
2023年论文导读第十一期
【论文导读】2023年论文导读第十一期
CCF多媒体专委会 2023-06-06 14:00


论文导读
2023年论文导读第十一期(总第七十七期)
目 录
|
1 |
Guided Colorization Using Mono-Color Image Pairs |
|
2 |
TRNR: Task-Driven Image Rain and Noise Removal With a Few Images Based on Patch Analysis |
|
3 |
Memorizing Complementation Network for Few-Shot Class-Incremental Learning |
|
4 |
Binary Change Guided Hyperspectral Multiclass Change Detection |
|
5 |
Dynamic Training Data Dropout for Robust Deep Face Recognition |
|
6 |
Unsupervised Cumulative Domain Adaptation for Foggy Scene Optical Flow |
01
Guided Colorization Using Mono-Color Image Pairs
作者:盛泽华1,沈会良1, 2*,姚博文1,张华琪3
单位:1浙江大学信息与电子工程学院,2浙江省协同感知与自主无人系统重点实验室,3维沃移动通信有限公司
邮箱:
shengzehua@zju.edu.cn
shenhl@zju.edu.cn
bwyao36@zju.edu.cn
zhanghuaqi@vivo.com
论文:
https://ieeexplore.ieee.org/document/10017185
*通讯作者
1. 引言
现代成像系统中,彩色相机普遍使用颜色滤波阵列(Color Filter Array,CFA)记录场景的颜色信息。然而,CFA在空间上的降采样处理使得成像结果存在纹理和细节的丢失。同时,滤光片的使用阻挡了一部分入射光进入相机内部,从而降低了传感器的成像效率。相比之下,黑白相机无需使用CFA进行颜色记录,但是能够获得信噪比更高、细节更加丰富的成像结果。因此,基于黑白-彩色双目相机系统,本文通过融合黑白图像的结构信息与彩色图像的颜色信息,实现图像的质量增强。我们将该增强任务建模为一个引导着色问题,将黑白图像作为亮度通道,根据非对齐的彩色图像对黑白图像中的各目标像素点进行颜色估计。具体地,本文提出了一种基于统计分析的着色策略,对于黑白图像的一个像素点,算法从引导图像中匹配获得多个颜色候选值,根据这些候选值的统计分布特性,实现颜色的鲁棒估计与置信度分析。在此基础上,基于后验概率分析,我们进一步设计了一个采样策略,使得算法效率得到了大幅提升。
2. 方法
