
2023年论文导读第五期
【论文导读】2023年论文导读第五期
CCF多媒体专委会 2023-03-14 09:40 发表于北京


论文导读
2023年论文导读第五期(总第七十一期)
目 录
|
1 |
Perceptual Quality Assessment of Cartoon Images |
|
2 |
Deep-PCAC: An End-to-End Deep Lossy Compression Framework for Point Cloud Attributes |
|
3 |
Efficient Spatio-Temporal Contrastive Learning for Skeleton-Based 3-D Action Recognition |
|
4 |
Learning Personalized Image Aesthetics From Subjective and Objective Attributes |
|
5 |
Explicit Cross-Modal Representation Learning for Visual Commonsense Reasoning |
|
6 |
A Universal Quaternion Hypergraph Network for Multimodal Video Question Answering |
01
Perceptual Quality Assessment of Cartoon Images
作者:陈航威1,柴雄力1,邵枫1,王雪津2,姜求平1,孟祥超1,Yo-Sung Ho3
单位:1 宁波大学信息科学与工程学院,2 福建工程学院计算机科学与数学学院,3the School of Information and Communications, Gwangju Institute of Science and Technology
邮箱:
shaofeng@nbu.edu.cn
论文:
https://ieeexplore.ieee.org/document/9585540
数据集和代码:
https://github.com/1010075746/NBU-CIQAD
在卡通动画行业中,失真和颜色变化会引起卡通图像的质量退化。现有的无参考图像质量评价方法通常测量自然图像的感知质量,而卡通图像和自然图像在外观、结构和颜色特征上都有所不同,导致传统的自然图像评价方法并不适用于卡通图像。因此,如何客观和准确地评价卡通图像的质量具有重要的研究与应用价值。本文围绕卡通图像的主观和客观视觉质量评价方法设计开展研究。
在主观评价方面,我们构建了一个新的具有不同程度的亮度变化(BC)、饱和度变化(SC)和对比度变化(CC)的卡通图像质量评估数据库(NBU-CIQAD)。该数据库包括100张参考图像,1800张单一失真图像和800张多失真图像。我们邀请志愿者对这些单一失真和多失真图像进行主观评价测试,以获得每张图像的人类主观得分(MOS)。图1展示了NBU-CIQAD中的部分颜色变化卡通图像。图2展示了所有颜色变化类型卡通图像的MOS平均值和标准差。

