
2022年论文导读第二十五期
【论文导读】2022年论文导读第二十五期
CCF多媒体专委会 2022-12-13 12:50 发表于吉林


论文导读
2022年论文导读第二十五期(总第六十五期)
目 录
|
1 |
Attacking Video Recognition Models with Bullet-Screen Comments |
|
2 |
Low-light Image Restoration with Short- and Long-exposure Raw Pairs |
|
3 |
Coarse-to-Fine Embedded PatchMatch and Multi-Scale Dynamic Aggregation for Reference-based Super-Resolution |
|
4 |
Image Co-Saliency Detection and Instance Co-Segmentation Using Attention Graph Clustering Based Graph Convolutional Network |
|
5 |
Emotion Expression with Fact Transfer for Video Description |
|
6 |
IDHashGAN: Deep Hashing With Generative Adversarial Nets for Incomplete Data Retrieval |
01
Attacking Video Recognition Models with Bullet-Screen Comments
基于强化学习的视频弹幕攻击
作者:陈凯1,魏志鹏1,陈静静1#,吴祖煊1,姜育刚1#
单位:1复旦大学
邮箱:
kaichen20@fudan.edu.cn
zpwei21@m.fudan.edu.cn
chenjingjing@fudan.edu.cn
zxwu@fudan.edu.cn
ygj@fudan.edu.cn
论文:
https://ojs.aaai.org/index.php/AAAI/article/view/19907
代码:
https://github.com/kay-ck/BSC-attack
#通讯作者
深度神经网络已经在各种与视频相关的任务中表现出卓越的性能,例如视频识别、视频字幕和视频分割等。然而,最近的工作表明,深度神经网络极易受到视频对抗样本的影响。现有的视频对抗样本大多是通过基于扰动的攻击生成的,虽然它们能够有效地攻击视频识别模型,但它们通常难以应用于物理世界。相比之下,基于补丁的攻击在物理世界中更强大、有效。但是,现有的基于补丁的攻击主要集中在图像上,大家很少探索对视频的基于补丁的攻击。为了解决上述问题,我们提出了一种针对视频识别模型的新型对抗弹幕攻击方法。由于弹幕在人们在线观看视频时比较常见,因此与基于补丁的图像攻击中所使用的矩形补丁相比,人们对弹幕这种有意义的补丁更不敏感。图1展示了对抗弹幕攻击的示例。可以看出,少量的弹幕并没有影响对于视频的理解,而是成功地欺骗了视频识别模型。
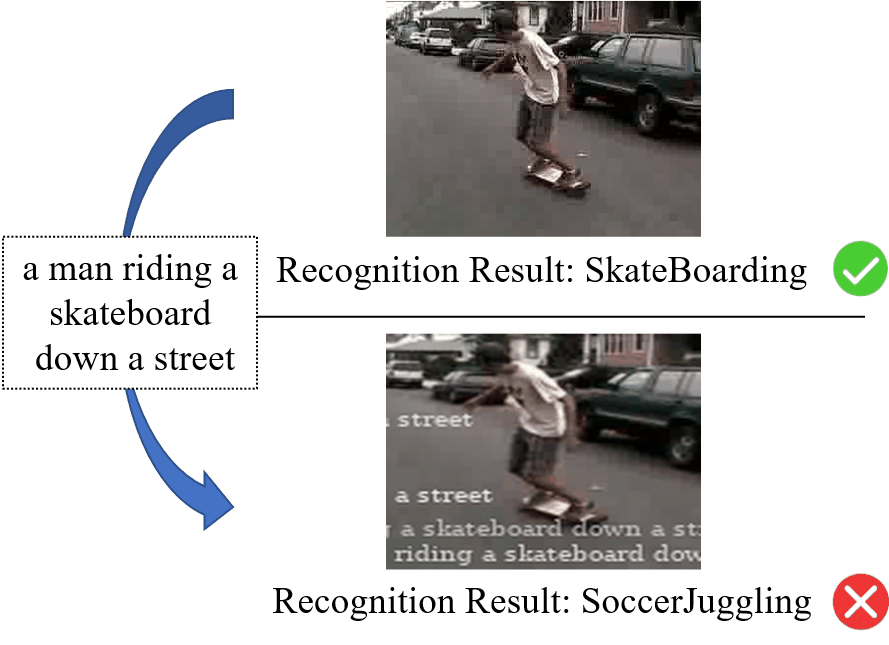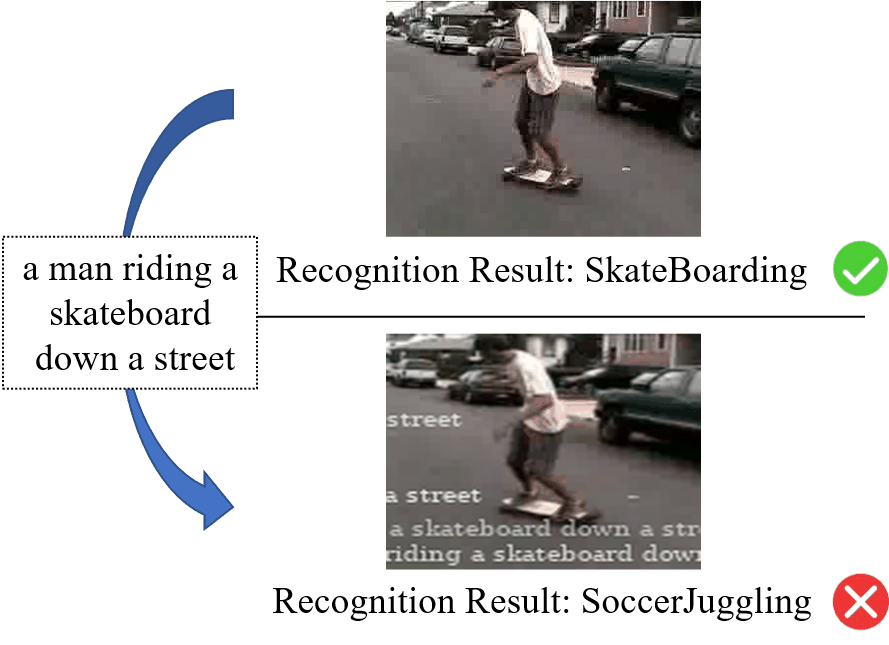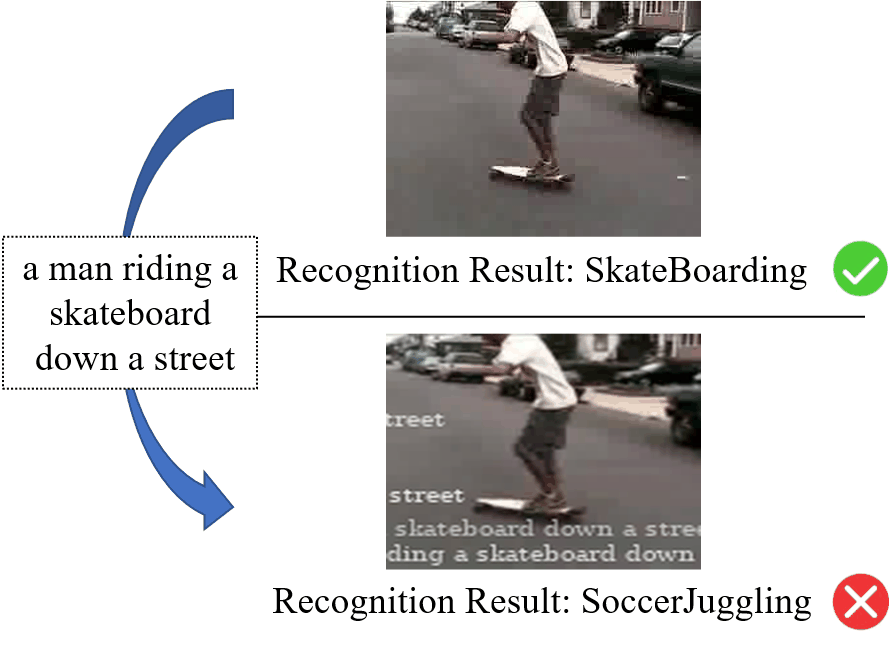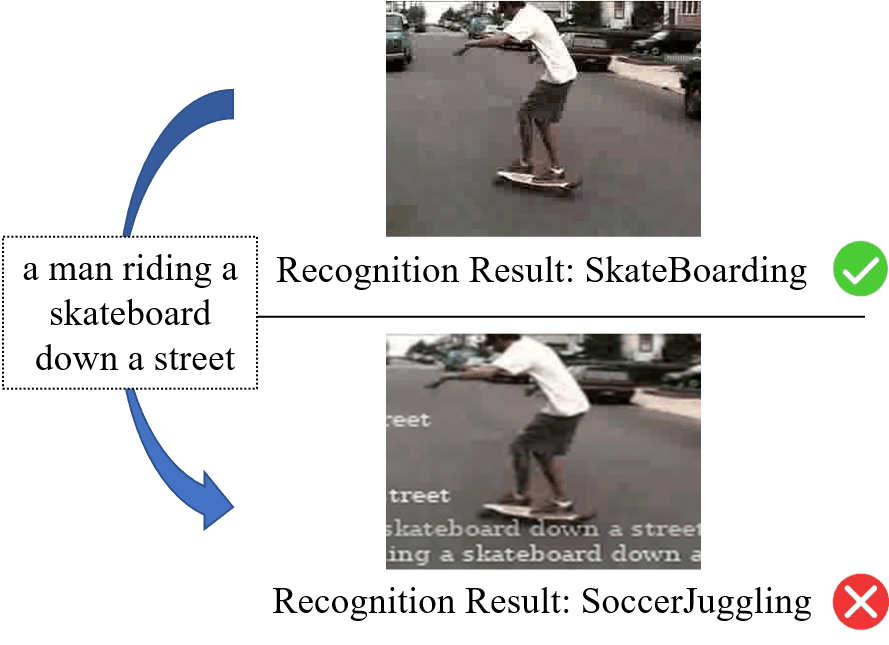
图1 对抗弹幕攻击的示意图
为了使添加到每个视频的弹幕彼此不同,对抗弹幕攻击使用一个图像字幕(image caption)模型来自动生成弹幕内容。然后基于两个目标选择对抗弹幕的位置和透明度。首先,将选定透明度的弹幕放置在选定位置上应该实现较高的欺骗率。其次,弹幕之间不应相互重叠,以避免明显模糊视频的细节。