
2023年论文导读第一期
【论文导读】2023年论文导读第一期
CCF多媒体专委会 2023-01-10 11:13 发表于吉林


论文导读
2023年论文导读第一期(总第六十七期)
目 录
|
1 |
Frame-wise Cross-modal Matching for Video Moment Retrieval |
|
2 |
Heterogeneous Hierarchical Feature Aggregation Network for Personalized Micro-video Recommendation |
|
3 |
Multi-Modal Variational Graph Auto-Encoder for Recommendation Systems |
|
4 |
Multi-Modal Meta Multi-Task Learning for Social Media Rumor Detection |
|
5 |
Collaborative Learning With a Multi-Branch Framework for Feature Enhancement |
|
6 |
Unpaired Image Captioning With semantic-Constrained Self-Learning |
01
Frame-wise Cross-modal Matching for Video Moment Retrieval
作者:唐昊煜1,祝继华2,刘萌3,高赞4,程志勇4#
单位:1山东大学,2西安交通大学,3山东建筑大学,4齐鲁工业大学(山东省科学院)
邮箱:
tanghao258@sdu.edu.cn;
zhujh@stu.xjtu.edu.cn ;
mengliu.sdu@gmail.com;
zangaonsh4522@gmail.com;
jason.zy.cheng@gmail.com
论文:
https://ieeexplore.ieee.org/abstract/document/9374685
代码:
https://github.com/tanghaoyu258/ACRM-for-moment-retrieval
#通讯作者
引言:
基于查询的视频时刻定位研究旨在给定一个查询的条件下从未经裁剪的长视频中寻找到与查询描述最为匹配的片段,是多媒体计算领域在近几年引起关注的重要任务。现有方法对于跨模态关联语义信息利用不足,且对于视频片段内部帧与查询之间的关联信息挖掘不足。为了解决上述问题,我们首先强调了跨模态关联信息构建的重要性,然后基于相似性和距离度量提出针对此任务的跨模态关联语义信息构建方法,同时利用视频帧与查询单词之间的细粒度注意力来进一步挖掘二者之间的跨模态关联语义;设计了视频片段内部帧预测器以实现视频片段内部帧与查询语义之间的最大化跨模态语义关联。

