
2023年论文导读第十期
【论文导读】2023年论文导读第十期
原创 多媒体专委会 CCF多媒体专委会 2023-05-23 14:00 发表于山东


论文导读
2023年论文导读第十期(总第七十六期)
目 录
|
1 |
Doing More with Moiré Pattern Detection in Digital Photos |
|
2 |
Boosting Broader Receptive Fields for Salient Object Detection |
|
3 |
CPP-Net: Context-aware Polygon Proposal Network for Nucleus Segmentation |
|
4 |
Selecting High-Quality Proposals for Weakly Supervised Object Detection With Bottom-Up Aggregated Attention and Phase-Aware Loss |
|
5 |
DeflickerCycleGAN: Learning to Detect and Remove Flickers in a Single Image |
01
Doing More with Moiré Pattern Detection in Digital Photos
作者:杨聪1,杨振宇2,Yan Ke3,陈涛1,Marcin Grzegorzek4,John See5
单位:1苏州大学,2东南大学,3扩博智能,4德国吕贝克大学,5英国赫尔瓦特大学
邮箱:
cong.yang@suda.edu.cn
yan@clobotics.com;
论文:
https://ieeexplore.ieee.org/document/10006755/
代码与数据集:
https://github.com/cong-yang/MoireDet
在图像校准、照片恢复、假体攻击、欺骗检测、多媒体制作等方面,摩尔纹检测均有广泛应用,也是计算机视觉中的重要研究课题。然而,摩尔纹不但隐式存在(与图片背景纹理纠缠),形态与颜色均不稳定,且随相机类型、屏幕分辨率、背景图片、相机位姿而灵活变换,极难复用传统方法进行检测。该论文详细阐述了全新摩尔纹检测框架,突破了高仿真摩尔纹合成、实时摩尔纹检测及弹性摩尔纹去除等多个技术难点,不但使得摩尔纹采集效率比传统方法提升3-4倍,精确捕捉各类屏幕与相机组合中产生的摩尔纹,还从底层补齐了摩尔纹图像恢复中的多个技术短板,在6个摩尔纹开源数据库及3摩尔纹相关任务中均取得了最优效果。相关算法简单且高效,已成功应用于扩博智维护产品,有效提升店铺巡检质量。


图1 真实摩尔纹采集与训练数据制备方法
为了更好捕捉及识别摩尔纹,团队从训练数据准备和摩尔纹检测模型两方面入手,搭建了整个框架。如图1所示,研究团队提出了一种提出了一种简单且高效的方法,巧妙利用色差降低背景对摩尔纹干扰,并使用分割算法进一步滤波,最后使用筛选算法进行细粒度摩尔纹提取。在此基础上,研究团队利用正片叠底思路,提出了一种摩尔纹图片合成方法。该方法模拟实际相机拍摄,最大限度保留了背景图片及摩尔纹特征,使得最终合成摩尔纹图片不但与摩尔纹层实现像素级对应,且与真实摩尔纹图片近似,可快速实现高质量、大规模、低成本摩尔纹训练数据制备,便于训练各类场景下的深度学习模型。