本文提出的着色策略主要基于两点假设:1)在局部范围内,两个像素点的亮度越相似,那么其颜色值也大概率越相似;2)对于一个目标像素点的多个匹配结果,其中亮度与目标点相似的数量越高,那么使用这些匹配结果进行颜色估计的置信度也越高。基于假设1),对于黑白图像的目标像素点,我们使用块匹配策略为其在彩色图像中寻找多个亮度最接近的像素点,通过对这些匹配点对应颜色值进行加权融合,实现该目标点的颜色估计。基于假设2),我们使用最小可觉察误差(Just Noticeable Difference,JND)作为阈值对于匹配结果与目标点亮度的相似性进行衡量,进一步判断着色结果的置信度。我们仅保留那些高置信度的颜色估计,基于图像相邻内容的相关性,使用颜色传播策略对剩余非置信区域进行颜色填充。算法的总体流程框架如图1所示。

图1 算法框架
为了保证算法效率,考虑到图像自身的冗余性,实际上不需要匹配所有图像块来获得鲁棒的着色结果。因此,我们提出了一个采样策略:对于一个目标像素点能够获得的所有匹配结果,我们仅从中采样N个,如果其中至少有T个与目标点的亮度相似,那么我们可以认为该颜色估计具有高置信度。基于此,我们提出了度量��confidence对置信度进行描述。同时,为了尽可能充分利用输入彩色图像的颜色信息,我们期望能够通过匹配尽可能多地完成像素点的颜色估计,因此提出了有效匹配度量��valid_match来描述通过匹配实现成功着色的概率。如图2所示,我们在训练数据中对采样指标R=��confidenced·��valid_match的分布进行学习,以此确定采样参数N与T的取值。上述采样机制只需使用2%的图像块就可以完成颜色估计,极大地降低了算法的计算量,并且对着色精度的影响较小(如表1所示)。
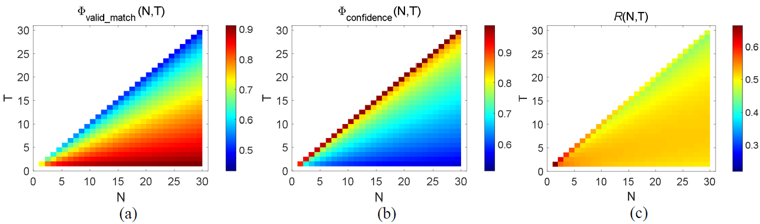
图2 有效匹配度量��valid_match,置信度度量��confidenced,采样指标R关于采样参数N与T的分布可视化。指标越高,表明着色置信度与彩色图像信息利用率二者综合表现越好。
表1 采样前后着色精度比较

3. 实验结果
我们在仿真与真实的黑白-彩色双目数据上对算法进行了测试。如图3、图4所示,本算法能够更加准确地根据输入的彩色图像对黑白图像进行颜色估计,且相比当前工作能够更加有效解决颜色溢出问题,获得更加自然的着色结果。

图3 仿真图像着色结果对比

图4 真实图像着色结果对比
02
TRNR: Task-Driven Image Rain and Noise Removal With a Few Images Based on Patch Analysis
基于图像块分析的图像去雨、去噪的任务驱动式学习
作者:冉武,杨博弘,马培荣,路红
单位:复旦大学,计算机科学技术学院,智能信息处理重点实验室
邮箱:
wran21@m.fudan.edu.cn;
15110240016@fudan.edu.cn;
prma20@fudan.edu.cn;
honglu@fudan.edu.cn
论文:
https://ieeexplore.ieee.org/document/10007859/
代码:
https://github.com/Schizophreni/MSResNet-TRNR
数据集:
Google drive:
https://drive.google.com/drive/folders/14qWdyxcbw7FMpWGWBQL5ubzgOIbGR7IP?usp=sharing
百度网盘:
https://pan.baidu.com/s/1Izk3e8XThCE0wGJ_neCt3A?pwd=otjs#list/path=%2F
基于深度学习的图像去雨、去噪模型已经取得极大的成功,在公开数据集上已经实现了极高的性能。然而大多数深度学习去雨、去噪模型依赖大规模标注数据集进行训练。这一数据驱动学习范式限制了深度学习模型在真实数据稀少场景下的应用。另一方面,目前深度模型训练过程采用的图像采样策略存在图像信息利用率低的问题:其一是数据批次中图像块类型多样性不够;其二是对更稀有、信息更丰富的图像块利用率低下 (如图一所示)。
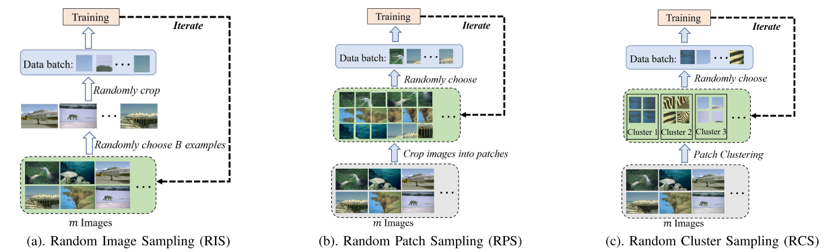
图1 三种不同的图像块采样算法。图(a), (b)为主流的采样策略 (容易多次采样到简单的图像块,如“天空“), 图(c)为本文提出的采样策略。
为了解决图像信息利用率低的问题,本文提出了一种新的采样方式:随机类别采样,如图一(c)所示。该采样方式能够均衡训练过程中对不同类型图像块的采样,并能有效提高稀有的、图像信息丰富的图像块的利用率。为了进一步缓解深度模型训练对大数据集的依赖,基于提出的随机类别采样方式,本文提出了任务驱动式学习方法用于代替主流的数据驱动方法。具体地,任务驱动式学习能够基于少量数据生成大量的子任务,使得模型能够从大量的子任务上进行学习,有效避免了模型对大规模数据集的依赖。此外,所提出的任务驱动式学习方式受元学习中MAML算法启发。图二展示了本文提出的任务驱动式学习方法的主要框架。
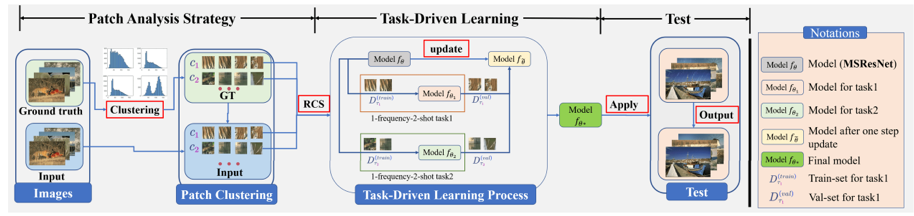
图2 本文提出的任务驱动式学习示意图。
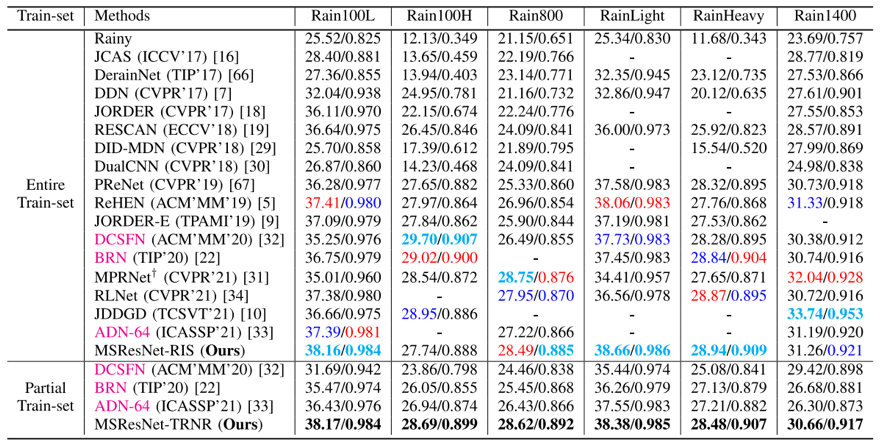
本文进一步验证了所提出的任务驱动式学习方法的优越性。具体地,本文基于公用的多个去雨、去噪数据集构建了对应的小样本数据集。在构建的小样本数据集上,本文采用所提出的任务驱动式方法进行训练。如表一所示,本文提出的算法在小样本数据集上训练的性能已经超越了多种在大规模数据集上训练的主流深度模型。这一结果表明本文提出的任务驱动式学习方法能够使得深度模型从少量数据学习,有效缓解了深度模型对大规模数据集的依赖。(图像去噪的结果可参考论文中的表8和表9)
表1 公用数据集上和主流方法的性能比较
最后,本文比较了小规模数据集上训练模型和大规模数据集上训练模型在真实雨图上的泛化性。如图三所示,在小规模数据集上训练的模型在真实雨图上反而实现了更好的去雨效果。此外,本文从梯度下降算法层面证明了提出的任务驱动式算法相对于数据驱动式算法能提供更好的参数梯度,并拥有更好的泛化性。

图3 不同方法在真实雨图上的泛化性比
03
Memorizing Complementation Network for Few-Shot Class-Incremental Learning
