
2022年论文导读第十八期
【论文导读】2022年论文导读第十八期
CCF多媒体专委会 2022-09-06 12:20 发表于北京


论文导读
2022年论文导读第十八期(总第五十八期)
目 录
|
1 |
Ingredient-Guided Region Discovery and Relationship Modeling for Food Category-Ingredient Prediction |
|
2 |
Towards Fewer Annotations: Active Learning via Region Impurity and Prediction Uncertainty for Domain Adaptive Semantic Segmentation |
|
3 |
Source-Free Object Detection by Learning to Overlook Domain Style |
|
4 |
Active Learning for Domain Adaptation: An Energy-based Approach |
|
5 |
Learning Soft Estimator of Keypoint Scale and Orientation with Probabilistic Covariant Loss |
|
6 |
Fine-Grained Predicates Learning for Scene Graph Generation |
|
7 |
UniCoRN: A Unified Conditional Image Repainting Network |
01
Ingredient-Guided Region Discovery and Relationship Modeling for Food Category-Ingredient Prediction
作者:王致岭1,2,闵巍庆1,2,*,李卓1,2,康丽萍3,魏晓明3,魏晓林3,蒋树强1,2
单位:1中国科学院计算技术研究所,2中国科学院大学,3美团
邮箱:
wangzhiling02@meituan.com;
minweiqing@ict.ac.cn;
zhuo.li@vipl.ict.ac.cn;
kangliping@meituan.com;
weixiaoming@meituan.com;
weixiaolin02@meituan.com;
sqjiang@ict.ac.cn
论文:
https://ieeexplore.ieee.org/document/9846887
1. 引言
由于食品在人们生活中的基础性地位,来自物联网、社交网、互联网等各种网络产生的海量多媒体食品数据在食品工业和餐饮服务业等诸多领域,及食品营养和疾病健康等社会生活的诸多方面蕴含着广阔应用前景和社会价值,逐渐形成了“食品计算”这一新兴方向。食品图像类别识别及食材预测作为食品计算的基本任务,在营养评估和食品推荐等应用中发挥重要的支撑作用。我们提出了一种多任务食品联合学习方法同时进行食品类别识别和食材预测。该方法主要由食材视觉区域提取和食材关系建模学习构成。食材视觉区域提取通过构建一个食材字典来捕获食品图像中的多样化食材区域并获得相应的食材分配图,进而用于发现并提取相应的食材特征;对于食材关系建模,利用食材视觉表征作为节点,食材词嵌入间的语义相似度作为边,构建面向食材的语义-视觉图,并通过图卷积网络对食材间的关系进行建模和学习。该方法采用多任务学习优化整个网络,同时进行食品类别识别和食材预测。我们在三个基准数据集(ETH Food-101、Vireo Food-172和ISIA Food-200)上进行评估,验证了方法的有效性。
2. 方法概述
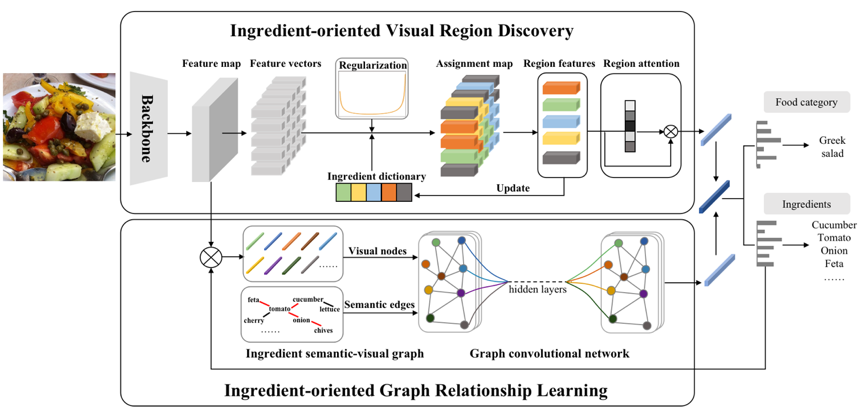
图1 多任务食品类别-食材联合学习框架
本文所提出的多任务食品联合学习框架如图1所示,主要由两部分组成:食材视觉区域提取(Ingredient-oriented Visual Region Discovery,IVRD)和食材图关系建模学习(Ingredient-oriented Graph Relationship Learning,IGRL)。