图2 MoireDet实时摩尔纹检测模型
在摩尔纹检测模型设计上,团队提出了兼具浅粒度特征和深粒度特征的深度学习模型。与普通的纹理相比,摩尔纹的特别之处在于它已融入背景图片,且会随着图像的放大和缩小而发生更改。针对此特性,团队提出了三种编码方式:高层编码器(High-Level Encoder)、低层编码器(Low-Level Encoder)及空间编码器(Spatial Encoder),用于充分捕捉摩尔纹在不同粒度、不同尺寸及不同位置下的特征值。其中,High-Level Encoder用于编码不同背景下的摩尔纹整体特征;Low-Level Encoder用于编码小条纹、波纹和曲线产生的低层次摩尔纹特征;在Spatial Encoder中,团队提出了一种全新的自适应编码方法,不但针对于不同图片进行自适,还针对于同一图片的不同位置进行自适,充分编码摩尔纹空间特征。针对于以上三个编码器,还提出了三个相应的损失函数,有效引导特征提取及模型泛化,进一步提升模型训练效率及摩尔纹检测精度(见图3)。

图3 不同屏幕类型下的摩尔纹检测结果
02
Boosting Broader Receptive Fields for Salient Object Detection
感知扩展与环路代偿的前景物体分割方法
作者:马明灿#1,夏长群#2,谢晨熹1,陈小武1,李甲12
单位:1 北京航空航天大学,2 鹏城实验室
邮箱:xiachq@pcl.ac.cn
论文:
https://ieeexplore.ieee.org/document/10006743
代码:
https://github.com/iCVTEAM/BBRF-TIP
论文介绍:
https://blog.csdn.net/SunMoonVocano/article/details/128621694
#共同作者
图像前景物体分割是深度学习、计算机视觉等领域的研究热点,在机器视觉、智能交通、智慧医疗、智能创作等领域具有重要的应用价值。近年来,面向常规尺寸物体场景的前景物体分割算法取得了突破性进展。然而,由于提取极端尺度感受野的低效性,现有方法在处理尺度变化场景尤其是包含极端大或者小尺度物体时面临瓶颈。
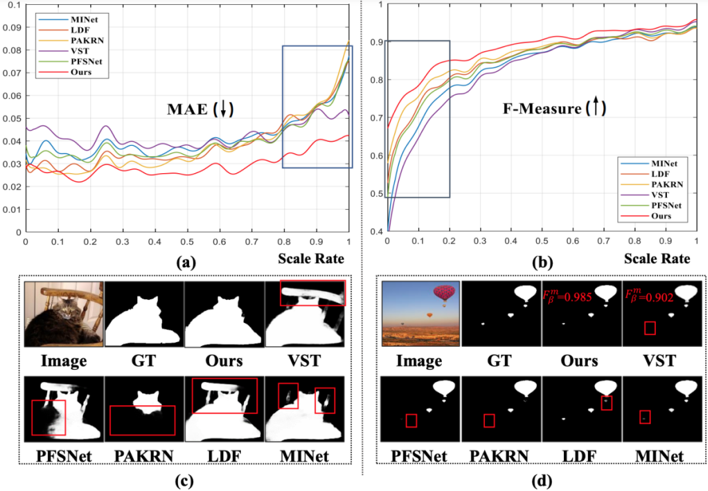
图1 本工作和6种国际最新方法在极端大或小尺度物体数据上的综合对比。其中,(a) 和 (b) 分别表示6种方法的平均误差和结构性指标对比;(c) 和 (d) 分别为极大和极小尺度物体分割效果对比。