图1 NBU-CIQAD中的颜色变化卡通图像示例
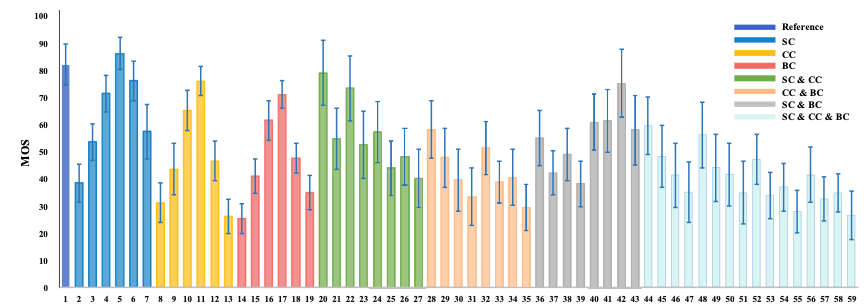
图2 所有颜色变化类型图像的MOS平均值和标准差
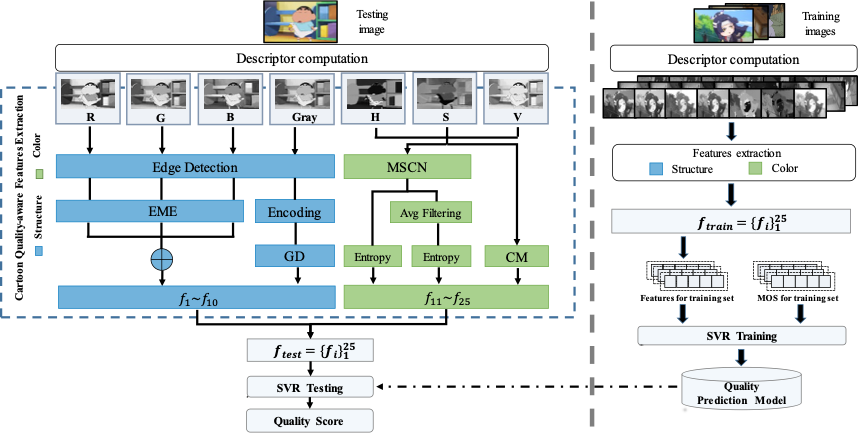
图3 本文提出的客观评价方法整体流程框架
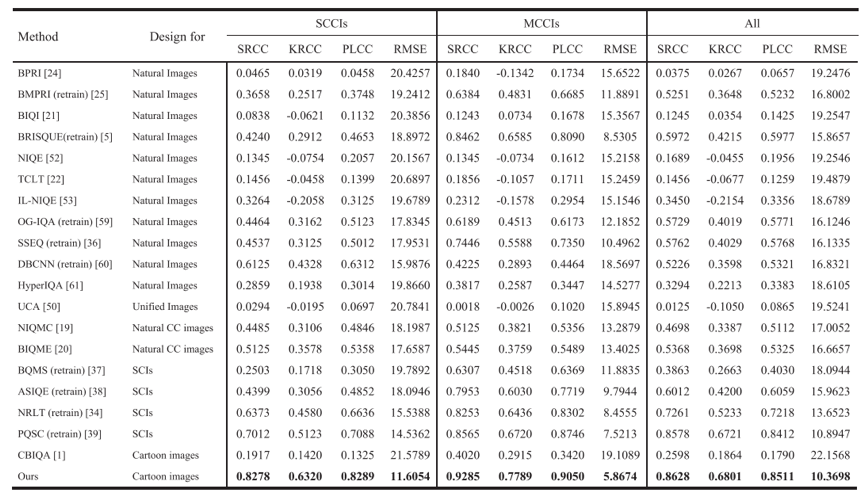
在客观评价方面,本文提出了一种新的卡通图像的无参考质量预测模型,如图3所示。该框架主要由特征提取和质量回归两部分组成。该模型首先在梯度域中提取纹理和边缘特征,以合理估计结构变化,并在HSV颜色空间中提取矩和熵特征,以获取颜色信息。最后,借助支持向量回归机(SVR)来建立质量回归模型。本方法在提出的NBU-CIQAD数据集上的测试结果如表1所示。由表1可知,提出的方法优于现有方法且具有较高的评价准确性。
表1 在NBU-CIQAD数据集上的测试结果
02
Deep-PCAC: An End-to-End Deep Lossy Compression Framework for Point Cloud Attributes
作者:盛锡华1,李礼1* ,刘东1 ,熊志伟1 ,李竹2 ,吴枫1
单位:1中国科学技术大学, 2密苏里大学-堪萨斯分校
邮箱:
xhsheng@mail.ustc.edu.cn ;
lil1@ustc.edu.cn ;
dongeliu@ustc.edu.cn ;
zwxiong@ustc.edu.cn ;
zhu.li@ieee.org ;
fengwu@ustc.edu.cn
论文:
https://ieeexplore.ieee.org/document/9447226
代码:
https://github.com/xhsheng-ustc/Deep-PCAC
* 通讯作者
1. 引言
点云在自动驾驶、沉浸式视觉通信、虚拟现实等领域已被广泛应用。点云通常由空间几何坐标和属性,如颜色、法线、反射率等组成。随着点云采集设备的更新换代,一个采集的点云通常包含上百万个点,其庞大的数据量给存储和传输带来了巨大的挑战,因此迫切的需要开发高效的点云压缩算法,以减少点云的存储和传输开销。近年来,深度学习在图像、视频压缩领域取得了突破性成功。受其启发,在本工作中,我们针对点云颜色属性,提出了首个基于深度学习的端到端点云属性有损压缩框架(Deep-PCAC)。
2. 方法
所提出的端到端点云属性有损压缩框架如图1所示。该框架由点云属性自编码器、预处理模块、后处理模块三部分组成。点云属性自编码器可以在点云几何坐标的辅助下,直接编解码点云属性,无需对点云进行体素化或投影。预处理模块用于将包含上百万个点的点云划分为子块,每个子块作为一个编码单元,独立且相同地被编码。后处理模块用于将解码的子块重新拼接为完整点云。
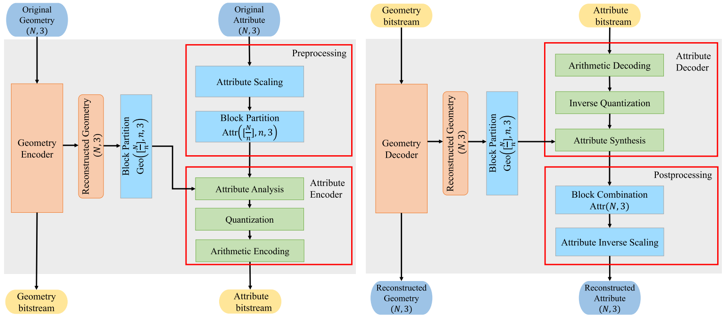
图1 所提出的端到端点云属性有损压缩框架示意图
所提出的点云属性自编码器如图2所示,其主要包含多层感知器(Multilayer Perceptron)、点密集开端模块(Dense Point-Inception Block.)、二阶点卷积层(Second-Order Point Convolutional Layer)、点反卷积层(Point Deconvolutional Layer)。多层感知器和点密集开端模块用于提取点云属性特征。在编码器中,二阶点卷积层利用最远点下采样(Farthest Point Sampling)减少点的数量,利用更大的感受野,为下采样后的点聚合空间中更多的点特征,得到压缩后的点云属性隐变量。在解码器中,点反卷积层利用加权距离插值将下采样后的低分辨率的点云的特征传播至高分辨率的点云,实现点云属性的重建。为了更好地建模下采样后的点云属性隐变量的概率分布,减少点云属性隐变量的比特开销,超先验熵模型被嵌入到自编码器中。

