
2023年论文导读第十五期
【论文导读】2023年论文导读第十五期
CCF多媒体专委会 2023-08-01 07:30 发表于山东


论文导读
2023年论文导读第十五期(总第八十一期)
目 录
|
1 |
QPGesture: Quantization-Based and Phase-Guided Motion Matching for Natural Speech-Driven Gesture Generation |
|
2 |
Explicit Boundary Guided Semi-Push-Pull Contrastive Learning for Supervised Anomaly Detection |
|
3 |
PlenVDB: Memory Efficient VDB-Based Radiance Fields for Fast Training and Rendering |
|
4 |
PA&DA: Jointly Sampling PAth and DAta for Consistent NAS |
|
5 |
Style Projected Clustering for Domain Generalized Semantic Segmentation |
01
QPGesture: Quantization-Based and Phase-Guided Motion Matching for Natural Speech-Driven Gesture Generation
作者:杨思程1, 吴志勇1,3 , 李明磊2 , 张镇嵩2, 郝磊2, 鲍威弘1 , 庄昊霖1
单位:1清华大学, 2华为, 3香港中文大学
邮箱:
yangsc21@mails.tsinghua.edu.cn,
bwh21@mails.tsinghua.edu.cn,
zhuanghl21@mails.tsinghua.edu.cn,
zywu@sz.tsinghua.edu.cn
liminglei29@huawei.com,
zhangzhensong@huawei.com,
haolei5@huawei.com
论文:
https://arxiv.org/abs/2305.11094
代码:
https://github.com/YoungSeng/QPGesture
1. 背景及动机
在人机交互和虚拟现实等领域,语音驱动的手势生成是一个重要的研究课题。然而,人类运动的随机抖动以及人类语音和手势之间的内在异步关系,使得这个问题变得异常复杂。为了解决这些挑战,本文提出了一种新颖的量化和相位引导的运动匹配框架。

图1 我们提出的方法在各类语音上生成的手势示例
2. 算法简介
我们的方法将一段音频、相应的文本、种子姿势和可选的控制信号序列作为输入,并输出手势动作序列。我们首先自动将这些输入和动作数据库预置为量化的离散形式。然后,我们分别为语音和文本找到最佳候选。最后,我们根据种子代码对应的相位和两个候选相位选择最佳手势。
首先,本文提出了一个手势VQ-VAE模块,通过学习一个代码本来总结有意义的手势单元。每个代码代表一个独特的手势,有效地缓解了随机抖动问题。然后,本文使用Levenshtein距离来对不同的语音进行多样化的手势对齐。基于音频量化的Levenshtein距离作为手势对应语音的相似性度量,帮助匹配更适当的手势与语音,并很好地解决了语音和手势的对齐问题。此外,本文引入了相位来指导基于语境或音频节奏的语义的最佳手势匹配。相位指导了基于文本或基于语音的手势何时应该执行,使生成的手势更自然。

图2 我们提出的框架的手势生成流程。Quan. "是 "量化 "的缩写,"Cand. "是 "候选 "的缩写。给定一段音频、文本和种子姿势后,音频和手势将被量化。语音的候选姿态是根据莱文斯坦距离计算的,文本的候选姿态是根据余弦相似度计算的。根据种子代码对应的相位引导和两个候选者对应的相位,选择最佳手势。
3. 实验效果
在实验中,该方法在语音驱动的手势生成方面优于最近的方法。这表明本文的框架可以有效地缓解抖动和异步性问题,提供了一种新颖的解决方案,为语音驱动的手势生成提供了新的可能性。
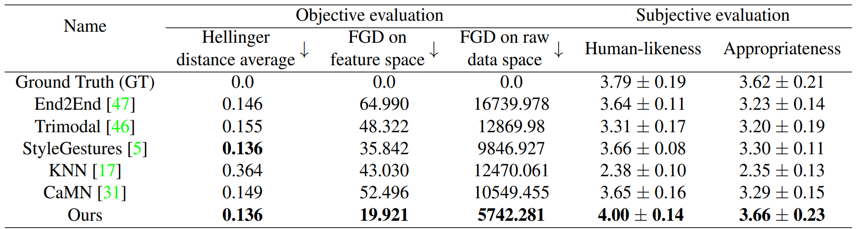
表1 测试集的量化结果。粗体表示最佳指标。在比较的方法中,End2End、Trimodal、StyleGestures、KNN和CaMN是使用官方发布的代码和一些优化设置复现的。与人类的相似度和适当性是 MOS 的结果,带有 95% 的置信区间。
02
Explicit Boundary Guided Semi-Push-Pull Contrastive Learning for Supervised Anomaly Detection
作者:姚欣成1,李若琦1,张静2,孙军1,张重阳1,*
单位:1上海交通大学电子系图像所,2军事科学院系统工程研究所
邮箱:
i-Dover@sjtu.edu.cn,
sunny_zhang @sjtu.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Yao_Explicit_Boundary_Guided_Semi-Push Pull_Contrastive_Learning_for_Supervised_Anomaly_Detection_CVPR_2023_paper.pdf
代码:
https://github.com/xcyao00/BGAD
*通讯作者
图像异常检测在工业质检等领域有着广泛的应用。由于难以收集大量的异常数据,并且不可能收集到所有的异常种类,之前的方法大多是基于无监督的,即训练数据中仅有正常样本。但是仅仅从正常样本中学习会限制异常检测模型的判决能力,如图1所示,在没有任何异常的情况下,决策边界通常是隐式和判决性不足的。由于训练时缺乏异常知识而存在的判决不充分问题是无监督异常检测中的一个常见问题。