为了实现这两个目标,对抗弹幕攻击使用强化学习来搜索弹幕的位置和透明度。具体来说,在强化学习中,环境(environment)被定义为目标模型,代理(agent)充当选择弹幕的位置和透明度的角色。通过不断查询目标模型并接收反馈,代理逐渐调整其选择策略,以实现上述的两个目标。图2概述了提出的攻击框架。
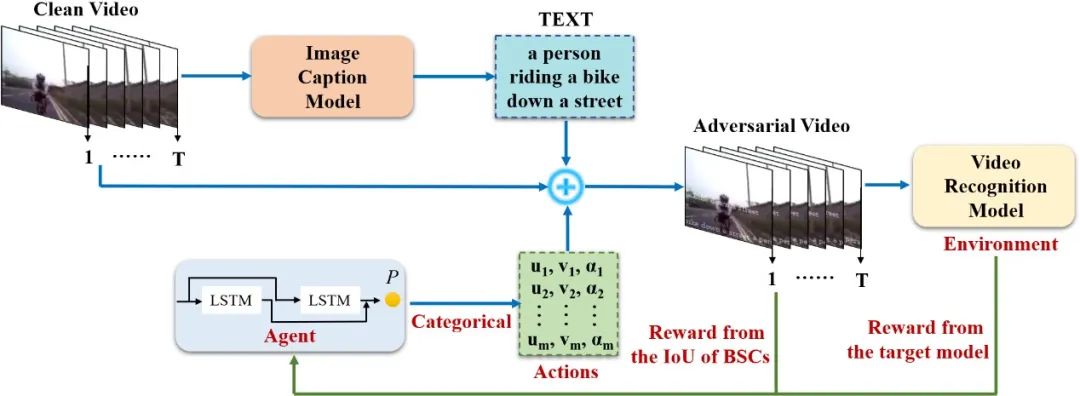
图2 对抗弹幕攻击方法的概述
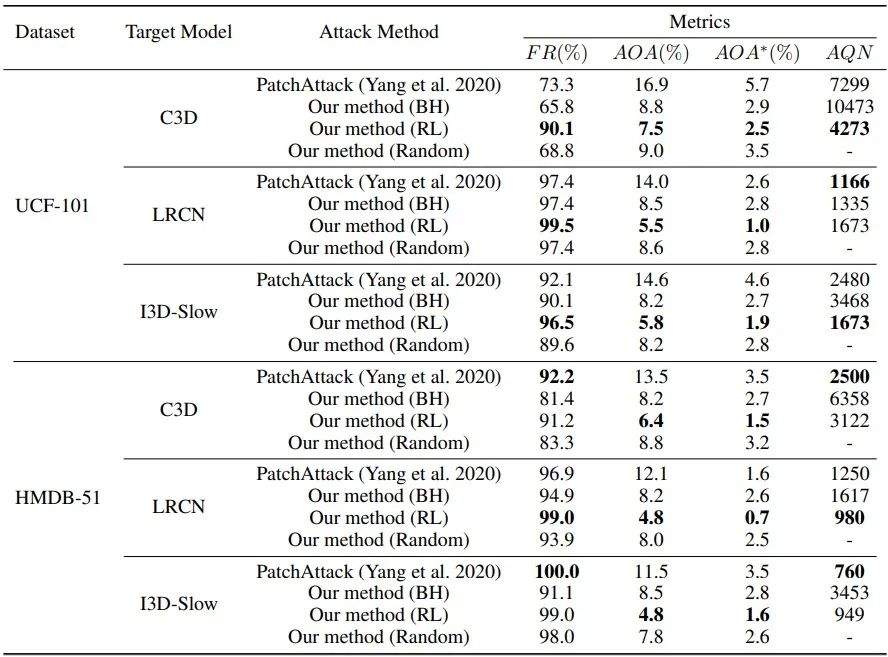
我们选择UCF-101和HMDB51两个数据集,C3D、LRCN和I3D-Slow三种不同结构的视频识别模型来进行实验。除此之外,我们还使用了三个评价指标,1)欺骗率(Fooling rate, FR):视频对抗样本被成功误分类的比率;2)平均遮挡面积(Average occluded area, AOA):视频中被弹幕遮挡的平均面积百分比,AOA∗表示视频中的显著区域被弹幕遮挡的平均面积百分比;3)平均查询次数(Average query number, AQN):攻击过程中,查询目标模型的平均次数。我们将对抗弹幕攻击与1)使用相同大小的矩形补丁的PatchAttack、2)使用盆地跳跃(Basin Hopping, BH)算法搜索弹幕位置和透明度的策略、3)随机选择弹幕位置和透明度的策略进行比较。从表1可以看出,在大多数情况下,对抗弹幕攻击取得了更好的性能:与PatchAttack相比,对抗弹幕攻击的AOA和AOA∗显著减少了,我们认为这是因为弹幕比矩形补丁更加分散;与BH相比,使用强化学习搜索弹幕的位置和透明度更加高效;在相同的AQN下,使用强化学习比随机选择取得了更好的性能。
表1 不同攻击方法在两个数据集上针对不同视频识别模型的性能对比
通过Grad-CAM可以看出,弹幕改变了视频识别模型对于视频帧的注意力分布。