图2 所提出的点云属性自编码器结构示意图。
3. 实验
客观和主观实验结果分别如图3和图4所示。实验结果表明,我们提出的端到端点云属性有损压缩框架的编码性能超过了具有区域自适应分层变换和游程哥伦布熵编码器的点云属性编码方法(RAHT-RLGR)。但我们的方法与MPEG G-PCC点云编码标准的参考软件TMC13中的RAHT和Predlift依然较大差距,说明我们的方法依然有巨大的改进空间。

图3 所提出的点云属性编码框架在测试集上的码率-失真曲线。


图4 主观质量比较。从左到右依次是原始点云、所提出框架的重建点云、RAHT-RLGR的重建点云。
03
Efficient Spatio-Temporal Contrastive Learning for Skeleton-Based 3-D Action Recognition
用于3D骨架行为识别的高效时空对比学习
作者:高学浩1、杜少毅1,杨旸1,张艺萌1,李茂森2,余晋刚3
单位:1西安交通大学,2上海交通大学,3华南理工大学
邮箱:
gaoxuehao.xjtu@gmail.com;
dushaoyi@gmail.com;
yyang@mail.xjtu.edu.cn;
yimengzhang@stu.xjtu.edu.cn;
maosen_li@sjtu.edu.cn;
jingangyu@scut.edu.cn;
论文:
https://ieeexplore.ieee.org/document/9612062
相较于人脑中强大的视觉建模机制能在复杂的开放式观测环境中做出快速且准确的行为类别判断,行为识别的算法模型的通常缺乏学习鲁棒的行为表征的能力。为此,我们提出了名为骨架行为识别的高效时空对比学习算法用以在无标注的骨架动作视频中以更高效的方式学习更鲁棒的行为表征信息。

图1开放观测场景下的语义一致性。
首先,如图1所示,不同的观测场景只会对骨架运动在基于位置信息的空间内呈现不同的表观特征,但在其高层语义特征空间中并不会造成扰动。因此在不同观测场景下的同一个骨架行为需要在特征空间中保持一致。
其次,通过分析人脑中对于动作的视觉建模过程,在对于人体动作整体的语义理解的过程中,人脑首先会有人体部位识别和判断的预处理阶段,即先准确对诸如手部,腿部等人体部位的进行准确的理解,再结合不同身体部位的协同运动状态做出整体动作语义的判别,这一人体关节部位预判别过程对于识别算法而言十分关键,尤其在不同的观测场景下的骨骼运动而言,对于骨架关节点准确的语义理解对于整体动作语义的判别显得尤为重要。