方法:
如图2所示,提出的方法包含特征提取、细粒度注意力、跨模态关联与边界和内部帧预测四个模块。
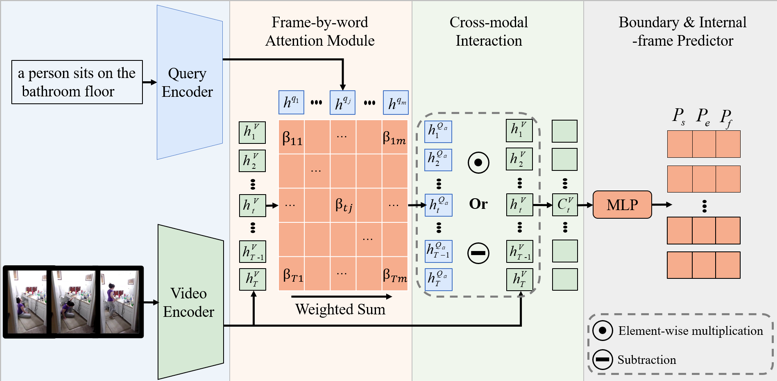
图2 所提出方法模型图
在分别提取视频帧和查询单词序列特征后,我们计算视频帧-查询单词之间的细粒度注意力以得到关于特定帧的全局查询表示。通过全局查询表示和视频帧之间的相似性计算或距离度量得到视频和文本的跨模态关联语义表示,最后利用内部帧预测模块挖掘所需视频片段与查询文本语义之间的最大化跨模态关联。
实验结果:
本文选择Charades-STA和TACOS两个数据集验证所提出方法的有效性。本文使用了R@n, IoU=m和mIoU两个评价指标。从表1可以看出,所提出的方法在使用不同相似度和距离度量方式时,相比于现有方法均在所有的评价指标上取得了很大的定位性能提升;从表2消融实验结果可以看出,所提出的细粒度注意力、跨模态关联、内部帧预测三个模块均能有效挖掘跨模态语义关联信息并提升模型的视频定位性能。
表1 所提出方法在TACOS数据集上的视频定位结果对比
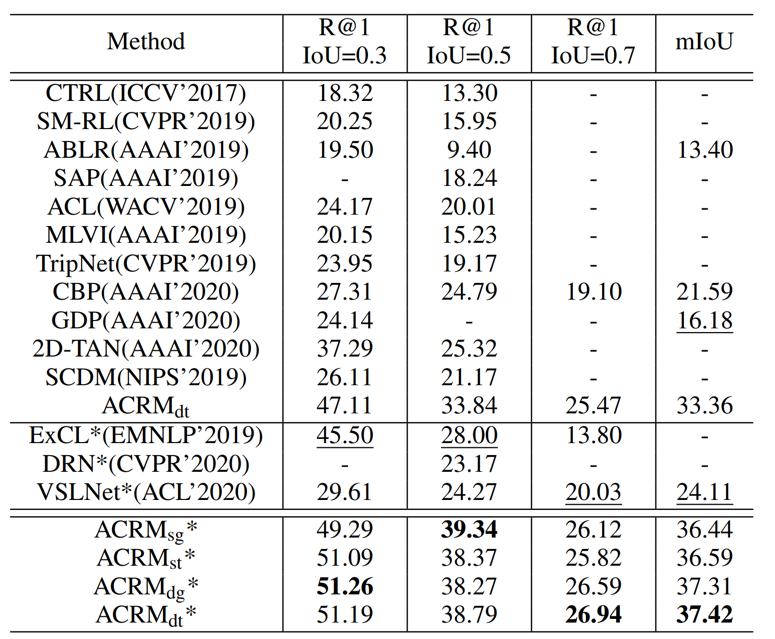
表2 所提出方法在Charades-STA和TACOS数据集上的消融结果对比
通过图3可视化结果可以看出,所提出的方法能通过捕捉视频文本注意力以有效提升内部视频帧的重要程度,实现精准视频定位。
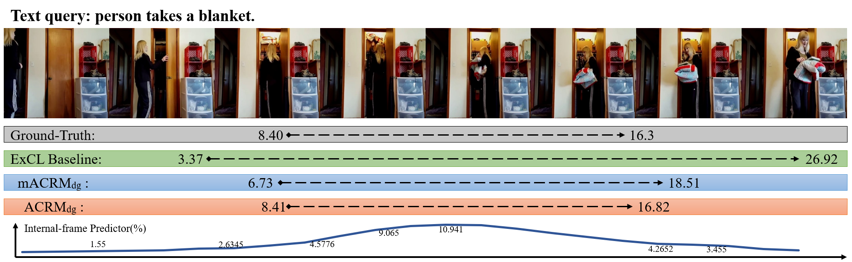
图3 所提出方法的视频定位可视化
02
Heterogeneous Hierarchical Feature Aggregation Network for Personalized Micro-video Recommendation
作者:蔡德胜1 , 钱胜胜2,3 ,⽅全2,3 ,徐常胜 *,2,3
单位:1 合肥⼯业⼤学, 2 中科院⾃动化研究所, 3 中国科学院⼤学
邮箱:
caidsml@gmail.com;
shengsheng.qian@nlpr.ia.ac.cn;
qfang@nlpr.ia.ac.cn;
csxu@nlpr.ia.ac.cn
论文:
https://ieeexplore.ieee.org/document/9360479
*通讯作者
1. 研究背景
随着移动互联⽹技术的快速发展,短视频分享平台,如快⼿和抖⾳,也变得越来越受⼤众欢迎。同时,短视 频推荐算法也逐渐受到学术界和⼯业界的⼴泛关注。
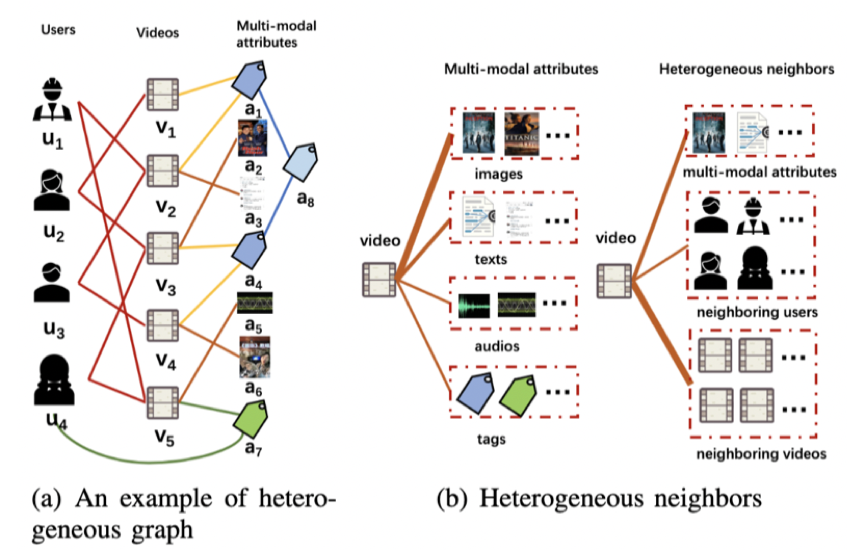
图1