图3 通过Grad-CAM生成的热力图
02
Low-light Image Restoration with Short- and Long-exposure Raw Pairs
作者:常猛,冯华君,徐之海,李奇
单位:浙江大学
邮箱:
changm@zju.edu.cn
论文:
https://github.com/JimmyChame/LSFNet
引言
使用手持成像设备在暗光环境下成像是一个挑战性课题。受限于光照条件以及成像设备硬件条件,获取的图像往往可能面临着高噪声、模糊、偏色、动态范围截止等问题。现有的方法往往只是针对于其中一两个方面进行研究,而且由于获取真实数据集的难度较大,许多数据集构建方式与真实场景下的图像获取存在差异。这造成了这些方法难以应用于真实成像场景。本文提出了一种基于长短曝光图像互补信息进行暗光场景图像复原的方法。
本文的主要技术贡献如下:
通过分析暗光环境下的真实成像模型,提出了一种更加真实的数据退化方法用于生成长短曝光Raw数据。从而解决了手持设备在暗光场景下成像这种常见又困难场景的数据集构造难题;
提出了一种新的长短曝光融合的网络结构,以长短曝光Raw数据作为输入,可以同时处理配准,噪声,模糊,偏色,动态范围截止等问题,输出高质量复原图像;
方法
为了得到长短曝光的Raw图像以及对应的高质量参考图像作为数据集,我们首先使用清晰的Raw数据合成相机接受到的辐射度图像,然后跟随成像流程,依次建模并添加模糊,偏移,噪声,偏色,动态范围截止,bayer采样,量化等退化模块。在训练模型时,以长短曝光Raw图像作为输入,线性域RGB图像作为输出,经过ISP后处理得到最终的sRGB图像。

