大技术难题就是极暗光下的RGB图像与NIR图像之间的结构不一致问题。在RGB图像强噪声的影响下,目前的融合算法所生成的融合结果中往往存在非常明显的非自然错误纹理(Artifact),这反而降低了图像质量并严重影响下游任务的效果。

图1 结构不一致问题如何影响融合算法
图1中红框标记出现来的区域就是两种常见的RGB-NIR结构不一致区域:上方红框展示的是由于油墨涂料本身的物理特性,在RGB图像中十分明显的"CODE COMPLETE"在NIR图像中却几乎完全消失。下方红框展示的是由于NIR补光灯的影响,NIR图像中往往出现了一些RGB图中不存在的"伪影"。从现存融合方法的结果可以看出,现存方法无法处理这种结构不一致问题,会产生明显的非自然错误纹理。下面,我们将现存的融合方法分成两类,分别分析它们无法处理结构不一致问题的原因:
(1)以ScaleMap为代表的传统融合算法处理噪声干扰的能力有限,因此无用适用于极端暗光环境。对于ScaleMap算法来说,十分依赖从原图中提取图像的结构信息(梯度)。再根据专家先验知识来建模RGB-NIR图像的结构差异,从而指出哪些区域存在明显的结构不一致性,哪些区域则相反。然而,在极暗光环境下的强噪声使得直接从原图中提取清晰的梯度图变得十分困难。这就使专家先验知识无法能正确的反映出RGB-NIR图像之间的梯度不一致性,自然导致传统算法无法输出高质量的融合结果。
(2)以CUNet,DKN为代表的基于CNN的融合算法也依然无法解决结构不一致问题。虽然凭借CNN强大表示能力,这类融合算法对于噪声相对不敏感。但是,缺乏了专家先验知识的引导,单纯基于数据驱动的训练方式很难使得CNN学习到RGB-NIR图像之间结构不一致性,使得最终的融合结果在结构不一致的区域会产生明显的非自然错误纹理,非常影响图像的质量。
2. 算法原理
综上所述,既然单独使用专家先验知识和CNN都不能处理结构不一致问题,那么为什么不能把它们结合起来使用呢?我们从这个思路出发,我们提出了一个全新的专家先验知识,并设计了一个巧妙的网络结构将这个先验知识引入到RGB-NIR深度特征的融合过程中,从而兼顾了传统算法和CNN类方法的优点,很好地解决了RGB-NIR图像之间的梯度不一致问题。
2.1 深度结构
要引入专家先验知识,首先需要解决的技术难题就是如何从低信噪比的图像中提取出清晰的结构信息。我们通过实验发现,类似于U-Net的网络在降噪过程中学习到的深度特征本身就包含有丰富的结构信息,我们将这些包含了结构信息的深度特征简称为成为深度结构(Deep Structure)。

图2 深度结构和深度不一致
从图2中可以看出,深度结构中不仅包含了丰富的结构信息,还对噪声的干扰十分鲁棒。也正是如此,我们就可以在低信噪比的图片上提取它的深度结构,并在其上引入专家先验知识,对RGB-NIR图像之间的结构不一致性进行建模。
2.2 深度不一致先验
在深度结构的基础上,我们提出了一个简单却有效的先验知识——深度不一致性先验(Deep Inconsistency Prior, 简称为DIP),来建模RGB-NIR在结构之间不一致性:
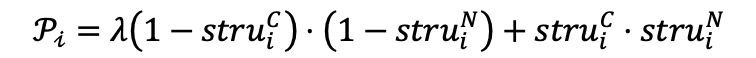
式中, struiC和struiN分别代表着从RGB图和NIR图中提取得到的深度结构的第个通道,其每个像素点的取值范围为(0,1) 代表着该像素位置是否存在明显的边缘;Pi则代表着计算得到的深度不一致图,其长和宽的尺寸与struiC, struiN相同, 每个像素点的取值范围同样为(0,1)。
如图2所示, 在struiC与struiN值差异很大的区域(极端情况下struiC=1,struiN=0或者struiC=0,struiN=1), Pi的值会接近于0, 表明这些区域存在明显的RGB-NIR结构不一致现象,在后续的融合过程中,不应该从NIR图像中提取信息来增强RGB图像;
而在struiC与struiN的值都接近1的情况下,Pi的值同样接近1,表明这些区域RGB-NIR之间的结构基本一致,后续的融合过程中可以更多的从NIR图像搬运细节信息来增强RGB图像;
剩下的struiC与struiN的值都接近0的情况下,Pi的值为一个超参数λ,这意味着这些区域RGB-NIR之间的结构是否一致是不确定的,后续的融合过程中应该有限度地依赖NIR图像。超参数λ的值一般被设置为0.5。
3. 技术实现
基于上述的两大技术创新点深度结构和深度不一致先验,我们提出了一个新的RGB-NIR融合算法Dark Vision Network (DVN)。DVN有效地解决了结构不一致性问题,并取得了目前最好的融合效果。