最新的前景物体分割研究并不缺乏对感受野问题的探索,根据使用的骨干模型可划分为卷积类方法和视觉Transformer类方法。基于卷积神经网络的方法通常利用多层卷积同时提取全局语义和局部细节特征,而基于视觉Transformer的方法则打破卷积的视觉注意机制,提供了一种从整体角度理解图像的方法。然而,这两类方法在分割图像时仍然面临前景物体尺度变化多样性的挑战。如图1(a)和(b)所示,具有大尺度物体的预测结果往往具有更好的精确率和召回率,同时存在较大的均方误差,而小尺度物体的分割图通常表现出相反的效果。也就是说,对于包含非常大或非常小的物体的图像场景,存在非对称分割要求。如图1(c)和(d)所示,基于卷积神经网络的方法如LDF在处理大型物体时可能会产生更多的失败样例,而基于视觉Transformer的方法如VST则在处理小型物体时遇到问题。
针对极端尺度场景这种非对称需求,本工作提出了感知扩展与环路代偿的前景物体分割方法。在该类分割场景中,大尺度物体需要更宽的感受野以区别前景和背景,而小尺度物体需要高分辨率的特征来补充更丰富的细节。为了同时满足极端尺度物体的非对称分割需求,优化并补充极端大或小尺寸物体的感受野,本工作首先构造了分辨率极端解耦的特征感知扩展编码器,以实现全局低分辨率特征和细节高分辨率特征的并行提取;然后设计了动态互补注意力模块,以实现全局和细节特征的增强与整合;在此基础上,构造了环路代偿的多尺度路径互补解码器,实现了不同尺度特征的相互补充和增强;最后,在5个国际基准数据集上进行实验对比,该方法在5个常用评估指标上超过了16种同类高水平前景物体分割方法,能够更好地处理极大和极小尺寸物体的分割问题。该成果已被CCF-A类期刊Transactions on Image Processing (TIP) 2023录取。
03
CPP-Net: Context-aware Polygon Proposal Network for Nucleus Segmentation
作者:陈圣聪1,丁长兴1,刘民锋2,程骏3,陶大程4
单位:1华南理工大学, 2南方医科大学,3A*STAR,4悉尼大学
邮箱:c.shengcong@mail.scut.edu.cn
论文:
https://ieeexplore.ieee.org/document/10024152
代码:
https://ieeexplore.ieee.org/document/10024152
细胞核分割任务常常在细胞计数以及细胞追踪等相关系统中充当重要角色。在细胞核分割任务中,为区分粘连细胞,一种较为常见的方案是使用多边形来拟合每个独立的细胞核实例。然而,已有的基于多边形拟合的方法一般只使用每个细胞核中心或者中心附近的多边形预测结果来拟合整个细胞核,而忽略了当前细胞核其余像素上携带的有用信息,这一问题常常会导致该类方法在分割精度上的下降。在本研究中,我们提出了上下文感知多边形候选框网络(Context-aware Polygon Proposal Network, CPP-Net) ,从模型结构、损失函数以及处理流程三个角度对已有的多边形拟合方法进行了改进,从而让所提出的算法能产生更精细且更鲁棒的预测结果。
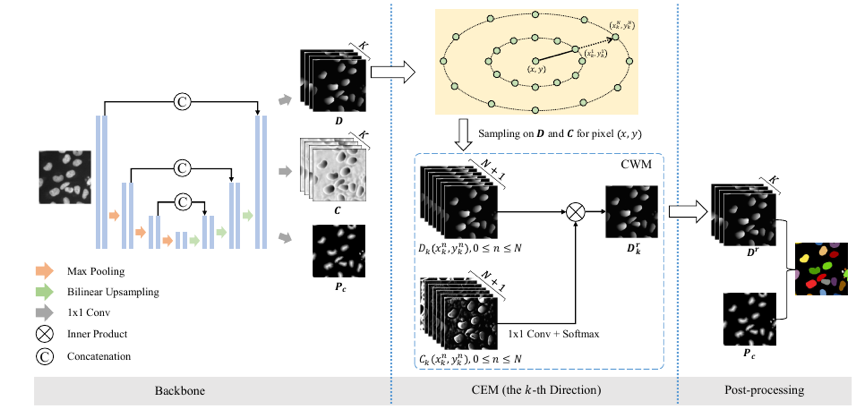
图1 CPP-Net的整体展示
