
2023年论文导读第七期
【论文导读】2023年论文导读第七期
CCF多媒体专委会 2023-04-11 17:22 发表于北京


论文导读
2023年论文导读第七期(总第七十三期)
目 录
|
1 |
Joint Decision Tree and Visual Feature Rate Control Optimization for VVC UHD Coding |
|
2 |
Causal Interventional Training for Image Recognition |
|
3 |
Towards Task-Generic Image Compression: A Study of Semantics-Oriented Metrics |
|
4 |
Human Co-Parsing Guided Alignment for Occluded Person Re-identification |
|
5 |
Spike-Based Motion Estimation for Object Tracking Through Bio-Inspired Unsupervised Learning |
01
Joint Decision Tree and Visual Feature Rate Control Optimization for VVC UHD Coding
联合决策树和视觉特征的超高清视频编码码率控制优化方法
作者:周明亮1,魏雪凯2,贾维嘉3,Sam KWONG4
单位:1重庆大学,2北京师范大学,3北京师范大学-香港浸会大学联合国际学院,4香港城市大学
邮箱:
mingliangzhou@cqu.edu.cn;
11132021609@bnu.edu.cn;
weijiaj@gmail.com
cssamk@cityu.edu.hk
论文:
https://ieeexplore.ieee.org/document/9979046
超高清(UltraHigh-Definition,UHD)视频旨在提供高空间分辨率、高时域帧率、高采样位深和广像素色域,是高清视频的进一步发展。除了将高清提升到4K高分辨率外,UHD视频还具备高帧率、高动态范围、广色域等诸多特征。多功能视频编码(Versatile Video Coding,VVC)作为最新的视频编码标准,能够为UHD视频提供更好的压缩性能。
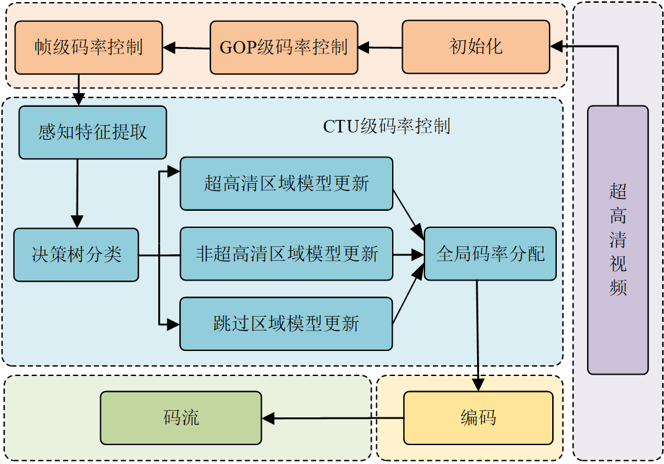
图1 本工作所提出码率控制框架
本工作提出了一种联合决策树和视觉特征的超高清视频编码码率控制优化方法,如图1所示。所提出算法的步骤可以大致分为率失真(Rate-Distortion,R-D)模型建立、帧级比特分配、编码树(Coding Tree Unit,CTU)级比特分配以及率失真模型参数更新几个阶段。
本工作可以总结为如下几个方面:首先,本工作借助基于决策树的UHD视频区域划分方案为UHD视频设计了一种新的R-D模型,通过充分考虑视觉特征来提高R-D模型的预测精度,所提出的R-D模型拟合结果如图2所示,结果表明所提出的新的UHD视频R-D模型在CTU级和帧级都实现了良好的拟合效果。第二,本工作使用每帧的失真来衡量每帧的编码复杂度并得到每帧的编码权重和码率,之后使用R-λ模型来获得帧级λ以及量化参数(Quantization Parameters,QP)。第三,在获得帧级码率后,本工作进一步通过全局优化方法来获得CTU级比特。最后,本工作提出基于已编码信息来估计模型参数,并添加了区域级模型参数更新方法,以限制CTU级别的模型参数更新幅度。区域级别的模型参数更新包括以下步骤:1)忽略跳过区域CTU;2)记录非UHD区域和UHD区域 CTU的平均比特和λ;3)使用平均比特计算非UHD区域和UHD区域 CTU的码率;4)使用计算得到的码率和λ来更新相应的率失真模型参数。

