
2023年论文导读第十二期
【论文导读】2023年论文导读第十二期
CCF多媒体专委会 2023-06-20 19:00 发表于山东


论文导读
2023年论文导读第十二期(总第七十八期)
目 录
|
1 |
Mapping Degeneration Meets Label Evolution: Learning Infrared Small Target Detection with Single Point Supervision |
|
2 |
Video Event Restoration Based on Keyframes for Video Anomaly Detection |
|
3 |
Tri-Perspective View for Vision-Based 3D Semantic Occupancy Prediction |
|
4 |
SIEDOB: Semantic Image Editing by Disentangling Object and Background |
|
5 |
Class Balanced Adaptive Pseudo Labeling for Federated Semi-Supervised Learning |
01
Mapping Degeneration Meets Label Evolution: Learning Infrared Small Target Detection with Single Point Supervision
作者:应昕怡
单位:国防科技大学
邮箱:
yingxinyi18@nudt.edu.cn
论文:
https://arxiv.org/pdf/2304.01484.pdf
代码:
https://github.com/XinyiYing/LESPS
论文介绍网址:
https://xinyiying.github.io/LESPS/
近年来,训练卷积神经网络以全监督的方式实现红外小目标检测,已经取得了显著的研究进展。然而,全监督的训练方式需要大量的逐像素注释,标注成本高昂。为了解决这一问题,本文首次尝试实现点监督下的红外小目标检测。
在点标签监督的训练阶段,我们发现了一个有趣的“映射退化”现象。如图1所示,在单点标签作为监督的情况下,卷积神经网络总是倾向于在早期以低置信度分割目标附近的像素簇(区域-区域映射),然后逐渐收敛以高置信度预测真值点标签(区域-点映射)。“映射退化”现象的原因可总结如下:1)红外系统的特殊成像机理。目标只有强度信息,没有结构和纹理细节,导致目标区域内的像素高度相似。2)红外小目标的局部对比度先验。目标区域内的像素更亮或更暗,与局部背景杂波形成高对比度。3)卷积神经网络从易到难的学习特性。卷积神经网络总是倾向于先学习简单的映射,然后收敛到困难的映射。与区域到点映射相比,区域到区域映射更容易,因此往往是区域到点映射的中间结果。其中,前两个因素导致点标签之外的映射区域,最后一个因素导致映射退化的过程。