首先,我们提出了上下文增强模块(Context Enhancement Module, CEM)。对每一个像素,在获得了该像素沿着K个预定义方向到其对应实例边界距离预测后,CEM将沿着每个方向利用该距离均匀选取该方向射线上的N个点,并融合当前点本身的距离预测与所选点的距离预测,从而得到更精准的距离预测结果。经过上述的采样融合的过程,每个像素上的距离预测将同时由其自身及其所在实例内的点集共同决定。其次,考虑到边界像素的预测噪声影响,我们引入了置信度预测分支,从而自适应地对所采样的点集重要性进行加权。第三,考虑到常见的损失函数往往只从像素层次监督预测结果而缺失了细胞核整体的监督信号,我们设计了形状感知(Shape-aware Perceptual, SAP)损失函数。最后,为了让多边形拟合的方法能产生更为精细的预测结果,且让该类方法更好地处理具有复杂形状的细胞核,我们引入了一组额外的语义分割支路,并基于该支路语义分割的结果改进了最终的后处理流程。
所提出的方法在DSB2018、BBBC006v1以及PanNuke三个数据集上都进行了验证,并且在这三个数据集上都取得了显著提升。为了验证CPP-Net的鲁棒性,我们也进行了跨数据集的验证实验,如表3所示,在跨数据集实验中我们的方法同样取得了显著的提升。
表1 在DSB2018和BBBC006v1上与SOTA方法的比较
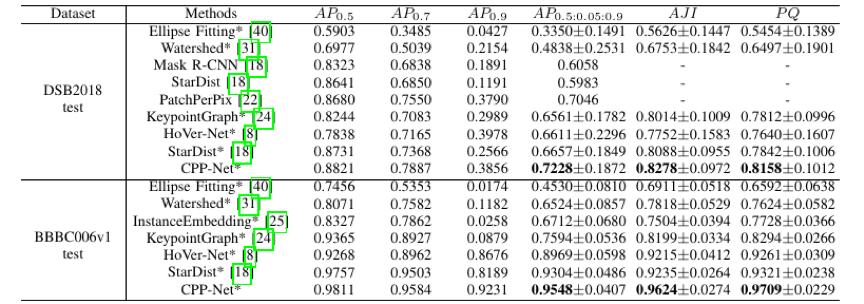
表2 在PanNuke上与SOTA方法的比较

表3 跨数据集比较

04
Selecting High-Quality Proposals for Weakly Supervised Object Detection With Bottom-Up Aggregated Attention and Phase-Aware Loss
通过自底向上的聚合注意力和阶段感知损失为弱监督目标检测选择高质量的提案
作者:吴志昊1,刘成亮1,文杰1,徐勇*1,2,杨健3,李学龙4
单位:1 哈尔滨工业大学(深圳),2 鹏城实验室,3 南京理工大学,4 西北工业大学
邮箱:
horatio_ng@163.com ;
liucl1996@163.com;
jiewen_pr@126.com;
laterfall@hit.edu.cn;
csjyang@njust.edu.cn;
xuelong_li@nwpu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10003247
谷歌学术主页:
https://scholar.google.com/citations?user=EnmDOYMAAAAJ
Github主页:
https://github.com/Horatio9702
(一)问题分析
本研究聚焦于弱监督目标检测(WSOD)任务,即检测器训练时仅知道图像中目标的类别,而不知道它们的具体位置。主流方法通常遵循两阶段范式:实例挖掘阶段首先生成一系列与类别无关的目标潜在位置的候选区域并推测它们的所属类别,再从中选择样本(伪标签)用于检测器的训练;实例细化阶段迭代地使用上一阶段生成的伪标签训练分类器,以获得越来越完善的检测结果。本工作旨在缓解两类不准确伪标签对检测器性能的不利影响:一是局部主导,即仅检测到目标最具有鉴别力的部位,如动物的头部;二是非紧密框,即来自同一类别的多个相邻实例被认为是一个整体,或者边界框包含一些背景区域。
