
2023年论文导读第九期
论文导读】2023年论文导读第九期
CCF多媒体专委会 2023-05-09 15:00 发表于北京


论文导读
2023年论文导读第九期(总第七十五期)
目 录
|
1 |
Searching Efficient Model-Guided Deep Network for Image Denoising |
|
2 |
Simultaneous Destriping and Image Denoising using a Nonparametric Model with the EM Algorithm |
|
3 |
Rain Removal From Light Field Images With 4D Convolution and Multi-Scale Gaussian Process |
|
4 |
Complementary Calibration: Boosting General Continual Learning with Collaborative Distillation and Self-Supervision |
|
5 |
Edge Devices Clustering for Federated Visual Classification: A Feature Norm Based Framework |
|
6 |
Unsupervised Adaptive Feature Selection With Binary Hashing |
01
Searching Efficient Model-Guided Deep Network for Image Denoising
作者:宁倩1 ,董伟生1* ,李欣2 ,吴金建1
单位:1西安电子科技大学人工智能学院,2西弗吉尼亚大学
邮箱:
ningqian@stu.xidian.edu.cn;
wsdong@mail.xidian.edu.cn;
xin.li@mail.wvu.edu;
jinjian.wu@mail.xidian.edu.cn;
lep666@buaa.edu.cn;
论文:
https://ieeexplore.ieee.org/document/10003244
项目主页:
https://see.xidian.edu.cn/faculty/wsdong/Projects/Mod-NAS.htm
*通讯作者
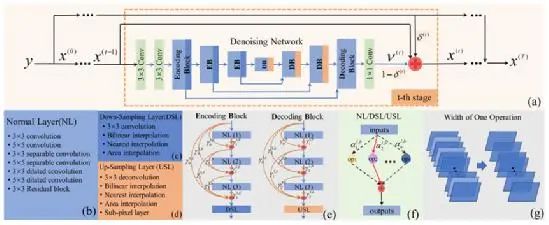
图1 基于模型引导的网络架构搜索框架
1. 引言
与神经架构搜索(NAS)在high-level视觉任务中的成功不同,通过神经网络架构搜索的方法在low-level视觉任务中如图像去噪等应用仍然具有挑战性。如何利用可微分的神经网络架构搜索方法搜索到计算高效,低延迟图像去噪网络是一个亟待解决的问题。而在搜索过程中,由于超网和子网络之间的优化差距,训练过程并不不稳定性。其次,面向high-level视觉任务所设计的搜索空间对于low-level视觉任务并不适用,存在性能表现不足以及推理时间长等问题。
2. 方法
针对上述问题,我们提出了一种基于模型引导的神经网络架构搜索方法(MoD-NAS)。具体来说,我们在模型引导框架下构建了一个新的搜索空间,并提出了更稳定和高效的可微分搜索策略。MoD-NAS采用高度可重用的宽度搜索策略和基于稠密连接的搜索块来自动选择每层的操作,同时使用梯度下降算法优化更加网络参数和架构参数,以实现自适应搜索图像去噪网络的宽度和深度。在搜索过程中,由于在模型引导框架下设计了更平滑的搜索空间,因此所提出的MoD-NAS在训练超网过程中保持稳定。
3. 实验结果
在几个常用数据集上的实验结果表明,我们提出的MoD-NAS方法在参数更少,计算量更少(使用Flops来衡量),所需推理时间更短的情况下,具有和目前SOTA方法相当甚至更好的性能表现。
表1 基于模型引导的网络架构搜索的网络去噪结果对比