作者:冀中1,侯志申1,刘西瑶1,2,庞彦伟1,李学龙3
单位:1天津大学,2中科院自动化所,3西北工业大学
邮箱:
jizhong@tju.edu.cn
zshou@tju.edu.cn
xiyaoliu@tju.edu.cn
pyw@tju.edu.cn
li@nwpu.edu.cn
论文:
https://arxiv.org/abs/2208.05610
少样本类增量学习(Few-shot Class-Incremental Learning, FSCIL)旨在仅使用少量样本持续地学习新概念,因此容易出现灾难性遗忘和过拟合问题。旧类别的不可获取性和新样本的稀缺性使得在保留旧知识和学习新概念之间实现权衡变得非常困难。当前研究发现,单个模型主要关注于单方面的特征表示,而不同的模型会有不同的侧重点。因此,在不断学习新概念时,不同的模型可能会记住不同的知识。受此启发,本研究期望将多个模型集成以实现记忆互补。为此,本研究提出一种记忆互补网络(Memorizing Complementation Network, MCNet)来集成多种模型,在新任务中实现模型所记忆知识的互补。此外,为了用很少的新样本来更新模型,设计了一个原型平滑难挖掘三元组(Prototype Smoothing Hard-mining Triplet, PSHT)损失,以使新样本不仅在当前任务中彼此远离,同时也远离旧类别的分布。
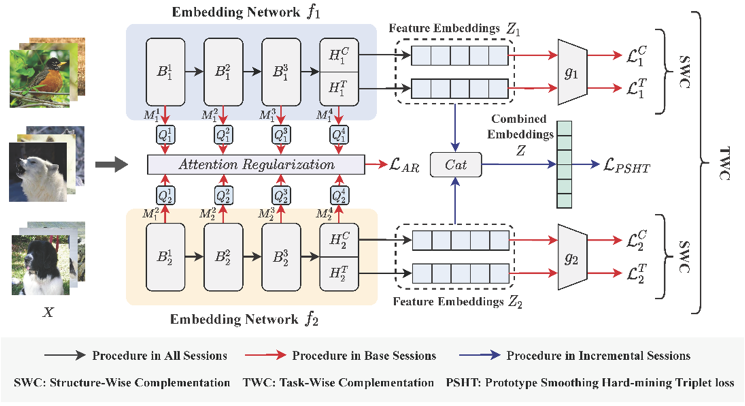
图1 记忆互补网络框架示意图
如图1所示,MCNet 分别由结构互补(Structure-Wise Complementation, SWC)策略和任务互补(Task-Wise Complementation, TWC)策略组成,用于获取多种特征提取网络。SWC 包含一个CNN 头和一个Transformer 头来提取不同的特征,而TWC通过使用余弦分类器的传统分类任务和使用基于度量分类器的跨模态分类任务来训练模型。此外,利用注意力正则化(Attention Regularization, AR)来进一步提高不同模型的多样性。本工作使用原型平滑难挖掘三元组损失损失实现模型的更新,不仅约束了当前任务中不同样本之间的相似性,同时也促使新样本远离旧样本分布,如图2所示。最后,在CIFAR100、miniImageNet 和CUB 三个基准数据集上进行了充分的实验,实验结果表明,所提方法的性能明显优于现有方法,能够有效缓解少样本类增量学习中的灾难性遗忘及过拟合问题。
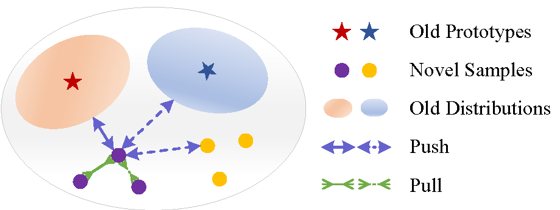
图2 原型平滑难挖掘三元组损失示意图
04
Binary Change Guided Hyperspectral Multiclass Change Detection
作者:胡美琪1,武辰1*,杜博2,张良培1
单位:1武汉大学 测绘遥感信息工程国家重点实验室,2武汉大学 计算机学院
邮箱:
meiqi.hu@whu.edu.cn;
chen.wu@whu.edu.cn;
gunspace@163.com;