图1 无监督异常检测存在的判决不充分问题
事实上,在真实应用场景中,少量的异常通常是可以获取的,这些少量的已知异常可以被充分地利用起来以解决或者缓解上述问题。但是,已知异常并不能代表所有种类的异常,直接建模一个有监督的二分类任务可能会产生对于已知异常的偏好,而导致模型在未知异常上的泛化能力下降。因此,我们对有监督异常检测定义为:在模型训练时可以有效利用少量已知异常,目标是提高模型对于已知异常的检测能力,同时保证对于未知异常的泛化能力。
针对有监督异常检测,我们提出了一个新颖的显性边界引导的异常检测方法(BGAD),如图1中所示,我们的方法有着两个核心的设计:显性边界生成和边界引导的优化。BGAD的具体模型结构如图2中所示。输入样本由一个预训练的特征提取网络提取多尺度的特征,训练时分为两阶段,首先通过归一化流模型学习归一化的正常特征分布。基于该分布,设置一个显性的划分边界,该显性的划分边界尽量靠近正常特征分布的中心,并由一个超参数β控制边界到中心的距离。这样得到的显性划分边界仅仅依赖于正常分布,和异常分布没有关联,因此由不充分的已知异常带来的偏好问题可以得到缓解。
在得到显性划分边界之后,论文进一步提出了一个边界引导的半推拉损失,来充分利用少量异常样本学习到更具判决性的表征特征。不同于一般的对比损失会将不同类的特征尽可能推拉开,边界引导的半推拉损失仅仅将对数似然小于边界的正常特征拉到一起,以形成更为紧凑的正常特征分布;而将对数似然大于边界的异常特征,推离边界一定的距离。这样既可以形成更为紧凑的正常分布,有利于未知异常的判决,同时并不会强制异常偏离正常分布过远,导致模型产生对于已知异常的偏好。

