
2023年论文导读第二十期
【论文导读】2023年论文导读第二十期
CCF多媒体专委会 2023-10-10 08:00 发表于山东


论文导读
2023年论文导读第二十期(总第八十六期)
目 录
|
1 |
Improving Generalization with Domain Convex Game |
|
2 |
Learning Distortion Invariant Representation for Image Restoration from A Causality Perspective |
|
3 |
A Unified Spatial-Angular Structured Light for Single-View Acquisition of Shape and Reflectance |
|
4 |
Fair Scratch Tickets: Finding Fair Sparse Networks without Weight Training |
|
5 |
MIANet: Aggregating Unbiased Instance and General Information for Few-Shot Semantic Segmentation |
|
5 |
Transfer Knowledge from Head to Tail: Uncertainty Calibration under Long-tailed Distribution |
01
Improving Generalization with Domain Convex Game
作者:吕芳蕊,梁健,李爽,张津铭,刘迪
单位:北京理工大学
邮箱:
fangruilv49@gmail.com,
liangjianzb12@gmail.com,
liudi010@gmail.com,
shuangli@bit.edu.cn,
jinming-zhang@bit.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Lv_Improving_Generalization_With_Domain_Convex_Game_CVPR_2023_paper.pdf
代码:
https://github.com/BIT-DA/DCG
领域泛化旨在将从多个源领域中学习到的知识泛化到未见的目标领域上,以此来缓解深度神经网络泛化能力差的问题。一种经典的解决方法是对现有的源领域进行领域增广,其核心思想为源域多样性的增强将有助于模型在分布外数据上的泛化性能。但这一主张更多依赖于直觉性的理解,而缺乏理论支撑。因此,本工作对模型泛化性能与领域多样性间的关系进行了探索,实验表明其并未呈现严格的正相关,随着增广领域数量的增加,有时反而会造成模型泛化性能的下降。这一方面可能是因为模型并未充分利用增广领域中的多样化信息,另一方面则可能是由于存在包含冗余信息或有害信息的低质量样本。上述探索结果表明领域增广对模型泛化性能的增强仍有提升空间,从而引发了我们对领域增广方法有效性的进一步思考。
