
2023年论文导读第二期
【论文导读】2023年论文导读第二期
CCF多媒体专委会 2023-01-31 09:00 发表于吉林


论文导读
2023年论文导读第二期(总第六十八期)
目 录
|
1 |
End-to-End Rain Removal Network Based on Progressive Residual Detail Supplement |
|
2 |
Employing Bilinear Fusion and Saliency Prior Information for RGB-D Salient Object Detection |
|
3 |
List-wise Rank Learning for Stereoscopic Image Retargeting Quality Assessment |
|
4 |
Multi-Scale Sparse Graph Convolutional Network For the Assessment of Parkinsonian Gait |
|
5 |
Beyond Triplet Loss: Person Re-Identification With Fine-Grained Difference-Aware Pairwise Loss |
|
6 |
Deep-IRTarget: An Automatic Target Detection in Infrared Image Using Dual-Domain Feature Extraction and Allocation |
|
7 |
Zwei: A Self-Play Reinforcement Learning Framework for Video Transmission Services |
01
End-to-End Rain Removal Network Based on Progressive Residual Detail Supplement
作者:杨勇1,管巨伟2,黄淑英1*,万伟国2,许亚婷2,刘家祥2
单位:1天津工业大学,2江西财经大学
邮箱:
greatyangy@126.com
jvguan@163.com
shuyinghuang2010@126.com
wanwgplus@163.com
xuytde@163.com
forworkliu@gmail.com
论文:
https://ieeexplore.ieee.org/document/9388918
代码:
https://github.com/whyandbecause/ERRN-PRDS
*通讯作者
1.引言:
雨天获取的图像往往会对图像分类、目标检测、图像分割或视频跟踪等视觉任务产生负面影响。为了减少这些视觉任务中雨滴带来的消极影响,图像去雨技术受到研究人员的广泛关注。目前大多数方法虽然都可以实现去雨的目的,但在复原图像中仍存在一些缺陷,如存在雨滴残留、图像模糊或边缘伪影等。因此,如何更彻底地去除雨层信息,同时如何在去雨后保留更多的图像细节信息,是值得深入思考和探究的。基于上述分析,提出一种基于渐进残差细节补充的去雨网络,能实现去除雨层信息的同时保留更多的图像细节信息。
2.方法:
本文从去除雨层信息和保留图像细节信息的思想出发,提出一种新的端到端的渐进式去雨算法,如图1所示。
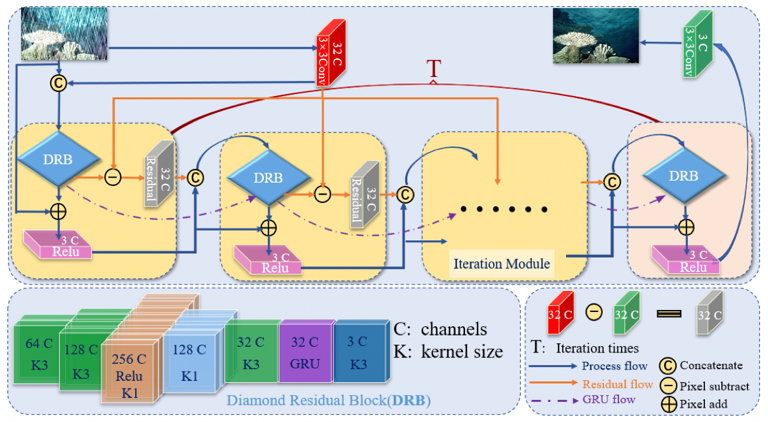
图1 提出的单幅图像去雨算法网络框架示意图
本算法采用多次迭代循环的过程对雨层信息逐步进行去除,并对细节信息由粗至细的进行重建恢复。在渐进式网络中,为了提取更加丰富的特征信息,本文设计了一个称为菱形残差块的主模块作为每一次迭代循环过程中的特征提取器。同时,为了充分利用网络中浅层的特征信息以及每次迭代过程中所学习到的丰富特征信息,提出了由两种细节补充方式构成的细节补充机制。其中一种通过传递残差信息给下一次迭代过程的方式,实现特征信息的迁移,这里的残差信息是原始特征与每次迭代过程中菱形残差块所提取特征的差值信息。另一种细节信息补充方式通过门控循环单元(GRU)来记忆选择菱形残差块所学习到的特征信息,并将记忆选择的信息传递给下一次迭代过程,实现细节信息的注入。经过T次总迭代次数后,即可实现雨层信息的去除,同时实现细节信息的保留,得到最终的去雨结果。
3.实验:
本文对公开的五个合成数据集(Rain100L、Rain100H、Rain200L、Rain200H和Rain12)和一个真实场景数据集进行实验。 其中,Rain100H 和 Rain200H数据集是大雨场景的模拟数据集,Rain100L、Rain200L和Rain12数据集是小雨场景的模拟数据集。从图2和表1可知,本文提出的方法在主观与客观指标上都较以往方法有大幅提升并且达到了最优,这有效地验证了本文方法的有效性。