zlp62@whu.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10011164
代码:
https://github.com/meiqihu/BCG-Net
引言
遥感影像多类变化检测任务相比常规的二类变化检测更具挑战性,不仅要检测影像中发生变化的区域,还要区分不同的土地变换,获得多类变化的个数和对应的变化区域。高光谱影像丰度的光谱信息可以协助多类变化检测,提供更加精细化的变化结果,对实际应用的感兴趣变化分析更具价值。传统的多类变化检测算法大多通过分类后比较或者解混后比较实现,但往往忽略了两时相影像之间的相关性,且任意影像的分类或者解混误差都会影像最终的变化检测结果,带来误差积累。
研究动机
我们发现二类变化本身是时序相关性的一种表征,即未变化像元在两个时相的组成成分大致一致,因此对应的多时相的丰度是一致的;反之亦然。因此我们提出从二类变化检测的角度,来检验多时相丰度的一致性和时序相关性,促进多时相解混的效果,而多类变化检测结果是由多时相丰度比较获得的,因此可以获得更好的多类变化检测结果。
方法概述
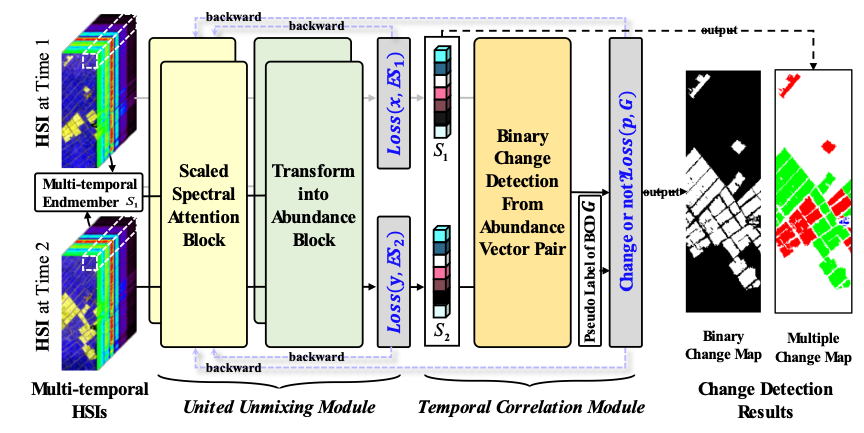
图1. 所提算法BCG-Net的结构图。
如图1所示,BCG-Net由联合解混模块与时序相关模块组成。其中,联合解混模块采用局部孪生网络结构,共享特征提取模式,并将和为一约束和非负约束融入到网络当中,无监督解混过程在网络优化中十分便利。而时序相关性模块提供了一种新颖的从解混结果提取变化信息的策略。无监督解混一般以最小化重建光谱与原始光谱之间的距离作为优化目标。而由于噪声或光照等局部条件影响,原始光谱可能含有噪声和扰动,重建误差越小并一定能保证丰度的准确性。而时序相关性模块本质是从变化检测的角度来检验双时相影像解混的效果。两个网络以交替迭代的形式进行优化,在网络的反向传播中,时序相关性模块反向作用于解混模块,使得未变化像元的丰度成分更加一致,而变化像元的丰度成分更加准确。
实验结果
为了验证BCG-Net方法的有效性,我们分别在合成Urban数据集,中国数据集以及美国数据集上进行测试,对比算法包括ISFA,BIT,GETNET,KPCA,MSU,PUC等在内的10种传统和基于深度学习的方法。在中国数据集上的二类变化检测结果如图2所示,多类变化检测如图3所示,由实验结果可得,所提BCG-Net在二类结果图上噪声更少,多类变化结果图上更加准确。表展示了加入时序相关性模块后,BCG-Net计算得到的丰度图的均方差误差更小,精度更高,体现了所提方法的有效性。

图2. 中国数据集上的二类变化检测结果。(a) CVA, (b) ISFA, (c) BIT, (d) GETNET (without unmixing), (e) GETNET (with unmixing), (f) C2VA, (g) KPCA, (h) MSU, (i) PUC, (j) Re3FCN, (k) BCG-Net, (l) Reference of binary change detection.