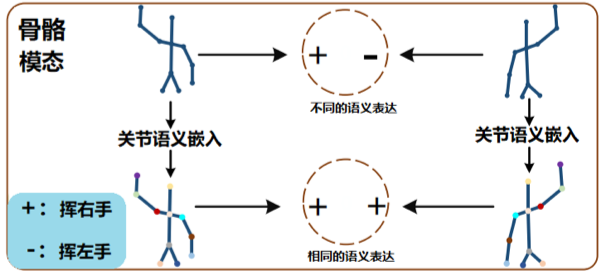
图2 对人体关节点语义的准确理解对于识别
我们发现,对比任务的设计对于自监督环境下的特征提取尤为关键,此外,高效的行为编码网络有助于进一步提高表征提取的质量和效率。为此,我们分别单独设计了Non-local GCN 与Multi-scale TCN 网络用于高效地提取骨架动作序列中的远距离的时空信息流。具体而言,为促进空间信息流,Non-local GCN通过动态学习人体骨架的拓扑结构,构建数据驱动的动态人体骨骼拓扑,从而大大促进了信息在同一帧中骨骼图上的传播。为促进时间维度上的信息传播,设计带有不同卷积核尺寸的时间卷积网络(TCN)促进同一个节点在不同帧上的信息传递。
最终,如表1所示,在NTU60,NTU120, NW-UCAL,和UWA3D数据集上,算法在行为识别准确率和效率方面均取得了较出色的表现。
表1 不同行为识别算法在不同数据集上参数量和准确率方面的比较。

04
Learning Personalized Image Aesthetics From Subjective and Objective Attributes
具有自适应实例细化的多实例检测网络
作者:祝汉城1,周勇1#,李雷达2,李亚乾3,郭彦东3
单位:1中国矿业大学,2西安电子科技大学,3OPPO研究院
邮箱:
zhuhancheng@cumt.edu.cn;
yzhou@cumt.edu.cn;
ldli@xidian.edu.cn;
liyaqian@oppo.com;
yandong.guo@live.com
论文:
https://ieeexplore.ieee.org/document/9599464/
#通讯作者
引言:
在个性化图像美学评价中,最大的挑战是个体用户通常只能标注少量的图像,难以直接训练一个基于深度网络的高效个性化图像美学评价模型。因此,现有的个性化图像美学评价方法主要是将大量用户评估的通用图像美学作为先验知识模型,然后再利用少量带美学标注的图像数据对先验模型进行微调来获取针对个体用户的个性化图像美学评价模型。然而,这种先验模型大都是通过提取图像中的客观属性进行学习,忽略了用户的主观属性对其个性化审美的影响。因此,在不考虑用户主观属性的情况下,直接将先验模型迁移到针对个体用户的个性化图像美学评价模型存在一定问题。为了解决上述问题,本文提出一种融合主客观属性的个性化图像美学评价方法,通过从用户的主观属性和图像的客观属性共同表征用户对图像的个性化审美偏好。
图1展示了两幅示例图像与一些相关的美学属性,以及五位用户评估的美学分数与相应的平均美学评分。美学分数的范围为从1到5,分数越高,说明图像的美感越好。可以看出,图1(a)的平均评分高于图1(b)的平均评分。这是因为图1(a)比图1(b)具有更好的客观美学属性,这使得图1(a)得到了大多数用户更高的审美评价。此外,不同用户对同一幅图像的美学评分也存在很大的不一致,这是因为用户的个性化审美偏好也受到其自身主观属性的影响。因此,图像的客观属性是通用的审美规则,可以用来衡量大多数人对图像的大众化审美体验,而用户的主观属性是决定其个性化审美偏好与图像的大众化美感之间差异的关键因素。
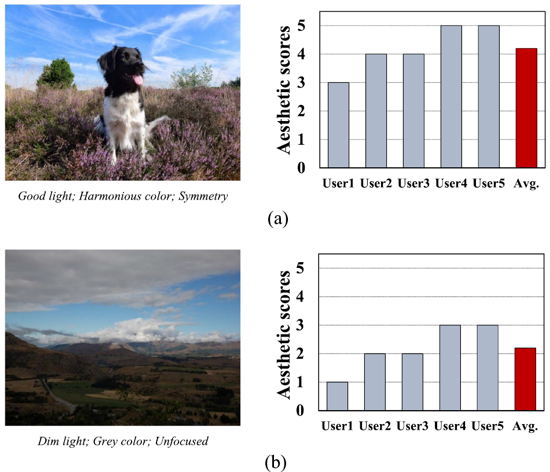
图1 两幅示例图像与一些相关的美学属性,以及五位用户评估的美学分数与相应的平均美学评分
方法:
如图2所示,本文方法框架由三个部分组成:属性提取模块、美学先验模型和个性化美学评价模型。首先构建属性提取模块来获取用户的大五性格特征(主观属性)和图像的美学属性(客观属性);然后利用用户的性格特征和图像的美学属性共同学习图像的美学分布和用户相比于其他用户之间的差异分数,来构建美学先验模型。最后通过使用目标用户的少量标注图像对先验模型进行微调,来获得针对该用户的个性化图像美学评价模型。