图2 不同方法在合成数据集上的去雨结果
此外,本文验证了所提方法在真实场景条件下的去雨和细节重建表现,如图3所示。从图中可以看出所提方法在雨滴去除上更彻底,细节重建上也更优,表明在真实场景中也具有很好的适用性。
表1 主流去雨方法和所提方法对比结果的平均 PSNR 值和平均 SSIM 值
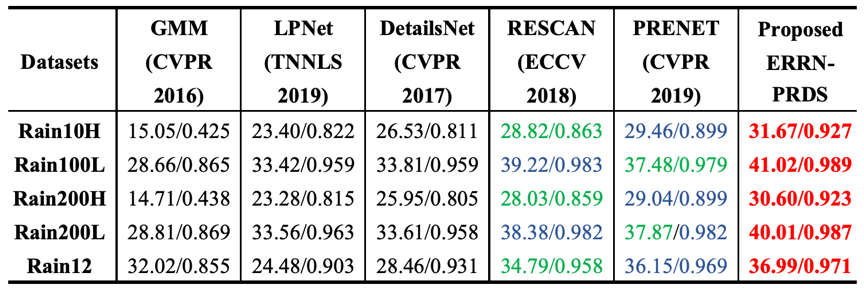

图3 不同去雨方法在真实场景雨图中的去雨结果
最后,为了验证所提算法的可拓展性,本文验证了所提方法在去噪任务上的表现,如图4所示。结果表明,对于不同的任务,本算法仍有很好的表现,具有优良的可迁移性。

图4 不同去雨方法的去噪结果
02
Employing Bilinear Fusion and Saliency Prior Information for RGB-D Salient Object Detection
基于双线性融合策略和显著先验信息指导的RGB-D图像显著目标检测算法
作者:黄年昌1,杨阳1,张鼎文2,张强1#,韩军功3#
单位:1西安电子科技大学, 2西北工业大学, 3 Computer Science Department, Aberystwyth University, SY23 3FL, UK.
邮箱:
nchuang@stu.xidian.edu.cn ,
yy18629370639@163.com,
zhangdingwen2006yyy@gmail.com,
qzhang@xidian.edu.cn,
jungonghan77@gmail.com.
论文:
https://ieeexplore.ieee.org/document/9392336/
代码:
https://github.com/nexiakele/Employing-Bilinear-Fusion-and-Saliency-Prior-Information-for-RGB-D-Salient-Object-Detection
#通讯作者
显著目标检测(Salient object detection, SOD)旨在检测出图像中最吸引注意的目标,作为重要的预处理技术之一,其在计算机视觉的诸多领域有着广泛应用。现有SOD算法主要是以单一模态 RGB图像为研究对象进行设计(RGB SOD),然而 RGB 图像仅能捕获场景的细节信息 (如颜色、纹理等),丢失了场景的三维空间信息 (如深度信息),使得在一些特殊场景下,RGB SOD算法难以准确地检测显著目标。深度图像可以捕捉场景的三维空间信息和物体间的位置关系,对 RGB图像做出补充。因此,利用深度图像和可见光图像 (RGB-D图像) 间的互补信息,能够解决现有显著性目标检测算法存在的问题,即RGB-D SOD,具有重要研究意义和应用价值。