本工作试图通过追求模型泛化性能和领域多样性间的严格正相关性来保证并进一步提高领域增广方法的有效性。为此,本工作从一个新的角度看待领域泛化,将其形式化为领域间的凸博弈问题,最终博弈目标即为模型泛化性能的最大化。具体来说,首先利用凸博弈的超模性构建了一个正则项约束,用于鼓励每个增广领域都能对模型泛化性能的提升做出贡献,同时尽量减缓领域的边际效应递减速度,从而有利于模型更好地利用多样化的信息。此外,考虑到可能存在一些对模型泛化不利的信息,本工作基于上述正则项进一步构造了一个样本过滤器,用于过滤掉不利于最终博弈目标的低质量样本,如噪音或冗余样本,从而避免潜在有害信息对模型带来的负迁移影响。
本工作所提出的算法框架为领域泛化的形式化分析提供了一种新的思路,保证并进一步提高了增强领域多样性对模型泛化能力的提升。启发性分析以及相关实验证明了本工作的合理性和有效性,同时真实世界数据集上的大量实验结果也表明本工作在领域泛化问题中取得了最先进的模型泛化性能。
02
Learning Distortion Invariant Representation for Image Restoration from A Causality Perspective
作者:李鑫, 李秉宸, 金鑫, 兰翠玲, 陈志波
单位:中国科学技术大学,微软亚洲研究院,东方理工高等研究院
邮箱:
lixin666@mail.ustc.edu.cn;
lbc31415926@mail.ustc.edu.cn;
jinxin@eias.ac.cn;
culan@microsoft.com;
chenzhibo@ustc.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Li_Learning_Distortion_Invariant_Representation_for_Image_Restoration_From_a_Causality_CVPR_2023_paper.pdf
代码:
https://github.com/lixinustc/Causal-IR-DIL
近年来,我们见证了深度神经网络模型在图像修复中的重大进展。然而,当前模型的局限性在于其受限于训练场景的失真,无法适应程度或类型更加复杂、未包含在训练集中的真实场景失真。本文从全新的因果学习角度建模分析图像修复,并提出了一种新的图像修复训练范式,以提升模型在训练集包含失真范围之外的,未知退化场景的去失真泛化能力。我们将该方法称为“失真不变表征学习”(DIL,如图2所示)。在本文中,我们将每种失真类型和程度视为一个特定的混淆因子,并通过消除每种失真的有害混淆效应来学习失真不变表征。从图1所示的因果图中可以看出,目前的图像修复模型泛化能力之所以差,是因为后门的存在,造成了修复过程与失真类型和程度的不独立。为了去除失真类型和程度等混淆因子对于修复过程的干扰,使他们互相独立,我们基于因果推断的后门准则,通过从优化角度建模不同失真对模型的混淆效应,推导出了失真不变表征学习的新范式。