传统的推荐算法主要是利⽤⽤户的历史交互数据或者原始属性特征数据进⾏表示学习,并⽤于对⽤户的短视 频推荐过程。最近的出现的基于图神经算法的推荐算法可以进⼀步利⽤历史交互关系数据构建graph挖掘隐藏的⾼ 阶关系⽤于提升推荐效果。然后这些算法仍然有以下限制:1. 忽视了数据中丰富的异构关系对⽤户和短视频表示 学习的作⽤。如图1(a)所示,异构关系包括交互关系(历史交互数据),包含关系(⼦标签和⽗标签之间的关 系)和共现关系(短视频和其属性之间的关系);2. 没有考虑同构数据和异构数据对表示学习的不同影响。如图1 (b),⼀个短视频可以包含多个同构邻居和异构邻居,不同邻居数据与短视频相关程度是不⼀样的。
2. 研究⽅法
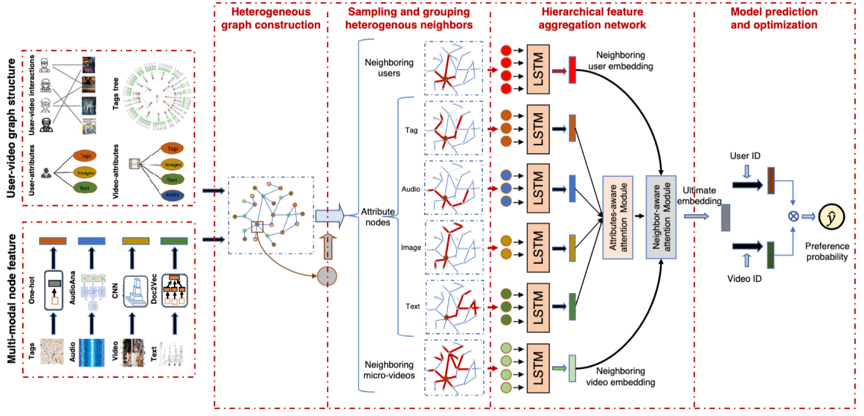
图2 框架图
为了解决上述问题,我们设计了层次异构特征聚合⽹络⽤于短视频推荐任务。核⼼是设计异构图,考虑多种异构节 点和关系数据进⾏表示学习。我们的模型主要包括:异构信息⽹络的构建,采样和分组异构邻居节点,层次特征聚 合⽹络和模型的优化和预测。
异构信息⽹络的构建(heterogeneous graph construction): 构建包括⽤户,短视频,对应的属性数据以及属性之间的关系的异构图G
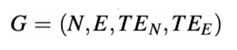
采样和分组异构邻居节点(sampling and grouping heterogeneous neighbors): 利⽤随机游⾛算法,获取当前节点的所有邻居节点,按照频率进⾏筛选,并根据节点类型解析分类。
层次特征聚合⽹络(hierarchical feature aggregation network): 对于同类节点,利⽤关于属性的⾃注意⼒机制进⾏节点聚合;对于异构节点,利⽤关于邻居的注意⼒机制进⾏聚合。最终获得⽤户和短视频的有效表示。

模型的优化与预测(model prediction and optimization): 推荐预测是基于学到的⽤户和短视频的表示进⾏点击概率计算。训练优化⽅法是基于负采样策略的BPR⽬标,其中我们设计了基于距离的负采样的⽅式。
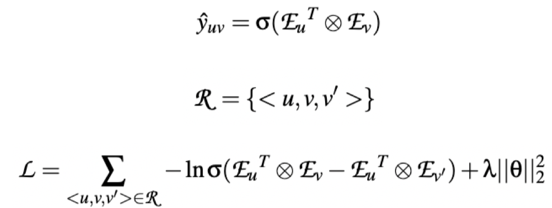
3.实验结果
数据集:从现实世界中收集整理的三个短视频推荐数据集
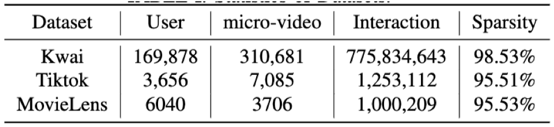
与基准算法的对⽐:我们的模型结果优于其他算法
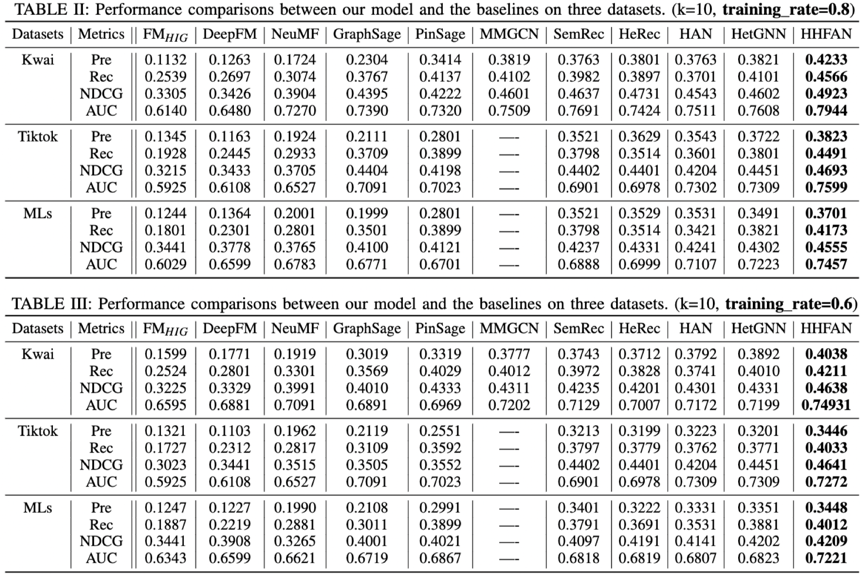
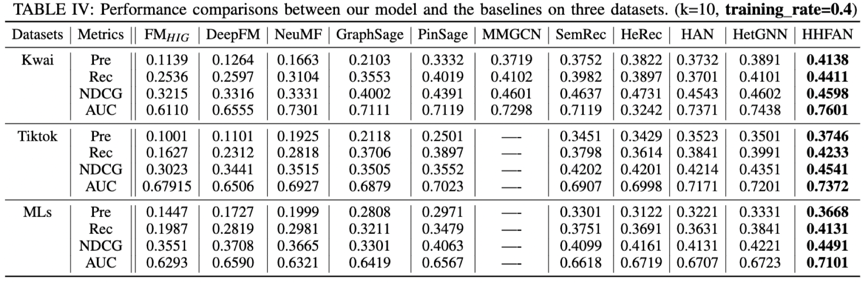
消融分析:结果证明我们的模型每个关键部分都是有效的。
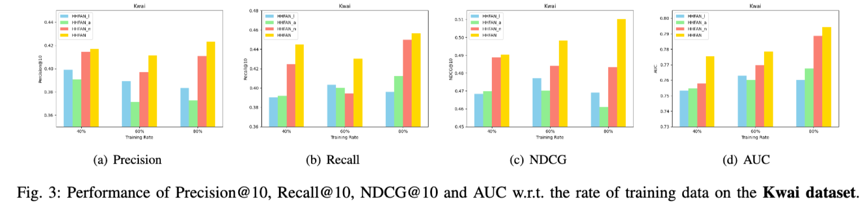
