
2023年论文导读第四期
【论文导读】2023年论文导读第四期
CCF多媒体专委会 2023-02-28 13:27 发表于北京


论文导读
2023年论文导读第四期(总第七十期)
目 录
|
1 |
SRDRL: A Blind Super-Resolution Framework with Degradation Reconstruction Loss |
|
2 |
Real-Time and Accurate UAV Pedestrian Detection for Social Distancing Monitoring in COVID-19 Pandemic |
|
3 |
Image Difference Captioning with Instance-Level Fine-Grained Feature Representation |
|
4 |
Multiple Instance Detection Networks With Adaptive Instance Refinement |
|
5 |
Discover Micro-Influencers for Brands via Better Understanding |
|
6 |
SPGNet: Serial and Parallel Group Network |
01
SRDRL: A Blind Super-Resolution Framework with Degradation Reconstruction Loss
SRDRL:基于退化重建损失的盲超分辨率框架
作者:何宗耀1,金枝*1,赵耀2
单位:1中山大学,2北京交通大学
邮箱:
hezy28@mail2.sysu.edu.cn,
jinzh26@mail.sysu.edu.cn,
yzhao@bjtu.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/9459506
代码:
https://github.com/FVL2020/SRDRL
* 通讯作者
1 研究背景
单幅图像超分辨率是指从一张低分辨率图像中重建出对应的高质量的高分辨率图像的过程,其在医学影像、监控设备、卫星图像等许多领域都具有广泛的应用场景与价值。最近几年以来,基于深度学习的单幅图像超分辨率方法已经取得了显著的成功。然而,大多数单幅图像超分辨率方法都假设低分辨率图像从高分辨率图像中经过简单的双三次(bicubic)下采样得到的。一旦实际的退化不是bicubic下采样,这些方法的出色性能表现就很难保持。现实世界图像的退化过程可以通过下采样、模糊和噪声的组合进行建模。基于这一退化过程,部分超分辨率方法使用模糊核和噪声水平的参数作为先验知识来训练和测试超分辨率网络,从而完成可以处理多种退化的超分辨率重建。然而,这些方法的表现与退化参数先验知识的准确性高度相关。在实际应用中,准确的退化参数很多时候是难以获取的。为了解决上述问题,我们提出了退化重建损失,它通过退化模拟器捕获超分辨率图像和高分辨率图像之间的退化差异。基于退化重建损失,设计了一个可以处理多种退化的,无需先验知识的盲超分辨率框架SRDRL。
2 方法介绍
我们提出的无需先验知识的图像盲超分辨率框架由两部分组成:一个用于超分辨率重建的超分辨率网络,以及一个用于计算退化重建损失退化模拟器网络。框架分为两阶段分别训练退化模拟器网络和超分辨率网络,而在测试阶段,只需使用到超分辨率网络即可完成超分。
在第一个训练阶段,我们训练退化模拟器网络以学习从高分辨率图像到低分辨率图像的退化过程。退化模拟器接收真实的低分辨率图像并估计包含其退化信息的退化图,再用退化图退化高分辨率图像以生成估计的伪低分辨率图像。我们通过最小化退化模拟器生成的伪低分辨率图像和真实的低分辨率图像之间的平均绝对误差来训练退化模拟器网络。类似地,退化模拟器可以接收低分辨率图像和超分辨率图像以生成伪低分辨率图像。因此在第二个训练阶段,我们基于预训练的退化模拟器来计算退化重建损失,从而优化超分辨率网络有效适应多种退化。退化重建损失,即使用了超分辨率图像生成的伪低分辨率图像特征图和使用了高分辨率图像生成的伪低分辨率图像特征图之间的平均绝对误差,其很好地衡量了超分辨率图像和高分辨率图像所携带的退化信息差异。退化重建损失可以用作即插即用的损失,使得任意现有的超分辨率网络能处理多种退化。
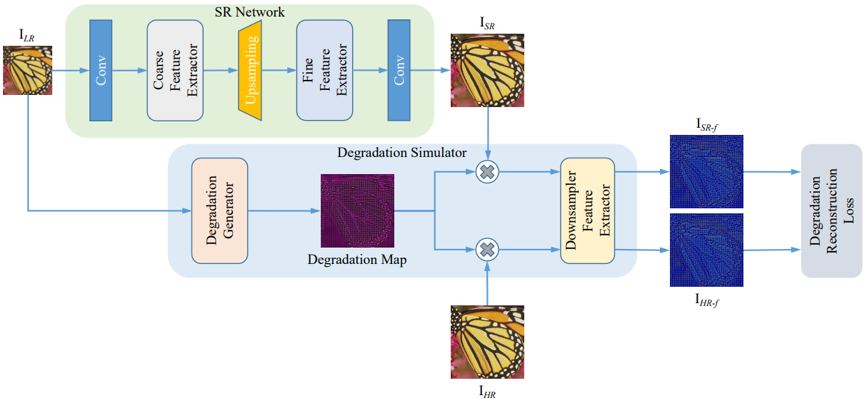
图1 基于退化重建损失的图像盲超分辨率框架
3 实验结果
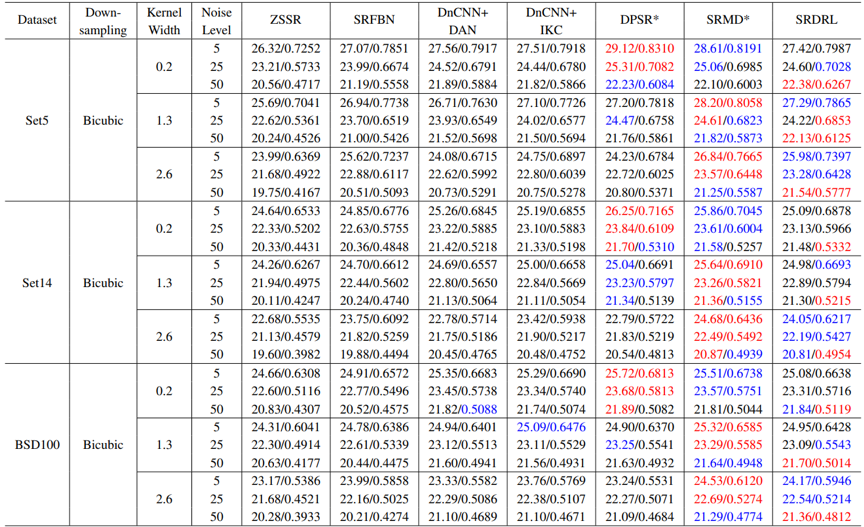
我们在经过多退化处理的Set5、Set14和BSD100数据集上进行了实验,使用了多个不同的模糊核和噪声水平来生成27组不同的测试集,从而评估超分辨率方法在复杂退化条件下的综合性能。表1的实验结果表明,我们提出的SRDRL在多退化测试集上显著优于现有的盲超分辨率方法和去噪+超分辨率方法,并能提供与使用了退化先验知识的超分辨率方法相当的性能。
表1 与超分辨率方法和去噪+超分辨率组合方法在多退化测试集上的比较
我们在真实退化数据集上对SRDRL和现有的盲超分辨率方法进行了比较,以证明SRDRL的实用性。如表2所示,与现有的盲超分辨率方法相比,本文提出的方法在DIV2K100 Corrupted数据集上取得了最优的PSNR和SSIM结果,能更好地处理了未知的退化。我们进一步将SRDRL与现有的盲超分辨率方法在真实低分辨率图像上进行了视觉效果比较。如图2所示,SRDRL生成的超分辨率图像具有更清晰的边缘、更高的对比度和更自然的视觉效果。
表2 与盲超分辨率方法在真实退化测试集上的比较。


