
2023年论文导读第八期
【论文导读】2023年论文导读第八期
CCF多媒体专委会 2023-04-25 09:00 发表于北京


论文导读
2023年论文导读第八期(总第七十四期)
目 录
|
1 |
Interpretable Multi-Modal Image Registration Network Based on Disentangled Convolutional Sparse Coding |
|
2 |
Fuzzy Semantics for Arbitrary-Shaped Scene Text Detection |
|
3 |
Adaptive Latent Graph Representation Learning for Image-Text Matching |
|
4 |
CMOS-GAN: Semi-Supervised Generative Adversarial Model for Cross-Modality Face Image Synthesis |
|
5 |
Vine Spread for Superpixel Segmentation |
|
5 |
CAVER: Cross-Modal View-Mixed Transformer for Bi-Modal Salient Object Detection |
01
Interpretable Multi-Modal Image Registration Network Based on Disentangled Convolutional Sparse Coding
基于解耦卷积稀疏编码的可解释多模态图像配准网络
作者:邓欣1,刘恩鹏2,李胜曦2,段一平3,徐迈2,*
单位:1北京航空航天大学网络空间安全学院,2北京航空航天大学电子信息工程学院,3清华大学电子工程系
邮箱:
cindydeng@buaa.edu.cn;
lep666@buaa.edu.cn;
论文:
https://ieeexplore.ieee.org/abstract/document/10034541
代码:
https://github.com/lep990816/Interpretable-Multi-modal-Image-Registration
*通讯作者
1 摘要
多模态图像配准旨在对来自不同模态的图像进行空间对齐,使得它们的特征点彼此匹配。由于拍摄设备或传感器的差异,不同模态的图像往往包含许多不同类型的特征,这使得配准任务变得具有挑战。随着深度学习的发展,研究者们提出了很多神经网络来解决这一问题,但这些模型往往缺乏可解释性。本文首先提出一种解耦卷积稀疏编码(DCSC)模型,用来建模不对齐的多模态图像。在建模过程中,我们将有利于配准的RA特征与不利于配准的nRA特征进行分离,再利用RA特征进行形变场预测,进而消除nRA特征的干扰,以提高配准的精度与效率。进一步地,我们将DCSC模型分离RA和nRA特征的优化过程被转化为一个深度网络,即可解释的多模态图像配准网络(InMIR-Net)。同时,为了确保RA和nRA特征的准确分离,我们进一步设计了一个辅助引导网络(AG-Net),以监督InMIR-Net中RA特征的提取。InMIR-Net的优点是它提供了一个通用框架来处理刚性和非刚性多模态图像配准任务,在大量的多模态图像数据集上均取得了极好的配准效果。
2 背景
现实世界中的图像处理和计算机视觉任务通常涉及来自不同模态的图像,例如 RGB 和深度图像、RGB 和近红外图像、T1/T2 核磁共振图像(MRI)等。对于很多多模态图像处理任务,多模态图像对间的配准精度往往决定了这些任务的效果上限,为保证后续多模态图像处理任务的可靠性,亟需精确有效的多模态图像配准(MIR)。然而,受限于拍摄设备、时间、环境等因素,不同模态图像的分辨率、质量、配准程度各不相同,所蕴含的信息差异较大,因此,与传统的单模态图像配准相比,由于不同模态之间的复杂关系,MIR 任务更具挑战性。单模态场景中常用的配准技术,如光流估计[1]、形状匹配[2],以及基于强度、梯度或结构相似性[3]的方法对于多模态场景并不适用。现有的一些多模态图像配准的方法大多依赖于优化某个相似性指标,例如互信息[4]、相关比[5]和结构特征描述符[6],通过最大化不同模态之间的相似性,实现精度较高的配准,然而这些方法往往需要大量的迭代,且计算复杂度十分巨大。另一方面,对于深度学习的方法,主要可分为两个思路,一是通过深度神经网络,提取多模态图像的特征图,并通过优化某些相似性度量指标实现高效的配准[7-9],这些方法虽然运行时间大幅加快,但高度依赖于相似性指标,往往只在某一指标上表现优异;另一种方法则是通过生成对抗网络(GAN)将不同模态转换到统一模态,将该任务变为单模态的配准[10-12],但是这些方法难以训练,还会引入噪声,同时无法打开深度学习的“黑盒子”,缺乏可解释性。因此,如何可解释地实现多模态图像配准,是一项亟待解决的挑战。