图 3 Dark Vision Network 的流程框图。DSEM 指的是深度结构提取模块 (Deep Structure Extraction Module, DSEM)
如图3所示,DVN的流程可以分为两个阶段:
(1)提取深度结构;
(2)深度不一致先验(DIP)引导下的多尺度RGB-NIR特征融合。
3.1 提取深度结构
因为从RGB图像中提取深度结构的过程与从NIR图像中提取的过程基本一致,我们在下文的描述中不作区分来做统一的表述。
为了从输入图像中提取出深度结构,我们设计了一个深度结构提取模块(Deep Structure Extraction Module,DSEM),其详细网络结构如图4(a)所示。

图4 重要模块的结构细节
DSEM首先接受复原子网络输出的多尺度特征feati(i代表尺度),通过监督学习的方式输出多尺度的深度结构structi。其训练所使用的损失函数如下所示:
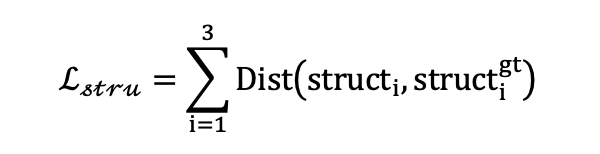
式中,structigt是我们为尺度的深度结构的所提供的监督信息。我们用一个预训练好的自编码器(AutoEncoder)来获取structigt , 其详情可见图4(b)。Dist则代表Dice损失。
此外,我们发现在进行特征融合之前对输入RGB图像进行降噪可以有效的特征融合效果。同时,为了获取高质量的深度结构structrgb,RGB图像的复原子网络Rrgb也需要具备初步的降噪能力。因此,DVN中使用Rrgb的输出Coarse-RGB图来代替Noisy-RGB图像输入到接下来特征融合模块。
3.2 DIP引导下的多尺度特征融合
在计算出深度不一致先验知识Pi之后,我们使用深度不一致性先验P来引导RGB-NIR的特征融合过程,从而处理结构不一致问题。具体来说,我们首先将Pi直接作用在NIR的深度结构struiN上,生成一致性NIR深度结构\widehat{struiN}:
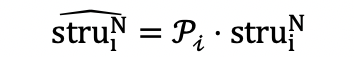
在"特征筛选"的作用下, \widehat{struiN}与struiN相比丢弃了结构不一致区域的结构信息。
在获取了\widehat{struiN}之后, 一个多尺度的RGB-NIR特征融合模块将\widehat{struiN}中的丰富细节信息融合到RGB特征中,具体详情可见图4(c)所示。
4. 实验与讨论