提出的网络结构包含了特征提取,配准,鬼影抑制,融合重建四个模块,分别应对长短曝光融合中遇到的图像偏移,鬼影模糊,融合信息等问题,另外模型还采用多尺度结构进行图像配准和融合,从而更好地实现端到端的图像复原。
实验
首先对提出的模型进行了消融实验,证明各个模块的有效性。然后在合成数据集和真实拍摄图像上与现有的暗光复原方法做了比较,对比方法包括了降噪,去模糊,多曝光融合等不同类型复原方法。在客观指标和主观视觉上,提出的方法都具有显著优势。

网络结构


客观指标


03
Coarse-to-Fine Embedded PatchMatch and Multi-Scale Dynamic Aggregation for Reference-based Super-Resolution
作者:夏彬, 田亚鹏, 杭煜程,杨文明,廖庆敏, 周杰
单位:清华大学
邮箱:
xiab20@mails.tsinghua.edu.cn
论文:
https://www.aaai.org/AAAI22Papers/AAAI-390.XiaB.pdf
代码:
https://github.com/Zj-BinXia/AMSA
基于参考的超分辨率(Reference-based Super-Resolution, RefSR)旨在在附加的高分辨率参考(Ref)图像的指导下,从低分辨率(LR)图像重建照片逼真的高分辨率(HR)图像。通过在LR图像和HR参考之间传递相关信息,最近的RefSR方法已经显示出非常好的结果。但是目前的RefSR方法还存在两个关键问题。一是通常使用枚举的方法搜索相关块,这非常低效,计算复杂度为输入图像大小的二次方。此外RefSR对于HR和LR间的尺度偏差非常敏感,其会带来巨大的性能下降。模型的整体架构如图1所示。
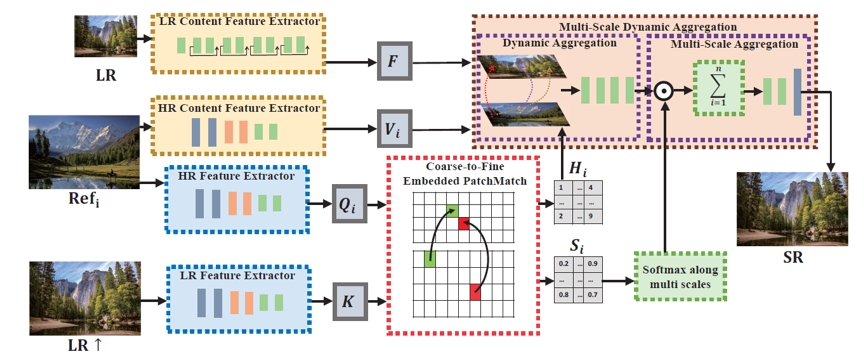
图1 基于参考的超分辨率加速多尺度聚合网络(AMSA)描述。我们直接使用C2-Matching训练好的特征提取器来提取匹配特征。然后利用由粗到细的嵌入PatchMatch进行特征匹配,最后将匹配到的高分辨率信息通过多尺度动态聚合模块用于低分辨率图像的细节纹理恢复。
为了解决相似块的搜索效率问题,我们提出了由粗到细的嵌入PatchMatch(CFE- PatchMatch)模块。对于Embedded PatchMatch可以分为随机初始化,LR Propagation & Evaluation 层,以及Ref Propagation & Evaluation 层。通过几次迭代就可以获得非常好的一个匹配效果,算法复杂度正比于输入图像的大小。算法流程如图2所示。
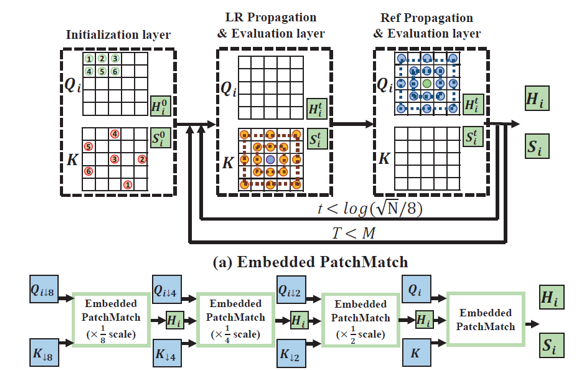
图2 CFE-PatchMatch的示意图。(a) 嵌入PatchMatch重复$Mlog(sqrt(N)/8)$次(t=0到$log(sqrt(N)/8)-1$,T=0到M- 1) 来预测对应的匹配坐标图,其中N是Ref和LR图像大小。Hit和Sit是第t次迭代中的中间对应坐标和相关性。(b)又粗到细嵌入匹配(CFE-PatchMatch)在1/8、1/4、1/2和原始尺度上应用嵌入匹配(Embedded PatchMatch),以快速获得Hit和Sit。
除此之外,为了缓解由于LR和Ref图像之间的尺度不匹配而导致的性能下降,并充分利用多尺度上的参考信息,我们提出了多尺度动态聚合(MSDA),包括动态聚合和多尺度聚合。在动态聚合中,我们采用改进的可形变卷积(DCN)形式纠正微小的尺度偏差,但这无法处理大规模偏差。因此,我们进一步通过聚合多尺度参考信息来设计多尺度聚合,以获得对对大尺度偏差的鲁棒性。相关的网络示意图见图1。
04
Image Co-Saliency Detection and Instance Co-Segmentation Using Attention Graph Clustering Based Graph Convolutional Network
作者:李腾鹏1,张开华1,沈诗文2,刘博2,刘青山1,李竹3
单位:1南京信息工程大学,2JD Digits, Mountain View, California 94035 USA,3University of Missouri, Kansas City, Missouri MO 64110 USA
邮箱:
1158257243@qq.com
zhkhua@gmail.com
shiwenshen@engineering.ucla.edu
kfliubo@gmail.com
qsliu@nuist.edu.cn
zhu.li@ieee.org
论文:
https://ieeexplore.ieee.org/document/9337219
代码:
https://github.com/ltp1995/GCAGC-CVPR2020/
引言:协同显著性检测作为视觉分割领域的一项重要技术,旨在一组图片中挖掘出相似且显著的物体,已在许多领域得到了广泛应用。传统的分阶段协同显著性检测方法主要依赖于颜色直方图、SIFT描述子等手工特征,后续又利用深度学习模型提取的语义特征提升模型的鲁棒性。基于端到端的深度学习模型可以脱离这种低效的分阶段检测模式,利用训练数据自动对协同区域和前景物体进行学习,更符合实际落地场景的需求。
研究动机:现有的端到端模型往往存在细节特征退化、高层语义表示难等问题,并且无法对图组中的协同显著物体进行有效关系建模。本文提出了一种基于图卷积网络和注意力图聚类(GCAGC)的方法,以提升模型在协同显著性检测和实例级协同分割任务上的表现。
方法概述:首先,本文基于CNN编码器提取多尺度多层次的特征,以生成密集的特征节点图。然后,利用设计的自适应图卷积网络(AGCN)对密集节点图进行关系建模,进而构建任意位置的图节点在全局范围内的关联。随后,通过提出的注意力图聚类算法(AGCM)以一种无监督的方式对前景显著物体进行判别。最后,通过解码器生成协同显著图。此外,本文还引入实例分割模型Mask-RCNN辅助GCAGC模型生成实例级的协同分割图。
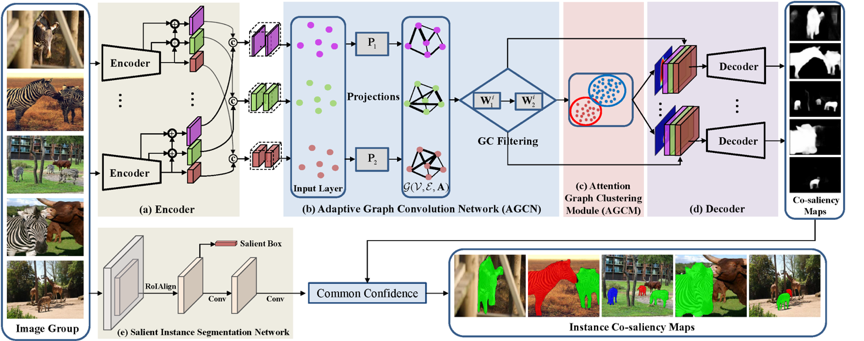
图1 GCAGC模型方法概述
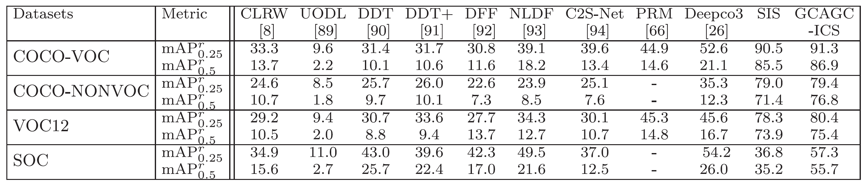
实验结果:在四个主流的协同显著性检测数据集,即iCoseg, Cosal2015, COCO-SEG和CoSOD3k,以及在四个实例级协同分割数据集,即COCO-VOC, COCO-NONVOC, VOC12和SOC上,本方法都取得了SOTA性能。
表1 协同显著性检测对比结果

