
2023年论文导读第十九期
【论文导读】2023年论文导读第十九期
CCF多媒体专委会 2023-09-26 08:00 发表于山东


论文导读
2023年论文导读第十九期(总第八十五期)
目 录
|
1 |
Fair Scratch Tickets: Finding Fair Sparse Networks without Weight Training |
|
2 |
Neural Residual Radiance Fields for Streamably Free-Viewpoint Videos |
|
3 |
Class-Conditional Sharpness-Aware Minimization for Deep Long-Tailed Recognition |
|
4 |
No One Left Behind: Improving the Worst Categories in Long-Tailed Learning |
|
5 |
Visual-Language Prompt Tuning with Knowledge-guided Context Optimization |
|
5 |
Learning Conditional Attributes for Compositional Zero-Shot Learning |
01
Fair Scratch Tickets: Finding Fair Sparse Networks without Weight Training
作者:唐鹏威,姚巍,李智聪,刘勇*
单位:中国人民大学高瓴人工智能学院,北京市大数据管理与分析方法重点实验室
邮箱:liuyonggsai@ruc.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Tang_Fair_Scratch_Tickets_Finding_Fair_Sparse_Networks_Without_Weight_Training_CVPR_2023_paper.pdf
代码:
https://github.com/HungerPWAY/Fair-Scratch-Tickets
最近的研究表明,计算机视觉模型有损害公平性的风险。有大量的工作使用预处理,在处理和后处理的方法,以缓解计算机视觉的不公平性。在本文中,我们在计算机视觉公平性的背景下,通过彩票假说的视角,引入了一种新的公平感知学习范式。我们随机初始化一个密集神经网络,并为其权重找到合适的二值掩码,从而得到公平的稀疏子网络,而无需进行任何权重训练。有趣的是,据我们所知,我们是第一个发现这种具有天生公平性的稀疏子网络存在于随机初始化的网络中,实现了与使用现有公平性感知处理方法训练的密集神经网络相当的准确性-公平性权衡。我们将这些公平子网称为公平彩票(FST)。我们从理论上也为其提供了公平性和准确性的保证。在我们的实验中,我们研究了FST在各种数据集、目标属性、随机初始化方法、稀疏模式和公平性代理上的存在性。我们还发现FSTs可以跨数据集传输,并研究了FSTs的其他特性。
首先,我们从理论上证明FST的存在性。我们根据彩票假说的相关理论分析,结合公平性和准确率的考量,证明了如果子网络和原网络输出的结果相差不大,那么子网络和原网络的公平性和训练集准确率也相差不大。如下定理中DDP代表模型在公平性定义DP上的违反程度,ACC代表训练集准确率。 附录中把该定理拓展到公平性定义EO中。

本文寻找稀疏子网络的方法是,训练mask来选择性地使得某些权重为0,从而达到对神经网络进行修剪的效果。我们对每个权重赋予一个得分,我们保留高得分的权重,而给低得分的权重乘上mask。得分通过梯度更新的形式进行训练。接着,我们分别将该方法结合经典的公平性正则化方法和公平性对抗训练的方法,得到稀疏且准确的公平子网络。我们对于不同的保留率、初始化、稀疏模式、公平性定义和数据集都做了充分的实验,实验结果在正文和附录中。我们发现,正如我们理论预想的一样,我们总能找到既公平又准确的稀疏子网络:
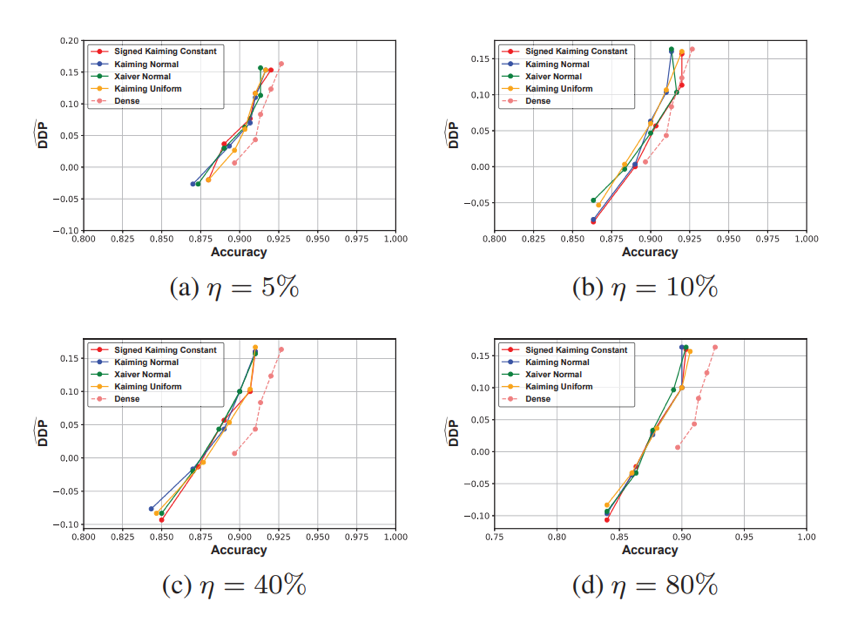
同时,我们发现我们的公平子网络具有迁移性,即大数据上获得的稀疏子网络在小数据集进行权重训练甚至能够取得比稠密网络更好的性能:

02
Neural Residual Radiance Fields for Streamably Free-Viewpoint Videos
可用于串流自由视角视频的神经残差辐射场
作者:王立翱1,3,胡强1,何其涵1,4,王子瑜1,虞晶怡1,Tinne Tuytelaars 2,许岚1,吴旻烨2
单位:1上海科技大学,2荷语鲁汶大学,3赜深科技,4叠境数字
邮箱:
wangla@shanghaitech.edu.cn
yujingyi@shanghaitech.edu.cn
xulan1@shanghaitech.edu.cn
minye.wu@kuleuven.be
论文:
https://openaccess.thecvf.com/content/CVPR2023/html/Wang_Neural_Residual_Radiance_Fields_for_Streamably_Free-Viewpoint_Videos_CVPR_2023_paper.html
公开数据集链接:
https://github.com/aoliao12138/ReRF_Dataset
代码:
https://github.com/aoliao12138/ReRF
论文介绍网页:
https://aoliao12138.github.io/ReRF
1 引言:
神经辐射场(NeRFs)在建模和自由视角渲染静态物体方面的成功,激发了对动态场景的众多尝试。目前利用神经辐射场技术进行动态场景的自由视角渲染还存在很多挑战,包括:1)受限于离线渲染,2)能够处理的序列比较短,3)序列中的场景变化,人物动作较小。
2 方法:
针对上述挑战,我们提出了 1)新的辐射场表达:残差辐射场或ReRF,作为一个高度紧凑的神经表示,以实现长时间动态场景的实时FVV渲染。2)顺序训练策略,以增强运动网格和残差网格的平滑性和稀疏性,从而在得到高压缩率的同时,维持原本的渲染质量。3)基于ReRF的编解码器,实现了三个数量级的压缩率,并提供了一个配套的ReRF播放器,支持动态场景的长序列FVV的在线串流播放。

图1 方法总览
如图1所示,我们首先使用我们的顺序训练方案为每帧i生成带有运动网格 Mi 和 ri 的紧凑 ReRF 表达。接下来,我们的基于 ReRF 的编解码器和播放器将对其进行压缩,以实现快速数据传输和在线播放。

图2 神经残差辐射场 (Neural Residual Radiance Field,ReRF) 示意图
ReRF表达的训练流程如图2所示。首先,我们估计一个稠密的动作场 Dt。接下来,通过动作池化,我们生成一个紧凑的动作网格 Mt。最后,我们利用Mt将 ft−1 的信息变换成网格 fˆt,并学习我们的残差网格rt,以增加网络特征的稀疏性并增加压缩率。
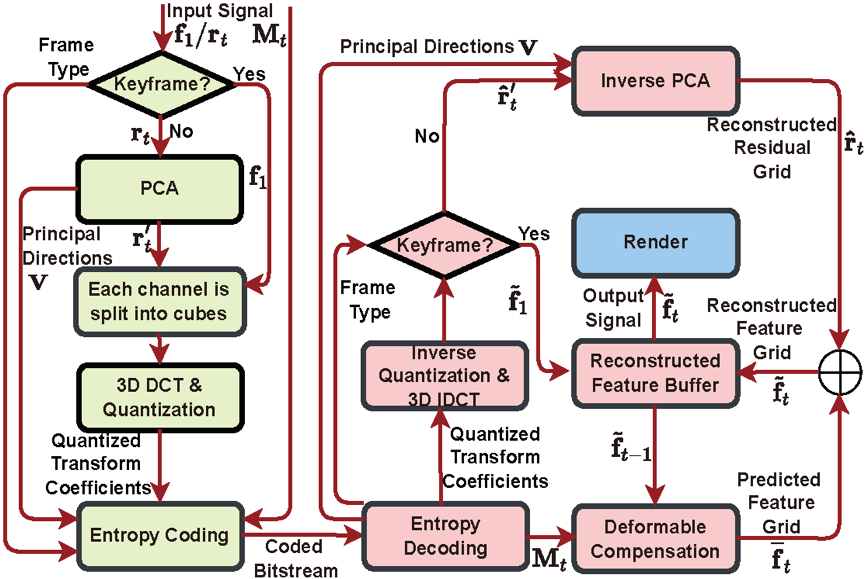
图3 基于 ReRF 的编解码器示意图
针对这样紧凑的ReRF表达,我们专门设计了编码器来支持动态场景的长序列播放。如图3所示,编码器和解码器分别用浅绿色和粉色阴影表示。编码器通过使用主成分分析(PCA)、3D-DCT、量化和熵编码将输入信号压缩为比特流。解码器接收压缩的比特流,以相反的顺序解码每个元素。
3 实验:
我们通过一系列实验说明我们方法的有效性。图4,图5和表1说明我们的方法相比其他方法能将容量压缩到很小的情况下,维持了很高的渲染质量。图6展示了我们方法不同部分的比特率-失真关系。我们的完整架构是最紧凑的,能够动态调整比特率以满足不同的存储需求。图7是关于帧数的定量比较。我们展示了随着帧数增加,我们的方法的性能不会降低。