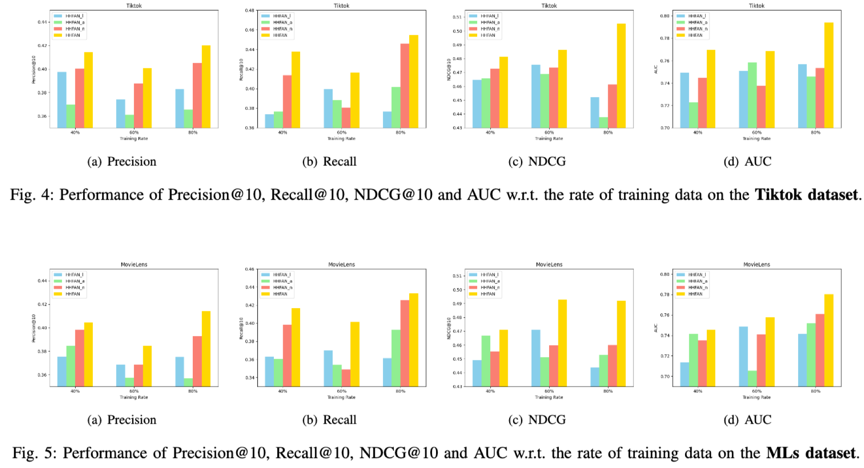
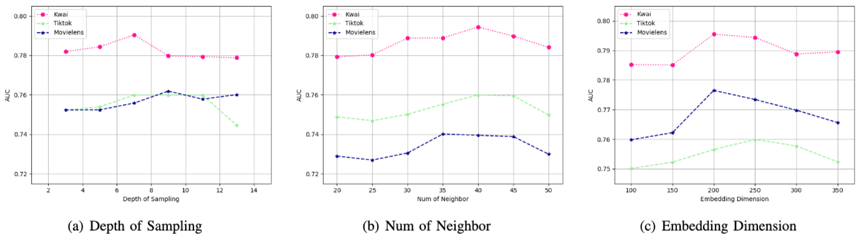
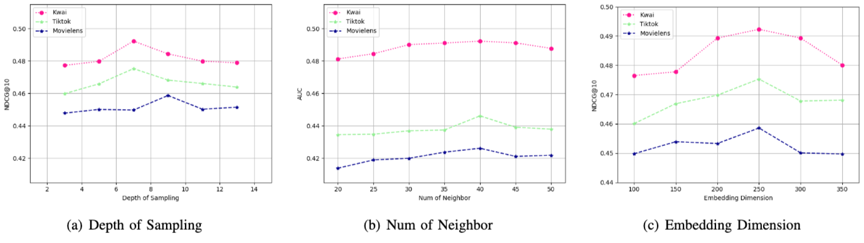
参数分析:模型各种相关的关键参数分析结果。
03
Multi-Modal Variational Graph Auto-Encoder for Recommendation System
作者:易静,陈震中*
单位:武汉大学
邮箱:
yijing-v@whu.edu.cn
zzchen@ieee.org
论文:
https://doi.org/10.1109/TMM.2021.3111487
*通讯作者
引言
如今推荐系统已成为在线服务平台不可或缺的一部分。庞大的用户物品量使得基于用户-物品交互矩阵建模的协同过滤模型难以取得最优的性能。随着在线多媒体越来越流行和普遍,利用物品的多模态内容辅助建模可以很好的缓解推荐系统稀疏性的问题。
研究动机
现有方法在利用多模态信息时存在以下问题建模不充分:1)基于隐因子模型的方法得到的嵌入具有不确定性;2)物品多模态内容中有大量的噪声以及与推荐不相关的内容;3)物品不同模态的内容有不同程度的噪声;4)模态缺失不可避免。
考虑到以上的挑战,本文提出了多模态变分图自编码器(MVGAE)用于推荐。首先,本文将用户和物品节点建模为高斯变量,其中,高斯变量的均值向量表示学到的语义信息,而方差向量表示对该节点的不确定性估计。通过显式建模用户和物品节点的方差,本文考虑了嵌入的不确定性,并在训练过程中给均值向量注入方差大小的噪声,从而实现对交互稀疏性和物品内容噪声的鲁棒性。其次,本文推导出多头乘积(PoE)的形式来融合各个模态学到的隐变量。该PoE形式通过利用方差的倒数对均值向量进行加权,可以给包含更少噪声的模态更高的权重。除此之外,PoE形式可以很好的解决测试时模态缺失的问题。
方法概述
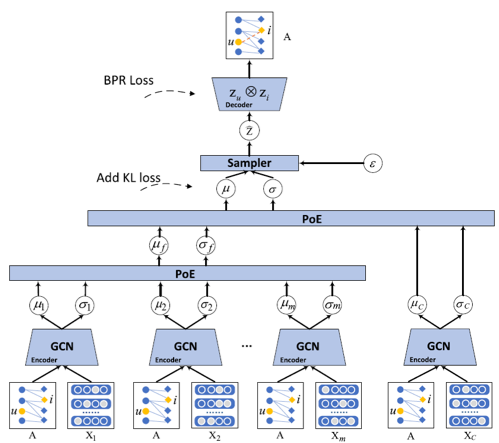
图1 MVGAE框架图
MVGAE的框架如图1所示。首先,本文使用模态特定的编码器来推断模态特定的潜在变量。各模态的特征和用户-物品邻接矩阵被基于GCN的编码器编码到模态特定的服从高斯分布的潜在变量中。其次,本文假设各模态条件独立,并推导出PoE的融合形式。具体的,联合隐变量的后验是各模态隐变量后验的乘积。由于本文使用高斯分布建模,该PoE形式有显示解,其中,学习语义信息的均值向量本质上利用各模态方差的倒数对其均值向量进行加权求和。同时,本文建模仅基于协同信息的隐变量,并利用PoE形式融合其与多模态联合隐变量。最后,一个点积解码器被用来重建用户-物品邻接矩阵。
实验结果
表1 MVGAE和其他baseline的结果