图2 基于模型引导的网络架构搜索的网络计算量,推理时间对比

图3 灰度去噪实验结果对比

图4 真实去噪实验结果对比
02
Simultaneous Destriping and Image Denoising using a Nonparametric Model with the EM Algorithm
基于非参数先验模型的条纹噪声去除算法
作者:宋凌飞1,黄华2
单位:1北京理工大学计算机学院,2北京师范大学人工智能学院
邮箱:
lingfei@bit.edu.cn
huahuang@bnu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10027861
代码:
https://github.com/slfff/Image-Destriping
条纹噪声是一种常见的结构化噪声,广泛存在于红外成像、遥感成像、暗光成像等应用领域。条纹的产生是因为探测器读出电路的参数不一致,导致输出的图像每一列具有不同的偏置。相比于常见的高斯白噪声,条纹噪声的去除更加困难。一方面,条纹噪声是非平稳的;另一方面,条纹噪声的结构特征需要使用更多参数进行刻画。现有的条纹噪声去除算法一般采用预处理的方法先去除每一列的偏置然后使用高斯噪声降噪算法进行去噪;或者将列偏置参数放入基于最大后验的图像复原框架中进行联合优化。这两种方法均不能保证算法发最优性,且处理后的图像容易出现伪影。另外,基于最大后验的方法需要已知显式的图像先验,而在实际应用中往往也会面临图像先验未知的问题。
为了解决上述问题,本文提出了一种基于期望最大化(EM)算法的红外图像去条纹框架。该框架的优势在于将条纹噪声去除分解为条纹参数估计和计算图像的条件期望问题,并且不需要指定显式的图像先验。通过在条纹参数估计和图像条件期望计算之间来回迭代,基于此框架的算法可以近似得到条纹参数的极大似然估计并最终有效去除条纹噪声。为了计算图像的条件期望,本文提出使用一种非局部均值的算法。可以证明,该算法在一定条件下是图像条件期望的相合估计。另外,如果放松对相合性的要求,图像条件期望的计算可以使用一般的图像降噪算法来进行。仿真及真实数据实验结果均验证了本文提出的去条纹算法的有效性。算法流程如图1所示。

图1 算法流程图
图2、图3展示了部分实验结果。可以看到,无论是在仿真实验上还是在真实数据实验上本文提出的算法均取得了更优的效果。

图2 仿真实验结果
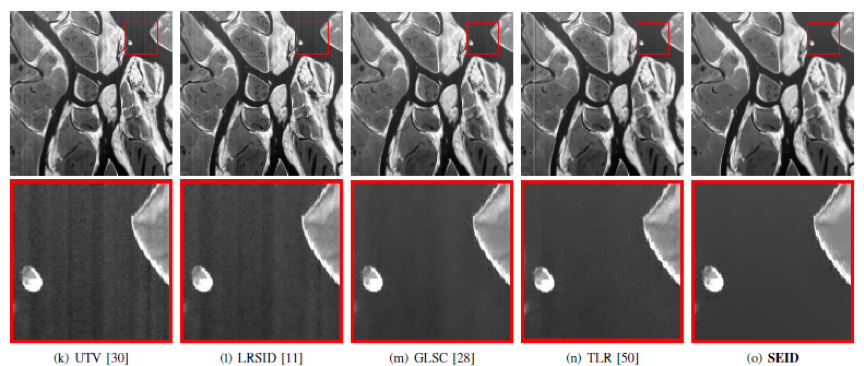
图3 遥感图像处理结果
03
Rain Removal From Light Field Images With 4D Convolution and Multi-Scale Gaussian Process
作者:晏涛1*,李明悦1,李彬1,杨洋2,Rynson W. H. Lau3
单位:1江南大学,2江苏大学,3香港城市大学
邮箱:
yantao.ustc@gmail.com
6191610004@stu.jiangnan.edu.cn
6201924100@stu.jiangnan.edu.cn
yyoung@ujs.edu.cn
rynson.lau@cityu.edu.hk
论文:
https://ieeexplore.ieee.org/abstract/document/10017170
代码:
https://github.com/YT3DVision/4D-MGP-SRRNet
*通讯作者
引言
现有的图像去雨算法主要集中于单个2D图像去雨任务研究。然而,针对单个输入图像恢复无雨图像,准确地检测和去除雨条纹是极其困难的。相比之下,全光相机拍摄的光场图像通过记录每个入射光线的方向和位置等信息,保存了目标场景丰富的3D结构和纹理信息。 然而,如何充分利用图像保存的丰富信息,如子视图阵列和每个子视图的视差图,来进行有效的图像去雨仍然是一个极具挑战性的问题。 我们提出一种新的图像去雨方法,4D-MGP-SRRNet,用于从光场图像中去除雨条纹和雨雾。我们的方法将具有雨条纹的光场图像所有子视图作为输入。为了充分利用光场图像,我们采用了4D卷积,以同时处理光场图像的所有子视图。我们提出了多尺度自导高斯过程(MSGP)模块的雨水检测模块MGPDNet,用于在多尺度上从输入光场图像的所有子视图中检测高分辨率的雨条纹图像。MSGP引入了半监督学习,通过计算真实光场图像的雨条纹的伪真值,在多尺度上对合成光场雨图像数据集和真实光场雨图像数据集进行协同训练,从而准确地检测雨条纹。
方法
基于4D卷积和多尺度高斯过程的光场图像去雨网络如图 1所示。该网络由雨条纹检测模块、深度估计模块和无雨图恢复模块三部分构成。首先,雨条纹检测模块通过多尺度密集网络从所有子视图中提取雨条纹,同时利用高斯过程建模雨条纹信息监督网络提取特征。然后初始的光场图像减去得到的雨条纹图后进入深度估计模块,通过4D 深度估计残差网络来估计所有子视图的深度图,再将预测的深度图转换为雾图,用于去除远处类似于雾的密集雨条纹。最后,将输入的子视图与相应的雨条纹图和雾图连接起来,进入无雨图恢复模块,利用对抗递归神经网络逐步去除雨条纹并恢复无雨光场图像。

