
2023年论文导读第十四期
【论文导读】2023年论文导读第十四期
CCF多媒体专委会 2023-07-19 09:41 发表于山东


论文导读
2023年论文导读第十四期(总第八十期)
目 录
|
1 |
VoP: Text-Video Co-operative Prompt Tuning for Cross-Modal Retrieval |
|
2 |
Learning Semantic-Aware Disentangled Representation for Flexible 3D Human Body Editing |
|
3 |
Crowd3D: Towards Hundreds of People Reconstruction From a Single Image |
|
4 |
Boost Vision Transformer with GPU-Friendly Sparsity and Quantization |
|
5 |
Ultra-High Resolution Segmentation with Ultra-Rich Context: A Novel Benchmark |
01
VoP: Text-Video Co-operative Prompt Tuning for Cross-Modal Retrieval
作者:黄思腾,龚镖,潘玉霖,蒋建文,吕奕良,李宇渊,王东林
单位:西湖大学,阿里巴巴达摩院,浙江大学
邮箱:
siteng.huang@gmail.com
论文:
https://arxiv.org/pdf/2211.12764.pdf
项目主页:
https://kyonhuang.top/publication/text-video-cooperative-prompt-tuning
近年来,大规模文本-图像预训练模型的火热发展也推动着文本视频检索技术的更新换代。从视频抽取几张视频帧作为静止图像后,文本-图像预训练模型可以计算这些图像和查询文字的内容相关度,并汇聚计算结果来作为视频和查询的相关度。进一步用下游的文本-视频数据对预训练模型进行参数的更新,可以取得更好的检索效果。与常用的参数整体更新(即“全局微调”)策略相比,我们的研究首次从文本-视频跨模态协作的角度出发,为文本视频检索探索更好的参数高效微调方案。通过在处理文本和视频时加入精心设计的、可学习的提示,我们仅增加了少量需要更新的参数,就能够取得比全局微调和现有参数高效微调方法更好的检索性能。总结来说,我们提出了兼顾精度和效率的新方案,来将文本-图像预训练模型用于文本视频检索。
具体来说,本文首先提出一种文本视频检索的微调基线方案VoP。VoP的原理结构如图1所示,在保持预训练模型参数冻结的同时,我们在文本编码器和视频编码器的每一层都加入可学习的提示。仅需要数量相当于预训练模型0.1% 的需要更新的参数,VoP的检索表现可以持平甚至超越现有的参数高效微调方案。
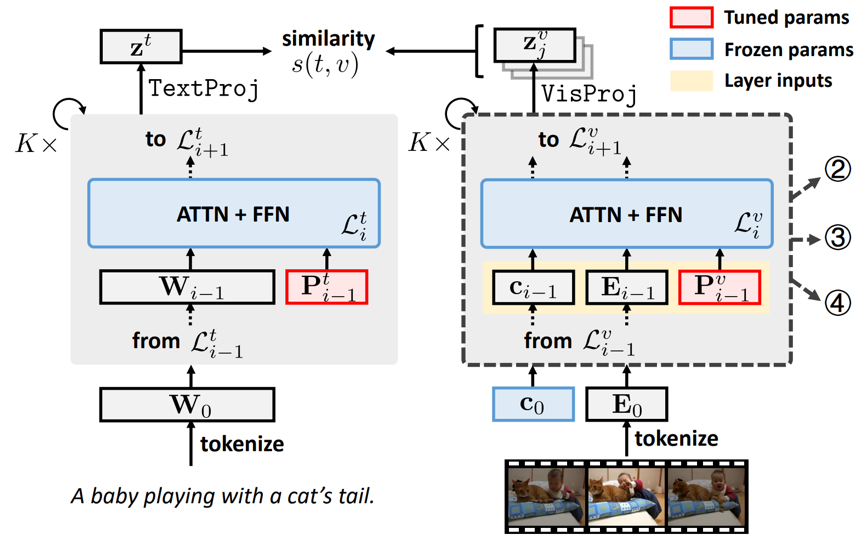
图1 VoP原理结构
为了解决VoP依然将视频帧当作独立的图像、因此缺少对时序信息的建模的问题,我们继续为视频处理提出了三种视频特定的视觉提示,用于无缝替换VoP中采用的通用视觉提示。如图2所示,它们分别是:(1)位置特定的视频提示(VoPP),用于建模所有视频中处于同一相对位置的帧之间共享的信息;(2)上下文特定的视频提示(VoPC),用于将每一帧的上下文信息注入到该帧的内部建模中;(3)层功能特定的视频提示(VoPF),用于根据编码器层功能来选择性辅助帧内建模或者帧间建模。

图2 三种视频特定提示的原理结构
我们在 MSR-VTT-9k、MSR-VTT-7k、DiDeMo、ActivityNet、LSDMC五个公开数据集上进行了实验。如图3所示,在最常用的MSR-VTT-9k数据集上,我们提出的视频特定提示方案能够在限定参数量不变时将VoP的R@1(top-1召回率)提升3%。而组合视频特定提示方案能最多将VoP的R@1提升5%,从而只需要更新完全微调所需参数的11.78% 就能够比其R@1高2.9%,在检索表现和参数效率上都取得了显著的领先。