为此,我们专注于选择高质量的提案作为WSOD的监督。以前的工作表明,部分主导背后的原因是基于CNN的分类器的顶层特征更关注语义特征而不是位置线索。因此,一个直观的想法是利用包含更多位置线索的低层特征。在弱监督和全监督目标检测领域,已经有一些工作遵循这一思路。例如,利用由浅层和超像素产生的低级信息来评估每个提案的目标性和利用网络多层产生的综合注意图来指导这些层的特征学习。特征金字塔网络融合了来自多个层的特征,以改善全监督目标检测器的位置表示。然而,它不适用于WSOD,因为它引入了具有可学习参数的新层,导致模型收敛到一个局部最小值。受其启发,我们提出了自底向上的聚合注意力(BUAA),其利用与目标定位相关的多层注意力图,且不需要额外的学习分支或可学习参数。与迫使各层的注意图拟合综合注意图和通过卷积层合并多级特征不同,我们以空间注意力的方式直接用综合图改进网络顶层的特征表示。通过这种方式,覆盖完整目标或至少是更大的目标区域可以得到高分。此外,它不添加学习分支或可学习参数。一方面,它不需要设置超参数来平衡分支的训练,所以它可以灵活地插入WSOD框架中。另一方面,训练初期的监督生成高度依赖于预训练模型的特征提取能力,而BUAA避免了因添加参数而导致的这种能力的削弱。
至于非紧密框问题,一个直观的解决方案是增加具有正确标签的实例损失的权重,而抑制具有非紧密框的标签的权重。因此,核心问题是如何区分它们。以前的许多工作都遵循这样的假设:正确框的置信度通常高于非紧密框的置信度。然而,这个假设忽略了这样一种情况,即只有低质量的提案被设置为伪标签时,它们可能在几次实例细化后获得高分,因为它们主导了以往分类器的训练。为了解决这个问题,我们提出使用实例挖掘阶段的损失来衡量监督质量。具体来说,我们认为实例挖掘阶段的损失越大,实例细化阶段的标签的整体质量就越低,反之亦然。其原因如下。较大的损失表明模型对图像包含正类实例的信心不足,因此即使是得分最高的提案也可能是不可靠的。如果没有准确的初始监督,在实例细化阶段产生的伪标签也可能是不精确的。基于这一假设,我们提出了一个阶段感知损失(PA-loss),其调制因子与实例挖掘阶段的损失有关,用于重新权衡实例细化阶段的损失。此外,在现有方法的启发下,我们还设计了一个损失权重(与提案分数相关),它与阶段感知损失协作,进一步平衡正确框和不紧密框对训练的影响。
(二)方法设计
提出的方法的整体架构如图1所示,包括两个新颖的模块:自底向上的聚合注意力和阶段感知损失。
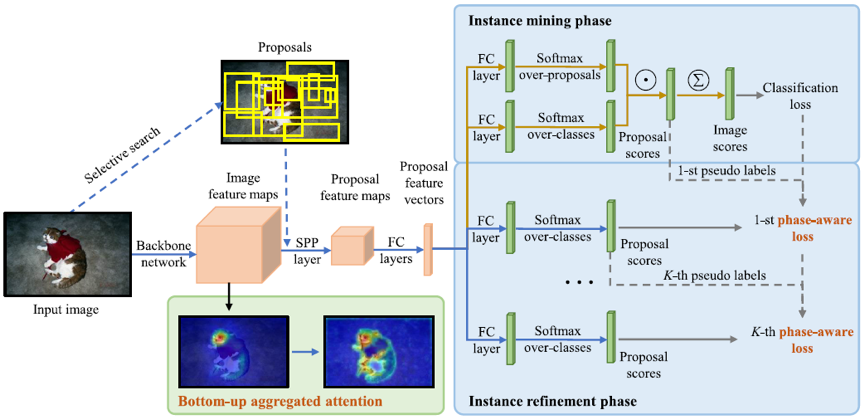
图1 提出的方法的整体架构图