图1 算法框图
本论文所提出的RGB-D SOD算法如图1所示,其主要对RGB-D图像显著目标检测算法的多模态信息融合策略和显著目标推理策略进行了研究。
首先,现有多模态信息融合策略以线性融合方法 (如相加和级联) 为基础进行设计,其能够较好地捕捉场景中 RGB 特征和深度特征之间的简单线性关系,难以充分挖掘 RGB-D图像中复杂的非线性关系,进而导致未能充分挖掘不同模态图像间的互补信息。为此,本算法提出了一种新的多模态特征交互模块,在现有线性融合策略的基础上,该模块引入了一种非线性融合策略(即双线性融合策略),并通过联合线性融合策略和非线性融合策略,同时挖掘了不同模态图像中存在的线性和非线性关系,更好地提取了多模态特征间的互补信息。
其次,在显著目标推理阶段,现有方法在多层级特征融合过程中通常忽略了来自低层级特征中的背景细节信息干扰,进而无法充分提取场景中上下文信息。为此,本算法提出了一种基于显著先验信息指导的特征融合模块,该模块通过引入显著先验信息来引导不同层级特征的融合过程,抑制了低层级特征中背景信息的干扰,更加充分地挖掘了场景上下文信息。最后,考虑到现有模型的显著图生成方法过于简单,难以充分利用提取到的场景上下文信息,本算法提出了一种显著信息调整和预测模块,其根据输入特征的特点,对输入特征中前景信息和背景信息进行优化调整,从而更好地利用了提取到的场景上下文信息,取得了较好的显著目标检测结果。
实验结果:如表1所示,我们在NJU2K、NLPR、STEREO 和 SIP 4个公共数据集上验证了所提出的算法,实验结果表明,所提出的算法取得了较好的检测性能。如图2所示,可视化结果进一步表明所提出算法的有效性。
表1 不同算法分别在NJU2K、NLPR、STEREO和SIP数据集上的检测结果
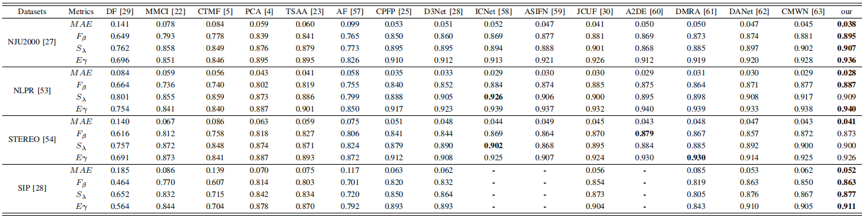

图2 所提出算法的可视化结果
03
List-wise Rank Learning for Stereoscopic Image Retargeting Quality Assessment
作者:王雪津1,邵枫1,姜求平1,柴雄力1,孟祥超1,Yo-Sung Ho2
单位:武汉大学
邮箱:
shaofeng@nbu.edu.cn
论文:
https://ieeexplore.ieee.org/document/9388879
随着立体显示技术的不断进步,各种立体显示设备逐渐进入消费市场。由于不同的立体显示设备具有各自的应用场景和市场定位,其屏幕宽高比往往也是不同的。为了让图像能够适配具有不同分辨率和宽高比的立体显示设备,并保留重要内容和3D感知信息,研究人员提出了一系列立体图像重定向(Stereoscopic Image Retargeting, SIR)技术。然而,由于图像结构和深度图的多样性,目前还没有一种通用的SIR方法能够适用于所有的立体场景。因此,亟需设计一种有效的图像质量评价(Image Quality Assessment, IQA)指标,用于选取最优SIR结果和指导SIR技术优化。