图3 MSR-VTT-9k数据集上各方案相比完全微调的检索表现增益及参数量对比
02
Learning Semantic-Aware Disentangled Representation for Flexible 3D Human Body Editing
作者:孙晓琨1,冯桥1,李雄政1,张劲松1,来煜坤2,杨敬钰1,李坤1*
单位:1天津大学,2卡迪夫大学
邮箱:
sxk_26@tju.edu.cn
fengqiao@tju.edu.cn
lxz@tju.edu.cn
jinszhang@tju.edu.cn
yjy@tjuu.edu.cn
lik@tju.edu.cn
LaiY4@cardiff.ac.uk
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Sun_Learning_Semantic-Aware_Disentangled_Representation_for_Flexible_3D_Human_Body_Editing_CVPR_2023_paper.pdf
代码:
https://github.com/2017211801/SemanticHuman
项目主页:
http://cic.tju.edu.cn/faculty/likun/projects/SemanticHuman
*通讯作者
1. 研究背景与动机
学习人体的低维表示在人体重建、人体生成与编辑等各种应用中具有重要作用。对于一种人体表示,可以从两个方面去评价它的好坏。首先是表示的几何刻画能力,即通过某种表示重建出的人体在多大程度上保留了原始的输入人体的几何;其次是表示的语义颗粒度,即表示的参数是否有明确且精细的几何或物理意义。现有的人体表示工作大致可以分为传统方法与基于学习的方法。传统方法如SCAPE[1]、SMPL[2],在语义层面,它们把人体解耦成姿态与形状,从而可以通过控制对应参数来改变人体属性;在几何刻画层面,它们采用PCA对人体形状进行建模,然而这种基于线性空间的方法无法处理人体网格中复杂的非线性结构。而基于学习的方法大多以编码器-解码器框架为基础,通过在输入与输出间施加几何约束来确保隐编码尽可能多地保留输入网格的几何细节,得益于神经网络强大的非线性拟合能力,这类方法在几何刻画层面显著优于传统方法;在语义层面,有监督的方法通过为每个网格配对一个具有中性姿态的网格来显式地约束隐编码的语义,但是制作配对监督数据耗时耗力,限制了其后续应用,无监督的方法通过设计新颖的无监督损失来隐式赋予隐编码明确的语义,但是其损失函数不够鲁棒,重建出的人体往往有明显的伪影。并且上述表示方法的语义都太过粗糙,只停留在对人体全局属性的描述,无法支持部件级别的灵活可控编辑。作者就以此为出发点,提出了一种既不需要配对监督数据又可以兼顾精细语义与几何刻画的三维人体表示——SemanticHuman。
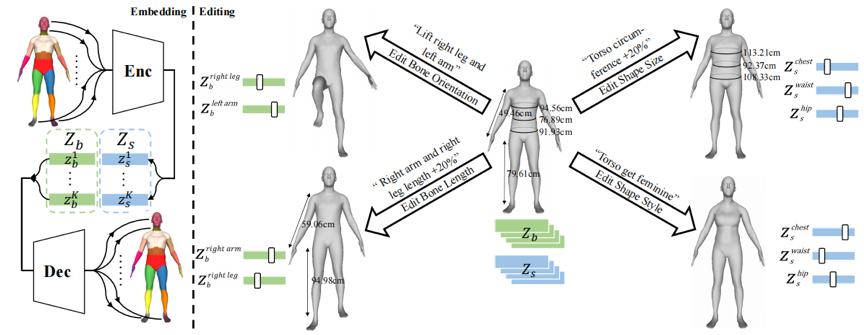
图1 SemanticHuman示意图。(左图) 获得输入人体的隐编码,(右图) 通过改变隐编码实现部件级别的灵活可控编辑
2. 方法思路与细节
2.1总览
作者的研究动机与目的已经在上文阐明,那么先前工作为什么无法做到呢?作者认为这是因为先前工作都遵循把人体解耦为姿态和形状的解耦思路,这种基于人体全局属性的解耦思路不仅限制了表示语义的精细程度而且不便于设计鲁棒且有效的无监督损失,为此作者提出了一种全新的基于人体局部的解耦思路,并且基于此思路设计了一系列新颖且有效的网络架构、训练流程与损失,下面将详细介绍。
2.2部件感知的骨骼分离的解耦策略
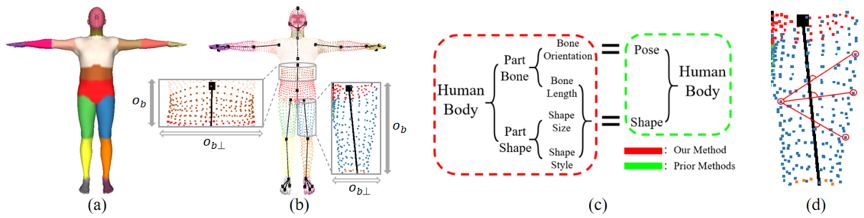
图2:解耦思路示意图。(a) 人体部件,(b) 人体骨骼与关节点,(c) 解耦思路概述,(d) 两点连线与骨骼形成的夹角
作者的解耦思路来源于一个关键观察,即人体是由 个部件组成的,并且每个部件都有一根由三维关节点定义的骨骼,如图2 (a) 和 (b) 所示。另外对于一些几何结构比较简单的人体部件,如腰部、手臂和腿部,其几何形状可近似成以骨骼为主轴的圆柱体,这也就意味着这些部位的几何形变可以被建模为沿其骨骼方向的变化以及沿其骨骼正交方向的变化,如图2 (b) 中小图所示。
受这一观察的启发,作者提出一种部件感知的骨骼分离的解耦策略,解耦思路概述如图2 (c) 所示。具体来说,作者将人体部件的几何形变解耦为与骨骼相关的变化(比如骨骼长度和方向的变化)和与骨骼无关的变化(比如形状尺寸和风格的变化),它们分别由第个部位的骨骼隐编码和形状嵌入表示。这种全新的基于人体局部的解耦策略不仅可以为表示提供了细粒度的语义,以实现部件级别的灵活可控编辑,还可以准确且高效地刻画几何结构,并且有利于无监督损失的构建,从而摆脱对配对监督数据的依赖。
2.3网络架构
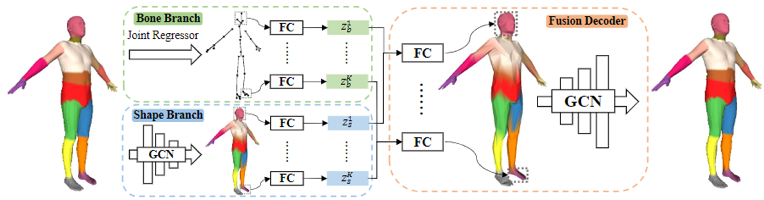
图3:网络架构示意图
网络架构以经典的编码器-解码器结构为基础,融合其解耦思路中的“部件感知”、“骨骼分离”特点,把编码器拆分为骨骼支路和形状支路,并且把一个全连接层拆成多个局部全连接层,这样设计不仅有利于人体特征的提取与聚合,得以更加有效地建模几何细节,而且显著降低了模型参数量,设计细节如图3所示。具体来说,输入一个网格x ,编码器的骨骼支路和形状支路分别编码其每个部件的骨骼信息与形状特征,得到骨骼隐编码Zb={z1b,...,zKb}和形状隐编码Zs={z1s,...zKs},其中zKb和zKs表示第个部位的局部隐编码。然后局部隐编码被送入对应的全连接层中得到局部特征,最终通过图卷积网络聚合不同部件的特征重建出输入的网格。
2.4训练流程与损失
在上述网络框架的基础上,作者通过设计不同的训练分支和对应的损失来分别达到精确几何重建、无监督解耦、部件级别人体编辑的目的,训练总览如图4所示。
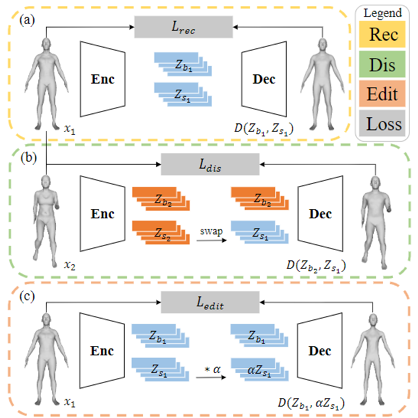
图4 训练流程示意图。整个训练流程由 (a) 重建分支、(b) 解耦分支、(c) 编辑分支组成
整个训练流程的损失函数如下,三种损失分别实现对应的任务:
![]()
重建分支:如图4 (a) 所示,作者采用如下的重建损失来实现精确的几何重建:
![]()
![]()

