
2023年论文导读第六期
【论文导读】2023年论文导读第六期
CCF多媒体专委会 2023-03-28 09:00 发表于北京


论文导读
2023年论文导读第六期(总第七十二期)
目 录
|
1 |
Cross-modality Transformer with Modality Mining for Visible-infrared Person Re-identification |
|
2 |
Multiple Description Coding for Best-Effort Delivery of Light Field Video Using GNN-Based Compression |
|
3 |
Semi-Supervised Knowledge Distillation for Cross-Modal Hashing |
|
4 |
Cross-modal Variational Auto-encoder for Content-based Micro-video Background Music Recommendation |
|
5 |
Multisample-Based Contrastive Loss for Top-K Recommendation |
01
Cross-modality Transformer with Modality Mining for Visible-infrared Person Re-identification
作者:梁腾飞1,金一1,刘武2,李浥东1
单位:1北京交通大学,2京东探索研究院
邮箱:
tengfei.liang@bjtu.edu.cn;
yjin@bjtu.edu.cn; liuwu@live.cn;
ydli@bjtu.edu.cn
论文:
https://arxiv.org/abs/2110.08994
面向可见光与红外图像跨模态行人重新识别(Visible-Infrared person Re-IDentification,VI-ReID)是一项具有挑战性的ReID任务,其目的是在异质的可见和红外模态之间检索和匹配具备相同身份的行人图像。因此,这项任务的核心是消除这两种模态图像表征之间存在的巨大差距。现有的主流方法主要面临对模态信息感知不足的问题,并且不能学习到良好的具备模态不变性的行人辨别性特征向量,这限制了它们的性能。为了解决此问题,本研究提出了一种新的基于Transformer模型的跨模态ReID方法(Cross-Modality TRansformer,CMTR),该方法可以显式地挖掘每个模态的信息,并在此基础上生成更好的辨别性特征。

图1 模型方法的整体情况概览
如图1所示,为了提取模态的内在特性,本研究设计了针对性的模态向量(modality embeddings),并将其与图像的分块表示(Patch Token)相融合以直接对模态信息进行编码学习。此外,为了增强模态向量的表示并调整行人图像特征向量的分布,本研究进一步提出了一种基于模态向量知识的模态感知增强损失,该损失包含两个分量,以同时减少类内距离和扩大类间距离。本研究提出了首次将Transformer主干网络模型应用于跨模态再识别任务的方法。在公共SYSU-MM01和RegDB数据集上的大量实验表明,与以前的方法相比,本研究方法在跨模态检索中具有更强大的特征表示能力,取得了良好的性能。
02
Multiple Description Coding for Best-Effort Delivery of Light Field Video Using GNN-Based Compression
基于图神经网络压缩的光场尽力而为传输多描述编码方案
作者:胡欣珏1, 2, 3,潘宇轩1,望育梅1,张琳1, 4,Shervin Shirmohammadi2
单位:1北京邮电大学,2加拿大渥太华大学,3武汉理工大学,4北京市大数据中心
邮箱:
huxinjue@whut.edu.cn
panyx@bupt.edu.cn
ymwang@bupt.edu.cn
zhanglin@bupt.edu.cn
shervin@eecs.uottawa.ca
论文:
https://ieeexplore.ieee.org/abstract/document/9625786
代码:
https://github.com/xinjuehu/VideoLightField-MDC
作为一种新的沉浸式媒体(Immersive Media)格式,具有密集视点的光场(Light Field)能够有效地感知场景内的光线变化并捕捉真实的场景环境信息,为用户提供逼真的六自由度(Degree of Freedom)沉浸式体验。然而,光场视频数据的大容量及高密度特性为其在数据压缩和交付传输带来了巨大的挑战。为了适应不同光场业务场景下的实时性要求和对不可靠网络环境下传输的鲁棒性要求,本研究提出了一种基于多描述编码(Multiple Description Coding, MDC)的自适应可靠光场流媒体传输方法。该方法将密集光场阵列数据切分为不同级别下采样率的稀疏光场描述,并对光场描述的传输队列进行优化调度,从而确保其可以自适应地调节图神经网络基本单元设计来使得所提光场传输架构能够更灵活地适应用户视点请求的实时变化,从而最大程度节省不必要的视点传输开销,并最大程度降低网络丢包及网络状态波动对光场数据传输业务的不利影响。
本研究提出基于多描述编码(MDC)技术的光场自适应可靠传输方法,该方法将光场阵列划分为多组描述(Descriptions),并各自独立传输。光场阵列由来自不同视点的多个视频流组成,因此易于以视点为单位对光场阵列进行均匀采样来获得不同MDC描述。不同的下采样率代表不同的描述级别,多个低级别描述可以组合成一个高级别描述。通过光场GNN重构方法,任何级别的描述都可以作为输入来恢复完整的光场阵列。输入描述的级别越高,恢复结果的质量越好。因此接收端只需尽可能的在数据接收过程中动态自适应地根据所接收低级别描述自由组合出更高级别的描述,即可实现在不破坏光场业务流传输连续性的前提下调整接收端光场数据质量的目的,图1展示了所设计的光场MDC传输架构。