图2 与盲超分辨率方法在真实低分辨率图像上的比较。
02
Real-Time and Accurate UAV Pedestrian Detection for Social Distancing Monitoring in COVID-19 Pandemic
基于实时准确行人检测的公共疫情社交距离监测
作者:邵振峰,程归*,马佳义,王中元,汪家明,李德仁
单位:武汉大学
邮箱:
shaozhenfeng@whu.edu.cn
chenggui@whu.edu.cn
jyma2010@gmail.com
wzy_hope@163.com
wjmecho@163.com
drli@whu.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/9417704
* 通讯作者
1、研究背景
保持社交距离被认为是减缓新冠病毒传播最有效的非药物措施。与地面固定的监控摄像机相比,无人机更加灵活,可以在任何区域提供实时的动态信息。基于这些优势,无人机是一种理想的社交距离监测平台。本文设计了一种基于无人机的社交距离监测系统,可以分为行人检测和社交距离计算两部分,整个流程如图1所示,包括5个步骤:1)无人机在校准状态下拍照;2)利用本文的行人检测算法,可以计算出每个行人头部的图像像素坐标;3)通过投影变换矩阵可以快速计算出现实世界中每个行人的坐标;4)基于现实坐标,计算每个行人之间的距离并存储在距离上三角矩阵中;5)判断矩阵中每个距离是否小于2米。如果是,说明该区域存在聚集情况。然后执行警报。该系统可以在无人机飞行过程中实时监测各个区域的社交距离。