x是输入网格,Lvert和Ledge分别从顶点和边的层面对重建的网格进行几何约束,以实现精确的几何重建。
解耦分支:在重建分支的约束下,表示已经具备刻画复杂几何的能力,可是其隐空间仍然是耦合的,因此作者采用如下的解耦损失来实现无监督解耦:
![]()
给定两个输入网格x1和x2,xswp表示生成的网格D(Zbz,Zs1),它由来自x2的骨骼隐编码和来自x1的形状隐编码解码得到,如图4 (b) 所示。Ldis_b和Ldis_s分别用于保留属于x2的骨骼信息和属于x1的几何特征。通过这种方式,该表示可以通过无监督学习实现解耦。因为骨骼由关节点决定,所以xswp应该具有与x2相似的关节点位置,因此Ldis_b定义如下,其中J(·)为关节回归器:
![]()
然而如何保留人体的局部几何特征是一个很有挑战性的问题,一个简单的想法是用欧式距离矩阵来描述人体部件的几何特征,如下式所示:

其中xk是指x的第k个部件,De(xk)指xk的顶点间的欧式距离矩阵,如果xk有nk个顶点那么其矩阵大小为[nk,nk]。然而骨骼的长度是耦合在该矩阵中的,这会导致不彻底的解耦从而影响人体编辑的精度。
为了缓解这个问题,作者提出方向自适应权重(orientation-adaptive weighting, OAW)策略。具体来说,对于人体部件xk ,作者首先通过连接每对顶点形成一条线,然后计算该线与骨骼方向obk所形成的夹角,从而构建一个大小为[nk,nk]角度矩阵A(xk),如图3 (d) 所示。显然该夹角越大代表该线对沿着obi的形状变化的贡献越大。接着作者采用下面的阈值处理和归一化函数f(·)来获得大小同为[nk,nk]的权重矩阵W(xk):
![]()