图2 提出的率失真模型拟合值与实际值之间的关系
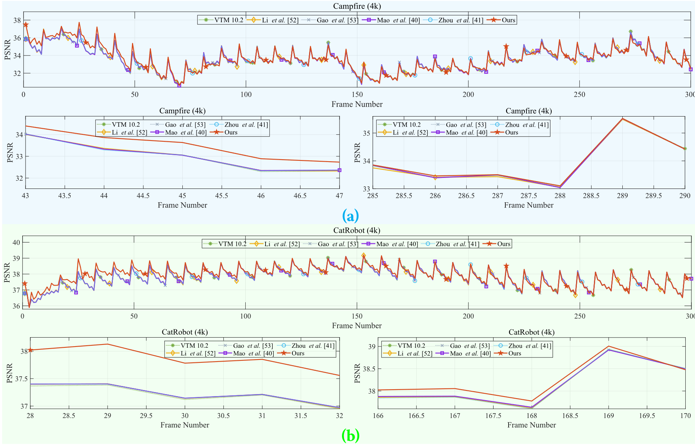
图3 不同方法的PSNR逐帧比较
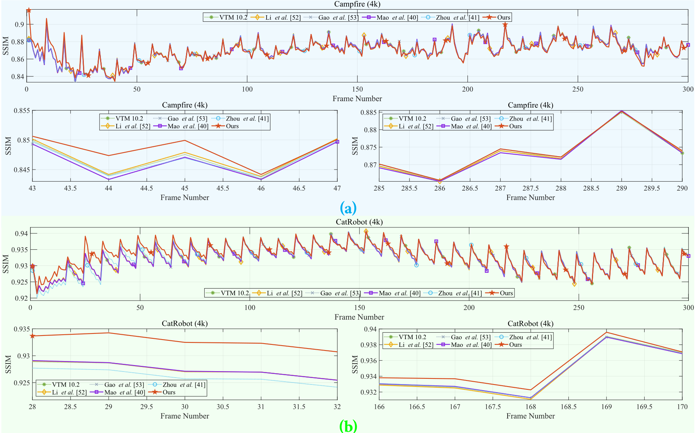
图4 不同方法的SSIM逐帧比较
本工作将所设计的算法和对比的其他先进算法统一到VTM 10.2软件中并进行了对比实验,如图3、4所示。结果显示,与其他先进算法相比,本工作所提出的方法可在保持给定的峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)或结构相似性度(Structural Similarity Index Measure,SSIM)的情况下实现显著的码率降低。
02
Causal Interventional Training for Image Recognition
作者:秦伟1,张含望2,洪日昌1,Ee-Peng Lim3,孙倩茹3
单位:1合肥工业大学,2南洋理工大学,3新加坡管理大学
邮箱:
qinwei.hfut@gmail.com
hanwangzhang@ntu.edu.sg
hongrc.hfut@gmail.com
eplim@smu.edu.sg
qianrusun@smu.edu.sg
论文:
https://ieeexplore.ieee.org/document/9656623
代码:
https://github.com/qinwei-hfut/CIT
1 引言
图像分类是计算机视觉领域的经典任务。如图1(a)所示,我们使用结构化因果模型(Structural Causal Model)重新审视构建视觉分类识别系统的基本过程。通过因果模型,我们发现物体内容(X)和标签类别(Y)之间是可靠稳定的因果相关性。背景内容(C)被拆分为两种,一种是和物体有常识上因果依存关系的因果背景(A);一种是由混杂因子产生的混杂背景(B)。正如图1(b)的例子中,标签为「轿车」类别的图片样本中,轿车的图片区域与标签「轿车」有因果相关性;图片背景中的公路区域属于因果背景,因为其和标签「轿车」有常识上的因果关联的(公路和轿车是相互依存);图片中的其他背景内容(戈壁,森林和高楼)是混杂背景。因此,稳定可靠的因果相关性X→Y 和 X→A→C→Y应该被保留学习,而由于混杂背景存在的伪相关性X←B→C→Y应该被剔除。本文将使用因果干预技术改善训练框架,使得模型学习可靠的因果相关性和避免拟合不可靠的伪相关性。
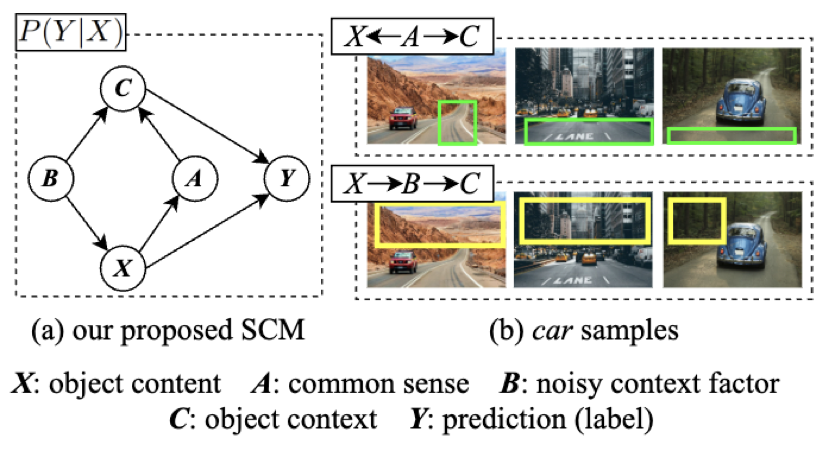
图1 (a)图是我们对视觉分类任务构建结构化因果模型。Y代表图片标签,X代表图片中物体(object),C是背景(background), A是C中因果背景部分,B是C中混杂背景部分。(b)图是我们以汽车图片作为案例,举例说明我们根据因果模型的分析结果。
2 方法
方法实现:本文通过对B节点(混杂背景)进行因果干预中的分层(Stratification)剪断了伪相关性X← B → C → Y,从而让模型只学习因果相关性 X→ Y 和 X → A → C → Y。具体而言,如图2(a)所示,我们首先利用显著性模型,将所有的图片分解为物体(object)部分和背景(background)部分。然后如图2(b)所示,将卷积神经网络改造成双通道。每个通道分别针对于图片样本的物体部分和背景部分。在训练阶段,我们将每一个图片样本的物体部分都和属于同类别其他图片的背景部分组合,作为干预样本。如图3第一行所示,汽车(car)类别的每张样本图片的汽车部分图像会和汽车类别的其他样本图片的背景部分做匹配,形成干预样本。我们将所有图片样本(包含原图片样本和干预样本)的物体部分和背景部分输入到双通道卷积神经网络。
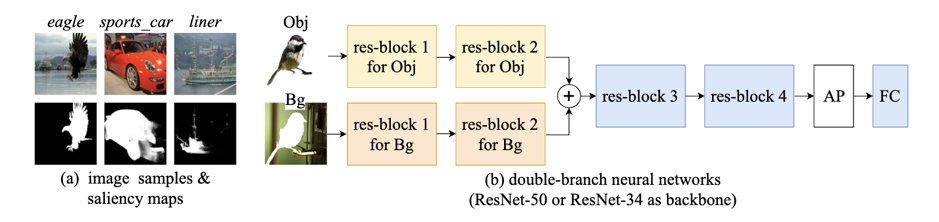
图2 (a)图展示了我们显著性测试进行数据处理的结果;(b)图展示了我们的双通道ResNet