图1 “映射退化”现象
基于“映射退化”现象,我们为弱监督下的单帧红外小目标检测问题提出了一个单点监督下的标签进化框架(label evolution with single point supervision, LESPS)。为了便于理解,我们采用1维曲线说明标签进化框架的具体流程。如图2所示,虚线左侧的子图表示网络预测结果,其中黑色曲线表示标签更新框架内的网络预测结果,而灰色曲线表示网络在没有标签进化下的网络预测结果。在虚线的右侧,第一列和第二列分别表示当前标签和更新的标签,黑色箭头表示每一轮标签更新。标签更新总体框架可概括如下:在点标签作为监督的情况下,在第1轮标签更新中,当前的网络预测1st Pred用于更新当前点标签Point Label以生成第1个更新标签1st Label。随后该标签用于监督网络训练,直到第2轮标签更新。通过迭代标签更新和网络训练,网络预测最终可以近似更新后的伪掩码标签,并且网络可以同时学习以端到端的方式实现像素级红外小目标检测。实验结果表明,标签更新框架可以应用于现有的不同的单帧红外小目标检测网络,并使它们在交并比(Intersection over Union, IoU)和检测概率(Probability of detection, Pd)方面分别达到70%和95%以上的全监督性能。
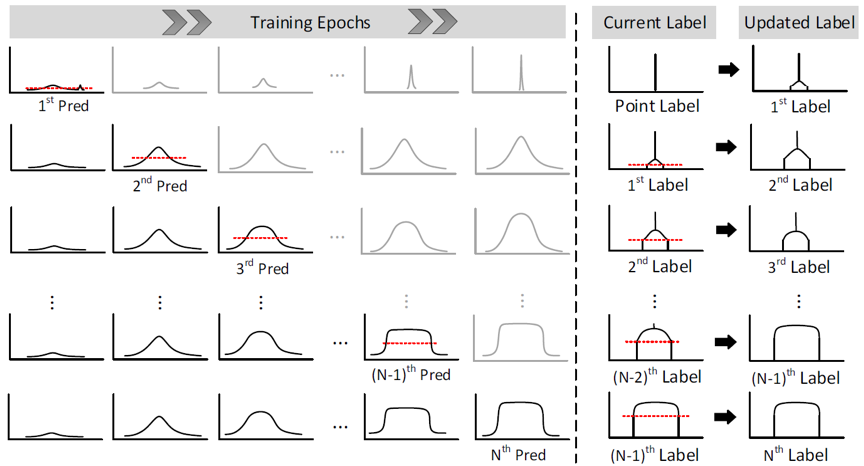
图2 单点监督下的标签进化框架
02
Video Event Restoration Based on Keyframes for Video Anomaly Detection
作者:杨智伟1,刘静1*,毋朝阳1,吴鹏2*,刘晓涛1
单位:1西安电子科技大学,2西北工业大学
邮箱:
zwyang97@163.com
neouma@163.com
15191737495@163.com
xdwupeng@gmail.com
xtliu@xidian.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/html/Yang_Video_Event_Restoration_Based_on_Keyframes_for_Video_Anomaly_Detection_CVPR_2023_paper.html
*通讯作者
1 引言
视频异常检测是一个至关重要的计算机视觉问题。现有的基于深度神经网络的视频异常检测方法大多遵循帧重构或帧预测两种路线。然而,由于缺乏对视频中更高阶视觉特征和时序上下文关系的挖掘,限制了这两种方式异常检测性能的进一步提升。受视频编解码理论的启发,我们提出了一种新的视频异常检测范式来突破这些限制:首先,我们提出了一个新的基于关键帧还原视频事件的任务,此任务通过鼓励深度神经网络基于视频的关键帧来推理视频序列中间缺失的多帧,从而还原完整的视频事件,它能促使深度神经网络来挖掘和学习视频中潜在的高阶视觉特征和全局时序上下文关系。为此,我们提出了一个新颖的带有双跳跃连接的U型 Swin Transformer 网络(USTN-DSC)用于视频事件还原。其中设计的跨注意力和时序上采样残差跳跃连接用来进一步辅助还原视频中复杂的静态和动态运动目标特征。另外,我们还提出了一个简单有效的邻帧差分时序损失函数用于约束视频序列的时序一致性。大量的实验结果表明,USTN-DSC的性能优于现有的大多数方法,验证了我们方法的有效性。
2方法
我们提出的USTN-DSC遵循着经典的U-Net网络架构设计形式,它主要由特征提取器、编码器、解码器和输出头四个部分组成。其中特征提取器和输出头主要由2D卷积层组成,编码器和解码器则由多层swin transformer 块和2D卷积层联合组成。图1展示了USTN-DSC的总体框架图。
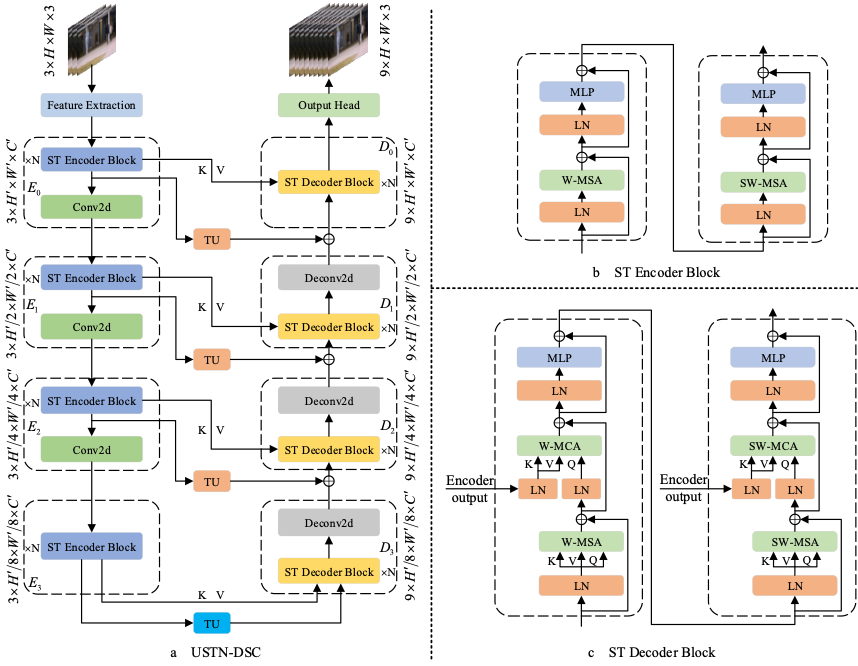
图1 方法总体框架
具体来说,给定一个包含T帧的视频序列,我们取其中的起始帧、中间帧和结束帧作为输入的三个关键帧。这三个关键帧在时序维度上堆叠,然后输入特征提取器进行初始的特征提取和维度缩减。接着,再将其输入编码器进行特征编码,得到高阶特征表示,再将其输入解码器进行解码。在解码部分,为了应对视频中复杂的运动模式从而更好的还原视频事件,我们在USTN-DSC的编解码器中构建了双跳跃连接。首先,我们在构成编码器和解码器的swin transformer块中的基于常规和偏移窗口的多头自注意力模块后分别加入了一个跨注意力机制模块。这个模块接收来自前一个解码层的输出特征作为Query,接收来自编码器对应层级输出的特征作为Key和Value。通过查询编码器对应层级输出的不同尺度和距离的特征,跨注意力机制模块能辅助解码器更好的生成缺失帧中特定快速运动目标的特征。另外,我们还设计了一个由3D反卷积层构成的时序上采样模块,以残差的形式连接编解码器对应的各个编解码层。这个模块可以弥补跨注意力连接中原始细节特征查询的不足,从而进一步促进解码器更好地恢复视频序列中的背景和慢速物体的细节信息。最后,解码器的输出通过输出头得到还原后的视频序列,根据还原的视频序列与真实视频序列之间的误差即可判定是否发生异常。
表1 USTN-DSC在公开数据集上与主流方法的性能对比