加权后的欧式距离矩阵定义为:
![]()
其中⨂表示矩阵的逐元素相乘,OAW策略尽可能地将骨长信息与欧式距离矩阵分离,从而实现更彻底的解耦和更高精度的编辑。
编辑分支:在解耦分支的约束下,网络学习到的隐空间已经实现了人体部件骨骼与形状的无监督解耦,因此用户可以通过修改输入的关节点位置控制人体部件骨骼的方向和长度,但是对于部件的形状仍然无法实现可控的编辑。为了解决这个问题,作者提出了如图4 (c) 所示的编辑分支,通过 监督生成的网格按照期望变形,从而实现部件级别的形状编辑:
![]()

![]()
其中α是从均匀分布(αmin,αmax)中随机采样的标量,xsca表示由D(Zb1,αZs1)生成的网格。具体来说,Ledit_s监督xsca的第k个部位具有由αDWe(xk1)描述的形状。由于DWe(·)捕获的是沿着ob⊥的成对的欧式距离,所以当部件沿着ob⊥缩放时该矩阵中的元素也应该相应的缩放。此外还引入了Ledit_b来确保编辑过程中的骨骼信息保持不变。
3. 实验结果
作者DFAUST和SPRING数据集上评估了所提出方法的几何表示能力(重建精度)和编辑能力(语义)。
3.1 重建实验
作者首先比较了四类方法来验证该方法的重建精度,分别是基于谱域卷积的方法COMA[3],基于螺旋卷积的方法Neural3DMM[4]和Spiralplus[5],基于注意力的方法Pai3DMM[6]和Deep3DMM[7],以及无监督解耦方法Unsup[8],采用输入网格与重建网格间的平均顶点欧式距离来评价重建精度。如表1所示,该方法在更少的参数量下显示了更出色的几何表示能力。图5显示了一些重建结果与误差图,可以观察到该方法的重建精度显著优于其他方法,尤其在几何细节丰富的部件上(如人脸人手)。
表1 重建实验定量表

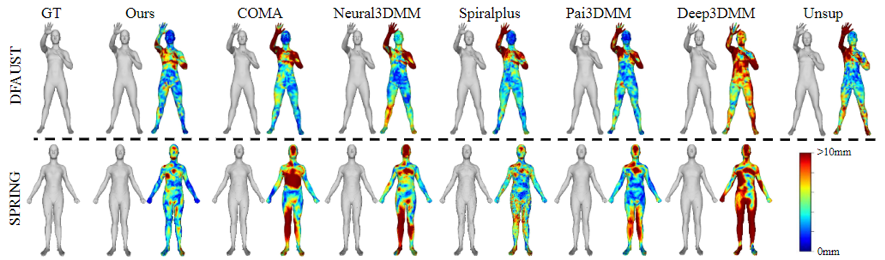
图5 重建实验定性图
3.2 编辑实验
作者还展示了该方法在三个编辑任务上的灵活编辑能力:编辑骨骼方向和长度,以及编辑部件形状大小。由于骨骼方向相当于姿势,所以作者在该任务上与无监督姿势和形状解耦工作 Unsup[8]比较;而骨长和形状大小属于形状信息,因此作者在这两项任务上与人体重塑工作HBR[9]进行比较。由于这些编辑任务没有真值,所以作者利用关节点误差Ejoint和周长误差Ecirc来评估编辑骨骼和形状的准确性,其公式如下所示:
![]()