图3 展示了部分类别的物体部分图像和我们干预后的背景部分图像
直观诠释:因果背景和物体之间具有强关联度,故在该类别的图片中都出现频率高,而混杂背景是和物体没有关系,每一种混杂背景在该类别的图片中出现的频率不高。我们分层干预后,每一个物体(例如汽车)都和固定的因果背景(例如公路)、多种多样的混杂背景(例如戈壁,森林,高楼)组成新的干预样本。所以,神经网络很容易捕捉到物体(汽车)、因果背景(公路)和标签(「汽车」)之间的相关性,而减少学习了混杂背景(森林,戈壁,高楼)和标签(「汽车」)之间的相关性。
3 实验
表1展示了我们的方法在公平对比下,稳定提升了性能。图3展示了,我们的方法在训练集的loss值高于原始训练方法。但是意料之外的是我们的测试集loss却是最小的。因为我们剔除了部分训练集中的伪相关性,所以降低了模型对训练集的过拟合,提升了在测试集的泛化性。
表1 我们的方法在ImageNet上和对比方法的比较
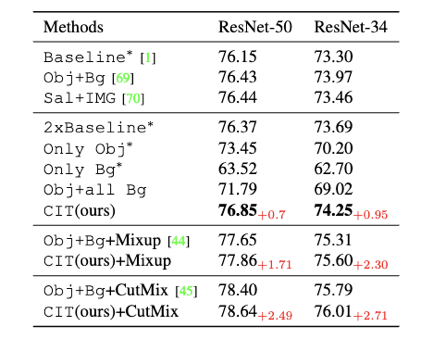
表2 不同方法在ImageNet训练集和测试集的loss值曲线