图4 对动态场景重建方法和每帧静态重建方法的定性比较
表1 对动态场景重建方法和每帧静态重建方法的定量比较
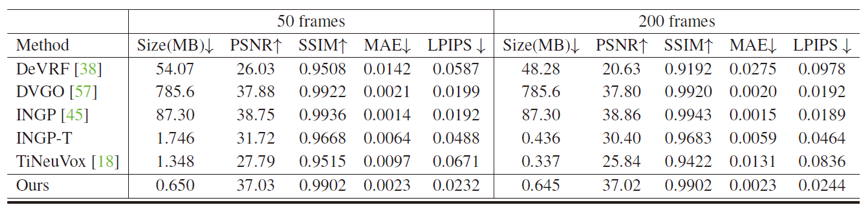
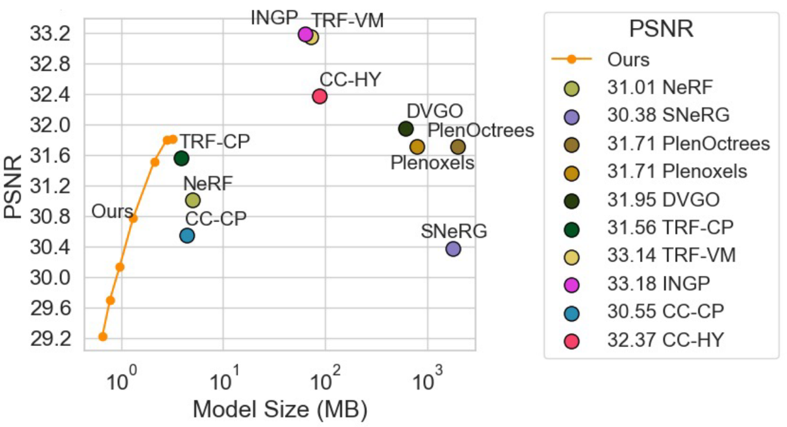
图5 在Synthetic NeRF 数据集的定量结果
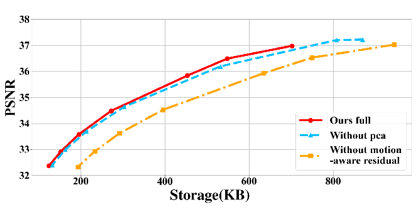
图6 比特率-失真曲线

图7 不同帧数下的定量比较
03
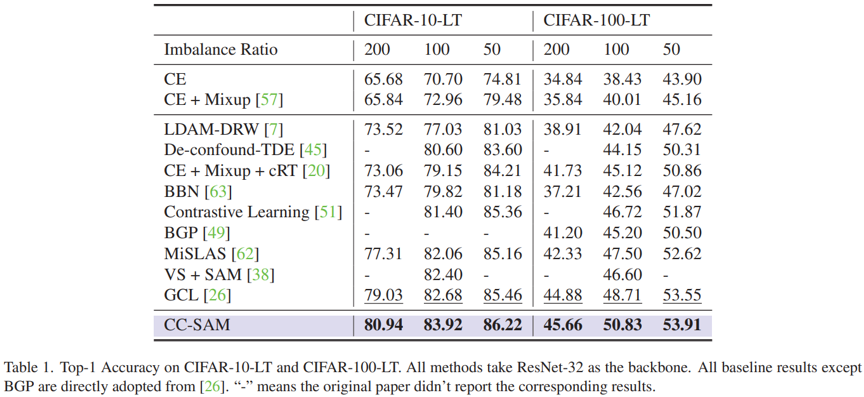
Class-Conditional Sharpness-Aware Minimization for Deep Long-Tailed Recognition
作者:周志鹏1*,李蓝青2,4*,赵沛霖3#,王平安2,龚伟1#
单位:1中国科学技术大学,2香港中文大学,3腾讯AI Lab, 4之江实验室
邮箱:
zzp1994@mail.ustc.edu.cn,
lanqingli1993@gmail.com,
masonzhao@tencent.com,
pheng@cse.cuhk.edu.hk,
weigong@ustc.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Zhou_Class-Conditional_Sharpness-Aware_Minimization_for_Deep_Long-Tailed_Recognition_CVPR_2023_paper.pdf
代码:
https://github.com/zzpustc/CC-SAM
*共同一作,#共同通讯
1. 研究背景和动机
在真实世界中,不平衡甚至是长尾的数据分布是十分普遍的,而该现象打破了传统机器学习中对训练集和测试集样本独立同分布的假设,对于算法模型提出了更大的挑战。以往的研究工作提出了多种不平衡学习方法,包括采样策略、数据增强、损失重加权、logit调整、解耦训练、集成学习等。本文则从一个全新的角度处理长尾学习,即寻找模型参数空间的平坦最小值区域(flat minima)以增强其泛化性。为此,本文首先选取主流的长尾学习方法(CE, LDAM-DRW,MiSLAS,GCL),对其训练后的模型加入幅度逐渐增长的随机参数扰动,观察其损失变化曲线(如图1所示)。由图可见,以Cross-Entropy (CE) 为参照,LDAM-DRW和GCL均呈现更尖锐的曲线变化。该实验一定程度上反映了现有长尾学习模型的参数普遍收敛到了尖锐的最小值(Sharp minima)区间,从而无法保证好的泛化性 。更新一步,本文将主流的平坦化方法,例如SWA, Spectral Normalization(SN), Gradient Penalization(GP), Model Perturbation(MP)等应用到现有长尾模型方法中,观察其对模型的增益(如图2),发现直接应用已有平坦化方法难以奏效。

