
2023年论文导读第十三期
【论文导读】2023年论文导读第十三期
CCF多媒体专委会 2023-07-04 19:00 发表于山东


论文导读
2023年论文导读第十三期(总第七十九期)
目 录
|
1 |
Multiplex Transformed Tensor Decomposition for Multidimensional Image Recovery |
|
2 |
DeSTSeg: Segmentation Guided Denoising Student-Teacher for Anomaly Detection |
|
3 |
Efficient Mask Correction for Click-Based Interactive Image Segmentation |
|
4 |
Ambiguity-Resistant Semi-Supervised Learning for Dense Object Detection |
|
5 |
MoLo: Motion-augmented Long-short Contrastive Learning for Few-shot Action Recognition |
01
Multiplex Transformed Tensor Decomposition for Multidimensional Image Recovery
作者:冯兰兰,朱策,龙珍,刘佳妮,刘翼鹏
单位:电子科技大学
邮箱:
lanfeng@std.uestc.edu.cn;
eczhu@uestc.edu.cn;
zhenlong@std.uestc.edu.cn;
jianniliu@std.uestc.edu.cn;
yipengliu@uestc.edu.cn
论文:
https://ieeexplore.ieee.org/document/10153488
代码:
https://github.com/LanlanFeng/MTTD
随着计算设备的进步和存储容量的提高,高维数据在现实世界中变得无处不在。例如,彩色图像有两个空间维度和一个颜色维度,光场图像除了空间域之外还包含额外的角度域。张量是标量、向量和矩阵的高阶推广,可以直观地保留多路数据的高维结构信息。张量分解将一个大尺寸张量分解成许多小尺寸因子,具有广泛的应用,如视频监控中的背景初始化、子空间聚类、图像去噪、补全和回归其中,张量补全因其恢复张量数据缺失项的能力,近年来受到越来越多的关注。 这样的缺失问题在数据的获取、传输和表达过程中往往很容易出现。张量补全试图利用张量数据元素之间的相关性,通过假设待恢复数据具有低秩的结构,进而实现复原。
低秩张量补全因张量分解框架不同而异。与矩阵的SVD不同,张量有不同类别的分解形式。Tucker 分解只能探索张量一个维度与其他所有维度之间的相关性,这种极度不平衡性往往会导致性能不佳。T-SVD存在两个缺点:旋转敏感性和维度限制。前者意味着第三维的低秩信息没有得到充分的利用,因为矩阵SVD是在前两个维度上执行的,而在第三维度上只进行线性变换(比如FFT,DCT等);后者意味着其只对3阶数据有效。
因此,本文提出了一个新颖的多路变换张量分解框架MTTD,一方面,它依次挖掘了每个维度的冗余信息;另一方面,它对于任意N阶数据有效,而不仅仅适用于3阶张量。 它将一个N阶张量分解成一个核心张量,核心张量的每个维度通过张量乘积连接一个正交的3阶因子张量。以三阶数据为例,图1显示了其分解示意图。基于MTTD,我们构造了相关的多维square模型及其具有平滑约束的变体用于低秩张量补全,图2给出了所提算法的流程图。经典的交替方向乘子法用于求解凸优化问题。对于性能测试,我们为所提方法选择了三中线性可逆变换。四组模拟数据补全实验(彩色图像、多光谱图像、彩色视频和光场图像)和两组真实数据实验(高光谱图像修复和去云)都表明,所提出的方法在恢复性能方面优于最先进的方法,收敛速度也具有竞争力。

(a)