图2 提出方法的框架图
实验:
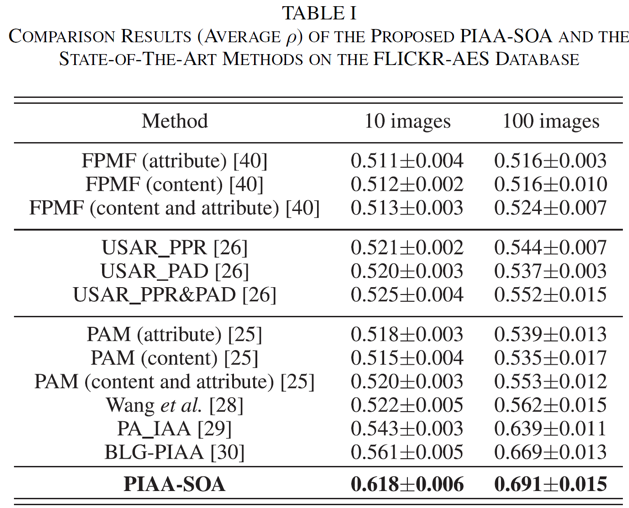
本文方法与几种主流方法在FLICKR-AES数据集中对37位测试用户进行了实验,并在表1中列出了这些个性化图像美学评价方法的对比结果。可以看出本文方法明显优于目前主流的方法,这表明本文方法可以将用户的性格特征和图像的美学属性有效地嵌入到针对个体用户的个性化美学先验模型中。
表4-1 在FLICKR-AES数据集上本文方法和几种主流方法对37位测试用户的性能对比结果(ρ)
05
Explicit Cross-Modal Representation Learning for Visual Commonsense Reasoning
基于显式跨模态表示学习的视觉常识推理方法
作者:张熙1,张飞飞2,徐常胜1,3
单位:1中国科学院自动化研究所,2天津理工大学,3鹏城实验室
邮箱:
zhangxi2019@ia.ac.cn
feifeizhang1231@gmail.com
csxu@nlpr.ia.ac.cn
论文:
https://ieeexplore.ieee.org/document/9465732
一、研究方案
由于深度神经网络的“黑盒”模型特性,其推理过程缺乏可解释性。为了克服这一问题,需要设计显式的推理模型。本方案拟提出一个基于神经模块网络的显式多模态推理模型,在句法结构的引导下,利用神经模块网络将模型的决策划分成多个小决策,并可视化每步决策的依据,提供推理证据,从而提高视觉推理模型的可解释性。
二、技术路线
以往的视觉问答方法大多基于注意力机制或关系网络进行多模态推理,这些方法虽然简单直观,但都进行的是隐式推理,无法为其决策提供令人信服的证据。近年来,由于神经模块网络(Neural Module Network, NMN)能够执行显式的基于序列的推理,它被越来越多地用于多模态理解任务。例如,在视觉问答中,基于神经网络的方法首先将问题编码到包含推理路径的功能模块组合中,然后对于输入图像执行神经模块以获得答案。这促使我们求助于神经模块网络进行显式的跨模态推理,并将中间结果作为推理证据。
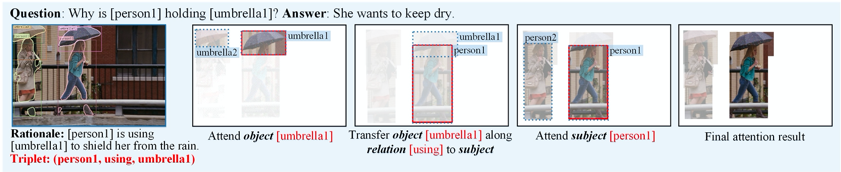
图1 根据句法三元组进行的可能推理步骤。
如图1所示,我们所提出的模型首先显式地将问题解析为句法三元组来指导推理,然后采用几个基于注意力机制的神经网络模块逐步关注于正确的图像内容。通过上述过程,模型就可以得到与文本相关的需要关注的视觉信息,有助于对多模态语义进行彻底的理解。
另外,对于视觉问答中的文本输入,现有的大多数方法使用递归神经网络(如LSTM)来提取文本特征。但是当视觉问答任务中的文本更复杂、含有更丰富的语义时,递归神经网络无法对对文本进行更深入的语境和语义理解。事实上,从句法结构中提取的句法关系隐含着单词间的依赖关系和上下文间的语义逻辑。例如,在从句子“[person1] is using [umbrella1] to shield her from the rain” 中提取的句法三元组“[person1],using,[umbrella1]”中,[person1]是谓语using的主语,[umbrella1]是谓语using的宾语。因此,我们利用句法关系,开发了一个基于句法的图卷积网络,建模复杂文本中语义结构的高阶内部关系并将句法信息融入到文本表示中,以辅助神经模块网络的推理。
我们拟设计一个如图2所示的基于神经模块网络的显式视觉推理模型。该模型由两个关键模块组成:基于句法的文本理解模块和句法引导的跨模态显式推理模块。具体来说,在基于句法的文本理解模块,我们首先将文本(例如,问题,候选答案)解析为主语-谓语-宾语三元组,然后基于三元组构建句法图,其边缘由解析后的三元组定义。之后,在句法图上实现句法图卷积网络,通过边缘间句法结构信息的传递来整合文本的上下文语义。最后,将提取的具有句法信息的文本特征输入到跨模态显式推理模块中指导多模态推理。在跨模态显式推理模块中,我们设计了一个双分支神经模块网络,对问题和候选答案进行可解释的语言到视觉推理。具体来说,我们首先在视觉对象上构建一个有向图。然后,由于三元组包含丰富的语义结构信息,我们可以将三元组作为推理的指导,构建可解释的推理步骤。具体来说,我们设计了一个由多个基于图注意力机制的神经模块构成的网络进行显式推理,该网络包括两个节点注意模块、一个边缘注意模块和一个转移模块组成。节点注意模块的输入是文本理解模块提取的主语(如“person1”)或宾语(“umbrella1”)的特征表示,而输出是用于定位相关图像内容的视觉注意力权重。通过边缘注意模块和传递模块,将与宾语相关的信息沿谓语(如“using”)传递给主语,获得最终的视觉特征。最终,该视觉特征与包含句法信息的文本特征融合后进行视觉问答任务。通过上述步骤,所提出的跨模态显式推理模块能够为模型的决策提供细粒度的中间证据,使模型更具可解释性。