本文在Amazon-Movies,Amazon-Electronics和AliShop三个数据集上验证了MVGAE的有效性。从表1中可以看到,本文提出的MVGAE性能优于其他研究方法。
表2 各单模态和多模态模型的Recall结果
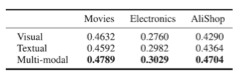
表3 不同多模态融合方法的Recall结果
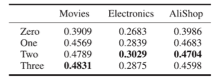
表4 测试阶段模态缺失的Recall结果(V和T分别表示视觉和文字模态)
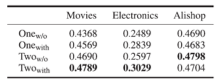
从表2中可以看出本文提出的多模态方法要优于只使用单模态的方法,验证了利用多模态信息的有效性。表3说明了相比于其他的多模态融合方法,PoE表现最好,证明了其有效性。从表4可以看出本文的方法对于测试时模态缺失具有很好的鲁棒性。
04
Multi-Modal Meta Multi-Task Learning for Social Media Rumor Detection
基于多模态元多任务学习的社交媒体谣言检测
作者:张怀文1,2,钱胜胜1,2,方全1,2,徐常胜1,2,3#
单位:
1中国科学院自动化研究所模式识别国家重点实验室
2中国科学院大学人工智能学院
3鹏城实验室
邮箱:
huaiwen.zhang@nlpr.ia.ac.cn
shengsheng.qian@nlpr.ia.ac.cn
qfang@nlpr.ia.ac.cn
csxu@nlpr.ia.ac.cn
论文:
https://ieeexplore.ieee.org/document/9376933
#通讯作者
随着社交媒体平台的快速发展,社交媒体数据规模的不断扩大。由于社交媒体帖子的真实性无法保证,谣言检测任务变得越来越重要。如果没有准确和系统的方法来验证这些帖子,社交媒体谣言的传播可能会造成大规模的负面影响。最近,一系列新颖的基于多任务学习的方法被提出,致力于在谣言检测任务中引入用户回复的立场信息。随着谣言的传播,总会出现质疑和反对的声音,这些声音可以作为信息真实性的有用标志。然而,现有的方法大多存在以下局限性: 1)只关注文本内容,忽略了社交媒体数据中包含的关键成分-多模态信息;2)忽略了立场检测任务与谣言检测任务在特征空间上的差异,导致立场信息的利用不充分;3)很大程度上忽略了细粒度立场标签中隐含的语义信息。
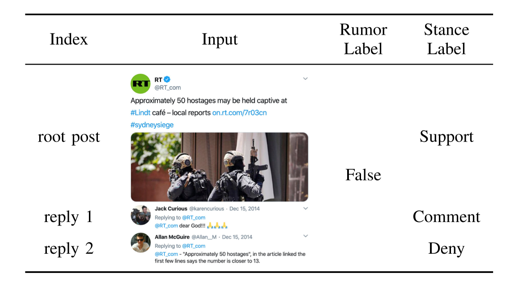
图 1 谣言检测和立场检测的任务差异
因此,本文设计了一种用于社交媒体谣言检测的多模态元多任务学习(MM-MTL)框架:
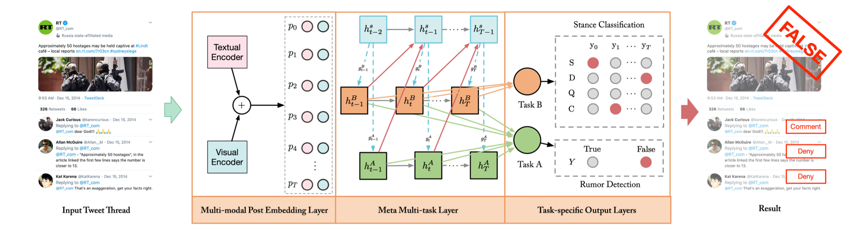
图 2 基于多模态元多任务学习的谣言检测