3 方法
DCSC模型
假设Ix与Iy代表两幅未对齐的多模态图像,根据DCSC模型,可以对两图进行如下建模:
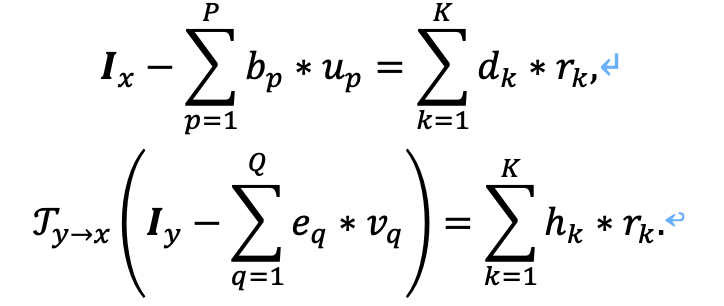
我们使用卷积稀疏表示模型对RA与nRA特征对图像进行表征,其中,{bp}Pp=1,{dk}Kk=1是两部分特征对应的卷积字典,{eq}Qq=1,{hk}Kk=1是Iy两部分特征对应的卷积字典,而{up}Pp=1,{vq}Qq=1,{rk}Kk=1则分别对应Ix的nRA特征的卷积稀疏响应系数,Iy的nRA特征的卷积稀疏响应系数,以及两者RA特征共享的卷积稀疏响应系数,如此建模的核心思想便是两幅不对齐多模态图像Ix与Iy的RA特征共享相同的卷积稀疏表示系数(CSR),即{rk}Kk=1,这样便可以将两个模态间的信息进行耦合,将两个模态关联起来。
DCSC模型求解
根据卷积稀疏表示的基础理论,得到如下的全局优化目标:
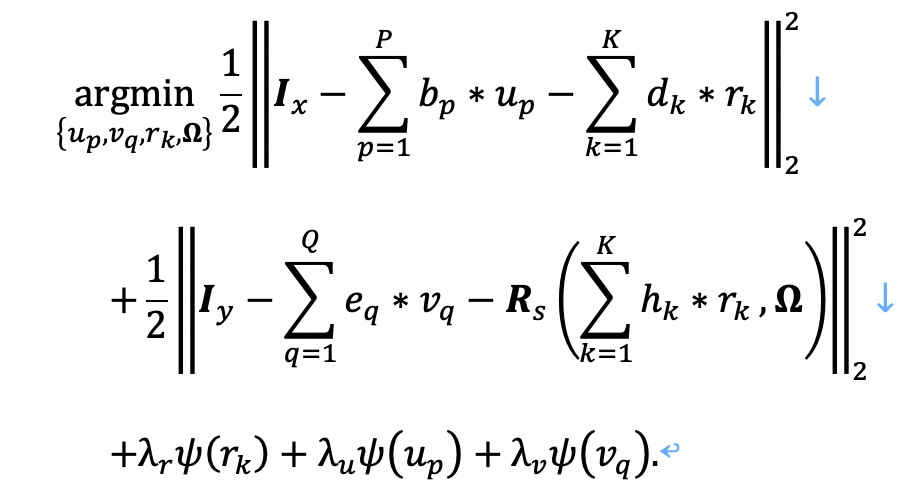
其中,我们使用一个固定的采样器Rs,以及形变场Ω来表示Ƒx➝y(·),其中形变方式既包括刚性又包括非刚性,即Ω={H,ψ}, Rs={RsH, Rsψ}。另外,ψ(·)是约束CSR稀疏性的函数,通常可由L1范数进行约束,λr,λp, λq是不同CSR的正则化系数。正如公式3.3所示,其中共有4个需要求解的变量,即{up}Pp=1,{vq}Qq=1,{rk}Kk=1,以及形变场Ω。其中,我们使用一个神经网络模型来求解Ω,为求解剩余三个变量,使得公式3.3具有全局最优解,我们采用迭代更新求解的方法,即求解某一变量时,固定其他变量。进而根据[13],将求解过程转化为如图1种的可解释神经网络模块,即nRA FPM以及RA FPM模块。
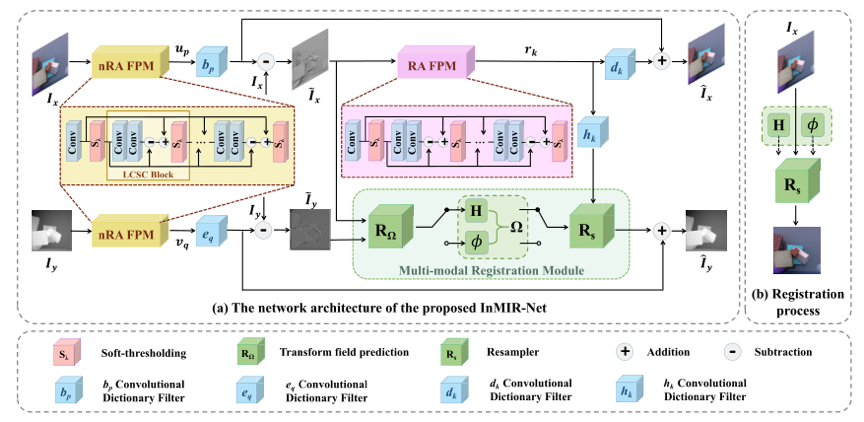
图1 InMIR-Net结构示意图
多模态配准模块:
该模块主要由两部分组成,即形变场预测模块RΩ,以及形变模块Rs,其中,RΩ主要根据输入的两幅不对齐的图像预测其对应的空间位置关系Ω,包括刚性形变场,用H矩阵描述,非刚性形变场ψ,即RΩ={RΩH, RΩψ};Rs则是根据输入的图像以及空间形变场进行图像空间变换,得到配准后的图像。
最终通过InMIR-Net,可以得到重构后的图像\hat{Ix}与\hat{Iy}:
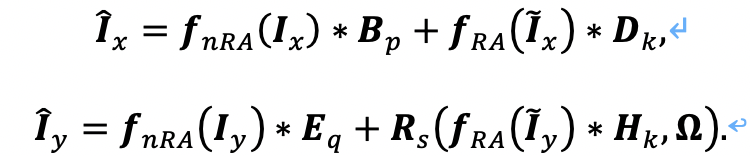
其中,代表nRA特征提取模块,fRA代表RA特征提取模块,Rs代表空间变换模块Bp,Dk,Eq,Hk,是卷积字典,最终配准后的图像可表示为:
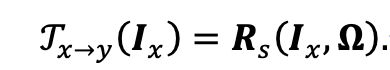
进而,可推导出如图1所示的InMIR-Net的整体框架,图中各个模块均由数学公式推导得出,具备良好的可解释性与鲁棒性。
4 实验及结果分析
配准结果:
本文在几个多模态数据集上验证了InMIR-Net在两种配准模式下的有效性,其中刚性的单应性估计任务应用到的多模态类型包括彩色-深度图像、彩色-多光谱图像、彩色-近红外图像;非刚性配准任务应用到的多模态类型包括医学核磁共振T1-T2图像、核磁共振-CT图像。图2与图3分别展示了两种配准模式下InMIR-Net与其他算法的对比结果,对于单应性估计任务,绿线代表不同算法所预测的坐标偏移,其越接近于代表真值的黄线,其预测越精确;而对于非刚性配准任务,从配准后图像与形变场均可明显看出InMIR-Net较其他算法的性能提升。

图2 不同数据集下的刚性配准结果比较
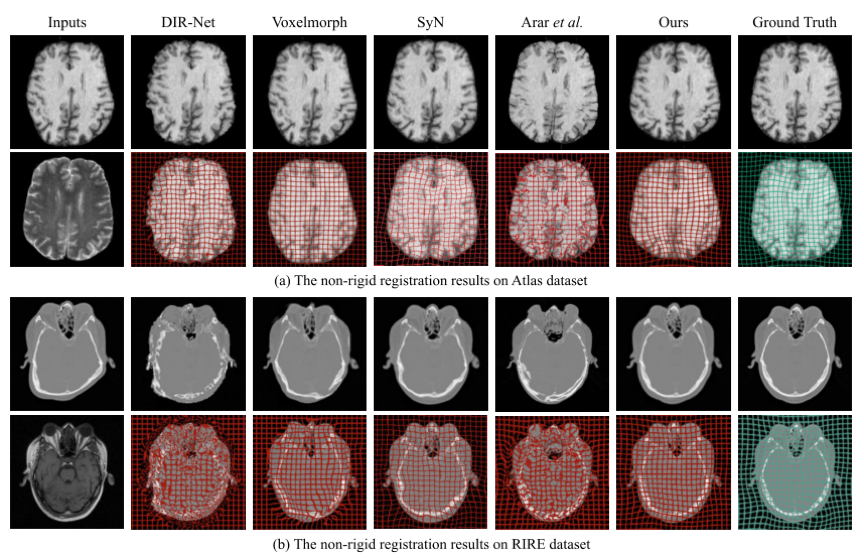
图3 不同数据集下的非刚性配准结果比较
特征提取结果:
根据DCSC模型,InMIR-Net能够合理地将RA特征与nRA特征进行分离,图4展示了本文算法对彩色-深度图像以及彩色-多光谱图像的特征分离结果,从图中可以明显看出,两模态共有的轮廓等特征在RA特征中得以保留,而内部纹理、色度等独有的信息则体现在nRA特征中。
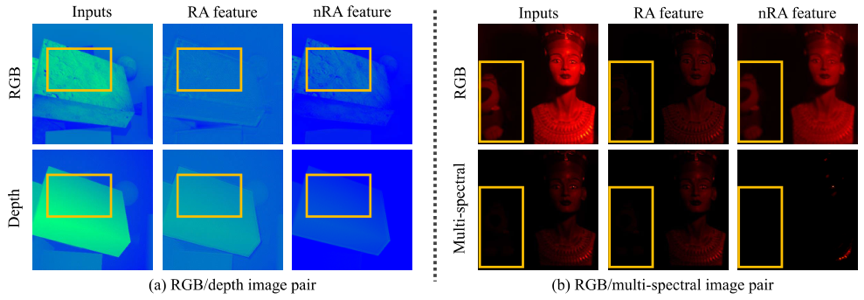
图4 不同数据集下RA与nRA特征分离结果示意图
5 总结
本文提出了一种面向多模态图像的可解释神经网络,InMIR-Net,通过所提出的DCSC建模方法,将不同模态间有利于配准任务(RA)的特征进行提取,并利用该特征进行形变场估计,可以高效实现两种模式的多模态配准任务,并在5个不同模态的数据集上进行了实验验证。另外,InMIR-Net作为一种通用框架,具有良好的可解释性与鲁棒性,可作为多模态图像任务的重要预处理阶段,插入到其他模型中,具有很广泛的应用价值。
参考文献:
[1] S. Jeon, S. Kim, D. Min, and K. Sohn, “PARN: Pyramidal affine regression networks for dense semantic correspondence,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 351–366.
[2] V. G. Kim, W. Li, N. J. Mitra, S. DiVerdi, and T. Funkhouser, “Exploring collections of 3D models using fuzzy correspondences,” ACM Transactions on Graphics (TOG), vol. 31, no. 4, pp. 1–11, 2012.
[3] X. Shen, L. Xu, Q. Zhang, and J. Jia, “Multi-modal and multi-spectral registration for natural images,” in European Conference on Computer Vision. Springer, 2014, pp. 309–324.
[4] W. M. Wells III, P. Viola, H. Atsumi, S. Nakajima, and R. Kikinis, “Multi-modal volume registration by maximization of mutual information,” Medical image analysis, vol. 1, no. 1, pp. 35–51, 1996.
[5] A. Roche, G. Malandain, X. Pennec, and N. Ayache, “The correlation ratio as a new similarity measure for multimodal image registration,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 1998, pp. 1115–1124.
[6] C. Bodensteiner, W. Huebner, K. J ̈ungling, J. M ̈uller, and M. Arens, “Local multi-modal image matching based on self-similarity,” in 2010 IEEE International Conference on Image Processing. IEEE, 2010, pp. 937–940.
[7] M. Simonovsky, B. Guti ́errez-Becker, D. Mateus, N. Navab, and N. Komodakis, “A deep metric for multimodal registration,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2016, pp. 10–18.
[8] B. D. de Vos, F. F. Berendsen, M. A. Viergever, H. Sokooti, M. Staring, and I. Iˇsgum, “A deep learning framework for unsupervised affine and deformable image registration,” Medical image analysis, vol. 52, pp. 128–143, 2019.
[9] X. Hu, M. Kang, W. Huang, M. R. Scott, R. Wiest, and M. Reyes, “Dual-stream pyramid registration network,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2019, pp. 382–390.
[10] C. Qin, B. Shi, R. Liao, T. Mansi, D. Rueckert, and A. Kamen, “Unsupervised deformable registration for multi-modal images via disentangled representations,” in International Conference on Information Processing in Medical Imaging. Springer, 2019, pp. 249–261.