(b)
图1 多路变换张量分解 (MTTD)
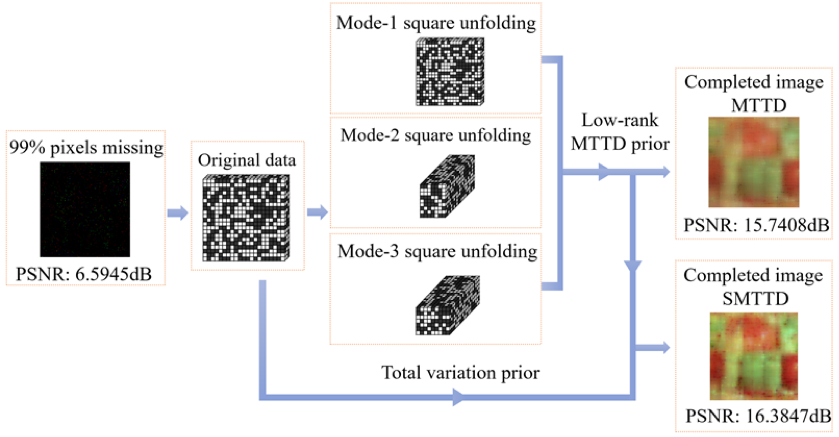
图 2 算法流程图
实验部分:
1. 彩色图像补全
为了更直观的看出所提方法的优越性,本文展示了彩色图像复原的结果,如图3所示。

图 3 在不同的采样率以及不同的缺失类型下,不同方法恢复图像的对比结果。(a) Observed images; (b) BCPF; (c) Square; (d) HaLRTC; (e) LRTCTV; (f) TRADMM; (g) TTNN (FFT); (h) TTNN (DCT); (i) TTNN (Data); (j) TNNTV; (k) WSTNN; (l) MTTD (FFT); (m) MTTD (DCT); (n) MTTD (Data); (o) SMTTD (Data).
2.去云实验
本文采用了大小为256 25638的多时相多云 Sentinel-2 图像,其中一帧的去云结果如图4所示。

图 4 不同对比方法的去云效果。
02
DeSTSeg: Segmentation Guided Denoising Student-Teacher for Anomaly Detection
作者:张轩1 ,李石羽2 ,李熹2 ,黄平2 ,单久龙2 ,陈挺1
单位:1清华大学,2Apple
邮箱:
riolu@vip.qq.com
shiyu_li@apple.com
weston_li@apple.com
huang_ping@apple.com
jlshan@apple.com
tingchen@tsinghua.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/html/Zhang_DeSTSeg_Segmentation_Guided_Denoising_Student-Teacher_for_Anomaly_Detection_CVPR_2023_paper.html
代码:
https://github.com/apple/ml-destseg
图像异常检测在工业产品质检等领域有着广泛的应用。由于异常数据发生频率极低且种类不可预知,本工作将其建模为一个单分类问题,即训练数据中仅有正常数据,但在推断中需要识别出异常数据,且在图像异常检测中需要识别出异常区域。已有的基于知识蒸馏的异常检测方法使用一个固定的预训练卷积网络作为教师网络,使用一个与教师网络同结构的随机初始化的网络作为学生网络,在训练时使用正常数据同时作为教师网络和学生网络的输入,优化学生网络使得学生网络生成和教师网络尽可能相似的特征表示;在推断时由于学生网络只在正常数据上进行训练,在异常数据上很可能产生和教师网络差异较大的特征表示(假设条件),以此进行异常检测。
上述技术路线有两个不足。第一,上述方法成立的核心在于假设条件的正确性,然而该条件的正确性缺乏理论保障,事实上在一些工作中已经发现神经网络具有过泛化的特性。第二,由于卷积网络各层的感受野差异,上述方法往往对多层特征同时进行优化,而在推断时汇总各层特征距离的方法往往是经验性的相加或相乘,这可能导致次优的结果。
本工作提出了DeSTSeg模型用于改进上述不足,其网络结构和训练过程如图1所示。DeSTSeg由一个固定的教师网络,一个降噪学生网络和一个异常分割网络构成,其训练分两步进行。首先,本工作使用基于随机Perlin噪声的方法生成随机异常区域掩码,并与异常纹理图像叠加,以对训练集中的正常图像生成配对的模拟异常图像。在第一步中,分别使用正常图像和模拟异常图像作为教师网络和降噪学生网络的输入,其优化目标与传统方法一致。在该过程中,降噪学生网络可以习得将异常图像复原为正常图像的特征表示,即在异常区域上对学生网络的输出进行了约束,改善了第一点不足。由于特征降噪任务更为复杂,需要全局语义信息的支持,本工作将学生网络的结构改为编码器-解码器结构。在第二步中,固定训练完毕的降噪学生网络,同时使用模拟异常图像作为教师和学生网络的输入,将两个网络的各层特征相似性信息输入到一个结构较简单的异常分割网络,使用该图像对应的异常区域掩码作为监督信号训练该分割网络。这使得模型以自适应的方式融合各层的特征相似性信息,得到更好的结果,改善了第二点不足。
本工作在MVTec AD数据集上进行了实验验证。在图像级异常检测上可达98.6%的AUC,在像素级异常检测上可达75.8%的AP,在实例级异常检测上可达76.4%的IAP,其性能超过了已有方法,具体异常检测的示例如图2所示,由图可知我们的方法可以准确、清晰地定位出各种大小与类型的异常区域。