为了利用多模态信息,我们设计了一个同时考虑文本和视觉内容的多模态嵌入层。为了克服立场检测任务和谣言检测任务的特征共享问题,本文提出了一种元知识共享方案,通过共享更高的元网络层来建模多模态帖子背后的元知识。为了更好地利用隐藏在细粒度立场标签中的语义信息,模型进一步采用注意力机制来估计每条回复的权重。
表 1 基于多任务学习的谣言检测方法对比
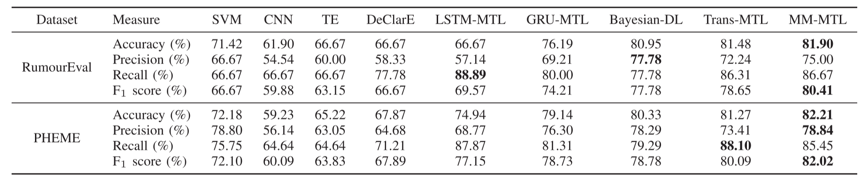
在两个Twitter基准数据集上进行的实验表明,所提出方法在社交媒体谣言检测任务上取得了更好的性能。
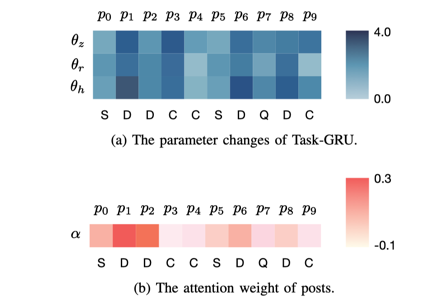
图 3 (a)任务网络的参数变化。(b) 事件中各帖子的注意力。
我们将元网络层生成的任务层参数的变化,以及事件中各帖子的注意力进行可视化。可以观察到在判定给定事件时,任务网络在面对帖子立场转变时,参数变化灵活,模型聚焦在若干连续持否定立场的帖子上。证明了多模态元多任务学习在建模事件、跟踪事件发展上的优越性。
05
Collaborative Learning With a Multi-Branch Framework for Feature Enhancement
作者:栾晓,赵圆圆,刘玲慧,李伟生,舒禹程,耿弘民
单位:重庆邮电大学
邮箱:
luxiao@cqupt.edu.cn,
zyy31213121@gmail.com
论文:
https://ieeexplore.ieee.org/document/9362279
代码:
https://github.com/zyyupup/BranchNet/
在计算机视觉领域诸如图像分类,目标检测,语义分割等研究课题中,如果网络模型的特征表征能力不强,则很可能在训练过程中只能对图像的部分特征进行拟合。因此提升神经网络的特征表征能力是取得优秀性能的关键。为了得到具有更强的特征表征能力的模型,许多研究者关注于如何不断增加卷积神经网络的深度,同时避免梯度消失等问题。但常见的层堆叠卷积神经网络模型由于多次下采样,不可避免地会受到特征图尺度在前向传播过程中缩减带来的信息损失。本文关注如何增强神经网络的多尺度表达能力,基于深监督模型和协同学习提出了一个新颖的多分支网络结构,以达到特征表达增强效果。
下图是基于上述观点提出的BranchNet(带有三个分支单元)结构示意图
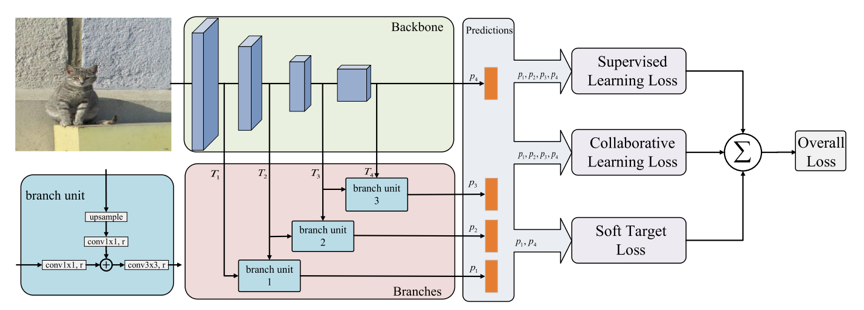
得到网络的深监督损失函数公式:
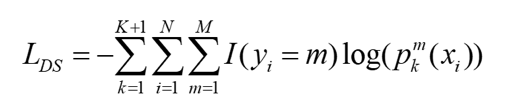
为了进一步增强特征表征,本文设计了三种损失函数同时监督模型训练,分别是:深监督学习损失、协同学习损失、软目标损失。