图 1 基于4D卷积和多尺度高斯过程的光场图像去雨网络图
实验
本文方法与主流方法在我们提出的数据集(Rainy LFI with Motion Blur, RLMB)上进行了实验,并在表 1中列出了在合成场景上的定量实验结果,可以看出本文方法作为半监督去雨算法,在合成场景上具有优秀的表现。图2展示了在真实场景上的去雨结果比较,可以清晰地看出,我们的方法与其他方法相比,可以最大程度上去除雨条纹,恢复高质量的无雨光场图像。 在合成光场雨图和真实光场雨图上进行的充分定量和定性实验评估证明了我们提出的方法的有效性。
表1 本文方法与主流方法在RLMB数据集合成场景上的定量实验结果

图2 本文方法与主流方法在RLMB数据集真实场景上的定性实验结果
04
Complementary Calibration: Boosting General Continual Learning with Collaborative Distillation and Self-Supervision
作者:冀中1, 2,黎晋1, 2,王强1, 2,张仲非3
单位:1天津大学,2天津市类脑智能技术重点实验室,3纽约州立大学宾厄姆顿大学
邮箱:
jizhong@tju.edu.cn;
lijincm@tju.edu.cn;
qiangwang306@tju.edu.cn
zzhang@binghamton.edu
论文:
https://doi.org/10.1109/TIP.2022.3230457
代码:
https://github.com/lijincm/CoCa
人类具有从复杂多变的现实场景中快速学习新知识同时不“灾难性地遗忘”旧知识的天赋,但对于当下炙手可热的人工智能体而言这种天赋仍然是可望而不可及。为了使智能体可以在动态环境中连续自适应地学习,一种称为广义持续学习的范式被提出。它旨在从非平稳的无限数据流中学习新知识同时免于对旧知识的灾难性干扰或遗忘。
其中,一类有效的方法是在记忆回放的基础上借助知识蒸馏来缓解灾难性遗忘。然而,由于存储旧任务的记忆容量有限的,从而导致新旧任务样本数量不平衡,进而使得模型输出偏向于新任务。借助这种有偏的模型输出进行知识蒸馏会误导模型,从而不利于旧知识的保持;同时由于特征提取器偏向于提取对新任务有判别性的特征,从而使得获取的特征不能很好的区别新旧任务。