其中circ(·)是求部件围度的函数,表2给出了量化的编辑结果。该方法不仅在所有的编辑任务中取得了最好的性能,而且还好地保留了其他未编辑的属性。图6展示了一些可视化结果,与Unsup[8]和HBR[9]相比,该方法可以更准确、合理、灵活地编辑人体。
表1 编辑实验定量表。
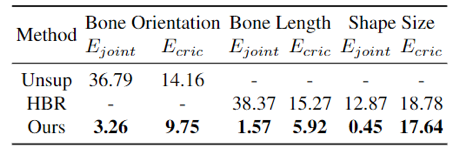
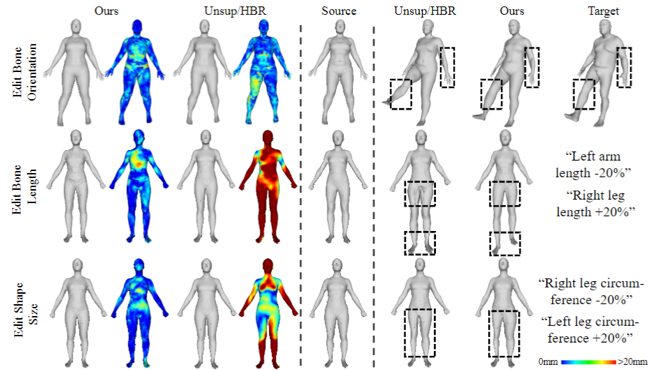
图6 编辑实验定性图
4. 参考文献
[1] Dragomir Anguelov, Praveen Srinivasan, Daphne Koller, Sebastian Thrun, Jim Rodgers, and James Davis. SCAPE: shape completion and animation of people. ACM Trans. Graph., 2005.
[2] Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. SMPL: A skinned multi-person linear model. ACM Trans. Graph., 2015.
[3] Anurag Ranjan, Timo Bolkart, Soubhik Sanyal, and Michael J Black. Generating 3D faces using convolutional mesh autoencoders. In Eur. Conf. Comput. Vis., 2018.
[4] Giorgos Bouritsas, Sergiy Bokhnyak, Stylianos Ploumpis, Michael Bronstein, and Stefanos Zafeiriou. Neural 3D morphable models: Spiral convolutional networks for 3d shape representation learning and generation. In Int. Conf. Comput. Vis., 2019.
[5] Shunwang Gong, Lei Chen, Michael Bronstein, and Stefanos Zafeiriou. SpiralNet++: A fast and highly efficient mesh convolution operator. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2019.
[6] Zhongpai Gao, Junchi Yan, Guangtao Zhai, Juyong Zhang, Yiyan Yang, and Xiaokang Yang. Learning local neighboring structure for robust 3D shape representation. In AAAI, 2021.
[7] Zhixiang Chen and Tae-Kyun Kim. Learning feature aggregation for deep 3D morphable models. In IEEE Conf. Comput. Vis. Pattern Recog., 2021.
[8] Keyang Zhou, Bharat Lal Bhatnagar, and Gerard PonsMoll. Unsupervised shape and pose disentanglement for 3D meshes. In Eur. Conf. Comput. Vis., 2020.
[9] Yanhong Zeng, Jianlong Fu, and Hongyang Chao. 3D human body reshaping with anthropometric modeling. In International Conference on Internet Multimedia Computing and Service, 2017.
03
Crowd3D: Towards Hundreds of People Reconstruction From a Single Image
作者:温浩1,†,黄敬1,†,崔慧丽1,林浩哲2,来煜坤3,方璐2,李坤1,*
单位:1天津大学,2清华大学,3卡迪夫大学
邮箱:
wenhao@tjuu.edu.cn
hj00@tju.edu.cn
huilicui_1@tju.edu.cn
lik@tju.edu.cn
linhz@tsinghua.edu.cn
fanglu@tsinghua.edu.cn
LaiY4@cardiff.ac.uk
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Wen_Crowd3D_Towards_Hundreds_of_People_Reconstruction_From_a_Single_Image_CVPR_2023_paper.pdf
代码:
https://github.com/1020244018/Crowd3D
项目主页:
http://cic.tju.edu.cn/faculty/likun/projects/Crowd3D
†共同作者
*通讯作者
1. 方法动机
现有的单目多人重建方法大多局限于固定FoV(Field of View)的小场景,重建人体网格的三维姿态、形状和相对位置。这些方法无法直接地从大场景图像中回归人体,因为与图像尺寸相比,图中人的尺度相对较小且变化较大。即使采用图像裁剪策略,由于在推断时为每个裁剪图假设独立的相机系,这些方法也无法获得全局空间一致的人群重建。作者观察到在大型场景中,地面是人群最通用的交互对象,能够体现人与场景的和谐性。同时地面也是场景中最常见的元素,且一般的监控场景通常只含有单个或多个地平面。以此为出发点,作者参考了人和地面的交互关系,定义了人与场景虚拟交互点(HVIP)的新概念,提出了基于HVIP的渐进式位置变换网络,从而建立了2D像素与人的3D全局空间位置的对应关系,将复杂的3D人群定位简化为2D的像素点预测,实现了百人大场景下全局空间一致的人群重建。
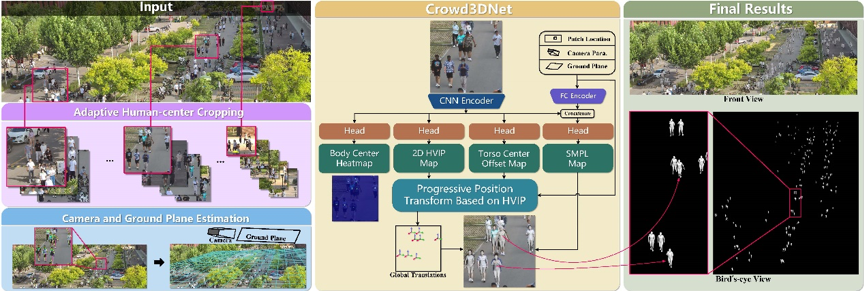
图1 Crowd3D框架总览
2. 方法思路
Crowd3D框架总览
Crowd3D的目的是从包含数百人的单张大场景图像中重建全局空间一致的人群3D位置、姿势和形状。如图1所示,该方法包含三个主要阶段:1)采用自适应的以人为中心的裁剪方案(Adaptive Human-center Cropping)将大场景图像裁剪成具有层级大小的图像块,以确保不同裁剪图像中的人具有合适的占比;2)使用人的2D姿态检测作为先验来估计全局场景的相机内参和地平面方程(Camera and Ground Plane Estimation),用于后续的推断;3)设计基于HVIP的渐进式位置变换网络(Crowd3DNet),以裁剪后的图像、地平面和相机参数作为输入,直接预测大场景相机坐标系下的多人人体网格。
自适应的以人为中心的裁剪策略
为了处理大场景图像中大量的人和不同的人体尺寸,作者提出了自适应的以人为中心的裁剪策略,使不同的裁剪图像中的人与相应裁剪图像的高度比例尽可能一致,有利于后续的人体推断。作者观察到人的身高像素在大场景图像的垂直方向上像金字塔一样分层变化,认为裁剪图像的尺寸也应该符合类似的分层变化,启发式地采用等比序列来模拟垂直方向上块尺寸的层次变化。该想法是简单而有效的。定义图像顶部和底部的人的身高是 和,图像处理区域的上下界为和。考虑垂直方向上不重叠的方形块,从上到下的尺寸大小定义为{ci}ni=1,并认为它们服从等比数列的规则。作者设置人的身高是块尺寸的一半,因此有c1=2*ht,ci=c1*qi-1且��ni=1ci=bl-bu,分块问题被转化为求解以下问题:

在此基础上,作者进一步在相邻行之间增加重叠块,重叠块的尺寸被设置为相邻行裁剪块尺寸的均值,来保证每个人都至少完整的处在一个分块中。对于水平方向,块的尺寸是相同的,也包含重叠块。
人与场景虚拟交互点(HVIP)
为减轻单目重建的深度-尺度歧义性的影响,作者定义了人与场景虚拟交互点(HVIP),来帮助推断大场景相机系统中人的准确3D位置。HVIP表示一个人的3D躯干中心在全局相机空间中的地平面上的投影点,记为 Pv=(xv,yv,zv)。人的躯干中心是人体上的一个语义点,文中指人的肩膀关节和髋关节的中心,用Pt=(xt,yt,zt)表示。
基于HVIP,作者构建了一种渐进式的地面变换。如图2所示,作者通过HVIP建立了图像像素点和人的全局3D空间位置的映射关系,从而实现仅预测2D像素点(2D躯干中心 和2D HVIP )就能推断出人的准确3D位置。蓝色的HVIP是地平面上的点,它可以直接参与地面变换,建立图像像素到地平面上三维点的关系映射;HVIP与人的躯干中心通过垂直关系绑定,结合透视投影约束可准确推断出人的3D躯干中心位置。值得注意的是,由于HVIP不在人体上,位置推理过程对人的姿态没有限制,不会影响重建网络重建各种姿态的人体。 基于HVIP的渐进式地面变换的公式化表达如下:
![]()



图2 基于HVIP的渐进式地面变换
相机和地平面估计
HVIP的设计需要预估场景的地平面方程和相机参数,作者使用预先预测的人体2D姿态检测作为先验来实现。作者通过实验统计表明:为一个大型场景图像预测地面和相机参数,只需要包含站立着的十人的2D姿态就足够了。这在实际大场景图像中很容易满足。在预估场景参数时,该方法假设站立人的颅尾方向(文中指肩部中点和脚踝中点的连线)与地面垂直,站立人的脚踝在地面上,并结合透视投影关系迭代优化出相机和地面参数。
基于HVIP的渐进位置变换网络
在网络设计上,如图1所示,作者采用了单阶段的多头网络,同时预测人体中心热图、躯干中心偏移图、2D HVIP图和SMPL参数图。其中,人体中心热图用于发现人,预测每个位置是人体中心的概率。如果人体中心热图预测正响应,则网络从相应中心位置的其他参数图中采样相关参数,获取人体的2D躯干中心、2D HVIP和SMPL参数。通过基于HVIP的渐进式位置变换,网络能够直接推断出大场景相机系下的人体网格 Mcam=Msmpl-pt+Pt,从而实现全局空间一致的大场景多人重建。
3. 实验结果
因为现存的单目多人重建方法不能全局一致的处理数百人的大场景图像,作者对SMAP[1]、CRMH[2]、BEV[3]三种方法进行了合理扩展,将各自的重建结果统一到与Crowd3D相同的全局相机系中用于公平比较,修改后的方法定义为SMAP-Large、CRMH-Large和BEV-Large。如图3所示,在定性比较上,俯视图的结果清晰显示出Crowd3D重建的人群的空间分布与输入图像是一致的,而其他方法不一致。数字标记的人显示该方法准确推断出排队人群的位置。此外,尽管对比方法也显示出合理的投影结果,但不准确的位置估计意味着它们预测的三维人体具有错误的绝对尺度。在定量比较方面,如表1所示,Crowd3D在四个指标上均优于其他方法,显示出该方法重建的人群具有更准确的位置分布和姿势,其中位置分布包括物理距离和相对排列。