图1 NBU SIRQA图像数据库中重定向立体图像示例。SIR结果 1、2和3分别是由SSCL、VASSC [22] 以及SLWAP [23]生成的图像。括弧里的值分别是主观分值(红色)和用所提出方法预测的分值(蓝色)
虽然目前已有一些针对立体图像或图像重定向的客观质量评价方法,但这些方法并不适用于SIR,原因如下:1)立体图像质量评价通常通过综合考虑多个感知维度(如图像退化、深度感知和视觉舒适度)来评估立体图像的视觉质量。然而,与传统IQA指标中的失真不同,几何失真和信息丢失是SIR图像退化的两个主要原因。如图1所示,由于SIR结果1和结果2的几何失真严重,主观评分较低。2)与2D图像重定向相比,SIR还要考虑3D感知因素,而为2D图像重定向设计的IQA指标无法处理复杂的3D感知任务。如图1的第三行所示,虽然SIR结果2的形状和目标保持更好,但由于深度范围太大导致视觉不舒适,所以其主观评分远低于SIR结果3。因此,本文提出了一种综合考虑形状保持、目标保持和视觉舒适度的重定向立体图像质量评价方法。所提方法的框架如图2所示,主要由训练阶段和测试阶段组成。在训练阶段,首先,从几何失真、内容损失以及视觉舒适度三个维度提取重定向立体图像的感知特征。具体地,使用宽高比相似度(Aspect Ratio Similarity, ARS)和三角网格相似度(Triangular Grid Similarity, TGS)来互补地估计重定向图像的几何失真程度,并从全局和局部两个角度估计图像的内容损失,包括双向内容统计差异与显著信息保留比率。另外,考虑到重定向图像质量与3D感知质量之间的相互作用,提出新的舒适度模型用于评估3D感知质量。其次,用排序学习算法对所提取的特征进行融合,通过训练得到质量预测模型。在测试阶段,用相同的方法对测试图像提取相应的特征,然后通过质量预测模型预测得到图像的客观质量值。在实验中,本文基于NBU SIRQA和SIRD两个标准的重定向立体图像质量评价数据库,对所提出方法的性能进行测试和比较分析。实验结果证明了所提出方法比其它重定向2D/立体图像质量评价方法具有更好的评价性能。

图2 基于List-wise排序学习的重定向立体图像质量评价框图
04
Multi-Scale Sparse Graph Convolutional Network For the Assessment of Parkinsonian Gait
作者:郭睿1,邵向鑫2,张陈诚3,钱晓华1
单位:
1上海交通大学生物医学工程学院,医学图像与健康信息分析实验室,
2长春工业大学电气与电子工程学院,
3上海交通大学医学院附属瑞金医院功能神经外科
邮箱:
xiaohua.qian@sjtu.edu.cn
论文及补充材料链接:
https://ieeexplore.ieee.org/abstract/document/9385969
实验室主页:
https://mihi.sjtu.edu.cn
论文相关的研究课题介绍:
https://mihi.sjtu.edu.cn/research.html
一. 研究背景
帕金森病(PD)是一种常见的神经退行性疾病,运动障碍是帕金森病的典型临床特征。目前帕金森病运动功能评估的金标准是使用临床评分量表(即MDS-UPDRS)。然而,临床实践中医生对该量表的面对面评估方式存在两个局限性:首先,这种方式费时费力,并且医生经验水平的差异会导致评估结果存在主观性;其次,难以实现帕金森病患者移动化的家庭管理和及时的病情反馈。因此,自动、客观地进行帕金森病患者的运动功能评估已成为当前重要的研究热点。
步态运动障碍是帕金森病中常见的运动障碍症状之一,医生主要通过分析患者的步幅大小、步速、足部离地的高度、走路时足跟着地的情况、转身和摆臂等来评估。步态评估与帕金森病的严重程度密切相关,也是MDS-UPDRS中运动功能检查的重要组成部分(图1)。因此,步态运动障碍的自动量化评估对于实现帕金森病患者的运动功能评估至关重要。

