
2023年论文导读第三期
论文导读】2023年论文导读第三期
CCF多媒体专委会 2023-02-14 09:00 发表于吉林


论文导读
2023年论文导读第三期(总第六十九期)
目 录
|
1 |
Structured Attention Network for Referring Image Segmentation |
|
2 |
The Model May Fit You: User-Generalized Cross-Modal Retrieval |
|
3 |
Graph-Based Visual-Semantic Entanglement Network for Zero-Shot Image Recognition |
|
4 |
Gated SwitchGAN for multi-domain facial image translation |
|
5 |
Disentangling Semantic-to-Visual Confusion for Zero-Shot Learning |
|
6 |
Spatial-Temporal Graphs for Cross-Modal Text2Video Retrieval |
01
Structured Attention Network for Referring Image Segmentation
作者:林倞,颜鹏翔,许晓倩,杨思蓓,曾坤,李冠彬
单位:中山大学
邮箱:
linliang@ieee.org
liguanbin@mail.sysu.edu.cn
论文:
https://ieeexplore.ieee.org/document/9408401
1.引言
Referring Image Segmentation(基于指代描述的物体分割)旨在分割出自然语言表达式所指的物体或内容区域,这项任务的挑战在于需要同时理解视觉和语言并实现跨模态的精细语义对齐。考虑到指代表达式的语言结构可以为视觉和语言概念的推理提供直观及可解释的布局,本文提出结构化注意力网络(SANet),以探索其在解析的指代表达式依赖树上实现有效的多模态推理。具体而言,SANet使用多模态树结构循环感知模块(AMTreeGRU),以自下而上的方式实现多模态推理。为了改善分割的图像细节,SANet使用注意力跳跃连接模块将语义引导的低级特征进一步并入高级特征。本文方法在四个基准数据集上得到了更具解释性的可视化跨模态注意力分布图,验证了SANet的有效性。
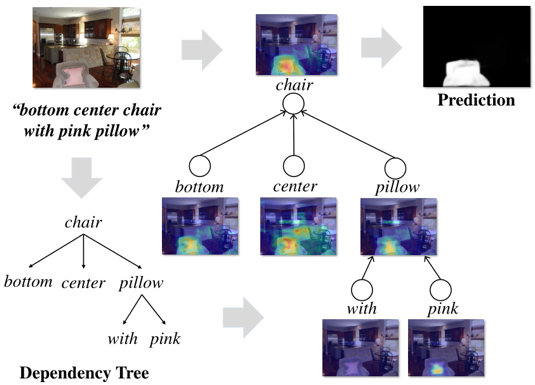
图1 基于指代表达式的解析依赖树实现跨模态推理
2. 研究方法