表2 实例级协同分割对比结果
可视化结果:图2和图3的结果也显示了模型在协同显著性检测和实例级协同分割数据集上的有效性。
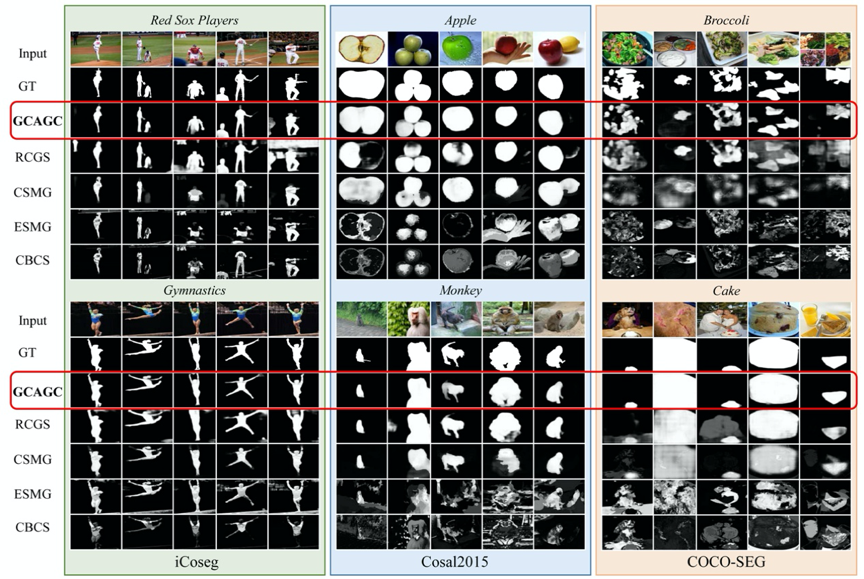
图2 协同显著性检测可视化结果