图1 DeSTSeg的网络结构和训练过程

图2 异常检测的示例。左:原图;中:异常区域的金标准;右:模型给出的异常分割结果
03
Efficient Mask Correction for Click-Based Interactive Image Segmentation
作者:杜飞,袁建龙,王志斌,王帆
单位:阿里巴巴达摩院
邮箱:
dufei.df@alibaba-inc.com,
gongyuan.yjl@alibaba-inc.com,
zhibin.waz@alibaba-inc.com,
fan.w@alibaba-inc.com
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Du_Efficient_Mask_Correction_for_Click-Based_Interactive_Image_Segmentation_CVPR_2023_paper.pdf
代码:
https://github.com/feiaxyt/EMC-Click
交互式分割的目的是根据用户提供的信息来获得用户感兴趣目标的分割结果,主要用于分割任务的标注,可以简化标注的过程并减少标注成本。目前主流方法是通过鼠标点击正负点,正点点击在目标上,负点点击在背景上,以此来区分目标和背景。在这类方法中,通常采用一个现有分割网络作为基础模型,每次交互都推理整个模型。由于交互次数较多,模型的运行效率至关重要。如果每次都推理整个模型,整个交互运行效率比较低,尤其是在采用一个大骨干网络时。所以本文提出只在第一帧推理整个模型,并提取图像特征。从第二帧开始,只通过推理一个轻量的mask更新模型来获得更新的mask结果。通过这种方法,从第二帧开始,模型推理时间会有显著降低。本文方法与传统方法的区别如图1所示。
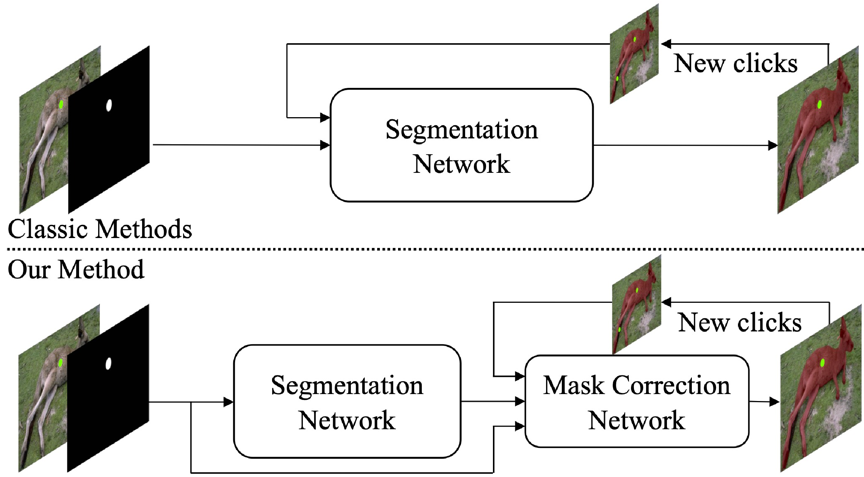
图1 与传统方法的对比
受限于mask更新模型的轻量性,一个简单的推理网络难以获得与当前其他方法相匹配的性能。所以本文进一步提出利用correlation和self-attention这两个模块来增强特征的区分能力。这两个模块通过更好地挖掘用户click的信息,提升mask更新网络的性能,使整个交互式分割模型能够达到SOTA结果。整个网络的框架如图2所示。图中比较重要的template selection、self-attention和correlation这三个模块。Template selection模块通过选择与click相似的像素做为模板,从而提升有限click特征的表达能力。self-attention将模板信息传播到整个特征图上,使特征更有利于区分目标和背景,correlation直接通过计算相似度图的方式获得目标的轮廓,提供目标的先验。