结构化注意力网络(SANet)的总体框架如图2所示,SANet分别从视觉主干网络和语言模型中提取视觉和语言特征。为了更好地对齐视觉和语言域的特征,SANet通过设计的多模态树结构循环感知模块(AMTreeGRU)在视觉和语言特征之间执行自下而上的协同推理。此外,为进一步改善分割区域的空间细节,我们提出了注意力跳跃连接(ASC)模块,通过跨模态注意力(CMA)模块实现图像特征的提取。具体而言,CMA模块根据不同模态的特征图G对输入特征图F进行加权,并输出引导注意力图和软加权特征图,计算公式为
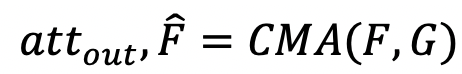
如图2所示,SANet分别从CNN和LSTM中提取多层次视觉和语言特征,然后将这两个特征输入多模态树结构循环感知模块(AMTreeGRU),进而从指代表达式解析依赖树上执行跨模态推理。AMTreeGRU输出的特征会进一步与语言特征结合并作为ASPP(Atrous Spatial Pyramid Pooling)模块的输入,通过多尺度学习来提升多模态融合特征的分辨率。最后,我们将多模态特征作为高层次的引导信息,通过注意力跳跃连接(ASC)模块与低级视觉特征相连接,将ASC模块的生成结果输入到解码器,生成最后的分割结果。
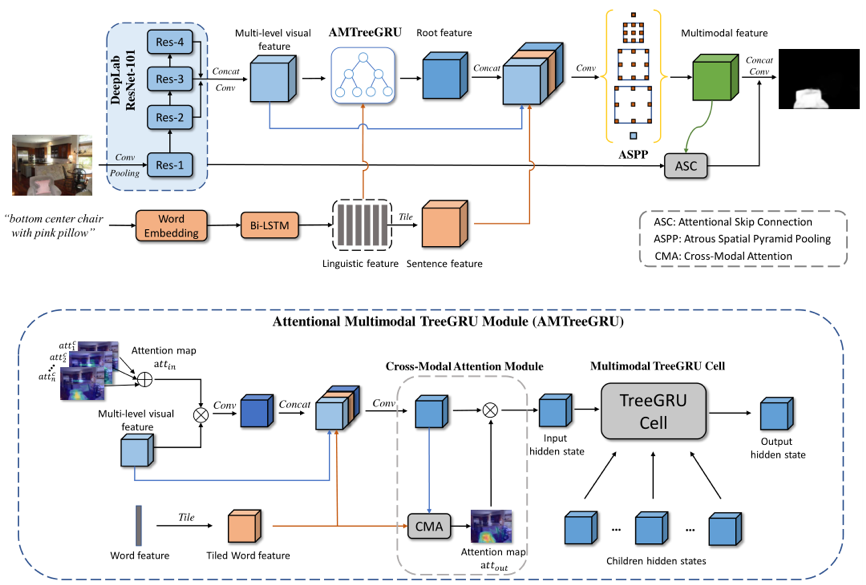
图2 基于结构化注意力网络(SANet)的指代表达式图像分割总体框架
3. 实验结果
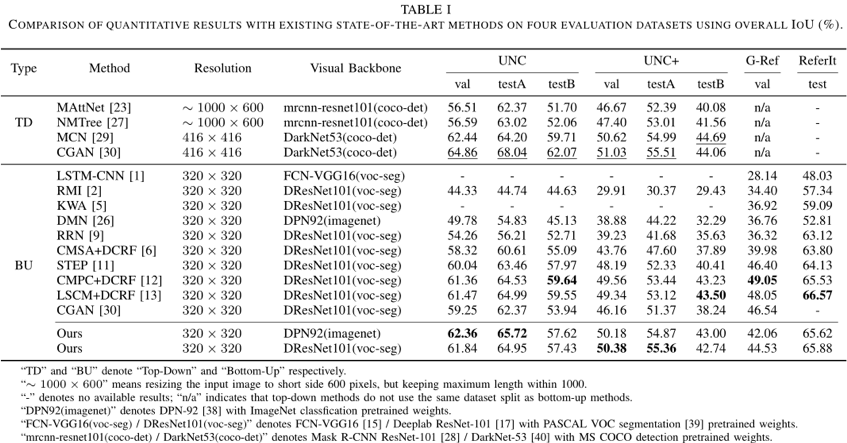
我们在UNC,UNC+、G-Ref和ReferIt四个数据集上验证了SANet的有效性。从表1可以看出,本文提出的SANet可以通过挖掘自然语言所隐含的结构信息有效地在图像和语言间实现跨模态的推理及语义对齐。
表1 本文提出的方法在四个数据集上与当前最佳方法的整体IoU比较(%)
我们在UNC+验证集上进行了消融实验,以验证提出的AMTreeGRU模块和ASC模块的有效性。表2总结了消融结果的prec@X以及总体IoU性能。通过替换SANet完整模型中的视觉主干(表2中的第12行),我们评估了不同视觉骨干网络的性能。表3总结了不同视觉骨干的prec@X以及总体IoU。
表2 本文方法在UNC+验证集上的消融结果
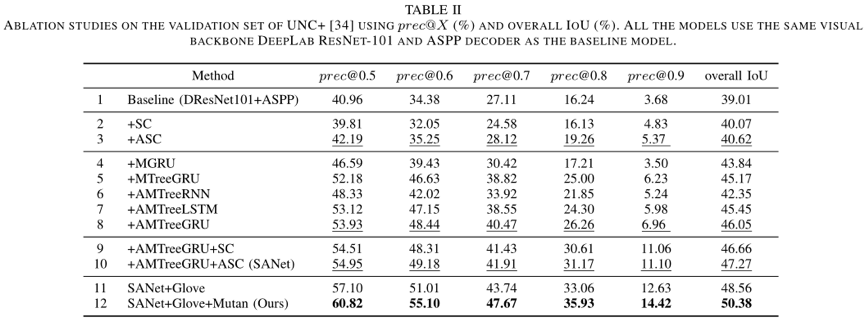
表3 不同视觉骨干在UNC+验证集上的结果
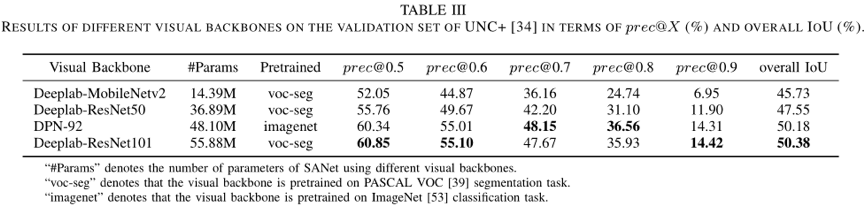
从上述表格可以看出,本文提出的SANet在四个基准数据集上得到了超越已有方法的最佳性能,大量的消融实验也证明了模型的有效性。
02
The Model May Fit You: User-Generalized Cross-Modal Retrieval
用户泛化的跨模态检索
作者:马昕宏1,2,3,杨小汕1,2,3,高君宇1,2,徐常胜1,2,3#
单位:1中国科学院自动化研究所, 2中国科学院大学, 3鹏城实验室
邮箱:
xinhong.ma@nlpr.ia.ac.cn,
xiaoshan.yang@nlpr.ia.ac.cn