图5 对比结果
图5 展示了DVN的结果与其他对比方法之间的对比。其中ScaleMap是最具有代表性的传统RGB-NIR融合算法,DKN、CUNet则是基于深度学习的融合算法,MPRNet是单RGB降噪算法。可以很明显的看出,相比其他所有的对比算法,DVN在不仅有效地对噪声进行了抑制,也良好地恢复了RGB图像中的细节细节。同时,DVN的融合结果中也并不包含由于RGB-NIR之间结构不一致问题所导致的非自然错误纹理。
03
SpikeConverter: An Efficient Conversion Framework Zipping the Gap between Artificial Neural Networks and Spiking Neural Networks
作者:刘方鑫1,2,赵文博1,2,陈勇彪1,汪宗武1,蒋力1,2
单位:1上海交通大学,2上海期智研究院
邮箱:
liufangxin@sjtu.edu.cn
ljiang_cs@sjtu.edu.cn
论文:
https://www.aaai.org/AAAI22Papers/AAAI-364.LiuF.pdf
详细介绍:
https://mp.weixin.qq.com/s/OZ-dsdwqGqUJWUqQretclQ
背景介绍
脉冲神经网络(Spiking Neural Network, SNN)被誉为第三代的神经网络,以其丰富的时空领域的神经动力学特性、多样的编码机制、事件驱动的优势引起了学者的关注。现有的脉冲神经网络分为两类:直接训练的SNN和基于人工神经网络转换的SNN。
基于转换的SNN:基于ANN训练的权值,直接使用神经元函数替换ANN中的ReLU函数,再通过特定手段将其转换为SNN。其具有以下特点:
1. 基于转换的SNN的训练依赖于传统ANN中执行的反向传播算法,因此它避免了直接训练的SNN所面临的梯度消失、脉冲信号消失的问题。
2. 预测准确度高
3. 快速地将ANN领域的最新研究成果转换和应用到SNN领域,并继承SNN的低功耗优势
同时也存在挑战:基于转换的SNN通常需要数百上千的时间步数来表示脉冲序列中编码的信息,以完成一次推理。在当前主流时钟驱动的同步执行机制下,SNN的所有神经元需要在每个时间步上进行迭代计算,这抵消了SNNs低能效和低时延的优势。

方法介绍
本文提出一种基于高效且准确的ANN-SNN转换框架,不仅可以应用到传统神经网络的最新发展,而且大幅度降低了时间步的数量。
转换中的一致性关系
首先,我们在神经元发射脉冲之后采用了软重置的策略,其公式表达为

其中V[t]是t时刻的膜电压,k是每个时间步之间的膜电压衰减系数。Xi是第i个相邻神经元的脉冲序列,0表示t时没有脉冲传输。Y是当前神经元的输出脉冲序列。将公式(1)在t=1到T累加,得到
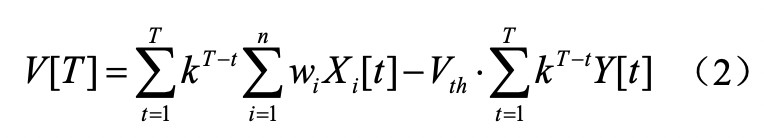
在理想情况下,最后神经元内没有膜电压存留,即V[T]=0。此时,公式(2)可以简化为

不难发现,公式(3)与传统神经网络的MAC计算模式
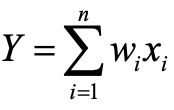
神经元计算中的时域分离
文章采用时域分离的方法,将膜电压的累积过程和膜电压释放脉冲的过程在时域上分离开,避免膜电压累积信息丢失的情况出现。文章提出了与传统LIF相反的模型,iLIF,在每个时间步结束后增幅而不是减少模电压。