由于浅层网络输出的图像特征与深层特征具有相同的优化目标,所以本文采用KL散度度量以减小不同分支的概率分布的距离,引入协同学习将深层的语义信息传递给浅层网络。
得到协同学习损失:
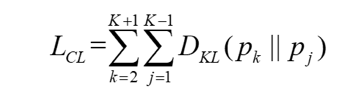
同时,由于多分支网络结构有多个输出结果,每个输出所对应的卷积层深度不一样,因此其性能表现也有差异。故本文提出一个软目标损失函数来缩短这个差距。软目标策略是在知识蒸馏中广泛应用的策略,以达到将信息从复杂的网络模型传递至简单而小规模的网络模型中。
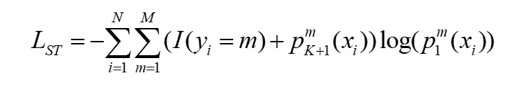
至此得到BranchNet的总损失函数:
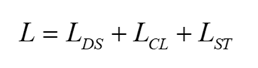
在CIFAR和ImageNet上对BranchNet方法进行了实验:
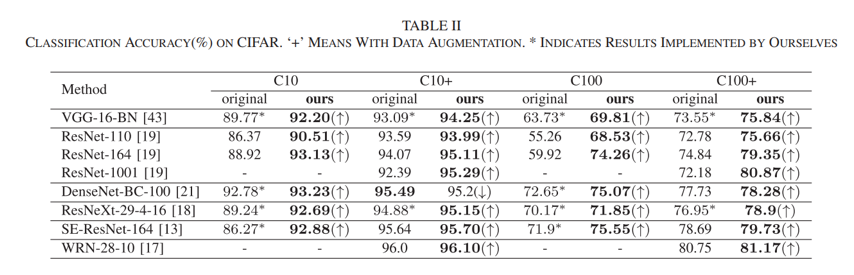
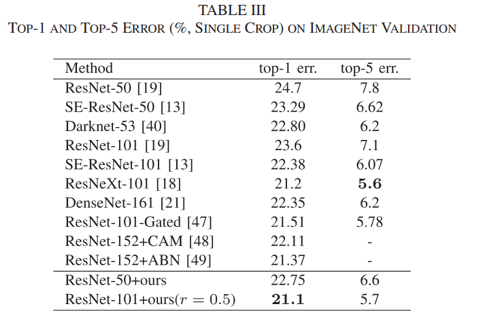
可以看到将提出的方法结合ResNet,VGG等网络模型的表现,分别在CIFAR上的分类准确率和在ImageNet上的测试误差率分别有一定的提升和降低。
同时在实例分割任务上,也在COCO数据集上进行了实验:
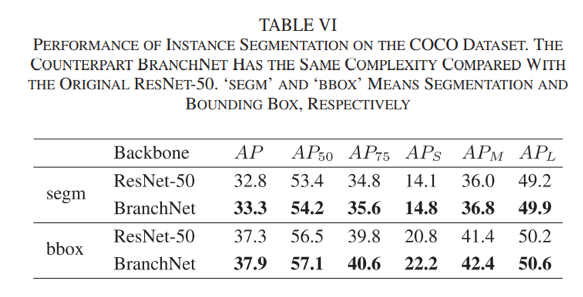
本方法在AP上的表现超出ResNet-50有0.5个百分点,此外本方法在小、中和大目标的精度均超过ResNet-50。这证明本方法在实力分割任务上也有稳定的性能提升。
为了验证本文方法对特征表达增强的有效性,对不同尺寸的特征响应图进行了可视化。
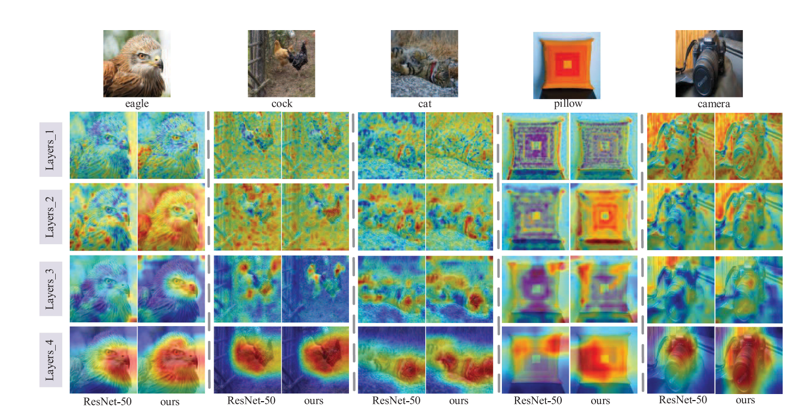
06
Unpaired Image Captioning With semantic-Constrained Self-Learning
基于语义约束的无监督自学习图像描述生成
作者:贲辉霞1,潘滢炜2,李业豪2,姚霆2,洪日昌1,汪萌1,梅涛2
单位:1合肥工业大学;2京东科技
邮箱:
huixiaben@gmail.com
panyw.ustc@gmail.com
yehaoli.sysu@gmail.com
tingyao.ustc@gmail.com
hongrc.hfut@gmail.com
eric.mengwang@gmail.com
tmei@live.com
论文:
https://ieeexplore.ieee.org/document/9362305
由于图像描述生成中的大部分工作都依赖于大量成对的图像和文本训练数据集,一方面这些成对的图像文本数据集的获取是极为昂贵且耗时的,另一方面,过分依赖成对的图像文本数据集,阻碍了图像描述生成器在自然场景中的实际应用。为了消除图像描述生成器对注释文本的依赖,最近的研究开始探索以无监督的方式训练图像描述生成模型。