图1 基于视点分割的光场MDC传输架构图
本研究与SVC及传统视频MDC方案进行了性能测试对比,测试结果验证了所提光场专用MDC架构在过载及易错网络中的光场业务传输鲁棒性,实验结果如图2所示。图中在不同丢包率网络环境下,MDC方案都能取得相较于传统可伸缩视频编码(Scalable Video Coding, SVC)方案更稳定且鲁棒的传输性能优势,这证明本研究所提传输架构相较于SVC及传统视频MDC方案更为适应光场数据特性及业务需求。
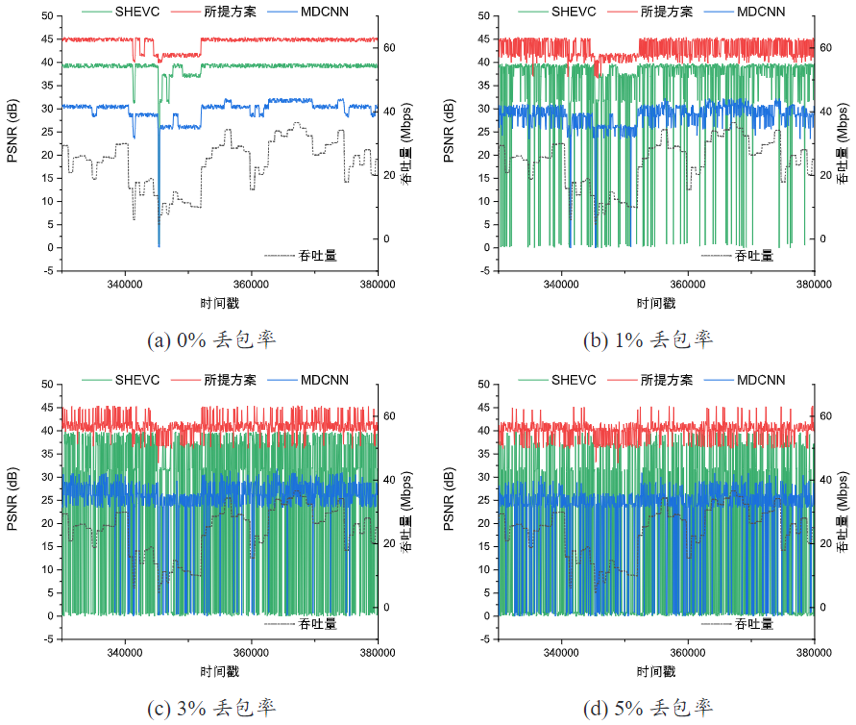
图2 不同丢包率网络环境下传输性能对比图
本研究前置工作(光场图神经网络压缩编码相关):
Xinjue Hu, Shan J, Liu Y, et al. An Adaptive Two-Layer Light Field Compression Scheme Using GNN-Based Reconstruction[J]. ACM Transactions on Multimedia Computing Communications and Applications, 2020, 16(2s): 1–23.
03
Semi-Supervised Knowledge Distillation for Cross-Modal Hashing
作者:苏明月1,顾广华1*,任贤龙1,付灏1,赵耀2
单位:1燕山大学信息科学与工程学院,2北京交通大学信息科学研究所
邮箱:
guguanghua@ysu.edu.cn
论文:
https://doi.org/10.1109/TMM.2021.3129623
https://ieeexplore.ieee.org/document/9623504
1 引言
有监督跨模态检索方法,需要耗费大量人工成本以获取有监督场景下的语义标签,而无监督或半监督方法又存在检索精度严重下降的问题。为实现可媲美有监督性能的半监督方法,本文提出基于半监督知识蒸馏的跨模态哈希(SKDCH)方法,充分利用训练数据对的成对相似性知识,通过知识蒸馏获得与语义类别标签具有相似属性的无标签数据的伪标签,并利用知识蒸馏的方法从教师模型中提取知识来帮助训练学生模型,从而提高跨模态检索的精度。通过师生优化,用半监督模型的输出来指导有监督模型,以达到提高检索精度的目的。
2 方法
SKDCH由教师模型、知识蒸馏和学生模型三部分构成,如图1所示。教师模型由生成器G和判别器D组成。生成器G接收不同模态的有标签和无标签数据作为输入。给定一个有标签数据作为查询样本,G需要在另一模态的边距误差范围内选择相近的无标签数据,以形成生成对。判别器D则需要能够更好地区分生成对和真实对。有监督信息能够提高哈希码的判别能力,因此我们借助教师模型所学到的知识为数据集中的跨模态样本构建相似矩阵,并基于该相似性关系估计出无标签样本的伪标签,如图2所示。SKDCH的学生模型通过知识蒸馏获得了所有数据的标签,达到了有监督学习的条件。学生模型与教师模型有着类似的网络结构,主要区别在于学生模型的生成器不再计算无标签数据的相关分布,而是根据真实分布选取查询数据的相关样本以构造生成对,从而更好地欺骗判别器。
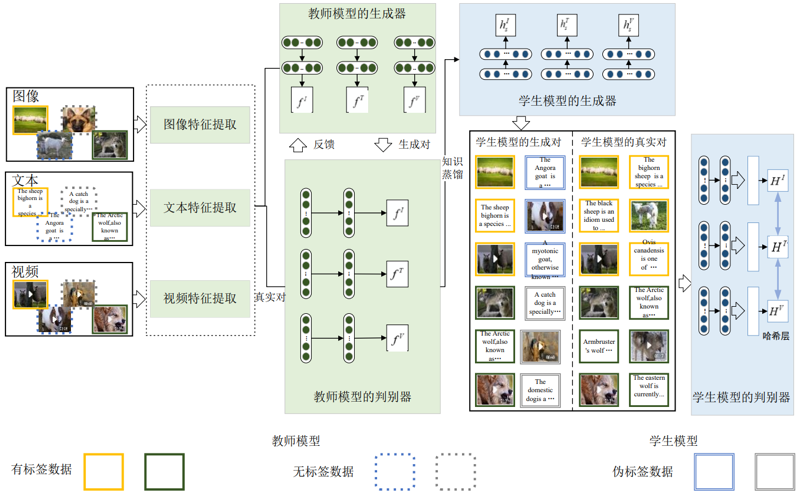
图1 基于半监督知识蒸馏的跨模态哈希总体框架