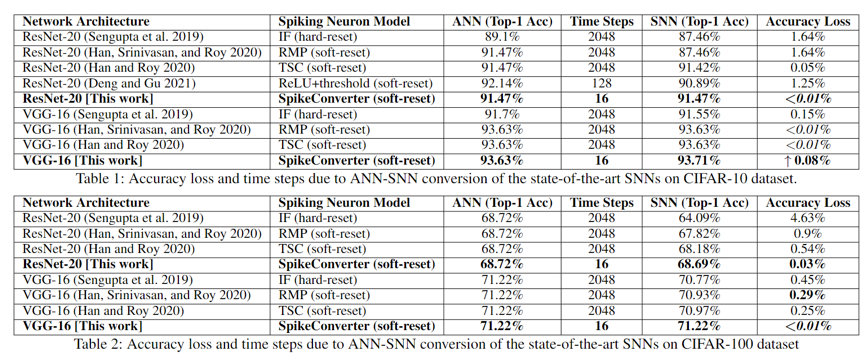
实验结果
文章使用CIFAR-10/100和ImageNet数据集进行实验,SpikeConverter在仅需要16个时间步的情况下,可以达到和传统神经网络几乎一致的精度,极大节省空间存储和计算代价。部分结果如下。
未来方向
脉冲神经网络还有较大的挖掘空间,还有许多领域SNN未能成功应用,可以在视频识别、机器人控制等方面继续研究。
04
Towards Fully Sparse Training: Information Restoration with Spatial Similarity
作者:许伟翔,贺翔宇,程科,王培松,程健
单位:中国科学院自动化研究所
邮箱:
xuweixiang2018@ia.ac.cn
chengke2017@ia.ac.cn
xiangyu.he@nlpr.ia.ac.cn
peisong.wang@nlpr.ia.ac.cn
jcheng@nlpr.ia.ac.cn
论文:
https://ojs.aaai.org/index.php/AAAI/article/view/20198
NVIDIA Ampere架构发布的2:4结构化稀疏要求连续四个元素当中至少有两个为零,从而能够使得矩阵乘法的吞吐量翻倍。近期的研究工作主要集中在利用2:4稀疏特性进行推理加速,而忽略了它在训练加速场景下的应用。训练场景下,反向传播消耗了大约70%的时间。但与推理不同,训练加速场景由于需要保持正确的梯度更新方向、并减少引入2:4稀疏性所带来的额外开销,使得使用结构化剪枝变得比较困难。本工作提出完全稀疏训练框架,其中“完全”表示前向和后向传播中的所有矩阵乘法都进行了结构化稀疏,如图1(b)所示。为此,我们从稀疏的显著性分析开始,研究不同稀疏对象对结构化剪枝的敏感度。基于对中间层特征在im2col域当中具有空间相似性的观察,我们提出使用固定位置的2:4掩码来对输入特征进行剪枝。此外,我们提出了一种信息恢复模块来恢复在稀疏过程中所丢失的信息,该模块可以通过高效的梯度移位操作来实现。

图1(a)常规训练和(b)完全稀疏训练的计算图
在训练过程中,神经网络每层有三个矩阵乘法:正向传播Y=WX、激活梯度反向传播

和权重梯度计算
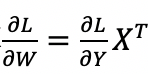
通过分析三个矩阵乘法对结构化稀疏的敏感度,我们发现如果对激活梯度稀疏,它的误差会随着梯度反传呈指数级逐层累积,因此最终稀疏的对象分别是W,WT和XT。我们分别采用SR-STE和独立优化的方式对W和WT进行稀疏。对激活XT稀疏的困难主要在于它的维度太大,采用排序的方式引入稀疏会带来较大的额外计算代价,与我们训练加速的初衷相违背。对此,我们的方法是基于对激活值在im2col域中具有空间相似性的观察,如图2所示。具体地说,原始的三维激活特征经过im2col变换后,相邻列之间的特征值接近,这是im2col变换本身特殊的排布方式导致的。利用这一特性,我们提出固定位置的剪枝:将所有偶数列置为0,保留奇数列,使得激活满足2:4稀疏的要求。同时为了恢复稀疏激活所造成的信息丢失,我们进一步利用上述空间相似性,用奇数列来近似偶数列