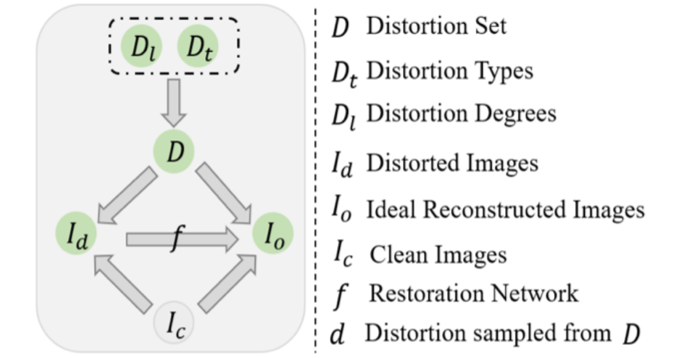
图1 图像修复的因果结构图
具体来说,我们从三个角度实现了图像修复的失真不变表征学习。1)基于反事实的失真增广,实现满足因果学习的训练集构建;2)从优化角度建模因果推断后门准则,取得失真不变表征学习的理论指导;3)从元学习角度提出了四种失真不变学习的优化策略。其中,反事实失真增广可以用来模拟不同失真类型和程度的混淆因子,而通过元学习则可以消除它们对修复过程的干扰。
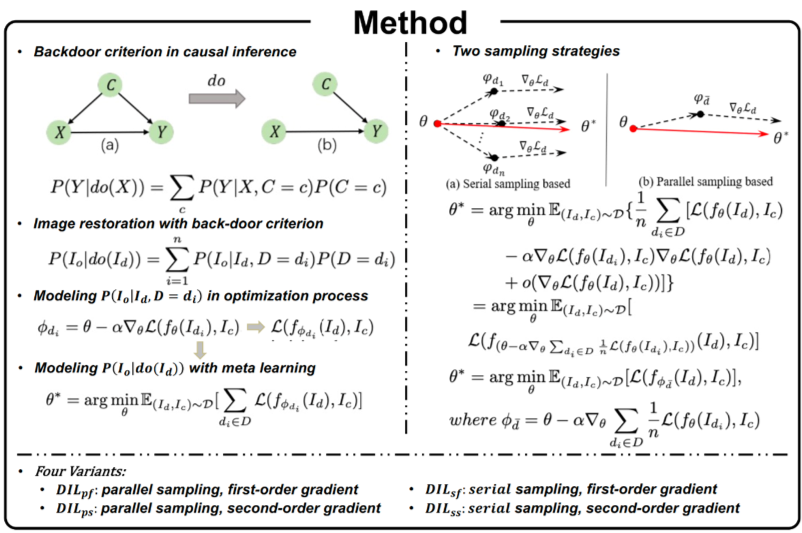
图2 DIL方法示意图
我们在六个任务上验证了我们的失真不变表征学习,其中包括图像去噪(如图3所示),去模糊,混合失真去除,真实场景超分变率(如图4所示),真实场景去噪,和去雨(如图5所示)等任务。在多个任务上的详尽的实验结果表明,我们提出的新范式有效的消除了混淆因子对图像修复过程的干扰,极大的提升了模型在训练集未见过的真实场景失真上的泛化能力,论证了因果学习在图像修复领域的无限可能。我们的论文发表于CVPR2023,如果大家感兴趣,欢迎一起探讨,共同改进!
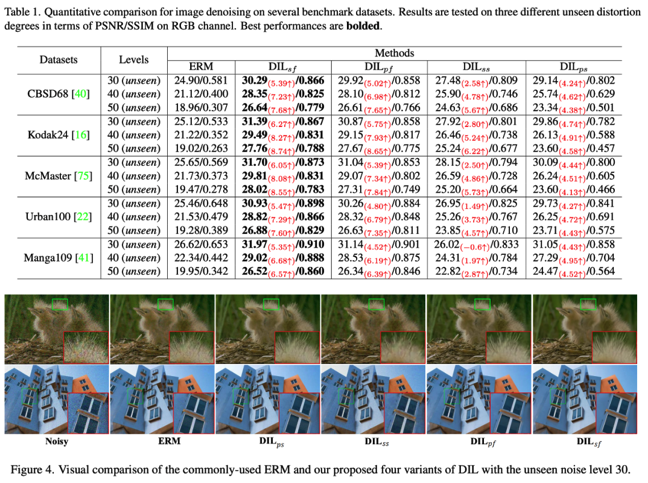
图3 DIL在图像去噪任务上的性能展示
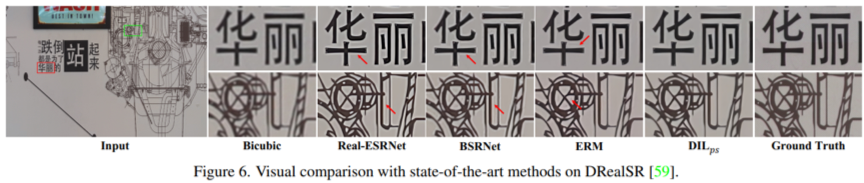
图4 DIL在真实图像超分辨率任务上的主观效果展示
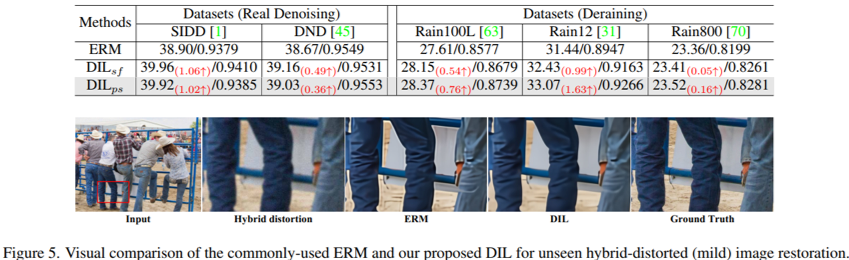
图5 DIL在真实去噪和真实去雨任务上的性能展示
03
A Unified Spatial-Angular Structured Light for Single-View Acquisition of Shape and Reflectance
作者:徐贤民,林雨欣,周浩洋,曾充,余亚鑫,吴鸿智,周昆
单位:浙江大学计算机辅助设计与图形系统全国重点实验室,杭州相芯科技有限公司
邮箱:
xuxianmincs@gmail.com
yuxinlin.in@gmail.com
zhouhao@student.ethz.ch
chongzeng2000@gmail.com
22021283@zju.edu.cn
hwu@acm.org
kunzhou@acm.org
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Xu_A_Unified_Spatial-Angular_Structured_Light_for_Single-View_Acquisition_of_Shape_CVPR_2023_paper.pdf