图1 补偿校正框架在训练阶段示意图
为了解决上述问题,我们提出一种的基于补偿校正框架的广义持续学习技术,如图1所示。它在经典的经验回放模块基础上引入了协作知识蒸馏模块和协作对比学习模块。协作对比学习模块探索互补的模型特征,它由上下文实例对比学习和实例间监督对比学习组成,上下文实例对比学习可以尽可能地迫使模型学习样本完整的特征而实例间监督对比学习可以帮助模型学习判别性的特征,上下文实例对比学习为实例间对比学习提供了更多的判别依据,实例间对比学习也可以抑制上下文实例对比学习提取的无意义特征,缓解了所提取的特征表示不具备充足判别性的问题。协作知识蒸馏模块在知识蒸馏中探索更好的目标模型输出来指导学生模型的输出,通过发掘当前模型输出和校正的保存模型输出之间的互补特性来平衡类之间的关系,校正的保存模型输出在知识蒸馏中能够很好地缓解保存时刻所见类别的灾难性遗忘,但是忽略了旧类别和保存时刻到当前时刻之间出现的新类别之间的关系,这一关系存在于当前的模型输出中,通过将这两个模型输出进行集成,能够在知识蒸馏的过程中为学生模型提供更丰富的信息,从而有校正了模型输出层级的灾难性遗忘问题。协作知识蒸馏和协作对比学习通过分别在模型输出和特征层级进行补偿校正,有效地缓解了广义持续学习中的灾难性遗忘问题。在6个主流数据集上的实验表明所提方法的有效性。
05
Edge Devices Clustering for Federated Visual Classification: A Feature Norm Based Framework
作者:魏晓翔1,黄华2*
单位:1北京理工大学,2北京师范大学
邮箱:
weixiaoxiang@bit.edu.cn,
huahuang@bnu.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10024116
*通讯作者
1. 引言
联邦学习能够在保护数据隐私的前提下利用分布式数据训练机器学习模型,在边缘计算场景中具有重要的应用价值。然而,边侧设备中的数据一般是非独立同分布的,这使得模型在边侧设备中进行本地训练时容易出现更新方向发散的情况,从而导致模型性能的下降。聚类联邦学习方法将数据分布相似的边侧设备划分至同一个聚簇,聚簇内设备共同训练一个模型,是解决更新方向发散问题的有效方法。现有聚类联邦学习方法一般基于模型参数的相似程度或者目标函数损失值来度量不同客户端数据分布的相似程度,但这些度量方式不够准确,可能为客户端聚类过程带来一些误差。为了解决这一问题,本文提出基于特征范数向量的聚类联邦学习算法(cFedFN),其利用客户端数据的特征范数信息辅助客户端数据分布相似度的计算,并以此度量方法为基础对客户端进行层次聚类。在多个图像分类数据集的实验表明,所提出的cFedFN算法能够在不明显增加通信成本的前提下提升机器学习模型的性能。
2.方法
有研究提出,模型基于某一样本输出的特征范数越大,所对应特征的信息含量越大。cFedFN算法基于上述现象提出了更进一步的假设,即模型对某一数据集输出的特征范数能够反映此模型与此数据集的契合程度。在联邦学习环境下,当两个客户端数据分布存在差异时,其数据集样本所对应的特征范数也会存在差异。图1展示了联邦模型在数据分布不同的两个数据集上所输出的二维特征,可以看到两数据集所对应的特征范数存在明显差别。基于这一假设,cFedFN通过将同一个类别样本特征的范数进行平均,为每一个客户端都生成了相对应的特征范数向量。然后,基于不同客户端特征范数向量的距离来度量客户端数据分布之间的差异。在通过上述方法计算得到客户端之间的分布相似矩阵后,就可以开始对客户端进行聚类。cFedFN使用如图2所示的层次聚类策略,通过将所有客户端划分到同一个初始聚簇并随训练过程逐渐划分为更加精细的子聚簇,能够为每一个聚簇都训练出高性能模型。

图 2 联邦模型在数据部分不同时输出的二维特征
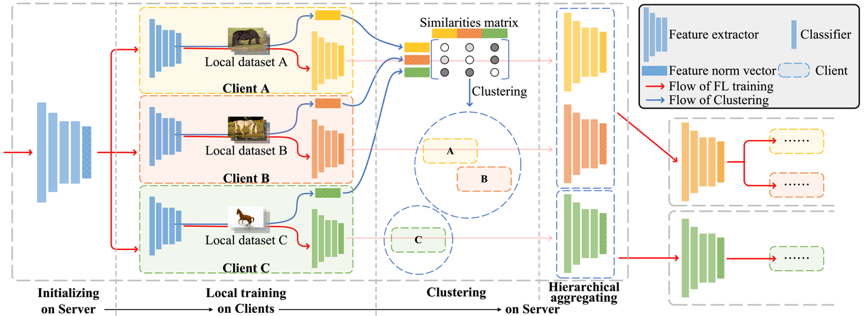
图 3 cFedFN的聚类过程
3. 实验
为了验证所提出cFedFN方法的有效性,本文在多个图像分类数据集上进行了实验。表1所示的模型准确率结果证明cFedFN在数据分布差异较为明显的情况下能够提升模型的性能。图3所示的聚类邻接矩阵可视化说明cFedFN相比其他聚类联邦学习算法能够实现更加准确的客户端聚类。
表 2 不同数据集下的聚类联邦学习算法对比