,其中T是由一系列初等矩阵的乘积得到的变换矩阵。经过矩阵变换,T相当于对激活梯度做了矩阵右乘。在底层实现时,并不需要知道变换矩阵T的具体形式,只需要知道它的物理含义等价于对激活梯度做列上的平移。最终是通过硬件友好的移位操作来实现的。
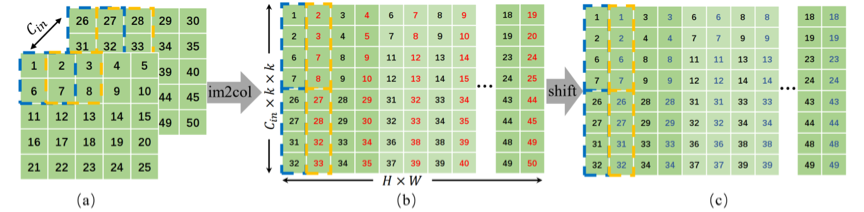
图2(a)三维激活特征(b)im2col域中的空间相似性(c)固定位置剪枝并利用空间相似性恢复丢失信息
我们对所提出的方法做了速度和精度两方面的评估,总体上本方案能够以微小的精度代价在NVIDIA Ampere架构上获得两倍吞吐量的训练加速。
表1 精度评估实验结果
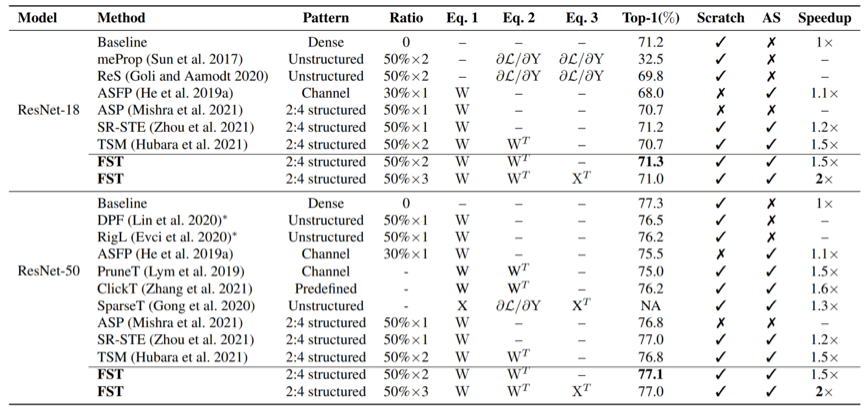
05
Learning Robust Policy against Disturbance in Transition Dynamics via State-Conservative Policy Optimization
作者:匡宇飞1,陆淼1,王杰1,2 #,周祺1,李斌1,李厚强1,2
单位:1中国科学技术大学,2合肥综合性国家科学中心人工智能研究院
邮箱:
yfkuang@mail.ustc.edu.cn
lumiao@mail.ustc.edu.cn
zhouqida@mail.ustc.edu.cn
jiewangx@ustc.edu.cn
binli@ustc.edu.cn
lihq@ustc.edu.cn
论文:
https://ojs.aaai.org/index.php/AAAI/article/view/20686
代码:
https://github.com/MIRALab-USTC/RL-SCPO
详细介绍:
https://mp.weixin.qq.com/s/bl2tgeI_6DwdPIycvrPfEg
#通讯作者
深度强化学习算法在源环境和目标环境出现差异时往往会遭受明显的性能下降。现有的鲁棒强化学习方法通常通过将目标环境的扰动提前建模并添加至源环境中来增强策略迁 移时的鲁棒性。然而在很多真实应用的场景下,我们可能会缺乏关于目标环境中扰动的先验知识,或者目标环境中的扰动形式难以直接建模到训练环境。为了解决该问题,我 们提出了一种新的基于状态扰动的鲁棒强化学习方法 (State-Conservative Policy Optimization, SCPO) ,将难以提前建模的真实环境扰动转换为状态扰动并通过正则项近似后 引入训练过程,以实现在使用较少先验知识的情况下增强策略迁移时的鲁棒性。具体地,我们定义了一个新的目标函数,以显式地考虑在马尔可夫决策过程中来自每一时刻状 态扰动的累积对智能体最终能得到的累积奖励的影响。即:

我们将该优化目标称作保守状态优化目标 (state-conservative objective),并将基于该优化目标的马尔可夫决策过程称作保守状态马尔可夫决策过程 (state-conservative Markov decision process, SC-MDP)。当我们只考虑确定性环境状态转移函数p,且不确定性集为在 Wasserstein 度量下有界的集合时,SC-MDP 和 RMDP 是等价的(在一般条件下,该等价性未必成立)。注意到相较于RMDP的优化目标,SC-MDP通过对状态 的邻域取极小值而不是对状态转移函数构成的不确定集 取极小值,使得该优化问题形式上简化为一个有限维约束优化问题。
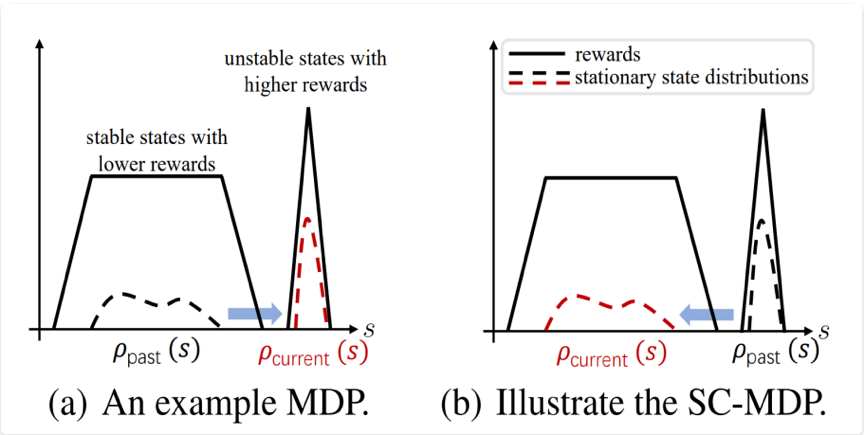
图1 使用一个简单的示例来解释SC-MDP。考虑一个状态空间维度为1的MDP,并假设其奖励只取决于状态 s。一般的MDP的目标函数鼓励状态的稳态分布 $\rho(s)$ 集中 在高奖励区域(图1.a),然而SC-MDP的目标函数鼓励状态的稳态分布 $\rho(s)$ 集中在受到状态扰动后更稳定的区域(图1.b)。
基于SC-MDP可以递归地定义相应的状态-动作价值函数(Q函数),即:
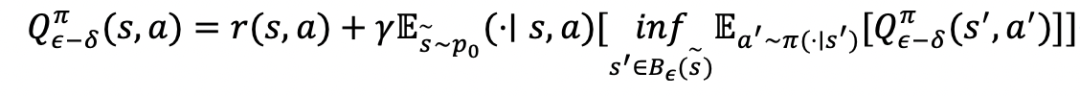
并证明基于该函数的保守状态策略迭代算法在我们新定义的保守状态马尔可夫决策过程中仍然是可以收敛的。我们进一步将上述保守状态策略迭代算法拓展到连续动作空间, 该算法分为保守状态策略评价和保守状态策略提升两个部分。注意到此时我们需要求解如下的约束优化问题:
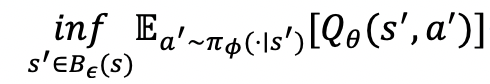
实验发现状态s的小邻域内Q 函数具有良好的线性性质(图2),因此,我们采用Q函数的一阶泰勒展开来作为该约束优化问题的近似解,得到基于保守状态策略优化的软 执行者-评论家算法(SC-SAC)算法(算法1)。
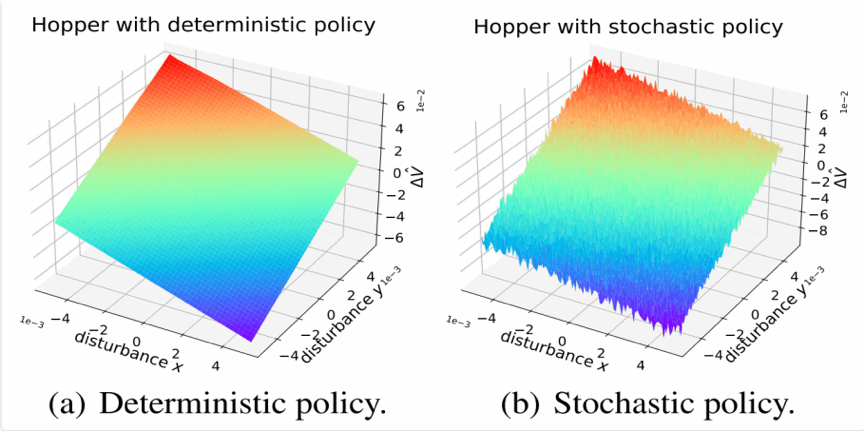
图2:Q函数的局部线性性质(Q函数使用SAC算法进行训练)。其中图2.a我们只使用SAC算法训练得到的策略输出的高斯分布均值;图2.b使用SAC算法训练得到的高斯分布的随机策略。