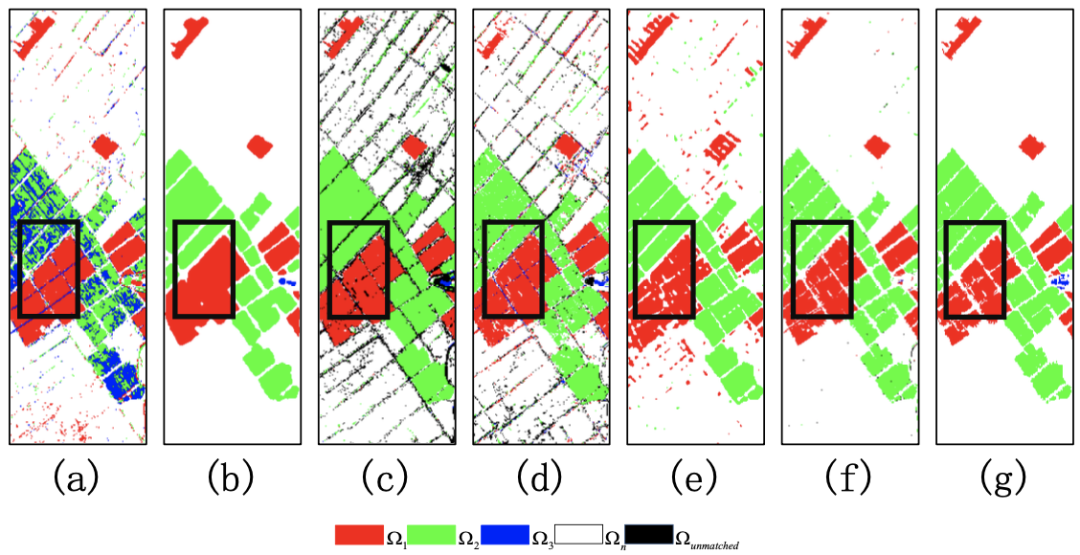
图3. 中国数据集上的多类变化检测结果。 (a) C2VA, (b) KPCA-MNet, (c) MSU, (d) PUC, (e) Re3FCN, (f) BCG-Net, (g) Reference of multiclass change detection.
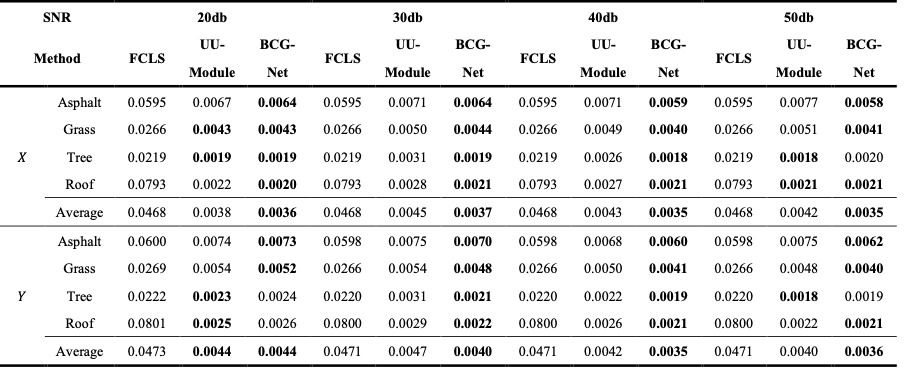
表1 合成Urban数据集的丰度均方差MSE对比结果,不含时序相关性模块(FCLS, UU-Module)与加时序相关性模块(BCG-Net),其中最优结果加粗表示
05
Dynamic Training Data Dropout for Robust Deep Face Recognition
作者:钟瑶瑶1,邓伟洪*1,方瀚1,胡佳妮1,赵东悦2,李献2,温东超2
单位:1北京邮电大学,2佳能信息技术(北京)
邮箱:
zhongyaoyao@bupt.edu.cn;
whdeng@bupt.edu.cn;
论文:
https://ieeexplore.ieee.org/abstract/document/9591391
在深度人脸识别中,基于Softmax的大间隔损失函数(如ArcFace)近几年取得了成功,但这类方法主要是为干净的人脸训练集设计的。训练集中不可避免存在的标签噪声和低质量图像等影响了模型性能。模型的鲁棒训练是一个具有实际挑战性的问题,针对于此,本文提出了一种动态训练数据丢弃(Dynamic Training Data Dropout, DTDD)方法,如图一所示,在模型训练过程中动态过滤训练数据库中的标签噪声和低质量图像,并逐步形成用于模型学习的稳定的细化数据。

图1