图2 SKDCH与原始特征空间预测的伪标签对比
3 实验
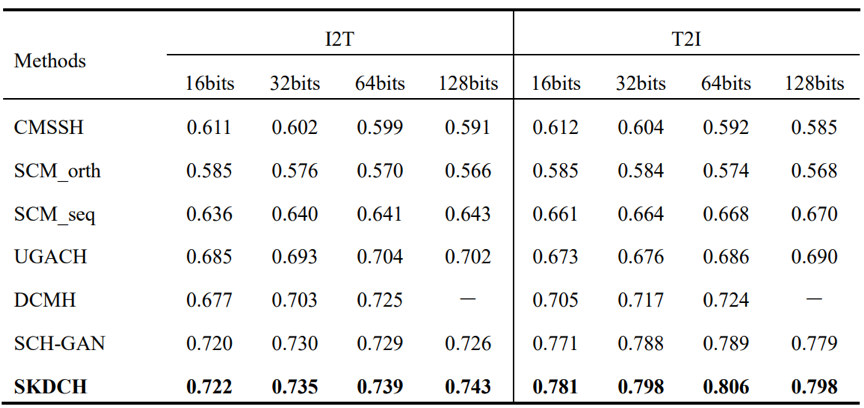
为了评估SKDCH在多模态检索方面的性能,我们在PKU XMedia数据集上与3种基于实值的多模态方法(MCCA、GMLDA、MvDA)和3种基于深度学习的哈希方法(UGACH、DCMH、SCH-GAN)进行对比,结果如表1所示。同时,我们也在MIRFlickr数据集上与5种基于哈希的方法进行了比对,如表2所示。由实验结果可知,与基于实值的多模态方法、浅层的有监督跨模态哈希、基于深度学习的无监督跨模态方法和基于GAN的半监督跨模态哈希等相比,SKDCH都表现出了更优的性能。
表1 不同方法在PKU XMedia数据集上跨模态检索性能比较