图1 社交距离监测系统
2、方法概述
本文的行人检测网络是一个轻量级实时检测网络,由PeleeNet、多尺度空间注意模块和检测层三部分组成,如图2所示。作为骨干,PeleeNet可以基于改进的密集连接完全提取特征。利用多尺度空间注意模块集成多尺度特征,增强小目标信息。同时,不同尺度的空间注意信息有利于目标检测。检测层用于预测目标的位置。
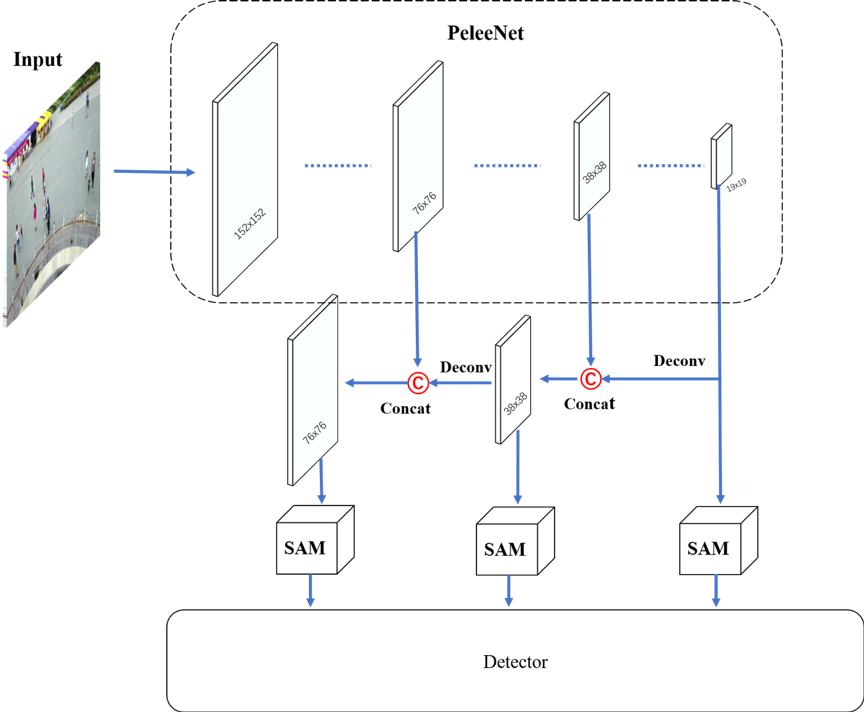
图2 网络结构
垂直成像原理可以简化为如图3所示,其中O-XYZ表示现实坐标系,u-o-v表示图像坐标系。P是真实世界的坐标点,P'是对应的图像点。f为相机焦距,H为相机焦距到地面的距离。设Pirw=[xi,yi,1]为每个头部二维平面现实其次坐标,Piv=[ui,vi,1]为对应的垂直图像其次坐标。根据垂直成像原理可以推导出以下公式:
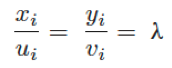
λ是指像素与米的比值。从Piv到Pirw的映射可以表示为:

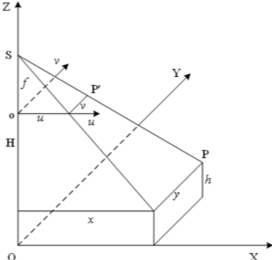
图3 垂直摄影的成像原理
倾斜图像比垂直图像复杂,本文首先利用单应矩阵将倾斜图像变换为垂直图像,然后根据垂直图像变换现实坐标的原理,将垂直图像变换为现实坐标,如图4所示。
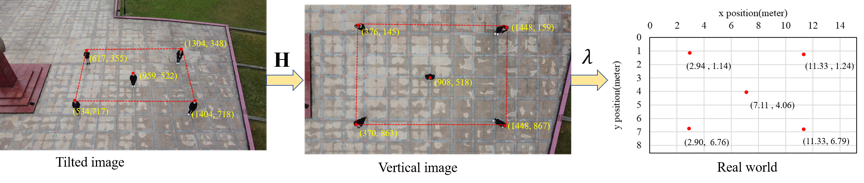
图4
单应性是点和线在射影平面上的可逆映射。假设Pit=[ui',vi',1]是倾斜图像坐标点的齐次坐标。Piv与Pit之间的变换关系可以用以下公式表示 :
![]()
其中H为单应矩阵,可以表示为:
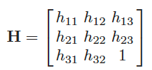
因此,可用以下公式实现图像倾斜坐标到真实坐标的变换:
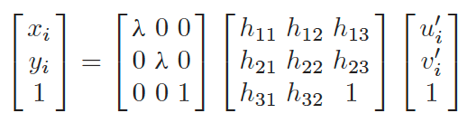
得到真实世界坐标后,即可计算出行人之间的社交距离。
3、实验结果
本文的方法和比较方法在UAV-Head数据集上的测试,本文的行人检测方法实现了88.5%的AP,高于对比方法YOLOv3(87.9%)、YOLOv3-tiny(82.3%)、SSD512(80.2%)。本文方法的FPS是75。这表明本文的行人检测方法同样可以实现对无人机图像的实时、准确的检测。
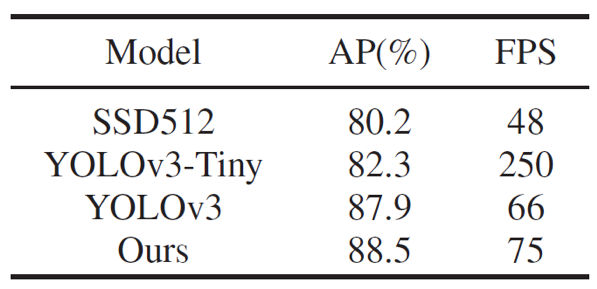
图5 不同方法在无人机数据集的结果对比