图3 实例级协同分割可视化结果
05
Emotion Expression with Fact Transfer for Video Description
作者:王瀚漓,汤鹏杰,李秦渝,程孟
单位:同济大学
邮箱:
hanliwang@tongji.edu.cn;
tangpengjie@jgsu.edu.cn;
qinyu.li@tongji.edu.cn;
chengmeng@tongji.edu.cn
论文:
https://ieeexplore.ieee.org/document/9352546
数据集、代码:
https://mic.tongji.edu.cn/
论文概述:将一段视频转换为自然语言描述是当前的研究热点之一。目前研究多集中于对视频中物体、场景、事件等方面的事实描述,对其融合情感的描述生成关注不够,较少挖掘视觉信息中蕴含的情感语义,生成的描述语句缺少感性色彩,语义丰富程度受到一定限制。本文提出一种基于事实语义迁移的视频情感描述方法。构建了一个带有情感表达的视频描述数据集;设计了一个基于事实迁移的视频情感描述框架,并提出一种综合事实和情感表达的描述评价方法。多组实验结果证明了包括数据集构建、模型设计以及评价指标计算的合理性和有效性。
主要工作:本文构建了一个包括两个子集的视频情感描述数据集。首先,在MSVD数据集中抽取部分视频和对应的参考描述语句;然后以 “情感轮(Emotional Wheel)”理论为基础,选取相关情感类型和情感词汇,对视频描述语句进行情感嵌入,构建EmVidCap-S子集。其次,在既有的视频情感分析数据集基础上,对视频进行重新剪辑,并为每段视频进行融合情感的语句标注,构建EmVidCap-L子集。最后将两个子集合并,形成描述更为丰富的EmVidCap数据集。数据集示例如图1所示。


图1 EmVidCap数据集示例(左子图来自EmVidCap-S,右子图来自EmVidCap-L)
为生成融合情感的视频描述,本文提出一种基于事实迁移的视频情感描述框架(FT)。采用两阶段优化策略,首先使用仅具有事实描述的数据集训练模型的事实部分,使模型学习事实表达;其次在包含情感表达的数据集上对模型情感部分进行训练,同时对事实部分进行微调。两部分的输出误差不仅被反向传播到其各自的分支,还通过共享嵌入传播到另一分支。在测试时,通过对两部分的输出概率加权融合,实现事实和情感的融合表达。模型框架如图2所示。


图2 FT模型的训练和测试框架(左子图为模型训练框架,右子图为测试框架)
为验证生成句子质量,本文设计针对情感描述的评价指标,通过情感用词准确性(Accsw)、情感句子准确性(Accc)衡量生成句子情感语义的准确性和丰富性;此外,将情感评价指标与传统评价指标相结合,设计了综合评价指标(BFS和CFS),对生成句子进行更为合理而完整的评价。
实验结果:在EmVidCap-S和EmVidCap数据集上对提出的FT模型进行了验证。与其他对比模型相比,所提出的FT模型在传统指标、情感评价指标和综合评价指标上都获得了更优的性能表现(如表1、表2所示)。
表1 各模型在传统指标上的性能对比
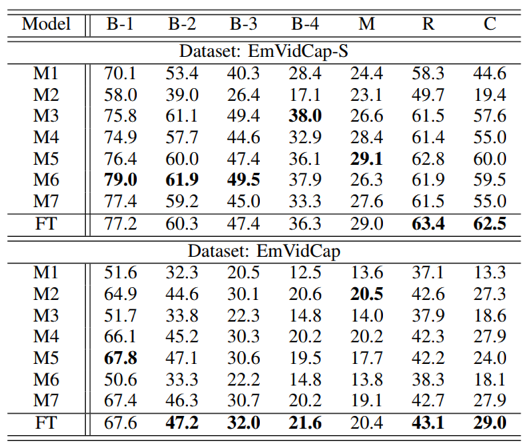
表2 各模型在情感评价指标和综合评价指标上的性能对比