论文主页:
https://svbrdf.github.io/publications/unified/project.html
背景
如何数字化真实世界中的复杂物体是计算机图形学与计算机视觉中的经典问题。高精度数字化结果由三维几何与高维材质组成。主流的结构光方法(图1)能够分别对空间域和角度域编解码以获取几何与材质信息。对于几何扫描,空间结构光方法将精心设计的光照图案投射到三维空间中来区分不同光线,从而实现精确的三角化测量。对于材质采集,角度结构光方法能够编程控制每个光源在不同时刻的亮度,依据相机测量值对复杂外观进行精准推断。虽然结构光已经能单独采集高精度几何或材质,但在将其应用到几何与材质的联合采集的场景时依然存在困难。本文首次提出了能同时采集几何与材质信息的轻量级高维结构光框架,通过LED阵列与LCD遮罩组合而成的光源原型,以及研究者搭建的能够自动优化遮罩与光照图案的可微分联合采集管线,等效构建了3072个分辨率约为320x320的投影仪,仅用单个相机即可实现0.27mm的几何重建精度以及SSIM=0.94的材质重建精度,在复杂物体重建实验中超越了SOTA。

图1 基于空间结构光和角度结构光原理的代表性产品/系统。左图为加拿大Creaform的HandySCAN 3D几何扫描仪,右图为本团队发表于SIGGRAPH Asia的专业级非平面外观采集系统。
硬件
本文提出的轻量级光源原型(图2)由LED阵列和LCD遮罩组成,对于几何采集,每个LED将遮罩图案(mask pattern)投射到空间中以编码形状信息。对于材质采集,相同的LED阵列在编程后产生不同的光照图案(light pattern),穿过被设置成全透明的LCD遮罩来采样随光照角度变化的材质。
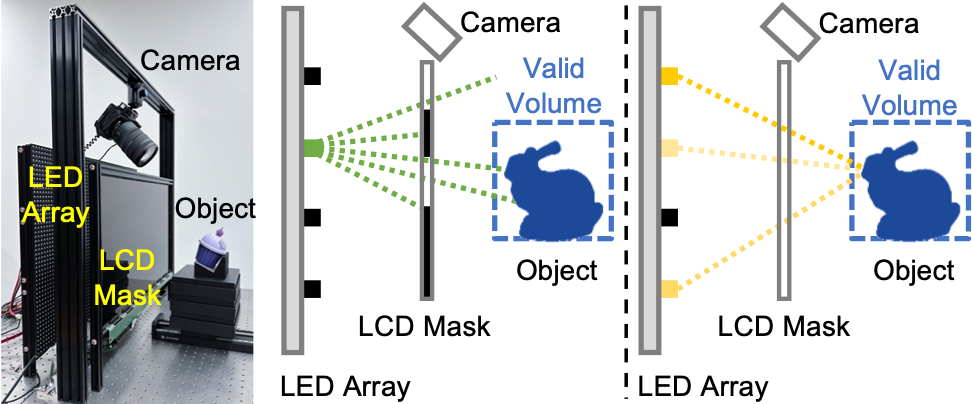
图2 团队自研的结构光硬件原型(图左),包括 64x48 的 LED 阵列、一个 1920x1080 分辨率的 LCD 遮罩(通过对普通液晶显示器拆卸后得到)和一台相机。使用单个 LED 能投影一组遮罩图案来采集三维几何(图中),而多个 LED 能投影光照图案穿过全透明遮罩来采集高维材质(图右)。
软件
本文建立了可微分联合采集管线(图3)来自动优化遮罩与光照图案,从而充分利用新型结构光的硬件采样能力。
对于几何采集,研究人员为每个 LED 独立学习出一组遮罩图案(18 张),优化目标是最小化沿任意相机射线的深度不确定性。每次拍摄,面光源透过特定遮罩图案得到的像素值为:
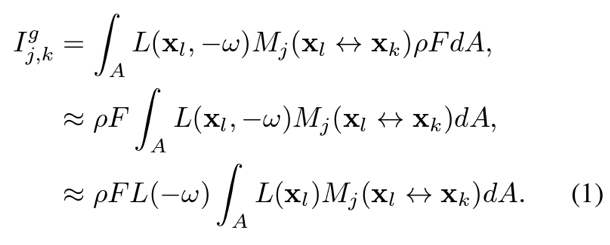
对多次拍摄得到的一组像素值正则化得到的编码向量为:
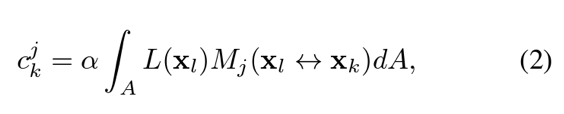