[11] D. Mahapatra, B. Antony, S. Sedai, and R. Garnavi, “Deformable medical image registration using generative adversarial networks,” in 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018). IEEE, 2018, pp. 1449–1453.
[12] M. Arar, Y. Ginger, D. Danon, A. H. Bermano, and D. Cohen-Or, “Unsupervised multi-modal image registration via geometry preserving image-to-image translation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 13 410–13 419.
[13] H. Sreter and R. Giryes, “Learned convolutional sparse coding,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 2191–2195.
02
Fuzzy Semantics for Arbitrary-Shaped Scene Text Detection
作者:王芳芳1,2,徐晓刚1,2,陈怡峰2,李玺2
单位:1之江实验室,2浙江大学,3浙江工商大学
邮箱:
wangff@zhejianglab.com
xxgang2013@163.com
yifengchen@zju.edu.cn
xilizju@zju.edu.cn
论文:
https://ieeexplore.ieee.org/document/9870672
在处理任意形态文本检测问题时,自底向上的基于分割的方法具有较强的灵活性,有着广泛的应用。然而,文本区域当中的像素混合了笔划像素和背景像素,造成高度同质化的内部纹理,使文本区域并不具有天然清晰的语义边界。同时,场景当中的文本实例通常呈聚集性分布,导致模糊边界的文本区域发生堆叠和粘连。因此,如何在分割框架中得到清晰完整的实例分界线,将相互堆叠的相邻实例区分开来,是自底向上语义建模方法的一个突出难点,也是本文的研究重点。
针对上述问题,本文提出在自然场景图像中直接建模两种独立的模糊语义,即文本与文本实例分界线,并通过像素级别语义属性的可靠性分析,从冗余去除的角度来对文本目标进行发现。总体上,本方法设计一个端到端的分割框架对文本图像进行局部语义建模,稠密地进行像素语义分类以及每种语义的可靠性回归,框架结构图如图1。由于文本与分界线两种模糊语义并不严格互斥,二者在靠近语义边界的位置会有重叠,即一个像素属于文本或分界线的概率是相互独立的。因此,与普通语义分割进行的单标签分类不同,本方法利用两个独立分支分别进行文本/非文本分类以及分界线/非分界线分类。另外,本框架还采用两个额外的独立分支来分别进行文本和分界线的可靠性预测。在本文工作中,可靠性是基于像素到离它最近的语义边界的距离变换来定义,即一个像素离语义边界越近则其分类得分的可靠性就越低。在网络优化过程中,为了充分挖掘两种模糊语义,本方法提出一种跨图像归一化的焦点损失函数来平衡极度不均衡的正负像素点比例,并结合语义可靠性的指导来减轻不可靠像素给模型带来的影响。在测试阶段,像素的语义得分将根据可靠性进行重新计算来解决文本和分界线两种语义之间的竞争问题并判定最终的文本属性,检测结果则可通过在文本属性图上提取连通域的方法获得。图2直观地展示了本方法各分支输出结果以及本方法最终检测结果,其中初始检测为从单一文本分割图中提取的连通域结果,其文本实例粘连情况多发,最终检测为本方法获得的检测结果,实例粘连情况得到了很好的解决。