gaojunyu2015@ia.ac.cn,
csxu@nlpr.ia.ac.cn
论文:
https://ieeexplore.ieee.org/abstract/document/9465686/
#通讯作者
随着各类社交媒体平台用户和多媒体数据(图像,文本和视频等数据)的快速增长,跨模态检索技术已经成为互联网搜索系统中最为重要的技术之一。互联网用户由于文化背景,民族,性格和情绪等方面的不同,导致不同的用户数据之间存在显著的数据分布差异。本文定义同一用户的数据为一个用户域,不同用户域的数据分布差异定义为用户域差异。由于跨模态检索任务涉及多模态数据,故用户域差异也具备多模态的特性。如果目标用户领域(需要检索服务的目标用户)显著不同于源用户域(检索模型的训练数据),用户域差异会显著降低模型的检索准确率。目前,大多数的检索方法在设计过程中没有考虑用户域差异的问题。
与用户泛化跨模态检索任务最相关的任务便是视觉领域泛化问题。该任务要求在多个源域上训练模型,在数据分布显著不同于源域的目标域中进行测试。目前大多数领域泛化方法只能够解决单模态(如:图像)的领域差异,而用户泛化跨模态检索任务需要同时应对多模态数据的模态差异和未知用户领域的泛化问题。
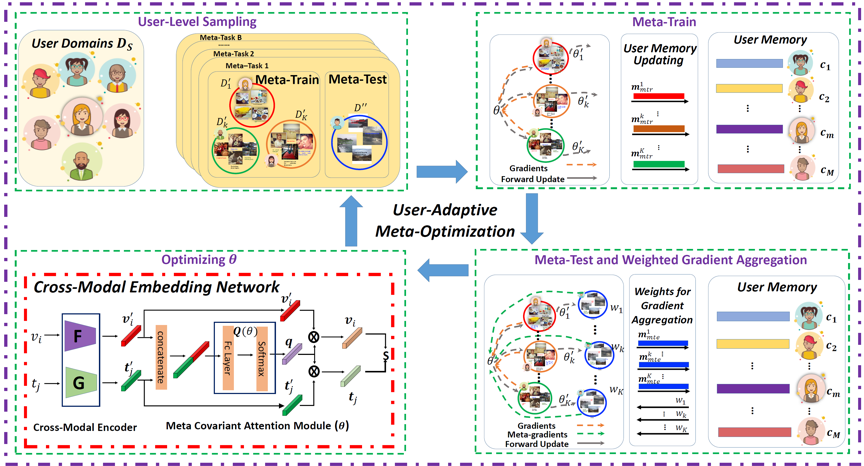
图1 模型框架图
为了解决上述挑战,本文提出了多模态用户泛化元学习(Meta-Learning Multimodal User Generalization, MLMUG)方法。如图所示,本方法利用元学习来模拟用户域差异,使得多模态数据可以高效编码特征并促使模型泛化到任何未知的用户领域。具体地,MLMUG首先设计了跨模态映射网络。该网络包含一个可学习的元协变注意力模块来产生模态共享的掩膜,从而对多模态特征进行选择。为了在特征选择过程中编码不同用户可迁移的知识并改善模型对未知用户领域的泛化性,MLMUG还设计了用户自适应元优化方法。该优化方法包含四个学习阶段:用户级别采样,元训练,元测试和加权梯度聚合阶段。用户级别采样阶段将所有可训练的用户领域划分为元训练/元测试用户域,从而模拟用户领域差异。元训练阶段计算元训练用户域的梯度。元测试阶段计算元测试用户域的元梯度信息。最后,在加权梯度聚合阶段,模型依据训练用户域和元测试用户域的分布差异来自适应聚合梯度和元梯度,更新元协变注意力模块的参数。与传统的元学习相比,本文提出的模型不需要进一步更新参数便可以直接泛化到未知用户领域。更重要的是,本文提出的模型灵活易扩展,可以很方便地嵌入到现有的跨模态检索方法中来改善模型的泛化性。
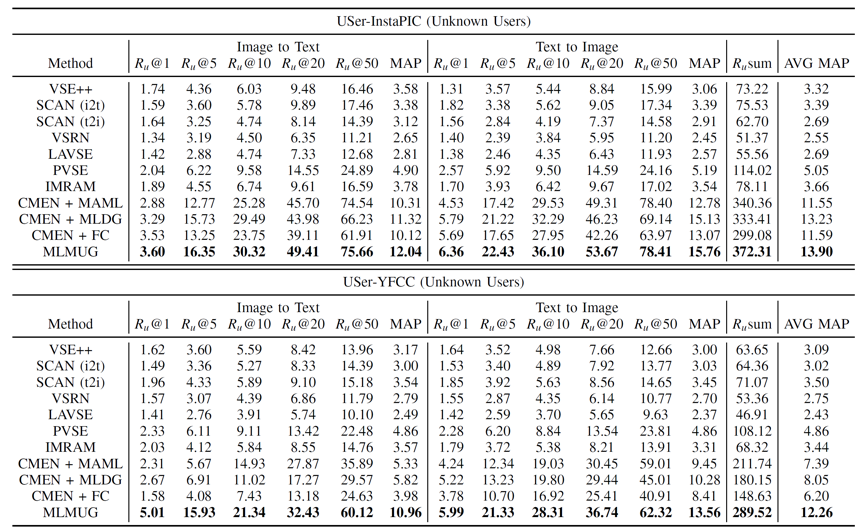
为了合理评测用户泛化跨模态检索任务,构建了两个数据集。大量实验验证了模型的有效性和优越性。
表1 未知用户上的跨模态检索精度对比
03
Graph-Based Visual-Semantic Entanglement Network for Zero-Shot Image Recognition