图2 本文方法框架图
实验分别验证了本文方法与现有方法在运行效率和性能上的对比。表1展示了本文方法与现有方法在模型参数、FLOPs以及在CPU上每次交互所需推理时间的对比。从第二个click开始,本文方法只需要推理mask更新网络,FLOPs和推理时间都非常低。对于一些比较复杂、需要更多交互才能完成分割的场景,本文方法具有明显优势。
表1 本文方法与现有方法在运行效率上的对比
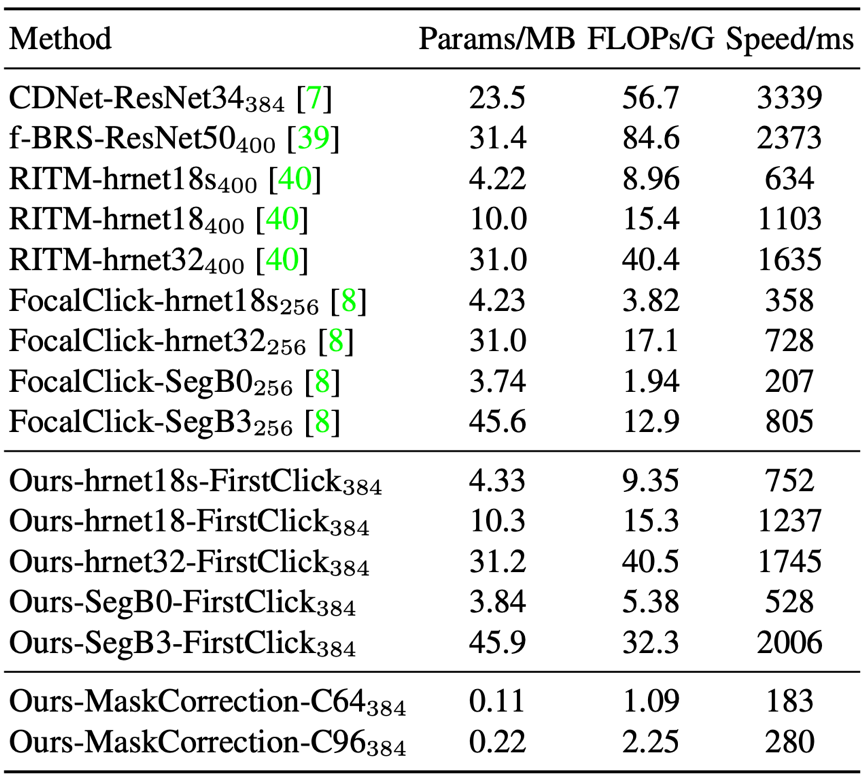
表2展示了本文方法与其他方法在相同backbone和相同训练数据的直观对比,本文的方法在整体上展现了与SOTA方法想匹配的性能。考虑到高效性,本文方法是更好的选择。
表2 本文方法与现有方法在性能上的对比