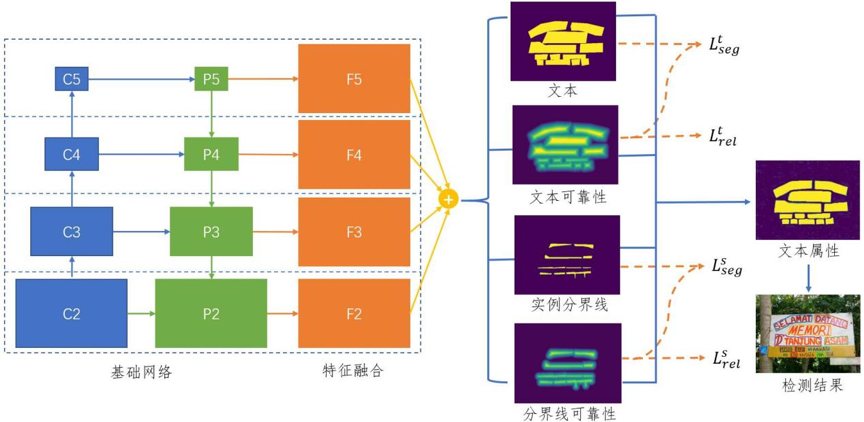
图1 框架结构图

图2 定性结果展示
03
Adaptive Latent Graph Representation Learning for Image-Text Matching
作者:田孟潇1,吴心筱1*, 2*,贾云得1, 2
单位:1北京理工大学,2深圳北理莫斯科大学
邮箱:
mengxiao_tian@bit.edu.cn;
wuxinxiao@bit.edu.cn;
jiayunde@smbu.edu.cn
论文:
https://ieeexplore.ieee.org/document/9991857/
代码:
https://github.com/Mengxiao-Tian/ALGR
*通讯作者
1. 引言
图文匹配旨在输入图像(文本),查询与之语义匹配的文本(图像),在跨模态检索、图像描述和视觉问答等领域已被广泛应用。现有大多数图文匹配方法通常将图像与文本映射到一个共同表示空间,衡量它们在此空间中的相似度。这些方法可以大致分为两类:(1)全局关联:将图像和文本的全局表示映射到共同空间进行相似度计算;(2)局部关联:学习图像区域和文本单词之间的细粒度语义对齐关系。然而,这些方法深受图像和文本中不相关实体关系的干扰,例如图像中与查询文本不相关的对象和背景区域,或文本中与查询图像不相关的噪声单词和短语,导致错误的图文匹配。为了解决上述问题,本文提出一种自适应潜在图表示学习方法,利用图结构化表征的变分解耦学习,克服噪声影响,实现不同模态的准确对齐。
2. 方法
如图2所示,本文方法有两个部分组成:图构建模块和图变分自编码器模块。图构建模块采用图结构,对图像和文本中实体之间的关系进行建模。图变分自编码器模块从采样重构过程中学习不同模态的潜在图表示,然后将各模态的潜在图表示映射到一个共同的嵌入空间。在该空间中,对这些表示进行语义对齐和分布对齐。对于语义对齐,通过利用跨模态注意力机制,自适应调整图像和文本的潜在表示之间的注意力权重,以关注较为重要的实体关系;对于分布对齐,通过最小化图像和文本的潜在表示之间的Wasserstein距离来减少它们之间的分布差异。
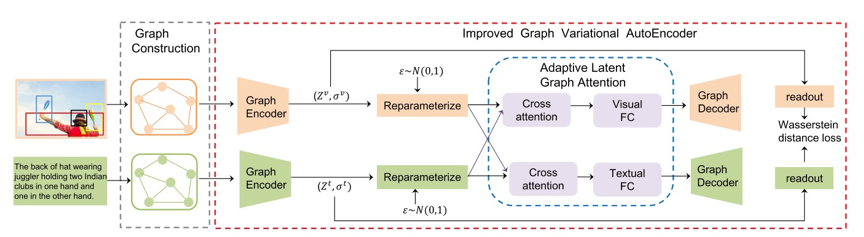
图2 潜在图表示学习
提出的语义失真度量应用于端到端图像编码框架中,如图2所示。该端到端图像编码框架将原始图像、重要性图以及它们的乘积作为网络的输入,并使用提出的语义失真度量进行网络优化,实现任务通用的图像编码。
4. 实验
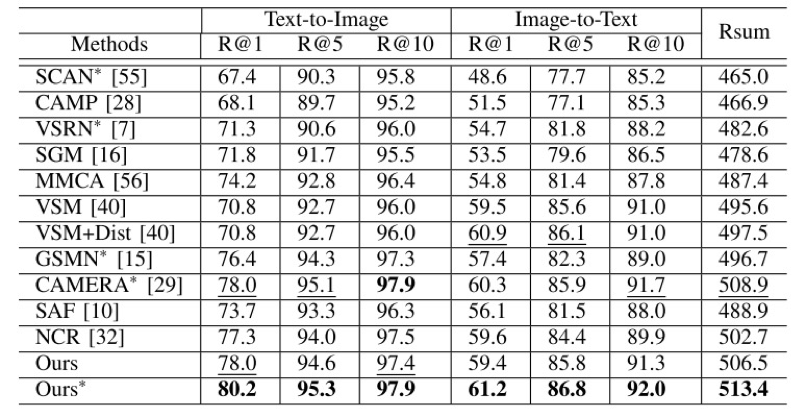
为验证本文方法的有效性,我们在Flickr30K和COCO两个数据集上进行了实验。从图3所示的可视化结果可以看出,本文方法通过减少与各模态不相关的噪声实现了精确的图文匹配。从在表1所示的定量实验可以看出,本文方法在Flickr30K数据上相比于现有方法,在所有评价指标上均取得了较大的性能提升。

图3 本文方法在Flickr30K和COCO测试集上的匹配结果