3 实验结果
我们在Ped2、Avenue和ShanghaiTech三个公开数据集上进行了实验。我们采用帧级别的AUC作为评价指标。表1对比了我们的方法与现有主流方法的性能。
为了更直观的表明我们方法的效果,我们展示了一些定性的结果。图2展示了我们方法在三个数据集上部分测试样本上的异常分数曲线图。从异常曲线图中可以观察到,我们的方法对异常事件具有良好的灵敏性,能有效检测出视频中的异常事件。
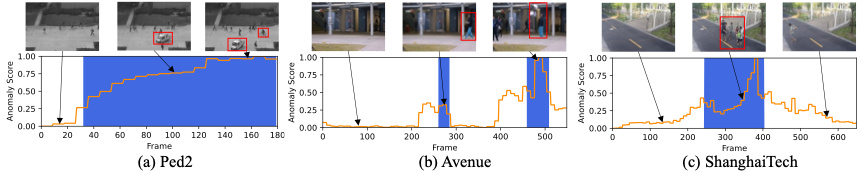
图2 异常分数曲线图
03
Tri-Perspective View for Vision-Based 3D Semantic Occupancy Prediction
作者:黄原辉*,郑文钊*,张云鹏,周杰,鲁继文†
单位:清华大学
邮箱:
huangyh22@mails.tsinghua.edu.cn
zhengwz18@mails.tsinghua.edu.cn
lujiwen@tsinghua.edu.cn
论文:
https://arxiv.org/pdf/2302.07817
项目主页:
https://wzzheng.net/TPVFormer/
代码:
https://github.com/wzzheng/tpvformer
*共同作者
†通讯作者
以视觉为中心的自动驾驶感知方法广泛采用鸟瞰图(BEV)表示来描述3D场景。尽管它比体素表示更高效,但它难以用单个平面描述场景的细粒度3D结构。为了解决这个问题,我们提出了一种三平面(TPV)表示法,它推广了现有的BEV表示,加入了相互正交的另外两个平面。对于三维空间中的每个点,TPV 通过将其在三个平面上的投影特征相加来对其进行建模。