本文将该优化问题转化为多分类问题,采用交叉熵损失函数优化遮罩图案。研究人员还利用了造成遮罩图案投影轻微失焦的物理卷积过程,来编码更丰富的空间信息进行深度消歧。
对于外观采集,光照图案(32 张)作为自编码器的线性编码部分进行优化[Kang et al.2019],依据使用上述光照图案获取的测量值优化出高维材质。在这个过程中,已重建的三维几何也会被考虑(用来模拟阴影等由于几何所造成的现象),从而提高材质结果的质量。
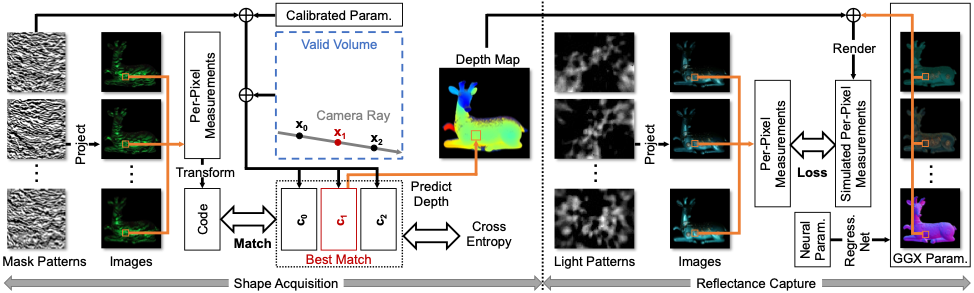
图3 整个系统的采集重建流程。
结果
研究人员使用自研原型系统采集重建了多种复杂物体的几何与外观。下图 4 对比了实拍照片、本系统的几何与外观重建结果以及相关 SOTA 方法的结果。
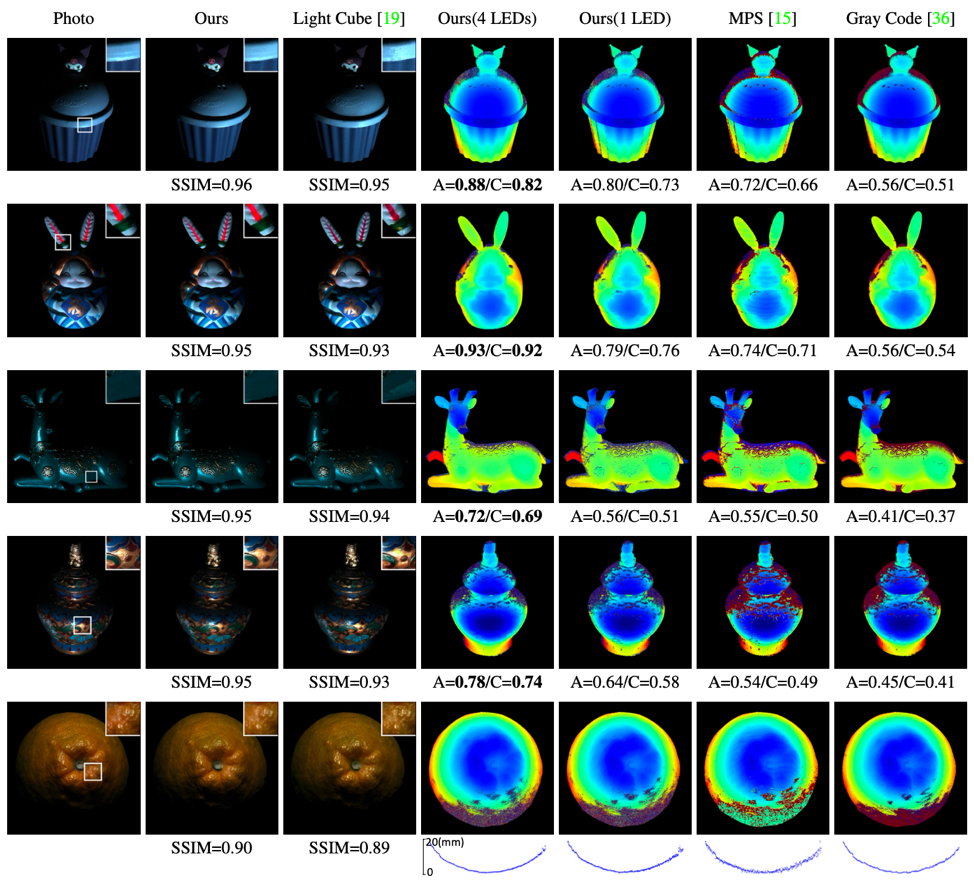
图4 实拍照片、本系统的采集重建结果以及相关 SOTA 方法之间的比较。外观质量用 SSIM 衡量,几何质量以精度(缩写为 A)和完整性(缩写为 C)比例来表示。数值越大,质量越高。
本系统生成的外观结果使用工业界标准的各向异性 GGX BRDF 参数纹理来表示,可以由任意基于物理的绘制器(PBR)读取并绘制出全新光照和视角下的图片。下图 5 展示了外观重建结果的分项参数。

图5 外观重建结果的分项参数(漫反射率、高光反射率、法向量和粗糙度)。
04
Fair Scratch Tickets: Finding Fair Sparse Networks without Weight Training
作者:唐鹏威,姚巍,李智聪,刘勇*
单位:中国人民大学高瓴人工智能学院,北京市大数据管理与分析方法重点实验室
邮箱:
liuyonggsai@ruc.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Tang_Fair_Scratch_Tickets_Finding_Fair_Sparse_Networks_Without_Weight_Training_CVPR_2023_paper.pdf
代码:
https://github.com/HungerPWAY/Fair-Scratch-Tickets
*通讯作者
最近的研究表明,计算机视觉模型有损害公平性的风险。有大量的工作使用预处理,在处理和后处理的方法,以缓解计算机视觉的不公平性。在本文中,我们在计算机视觉公平性的背景下,通过彩票假说的视角,引入了一种新的公平感知学习范式。我们随机初始化一个密集神经网络,并为其权重找到合适的二值掩码,从而得到公平的稀疏子网络,而无需进行任何权重训练。有趣的是,据我们所知,我们是第一个发现这种具有天生公平性的稀疏子网络存在于随机初始化的网络中,实现了与使用现有公平性感知处理方法训练的密集神经网络相当的准确性-公平性权衡。我们将这些公平子网称为公平彩票(FST)。我们从理论上也为其提供了公平性和准确性的保证。在我们的实验中,我们研究了FST在各种数据集、目标属性、随机初始化方法、稀疏模式和公平性代理上的存在性。我们还发现FSTs可以跨数据集传输,并研究了FSTs的其他特性。