表1 在Flickr30K数据上本文方法和目前主流方法的性能对比结果
04
CMOS-GAN: Semi-Supervised Generative Adversarial Model for Cross-Modality Face Image Synthesis
基于生成对抗模型的半监督跨模态人脸合成方法
作者:俞诗康1,2,韩琥1,2,3#,山世光1,2,3,陈熙霖1,2
单位:
1中国科学院计算技术研究所智能信息处理重点实验室
2中国科学院大学
3鹏城实验室
邮箱:
shikang.yu@vipl.ict.ac.cn;
hanhu@ict.ac.cn;
sgshan@ict.ac.cn;
xlchen@ict.ac.cn
论文:
https://ieeexplore.ieee.org/document/9975261
代码:
https://github.com/skgyu/CMOS-GAN
#通讯作者
1. 引言
跨模态人脸图像合成(如素描画像-人脸照片、近红外图像-可见光图像、可见光图像-深度图像)在人脸识别、人脸动画和数字娱乐等方面有广泛的应用。传统的跨模态合成方法通常需要成对的训练数据,即每个人脸都有两种模态的图像。然而,成对的跨模态人脸图像数据往往难以大量获取,而未成对的单一模态人脸图像数据大量存在。针对以上问题,本文提出了一种新的半监督跨模态人脸图像合成方法(即CMOS-GAN)。它可以利用成对和未成对的单一模态人脸图像来学习跨模态人脸图像合成,其优势在于:1) 可以充分利用大量存在的未成对的单一模态图像去增强跨模态人脸图像合成效果,更符合实际应用场景的需求。2) 对多种跨模态人脸图像合成任务都具有较好的合成效果。
2.方法
所提出的方法如图 1所示:我们使用像素级约束和特征级约束去使用成对数据。使用对抗损失来确保使用不成对以及成对图像生成人脸图像的质量。同时使用交叉熵损失确保这两个域的生成图像较好地保持了身份信息。我们还修改了传统的三元组损失函数,以增强跨模态生成网络在保留身份判别特征方面的能力。我们认为,合成的人脸图像应该比任何其他身份的合成图像或真实图像(负样本)更接近该身份的任何其它合成图像或真实图像(正样本)。
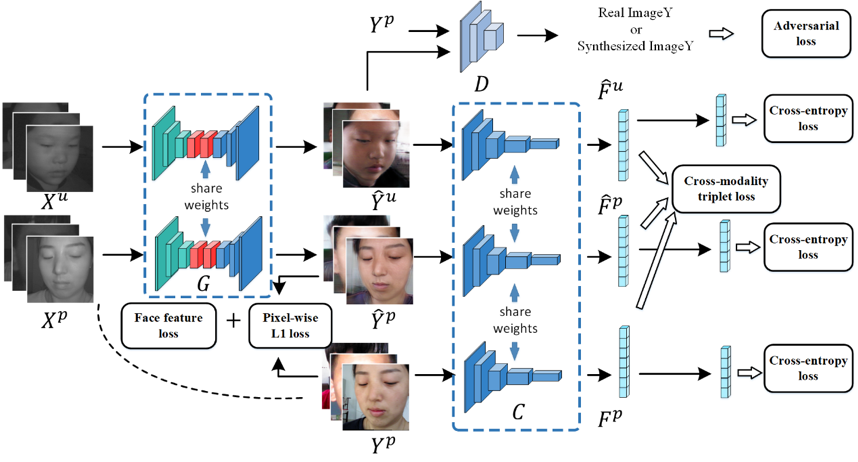
图1 所提出的基于生成对抗模型的半监督跨模态人脸合成方法框架
3. 实验
表 1 在VIPL-MumoFace-3K数据集上我们的方法和基线方法在近红外-可见光合成方面的效果比较
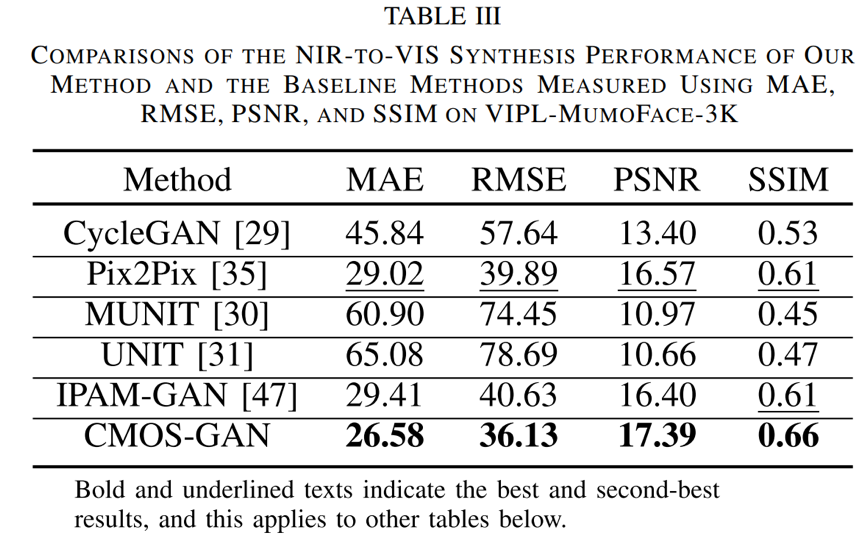
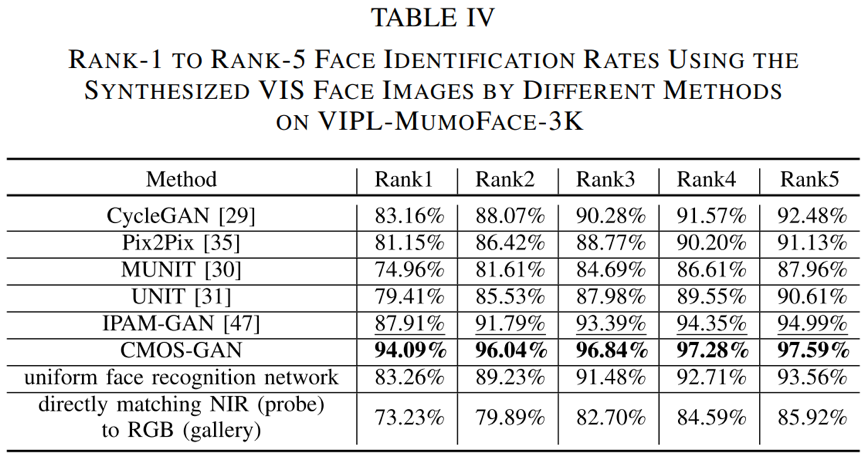
表 2 使用不同方法合成的可见光人脸图像在 VIPL-MumoFace-3K 数据集上的Rank-1到Rank-5的人脸识别准确率
本文在VIPL-MumoFace-3K、RealSense II RGB-D、BUAA Lock3DFace、 CUFSF、CUFS等多个数据集上评估了所提出的半监督跨模态人脸合成方法在画像-照片、近红外-可见光、可见光-深度等任务上的人脸合成性能。其中VIPL-MumoFace-3K是本工作采集、处理的数据集,它包含248561对可见光-深度-近红外人脸图像对。
表 1展示了在VIPL-MumoFace-3K数据集上我们的方法和基线方法在近红外-可见光合成方面的效果对比。结果表明所提方法能利用成对和未成对数据实现更好的从近红外到可见光人脸图像的合成。