作者:胡杨1,2,文贵华1*,安德瑞安.查普曼2,杨沛1,骆明楠1,徐映雪1,戴丹1,3,温迪.赫尔2
单位:
1华南理工大学,中国
2南安普顿大学,英国
3林肯大学,英国
邮箱:
superhy199148@hotmail.com,
yang.hu@soton.ac.uk,
yang.hu@ndm.ox.ac.uk
crghwen@scut.edu.cn
yangpei@scut.edu.cn
daidanjune@hotmail.com
wh@ecs.soton.ac.uk
论文:
https://ieeexplore.ieee.org/abstract/document/9437712
*通讯作者
1. 摘要
零次学习(ZSL)使用语义属性空间连接未见类别对象的搜索空间。近年来,虽然深度卷积网络为ZSL任务带来了强大的视觉建模能力,但其视觉特征具有严重的模式惯性,缺乏语义关系的表示,导致严重的偏差和歧义。针对这一问题,我们提出了基于图的视觉-语义纠缠网络(Graph -based Visual - Semantic Entanglement Network,GVSE)对视觉特征进行图建模,并利用知识图谱将视觉特征映射到对应的语义属性上。它有如下新颖的设计:1. 利用卷积神经网络(CNN)和图卷积网络(GCN)建立多路径纠缠的网络,将卷积神经网络中的视觉特征输入到GCN中建模隐式语义关系,GCN将图建模信息反馈到CNN特征; 2. 以属性词向量为目标对GCN进行图语义建模,为图建模形成自洽的回归并监督GCN学习更多个性化的属性关系; 3.它将图建模细粒度的分层视觉语义特征融合补充为新的视觉嵌入。我们的方法通过促进视觉特征的语义链接建模,在多个代表性的ZSL数据集上(如AwA2, CUB和SUN)优于最先进的方法。
2. 方法理论动机
在ZSL任务中,输入图像记为, 基于CNN的视觉嵌入函数为θ(·)。除此之外,语义嵌入ψ(y)表示类别y的属性分布向量。我们有F(x,y,Wψ)=Fψ(θ(x),Wψ)φ(y)是分类得分的计算函数。视觉嵌入和语义嵌入之间的唯一连接是视觉-语义桥接Fψ(·,Wψ),它通常由几个全连接层(FC)构建。面对具有强大的模式惯性的视觉嵌入θ(·),Fψ(·,Wψ)承担了过大的建模压力,从而产生难以逆转的预测偏差。
为了解决典型的视觉特征缺乏对属性内部关系的理解这样一个挑战,我们必须利用属性间存在连接的知识关联来补全隐式语义关系的映射、建模和融合。
3. 研究方法
为了实现ZSL的视觉-语义纠缠特征建模的目标,我们采取了以下的步骤:
1. 语义知识图的构建:为GCN的执行构建语义知识图。知识图提取属性的共现关系。
2. 建立“视觉-语义”双通道的网络结构:建立一个职责明确的双通道网络结构,其中CNN负责常规图像视觉建模,GCN负责视觉特征语义关系的图形建模。