图1 损失值 VS 噪声范数比例 。各方法结果以ResNet-32为骨干网络,在CIFAR10-LT(不平衡率为100)上平均5个随机种子实验得到。
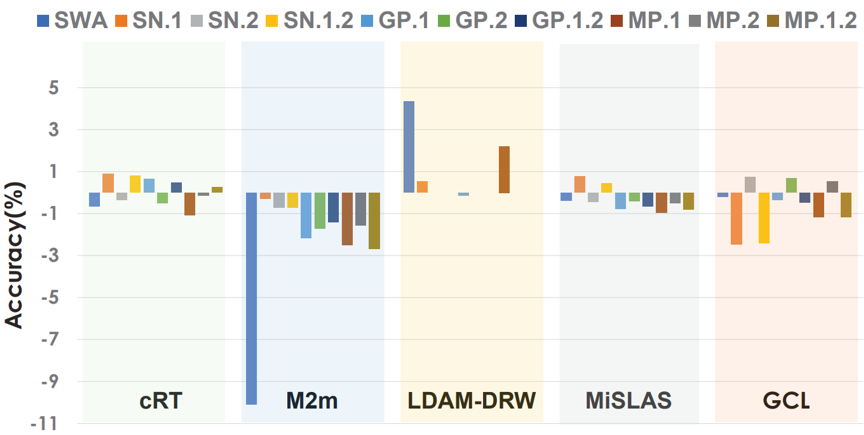
图2 简单应用平坦化方法于长尾学习模型的效果。其中数字表示在不同阶段应用平坦化方法,例如SN.1表示仅在第一阶段应用SN。该实验结果在CIFAR100-LT(不平衡率为100)评估得到。
为寻找对于长尾学习模型更有效的平坦化方法,本文基于谷歌在2021年提出的Sharpness-Aware Minimization(SAM)鲁棒优化算法对模型参数扰动下的泛化误差进行了分析,利用PAC-Bayesian理论以及数据源域(S: source domain)和目标域(T: target domain)的独立同分布假设,推导得到如下泛化误差上界:

上述不等式右侧为关于扰动半径ρ的凸函数,当其取极值即达到最小泛化上界时,ρ和ε的近似表达式为:
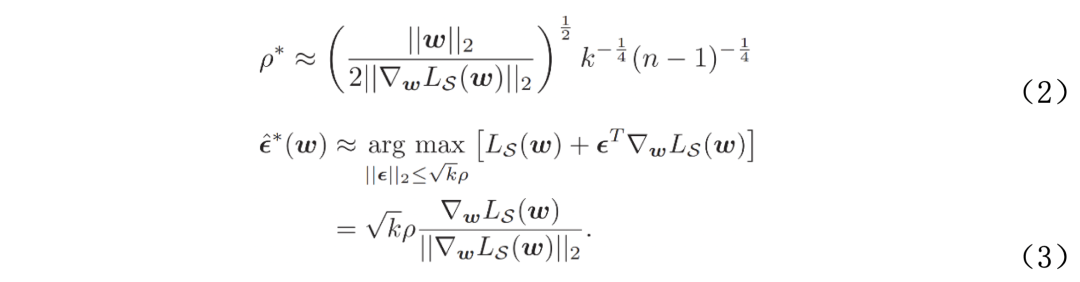
上述近似表达式建立了模型扰动参数和泛化误差的最优上界的联系,为提出本文方法CC-SAM提供了理论依据。
2. 方法
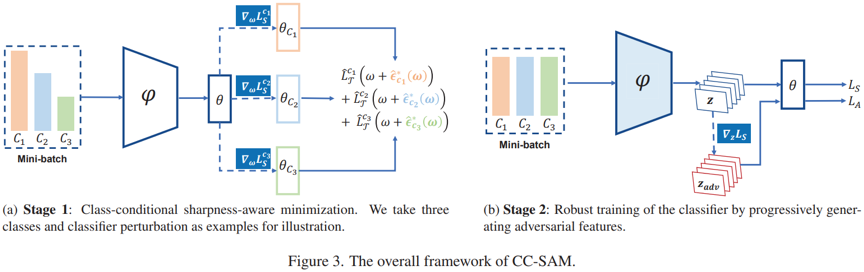
图3 以cRT为基础框架的CC-SAM算法框架。
前述理论分析可知,我们可以通过优化(1)式右侧的泛化误差最优上界来保证模型的泛化性,该上界与样本数量n呈负相关。另一方面,尽管长尾学习不满足数据源域(S)和目标域(T)的标签分布一致性ps(y)=pt(y),但仍可假设两者对于给定类别的样本的条件分布相同ps(x|y)=pt(x|y)。因此,上述(1)(2)(3)式虽然对于长尾数据集整体失效,但对于每个单独类别仍然适用:
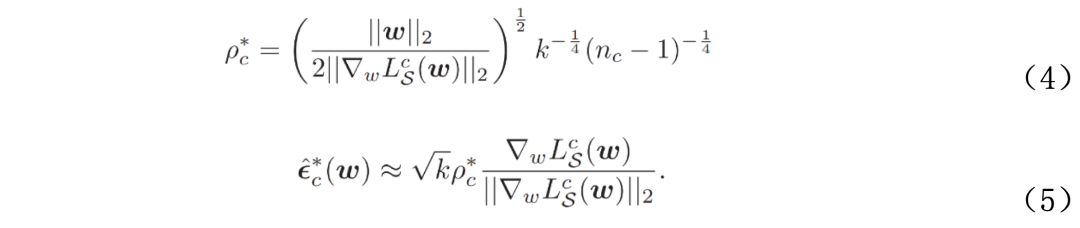
由上述公式即可得到本文所提出的CC-SAM算法框架(如图3所示)。在表征学习阶段(Stage 1),分别计算各个类别的梯度,得到对应的模型参数扰动ε^*ci(w),并根据(1)式优化扰动后的损失函数L^T(w+ε^*ci(w))。在分类器调整阶段(Stage 2),本文进一步采用了对抗训练方式,即生成特征层对抗样本以实现鲁棒混合训练:


3. 实验
在主流长尾识别数据集CIFAR10-/100-LT,Places-LT, ImageNet-LT, iNaturalist2018上的广泛实验均证明了我们方法的有效性。

04
No One Left Behind: Improving the Worst Categories in Long-Tailed Learning
作者:杜映潇,吴建鑫
单位:南京大学计算机软件新技术国家重点实验室
邮箱:
duyx@lamda.nju.edu.cn
wujx2001@gmail.com
论文:
https://arxiv.org/abs/2303.03630
1. 引言
与使用样本数量分布均匀的数据集训练得到的分类模型相比,在长尾图像识别任务中使用不均衡的训练集得到的模型,其各类别之间的准确率彼此相差很大(如图表1所示)。该领域现有的评价指标除了汇报总体准确率以外,一般还会按照训练图片的数目将所有类别划分为Many、Medium和Few三个子类,并汇报模型在这三个子类上各自的平均准确率。本文认为,使用这样的方式来衡量模型的优劣将使得某些类别不可避免地被忽略掉。
在均衡的测试集上,总体准确率是各类别准确率的算术平均,而由于算术平均这一指标对小数字并不敏感,因此即使某一类别准确率非常低,总体准确率仍然可能很高。另外一方面,从图表1中也不难看出,一些位于Many和Medium中的类别的准确率也比较低。事实上本文也发现,虽然近年来该领域的多项研究逐步地提升了模型在测试集上的总体准确率(即算术平均),但模型在表现最差类别上的性能却依然很低,这表明有类别被忽略了。如表格1所示,现有方法根据总体准确率(mean accuracy)得到的排序结果和根据表现最差类别的准确率所得到的排序结果差异极大。
本文认为,模型应该更关注提升表现最差类别的性能。这一指标难以优化, 但各类别准确率的调和平均或几何平均是它的有效近似。具体来说,本文提出了一个简单的插件式扩展方法,通过使用本文提出的GML损失重新训练现有模型的线性分类器部分,便能够提升模型表现最差类别的准确率。本文还提出了一个简单的集成技巧,在预测时能同时利用起新旧两个模型,进一步提升模型性能。

图1 使用不均衡度为100的CIFAR100数据集训练得到的模型各类别准确率
表1 现有方法在不均衡度为100的CIFAR100数据集上训练得到的模型表现最差类别的准确率和总体准确率