在食材视觉区域提取中,将一张食品图像输入到网络后,我们首先从最后一个卷积层中提取其特征图,通过预先构建好的食材字典将2D特征图分组为具体的食材区域,并采用一个U形先验正则化食材的出现频率,提高该过程中的食材发现能力。然后我们从食材分配图中池化出这些食材特征,并使用注意力机制对其加权。在食材图关系建模学习中,我们构建了一个面向食材的语义-视觉图来探索各种食材之间的关系。其中食材图的节点表示不同食材的视觉表征,食材图的边表示食材词之间的语义关系。然后我们将食材图输入到图卷积网络中学习食材之间的关系。最后,对于两个分支的输出,我们将二者融合在一起并将它们输入两个分类器,并通过多任务学习的方式优化整个网络模型,同时进行食品类别识别和食材预测。
3. 实验结果
表1 食品类别识别消融实验(%)
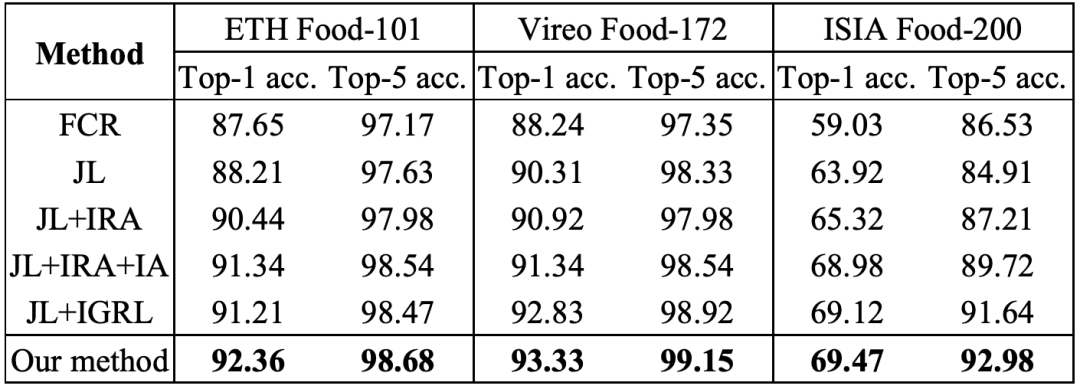
表2 食材预测消融实验(%)
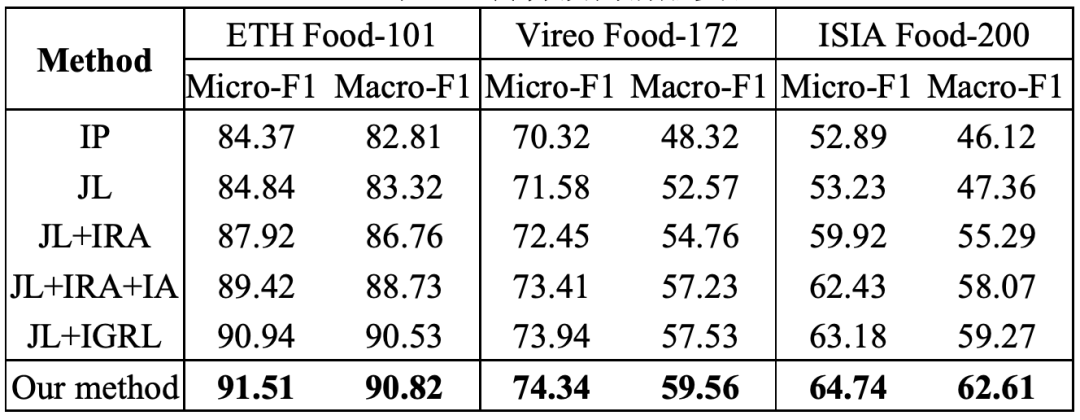
本文在消融实验中,我们对于三个数据集首先验证了多任务学习框架的性能,然后对食品类别识别和食材预测进行了单个任务消融研究,实验结果如表1和表2所示。可以看出,联合学习方式(Joint Learning,JL)的性能超过了单个任务,意味着这两个任务共同学习,相互促进;当将食材区域分配策略(Ingredient Region Assignment,IRA)引入到网络中,Top-1准确率和Macro-F1值均有所提高;当引入食材注意力机制(Ingredient Attention,IA)来增强区域特征时,实验性能获得进一步提升;当将食材关系学习(Ingredient-oriented Graph Relationship Learning,IGRL)引入到网络中后,两个任务的性能均进一步提高,意味着食材关系挖掘的重要性。
表3 在 ETH Food-101 上的食品类别识别性能比较(%)
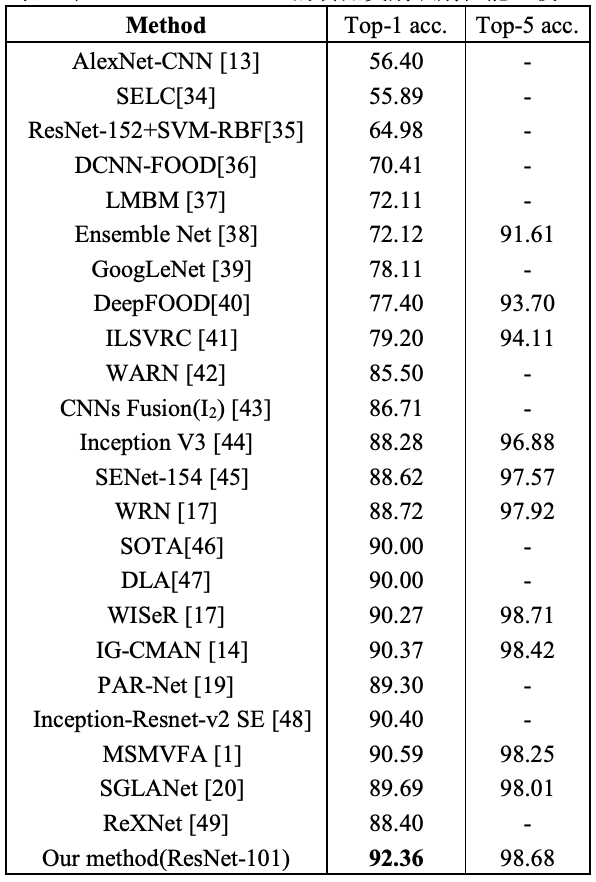
表4 在 ETH Food-101 上的食材预测性能比较(%)
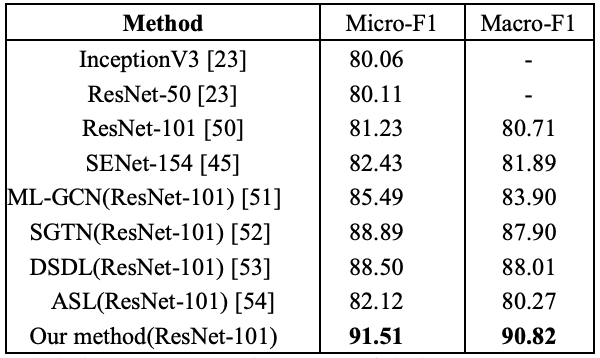
本文进一步在食品类别识别和食材预测两个任务上分别与当前主流方法进行了性能比较,实验结果如表3和表4所示。对于食品类别识别,本文的方法超越了其他所有方法,相较于MSMVFA有1.77%的性能提升,表明探索不同食材的组合方式和建模其关系的优越性。本文的方法比忽略了区域间关系建模的PAR-Net高出3.06%,证明使用 GCN 建模食材关系带来了较高的性能提升。对于食材预测,本文的方法优于其他所有方法,F1指标超过SENet154近10%,超过 DSDL接近3%,表明发现特定的食材区域可以帮助识别相应的食材类型。
4. 可视化结果

图2 方法中获取的部分样本的食材分配图和注意力图
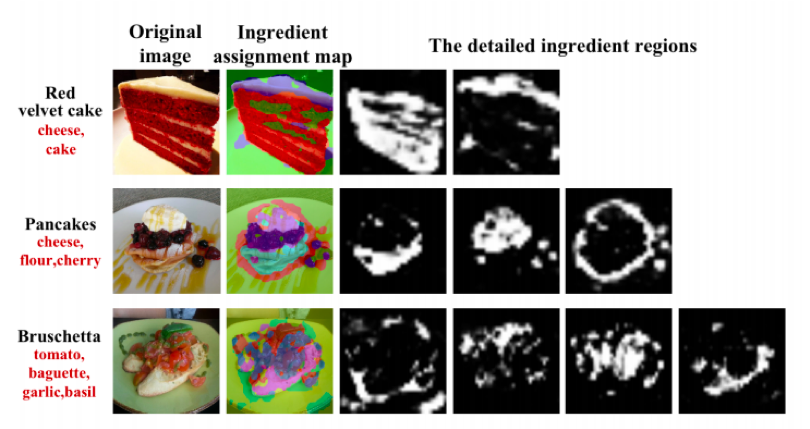
图3 食材分配图中对应的具体食材区域

图4 一些测试样本的实验结果
本文进一步在图2和图3中对食材分配图和食材注意力图进行可视化。图4展示了一些测试样本的实验结果。结果显示图中的食材预测结果并不总是正确的,其可能的原因是混合食材区域没有明确划分以及食材空间结构的变化等。此外,本文所提的方法在部分情况下也可能无法正确识别食品类别,可能的原因是部分不同食品的视觉模式非常相似,并且它们有较多共同食材等。
更多食品计算相关的工作请访问如下网站:
http://123.57.42.89/FoodComputing__Home.html
02
Towards Fewer Annotations: Active Learning via Region Impurity and Prediction Uncertainty for Domain Adaptive Semantic Segmentation
作者:谢斌辉1 ,袁龙辉1 ,李爽1,* ,刘驰1 ,程新景2 ,*
单位:1 北理工大学, 2赢彻科技
邮箱:
binhuixie@bit.edu.cn
论文:
https://arxiv.org/pdf/2111.12940.pdf
代码:
https://github.com/BIT-DA/RIPU
主页:
https://binhuixie.github.io
*通讯作者
摘要:
深度神经网络擅长从海量标记数据中学习,但却很难将其推广到新的目标领域。无监督领域自适应(UDA)作为目前解决标签缺失情况下模型跨域迁移的主要技术之一,利用源域的标记数据和目标域的未标记数据来提高模型在目标域上的泛化能力。然而,UDA的局限性是显而易见的,目前仍然远远落后于有监督模型。在这种情况下,也许可以对一些目标数据进行标记,以提高模型的性能。首先面临的问题是:应该从目标数据集中选择哪些样本进行标注?样本选择之后的另一个问题是:如何有效地利用所有可用的数据来提高目标域模型的性能?