3. 设计CNN与GCN的纠缠策略:建立CNN视觉建模与GCN语义建模之间的交互函数。GCN从CNN接收视觉特征作为输入,CNN则获取GCN反馈来的语义信息,作为辅助进一步优化视觉特征。
4. 图语义编码和可视化表示的融合:为了进一步加强ZSL桥接之前的特征表示,我们将来自GCN块的语义图建模特征合并到最终的可视化嵌入中。
提出方法的主要框架如图-1所示:
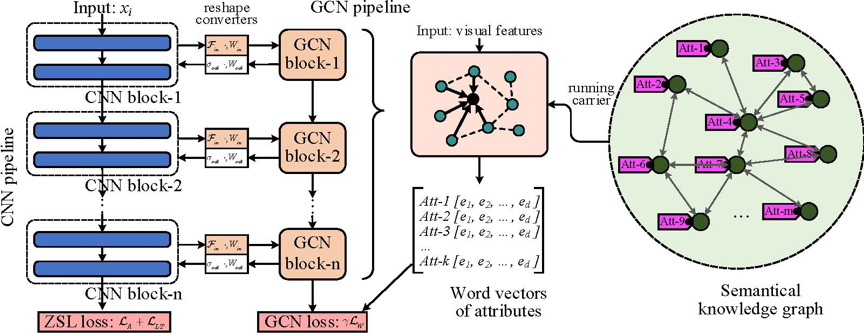
图1 GVSE框架示意图
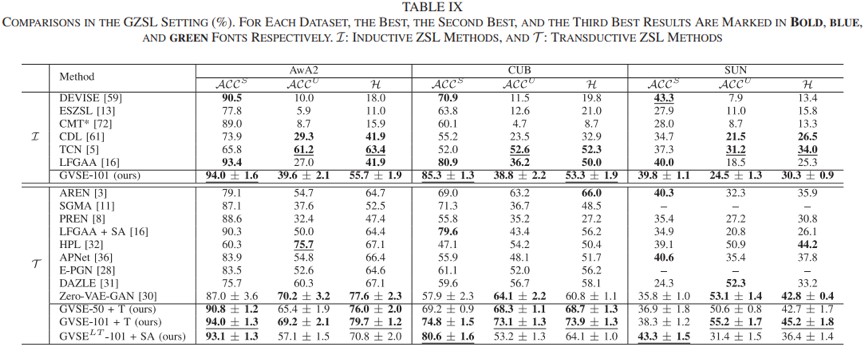
4. 实验结果
实验从狭义的ZSL(测试集不包含可见类别)和广义的ZSL(测试集把包含可见类别,会对不可见类别形成干扰)两种设定的场景下进行,均表现出了由于大多数对比方法的优异性能。

一些可视化的结果也体现了提出的方法能够捕获更全面的“视觉-语义”特征,对于干扰项类别具有更好的区别能力,如图-2所示:
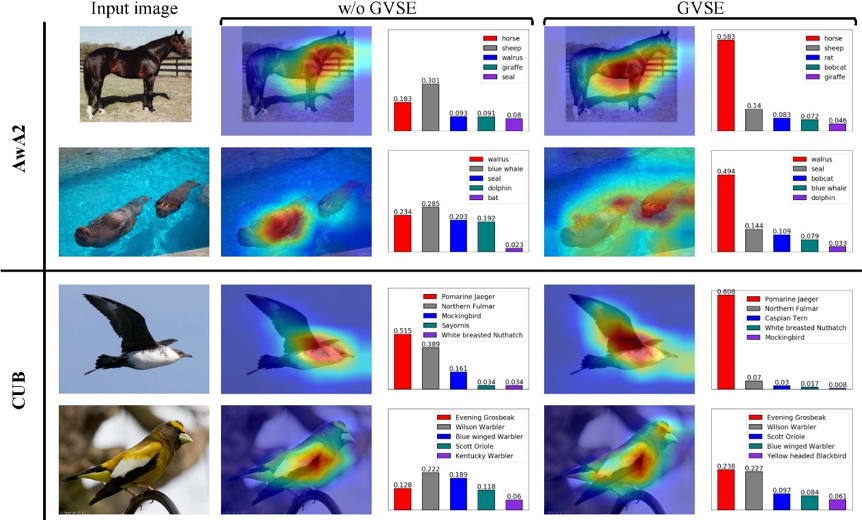
图2 图像注意力热图及分类抗干扰能力示意图
04
Gated SwitchGAN for multi-domain facial image translation
作者:张小康,朱渊略,陈文婷,刘文双,沈琳琳*
单位:深圳大学
邮箱:
zhangxiaokang2019@email.szu.edu.cn
zhuyuanlue2017@email.szu.edu.cn
chenwenting2017@email.szu.edu.cn
liuwenshuang2018@email.szu.edu.cn
llshen@szu.edu.cn
论文:
https://ieeexplore.ieee.org/document/9410376
*通讯作者
引言
图像翻译任务是将图像转换成一个或多个特定域的任务。最近关于多域人脸图像翻译的研究取得了令人印象深刻的成果。现有的方法通常提供具有辅助分类器的判别器来实行域转换,并通过轻微的图像操作达到收敛。然而这些方法忽略了基于域分布匹配的重要信息,使得合成图像缺乏了真实感。为了解决这个问题,本文提出了具有属性对抗开关的自适应判别器结构和带属性编码开关的生成器结构,以在多个域之间执行精细的图像翻译。
方法概述
首先,本文提出了一种新颖的人脸翻译框架SwitchGAN(如图1所示),其利用带有属性编码器开关的生成器和带有属性对抗开关的判别器来实现多域人脸图像翻译。特征开关操作被提出以实现特征选择和融合。在SwitchGAN中,标签向量被用作开关来决定生成器和判别器中所需的属性特征。
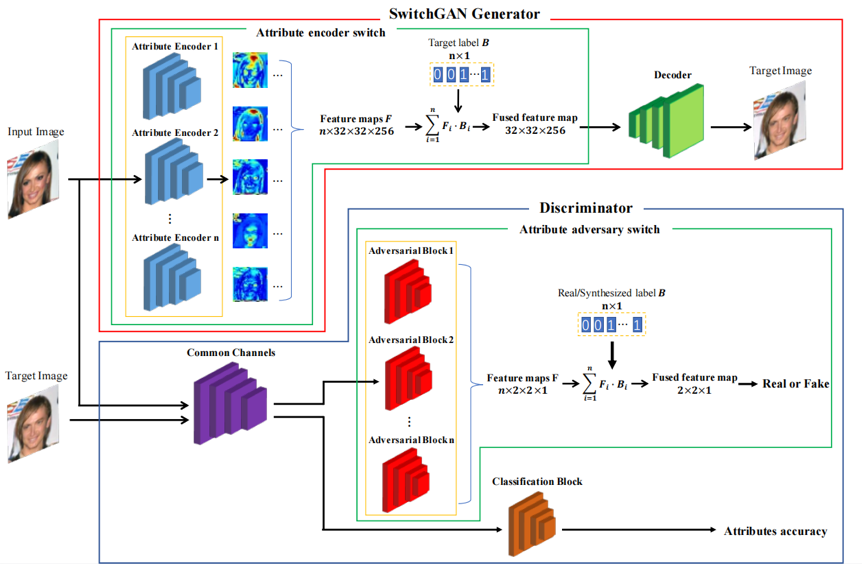
图1 SwitchGAN网络结构