表2 不同方法在MIRFlickr数据集上跨模态检索性能比较
04
Cross-modal Variational Auto-encoder for Content-based Micro-video Background Music Recommendation
作者:易静,朱耀晨,谢嘉仪,陈震中*
单位:武汉大学
邮箱:
yijing-v@whu.edu.cn
yaochenzhu@whu.edu.cn
xjyxie@whu.edu.cn
zzchen@whu.edu.cn
论文:
https://doi.org/10.1109/TMM.2021.3128254
*通讯作者
引言
视频-背景音乐的匹配或者推荐是一个值得研究的问题。如今短视频平台十分流行,用户可以自己拍摄视频,但庞大的音乐库使得用户挑选合适的配乐成为一个难题。因此,本文着眼于视频-背景音乐的匹配,利用丰富的短视频-背景音乐内容匹配的数据集来建模匹配模式从而进行推荐。
研究动机
考虑到没有开源的数据集用于研究,本文设法建立了一个短视频-背景音乐匹配数据集,命名为TT-150k。该数据集包括3000多个音乐片段和大约十五万个使用了候选音乐片段的短视频。 其次,短视频的语义结构与音乐有很大的不同:无声的短视频是视觉信息和文本信息的大杂烩,而音乐只包含音频信息。因此,如何将语义丰富的视频潜在空间与单调的音乐潜在空间进行匹配是一个挑战。基于此,本文设计了一个贝叶斯生成模型,通过将短视频与背景音乐投射到共享的低维潜在空间来进行匹配。通过跨模态生成,既视频隐变量生成音乐特征,而音乐隐变量生成视频特征来进行模态对齐,并限制匹配的视频-音乐对的嵌入比不匹配的更接近。通过此方法,可以获得更准确的短视频与音乐的相似度度量,并用于推荐。此外,短视频的视觉模态和文本模态的模态嵌入通过PoE进行融合,从而更好地利用互补的多模态信息。
方法概述

图1 CMVAE概率图模型
CMVAE的概率图模型如图1所示,在层次结构上,本文先对模态级潜在嵌入进行建模,得到短视频级的潜在嵌入。然后对音乐和短视频级的潜在嵌入通过交叉生成来限制其潜在空间的对齐。
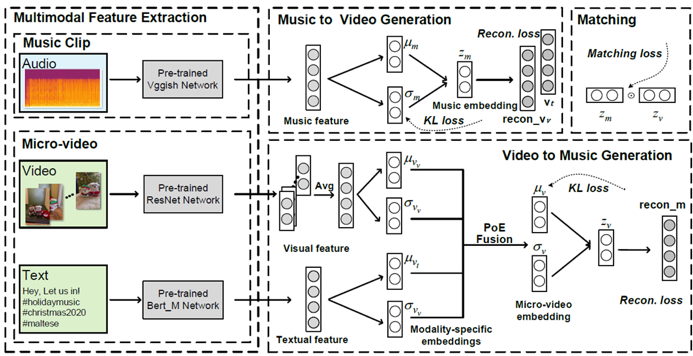
图2 CMVAE框架图
CMVAE的框架如图2所示。首先,本文用预训练模型提取各模态的特征。其中,对于音乐模态,本文使用Vggish特征和OpenSmile特征,对于短视频,本文提取视觉模态的ResNet特征和文字模态的Bert特征。各个模态的特征经过编码器编码到一个低维的高斯隐空间。其中,短视频的两个模态通过product-of-experts模型进行模态融合。最后,考虑到视频和背景音乐语义结构的差异性,本文使用跨模态生成策略来更好的匹配音乐和视频模态。最终损失函数包括跨模态重建的生成损失、KL散度损失和视频-音乐隐空间的匹配损失。其中,匹配损失使用margin-based的度量学习,并使用双边的约束来更好对正负样本间位置差距进行约束。
实验结果
表1 CMVAE和其他baseline的结果
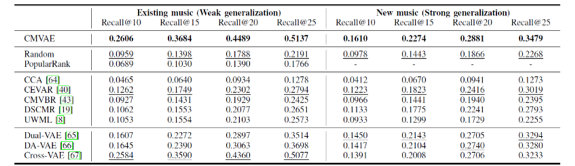
本文在TT-150k数据集上验证了CMVAE的有效性,并使用了两种数据划分的策略。第一种策略是“弱泛化”,测试集中的候选音乐片段都在训练集中出现。 第二种策略是“强泛化”,测试集中的音乐片段没有出现在训练集中。从表1中可以看到,本文提出的CMVAE性能优于其他研究方法(包括启发式方法,用于image-text matching 的方法,和基于VAE使用不同生成策略的方法)。
表2 不同跨模态生成策略的Recall结果
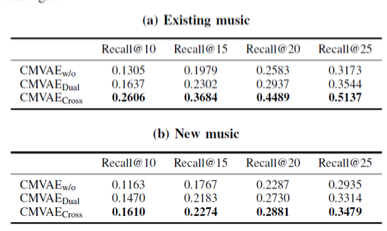
表3 不同多模态融合方法的Recall结果