针对无监督的图像描述生成中的两个困难,一是如何训练没有文本标记的图像,二是如何在无监督状态下确保生成的句子的质量,我们提出一种基于语义约束的图像描述生成框架(图1),采用迭代自学习策略用未成对的图像和文本数据集训练图像描述生成器。该框架包括两个交替迭代进行的阶段,即生成伪注释文本和将伪注释文本与图像耦合构造伪图像文本对用以训练图像描述生成器。图像中被识别的对象作为语义约束用以加强输入图像和输出句子间的语义对齐,指导整个框架的两个阶段训练。我们利用语义约束波束搜索生成伪文本注释,通过有限状态机在输出文本中添加已识别的对象同时排除不相关的对象来规范图像中识别对象的解码过程,提高生成的伪注释文本与图像的关联性。对于图像描述生成器的迭代训练,我们首先利用交叉熵在构造的伪图像文本对下以有监督的方式训练,继而使用自监督三元组来保持生成文本三元组关于输入图像三元组的相对语义的相似性排序。此外采用自批判性训练,利用对象包含奖励和对抗奖励分别鼓励输出文本中包含预测对象以及追求生成更为真实的句子。
在图像描述生成领域的最大数据集MSCOCO上,表1总结了我们的框架(SCS)比其他最先进的方法(Con2sen,Recons-Align,Embed-Align,Graph-Align)表现出更好的性能,特别是,我们SCS的性能在两个主要指标METEOR和CIDEr分数可以达到21.4%和74.7%,使得相对于最佳竞争对手的相对改善率分别达到2.4%和7.5%。图2 展示了MSCOCO数据集中六幅图像的识别对象、通过不同方法生成的句子以及人工标注的句子(GT)示例,从这些示例结果可以很容易地看出,由我们的框架(SCS)训练的图像描述生成器可以预测更多与图像相关的句子。实验结果证明了自学习的优势,交替进行伪图像文本对生成和图像描述生成器再训练的过程,随着学习周期的进行,逐步提高了图像描述生成器的理解能力。该研究方法已应用在多个标准数据集和多种语言数据集,均展现出领先的性能。
我们的研究主要提出一种基于语义约束的无注释图像描述生成自学习框架,提供了如何使用非成对的图像数据集和文本数据集的方法,以及图像描述生成如何从语义对象中更大化获益。
表1 我们的框架SCS和其他最先进的方法在MSCOCO中的性能比较
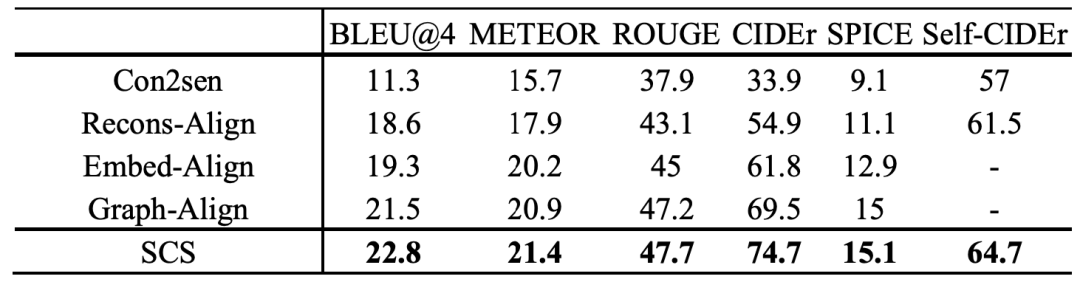

图1 基于语义约束的无监督图像字幕自学习模型示意图
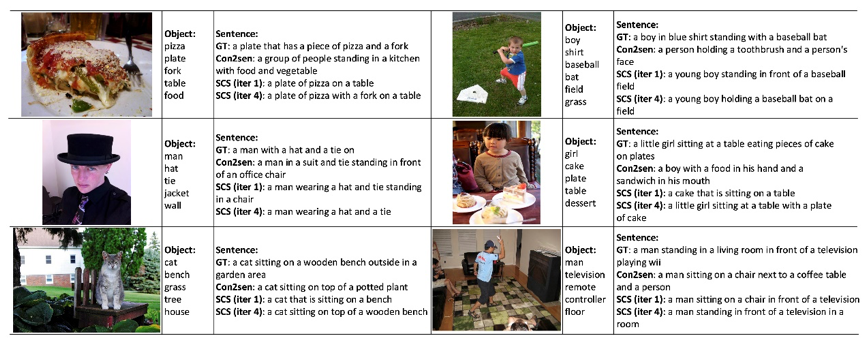
图2 MSCOCO数据集中识别对象和句子生成结果示例

 京公网安备11010802017125号
京公网安备11010802017125号