基于SwitchGAN,本文还提出了门模块(Gate Module)来控制属性转换的强度。Gated SwitchGAN(如图2所示)作为上述工作的扩展,进一步提高SwitchGAN模型的性能。不同于SwitchGAN中,标签向量仅用作开关来决定期望的属性特征,Gated SwitchGAN还使用属性编码器开关作为翻译期间属性强度的门控。由于只有与非零标签相对应的属性编码器通过属性编码器开关,因此门模块中的共享编码器被间接地强制编码内容信息和所有属性的中间状态(内容特征),该内容特征保留了输入图像的基本语义内容。当我们对开关施加不同的值时(如0.5或1),生成器的输出可以显示不同的属性转换强度,同时保留内容信息。
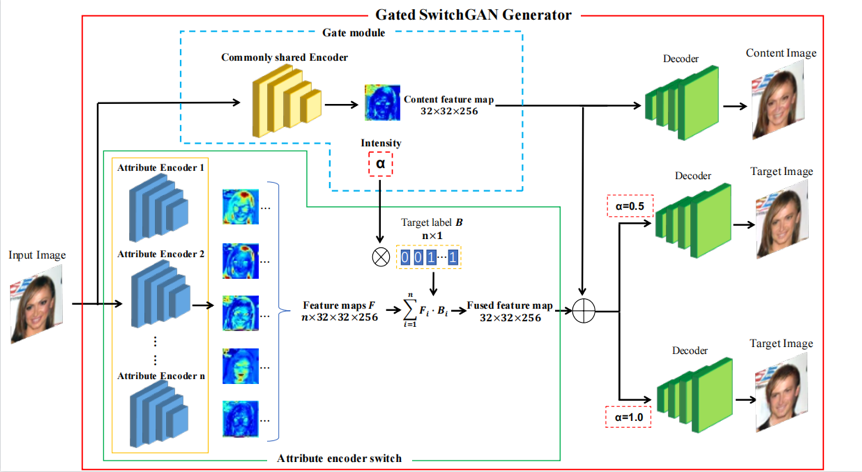
图2 Gated SwitchGAN网络结构
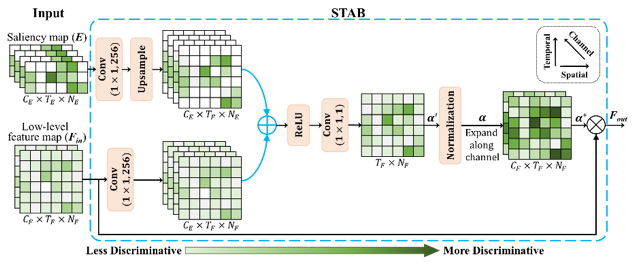
图3 时空注意力感知机制的实现
实验
本文对所提出的SwitchGAN和Gated SwitchGAN在不同任务中的表现进行了定性和定量的评估,如年龄控制、面部表情翻译和面部属性翻译等任务,分别对应于Morph、RaFD和CelebA三种数据集。如表1和表2所示,定量的评估验证了本文提出方法在图像质量和翻译精确性都要优于baseline。
表1 本文提出方法与baseline在年龄控制和表情翻译任务的对比
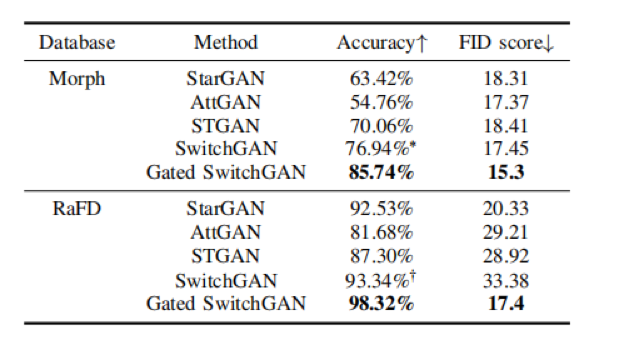
表2 本文提出方法与baseline在面部属性翻译任务的对比

本文还对不同方法的实验结果进行了可视化,如图3、4、5所示,可以发现,本文提出的SwitchGAN和Gated SwitchGAN均取得了比baseline更好的翻译质量。

图3 本文提出方法与baseline在年龄控制的定性实验对比

图4 本文提出方法与baseline在表情翻译任务的定性实验对比
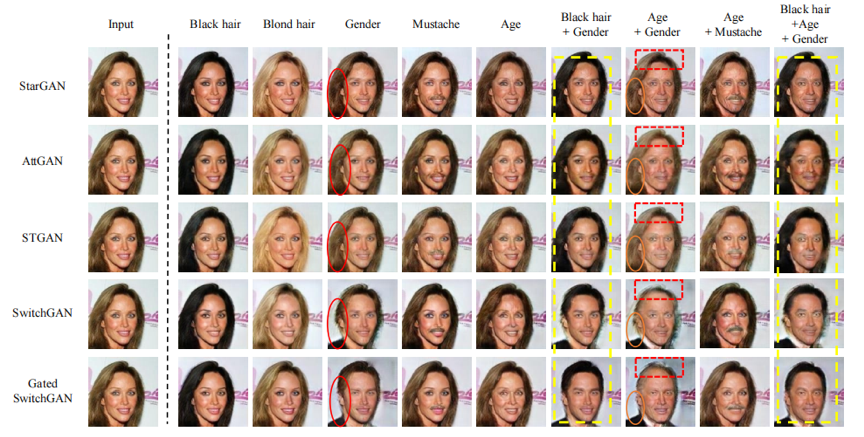
图5 本文提出方法与baseline在面部属性翻译的定性实验对比
05
Disentangling Semantic-to-Visual Confusion for Zero-Shot Learning
作者:叶子寒1,胡伏原2#,吕凡3,李玲燕4,黄开竹5#
单位:1西交利物浦大学,2苏州科技大学,3天津大学,4苏州经贸技师学院,5昆山杜克大学
邮箱:
Zihan.Ye22@student.xjtlu.edu.cn
fuyuanhu@mail.usts.edu.cn
fanlyu@tju.edu.cn
kaizhu.huang@dukekunshan.edu.cn
论文:
https://arxiv.org/abs/2106.08605;
https://ieeexplore.ieee.org/abstract/document/9454302
代码:
https://github.com/FouriYe/DCRGAN-TMM
#通讯作者
引言