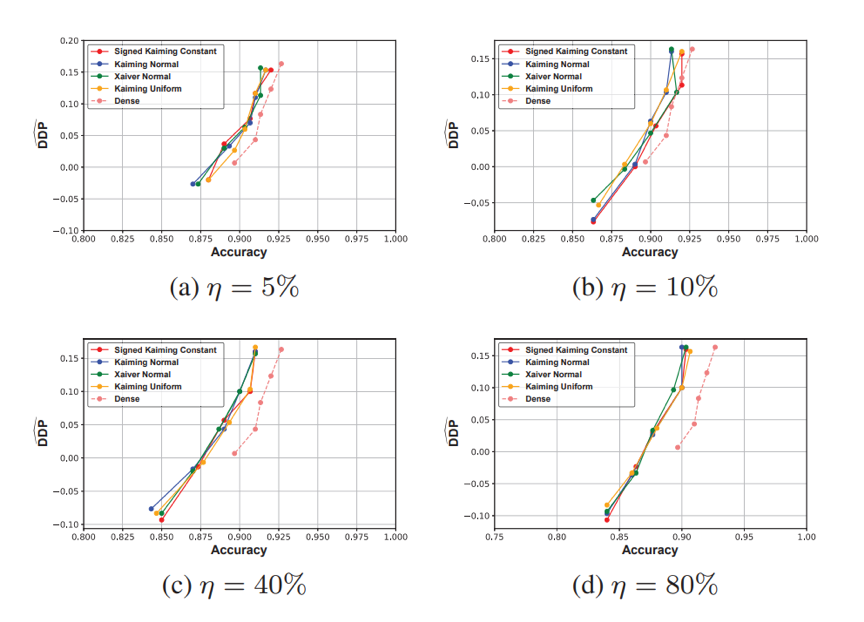
首先,我们从理论上证明FST的存在性。我们根据彩票假说的相关理论分析,结合公平性和准确率的考量,证明了如果子网络和原网络输出的结果相差不大,那么子网络和原网络的公平性和训练集准确率也相差不大。如下定理中DDP代表模型在公平性定义DP上的违反程度,ACC代表训练集准确率。 附录中把该定理拓展到公平性定义EO中。

本文寻找稀疏子网络的方法是,训练mask来选择性地使得某些权重为0,从而达到对神经网络进行修剪的效果。我们对每个权重赋予一个得分,我们保留高得分的权重,而给低得分的权重乘上mask。得分通过梯度更新的形式进行训练。接着,我们分别将该方法结合经典的公平性正则化方法和公平性对抗训练的方法,得到稀疏且准确的公平子网络。我们对于不同的保留率、初始化、稀疏模式、公平性定义和数据集都做了充分的实验,实验结果在正文和附录中。我们发现,正如我们理论预想的一样,我们总能找到既公平又准确的稀疏子网络:
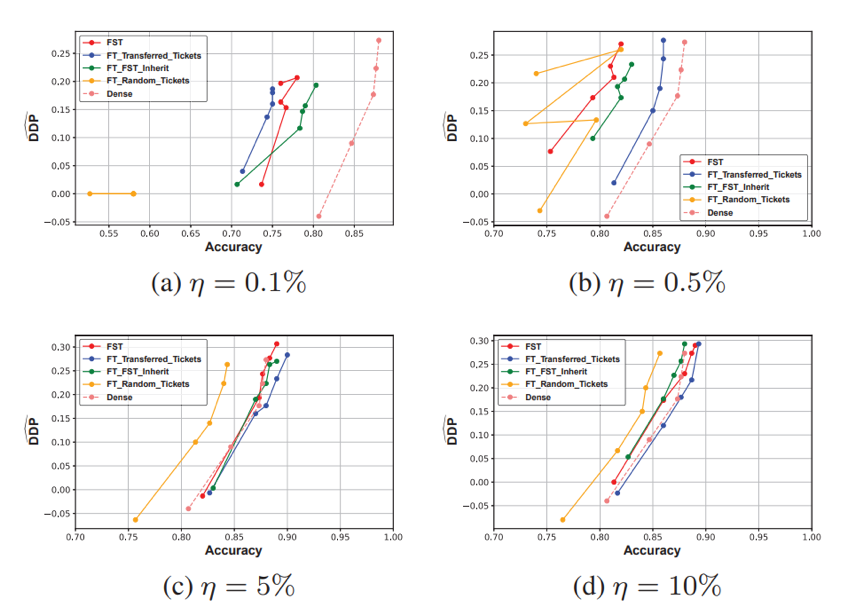
同时,我们发现我们的公平子网络具有迁移性,即大数据上获得的稀疏子网络在小数据集进行权重训练甚至能够取得比稠密网络更好的性能:
05
MIANet: Aggregating Unbiased Instance and General Information for Few-Shot Semantic Segmentation
作者:杨咏、陈琼、冯媛、黄天林
单位: 华南理工大学-计算机科学与工程学院
邮箱:
202021044116@mail.scut.edu.cn;
csqchen@scut.edu.cn;
202120143952@mail.scut.edu.cn;
202121044681@mail.scut.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Yang_MIANet_Aggregating_Unbiased_Instance_and_General_Information_for_Few-Shot_Semantic_CVPR_2023_paper.pdf
代码:
https://github.com/Aldrich2y/MIANet
1. 目前存在的问题
目前的小样本分割解决方案存在以下两个主要问题。(1)样本类内差异问题,即模型无法处理过大的样本类内差异。(2)预测偏置问题,即模型对未见过类别的预测容易偏向已见过类。