图2 BGAD的模型结构和训练过程
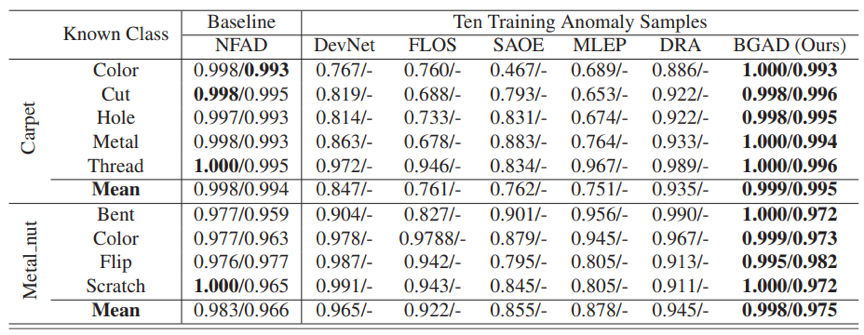
本工作在MVTecAD数据集上进行了实验验证。在每个工业产品中,仅使用10个异常样本,在图像级异常检测上可达99.3%的AUROC,在像素级异常定位上可达97.6%的PRO,其性能超过了当时已知方法,特别是像素级异常定位性能大幅超越了已知方法,具体检测结果如表1中所示。其次,我们还验证了该方法对于未知异常的泛化能力,其结果见表2中所示,其中显示了我们使用某一类异常作为已知异常参与训练,其他所有异常作为未知异常的平均检测结果,可以看到我们的方法远远好于之前利用异常的有监督异常检测方法。
表1 MVTecAD数据集上对于已知异常的检测结果
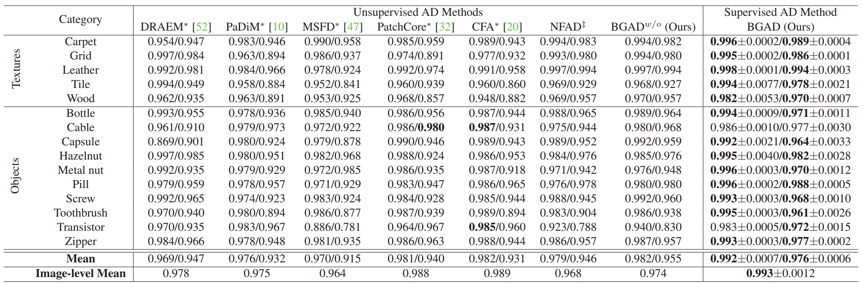
表2 MVTecAD数据集上对于未知异常的检测结果
最后,在图3中,我们给出可视化的结果,可以看到我们的BGAD可以明显取得更好的异常定位结果。

图3 检测结果可视化对比
03
PlenVDB: Memory Efficient VDB-Based Radiance Fields for Fast Training and Rendering
作者:严涵1,刘策龙2,马超1ᵻ,梅星2ᵻ
单位:1上海交通大学人工智能教育部重点实验室,2字节跳动
邮箱:
wolfball@sjtu.edu.cn,
chaoma@sjtu.edu.cn,
celong.liu@bytedance.com,
xing.mei@bytedance.com
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Yan_PlenVDB_Memory_Efficient_VDB-Based_Radiance_Fields_for_Fast_Training_and_CVPR_2023_paper.pdf
代码:
https://github.com/wolfball/PlenVDB
项目主页:
https://plenvdb.github.io/
†通讯作者
1. 引言
随着神经辐射渲染场的进步,新视角合成任务取得了重大进展。神经辐射渲染场通过MLP隐式地建模场景,利用体渲染方法建立了3D到2D的联系,实现了仅凭借2D图片监督,便可以学习3D场景模型,从而获得高质量的新视角图片。然而,基于神经渲染的方法在资源耗费和渲染时间上成本巨大,限制了NeRF的落地应用。于是,大量工作开始探索用不同数据结构来代替MLP,如八叉树、3D网格和哈希表等方案。

图1 VDB数据结构
VDB是一种层级的稀疏体数据结构(如图1),它不仅具有稀疏数据结构对数据的紧凑表示,而且可以像3D密集网格结构一样进行高效的数据访问,此外,它在影视界已经经过多年验证,拥有丰富的生态。因此,我们提出PlenVDB,一种基于VDB数据结构设计的新的神经辐射渲染场,用新设计的高效训练策略从已知相机姿态的图片上直接优化VDB数据结构,学习3D场景信息,并且通过良好设计的渲染算法,达到加速渲染的效果,pipeline如图2所示,凭借着VDB丰富的生态,学习到的VDB可以直接应用于传统图形渲染管道,进行高效渲染。
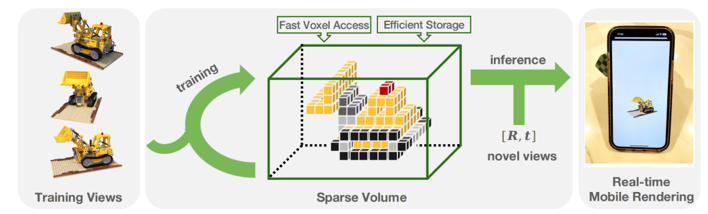
图2 Pipeline
2. 方法设计
然而,虽然VDB拥有丰富的C++库,但是无法直接应用于NeRF的训练管线:一方面,常用的VDB数据结构只支持1维和3维数据,而为了建模丰富的颜色,颜色向量往往是高维的;另一方面,VDB缺少深度学习的接口,无法直接通过梯度反传优化VDB上的数据。于是,我们封装了ColorVDB,用多个3维的VDB树存储高维颜色信息;为了支持基于Pytorch的训练管线,我们封装了DataVDB、GradVDB和OptVDB,分别存储数据、梯度和优化器参数,实现了直接在VDB上学习场景信息。VDB得益于其特殊设计的Accessor,能够执行高效的邻居访问,从而十分适合执行快速的三线性插值和ray-marching算法,于是,我们能够在CUDA端重写相应的算法实现训练和渲染的加速(如图3)。此外,为了减小拓扑冗余,我们将训练好的两个分别代表密度和颜色的VDB进行合并,进一步减小存储占用,并提高访问效率(如图4)。