图6 无人机数据集上行人检测可视化结果
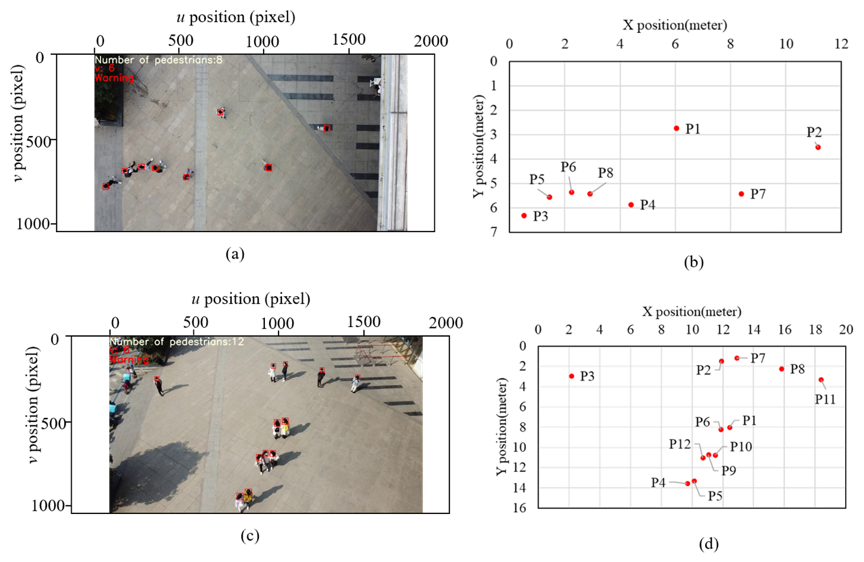
图7 无人机图像上的行人检测结果与真实世界中对应的坐标

图8 无人机图像(包括倾斜图像和垂直图像)社交距离监测结果
03
Image Difference Captioning with Instance-Level Fine-Grained Feature Representation
作者:黄清宝1,2、梁宇1,韦杰龙1,蔡毅2#,梁瀚予1,梁浩锋3,李青4
单位:1广西大学,2华南理工大学,3香港中文大学,4香港理工大学
邮箱:
qbhuang@gxu.edu.cn;
YLiangMail@126.com;
1712306010@st.gxu.edu.cn;
ycai@scut.edu.cn;
Hanyu_liang@163.com;
lhf@cuhk.edu.hk;
csqli@comp.polyu.edu.hk
论文:
https://ieeexplore.ieee.org/document/9410374/
代码:
https://github.com/VISLANG-Lab/IFDC
#通讯作者
引言:图像差异描述任务旨在从相似的图像对中定位出变化的对象,并用自然语言描述其差异,如图1所示。以往的研究主要集中在像素级图像特征上,忽略了图像对中对象丰富的显式特征,而这些特征有利于生成细粒度差异描述。此外,现有的生成模型在视点变化的干扰下无法准确定位差异。为了解决这些问题,本文提出了一个实例级细粒度差异描述(Instance-Level Fine-Grained Difference Captioning, IFDC)模型,该模型由细粒度特征提取模块、多轮特征融合模块、基于相似度的差异查找模块和差异描述模块组成。为了全面描述变化的对象,本文提取了实例级的细粒度特征,即视觉特征、语义特征和位置特征作为对象的表示。为了提高模型对视点变化的免疫能力,本文设计了基于相似度的差异查找模块,以准确定位变化目标。

图1 不同模型生成的不同图像差异描述。Xbef和Xaft表示变化前后的图像
方法:本文提出的模型如图2所示。IFDC由细粒度特征提取(Fine-Grained Feature Extraction, FFE)模块、多轮特征融合(Multi-Round Feature Fusion, MFF)模块、基于相似性的差异查找(Similarity-Based Difference Finding, SDF)模块和差异描述(Difference Captioning, DC)模块组成。与以往主流的像素级特征提取模型不同,IFDC更关注实例级的对象特征,使用包含视觉特征、语义特征和位置特征的细粒度特征来全面地表示对象。利用MFF模块来弥合文本和视觉形式之间的差距。为了准确定位图像对中变化的目标,并在一定程度上缓解视点的影响,利用SDF模块分别计算图像对中目标之间的特征相似度。最后,使用DC模块来生成不同的描述。