04
Ambiguity-Resistant Semi-Supervised Learning for Dense Object Detection
作者:刘畅1,*,张为明2,*,林相如2 ,张伟2,†,谭啸2,韩钧宇2,李小毛1,3,丁二锐2,王井东2
单位: 1 上海大学, 2 百度 VIS,3 上海人工智能实验室
邮箱:
liuchang123@shu.edu.cn
论文:
https://arxiv.org/abs/2303.14960
代码:
https://github.com/PaddlePaddle/PaddleDetection
项目主页:
https://cvpr.thecvf.com/virtual/2023/poster/23041
*共同作者
†通讯作者
1. 背景及动机
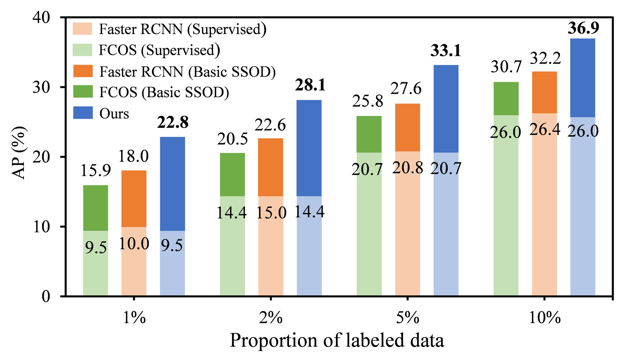
图 1. 在基础半监督框架下,单阶段检测器 (FCOS,绿色) 的提升弱于两阶段方法(Faster RCNN,黄色) 。
半监督目标检测 (SSOD) 旨在利用少量的标注数据和大量的无标注数据进行模型训练。在最新进 展中,半监督检测主要依赖于 Mean-Teacher 框架以及 Pseudo-labeling 技术,即用教师模型在 无标注图像上生成的伪标签训练学生模型,再基于学生模型在时序上的权重均值来更新教师模 型。然而基于该流程,相比于两阶段检测器 (如 Faster RCNN),单阶段检测算法 (如 FCOS) 仅能 取得相对有限的提升,如图 1.所示。通过定量分析,我们发现单阶段检测器的伪标签中存在严 重的筛选歧义性和样本分配歧义性。
表1 (筛选歧义性) 伪标签的质量分析。