表4 测试阶段模态缺失的Recall结果(V和T分别表示视觉和文字模态)

从表2和表3中可以看出,对于不同的数据集划分,本文提出的跨模态生成策略和PoE融合策略要优于其他的相应策略。从表4中可以看出, 本文模型对于测试时文字模态缺失有很好的鲁棒性。
05
Multisample-Based Contrastive Loss for Top-K Recommendation
作者:汤豪,吴玉霞,赵国帅,钱学明
单位:西安交通大学
邮箱:
th1002@stu.xjtu.edu.cn
wuyuxia@stu.xjtu.edu.cn
guoshuai.zhao@xjtu.edu.cn
qianxm@mail.xjtu.edu.cn
论文:
https://ieeexplore.ieee.org/document/9609670/
代码:
https://github.com/haotangxjtu/MSCL
1 研究思路
对比学习是近期的研究热点,但是现有研究往往局限于基于数据扩充的对比学习框架内。本文认为对比损失(CL)是对比学习的关键,对比损失非常适合Top-k推荐。本文提出基于多样本的对比损失MSCL,为推荐系统提供了性能更好、效率更高、具有多模型适用性的损失函数。
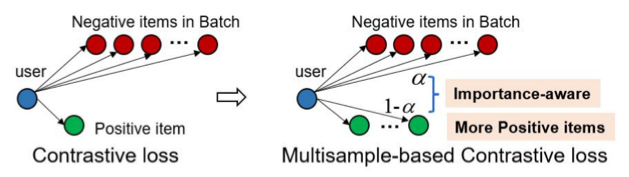
图1 MSCL对CL的优化
2 问题分析及改进方法
对比损失与Top-K推荐结合,存在着两大问题。(一)CL未区分正、负样本的不同的重要性:1)对比损失存在样本数量的不平衡问题或一个正样本和多个负样本(N-1个,N是batch size大小)的不同重要性问题。2)推荐系统面临着稀疏性问题,数据集越稀疏,正样本因稀少而更加重要。(二)现有Top-k推荐方法没有充分利用现有的正样本。推荐系统面临稀疏性问题,如何充分利用有限的正样本是一个关键问题。 本文提出了基于多样本的对比损失MSCL,将 MSCL 与优秀的基于 GCN 的方法 sLightGCN 相结合以验证所提出的损失函数的有效性,如下图所示。
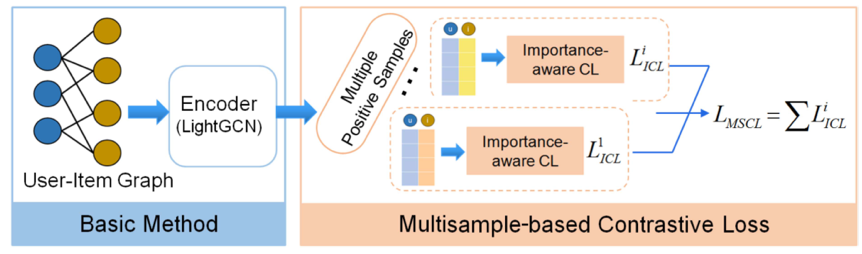
图2 MSCL损失及推荐流程
(1)基本的对比损失函数 :