图2 实例级细粒度差异描述模型概述
实验:本文使用CLEVR-Change数据集和Spot-the-Diff数据集来评估IFDC模型的性能。
1.对比实验:
表1 CLEVR-Change数据集的差异描述评价,*为同期研究成果。
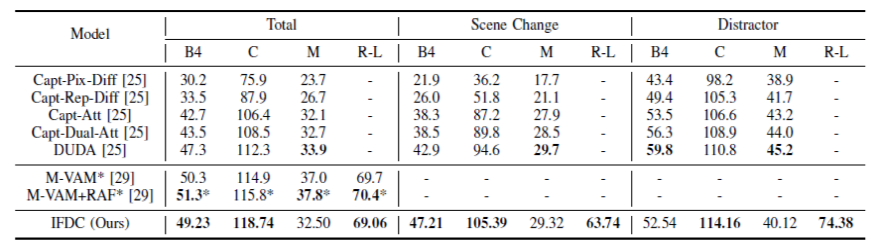
从表1可以看出,本文的IFDC模型在大部分指标上的表现普遍优于先前模型,特别是在Total数据集和Scene Change子集上。
表2 Spot-the-Diff数据集的差异描述评价,*为同期研究成果。
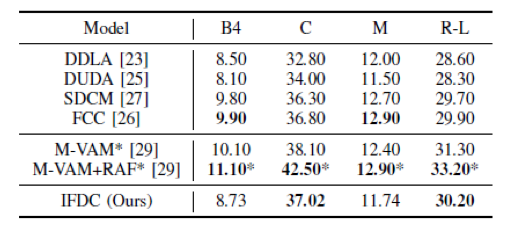
Spot-the-Diff数据集反映了真实监控视频不同帧之间的场景变化。表2表明,IFDC模型在Spot-the-Diff数据集上也表现良好。
2.消融实验:
表3 在CLEVR-Change数据集的消融实验。
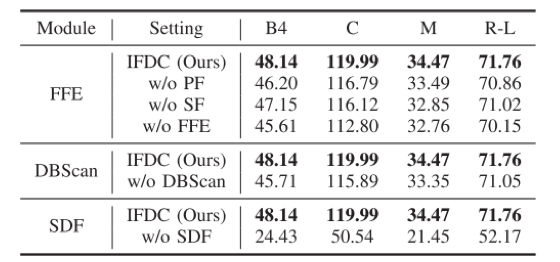
实验表明,IFDC模型的三个组成模块都有效。尤其是SDF模块在M和C等指标上效果明显,这表明SDF利于更好地找到实例级定位对象之间的差异,从而消除视点变化的干扰,生成准确的描述。
3.案例分析:

图3 CLEVR-Change 数据集上的案例分析
从图3中可以看出,IFDC模型生成的差异描述不仅包含了变化对象的多个属性信息(即微小、红色、金属和立方体),还包含了其空间位置信息,从而将其与图像对中的其他对象区分开来,可以正确预测变化类型,生成准确的差异描述,并在一定程度上缓解视点变化的影响。
04
Multiple Instance Detection Networks With Adaptive Instance Refinement
具有自适应实例细化的多实例检测网络
作者:吴志昊1,文杰1,徐勇*1,2,杨健3,张大鹏4
单位:1 哈尔滨工业大学(深圳),2 鹏城实验室,3 南京理工大学,4 香港中文大学(深圳)
邮箱:
horatio_ng@163.com
jiewen_pr@126.com
laterfall@hit.edu.cn
csjyang@njust.edu.cn
davidzhang@cuhk.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/9612070
谷歌学术主页:
https://scholar.google.com/citations?user=EnmDOYMAAAAJ
Github主页:
https://github.com/Horatio9702
*通讯作者
(一)问题分析
本研究聚焦于弱监督目标检测任务,即检测器训练时仅知道图像中目标的类别,而不知道它们的具体位置。主流方法是将其转化为候选区域的分类问题,即首先生成一系列与类别无关的目标潜在位置的候选区域并推测它们的所属类别,再从中选择样本(伪标签)用于检测器的训练。当前方法主要面临图1所示的三类定位失真问题:一是局部主导,即仅检测到目标最具有鉴别力的部位,如动物的头部;二是实例集群,即成群出现的同类目标被检测为一个整体,如停车场的车;三是实例丢失,即仅检测到最显著的目标个体,而不显著的被忽略,如小目标、阴影处的目标、罕见视角的目标等。这些问题发生的主要原因是基于CNN的分类器仅根据目标的局部即可分类,而目标检测要求发现全部的、完整的目标区域。因此,核心问题是如何使网络学习到尽可能多的完整目标。考虑到伪标签的选择主要基于提案的置信度分数,本研究的重点是如何充分利用提案分数。