本文提出的这一方法即依赖于模型预测的这种不稳定性,在累积训练时间段内,利用模型预测所提供的累积信息有效区分一般样本和低质量训练样本。如图二所示,左侧列展示了一般样本,右侧列展示了与左侧同一身份的标签噪声或低质量图像。其中,对于一般样本,样本和模型预测模板的角度距离曲线(红色曲线)与样本和标注类别模板的角度距离曲线(蓝色曲线)一致,而标签噪声的两曲线之间差异则更大。与根据某一时刻的指标来进行噪声甄别的相关工作相比,本文的方法更关注训练过程中的累积信息,从而能动态且准确地区分一般样本和噪声。此外,这一方法易于实现且稳定,可以与现有的最先进的损失功能和网络架构相结合使用。
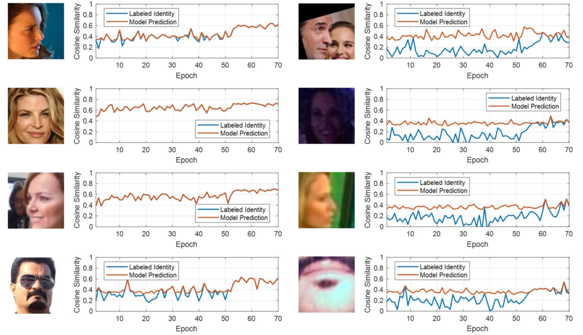
图2
本文在CASIA WebFace、VGGFace2和MS-Celeb-1M三个训练集,和LFW、CALFW、CPLFW、MegaFace、IJB-A和IJB-C多个测试集上实验验证了这一方法的有效性,这表明该方法可以在存在标签噪声和低质量图像的情况下鲁棒地训练深度人脸识别模型。
06
Unsupervised Cumulative Domain Adaptation for Foggy Scene Optical Flow
作者:周寒宇1, 昌毅1*, 闫问鼎2, 颜露新1
单位:1华中科技大学;2华为国际有限公司
邮箱:
hyzhou@hust.edu.cn;
owuchangyuo@gmail.com;
yan.wending@huawei.com;
yanluxin@hust.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Zhou_Unsupervised_Cumulative_Domain_Adaptation_for_Foggy_Scene_Optical_Flow_CVPR_2023_paper.pdf
1. 引言