2. 方法概述
本文提出了一个简单的插件式扩展方法,其训练流程分为三步,首先利用任意现有方法训练得到模型,然后固定住该模型的骨干网络部分,利用本文提出的GML损失微调分类器,最后可以使用本文提出的集成技巧将新旧两个模型同时利用起来进行预测。
在均衡的数据集上,总体准确率的本质就是各类别准确率的算术平均,而由于算术平均对小数字不敏感,因此以其为优化目标会导致部分类别被忽略。本文因此提出可以使用各类别准确率的调和平均作为优化目标,但因为调和平均的定义涉及倒数,不便于直接优化,本文进一步提出在优化时可以使用同样对小数字敏感的几何平均作为替代。对于各类别准确率r1,r2,...,rc的几何平均,做一个简单的对数变换可以得到:
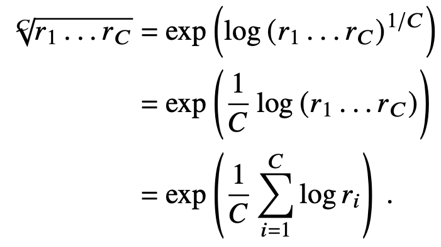
本文提出的GML损失如下所示:
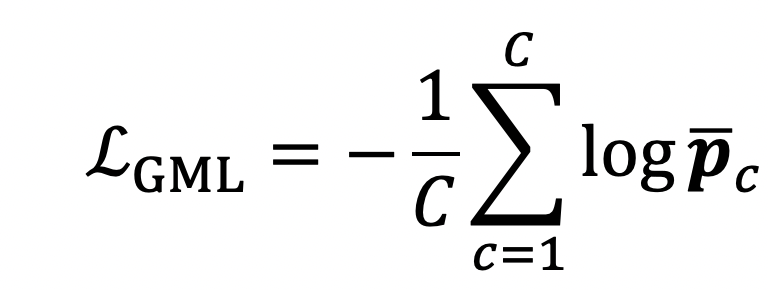
其中$\bar p_c$是模型对当前batch中所有真实类别为的样本,给出的其属于类别的概率(即softmax的输出)的平均值,可以被看作是类别的准确率的替代。所以
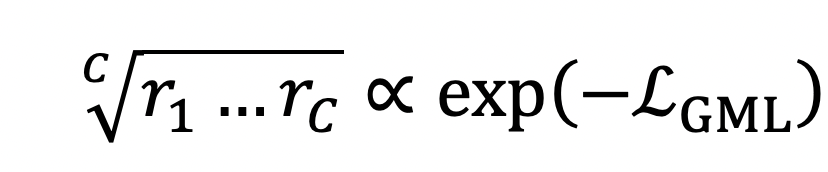
换句话说,训练时最小化GML其实就是在最大化训练集上各类别准确率的几何平均。
另外,本文提出的集成技巧非常简单,本质上就是将新旧两个模型的预测结果在校准后进行了简单的平均。进行集成的主要动机在于本文发现使用GML微调后的模型,部分之前准确率较高的类别性能有所下降,因此希望通过集成让两个模型能够取长补短。
3. 实验结果:
本文在三个基准数据集上进行了测试,部分实验结果如下所示。
从表格2可以看出,在保持总体准确率大致不变的情况下,本文方法能够大幅提升表现最差类别的准确率。
表格3表明将GML方法做为插件添加到多种方法中后,均可有效提升表现最差类别的准确率,从而验证了本文方法的适用性。
最后,图表2展示了CIFAR100数据集(不均衡比例100)上在使用GML方法之前和之后的每类别准确率,可以发现使用GML微调后的模型最差类别的性能确实上升了,各类别准确率分布得更均匀了,从而达到了本文标题中设置的目标:No One Left Behind: Improving the Worst Categories in Long-Tailed Learning.
表2 在不均衡度为100的CIFAR100上的实验结果,表中部分结果表示了星号(*),表示其表现最差类别的准确率为0,所示数值为在每个类别的准确率上加上0.001后计算得到的结果,以避免几何或调和平均为0