算法1:基于保守状态策略优化的软执行者-评论家算法(SC-SAC)。
将上述 SC-SAC 算法应用在 MuJoCo 仿真机器人控制环境上进行测试。结果显示我们提出的SC-SAC的算法在多个测试环境有更好的鲁棒性,且相比于 baseline 算法的得分 分布在高价值区域更为集中。
图3 对比 SAC、PR-SAC、SC-SAC 算法迁移到有扰动的测试环境时的鲁棒性。
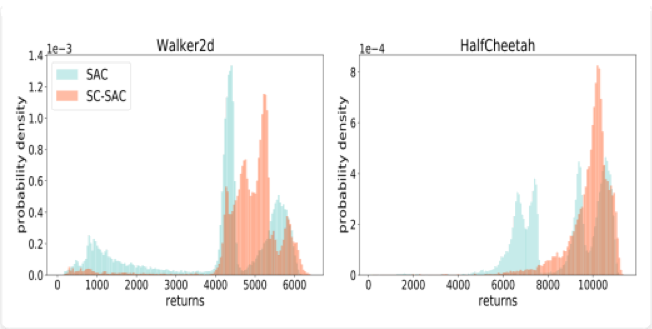
图4 对比 SC-SAC 与 SAC 算法迁移到测试环境的得分分布。
06
Resistance Training using Prior Bias: toward Unbiased Scene Graph Generation
作者:陈超 1,2, 詹忆冰 2, 于宝盛3, 刘柳3, 罗勇1 †, 杜博1 †
单位:1 武汉大学; 2 京东探索研究院; 3悉尼大学;
邮箱:
chenchao@whu.edu.cn,
luoyong@whu.edu.cn
dubo@whu.edu.cn
zhanyibing@jd.com
baosheng.yu@sydney.edu.au
liu.liu1@sydney.edu.au
论文:
https://ojs.aaai.org/index.php/AAAI/article/view/19896
代码:
https://github.com/ChCh1999/RTPB
†:通讯作者
场景图生成旨在基于图像内容生成描述图像中物体关系的结构化数据,构建低维图像信息与高维语义描述之间的桥梁。图1(b)是从图片1(a)构建的场景图,场景图中使用节点表示图像中的物体,使用节点之间的边描述物体之间的关系。场景图是对图像信息的有效抽象,这种结构化的数据能够有效降低计算机理解图像内容的难度,因此,高质量的场景图能够为视频问答(VQA)、图像描述(Image Captioning)、图像检索(Image Retrieval)等下游任务提供有力的支持。然而,现阶段场景图生成受数据集的长尾分布影响严重。如图1(c)所示,在现有的数据集中,少部分常见的关系、笼统的关系描述(如on, has, of)占据了绝大部分的标注数据,而其他的大量关系的标注率较低,关系的样本数量呈现严重的长尾分布。数据集的这种长尾分布导致训练得到的场景图生成模型存在严重偏见,难以生成均衡、可靠的场景图。