图1 帕金森病患者步态评估的视频示例
二. 方法介绍
我们开发了一种多尺度稀疏化时空图卷积网络模型(图2),解决了时空细粒度动作分析的技术挑战,最终实现了帕金森病患者步态运动障碍视频的自动细粒度评估(五分类)。主要技术贡献包含以下三点:
1)提出了双流时空图卷积网络(包含关节流和骨骼流),对从视频中提取的人体骨架序列进行时空建模;
2)开发了深度监督下的多尺度时空注意力感知机制(图3),在不同尺度之间的强相关性下捕获多尺度细粒度时空特征,提升所学习特征的判别性和鲁棒性;
3)提出了一种模型驱动的稀疏化策略,实现判别性特征的选择,有效地消除特征冗余。

图2 所提出的多尺度稀疏化时空图卷积网络框架
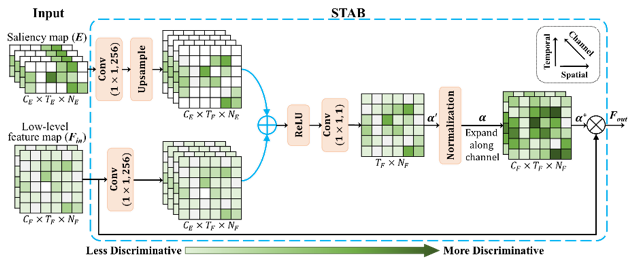
图3 时空注意力感知机制的实现
三. 实验结果
所开发的模型在上海交通大学医学院附属瑞金医院功能神经外科提供的临床视频数据集上进行了全面的评估,该数据集包含了2017-2019年搜集的142位患者的441个步态视频。据文献调查(表1),这也是目前帕金森病步态自动评估研究中最大的数据集。最终,所开发的模型在五折交叉验证中实现了65.66%的准确率和98.90%的可接受准确率,优于其他已有的帕金森病步态自动评估的方法(包括基于传感器的方法和基于视频的其他方法,如表1所示)。此外,所开发的模型还在来自42位患者的76个步态视频数据上进行了独立测试,获得了64.47%的准确率和98.68%的可接受准确率(表2),这显示了模型性能的稳定性。我们提出的非接触式方法为帕金森病患者步态视频的自动定量评估提供了一种新的潜在工具。
表1 与已有帕金森病步态自动评估研究的比较

表2 所开发模型的独立测试结果

05
Beyond Triplet Loss: Person Re-Identification With Fine-Grained Difference-Aware Pairwise Loss
作者:严程1,庞观松2,百晓1,宁欣3,谷林4,周峻5
单位:1北京航空航天大学,2阿德莱德大学,3中国科学院半导体研究所,4东京大学,5格里菲斯大学
邮箱:
beihangyc@buaa.edu.cn
pangguansong@gmail.com
baixiao@buaa.edu.cn
liuch@jxnu.edu.cn
ninxin@semi.ac.cn
lin.gu@riken.jp
jun.zhou@griffith.edu.au
论文:
https://dl.acm.org/doi/abs/10.1109/TMM.2021.3069562
引言
在行人重识别问题中,如何有效地捕捉不同行人间外观的细微差异,实现高精度的行人重识别,仍然是一项重大挑战。
尽管三元组损失在现有方法中被广泛采用并取得了良好的效果,但其在监督模型学习不同行人间的细微差异上仍具有局限性:1.如图1所示,当同一身份的两个样本具有较大的外观差异时三元组损失的值是无界的,这将导致参数的优化被这一组样本的损失所主导,存在过拟合风险;2. 在一个三元组中,若一对正样本行人的外观只有细微差异,则三元组损失的值为0,同时若一对负样本行人间只有细微差异,三元组损失的值只与样本距离线性相关,即三元组损失只对较显著的行人外观差异敏感,对捕捉行人间的细微差异仍然是不足的。
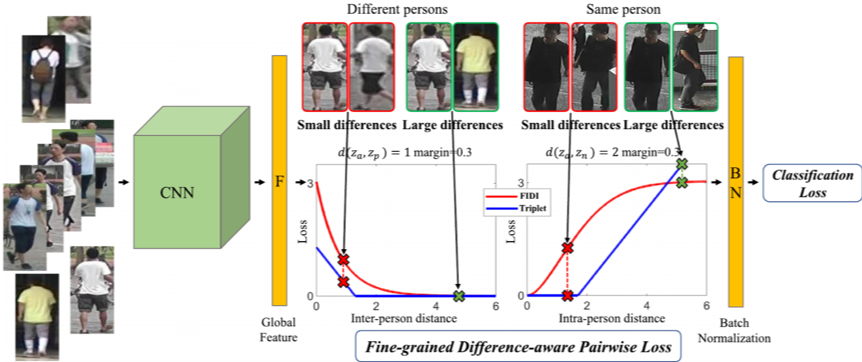
图1 三元组损失与本文方法对比
方法概述
针对上述问题,本文提出了一项FIDI损失对样本的两两距离进行约束,使模型学习到捕捉行人间细微差异的能力。
FIDI损失基于相对熵度量
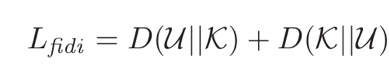
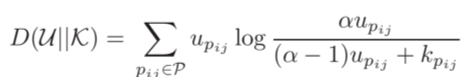
其中K与U分别为数据的真实分布与模型预测的分布。对两个样本xi与xj,若其身份相同则kpij为1,否则为0,upij则表示模型预测的两样本为同一身份的概率。为将两样本的距离映射为概率,本文采用了对数函数