表3 验证GML适用性的实验结果
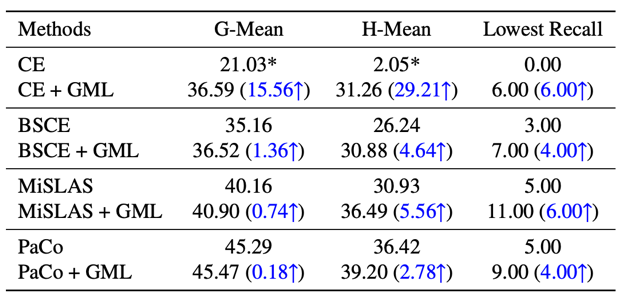
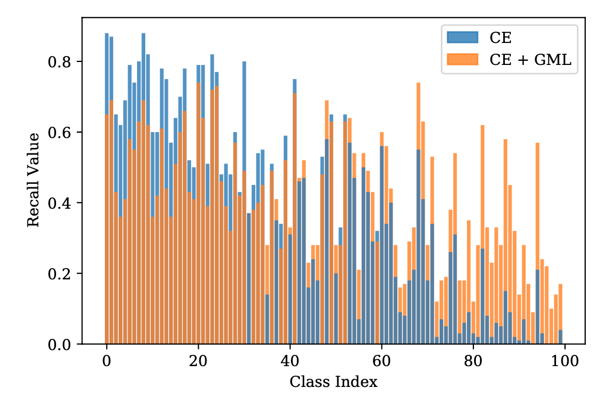
图2 对各类别准确率的可视化结果。可以发现使用GML微调后的模型最差类别的性能上升了,各类别准确率分布得更均匀了
05
Visual-Language Prompt Tuning with Knowledge-guided Context Optimization
作者:姚涵涛1,张蕊2,徐常胜1
单位: 1 中国科学院自动化研究所; 2 中国科学院计算技术研究所
邮箱:
hantao.yao@nlpr.ia.ac.cn;
zhangrui@ict.ac.cn;
csxu@nlpr.ia.ac.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/html/Yao_Visual-Language_Prompt_Tuning_With_Knowledge-Guided_Context_Optimization_CVPR_2023_paper.html
代码:
https://github.com/htyao89/KgCoOp
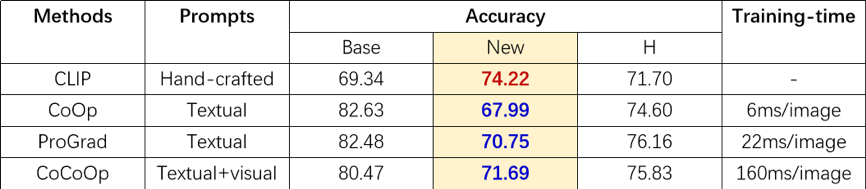
视觉语言模型的目的是对齐图像特征和文本特征或者融合图像特征和文本特征,代表性的视觉语言模型有CLIP, Flamingo,ALIGN等。其中CLIP是最具有代表性的一个工作。CLIP模型由一个文本编码器和一个视觉编码器组成。对于给定的图像-文本对,利用视觉编码器提取视觉特征,并利用文本编码器提取文本特征,用对比损失函数来约束视觉特征和文本特征的一致性实现将两种模态数据映射到统一表达空间的目的。由于CLIP是利用4亿个图像-文本对进行模型的训练,训练后的模型具有很好的泛化性。因此CLIP模型经常被当作预训练模型用于下游的视觉文本任务。为了有效的迁移视觉语言模型中包含的百科知识到下游任务,提示学习(Prompt Tuning)被广泛用于新知识的学习。在CLIP中,固定的模板(“a photo of {}”)被用来建模类别的文本空间描述并用于预测。不同于CLIP,基于提示学习的文本优化(Context Optimization)近来被用于建模新数据的有效类别特征空间。但是,目前的基于提示学习的文本优化会过拟合于训练域而在未知测试域上具有较差的性能(表1)。
表1 相比于预训练的CLIP模型,已有算法在未知域(New)上存在严重的性能退化
通过对于未知测试域上性能的退化程度分析,我们发现这些性能退化程度与对应的文本描述空间的距离正相关,如图1所示,某一个域上面的文本类别空间的距离越大,性能退化越严重,如DTD。
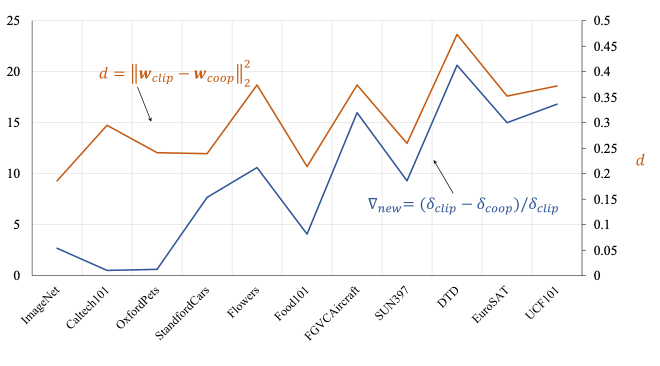
图1 未知域上的性能退化程度(蓝线)与文本空间的距离(橙线)正相关
基于上述讨论,我们提出了百科知识引导的提示学习算法。如图2所示,在传统的对比损失基础上,通过一个正则化约束Lkg来约束原始的文本特征空间wclip和基于提示学习的文本特征空间w之间的距离。由于这个距离是与未知域上性能的退化程度正相关,距离越大,性能退化约严重。因此,通过减小这个距离可以提升模型对于未知域的泛化能力。
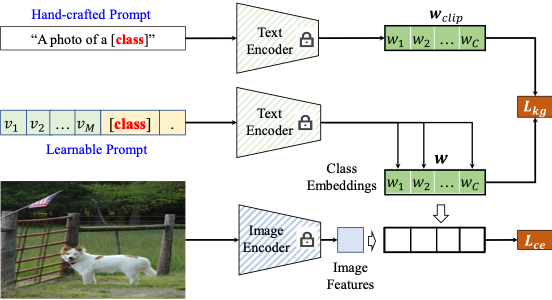
图 2 百科知识引导的提示学习
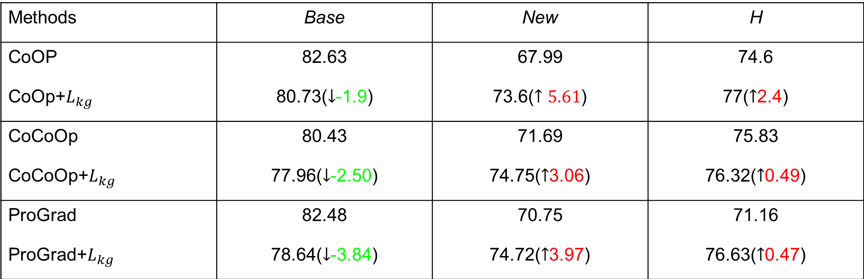
研究动机的合理性:如表2所示,距离Lkg越小,性能H越大。