06
IDHashGAN: Deep Hashing With Generative Adversarial Nets for Incomplete Data Retrieval
作者:徐黎明1,2,曾宪华1,李伟生1,白羚1
单位:1.重庆邮电大学计算机科学与技术学院,重庆市图像认知重点实验室;2.西华师范大学计算机学院;
邮箱:
xulimmail@gmail.com,
zengxh@cqupt.edu.cn,
liws@cqupt.edu.cn,
battylingb@gmail.com
论文:
https://ieeexplore.ieee.org/document/9339884
代码:
https://github.com/LimingXuM3/IDHashGAN_Pytorch
研究背景与动机
由于较低的存储成本和较高的检索效率,哈希学习已成为大规模图像检索中广泛采用的技术之一。深度哈希将特征学习和哈希编码集成到端到端框架中,很大程度上提高了图像检索的性能。由于生成对抗网络的不断发展与日趋成熟,基于生成对抗网络(GANs)的哈希检索进一步提高了图像检索的准确率。然而,现有的基于GANs的哈希方法仅适用于检索完整图像,尽管在检索完整图像实现了较高的精度,但用户的可接受度有待进一步提高。如图 2所示,查询图像为一辆红色的轿车,检索得到了一辆白色的轿车,尽管属于同一类,但视觉上并不相似。对此,本文提出一种基于多生成对抗网络的非完整图像哈希检索算法,实现了非完整图像的有效检索,同时提高了用户的可接受度。
方法概述
如图1所示,所提模型由三部分组成:生成网络、判别网络和哈希网络。生成网络用于复原非完整图像丢失的特征,判别网络用以区分输出图像是真实图像还是复原图像,并判断这两个图像是否相似,哈希网络则将非完整图像和完整图像编码成紧凑的二进制哈希码。所提算法将特征复原,特征学习和哈希编码集成到一个端到端的框架中,利用重建损失和对抗损失复原非完整图像缺失的特征,并且提出监督流形相似度来提高检索精度和获得良好的用户可接受度。理论证明,该相似度保持度量优于点对相似度度量和成对相似度度量,能够较好地保持图像之间的语义关系,在缩小相似图像之间海明距离的同时,增大非相似图像之间的海明距离。此外,在判别网络中利用对抗损失判别输入图像的真实性,引入分类损失区分输入图像与复原图像的相似性,在哈希网络中融合编码损失和量化损失来保持图像哈希码之间的相似性。

图1 所提算法模型结构示意图
实验结果
为了验证所提算法的有效性,本文在 CIFAR-10、NUS-WIDE 和 MIRFlickr 基准数据集上进行评估,然后将所提算法与近期优秀的基于手工特征和基于深度特征的哈希算法进行比较和分析。实验表明,本文提出的检索算法不仅在非完整图像检索中取得绝对的增量,在完整图像检索中也表现出较强的竞争力。
表1 非完整和完整数据集的检索精度
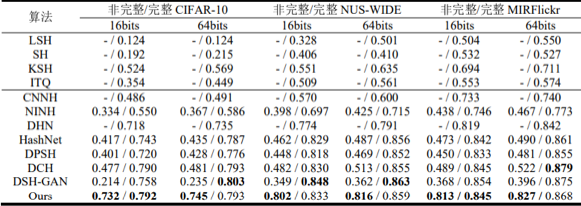

图2 前10幅检索图像及检索精度
图2中的“红圈”表示,检索到的图像与查询图像具有相同的类,但不满足用户的需求。如图2所示,查询图像是“红色”汽车,在使用点对监督信息进行检索时,检索到“白色”汽车。虽然检索结果属于同一类,但并不能最大限度地满足用户的需求。DPSH、DSH-GAN 和HashNet这三种对比算法仅仅用到了单一的监督信息,相比之下,所提算法(IDHashGAN)获得了更好的用户可接受度。对比 DSH-GAN 算法,尽管 IDHashGAN 在多标签数据集上检索精度有所下降,但它实现了令人满意的用户可接受度和较高的检索精度。
本文采用交替学习策略来优化目标函数,训练结束后会将产生生成网络、判别网络和哈希网络三个网络。如前所述,生成网络可以用来复原非完整图像的缺失特征。训练过程中,首先为原始图像添加随机掩码,然后使用训练好的生成网络来复原非完整图像。MIRflickr数据集上非完整图像的复原结果如图3所示。

图3 MIRFlickr数据集上的复原结果

 京公网安备11010802017125号
京公网安备11010802017125号