本文利用所提出的方法和多个基线方法进行从近红外到可见光的跨模态 人脸合成,并利用合成的可见光图像与注册集中真实的可见光图像来进行人脸识别。此外,我们还训练了一个跨模态的人脸识别网络,使用成对人脸图像域和单一模态人脸图像域中的所有人脸图像训练而不考虑它们的模态差异。该网络的结构(ResNet-50)和初始权重与我们方法中所用的相同。我们还使用预训练的RGB人脸识别网络直接进行近红外与可见光图像的跨模态识别。不同方法对应的人脸识别准确率见表 2。可以看到,所提出的方法能利用成对和非成对数据提升跨模态人脸识别准确率,并且取得了优于所有基线方法的效果。
05
Vine Spread for Superpixel Segmentation
作者:周沛,康学净,明安龙
单位:北京邮电大学
邮箱:
peizhou@bupt.edu.cn,
kangxuejing@bupt.edu.cn,
mal@bupt.edu.cn
论文:
https://ieeexplore.ieee.org/document/10015675
代码:
https://github.com/zach-pei/VSSS
引言
超像素分割(Superpixel Segmentation)是图像分割的一个子类,是图像处理领域的一项关键任务,它将图像中具有相似色彩、位置、纹理等特征的相邻像素聚合为一个个小区域,每个聚合后的区域被看作为一个超像素。超像素作为图像中不规则但有一定意义的像素块区域,能够保留图像中物体的边界信息。另外少量的超像素也能代替大量的像素来表达图像特征。因而,超像素往往作为高级视觉任务(语义分割,目标检测等)的预处理步骤,以提升后续视觉任务的性能。本方法旨在解决现有超像素方法的种子点初始化的随机性和粗感知性的问题以及像素分配问题,以提升超像素算法的分割质量。
方法
本方法受自然界中藤蔓蔓延现象的启发,构建了藤蔓模型,新的种子点初始化策略和“并行蔓延”的藤蔓蔓延过程解决超像素分割问题。
藤蔓模型包括土壤模型和藤蔓状态模型,其中,土壤模型定义了藤蔓生长所需的土壤环境,藤蔓状态模型定义了藤蔓的生理状态,如图1所示
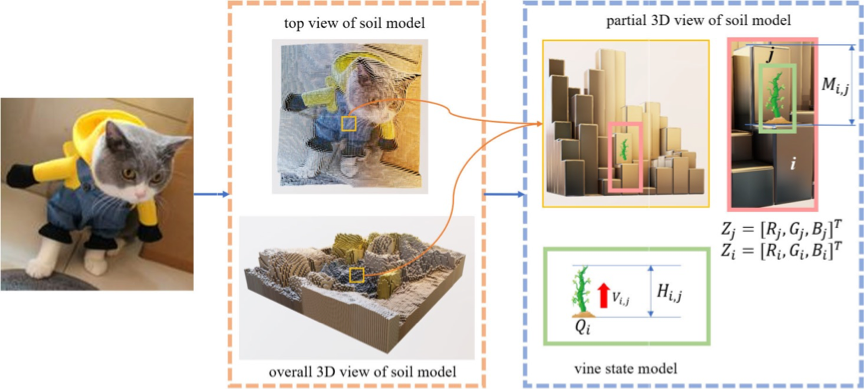
图1 土壤模型与藤蔓状态模型
另外,所提出的新的种子点初始化策略实现了像素级的稳定图像内容密度感知,这解决了以往算法的粗粒度感知和种子分布随机的问题,显著提升了算法分割图像细节与细枝区域的性能。
最后,“并行蔓延”的藤蔓蔓延过程实现了一种新的像素分配机制,在该过程中,我们提出了藤蔓的非线性速度函数,疯狂蔓延模式和土壤平均化策略,有效地解决了超像素在贴边性和规则性的权衡问题。
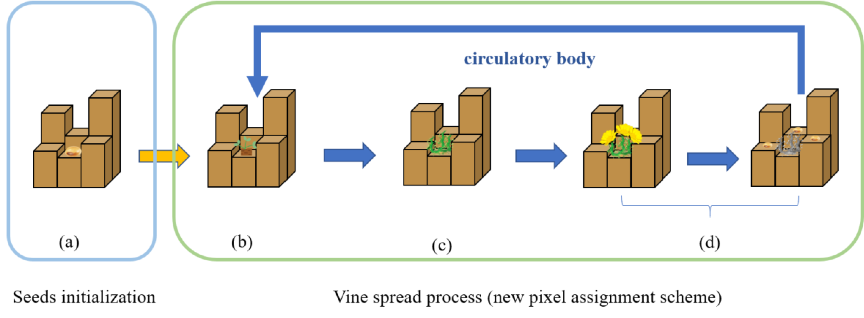
图2 种子点初始化与藤蔓蔓延过程示意图
实验
我们在3个数据集(BSDS500,SBD,FASHIONISTA)上从定性(图3、4)和定量实验(表5)两个角度对我们的方法与十几种算法进行横向对比,并采用消融实验(图5)的方式纵向对比,结果都证明了我们的方法可以有效分割图像细节和细枝区域及平衡超像素贴边性和规则性。同时我们的方法在基于种子点的方法中的众多定量指标的对比中也达到了非常有竞争力的水平。

图3 我们方法的细节分割结果展示

图4 我们方法的在平衡超像素的贴边性和规则性的结果展示
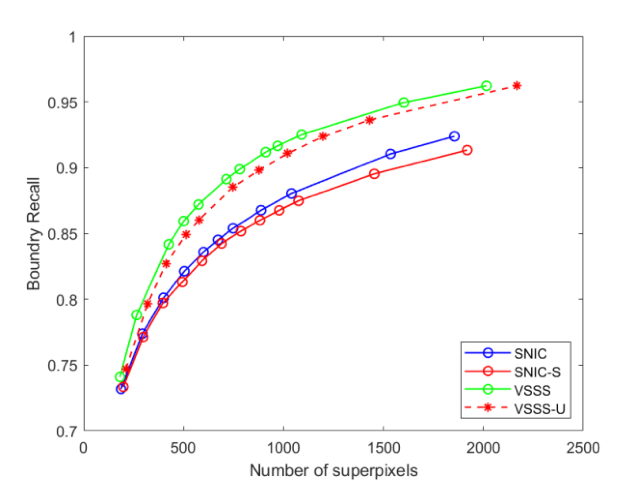