03
Towards Task-Generic Image Compression: A Study of Semantics-Oriented Metrics
作者:高长生,刘东 ,李礼,吴枫
单位:中国科学技术大学
邮箱:
changshenggao@mail.ustc.edu.cn;
dongeliu@ustc.edu.cn;
lil1@ustc.edu.cn;
fengwu@ustc.edu.cn
论文:
https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9627540
*通讯作者
1. 引言
近年来,人工智能技术突飞猛进,安防监控、辅助驾驶等领域的智能化程度迅速提高。在智能化应用领域中,产生的海量图像视频数据无法完全交由有限的人力分析,转而交由机器视觉算法进行分析理解。此外,一张图像往往会被不同的机器视觉任务进行多次分析,以支持实际部署中的各种应用。考虑编码失真对机器视觉分析的影响,设计一种任务通用(task-generic)的图像编码方法成为一个重要的研究课题。
2. 方法
我们从率失真优化出发,设计一种任务通用的语义失真度量,在编码器优化过程中保留机器视觉所需的语义信息。为兼顾多种机器视觉任务,我们分别从像素域与特征域设计了相应的语义失真度量,并利用二者的优势结合成任务通用的语义失真度量。像素域的失真度量通过VGG-16网络生成一个重要性图(如图1所示)度量像素对语义的重要性,并计算像素域的加权失真;特征域的失真度量将原始图像与重建图像通过VGG-16变换到语义空间,并在该空间中计算特征的均方误差作为特征域的语义失真度量。

图1 基于VGGG-16的像素重要性图生成过程。
提出的语义失真度量应用于端到端图像编码框架中,如图2所示。该端到端图像编码框架将原始图像、重要性图以及它们的乘积作为网络的输入,并使用提出的语义失真度量进行网络优化,实现任务通用的图像编码。
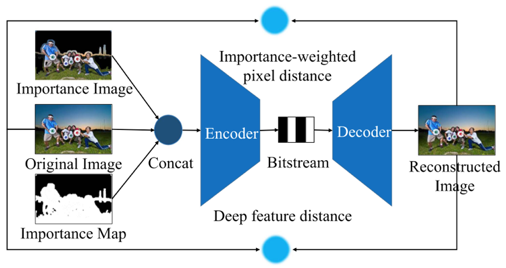
图2 提出的任务通用的图像编码方法框架。
3. 实验
率失准和率失真结果分别如图3和图4所示。实验结果表明,我们提出的方法在目标检测、实例分割、人体关键点检测以及图像注释任务上实现了率失真性能的大幅提升,同时验证了方法在多种机器视觉任务上的通用性。此外,我们的方法相对BPG与基线方法(以MSE为失真度量的端到端图像编码方法)去除了块效应并保留了更多的图像细节,取得了更高的感知质量。

图3 提出的任务通用图像编码方法在机器视觉任务熵的码率-失真曲线

图4. 感知质量比较。从上到下依次是原始图像、BPG、以MSE为失真度量的端到端图像编码方法以及提出的任务通用图像编码方法。
04
Human Co-Parsing Guided Alignment for Occluded Person Re-identification
作者:窦曙光1,赵才荣1,蒋忻洋2,张珊珊3,郑伟诗4,左旺孟5
单位:
1同济大学电子与信息工程学院
2微软亚洲研究院
3南京理工大学计算机科学与工程学院
4中山大学数据与计算机科学学院
5哈尔滨工业大学计算机科学与技术学院
邮箱:
zhaocairong@tongji.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/9994734
代码:
https://github.com/Vill-Lab/2022-TIP-HCGA