首先,样本类内差异是指同一类物体的不同图像之间的变异。如图1,同一类别的自然图片间存在语义差异和视觉畸变,自然图片间存在的这两个特点会导致支持集图片和测试集图片间存在类内差异。而当前的小样本分割方法先从支持集样本中抽取引导信息,然后使用度量方法将引导信息与查询样本图片特征进行匹配来分割查询图片。当支持集图片和查询集图片间的类内差异过大时,支持图片提供的引导信息和查询特征不能有效地支持匹配分割策略,从而严重影响模型的泛化性能。
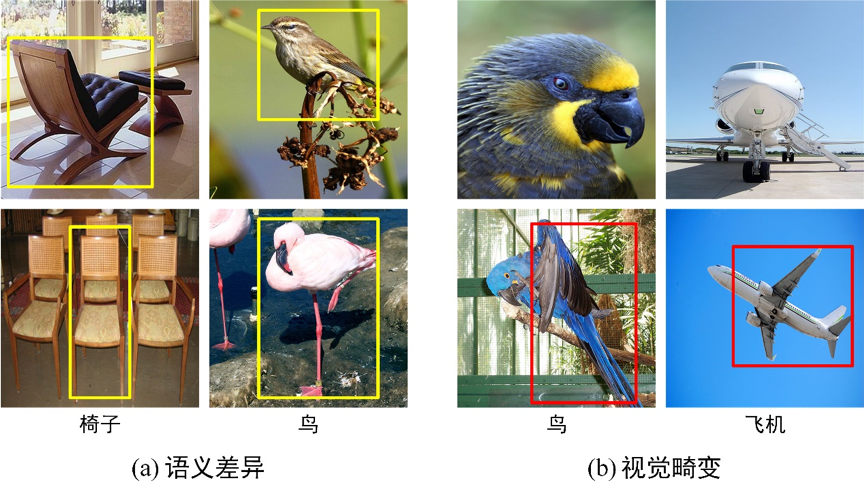
图1 同类别自然图片间存在的类内差异问题示意图
其次,目前的小样本分割方法设计大量模块来利用有限的实例信息,这些模块可以捕获上下文信息并且具有大量需要训练的参数。然而,基于度量的元学习策略的元训练阶段使用了大量已见过类别的标注数据来训练小样本分割模型,虽然一些模块冻结了骨干网络的参数,但剩下的需要训练的参数也会不可避免的适应这些训练数据的分布,从而使模型将训练阶段的已见过类别误分类为测试阶段的未见过类别。
2. 解决方法
为了解决上述问题,本文提出了一种名为多信息聚合网络(Multi-Information Aggregation Network, MIANet)的方法。模型结构如图2,首先提出了一个通用信息生成模块(General Information Module, GIM),来结合基于类别的词向量信息生成通用信息以补充匮乏的实例信息,缓解类内差异问题。此外,为了缓解预测偏置问题,本文提出了一个无参的层次先验信息生成模块(Hierarchical Prior Module, HPM)来生成无偏的多层次实例信息。最终,无偏的实例信息和通用信息被信息融合模块(Information Fusion Module)进行信息聚合,并对查询图片做出预测。
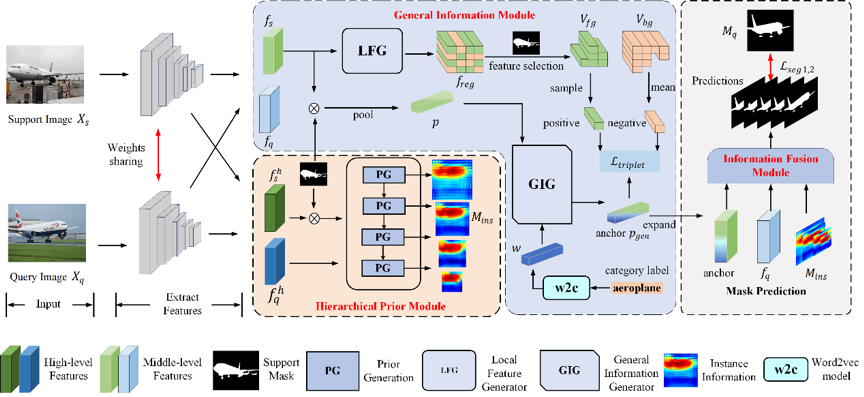
图2 模型MIANet 的结构示意图
3. 实验结果
表1和表2的综合实验表明,本文提出的MIANet所包含的创新之处有效地提高了Baseline模型的分割性能,取得了目前最优的分割性能。此外,图3中给出了一些Baseline模型和MIANet在PASCAL-5i和COCO-20i数据集上的可视化性能对比。相比于Baseline模型,本文提出的MIANet能够更准确地分割目标类别。
表1 在PASCAL-5 数据集上的mIoU性能对比
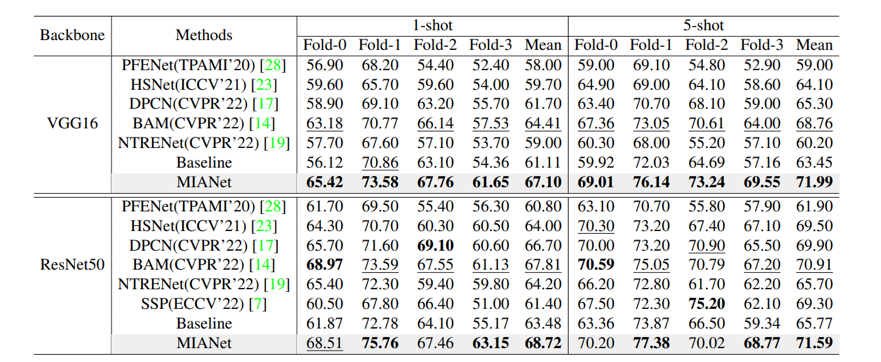
表2 在COCO-20i数据集上的mIoU性能对比
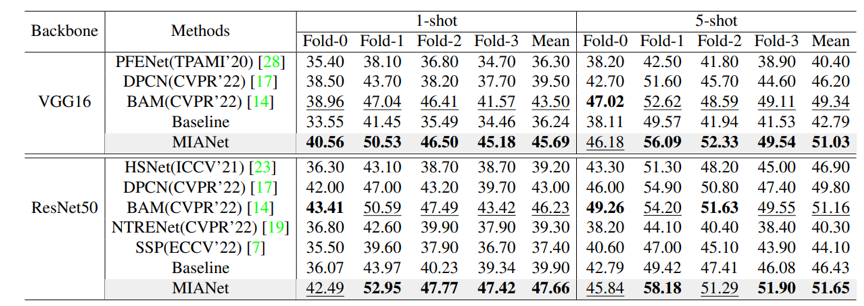

图3 模型在 PASCAL-5i和COCO-20i数据集上的可视化预测对比图
06
Transfer Knowledge from Head to Tail: Uncertainty Calibration under Long-tailed Distribution
作者:陈嘉浩1,2,苏冰1,2
单位:
1中国人民大学高瓴人工智能学院,2大数据管理与分析方法研究北京市重点实验室