其中d(·,·)为两样本特征的欧氏距离。同时,FIDI损失对较大与较小的样本差异均具有良好的有界性.
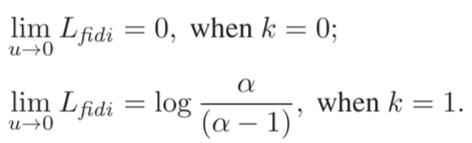
降低了对极端样本的过拟合风险。
实验验证
如表1与表2,本文提出的FIDI损失具有广泛的适用性,可以在不同的行人重识别以及车辆重识别方法中取代三元组损失,并提升模型效果。
同时,图2表明FIDI损失在训练数据较少的情况下可以取得优于三元组损失的效果,对训练数据的应用更加高效。
总结
本文主要贡献如下
1. 针对三元组损失,本文分析了其在监督模型捕捉行人外观细微差异上的局限性。
2. 针对三元组损失的不足,本文提出了对行人间的细微差异更加敏感FIDI损失,并降低了三元组损失过拟合的风险。
3. FIDI损失对数据的利用更加高效,相比于三元组损失,在训练数据较少的情况下具有更优的效果。
4. 实验结果表明FIDI可以在不同的模型中取代三元组损失,具有广泛的适用性。
表1 FDID损失在行人重识别模型中的验证效果
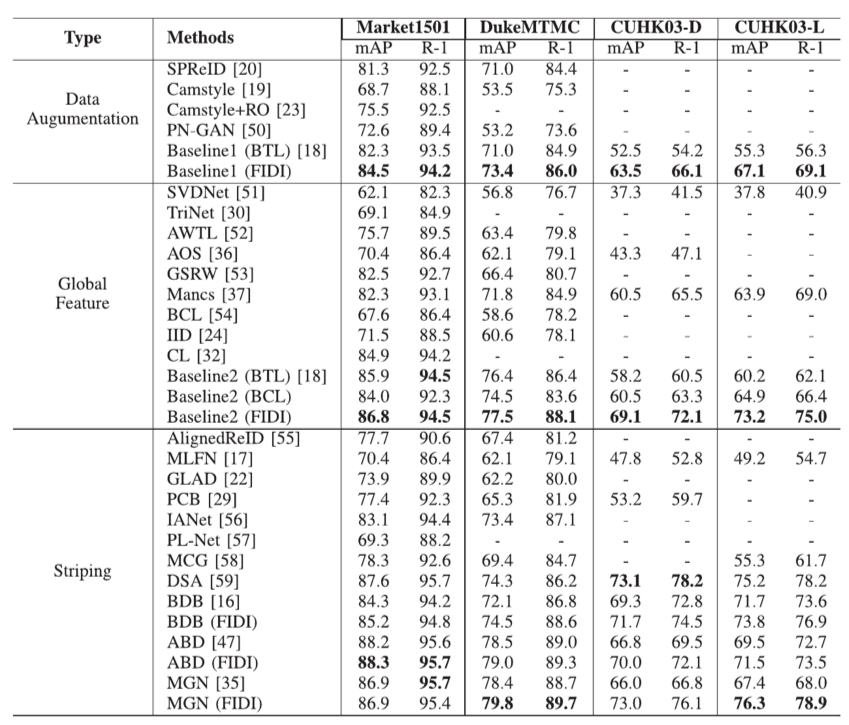
表2 FIDI损失在车辆重识别模型中的验证效果