为了将2D图像特征提升到3D TPV空间,我们进一步提出了一种基于Transformer的TPV编码器(TPVFormer)以高效地提取TPV特征。我们使用2D Backbone来提取环视相机图像的多尺度特征。然后,我们使用交叉注意力自适应地将2D特征提升到TPV空间,并使用跨平面混合注意力来实现TPV平面之间的交互。最后,我们使用一个轻量级预测头来预测三维空间中某点的语义占用。TPVFormer以相机图像为输入,且仅使用稀疏的LiDAR语义标签进行训练,但可以有效地预测所有体素的语义占用。
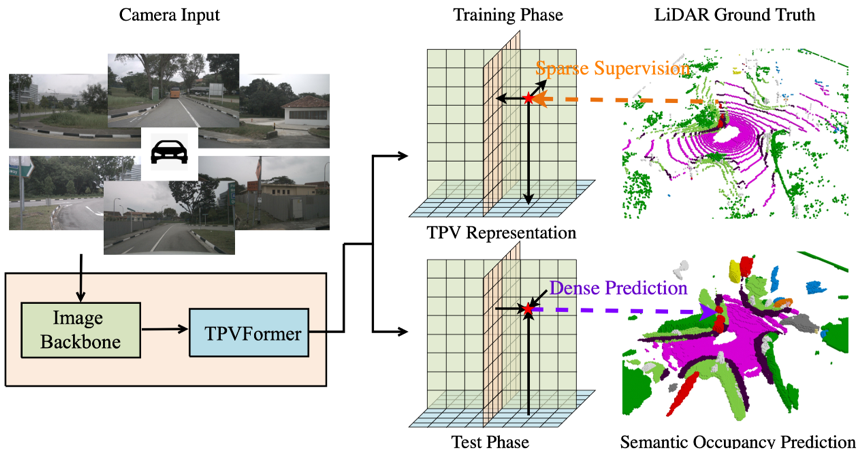
我们在三种不同任务上进行了测试,即三维语义占用预测、点云分割和语义场景补全。对于所有任务,我们的模型仅使用RGB图像作为输入。由于难以获得密集的语义标签,我们为基于视觉的三维语义占用预测提出了一种实用但具有挑战性的范式。在该范式下,模型仅使用稀疏语义标签(点云)进行训练,但需要在测试期间为相关3D空间中的所有体素生成语义占用。我们的方法是第一个在这项具有挑战性的任务上取得成效的方法。

在点云分割任务上,TPVFormer取得了和基于点云的方法相当的性能,首次证明了基于视觉的方法在点云分割任务上的有效性。此外,TPVFormer在KITTI数据集的语义场景补全任务上,取得了基于视觉方法中的SOTA性能。
04
SIEDOB: Semantic Image Editing by Disentangling Object and Background
作者:罗午阳1,杨夙1,张新建1,张卫山2
单位:1复旦大学,2中国石油大学(华东)
邮箱:
wyluo18@fudan.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Luo_SIEDOB_Semantic_Image_Editing_by_Disentangling_Object_and_Background_CVPR_2023_paper.pdf
代码:
https://github.com/WuyangLuo/SIEDOB
语义图像编辑是一种有效的图像编辑工具,它能够根据用户提供的语义图灵活地修改输入图像的内容。对于图像编辑任务,背景和前景具有完全不同的特点。前景包含了一个个独立的物体,而背景具有无规则的形状并且可能横跨很大的面积。然而,之前的方法将输入图像的背景和前景视作一个整体,使用单一的模型处理它们。这种方式导致这些方法很难处理复杂内容的图像,因为可能导致生成不真实的物体和纹理不一致的背景。为了解决这个局限性,本文提出了一种新的生成策略,被称为 SIEDOB,他的核心思想是显式地利用多个异构的子网络去分离地处理前景物体和背景。我们在 Cityscapes 和 ADE20K-Room 两个复杂数据集上进行了广泛的实验,展示了本文方法能够有效地合成逼真的和多样性的物体以及纹理一致的背景。