自底向上的聚合注意力:我们的目标是通过空间注意力机制,充分利用多个卷积层中包含的空间线索。为此,我们首先回顾一下流行的空间注意力结构。给定一个特征图F∈H*W*D,其中H、W和D分别代表高度、宽度和深度。注意力模块以为输入,通过一些卷积层生成一个归一化的注意图A∈H*W。之后,A乘以F获得精炼的特征图F^作为下一层的输入。然而,卷积层包含可学习的参数,可能导致训练偏离理想的解。因此,一个挑战是如何在不增加可学习参数的前提下生成A。另一个挑战是如何聚集多尺度注意力图。出于同样的原因,具有卷积操作的连接是不适用的。
为了解决上述挑战,我们对调整后的特征图进行空间最小-最大归一化,以产生注意力图,然后通过一个逐元素取最大值操作,自下而上地融合它们。形式上,网络包含Q个卷积块{B1,......,BQ},相应的特征图被表示为{FB1,...,FBQ},其中FBQ∈H*W*D代表顶层特征图。
如图2所示,我们首先通过最大池化操作将{FB1,...,FBQ}大小调整为与FBQ相同的高度和宽度,表示为{FB1r,...,FBQr}。接下来,每个块的注意力图ABq∈H*W通过逐通道平均池化和空间最小-最大归一化计算:
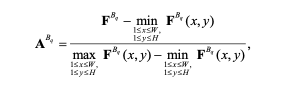
其中
![]()
然后,我们计算聚合注意力图如下:
![]()
其中max()是逐元素取最大值操作,A表示综合注意图。最后,我们通过A来细化顶层特征图:
![]()
其中Y∈H*W是全1矩阵,⊗表示逐元素乘法。值得注意的是,最小-最大归一化+逐元素取最大值并不是产生综合注意力的唯一选择。我们还探索了其他方法,如用逐元素Sigmoid函数生成注意图,用逐元素取平均值操作聚合注意图。这些方法也取得了性能上的提高,但不如最小-最大归一化+逐元素取最大值效果好。
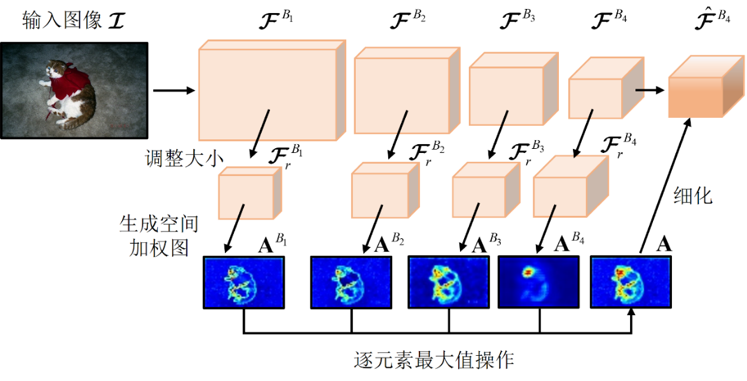
图2 在VGG-16上应用BUAA的图示
阶段感知损失:我们的目标是提高具有正确标签的实例的损失权重,并抑制具有非紧密框的实例的权重。核心问题是如何鉴别它们,因为边界框的真值是未知的。在本工作中,我们提出实例挖掘阶段的损失是衡量监督质量的一个重要指标。具体来说,大的损失表明当前的模型对图像中包含正例的信心不足。因此,生成的监督可能是不可靠的。一方面,如果没有准确的初始监督,在实例细化阶段挖掘出的提案也可能是不精确的。另一方面,这些不准确的例子在训练中占主导地位,导致它们在细化中逐渐获得高分。因此,基于置信度的策略会把它们误认为是高质量的提案,导致训练偏离正确的方向。总而言之,在挖掘阶段的大的损失通常意味着在细化阶段的整体低质量伪标签,反之亦然。
基于上述分析,我们建议在在线实例分类器细化方法(OICR)中使用的加权softmax损失函数中引入一个调制因子wPA=1+σ(-L0CE),其中σ()是sigmoid函数。我们将第k'个实例细化阶段的阶段感知损失定义为:
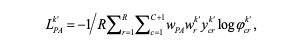
其中wk'r,r'对应于第{k' - 1}阶段中第c'类的最高分提案(即核心提案),r对应于最高分提案及其相邻提案。
遵循OICR,我们也设计了一个与提案分数相关的损失权重,以更好地衡量伪标签的质量。
![]()
(三)实验结果