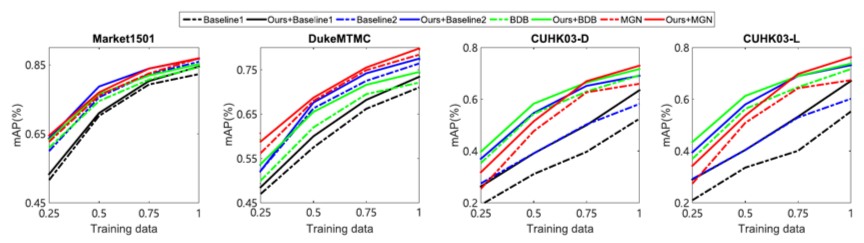
图2 FIDI损失与三元组损失在较小训练数据规模下取得的模型效果
06
Deep-IRTarget: An Automatic Target Detection in Infrared Image Using Dual-Domain Feature Extraction and Allocation
基于超复数傅立叶变换和注意力机制的红外目标检测方法
作者:张睿恒、徐立新、徐敏
单位:北京理工大学
邮箱:
ruiheng.zhang@bit.edu.cn
论文:
https://ieeexplore.ieee.org/document/9398929
引言:一直以来,红外图像目标检测领域存在着纹理信息模糊、分辨率低下、高频噪声干扰等问题,从而导致检测结果不准确。尽管现有卷积神经网络算法可以高效便捷地提取出RGB彩色图像特征,它在面对红外图像时仍然无能为力,这是红外图像自身的性质导致的。因此,本文从实现高效特征提取功能为出发点,设计出基于超复数傅里叶变换(HIFT)的频域特征提取和基于CNN的空域特征提取的双通道提取模块,引入注意力机制整合并增强上述信息。整体网络结构如图1所示:

图1 Deep-IRTarget的网络结构。我们使用的自注意力模块可以看作一种新颖的RAW,其同时在通道维度和位置维度中对特征进行整合与优化。优化后的特征图送入区域建议网络RPN中进行检测。
超复数傅立叶变换的频域特征提取:超复数傅里叶变换已经成功应用RG可见光图像的处理中,本文受其启发,成功将其运用于处理红外图像上。图2展示了其过程。输入一张单通道的红外灰度图像,根据重新定义的红外特征矩阵,形成红外图像的超复数表示形式。在经过超复数傅里叶变换后,通过一系列高斯核来创建频谱尺度空间,根据幅度和相位谱的计算,由傅里叶逆变换得到了不同高斯核值下的一组红外显著性特征图。最后,把这一系列的红外显著性特征图送入一个卷积层,得到最后的频域特征。
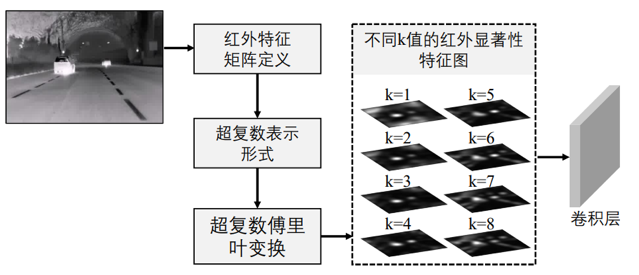
图2 基于超复数傅立叶变换的红外目标显著性特征模型的流程图
实验结果:本文分别在MWIR数据集(美国陆军夜视和电子传感器局),BITIR数据集(北京理工大学武器与总体设计实验室穆城坡团队),WCIR数据集(悉尼科技大学全球大数据实验室)上验证了网络性能,并开展了消融实验。表1(下)显示了在MWIR数据集上,我们的方法要优于传统的红外目标检测方法,表2(上)显示的对比实验结果表明我们的双通道特征提取、自注意力模块均可有效提高检测性能。
表1 在MWIR数据集上的平均精度与消融对比实验结果