使用生成模型从语义分布中合成视觉特征是近年来最流行的零样本图像分类解决方案之一。三元组损失 (Triplet Loss, TL) 广泛用于通过自动搜索判别性表示来从语义生成逼真的视觉分布。
![]()
然而,由于零样本学习中不可使用未见类别图像,传统的 TL 无法搜索可靠的未见类别的解耦表示。为了减轻这个缺点,我们在这项工作中提出了一种多模态三元组损失(Multi-Modal TL, MMTL),它利用多模态信息来搜索解耦的表示空间。
因此,所有类都可以相互作用,这有利于在搜索空间中学习解耦的类别表示。
![]()
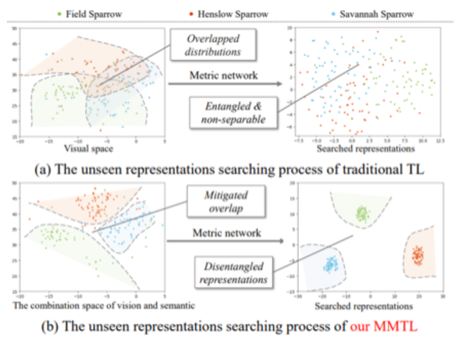
图1 传统TL与我们的MMTL 在 CUB 的三个未见鸟类类别上的比较。
由于重叠的未见类别的视觉分布,传统 TL 的搜索表示过于纠缠。 然而,MMTL 通过结合视觉和语义特征来减轻未见类别视觉特征的重叠问题,并因此搜索解耦的未见类别表示。此外,我们开发了一种称为解耦表示生成对抗网络 (DCR-GAN) 的新模型,专注于从模型训练、特征合成和最终识别三个阶段彻底利用解耦表示。

图2. DCR-GAN 训练过程的详细说明。 G 和 D 分别代表GAN 的生成器/鉴别器。 SRN 将语义空间投射到搜索到的表示空间。 F1 和 F2 是两个回归网络,分别将伪造视觉特征 G([a, R(a), z]) 投射到原始语义空间和搜索到的表示空间以实现类间多样性。
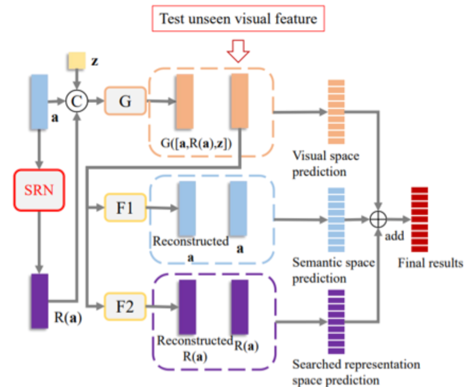
图3 零样本分类阶段
我们使用训练好的生成器进行未见类别视觉特征合成。然后,合成的特征用于训练 softmax 分类器。 类似地,训练语义分类器和搜索表示分类器。 我们还使用 F1 和 F2 将所有真实的看不见的视觉特征分别映射到语义空间和搜索表示空间。 我们整合了来自视觉、语义和搜索表示空间的最终结果。受益于解耦表示,DCR-GAN 可以在可见和未见特征上拟合更真实的分布。

图4. 合成视觉特征的可视化。 ·表示真实特征,×表示合成特征。 不同的颜色和数字表示不同的类别。
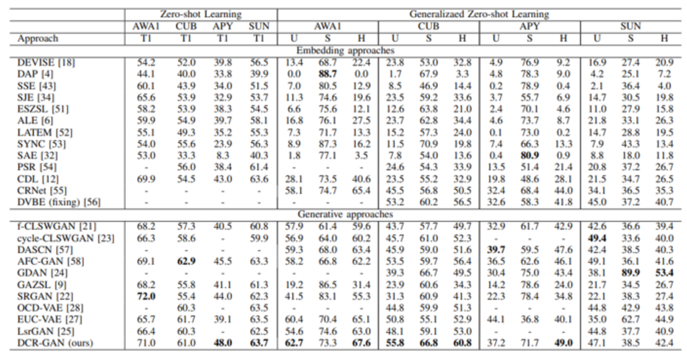
大量实验表明,我们提出的模型可以在四个基准数据集上产生优于最先进技术的性能。
表1 在四个数据集上与最先进的零样本分类方法进行比较
06
Spatial-Temporal Graphs for Cross-Modal Text2Video Retrieval
基于时空图的跨模态文本到视频检索
作者:宋雪、陈静静、吴祖煊、姜育刚*
单位:复旦大学
邮箱:
xsong18@fudan.edu.cn
chenjingjing@fudan.edu.cn
zxwu@fudan.edu.cn
ygj@fudan.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/9463746