图5 消融实验
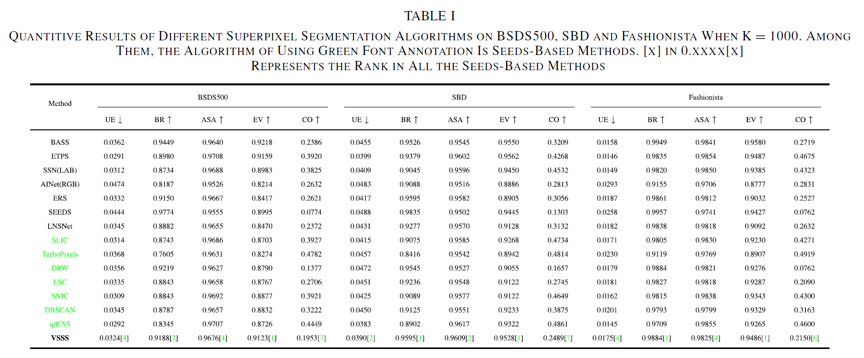
表1 我们的方法与其他算法在三个数据集上的定量比较
06
CAVER: Cross-Modal View-Mixed Transformer for Bi-Modal Salient Object Detection
作者:庞有伟,赵骁骐,张立和,卢湖川
单位:大连理工大学
邮箱:
lartpang@mail.dlut.edu.cn
zxq@mail.dlut.edu.cn
zhanglihe@dlut.edu.cn
lhchuan@dlut.edu.cn
论文:
https://arxiv.org/abs/2112.02363
项目主页:
https://lartpang.github.io/docs/caver.html
代码与预测结果:
https://github.com/lartpang/CAVER
现有的双模态(RGB-D和RGB-T)显著性目标检测方法,大多利用卷积运算构建复杂的交织融合结构实现跨模态信息集成。卷积运算固有的局部连通性限制了基于卷积的方法的性能。在这项工作中,我们从全局信息对齐和变换的角度重新思考这些任务,并提出了跨模态视角混合Transformer(CAVER)。如图1中所示,我们通过级联多个跨模态集成单元CMIU,构建了自上而下的基于Transformer的信息传播路径。CAVER中的多尺度和多模态特征的集成过程被视为“序列到序列”形式的上下文传播和更新,并构建在新颖的混合了空间与通道双视角信息的注意机制VMA之上。但是Transformer与输入token数量呈二次关系的复杂度限制了其实际应用的灵活性和扩展性。为此,在实际挖掘模态内与模态间互补信息的过程中,我们设计了一种无参的PTRE操作。这将原始token重组为更粗粒度的token组,从而降低了复杂度。最终在RGB-D和RGB-T两种双模态显著性目标检测任务上,所提方案展现出了良好的性能。
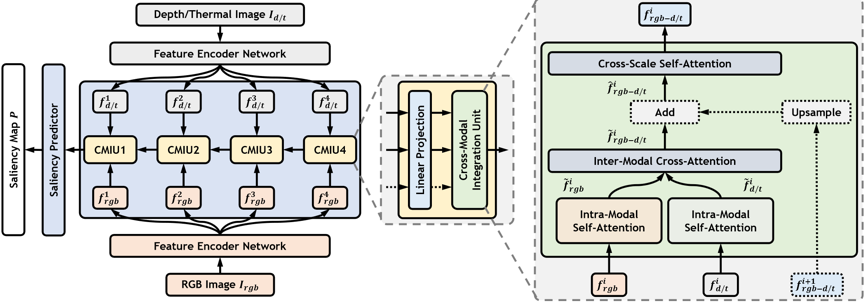
图1 所提方法的整体模型架构图
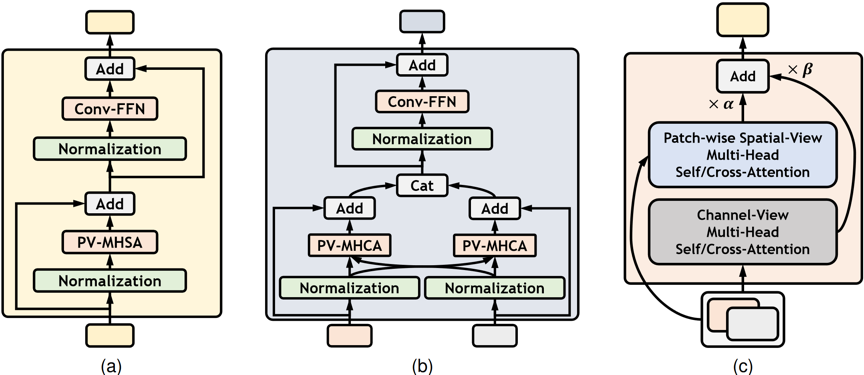
图2 基于PTRE的视角混合注意力机制:(a)自注意力模块;(b)交叉注意力模块;(c)视角混合注意力操作
图2所示的视角混合注意力机制是本文双模态信息交互设计的核心。其中,PTRE操作被引入到空间视角注意力的计算中,从而有效减少了空间密集交互带来的高昂计算成本。而通道视角注意力的引入,则为跨模态信息的感知提供了一个新的路径。两个不同视角的注意力机制利用可学习的权重进行组合。
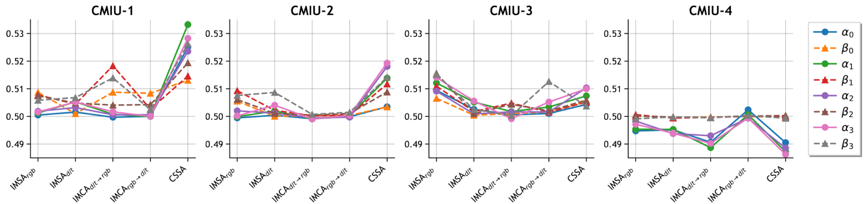
图3 不同位置上,空间与通道视角注意力操作对应的权重
随着模型的学习过程,二者各自的相对重要性也可以从对应的权重中得到展现。我们在图3中展示了训练后模型中的这些参数。不同位置权重参数的最终结果的差异也反映出了我们方法的灵活性。同时图3还反映出了一些有趣的现象。浅层中整体权重值相对较大,用于跨模态交互的IMCA中的通道分支起着更重要的作用。这也意味着引入浅层特征和通道视图的必要性。此外,尽管模型容量和训练数据存在差异,但四个模型权重的趋势非常相似,这背后的原因值得更多的探讨,也进一步凸显了通道交互模式在特征解码阶段的潜力。

 京公网安备11010802017125号
京公网安备11010802017125号