主要贡献:
本文提出了一种简单的基于区域的主动学习策略,更加适用于语义分割任务。利用空间上的多样性和预测上的不确定性来挑选极少区域进行标注,仅需极少的标注即可达到与有监督相当的性能。
方法概述:
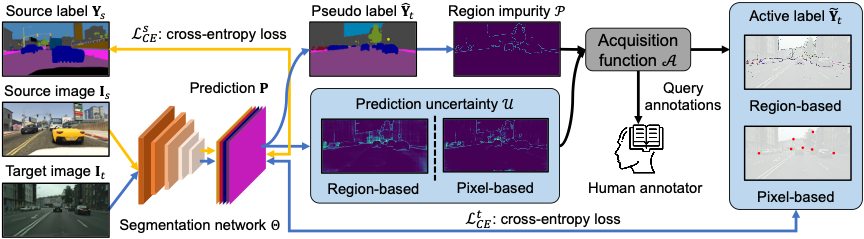
总体来看,我们的方法在每一轮筛选样本时,对于每一张每一张目标域图片,首先使用当前的分割模型评估其区域不确定度
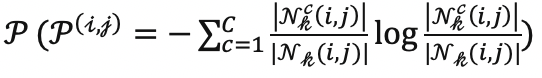
和预测不确定度
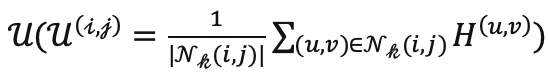
然后使用筛选函数��筛选一批区域或者像素,并且给与标注。最后使用目前所有的有标注数据重新训练网络。我们的方法总体如下图所示:
实验结果:
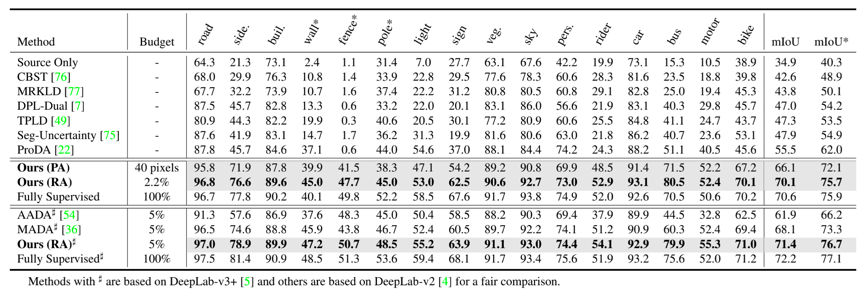
本文首先在两个基准任务上进行了实验验证(GTAV Cityscapes和SYNTHIA Cityscapes)。表1和表2展示了本文提出的方法与一些近期工作的比较结果,可以看出所提出的方法在各数据集上都优于其他最先进的方法。
表1 GTAV->Cityscapes结果对比
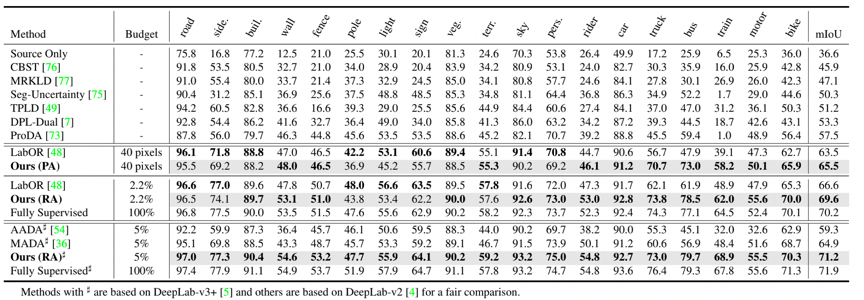
表2 SYNTHIA->Cityscapes结果对比
为了更清晰地了解主动学习如何提升模型的分割性能,我们还可视化了算法所挑选的区域:

图1 挑选区域的可视化
同时,为了验证挑选的区域具有class balance的效果,我们也统计了整个Cityscapes数据集和所挑选的区域的类别分布,从图2可以看出,我们的方法能够挑选出更多少数类的区域,一定程度上缓解了原始数据中的长尾问题。
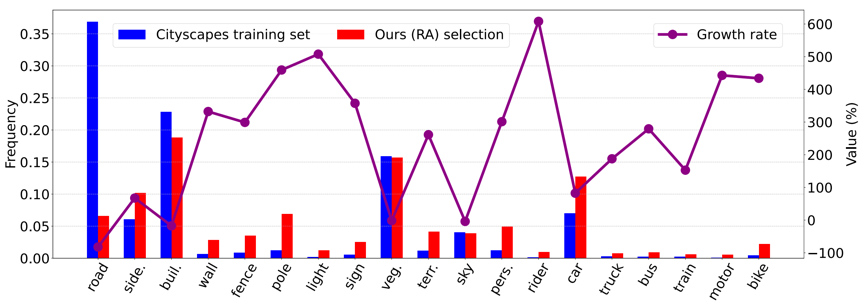
图2 类别频率
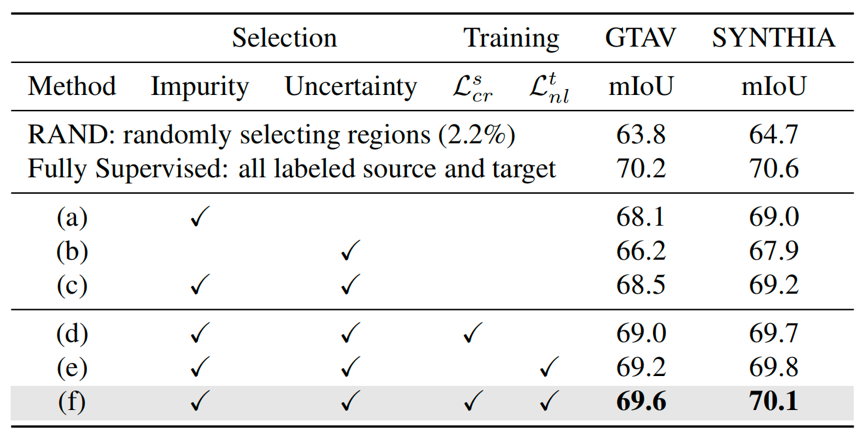
然后,消融实验(表3)验证了空间上和预测上两种挑选指标各自的效果,两者是互补的。同时,发现局部一致性和负学习损失可以进一步提高模型泛化到目标域的性能。
表3 消融实验
最后,将该方法扩展到了source-free的场景下,也取得了极大的性能提升。
表4 Source-free场景下GTAV->Cityscapes结果对比

表5 Source-free场景下SYNTHIA->Cityscapes结果对比

03
Source-Free Object Detection by Learning to Overlook Domain Style
作者:李帅锋,叶茂,朱霞天,周李华,熊林
单位:电子科技大学计算视听觉实验室
邮箱:
hotwindlsf@gmail.com
maoye@uestc.edu.cn
xiatian.zhu@surrey.ac.uk
论文:
https://openaccess.thecvf.com/content/CVPR2022/html/Li_Source-Free_Object_Detection_by_Learning_To_Overlook_Domain_Style_CVPR_2022_paper.html
代码:
https://github.com/Flashkong/Source-Free-Object-Detection-by-Learning-to-Overlook-Domain-Style
论文视频讲解:
https://www.youtube.com/watch?v=A7vBStzBZLY