算法的即插即用性:把提出的Lkg约束加在已有的三种经典的提示学习CoOp, CoCoOp, 和ProGrad上,都进一步提升了它们的性能。
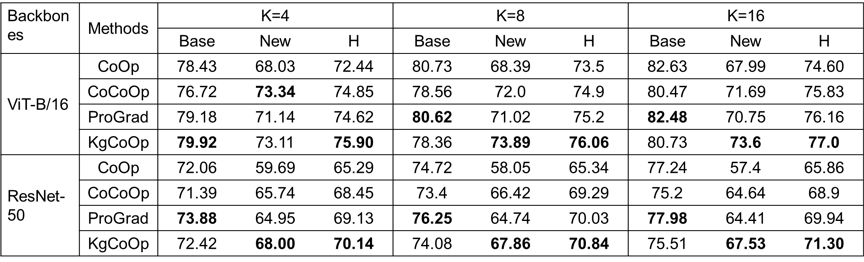
KgCoOp泛化性实验:两种网络结构(ViT-B/16, ResNet50)和三种K-shots(4/8/16)下的结果验证了算法的高泛化性。
06
Learning Conditional Attributes for Compositional Zero-Shot Learning
作者:王庆圣、刘灵峤、景晨琛、陈昊、梁国强、王鹏、沈春华
单位:
西北工业大学计算机学院与宁波研究院;
阿德莱德大学计算机学院;
浙江大学计算机学院
邮箱:
wqshmzh@mail.nwpu.edu.cn ;
peng.wang@nwpu.edu.cn
论文:
https://arxiv.org/pdf/2305.17940.pdf
代码:
https://github.com/wqshmzh/CANet-CZSL
介绍:组合式零样本学习(Compositional Zero-Shot Learning,CZSL)任务用于识别图像所属的组合,这些组合由基本概念单元组成,可以是属性和物体组合成的二元属性-物体对,例如属性“潮湿的”和物体“狗”可以组合成“潮湿的-狗”,并且被识别的组合在训练时没有出现过。举例来讲,令模型在训练时见过“潮湿的-狗”和“干燥的-猫”,一个性能良好的模型应该能够识别出“干燥的-狗”和“潮湿的-猫”。该任务难点之一在于如何建模与物体关系密切的属性概念。对此,我们将图像对其所属组合的概率使用多变量条件概率公式进行分解,发现属性概念应该以图像所属的物体和图像本身作为条件进行建模,并且提出一种含属性超学习器和属性基学习器的属性学习框架,如左图所示。通过对属性进行条件化编码,模型能够为从可见组合到未见组合的泛化过程产生更灵活的属性表征,实验结果证明这种条件属性学习方法能够带来更好的分类性能.

方法:假设模型将图像i识别为属性a*和物体o*,则识别概率可以写为以i为条件的条件概率P(a*, o*|i),采用多变量条件概率公式将其分解为两个单标签分类概率,可得:P(a*, o*|i)=P(a*| o*,i) P (o*|i),图像属于属性a*的概率取决于识别出的物体o*与图像本身。
网络结构如下图。 首先,计算映射到物体空间的图像视觉表征ωo(x)与所有物体词向量vo的余弦距离,得到识别出的物体o*,并提取其词向量vo*;然后,定义融合网络P,得条件表征β = P(cat(vo*, x)),cat()表示通道连接操作;其次,定义属性超学习器H与属性基学习器G,将条件表征β输入H,生成G的参数矩阵;最后,将所有属性的词向量输入G,得到以vo*和x为条件的属性表征ea,计算映射到属性空间的视觉表征ωa(x)与所有条件属性表征ea的余弦距离,对ωa(x)与ea进行对齐。
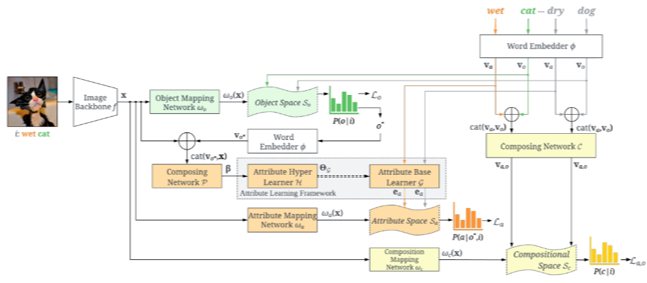
虽然属性表征会受到物体和图像的影响,但是物体也会受到属性的影响,例如“苹果”和“切开的-苹果”在视觉上也不同,我们将每个组合中的属性和物体两者的词向量做通道连接,并输入给另一个融合网络C,得到组合的语义表征va,o,计算映射到组合空间的视觉表征ωc(x)和所有va,o的余弦距离。在训练时,将三者余弦距离均乘一个温度系数后计算交叉熵损失La、Lo和La,o,总损失为0.5*(La+Lo)+La,o;测试时,计算P =(1+余弦距离)*0.5归一化到0到1区间,最终分类分数为:
![]()
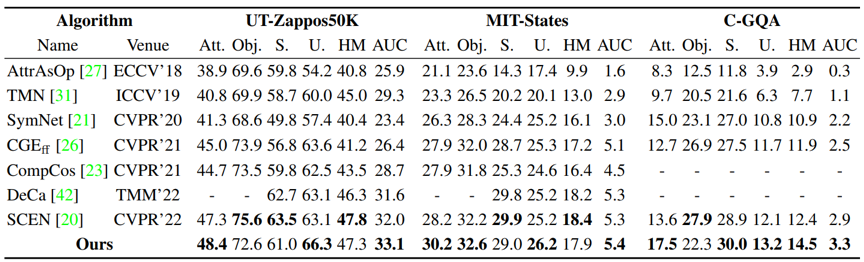
实验:采用广义零样本图像分类设置,在UT-Zappos50K、MIT-States和C-GQA数据集上的结果表明学习条件属性表征可带来分类性能的提高。

 京公网安备11010802017125号
京公网安备11010802017125号