07
Zwei: A Self-Play Reinforcement Learning Framework for Video Transmission Services
基于自我强化学习的视频传输框架
作者:黄天驰,张睿霄,孙立峰
单位:清华大学计算机科学与技术系
邮箱:
htc19@mails.tsinghua.edu.cn,
zhangrx17@mails.tsinghua.edu.cn,
sunlf@tsinghua.edu.cn
论文:
https://ieeexplore.ieee.org/document/9371417
代码:
https://github.com/thu-media/zwei
视频传输任务通常采用自适应传输算法来保证用户的需求。现有方案通常通过线性组合加权多个指标(例如码率,卡顿率,码率切换等)后对该评价函数完成策略优化。然而,本文发现给定的评价函数通常无法准确描述实际的需求,从而可能生成与实际需求相悖的自适应传输策略。本文提出了Zwei,一个结合博弈论与深度强化学习的视频传输算法生成框架。Zwei将优化奖励函数任务转化为“输赢任务”,即在同一个环境下执行多次采样,并且根据实际需求对策略排名,得出胜率,最后利用深度强化学习提升胜率。
方案介绍
Zwei的总体系统流程图如下所示,主要包括四个模块。
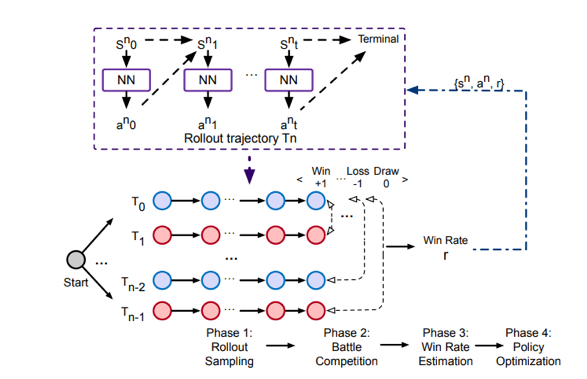
图:Zwei系统流程图
1)蒙特卡洛采样模块,即随机生成一个网络环境后,在该环境下根据策略的概率多次执行,并记录每次执行的轨迹(trajectory)
2)对战比赛模块,即根据真实的需求(例如:在不卡顿的情况下提升视频码率)依次两两判断轨迹的胜负:哪一个轨迹更符合需求。
3)胜率估计模块,即根据胜负的结果为每条轨迹估算胜率。
4)策略优化模块:即以胜率为奖励目标提升策略,这里使用on-policy强化学习算法Dual-PPO。
测试评估
文章评估了Zwei对各种边缘资源传输与传输任务的不同要求,包括自适应码率控制算法、直播流调度和实时通信算法。结果表明,Zwei能够根据各种指定的需求自我强化学习,在所有考虑的场景下都优于最先进的方法。其中在码率自适应场景中,与之前方案相比,Zwei训练的码率自适应算法的QoE分数提升32.24% - 36.38%。在直播视频分发调度场景中,与最优的强化学习算法LTS相比,Zwei生成的调度策略在降低6.5%卡顿率同时进一步减少22%的成本。

面向不同需求的ABR算法性能比较
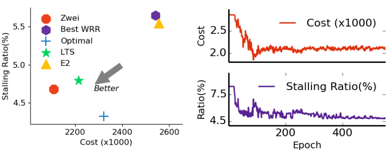
个性化需求的CDN调度算法性能

个性化需求的RTC码率控制算法性能

 京公网安备11010802017125号
京公网安备11010802017125号