研究背景与思路:
无源领域自适应目标检测假定仅使用由源域数据预训练的源域模型和无标签的目标数据完成知识迁移。现存方法多使用伪标签策略在伪标签生成和模型微调之间交替。由于域差异的存在,这类方法不仅无法生成高质量的伪标签而且也无法有效利用所有目标域数据。
本文提出了一个学习忽略域风格方法,从一个新颖的角度出发,通过强制模型忽略目标域风格来减少域差异对模型自适应的影响,使其更容易进行。如图1所示,我们增强了每个目标域图像的风格,并利用原始图像和增强图像之间的风格差异作为模型适应的自监督信号。而教师学生框架则巧妙地利用该监督信号,在双向知识蒸馏的作用下完成忽略域风格的学习。该方法的实验结果在多个数据集上均取得了突破,并通过可视化验证了模型学习到了忽略风格能力。
该研究已被CVPR 2022收录为Oral。
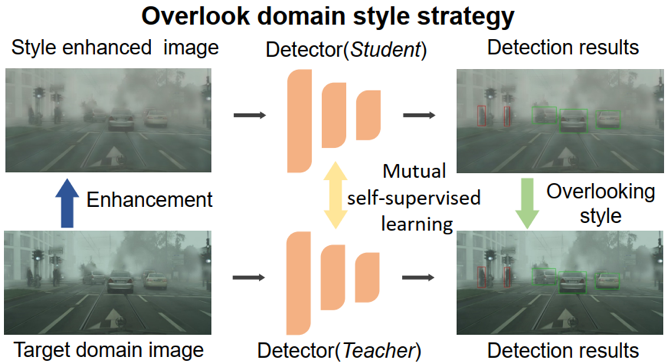
图1 本文的核心研究思路
实现方法:
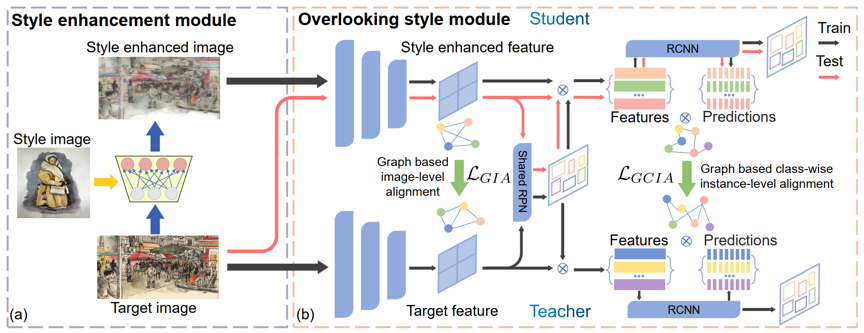
图2 模型图
根据研究思路,我们的方法被分为风格增强模块和忽略风格模块(如图2所示)。在保持目标域图片原始风格的前提下,风格增强模块通过非线性方式组合它和任意一张目标域图片(风格图片)的风格。具体地,如图3所示,在编码器-解码器结构下,预训练的VGG-16模型被用作编码器。每张图片的风格通过计算其特征在通道上的均值和方差得到,而后经过两个非线性网络生成增强的风格并融入到特征中,最后解码得到风格增强图片。
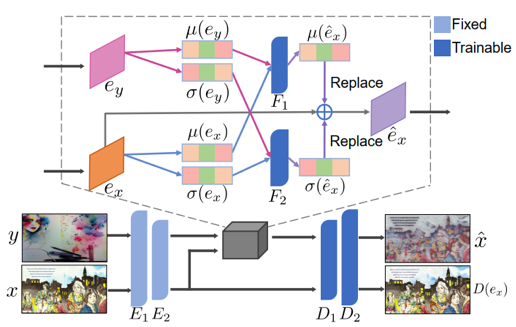
图3 风格增强模块
忽略风格模块以风格差异作为监督信号,在教师学生框架下强制教师和学生模型学习忽略域风格能力。风格增强图片和目标域图片被分别输入到学生和教师模型中(顺序不可互换),然后通过两个基于图的对齐使风格增强特征向目标域特征对齐,由于两张图片的内容完全一致,因此对齐操作会迫使学生模型忽略叠加的风格差异。
由于巧妙的图片输入顺序,在对齐过程中,知识从原始图片输入的教师模型流入学生模型。同时,随着模型的自适应过程,知识在指数移动平均的作用下从学生模型流入教师模型。在这个双向知识蒸馏作用下,风格增强模块和忽略风格模块形成一个闭环,教师和学生模型在其中朝着忽略域风格的方向一步一步地学习,完成模型自适应过程。
实验结果:
量化实验结果如图4所示。
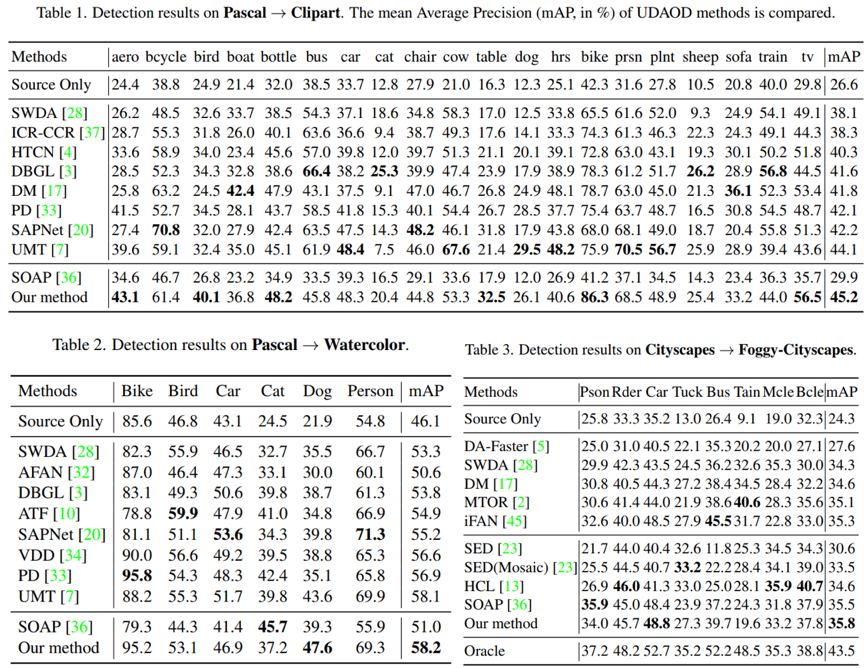
图4 实验结果
为了探究模型是否学习到了忽略域风格的能力,如图5,我们进行了可视化。通过对比第一列(目标域图片)和第四列(重建的目标域图片)以及第三列(风格增强图片)和第五列(重建的风格增强图片),模型中学到的忽略域风格能力得到验证。

图5 可视化验证
04
Active Learning for Domain Adaptation: An Energy-based Approach
作者:谢斌辉1 , 袁龙辉1 , 李爽1,* ,刘驰1 ,程新景2 ,王国仁1,*
单位:1北京理工大学, 2赢彻科技
邮箱:
binhuixie@bit.edu.cn
论文:
https://ojs.aaai.org/index.php/AAAI/article/view/20850
代码:
https://github.com/BIT-DA/EADA
*通讯作者
摘要:
无监督领域自适应(Unsupervised Domain Adaptation)近年来成为了深度神经网络泛化到新领域的范式之一。然而UDA与目标领域上的完全监督性能仍然相差极大。实际上,少量的标注数据,在时间消耗、经济开销等方面是可行的。本文的工作聚焦主动领域自适应(Active Domain Adaptation):在领域偏差存在的情况下,利用源领域的知识和目标域中少量挑选的样本给予标记,使得模型在目标域上的性能获得极大的提升。本文从能量模型的角度设计了一种全新的基于能量的主动领域自适应算法(EADA),在多个数据集上超越了SOTA的方法。
方法概述:
本文从如何训练能量模型角度出发。对于输入的一张图片,能量模型将其分类为最低能量的标签所对应的类别。于是为了训练一个能够正确分类的能量模型,采用负对数似然函数进行训练:
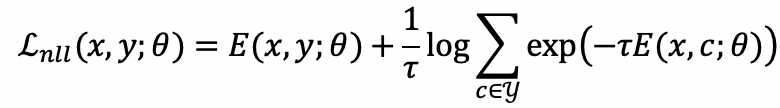
同时我们观察到,样本的自由能
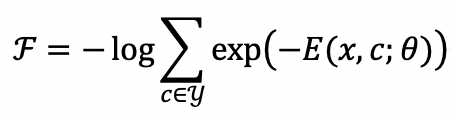
在源领域与目标领域上的存在分布偏差,即源领域样本的自由能相较于目标领域样本自由能普遍较低,而这也被看作领域偏差的一种体现。于是提出了自由能对齐正则项,隐式地减少目标领域与源领域之间的域间差异:
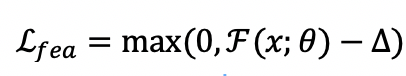
对于主动学习过程,提出了两步样本选择策略,结合样本的领域特征性和不确定性来充分保证最终所选择的样本具有较高的信息价值。首先采用自由能筛选领域特征性最强的一部分样本作为候选集,接着采用MvSM,即
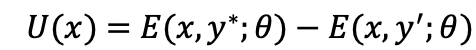
选择候选集中最不确定的样本作为本轮样本选择的结果。方法总体框架如图1所示。
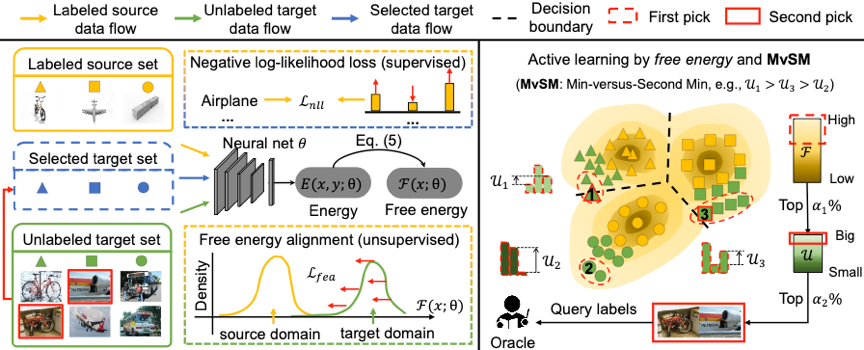
图1 总体框架图
实验结果:
首先在VisDA-2017上,采用不同标注预算与网络结构(图2),将EADA与现存方法进行对比,可以看到在不同的标注预算下,EADA结果最优,并且可以观察到当标注预算极其少时(1-3%),EADA相较于其他方法提升尤为明显(2-5%),证明了EADA确实能够选择到更具有信息价值的样本。
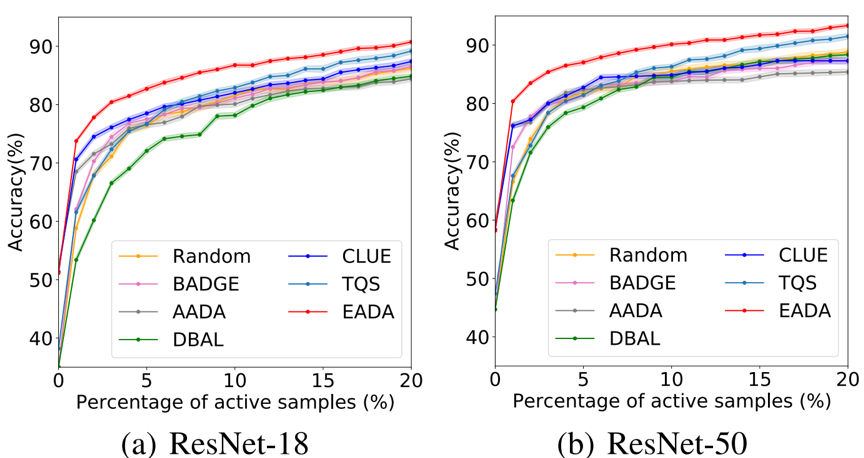
图 2 VisDA-2017上,标注预算变化时,结果对比图
随后,在语义分割场景下也对方法的有效性进行了验证(图3-a),可以看到5%的标注预算下,结果提升巨大。消融实验也展示了该方法各个组成部分的有效性(图3-b)。
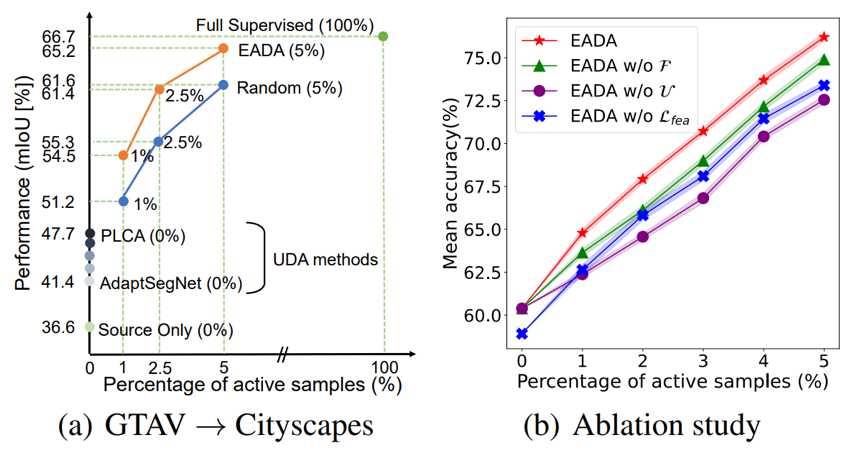
图 3(a)语义分割实验结果,(b)消融实验
最后,为了回答什么样本是值得标注的,我们给出了一个Toy Example进行可视化(图4)。可以看到,Random选择样本面临着十分严重的冗余问题,BADGE虽然一定程度上缓解了该问题,但仍然面临着选择已经对齐的样本的问题,而EADA极大程度上缓解了上述问题,选择目标领域中最具有领域特征性以及最不确定的样本。
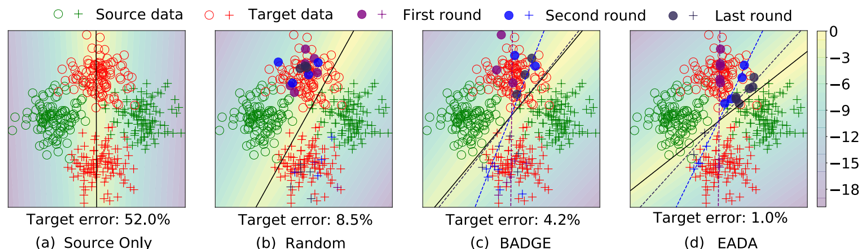
图 4 Toy Example
05
Learning Soft Estimator of Keypoint Scale and Orientation with Probabilistic Covariant Loss
作者:闫培1,谭毅华1*,熊胜洲1,邰园1,李彦胜2*
单位:1华中科技大学人工智能与自动化学院,2武汉大学遥感信息工程学院
邮箱:
yanpei@hust.edu.cn
yhtan@hust.edu.cn
xiongshengzhou@126.com
t_y_@hust.edu.cn
yansheng.li@whu.edu.cn
论文及补充材料链接:
https://openaccess.thecvf.com/content/CVPR2022/html/Yan_Learning_Soft_Estimator_of_Keypoint_Scale_and_Orientation_With_Probabilistic_CVPR_2022_paper.html
代码:
https://github.com/laoyandujiang/S3Esti
*通讯作者
研究动机
图像匹配任务中,提取具有视角不变性的特征是保证匹配精度的基础。为提升特征的视角不变性,主流方式之一是估计特征点的尺度和主方向以降低视角变化的影响。现有尺度/主方向估计模型可分为硬估计器(Hard estimator)和软估计器(Soft estimator):硬估计器对一个特征点仅预测一个尺度/主方向,而软估计器可对一个特征点预测多个尺度/主方向。
对于图像中广泛存在的复合模式(如复杂结构或多个物体形成的交错边缘),硬估计器难以预测鲁棒的尺度/主方向。以SIFT为代表的软估计器通过预测多个尺度/主方向提升对复合模式的鲁棒性。然而,现有软估计器主要基于人工计算准则,易受光照等成像条件变化的干扰,如图1(a)所示。以CovDet为代表的机器学习模型有效提升了对成像条件变化的适应性,但当前此类模型为硬估计器,难以兼顾对复合模式的鲁棒性,如图1(b)所示。为同时提升尺度/主方向估计对复合模式和成像条件变化的鲁棒性,论文设计了一种基于自监督学习的软估计器(Soft Self-Supervised Estimator,S3Esti),如图1(c)所示。
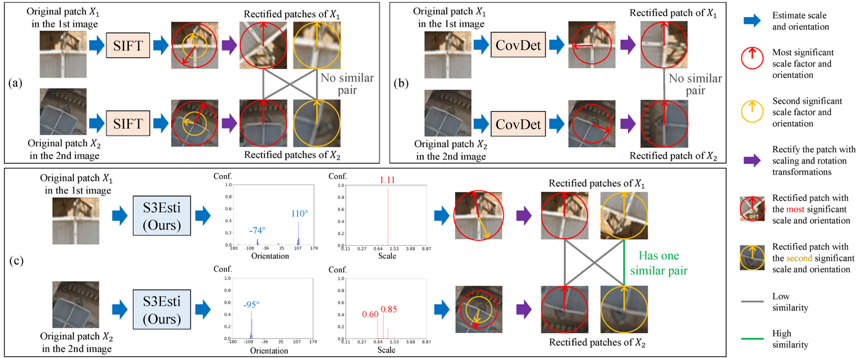
图1 S3Esti模型旨在兼顾对复合模式和成像条件变化的鲁棒性
方法概述
如图2所示,S3Esti的尺度和主方向估计器均为全卷积神经网络,其将局部图像分别映射为长度为Ns和So的置信度向量\hat{S}和O。以主方向置信度向量O中的No个分量为例,其表示输入图像块的主方向对应于No个离散角度值的置信度。S3Esti模型的训练基于论文设计的概率化协变损失和交替优化算法。如图3所示,优化S3Esti的核心思想是将不同视角下图像块的尺度/主方向对齐于一个潜在的尺度/主方向真实分布,该真实分布在交替优化算法中被表示为隐变量。
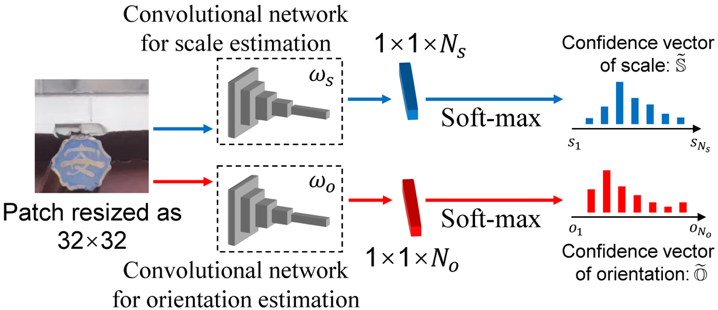
图2 S3Esti模型的网络结构
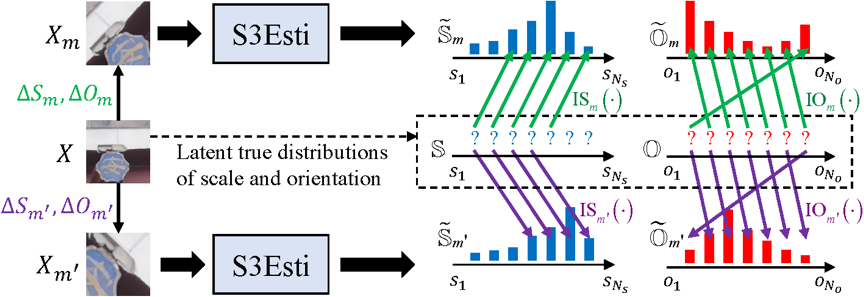
图3. 概率化协变损失的思想。S和O表示局部图像块X的尺度/主方向真实分布,“?”表示S和O的取值为隐变量。Xm和Xm'是对X进行缩放和旋转得到的变换图像块。以Xm为例,\hat{S}_{m}和Om是S3Esti对Xm预测的尺度/主方向置信度。依据缩放和旋转参数∆Sm,∆Om,概率化协变损失要求\hat{S}_{m}, Om与S,O按照绿色箭头表示的对应关系进行对齐。
实验结果
如图4所示,S3Esti可对图像块预测多个尺度/主方向,进而得到多个校正图像块。将多个校正图像块用于匹配有效降低了显著视角变化下图像的匹配难度。进一步地,S3Esti在HPatches、ETH Benchmark、MegaDepth三个数据集上均取得精度提升。图5展示了不同方法在HPatches数据集上的单应矩阵估计精度,S3Esti在大视角变化数据子集HPatches-view-large上取得了显著的精度提升,同时保持了在其他子集上的精度。