光流在清晰场景下已经取得了巨大进步,但是往往受限于雾天场景。究其原因,雾弱化场景对比度,打破了光流的亮度恒常性和运动连续性假设。一种最容易想到的策略是先去雾再估计光流,但是去雾后的结果可能存在过平滑干扰光流。现有工作尝试从域适应角度出发,利用仿真图像对来挖掘退化不变性特征以迁移清晰域运动知识到雾天域。然而,这种方法只能解决好清晰-退化之间的域差异,而忽略了仿真和实测之间的域差异,导致难以在实测雾天场景保证性能。为了解决这个问题,我们的目的是希望寻找一个中间域可以连接清晰域和实测雾天域,进而累积式地迁移清晰域运动知识到实测雾天域,如图1所示。我们发现雾天光流退化程度受深度影响,这启发我们设计一个深度关联域适应模块来缩小清晰-雾天之间的域差异;我们分析得仿真和实测雾图在cost volume空间具有相关性分布相似特性,这驱使我们设计一个相关性对齐域适应模块来缩小仿真-实测之间的域差异。统一框架下,提出的累积式域适应模块可以逐渐地将清晰域知识迁移到实测雾天域。
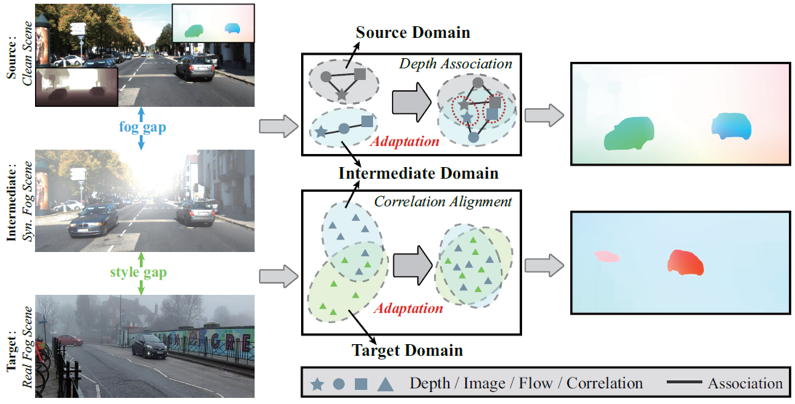
图1 累积式知识迁移框架
2. 方法概述
我们首先输入立体图像对,估计得到深度和清晰域光流。一方面,深度通过几何投影方程约束清晰域光流边缘;另一方面,深度通过大气散射模型合成仿真雾图。仿真雾图作为中间域,通过光流估计器得到仿真域光流,通过运动一致性达到清晰域光流知识向仿真雾天域的定向迁移目的。对于仿真-实测域差异,我们输入仿真和实测雾图,并将他们映射到运动特征空间,通过K-L散度约束二者之间的分布差异,在迭代优化过程中将仿真域运动知识迁移到实测雾天域,具体网络框架如图2所示,其具有知识鲁棒性、迁移定向性等优点。
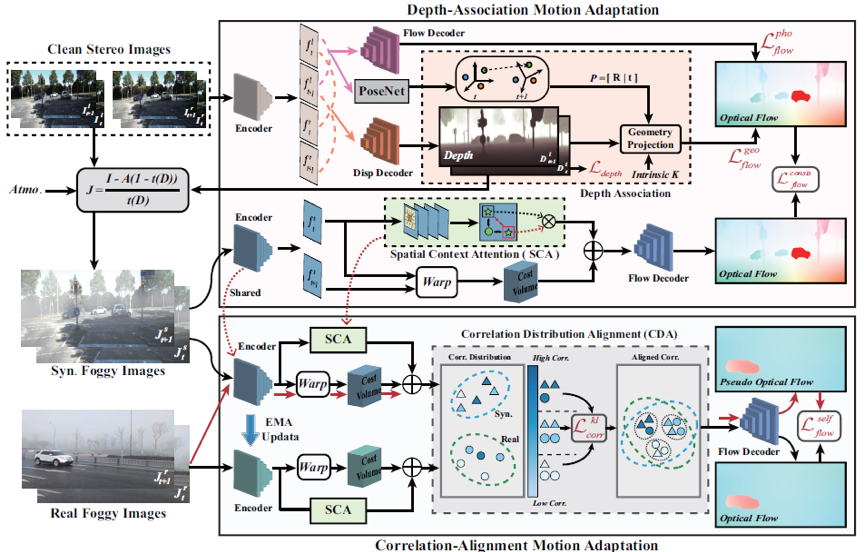
图2 深度关联和相关性对齐域适应模块
3. 实验结果
如图3所示,本文提出方法UCDA-Flow对实测雾天光流估计更加清晰且边缘锐利,验证了我们方法的有效性。
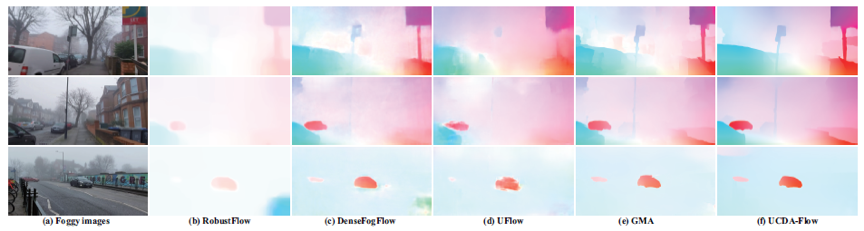
图3 实测雾天光流估计可视化对比结果

 京公网安备11010802017125号
京公网安备11010802017125号