图3 训练和渲染过程

图4 合并后的VDB
4. 实验
实验结果(如图5)从两方面证明了我们方法的有效性和高效性:一方面,我们的方法在渲染质量上几乎没有损失,且训练收敛很快;另一方面,我们的方法能够加速渲染,且获得更紧凑的数据表达。和我们选取的基线模型DVGO相比,在NeRF-Synthetic数据集上,我们的模型在渲染速度上有平均4-5倍的提升,在存储占用效率上有平均8倍的提升。此外,我们通过消融实验(如图6),证明了我们在渲染端的优化操作(重写渲染算法和合并操作)是高效的。

图 5 实验结果
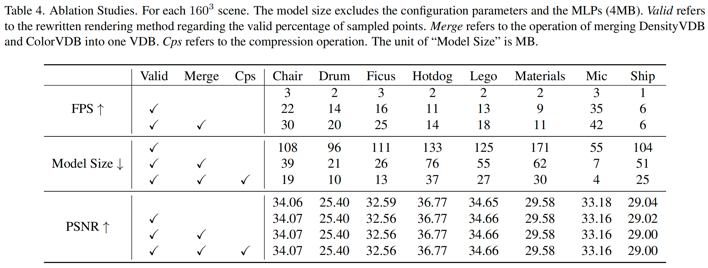
图 6 消融实验
04
PA&DA: Jointly Sampling PAth and DAta for Consistent NAS
作者:陆顺1,2、胡瑜1,2,*、杨隆兴1,2、孙自浩1,2、梅继林1、谈建超3、宋成儒3
单位:1智能计算机研究中心,中国科学院计算技术研究所;2计算机科学与技术学院,中国科学院大学;3 快手科技
邮箱:
lushun19s@ict.ac.cn
huyu@ict.ac.cn
yanglongxing20b@ict.ac.cn
sunzihao18z@ict.ac.cn
meijilin@ict.ac.cn
jianchaotan@kuaishou.com
songchengru@kuaishou.com
论文:
https://openaccess.thecvf.com/content/CVPR2023/html/Lu_PADA_Jointly_Sampling_Path_and_Data_for_Consistent_NAS_CVPR_2023_paper.html
代码:
https://github.com/ShunLu91/PA-DA
*通讯作者
1. 引言
由于深度神经网络在多种任务场景均取得了优异的性能,其在计算机视觉、自然语言处理等诸多领域得到了广泛应用。然而,深度神经网络架构十分依赖于人类经验进行手动设计,不仅需要丰富的专家先验知识和大量的试错实验,通常还难以找到最优的网络架构。 在这种情况下,神经网络架构搜索(Neural Architecture Search,简称“NAS”) 应运而生。
基于权重共享机制的One-shot NAS方法,通常使用采样训练来预训练一个包含所有候选操作的超网,由各个子模型继承超网的权重以进行高效的性能评估。该类方法能够显著降低架构搜索的开销,因此很多工作都采用了这种搜索范式。然而,NSAS、SUMNAS、和Few-Shot-NAS等研究工作指出,在采样训练过程中,共享权重会受到各个子模型不同梯度下降方向的影响。如图1所示,本文通过实验观察到,基于权重共享机制的超网在训练过程中会出现较大的梯度方差(黄色实线),进而导致子模型的排序一致性较差(蓝色实线)。