*通讯作者
引言:
跨模态视频-文本检索任务的基本框架是为视频和文本学习一个共同特征空间。一般情况下,建模视频内容时,往往使用帧层级的特征,然后再映射到共同空间中,但是帧层级特征只能表示粗粒度的视频信息,研究如何对视频中的细粒度语义关系进行建模,有助于提高检索性能。本文从文本分析出发,鉴于文本中主要包含名词和动词,分别表示物体及其关系,所以需要对视频内容进行相似的建模。基于此,本文提出了将视频表示为时空图,其中,空间图建模单帧中物体间的交互,时序图通过跟踪物体在帧间的变化,捕捉交互关系在时序上的连贯性,并且提出了一个基于视频时空图的跨模态视频-文本检索框架,通过实验验证了在跨模态检索任务中引入视频细粒度物体关系建模的重要性。
方法概述:
本文所提基于视频时空图的跨模态视频-文本检索框架如图1所示,该框架分为三个模块,分别是文本编码、视频编码和共同空间学习。文本编码模块先用BERT自带的分词器拆分单词,然后使用BERT对单词序列进行动态编码,从而得到句子表征。视频编码模块先对视频帧进行物体检测,然后构建时空图。其中,对于空间图,根据场景图解析器的检测结果,建立帧中物体间的交互关系;对于时序图,根据相邻帧间物体视觉表征的相似度来追踪同一物体的变化。接着使用图卷积网络对时空图进行编码,学习能够捕捉语义概念(物体)及其交互关系的细粒度物体级别特征,并与ResNet-152提取的粗粒度帧级别特征拼接后作为视频特征。共同空间学习模块则把句子表征和视频特征映射到同一空间中为视频和文本建立关联关系,从而实现跨模态匹配。
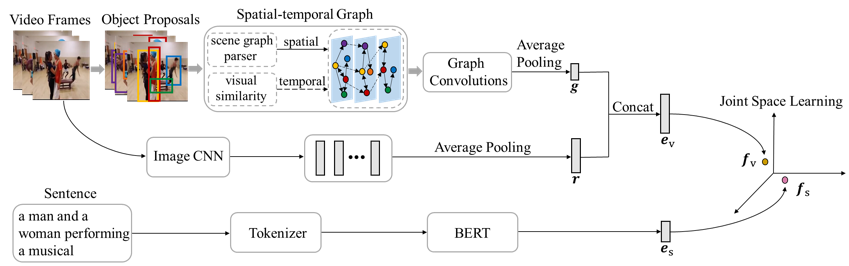
图1 基于视频时空图的跨模态视频-文本检索框架
实验结果:
本文实验采用的数据集是MSR-VTT和LSMDC。评价整体性能时,采用的指标是召回率之和(SoR)与中位数等级(MedR),而且MedR越小、SoR越大说明检索性能越好。为了验证时空图在跨模态检索中的有效性,本文先对所提框架进行了消融实验。表1和表2分别列出了空间图、时序图以及它们的组合—时空图在两个数据集上的性能提升,可以看出,建模视频中物体之间的空间图或时序图都有助于提高跨模态检索的性能,而且联合建模空间图和时序图为时空图可以更好地实现跨模态匹配。此外,为了验证模型性能的提升来源于时空图捕捉细粒度物体交互关系的能力,而不是引入了相当于物体层级的时空图特征,本文的另一个对比实验把时空图特征替换成了物体特征。实验结果如图2所示,所提框架在MedR和SoR评价指标上的性能都优于前述对比实验,说明了本文所提框架中时空图编码特征比单一物体特征蕴含更多的信息,也充分证明了在跨模态视频-文本检索中为视频内容建模引入细粒度物体交互信息的重要性。
表1 MSR-VTT数据集的消融实验

表2 LSMDC数据集的消融实验


图2 时空图特征和物体特征的性能比较

 京公网安备11010802017125号
京公网安备11010802017125号