我们在PASCAL VOC 2007(5,011用于训练,4,951用于测试)、PASCAL VOC 2012(11,540用于训练,10,775用于测试)和MS COCO 2014(82,783用于训练,40,504用于测试)上进行了广泛的实验。PASCAL VOC上的评价指标为mAP(用于测试集)和CorLoc(用于训练集)。MS COCO上的评价指标为AP50(IOU阈值为50%)和AP(IOU各阈值下的平均值)。实验结果表明我们提出的模块是有效的,方法达到了最先进的水平(见表1和图3)。
表1 在PASCAL VOC 2007上的mAP结果比较


图3 可视化结果对比
05
DeflickerCycleGAN: Learning to Detect and Remove Flickers in a Single Image
作者:林晓丹,李杨福,朱建清,曾焕强
单位:华侨大学
邮箱:
xd_lin@hqu.edu.cn
21013082029@stu.hqu.edu.cn
jqzhu@hqu.edu.cn
zeng0043@hqu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10006737
当光源使用交流供电时,若相机的曝光参数与光源频率不匹配时将导致图像频闪现象的发生。在CMOS相机的逐行曝光方式下,图像频闪表现为行和行之间的明暗变化。已有的针对单幅图像的频闪消除方法需要已知光源系统参数或相机快门参数,亦或需要利用同一相机拍摄的一组图像作为参照,因此对于现实中无先验信息的单幅频闪图像,其频闪消除性能难以发挥。
对此,本文提出了如图1所示的基于循环生成对抗网络的无监督频闪消除框架DeflickerCycleGAN。该框架包含两个生成网络和两个鉴别网络,生成器和鉴别器详细结构如图2 所示。其中两个生成网络分别实现频闪图像的生成和频闪的消除。为了利用频闪信号的特征,论文提出了两项损失函数:频闪损失和梯度损失,以在颜色和结构空间上对生成器进行充分的监督,从而避免去除频闪后的图像出现颜色失真和频闪去除不充分。此外,利用DeflickerCycleGAN训练得到的马尔可夫鉴别器,我们还构建了一个多尺度集成分类器。该分类器可以单独用于频闪图像的检测。
论文方案不需要成对的参考图像即可实现图像频闪的消除。我们在两个合成频闪图像数据集和一个真实数据集上进行了验证,表1和表2的实验结果表明:相比传统的利用图像平坦背景区域进行频闪消除的方法和基于原始的循环对抗生成网络进行频闪消除方法,我们提出的无监督图像去频闪方法极大地增强了复原图像的质量。
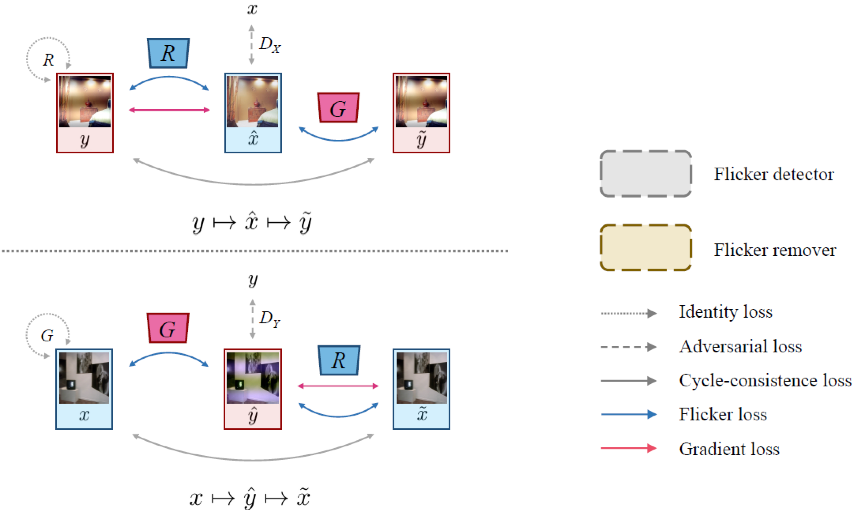
图1 DeflickerCycleGAN网络框架示意图

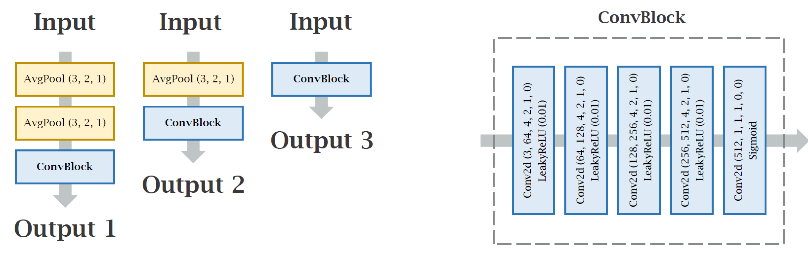
图2 生成器和判别器具体结构图
表1 图像去频闪性能在合成数据集的验证

表2 图像去频闪性能在真实数据集的验证


 京公网安备11010802017125号
京公网安备11010802017125号