图1 不同权重共享程度和不同方法下超网梯度方差和子模型排序一致性的变化
2. 方法概述
为了缓解该问题,本文提出联合优化路径(PAth)和数据(DAta)采样分布的NAS方法PA&DA(注:发音同Panda),显式地最小化超网训练过程中的梯度方差,从而提升超网的泛化性能,实现更好的子模型排序一致性。
具体而言,本文从理论上推导了梯度方差与采样分布之间的关系,并揭示了最优采样概率与路径和训练数据的归一化梯度范数成正比。在此基础上,本文提出使用归一化梯度范数作为路径和训练数据的重要性判据,并在超网训练过程中依据重要性来采样路径和数据,如图2所示。通过使用PA&DA超网训练方法,能够有效降低超网训练过程中的梯度方差,并提升子模型的排序一致性。
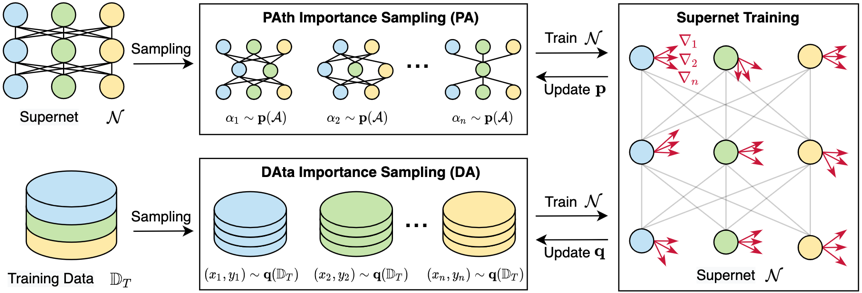
图2 PA&DA提出的基于路径重要性采样和数据重要性采样的超网训练框架
3. 实验结果
在多个搜索空间的实验结果表明,PA&DA在子模型排序一致性和搜索精度方面都取得了更好的效果。如图3所示,相比于随机采样训练的NAS方法SPOS,PA&DA在超网训练过程中始终保持了较低的梯度方差,最终实现了更好的子模型排序一致性。
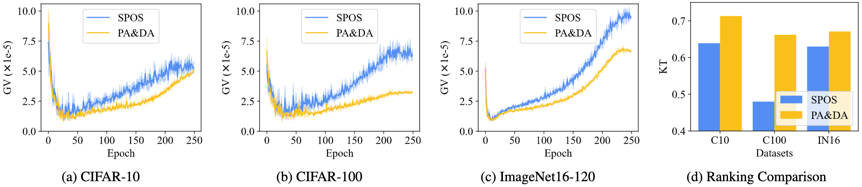
图3 在NAS-Bench-201使用三种不同数据集PA&DA与SPOS的梯度方差与子模型排序一致性对比
05
Style Projected Clustering for Domain Generalized Semantic Segmentation
作者:黄炜,陈畅,李勇,李家丞,李琤,宋风龙,颜友亮,熊志伟
单位: 中国科学技术大学,华为诺亚方舟实验室
邮箱:
weih527@mail.ustc.edu.cn
chenchang25@huawei.com
liyong156@huawei.com
jclee@mail.ustc.edu.cn
licheng89@huawei.com
songfenglong@huawei.com
yanyouliang@huawei.com
zwxiong@ustc.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/html/Huang_Style_Projected_Clustering_for_Domain_Generalized_Semantic_Segmentation_CVPR_2023_paper.html
代码:
https://gitee.com/mindspore/models/tree/master/research/cv/SPC-Net
由于训练数据集与真实场景之间往往存在着分布差异,导致训练好的模型在实际部署时性能急剧下降。为了解决这个问题,域泛化方法旨在缩小训练数据集与真实场景之间的分布差异,提升模型在未知场景下的泛化能力。与域自适应方法不同,域泛化方法在训练阶段对目标数据的分布是不可知的,即无法使用未带标签的目标数据参与训练。
最近,由于自动驾驶等安全关键应用的兴起,语义分割的领域泛化(DGSS)引起了越来越多的关注。现有的DGSS方法通过学习与域无关的表征来提高模型的泛化能力。这方面的研究总体上有着相似的目标,即提取图像内容的域不变特征,并消除特定域的特征(即图像风格)。实例归一化(Instance Normalization)和实例白化(Instance Whitening)是两类具有代表性的方法。它们将不同域的图像特征正规化到规范空间,如图1(a-b)所示。具体来说,实例归一化通过通道特征归一化实现中心级特征对齐,实例白化通过消除通道之间的线性相关性实现均匀特征分布。此外,将这两种方法进行组合还可以获得更好的泛化效果,如图1(c)所示。然而,由于部分特征信息被消除,特征正则化不可避免地削弱特征表示能力。此外,这类方法依赖一个很强的假设,即消除的信息严格是特定于域的信息。但在实践中,图像风格与内容的完美解耦却很难实现。这意味着在特征正则化的过程中也会消除一部分内容特征,从而降低分割性能。
我们的目标不是通过特征正则化来寻求共同点,而是以不同的方式解决DGSS问题。本文中,我们提出风格投影作为替代方案,它利用不同域的特征作为基来构建更好的表示空间,如图1(d)所示。风格投影的动机来自泛化的基本概念,即基于已知数据来表示未见过的数据。 具体来说,我们采用通道维度特征的统计量(即均值和方差)来表示图像风格。来自源域的图像样式被迭代地提取并存储作为表示的基。然后,我们将给定的未见过图像的风格投影到这个表示空间中以促进泛化。该投影过程是通过风格库的加权组合来实现的,其中风格之间的相似距离被用作加权因子,即图1(d)所示的λ1和λ2。
基于投影的风格特征,我们进一步设计模型的决策部分,这是为语义分割而进行设计的。通常,现有方法学习参数函数以将像素级特征映射到语义预测。我们用语义聚类代替这种确定性预测,其中每个像素的类别是通过与语义基的最小相似距离来预测的,如图1(d)所示。它遵循相同的风格投影概念,即根据已知数据来预测未见过的数据。更具体地说,为了促进语义聚类的性能,我们提出了一种对比损失的变体,以对齐相同类别的语义基础并增强不同类别之间的可区分性。整体框架如图2所示。