图1 SIEDOB 工作流程
SIEDOB的工作流程如图1所示。首先,SIEDOB将输入图像的被编辑区域拆分为背景和一个个物体实例。然后,我们将拆分的结果送入若干个特制的生成器,独立地完成它们的编辑。最后,所有被合成的局部内容被重新嵌入到它们原始的位置并通过一个混合网络生成上下文和谐的结果。为了使背景的生成区域与已有区域保持上下文的一致性,我们提出了一种SASPM模块,它能有效地将已知区域的纹理特征传播到被编辑区域,如图2所示。另外,为了进一步的增强上下文一致性,我们设计了一种锚定边缘的图像块判别器,如图3所示。对于前景物体,我们提出了一种基于风格银行的多样性物体生成器,如图4所示。在训练时,它首先从训练集中随机地选取一个同类别的图像作为风格图像,并通过一个风格编码器提取其风格码。最后,利用这个风格码控制生成结果的纹理风格。当训练完成时,利用风格编码器从所有的训练样本中提取并保存它们的风格码,进而建立一个风格银行。在测试时,随机从银行中采样不同的风格码以实现多样性的生成结果。
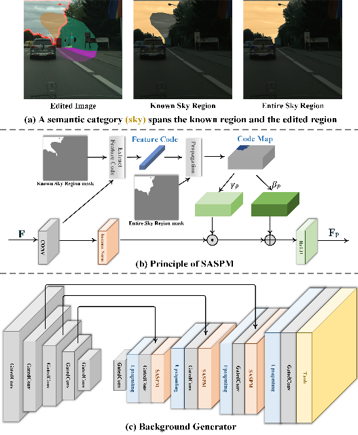
图2 SASPM模块和背景生成器的结构

图3 锚定边缘的图像块判别器

图4 风格多样物体生成器的结果及其训练测试过程
相比于之前的工作,本文的方法能够生成背景一致的结果并且更好地处理存在重叠的多个物体,如图5所示。

图5 可视化结果对比
05
Class Balanced Adaptive Pseudo Labeling for Federated Semi-Supervised Learning
作者:李明,李庆利,王妍*
单位:上海市多维度信息处理重点实验室,华东师范大学
邮箱:
lm1640362161@gmail.com,
qlli@cs.ecnu.edu.cn,
ywang@cee.ecnu.edu.cn
论文:
https://github.com/minglllli/CBAFed
*通讯作者
本文研究联邦半监督问题(FSSL)。随着联邦学习的兴起,联邦半监督问题在近几年被广泛的研究。然而,相比于传统的半监督任务,由于Non-IID的问题,联邦半监督学习有很多新的挑战:1)首先,未标记客户端没有标记数据。因此,在没有标签指导的情况下,训练可能很容易产生偏差。2)由于标记和未标记客户端的类别分布不同,即非独立和非同分布数据(Non-IID)设置,通过在标记客户端训练的模型使用伪标记或一致性正则化框架在未标记客户端上可能会产生不准确的监督信号。