图3 不同方法在LargeCrowd数据集上的定性对比结果
表1 不同方法在LargeCrowd数据集上的定量对比结果

参考文献
[1] Zhen J, Fang Q, Sun J, et al. SMAP: Single-shot multi-person absolute 3D pose estimation[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XV 16. Springer International Publishing, 2020: 550-566.
[2] Jiang W, Kolotouros N, Pavlakos G, et al. Coherent reconstruction of multiple humans from a single image[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 5579-5588.
[3] Sun Y, Liu W, Bao Q, et al. Putting people in their place: Monocular regression of 3D people in depth[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 13243-13252.
04
Boost Vision Transformer with GPU-Friendly Sparsity and Quantization
作者:余翀,陈涛*,甘中学*,范佳媛
单位:复旦大学
邮箱:
21110860050@m.fudan.edu.cn;
eetchen@fudan.edu.cn,
ganzhongxue@fudan.edu.cn,
jyfan@fudan.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/html/Yu_Boost_Vision_Transformer_With_GPU-Friendly_Sparsity_and_Quantization_CVPR_2023_paper.html
*通讯作者
由于其在各种应用中的有效性和泛化性,基于transformer结构的神经网络模型引起了从学术研究到工业应用各方面的极大关注。目前transformer结构已经成功的从自然语言处理领域扩展到了机器视觉领域。Transformer结构的神经网络中堆叠了大量的自注意力和交叉注意力模块,其中涉及许多高维张量乘法操作,因此视觉transformer模型在GPU硬件上的加速部署极具挑战性。
Transformer结构是视觉transformer模型中的基本构件,90%以上的模型权重参数和执行时间都集中在堆叠的transformer结构块中。因此,对于视觉transformer模型的性能提升,需要重点考量如何利用GPU支持的稀疏以及量化加速特性来压缩transformer结构块。图1所示为视觉transformer模型及分层缩放展示的transformer结构块和多头注意力单元。其中,全网络的线性投影层,以及每个transformer结构块中的前馈层和线性投影层,都是我们进行结构化稀疏压缩的目标层。图1下部所示为如何将一个稀疏压缩目标层的权重参数压缩成GPU所支持的结构化稀疏格式,并通过GPU中的稀疏张量运算核进行高效加速。

图1 如何对视觉transformer模型进行结构化稀疏压缩
为了最大限度地利用GPU硬件提供的细粒度结构化稀疏和量化加速特性,我们据此设计了一种名为GPUSQ-ViT的软硬件协同模型压缩方案。首先该方案考虑到GPU对FP16数据类型的结构化稀疏模式所提供的加速效果,通过细粒度结构化剪枝,将权重参数密集的原始大型模型裁剪为稀疏模型。此外我们的方案进一步考虑到GPU可以为INT8整数张量的稀疏计算提供额外加速,通过稀疏-量化感知训练将浮点稀疏模型进一步量化为定点INT8模型。在结构化剪枝和量化感知训练的过程中,我们的方案使用了混合策略的知识蒸馏,来进一步提高压缩模型的精度水平。GPUSQ-ViT模型压缩方案的流程图如图2所示。
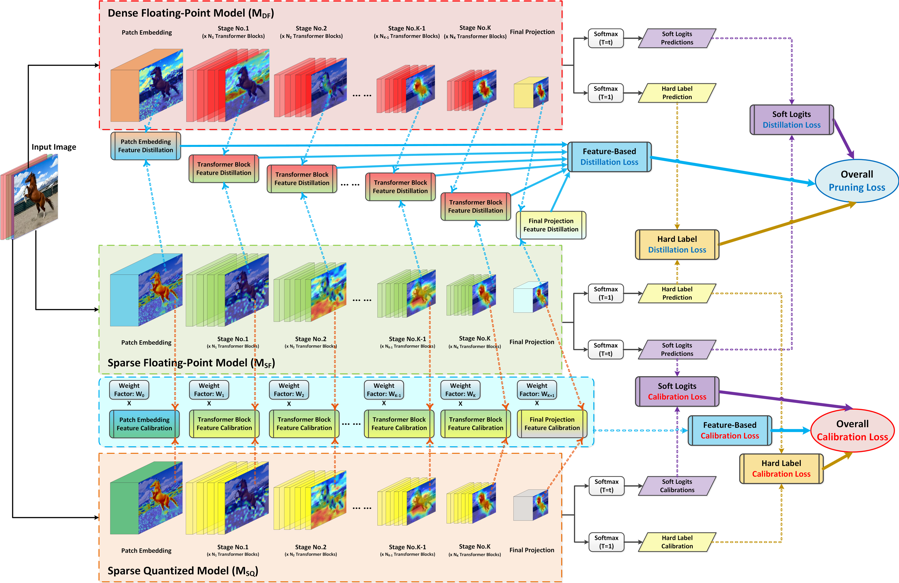
图2 GPUSQ-ViT软硬件协同模型压缩方案的工作流程图
实验结果表明,我们提出的GPUSQ-ViT模型压缩方案可以灵活地支持有监督和无监督的学习范式。GPUSQ-ViT方案可以将视觉transformer模型的模型大小压缩约6.4-12.7倍,FLOPs计算量减少约30.3-62倍,实现了当前最先进的模型压缩效果。并且GPUSQ-ViT压缩后的模型在ImageNet样本分类、COCO目标检测和ADE20K语意分割基准任务上的精度基本保持不变。此外,不管是在服务器场景中所使用的A100 GPU上,还是在机器人与无人驾驶等边缘计算场景中所使用的AGX Orin平台上,GPUSQ-ViT压缩得到的模型实际性能提升效果都非常明显。GPUSQ-ViT方案可以在A100 GPU上将视觉transformer模型实际延迟和吞吐的部署性能分别提高1.39-1.79倍和3.22-3.43倍。在AGX Orin平台上,可以将视觉transformer模型实际延迟和吞吐的部署性能分别提高1.57-1.69倍和2.11-2.51倍。
05
Ultra-High Resolution Segmentation with Ultra-Rich Context: A Novel Benchmark
超丰富的上下文的超高分辨率分割:一种新的基准
作者:纪德益1,2, 赵峰1,*, 卢宏涛3,*, 陶明渊2, 叶杰平2
单位: 1 中国科学技术大学, 2 阿里巴巴达摩院, 3 上海交通大学
邮箱:
jideyi@mail.ustc.edu.cn,
fzhao956@ustc.edu.cn,
htlu@sjtu.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Ji_UltraHigh_Resolution_Segmentation_With_UltraRich_Context_A_Novel_Benchmark_CVPR_2023_paper.pdf
数据集地址:
https://github.com/jankyee/URUR
*通讯作者
近年来,超高分辨率(Ultra-High Resolution,UHR)图像分割方法引起了广泛的兴趣关注,相关算法的研究已成为热点,为了推动这一领域的进一步发展,学术界迫切需要一个涵盖各种场景、具有完整细粒度稠密标注的大规模基准测试集。为此,本研究介绍了URUR,一个包含超丰富上下文信息的超高分辨率数据集。URUR包含了3008张来源于63个城市的、大小为5120*5120的超高分辨率图像,和约100万个精细标注的8个类别的目标实例。在体量上,URUR远优于现有的UHR数据集,包括DeepGlobe、Inria Aerial和UDD等。此外,在算法方面,我们提出了WSDNet,这是一种更高效、更有效的UHR分割框架,特别是在具有超丰富上下文的场景下。具体来说,在网络中,我们自适应地集成多级离散小波变换(DWT),以释放计算压力和保留更多的空间细节。同时,我们还提出了一个小波平滑损失函数(WSL),以平滑地重建输入图像的原始结构化背景和纹理。大量的实验结果验证了WSDNet在多个开源UHR数据集的先进性能。
URUR数据集和其他开源图像分割数据集的对比示例如图所示
详细参数对比如下表所示