图 2 基于神经模块网络的显式多模态推理模型
三、 实验结果
为验证所提出模型的有效性,我们在视觉问答领域的Visual Commonsense Reasoning(VCR)数据集上进行测试。根据图3中可视化结果,证明我们所提出的显式推理模型的有效性和推理的正确性。在表1的定量实验中,通过与目前效果最好的方法对比,证明我们的模型在三个子任务上都取得了最好的结果。
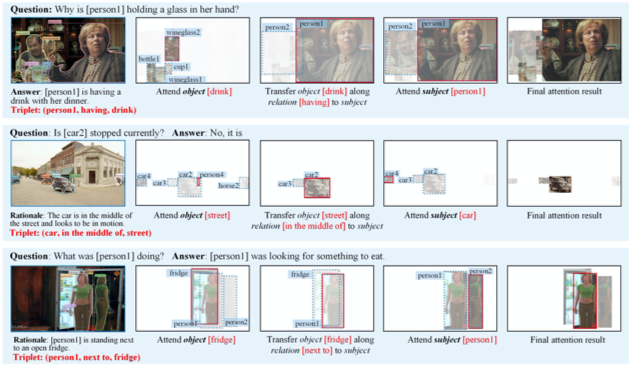
图3 所提出的显式跨模态推理过程的可视化结果。
表1 模型在VCR验证集的三个子任务上的消融分析。