图1 弱监督目标检测面临的三类定位失真挑战:从左至右依次为局部主导问题(红色框)、实例集群问题(红色框)和实例丢失问题(黄色框)。
(二)方法设计
提出的方法的整体架构如图2所示,包括三个新颖的模块:自适应实例挖掘、自适应分数调制和自适应知识精炼。
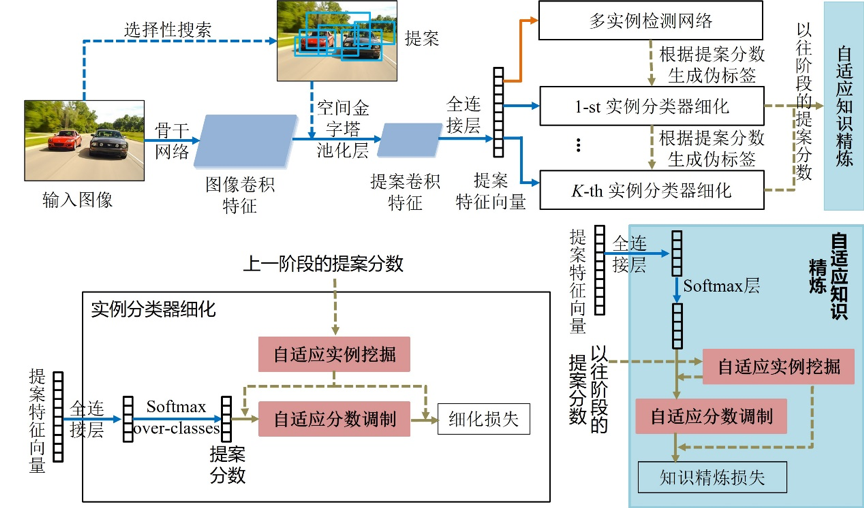
图2 提出的方法的整体架构图
自适应实例挖掘:同一图像可能包含多个同类目标,而当前的弱监督目标检测方法中网络学习到的目标有限。 (1)缺乏尺度和形态上的变化,可能不足以训练具有很强鉴别力的CNN分类器。(2)丢失的实例可能被选为负例,从而进一步导致训练偏离正确的方向。我们认为,对于具有一定鉴别力的网络,其检测到的正例和负例间应有明显的分数“断崖”,即正例的提案分数应该明显高于负例的提案分数。具体来说,第一步,将提案各类别得分从大到小排序,得到排序后的得分矩阵和对应的提案序号矩阵。第二步,对于排序后的得分矩阵,从末至首逐行相减,得到得分差值矩阵。第三步,计算各类别得分差值的最大值及序号,若序号小于设定的阈值(最佳阈值需通过实验得到),序号及之前的设为正例;否则,仅最大值设为正例。第四步,将已设为正例的提案的邻接提案也设为正例。
自适应分数调制:训练早期,几乎未经训练的分类器产生不精确的伪标签。也就是说,即使是最高的提案得分也是低分。而这些低质量的伪标签对训练有害,导致训练偏离正确方向。为此,我们提出了一种先易后难的策略:(1)训练开始时仅关注得分高的实例(简单实例、质量较高的伪标签),因为这些候选区域更可能包含对象或对象的部分。(2)随着训练的进行,分类器的鉴别能力和泛化力得到提升,更加关注得分低的实例(困难实例),以进一步提升网络的能力。以往的方法大多是设计新的损失函数,以调整具有不同难度(误差)的样本梯度(对训练的贡献)。而我们的方法不改变损失函数,直接调整样本的误差,从而调节不同样本对训练的贡献。也就是说,我们利用原有的梯度而无需创造新的。该方法对实际应用的开发也更友好,因为开发者无需关心损失函数的底层实现,直接调整预测误差即可。
自适应知识精炼:以往的方法中,当前阶段的监督仅由前一阶段的提案分数生成,这可能会丢失以往阶段中相对精确的定位信息。为此,我们用来自以往所有细化阶段的提案分数的加权平均值来生成新阶段的监督,这是因为每个阶段所生成的监督信息的误差大小不同、重要性也不同。
(三)实验结果
我们在PASCAL VOC 2007(5,011用于训练,4,951用于测试)、PASCAL VOC 2012(11,540用于训练,10,775用于测试)和MS COCO 2014(82,783用于训练,40,504用于测试)上进行了广泛的实验。PASCAL VOC上的评价指标为mAP(用于测试集)和CorLoc(用于训练集)。MS COCO上的评价指标为AP50(IOU阈值为50%)和AP(IOU各阈值下的平均值)。实验结果表明我们提出的模块是有效的,方法达到了最先进的水平(见表1和图3)。
表1 在PASCAL VOC 2007上的mAP结果比较