图1 CBAFed方法。
3)由于CNN中的灾难性遗忘问题,随着未标记客户端的训练过程进行,模型可能会忘记在标记客户端上学到的知识,从而大幅降低预测准确性。
为了解决这些问题,我们提出CBAFed方法,如图1所示,从伪标记的角度研究FSSL。在CBAFed中,对于标记客户端,如图1右上角所示,为了使模型达到更好的最优解,我们在本地监督训练和全局模型聚合中提出了残差权重连接,这种方法可以使得标记客户端本地的监督训练更加的稳定鲁棒,并且最后能够获得更好的本地模型。对于未标记客户端,如图1右下角所示,我们采用固定的伪标记策略来处理灾难性遗忘问题,通过在每轮通信开始时传递未标记数据的信息,获得并保持一个固定的数据集。接着,用这个数据集进行接下来的本地训练。最后,如如图1左侧所示,通过考虑本地客户端所有训练数据的经验分布,我们设计了类平衡的自适应阈值(class balanced threshold),以促进平衡的训练过程。分析表明我们设计的自适应阈值可以良好的促进类别平衡,并且可以给尾部类别(tail class)的数据设置较高的阈值,从而更适用于FSSL问题。
如表1所示,我们对五个数据集进行了广泛的实验,以展示CBAFed的有效性。实验表明,我们的方法的性能优于之前的方法,尤其在任务简单的数据集上(如Fashion MNIST),我们的方法的性能大幅度领先之前的方法。接下来,我们还进行了分析实验。我们首先展示了标记客户端使用/不使用残差权重连接方法训练时的测试正确率曲线,如图2所示。实验表明,残差权重连接方法可以使模型在数据量小且分布不均衡的情况下使得训练更加稳定鲁棒,并且最后拥有更好的性能。我们还研究了不同的伪标记方法在FSSL下的有效性,如图3所示。实验表明,我们提出的固定伪标记方法拥有最好的性能。最后,我们进行了消融实验来证明每个模块的有效性,以及敏度分析实验验证模型性能对超参数的敏感程度。
表1 在5个数据集上和SOTA方法的比较。
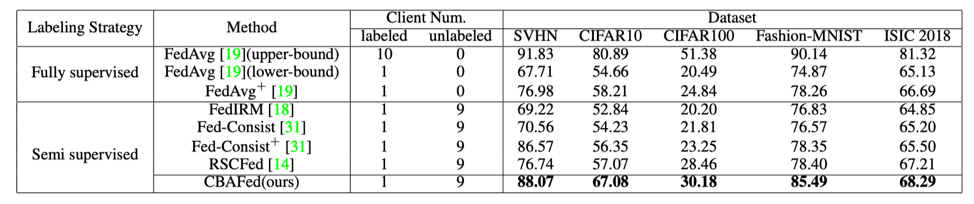
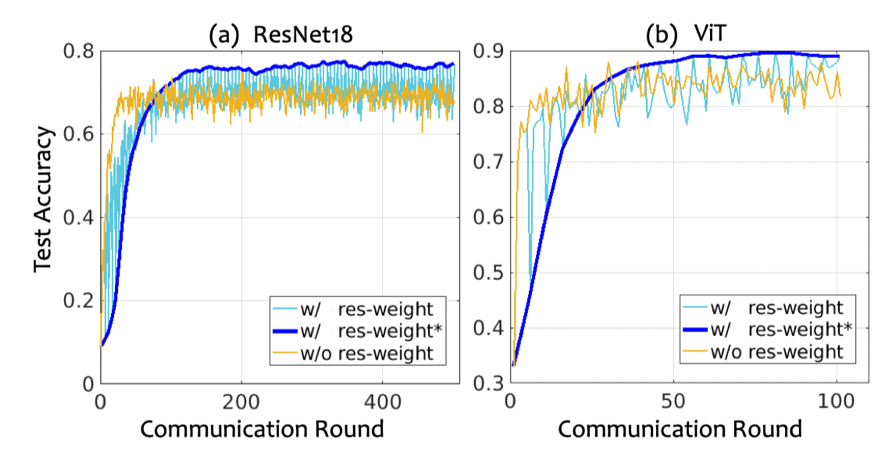
图 2 使用/不使用残差权重连接方法的测试正确率曲线。
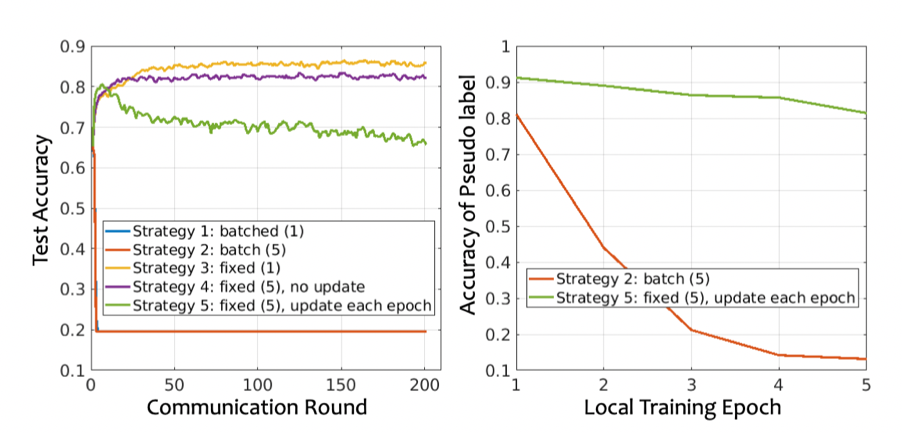
图 3 不同的伪标记方法在FSSL下的正确率曲线。

 京公网安备11010802017125号
京公网安备11010802017125号