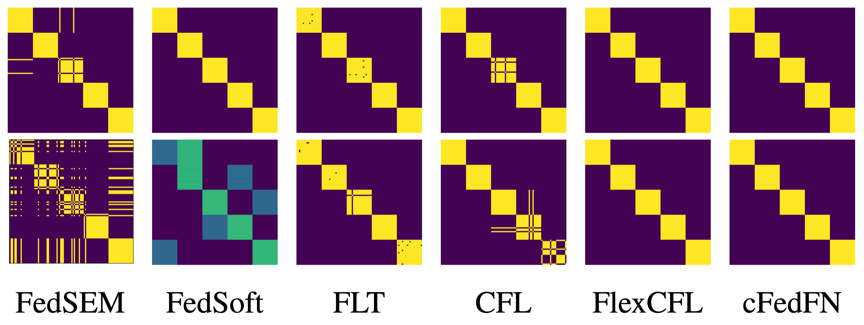
图 4 不同聚类联邦学习算法的聚簇邻接矩阵可视化
06
Unsupervised Adaptive Feature Selection With Binary Hashing
作者:石丹1,朱磊1,李晶晶2,张正3,常晓军4
单位:1山东师范大学,2电子科技大学,3哈尔滨工业大学,4悉尼科技大学
邮箱:
shidan0122@163.com,
leizhu0608@gmail.com,
lijin117@yeah.net,
zhengzhang@hit.edu.cn,
Xiaojun.Chang@uts.edu.au
论文:
https://ieeexplore.ieee.org/abstract/document/10014652
代码:
https://github.com/shidan0122/UMFS.git
1. 引言
随着信息技术的飞速发展,高维数据分析是多媒体计算、图像处理、模式识别等领域都面临的普遍问题。一方面,高维数据可以提供更丰富的特征信息;另一方面,也会带来具有挑战性的维度灾难问题。特征选择技术通过选择重要特征来降低特征的维数。现有的无监督方法在执行特征选择时没有标签信息指导或仅由单个伪标签指导。然而,现实世界中的大多数数据,如图像和视频,通常包含多个标签(如图1所示)。这些解决方案可能会造成严重的信息损失,并导致所选特征语义不足。因此,本文提出了一种新的基于二值哈希的弱监督标签自适应学习方法,并将其与无监督特征选择集成到一个统一的学习框架中,以选择具有判别性的特征。
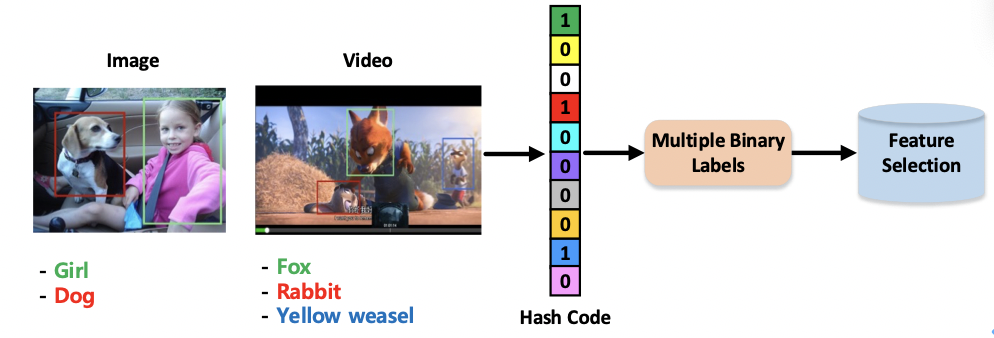
图1 真实世界的图像和视频通常使用多个标签进行标注。本文主要思想是学习二值哈希码作为弱监督多标签,同时利用学习到的标签指导特征选择过程。
2. 方法
为了在无监督场景下探索具有判别性的信息,本文在谱嵌入过程中施加二值哈希约束,自动学习弱监督多标签以指导最终的特征选择。本文针对单视图数据和多视图数据分别提供了解决方案。方法中,弱监督多标签的数量(即二值哈希码中“1”的数量)会根据数据内容自适应确定。这有效地缓解了先前方法(在没有标签指导或仅使用单个弱监督标签指导的情况下执行特征选择)存在的语义限制。此外,为了增强二值标签的判别能力,本文通过自适应构造动态相似度图来建模内在数据结构。最后,本文推导了一种基于增广拉格朗日乘子法(ALM)的二值优化方法,用于迭代求解公式化问题。
所提出的基于二值哈希的无监督自适应特征选择方法框架如图2所示,主要包括动态图学习、弱监督多标签学习和无监督特征选择三个模块。总的目标函数为:
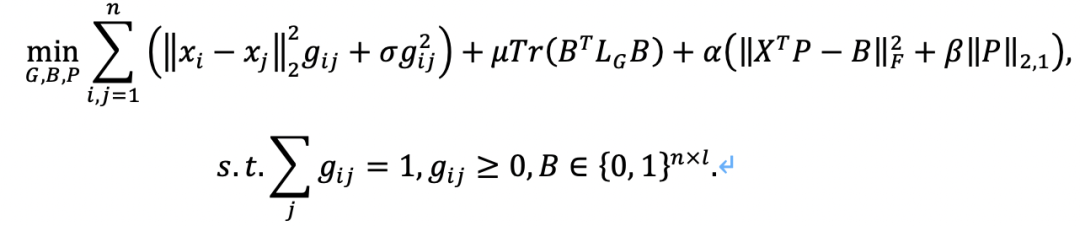