图3 可视化结果对比
05
Discover Micro-Influencers for Brands via Better Understanding
作者:王少鲲1,2,甘甜1#,刘雨桉3,4,张力5,吴建龙6,聂礼强6
单位:1山东大学,2西安交通大学,3中国科学院大学,4中科院计算技术研究所,5阿里巴巴,6哈尔滨工业大学(深圳)
邮箱:
shaokunwang.sdu@gmail.com
gantian@sdu.edu.cn
论文:
https://ieeexplore.ieee.org/document/9454334
#通讯作者
一、研究背景
近年来,随着影响者营销行业的快速发展,品牌与微影响者在多领域广泛开展了营销合作。 作为影响者营销的关键子任务,微影响者推荐(Micro-influencer Recommendation)致力于在社交网络中寻找合适的微影响者来帮助品牌做营销(图1)。现有的微影响者推荐方法主要考虑如何帮助给定品牌找到合作效果更好的微影响者,即这些工作重点关注品牌与微影响者合作时的营销效果。然而,在影响者营销中,仅考虑营销效果是片面的。选择合作伙伴会对品牌和微影响者自身的形象和发展方向都会产生潜移默化的长期性影响。因此,两者在选择合作伙伴时需要考虑是否契合自我发展需求。
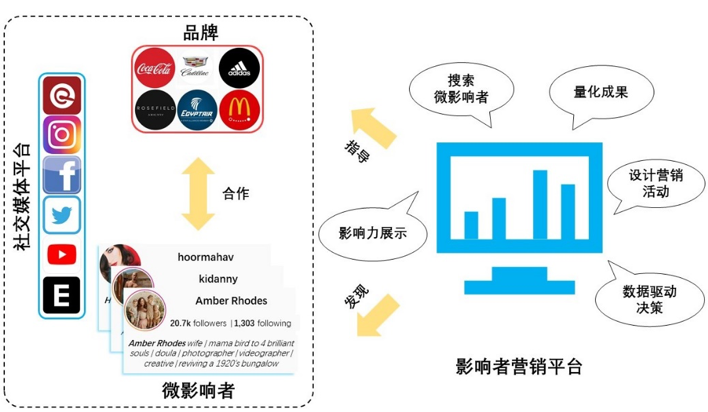
图1 影响者营销的常见工作流程
二、方法介绍
本文在微影响者营销这一实际背景下,综合考虑了微影响者推荐中的营销效果问题和自我发展需求问题,提出了一个基于社交媒体概念的微影响者推荐方法(CAMERA,图2)。主要贡献如下:
1)CAMERA通过在细粒度级别理解社交媒体账户的营销意图来解决微影响者推荐任务中营销效果问题和自我发展需求问题。
2) 我们设计跨模态社交媒体概念学习网络(COSMIC,图3)和双向概念注意力机制(BCAM)以从历史活动和营销方向两个角度学习社交媒体账户表示。同时,基于以上两个角度的可解释参数可以帮助品牌和微影响者做出决策。
3)我们在微影响者排序模块中建模品牌和微影响者合作时的代言信息以及微影响者的影响力信息,并定义了两个自适应学习指标(代言效果得分和微影响者影响力得分)以学习出更精确的微影响者排序函数。
4) 基于真实数据集的推荐性能分析和推荐可解释性分析分别验证了我们方法的推荐效果以及社交媒体概念对可解释性的帮助。

图2 CAMERA的架构图

图3 COSMIC的架构图
三、实验结果
我们的方法在山东大学iLearn实验室提供的brand-micro-influencer数据集上进行了全面的评估。该数据集包含了360个品牌和3,748个微影响者,其中品牌分为12个类别。在brand-micro-influencer数据集的基础上,我们收集了420个社交媒体概念来表示品牌和微影响者的社交媒体内容。如表1所示,与当前最优方法的比较验证了我们方法的推荐性能。同时,我们设计了一项包含两项任务的用户研究,分别测试社交媒体概念是否可以很好地体现社交媒体账户的营销特征以及社交媒体概念是否有助于用户理解账户的营销方向。志愿者除了要在24道题中选出正确答案,还需要从“易于理解性”,“全面性”和“合理性”这三个方面对答案进行评估。评估采用五分制(非常差,差,一般,良好和非常好)。如表2所示,该研究成功验证了将社交媒体概念引入微影响者推荐中的有效性。
表1 推荐性能分析