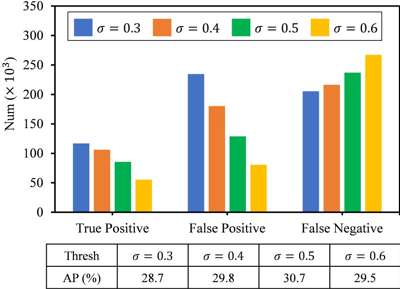
图2 (分配歧义性) 不同阈值下,样本分配的正确性。
筛选歧义性是指,由于检测结果的分类置信度和定位质量并不匹配,使得基于分类得分筛选的 伪标签不够准确。这一点在单阶段检测器中更加严重。表 1 中可以看到,相比于 Faster RCNN, FCOS 生成的检测结果中,分类得分和定位质量的相关性更低。换句话说,FCOS 筛选高质量伪 标签的能力更弱。
分配歧义性是指,基于伪标签的样本分配中,许多样本被分配了错误的学习标签。问题的根源 在于,为监督学习设计的样本分配方法忽略了伪标签的不可靠性。不准确的伪标签边界框使得 大量的背景区域被当成了正样本 (False Positive),同时被阈值过滤掉的物体被划分为了负样本 (False Negative)。如图 2.所示,不管伪标签的筛选阈值如何设置,分配结果中均存在大量的 FP 和 FN。相比于 Faster RCNN,FCOS 等单阶段检测器需要像素级的样本标签,因此对分配歧义性更加敏感。
2.算法简介
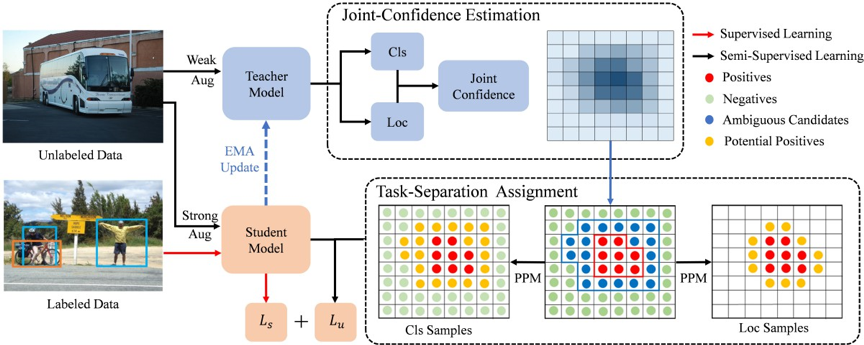
图 3. ARSL 框架图。对于无标签数据,教师模型首先通过 JCE 预测样本的联合置信度。然后,TSA 基于置信度将样 本划分为正样本、负样本和模棱两可的候选样本,并进一步为分类、定位任务挑选潜在正样本进行训练。
为了解决上述问题,我们提出了 Ambiguity-Resistant Semi-supervised Learning (ARSL),包括 Joint-Confidence Estimation (JCE) 和 Task-Separation Assignment (TSA)。针对伪标签的筛选歧 义性,JCE 基于分类任务和定位任务的联合置信度来评估伪标签的质量。更为具体地,JCE 通 过双分支结构,同时预测分类得分和定位质量,并将两者的乘积作为联合置信度,共同训练及 预测。针对伪标签的分配歧义性,TSA 摒弃了基于边界框的样本分配方法,直接利用教师模型在每个 样本点上预测的联合置信度其进行正负样本划分。更为具体的,TSA 首先使用自适应双阈值将 样本分为负样本、正样本和模棱两可的候选样本,然后在候选样本中分别为分类任务和定位任 务进一步筛选潜在正样本。对于分类任务,候选样本都值得学习 (平均 IoU 为 0.369),因此所 有候选样本都参与教师模型的一致性学习,直接模仿教师模型预测的概率分布。而定位任务对 样本的选择更加苛刻,差异性过大会导致定位任务不收敛。因此,TSA 通过评估候选样本与正 样本的相似性来进行筛选 (类别、定位、几何位置相似性),并使用正样本边界框的加权值作为 其学习目标。
3.实验效果
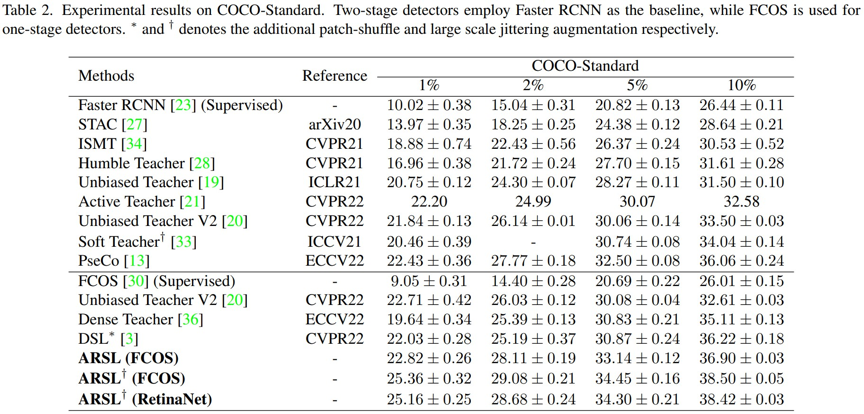
在 COCO-Standard 1%,2%,5%,10% split 中 (1%, 2%, 5%,10% 的训练集图像作为标注数据,剩余 作为无标注数据进行半监督训练,每个 split 均采样 5 组数据),ARSL 显著高于当前的 SOTA 算法,增加大尺度抖动 (large-scale jittering) 后进一步拉大了差距。
05
MoLo: Motion-augmented Long-short Contrastive Learning for Few-shot Action Recognition
作者:王翔1, 张士伟2, 卿志武1, 高常鑫1, 张迎亚2,赵德丽2,桑农1
单位:1 上海大学, 2 百度 VIS, 3 上海人工智能实验室
邮箱:
wxiang@hust.edu.cn,
qzw@hust.edu.cn,
cgao@hust.edu.cn,
nsang@hust.edu.cn,
zhangjin.zsw@alibaba-inc.com,
yingya.zyy@alibaba-inc.com,
zhaodeli@gmail.com
论文:
https://openaccess.thecvf.com/content/CVPR2023/html/Wang_MoLo_Motion-Augmented_Long-Short_Contrastive_Learning_for_Few-Shot_Action_Recognition_CVPR_2023_paper.html
代码:
https://github.com/alibaba-mmai-research/MoLo
当前先进的小样本行为识别方法通过对学习到的视觉特征进行帧级匹配来实现分类。然而,它们通常存在两个局限性:i)由于缺乏强制长期时序感知的引导,局部帧之间的匹配过程往往不准确(如图1所示); ii)显式地运动学习通常被忽略,导致部分信息丢失。为了解决这些问题,我们开发了一种运动增强长-短期对比学习(MoLo)方法,该方法包含两个关键组件,包括一个长-短期对比目标和一个运动自动解码器。具体来说,长-短期对比目标是通过最大化它们与属于同一类视频的全局标记的一致性,赋予局部帧特征长程的时间感知。运动自解码器是一种轻量级的结构,用于从差分特征重构像素运动,其显式地嵌入了运动特征。通过这种方法,MoLo可以同时学习长程时序依赖和运动线索,以进行全面的小样本匹配。为了证明其有效性,我们在五个标准基准上对MoLo进行了评估,实验结果表明MoLo优于最近的先进方法。