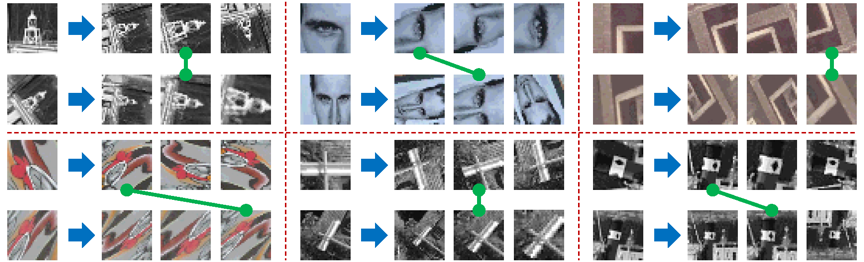
图4 基于S3Esti预测的尺度/主方向对图像块进行校正和匹配
图5 HPatches数据集上S3Esti与现有方法的精度对比
06
Fine-Grained Predicates Learning for Scene Graph Generation
作者:吕新昱1,高联丽1*,郭昱宇1,赵洲2,黄浩3,申恒涛1,宋井宽1
单位:1电子科技大学未来媒体研究中心,2浙江大学, 3快手科技
邮箱:
xinyulyu68@gmail.com
lianli.gao@uestc.edu.cn
jingkuan.song@gmail.com
论文:
https://openaccess.thecvf.com/content/CVPR2022/papers/Lyu_Fine-Grained_Predicates_Learning_for_Scene_Graph_Generation_CVPR_2022_paper.pdf
代码:
https://github.com/XinyuLyu/FGPL
*通讯作者
研究背景
当下的场景图生成方法仍受困于一些难以区分或细粒度的元素关系谓词,比如“在/站在/走在”以及“在…附近/在…前面/看向”。本文设计了细粒度谓词学习策略(FGPL),通过结合全局上下文信息帮助模型找到并区分易混淆谓词,如图1所示,具体包括谓词晶格和类别/实例鉴别损失,在场景图生成的三个子任务中,本方法的mean Recall分别比SOTA模型高22.8%、13.8%和11.5%。
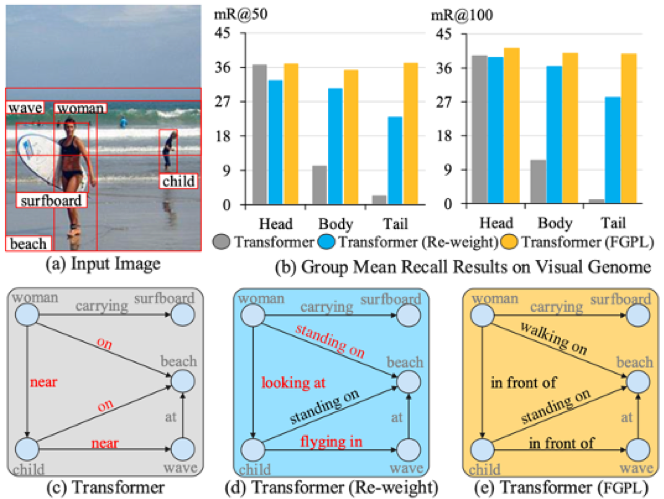
图1 对于易混淆谓词的说明。
本文方法
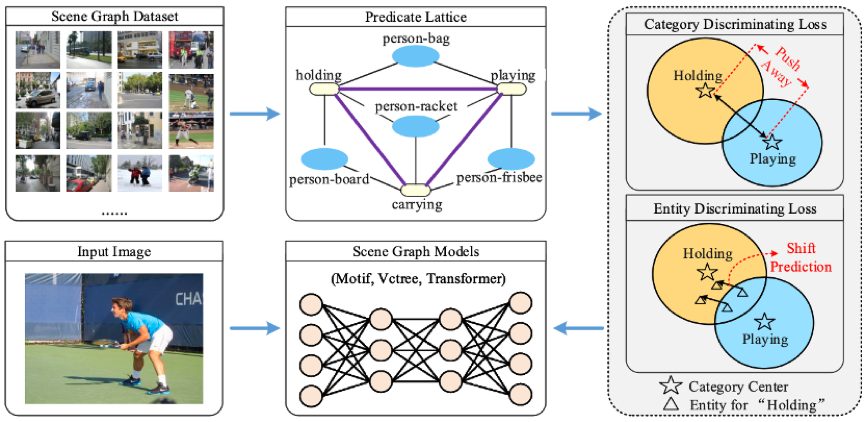
图2 本文算法流程图
谓词晶格构建:本方法利用谓词晶格来构建全局上下文之间的谓词联系,谓词晶格的构建总共分为三个阶段:第一个阶段是上下文-谓词关联。第二个阶段是偏差谓词预测。第三个阶段是谓词-谓词关联。最终,到谓词相关性归一化为S={sij}, sij∈[0,1],用于表征谓词的难区分程度。
类别鉴别损失: 传统重加权方法不考虑谓词相关性不能自适应的调节每个类的决策过程,减弱了对已辨识谓词的区分能力。因此,我们设计了类别鉴别损失函数,其根据在谓词晶格中获得的谓词关联,进一步调整重加权过程,公式如下:
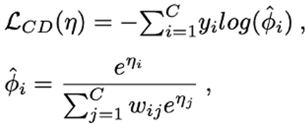
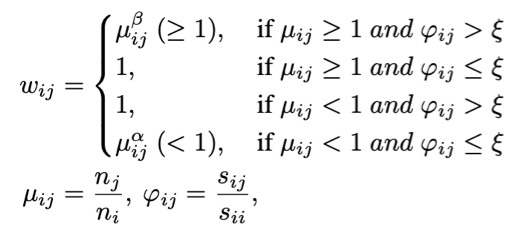
式子中的ψij表示两个谓词间的语义相关性。通过这种方式,我们加强了强关联谓词间的权重,使模型能在强关联谓词间获得更强的区分性。
实例鉴别损失: 类别鉴别损失存在两个缺陷1). 分配的权重在训练期间是固定的。2).不能以体现样本间的差异。因此,我们提出了实例鉴别损失,公式如下所示:
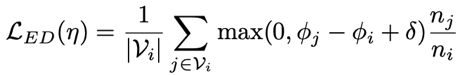
其中Vi表示谓词晶格中与谓词i有强关联的谓词集,φj与φi分别表示谓词j和i的预测概率,φj-φi表明了在训练阶段学习到的辨别能力。通过该损失函数我们可以对现有的场景图生成模型进行训练,以期获得更加精准的预测结果。
实验结果