图1 实例归一化(IN)、实例白化(IW)和我们方法(Ours)的图示。IN和IW将不同域的图像特征正规化到规范空间(a-c)。我们的方法基于已知领域的数据构建样式和语义表示空间(d)。
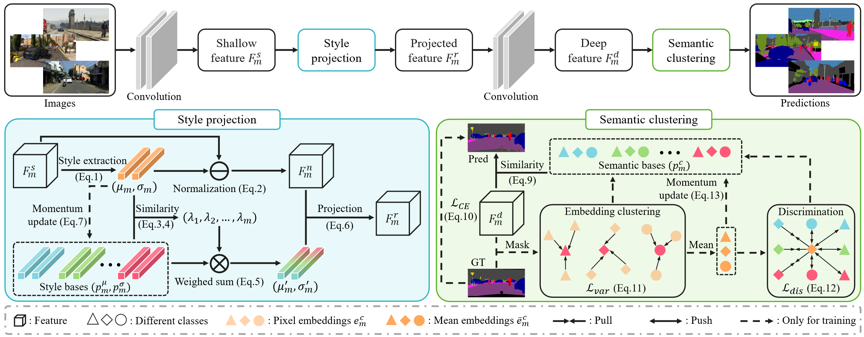
图2 风格投影聚类框架,由风格投影和语义聚类两个部分组成。
我们在单源和多源设置下进行了全面的实验,以证明我们的方法比现有DGSS方法具有更好的泛化能力。如图3和图4所示,我们在双源实验上对我们的方法进行了验证,从定量和定性的结果中可以看出,我们的方法取得了一致性的优势。
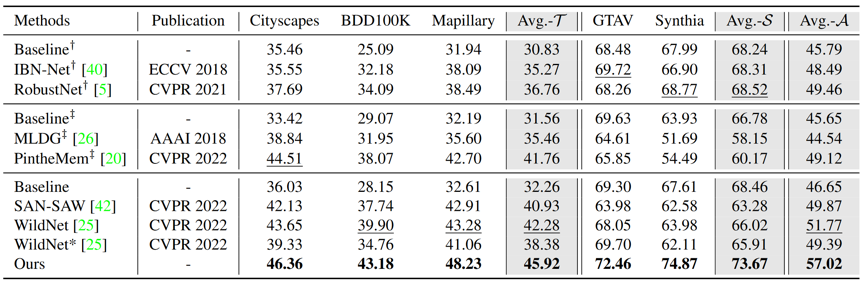
图3 双源定量结果,即在GTAV和Synthia数据集上进行训练,而在Cityscapes、BDD100K和Mapillary数据集上进行测试。

图4 双源定性结果。

 京公网安备11010802017125号
京公网安备11010802017125号