图1 现有的小样本行为识别方法采用局部匹配使得对存在相似帧的视频匹配错误
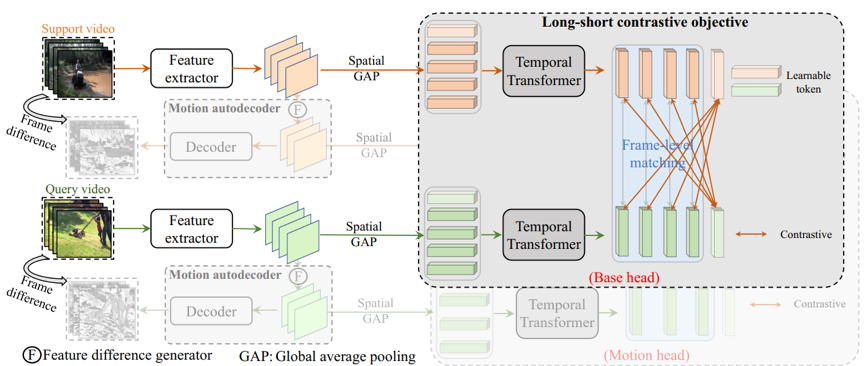
图2 提出的运动增强长-短期对比学习(MoLo)方法的网络图
网络图如图2所示,我们提出的方法主要包含两个组件:长-短期对比目标(long-short contrastive objective)和运动自动解码器(motion autoencoder)。长-短期对比目标通过在局部匹配过程中显式地约束局部视频帧去感知全局特征,来赋予局部特征时间上下文,进而产生鲁棒的匹配结果。运动自动解码器通过显式地引入特征差来构建相邻视频帧之间的运动信息,并且利用一个轻量的解码网络来重建视频帧之差来显式地约束网络学习运动信号。
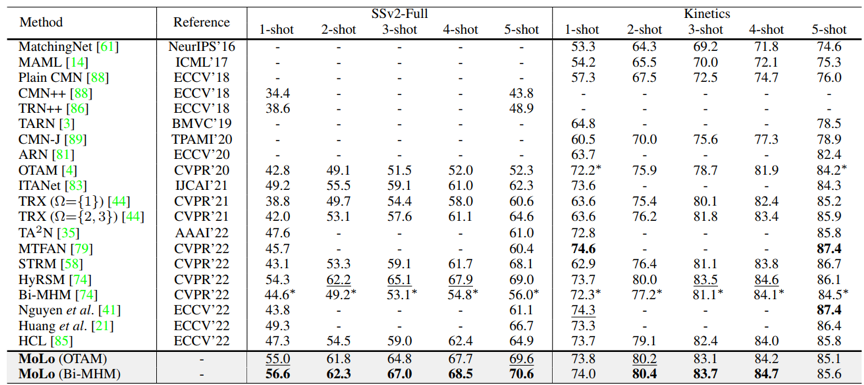
图3 提出的方法和现有方法的对比

图4 剥离实验
我们在多个数据集上对提出的MoLo方法进行了对比评估(图3)和深入的剥离实验(图4)。实验结果表明了方法的有效性,在多个设定上取得了领先于现有方法的性能。详细的剥离实验也表明了所提出方法中不同模块之间在功能上是互补的,可以相互促进,共同提升小样本行为识别性能。

 京公网安备11010802017125号
京公网安备11010802017125号