图1(a)图像以及其中的物体标注;(b)图(a)对应的场景图;(c)VG数据集中关系的长尾分布。

图2 方法总体架构。我们采用Faster RCNN作为目标检测器。使用Dual-Transformer网络编码物体特征以及物体间关系特征。RTPB在训练阶段通过调整关系分类结果以解决长尾分布问题。
为了解决这一问题,我们从两方面展开我们的工作。方法总体架构如图2所示。一方面,我们设计了一个Dual-Transformer网络来对场景中的物体和关系进行编码,通过将物体和物体间关系两个层次的特征编码分离开来,使用不同的网络对不同层次的特征进行编码,以充分挖掘图像内部的信息。另一方面,为了针对性地解决现有数据集中存在地长尾分布问题,我们设计了基于数据集先验信息的阻力训练方法。阻力训练方法与人类阻力训练的原理类似。在肌肉锻炼中,负重更大的肌肉在训练结束后会更强大。相应地,在模型训练中,我们通过给模型的分类结果添加阻力偏差来给模型分配“负重”,实现了对模型处理尾部类别的能力的增强,从而降低长尾分布对模型的影响。阻力偏差的一种基本形式为:

其中w为从训练集初始化的类别权重。然后如图3所示,阻力偏差通过影响模型输出的未归一化的分类结果介入到模型训练中。训练完成后,在模型测试阶段,我们移除阻力偏差。实验结果显示模型处理尾部类别的能力明显提升。
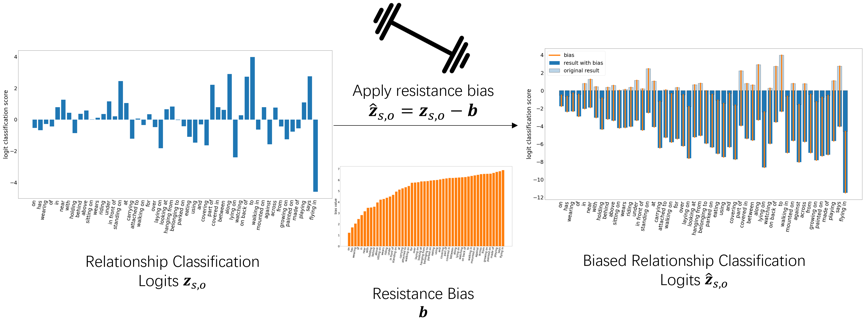
图3 阻力训练方法
表1 RTPB和现有场景图生成方法在VG数据集上的结果对比。
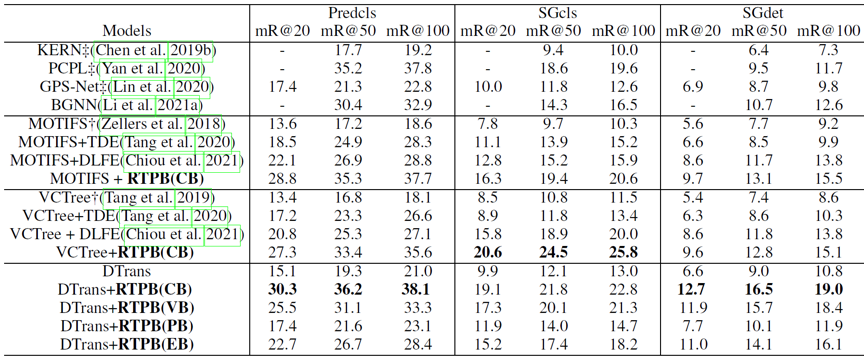
表1展示了不同方法在VG数据集上的平均召回率(mean recall)结果。我们的阻力训练方法在三个场景图生成子任务上都能显著提升已往模型的性能,并且提升明显大于现有的无偏场景图生成方法,如TDE(发表于CVPR 2020),DLFE(发表于ACMMM 2021)。

 京公网安备11010802017125号
京公网安备11010802017125号