图1 在行人图像中获取语义信息的不同监督方式
引言:基于监督的像素级对齐方法使用姿态估计或人类解析模型,这些模型由人类注释进行监督,以获取像素级对齐信息。然而,由于像素级注释的高成本,只能使用在其他领域训练的分割模型,导致分割结果不准确。此外,当图像中出现多个行人时,基于监督的像素级对齐方法还会提取无关行人的像素级对齐信息,这可能使行人再识别任务变得更加困难。与上述监督方法不同,基于无监督的像素级对齐方法使用无监督聚类方法,将行人特征映射作为输入。然而,使用传统聚类方法来获得语义信息是次优的。受协同分割的启发,本文不使用额外的跨域注释,而是以弱监督的方式训练人类解析模型以用于行人再识别。
方法:如图2所示,所提出的HCGA框架由两个子网络组成,HCNet的编码器是PRNet的骨干网络。HCGA训练阶段的每个历元由两个步骤组成:(1)将训练集中具有相同ID的一组图像作为一批输入到HCNet中。在HCNet的训练阶段,编码器的参数不会更新。对于训练集的每个ID,我们分别训练解码器,并在训练结束时输出该ID的所有图像的共同解析结果。(2) 共解析结果被用作PRNet的人类解析头的伪标签。在训练中,PRNet的所有参数都会通过反向传播更新。在训练的早期阶段,HCNet的分割效果并不好。随着PRNet不断优化Backbone中的参数,前景和背景的像素特征之间的差异越来越大。因此,HCNet通过迭代训练生成更好的分割结果。在从HCNet获得的语义信息的指导下,PRNet对遮挡具有鲁棒性。

图2 提出人体协同分割指引对齐框架示意图
实验:与第二好的基于CNN的方法MOS相比,HCGA在Rank-1中提高了3.6%,在mAP中提高了2.4%。与基于Transformer的方法相比,HCGA在Rank-1、Rank-5和Rank-10上都表现出有竞争力的性能。
表1 与最先进的基于CNN的方法在Occluded-DukeMTMC上的比较结果

表2 与最先进的基于TransFormer的方法在Occluded-DukeMTMC上的比较结果

05
Spike-Based Motion Estimation for Object Tracking Through Bio-Inspired Unsupervised Learning
作者:郑雅菁1,余肇飞1,2,王松3,黄铁军1,2
单位:1北京大学计算机学院视频与视觉技术国家工程研究中心;2北京大学人工智能研究院;3南加州大学计算机与电子系
邮箱:
yj.zheng@pku.edu.cn;
yuzf12@pku.edu.cn;
songwang@cec.sc.edu;
tjhuang@pku.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/9985998
目前,基于脉冲神经网络的算法大多数都是基于对静态图片进行泊松采样的方式转换成脉冲序列,再基于转化所得的脉冲序列进行脉冲神经网络的训练。然而,由于图片采样机制低帧率的缺点以及静态图片中不包含时序信息,目前的脉冲神经网络无法在传统视觉任务上与深度学习抗衡。为了充分利用脉冲相机的低时延优势,根据脉冲相机的输出利用脉冲神经元的特性动态记录其时序特性,并设计一个基于脉冲神经网络的检测跟踪框架,是一个亟待解决的问题。因此,本文提出了一种名为Spiking Network for Object Detection and Tracking(ODTSnet)的脉冲神经网络,可利用神经形态相机进行快速目标检测和跟踪。与图像重构任务需要尽可能多的时空信息以还原更多细节不同,目标检测和跟踪任务关注的是移动目标的位置等信息。由于脉冲相机的光电转换原理,背景/静止区域也会根据场景亮度以不同频率产生脉冲信号。因此,在设计面向脉冲相机的目标检测和跟踪算法时,需要设计滤波模块以去除冗余脉冲,并根据脉冲的时空关联性检测物体并持续跟踪。

图1 所提出的检测与跟踪网络模型ODTSNet框架
所提出的模型结构如图1所示,主要包含动态适应模块、运动估计模块和检测跟踪模块。如图2左侧所示,动态适应模块(Dynamic Adaption)是由基于短时程可塑性模型的时间滤波器和基于漏电积分发放模型(Leaky Integrate-and-Fire, LIF)的空间滤波器组成。运动估计模块是一个基于脉冲神经元的两层网络(图2右侧)。在运动估计层由表示不同运动模式的神经元组成。神经元的权重将根据STDP规则进行调整。在运动估计层之后,还有加入了侧向抑制的运动神经元竞争层,以去除运动估计时的噪声,使得局部的运动模式更具一致性。

图2 动态适应模块与运动估计模型
图3展示了基于STDP的运动估计模块在线学习出的脉冲流的运动矢量,主观效果优于现有面向事件相机的运动估计方法。结合运动估计信息及空间信息,ODTSNet网络能够极端事件相机数据集中取得最好的物体检测结果。

图3 基于STDP的运动估计模块在线学习出的脉冲流的运动矢量
论文的相关开源代码可以关注我们课题组的开源项目SpikeCV,相关模块代码可在该网站https://openi.pcl.ac.cn/Cordium/SpikeCV上找到相应介绍及使用方式。

 京公网安备11010802017125号
京公网安备11010802017125号