06
A Universal Quaternion Hypergraph Network for Multimodal Video Question Answering
多模态视频问答的通用四元数超图网络
作者:郭志成,赵嘉璇,焦李成,刘旭,刘芳
单位:西安电子科技大学,人工智能学院
邮箱:
zchguo@stu.xidian.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/9576650
1.摘要
多模态特征的融合和交互对于视频问答至关重要。 视频中不同对象之间的关系构成的结构信息非常复杂,限制了理解和推理。 在本文中,我们提出了一种用于多模态视频问答的四元数超图网络 (QHGN),以同时包含多模态特征和结构信息。 由于四元数运算适用于多模态交互,因此应用四元数向量的四个分量来表示多模态特征。 此外,我们基于视频中检测到的视觉目标构建了一个超图。 最重要的是,理论上推导出四元数超图卷积算子来实现多模态和关系推理。 将问题和候选答案嵌入四元数空间,创造性地设计了问答推理模块,准确选择答案。 此外,统一框架可以扩展到具有不同四元数解码器的其他视频文本任务。 对 TVQA 数据集和 DramaQA 数据集的实验评估表明,我们的方法达到了最先进的性能。
2.方法
电影/电视节目中的每个视频都具有三种模态的特征:外观特征、动作特征和字幕特征。 视频中的运动信息也可以看作是一种特殊的模态。 从另一个角度来看,问题被视为一个条件特征来指导视频信息的聚合。 最重要的是,我们将每种模态的特征视为四元数的不同组成部分。 换句话说,视频的四种模态由四元数向量表示。 通过汉密尔顿积,可以直接实现不同模态之间的融合和交互。 当将问答特征嵌入到四元数空间时,我们认为它们都与不同的模态相关。
利用图结构来探索视觉关系激发了我们对关系推理的思考。 为了实现视频中不同对象的关系推理,我们为视频片段构建了一个超图,其中每个片段都表示为一个顶点。 与简单图不同,超图中的超边允许连接两个以上的顶点。 因此,视频中检测到的每个视觉目标都被视为超边。 如果一个顶点包含与一条超边相同的视觉目标,那么它将被这条超边连接起来。 这样就可以根据视觉对象不断地在视频中找到上下文线索。
在四元数空间中,我们理论上推导了四元数超图卷积算子。 同时,创建四元数超图卷积网络来推理视频的多模态和多级结构信息。 接下来,系统分析证明了网络的有效性。 最后,我们通过四元数关系实现了一个问答推理模块,可以有效地预测跨度和选择答案。 此外,统一的四元数超图网络扩展到其他视频文本任务。
3.网络结构图

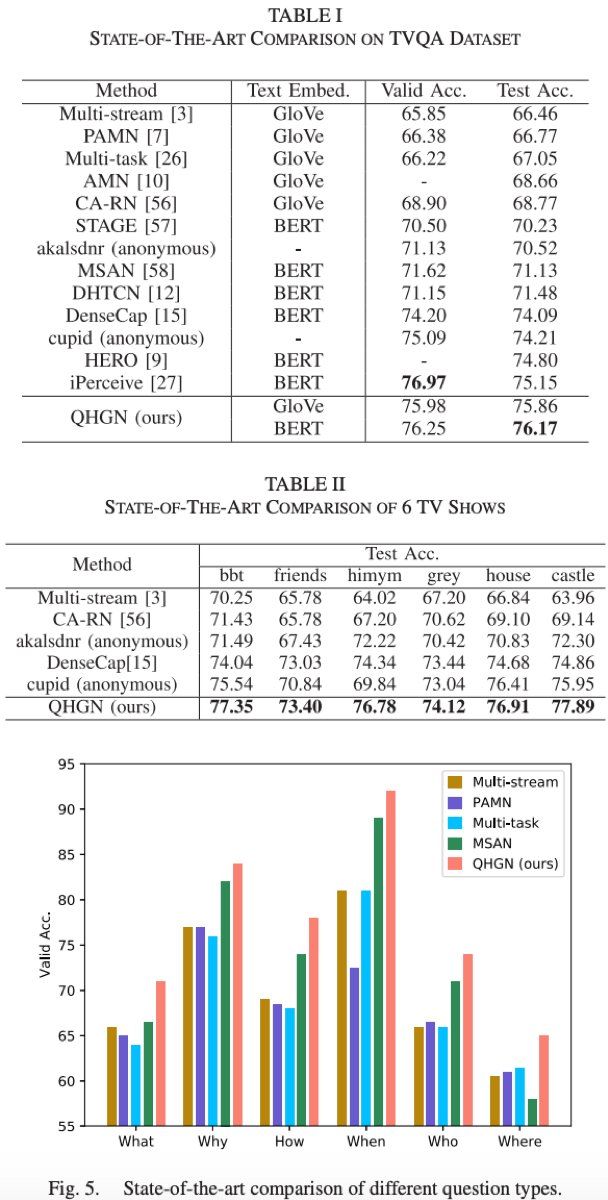
4.TVQA数据集上的评测结果
5.TVQA数据集的预测可视化


 京公网安备11010802017125号
京公网安备11010802017125号