表2 针对社交媒体概念有效性的用户研究

06
SPGNet: Serial and Parallel Group Network
作者:王萱1,赖申其1,柴振华2,张兴军1,钱学明1#
单位:1西安交通大学, 2美团
邮箱:
dream950@stu.xjtu.edu.cn
laishenqi@stu.xjtu.edu.cn
chaizhenhua@meituan.com
xjzhang@mail.xjtu.edu.cn
qianxm@mail.xjtu.edu.cn
论文:
https://ieeexplore.ieee.org/document/9454285
代码:
https://github.com/xiaolai-sqlai/SPGNet_TMM2021
#通讯作者
引言:
NPU在一些对延迟敏感的领域比如机器人或者边缘计算上有巨大的应用前景,但是目前很少有针对NPU优化的轻量级网络模型,在主流轻量化网络结构中大量采用了深度可分离卷积,这种卷积方式在理论上具有更少的计算量但是在实际使用中却对NPU并不友好,在NPU上相似FLOPs下,传统卷积速度甚至都要比深度可分离卷积快。因此我们提出了针对NPU优化的网络结构SPGNet,既保证了传统卷积在NPU上的速度优势又不引入巨大的计算量,在相似FLOPs下在NPU上速度相比MobileNetV2提升了120%,在ImageNet数据集上在准确率差不多的条件下NPU推理速度比GhostNet提高300%。

图1 SPGmodule结构图
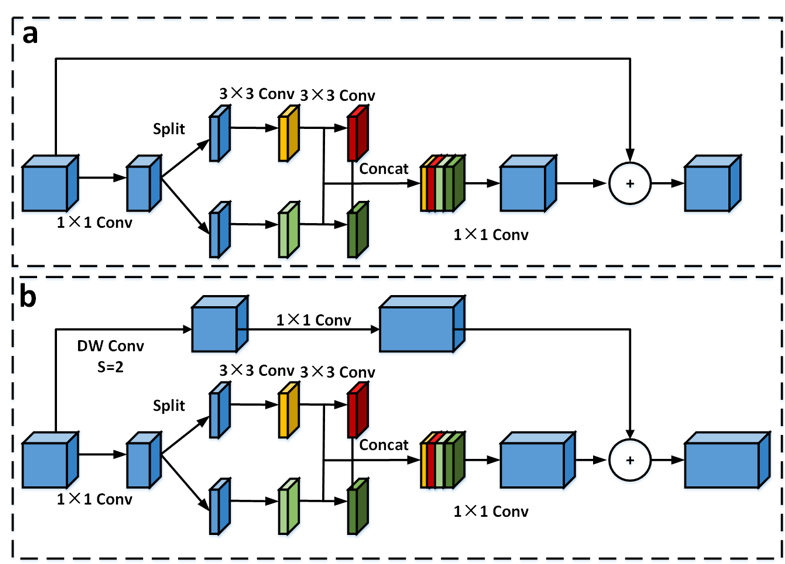
图2 SPGblock结构图
方法:
如图1所示,首先我们提出了轻量级的SGmodule来增加模型中的多尺度信息,为了减少FLOPs又进一步引入PGmodule,在PGmodule中为了适配NPU并行计算能力强的特点将分组数限制在8以内,并且每一组的计算量严格相等,最后结合两种模块的特点提出SPGmodule。假设网络分组数为P,串联层数为S,则SPGmodule的运算步骤为:
a) 首先对输入特征图在通道维进行分组,分组后得到P个通道数1/P为的特征图;
b) 对于每一个通道数为1/P的中间特征图进行一次输出通道数为1/P的3*3卷积;
c) 在每一个分组中,对于步骤B中得到的特征图进行S-1个1/PS连续的3*3卷积,这些3*3卷积的输入输出通道数完全相同,从而最大化降低内存访问消耗;
d) 将步骤B和步骤C中得到的PS个通道数为1/PS的特征图拼接得到最终输出。
在SPGNet中我们消融了不同的S以及P参数的组合,并提出了适配不同计算量下的4种模型,具体block结构如图2所示。
实验结果:
在Cifar100以及RK3399Pro上不同参数组合的实验结果如表1,在相似FLOPs下串联数S为2时准确率最高,同时在NPU上的推理速度会随着并联数P的增加而增加。为适配不同场景需求,我们除了四种不同计算量的模型,在ImageNet数据集上与其他轻量级网络对比可以看到我们在NPU上的速度遥遥领先于其他方法,同时准确率在相似FLOPs上也比MobileNetV2高2.1%。
表1 在Cifar100上不同参数组合消融实验

表2 在ImageNet上与其他网络的对比


 京公网安备11010802017125号
京公网安备11010802017125号