邮箱:
nicelemon666@gmail.com,
subingats@gmail.com
论文:
https://arxiv.org/abs/2304.06537
代码:
https://github.com/JiahaoChen1/Calibration
1. 介绍
如何估计给定模型的不确定性是一个关键问题。当前的校准技术平等对待不同类别,因此隐含地假设训练数据的分布是平衡的,但忽略了现实中的数据通常遵循长尾分布(Long-tailed distribution)。本文研究长尾分布训练的模型校准的问题。由于不平衡的训练分布与平衡的测试分布之间的差异,现有的校准方法如温度缩放(temperature scaling)无法很好地泛化到这个问题。我们提出了一种基于知识传递的校准方法,通过估计尾部类别样本的重要性权重来实现长尾校准。我们的方法将每个类别的分布建模为高斯分布,并将头部类别的源统计信息视为先验以校准尾部类别的目标分布。我们自适应地从头部类别传递知识,以获得尾部类别的目标概率密度。重要性权重通过目标概率密度与源概率密度的比值来估计。

图1 数据分布平衡情况下的不确定性校准。

图2 数据分布不平衡情况下的不平衡校准。
2. 方法
首先给在公式(3)给出不确定性校准的公式。但是从公式(3)拟合出来的温度系数(T)能泛化到测试集的前提是训练数据和测试数据同分布,显然这个条件在长尾分布的情况下无法满足。
由公式(4)可以看到如果正确的到目标域和源域的比值,那么我们就可以正确估计出能泛化到测试集上的温度系数,因此实现长尾分布校准的关键在于如何寻找重要性权重。本文通过假设数据分布为高斯分布以及长尾分布下头部类别和尾部类别具有相似的知识来实现重要性权重的估计。
具体地,本文提出的方法分为如下四个步骤:
(1) 估计验证集上每个类别的特征分布
(2) 基于头部和尾部类别分布之间的Wasserstein距离计算注意力权重
(3) 估计目标域的概率密度函数
(4) 估计重要性权重
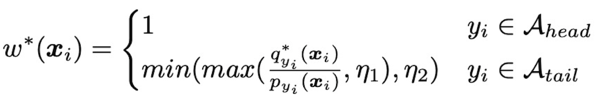
(5) 利用重要性权重学习温度系数T
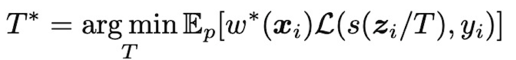
3. 实验
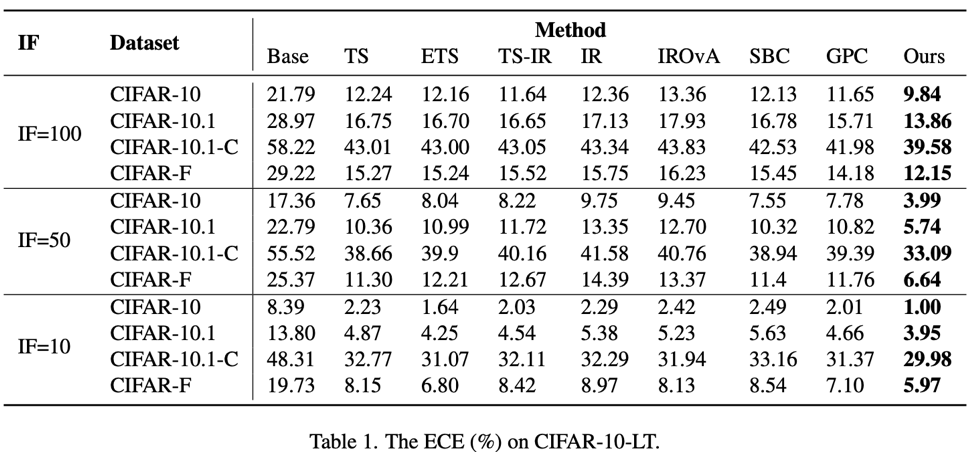
本文在CIFAR10-LT,CIFAR100-LT,MNIST-LT,ImageNet-LT四个数据集进行实验,实验结果证明了方法的有效性。CIFAR-10-LT的实验结果如表1所示。
同时本文给出了可视化的相似度来展示各个类别之间的关系,如图3所示,从图中可以看到一个尾部类别有多个相似的头部类别,这些头部类别的知识将会迁移到尾部类别中以更好的估计目标域的密度函数。

图3 相似度矩阵

 京公网安备11010802017125号
京公网安备11010802017125号