(1)与先前方法对比:
表1 与先前方法对比。
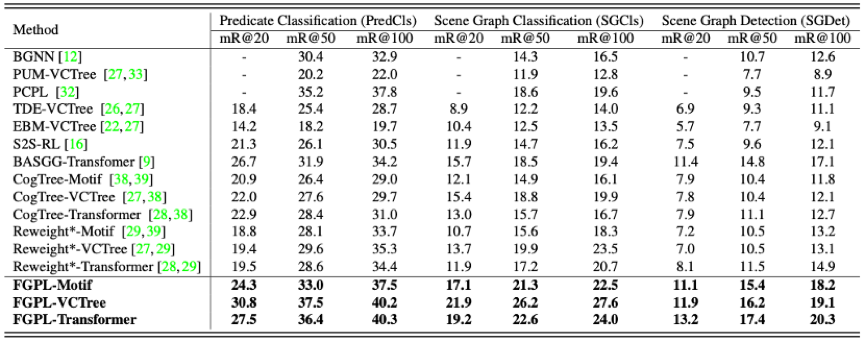
我们在上表对比了目前的SOTA方法,可以看出,无论是模型无关的方法,还是模型有关的方法,我们的效果都达到了同期最高。
(2)谓词辨识度:
表2 谓词识别度比较。
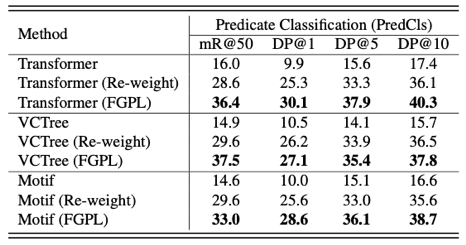
此外,我们对方法能否区分难以区分的谓词进行评价,设计了DP@K(K=1、5、10为具体阈值),可以定量地评价模型对于易混淆谓词的区分效果。如上表所示,在FGPL学习策略下,模型对难区分谓词的区分能力得到大幅增强。
(3)可视化结果:

图3 可视化结果对比。
我们在图3中比较了不同方法的可视化结果。我们发现我们的方法确实能够产生更加准确的谓词关系三元组,比如“man-walking in-snow”和“three-across-street”。
07
UniCoRN: A Unified Conditional Image Repainting Network
一体化的条件图像重绘网络
作者:孙冀蒙1,翁书晨2,常征1,李思1,施柏鑫2
单位:1北京邮电大学,2北京大学
邮箱:
sjm@bupt.edu.cn,
shuchenweng@pku.edu.cn,
zhengchang98@bupt.edu.cn,
lisi@bupt.edu.cn,
shiboxin@pku.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2022/papers/Sun_UniCoRN_A_Unified_Conditional_Image_Repainting_Network_CVPR_2022_paper.pdf
数据集:
https://drive.google.com/file/d/1KQqIrcLvnL89LsuxAMN5uHehNcZPzfdU/view?usp=sharing
代码:
https://github.com/shuchenweng/UniCoRN
论文介绍网页:
https://zhuanlan.zhihu.com/p/494622967
图像编辑作为一项非常重要的计算机视觉任务,在插画设计、视频封面制作、游戏素材制作等方面有着广泛的需求。条件图像重绘(Conditional image repainting, CIR)是一种先进的图像编辑任务,需要模型基于用户提供的多模态输入(颜色,几何,背景等),在指定的区域内生成让用户满意的视觉内容。
现有的两阶段模型方法受限于阶段间的独立性导致重绘区域和背景输入之间的拼接效果不够自然;同时,第一阶段生成的无意义的背景区域被丢弃,导致梯度回传不稳定,极大影响了重绘图像的生成质量;除此之外,模态间差异性导致重绘结果与输入颜色文本很难保持一致,难以满足用户需求。
针对以上问题,本文提出了一种一体化的模型以避免了两阶段模型带来的缺陷,并同时设计了多种模态的交互融合和注入模块,通过建立背景条件与其他条件的交互和依赖关系来缓解阶段独立性。对比之前的工作,本文提出的一体化方法可以得到质量更高,拼接效果更自然的重绘图像。
同时,本文提出了一种分层跨模态相似度模型来分别捕捉图像和颜色文本的语义特征,这兼顾了粗细粒度的特征匹配,缓解了两阶段中重绘图像和颜色文本不一致的现象。 此外,本文为扩展应用场景,收集了一个新的风景数据集,将人物重绘扩展到了风景重绘上。

 京公网安备11010802017125号
京公网安备11010802017125号