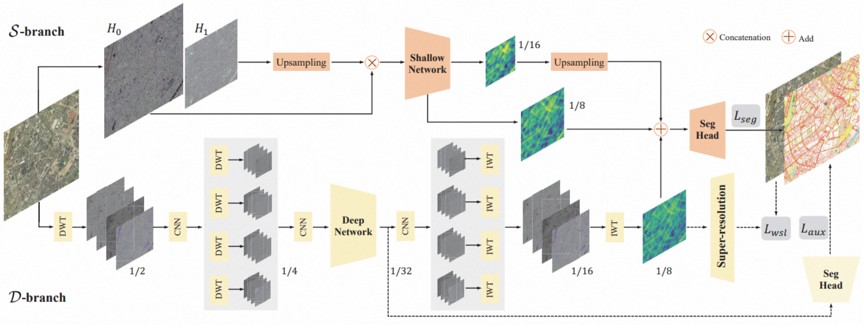
我们提出的WSDNet框架如下所示。WSDNet包括一个深层分支D和一个浅层分支S。在S中,输入图像通过拉普拉斯金字塔分解为两个自带,连接后,输入浅层网络以提取全面的空间细节。在D中,输入图像通过两级小波变换(DWT)进行下采样,送入深层网络以提取高纬度的类别上下文信息,之后通过两级逆离散小波变换(IWT)进行上采样。最后我们融合两个分支的多尺度输出特征,并使用基本的交叉上损失函数Lseg、辅助损失函数Laux以及所提出的WSL函数Lwsl联合训练。
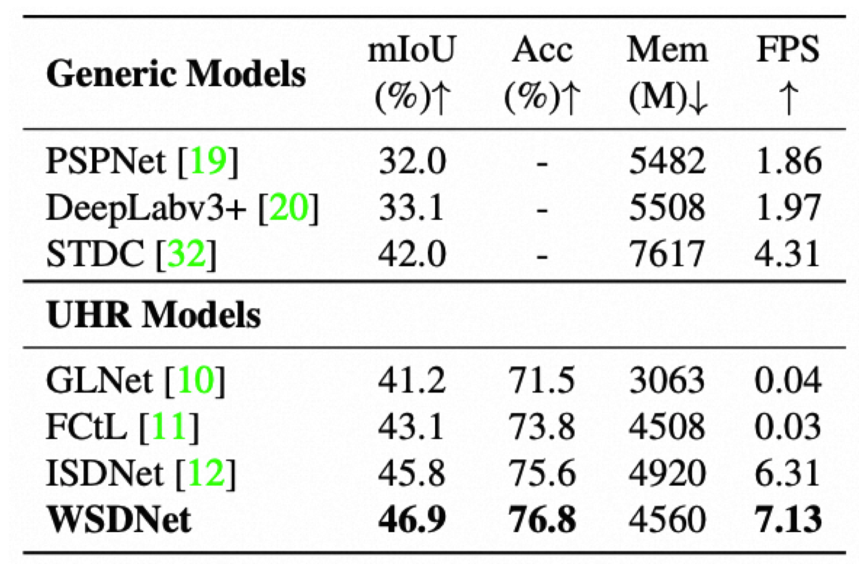
在URUR数据集上WSDNet与现有先进算法的对比如下表所示。

 京公网安备11010802017125号
京公网安备11010802017125号