(2)重要性感知的对比损失 (ICL)
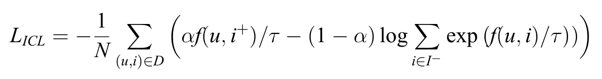
ICL通过权重来区分正、负样本的重要性,有助于解决正负样本的不平衡问题,并提高正样本在非常稀疏数据集中的重要性。
(3)多正例对比损失 (MCL)
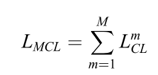
MLC通过组合使用多个正样本,从而更充分地利用现有稀少的正样本。①多正例组合:大大增加了用户可能遇到的情形,增大训练空间。假设用户有20个交互记录,常规训练中仅有20种训练情形,通过多正例组合可以形成最大C1020=184756种训练情形。②可对比数量=正例*负例,增大了对比空间。③可以看做是一种数据增强方法,但与传统图数据增强不同(每次输入数据不同,通过在模型学习中发挥数据增强的作用),本文方式则是在后端与多路径损失函数结合在一起,以进行达到更好的约束和反向传播。可以广泛地应用于图数据以及其他各种类型的数据。
(4)多样本对比损失 (MSCL)
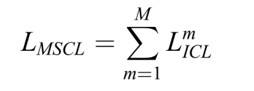
3 实验结果及优势分析
表1 性能对比结果

本文提出的sLightGCN_MSCL方法在这些对比方法中取得了最优的性能,优于基于对比学习的推荐方法方法SGL,特别是在Amazon-Book上性能提升显著。
表2 MSCL与BPR在不同模型上的性能对比

本文通过实验验证了MSCL的多种优点。(1)具有多模型的适应性,相对BPR都有明显的性能提升,特别是将MF性能提升到优于sLightGCN的水平。(2)MSCL有利于提升排序指标(NDCG)。(3)显著提升了训练效率,在Amazon-Book上3个epoch就能达到最优。MSCL 并没有明显增加每个epoch的训练时间,基于对比学习框架的 SGL方法是基线方法LightGCN 的时间的约 3.7 倍,而本方法大约是 LightGCN 的 1.5 倍。(4)本文方法和问题可以推广到基于多样本的BPR损失上,形成Multi-Sample based BPR Loss (MSBPR),其性能仍优于MSBPR。
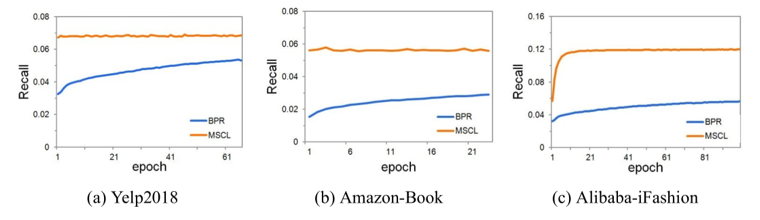
图3 训练效率
表3 BPR、MSBPR和MSCL的性能对比
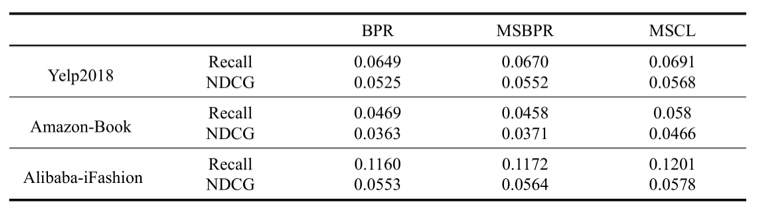
总之,对比损失相对于传统BPR有明显的优势,但结合不同的推荐场景、任务仍有很大的改进、提升空间,可以形成对比损失与推荐系统相结合的系列研究。同时,推荐阅读另一篇相关研究:Ranking-based Contrastive Loss for Recommendation Systems,代码https://github.com/haotangxjtu/RCL

 京公网安备11010802017125号
京公网安备11010802017125号