图2 基于二值哈希的无监督自适应特征选择方法框架
此外,本文将所提自适应二值哈希学习方法扩展到多视图设置下,并提出一种基于二值哈希的多视图特征选择方法,以处理多视图数据的特征选择问题。
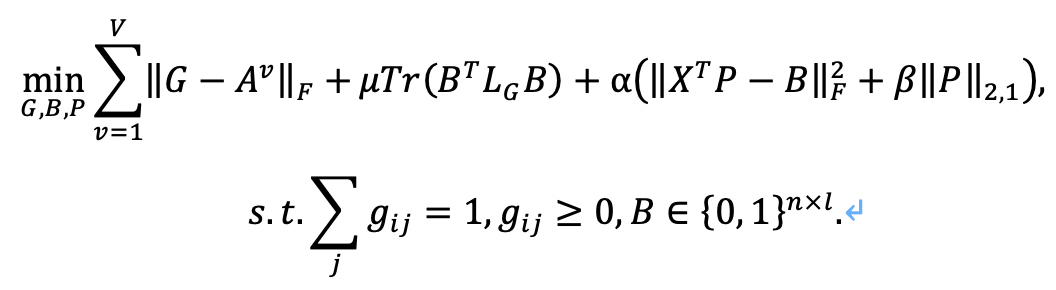
3. 实验
图3和表1分别展示了我们的方法在单视图数据和多视图数据设置下,基于公平对比,稳定提升了性能。
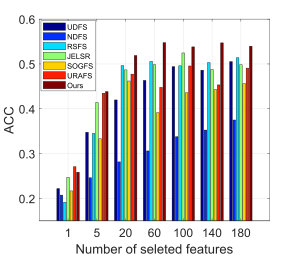
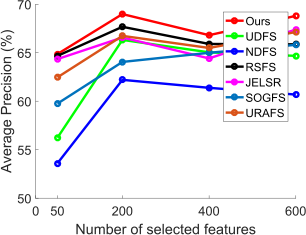
图3 单视图单标签数据集ORL(左图)和多标签数据集NUS-WIDE(右图)上的性能比较
表1 无监督多视图特征选择方法在选择不同特征数量时的性能比较


 京公网安备11010802017125号
京公网安备11010802017125号