
2023年论文导读第十六期
【论文导读】2023年论文导读第十六期
CCF多媒体专委会 2023-08-15 20:04 发表于山东


论文导读
2023年论文导读第十六期(总第八十二期)
目 录
|
1 |
Open-Category Human-Object Interaction Pre-training via Language Modeling Framework |
|
2 |
Minimizing Maximum Model Discrepancy for Transferable Black-box Targeted Attacks |
|
3 |
SCPNet: Semantic Scene Completion on Point Cloud |
|
4 |
Exploiting Completeness and Uncertainty of Pseudo Labels for Weakly Supervised Video Anomaly Detection |
|
5 |
LG-BPN: Local and Global Blind-Patch Network for Self-Supervised Real-World Denoising |
01
Open-Category Human-Object Interaction Pre-training via Language Modeling Framework
作者:郑思鹏,许博深,金琴
单位:中国人民大学
邮箱:
zhengsipeng@ruc.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Zheng_Open-Category_Human-Object_Interaction_Pre-Training_via_Language_Modeling_Framework_CVPR_2023_paper.pdf
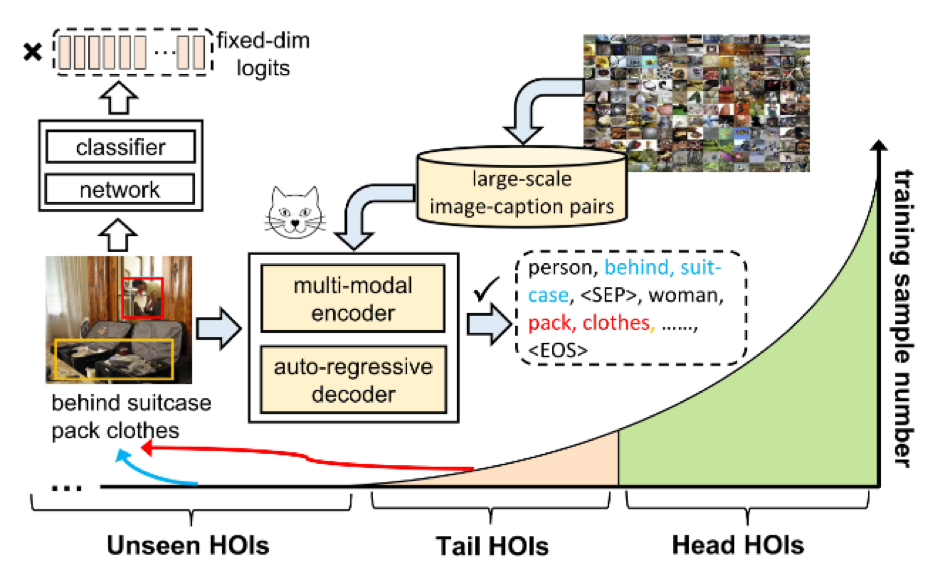
在日常生活中,人类具有识别各种复杂人-物关系的能力,并且有办法将他们用多种方式进行表达,但是,类似的开放类别预测能力一直都是人-物交互(human-object interaction, HOI)任务的瓶颈,我们认为,这主要由两个原因导致:预测方式的不灵活和监督数据的缺乏。首先,早先的工作将HOI视为一个类别固定的分类任务,它们将图片映射为维度固定的logit,这限制了模型进一步识别新类别的能力。受语言生成模型的启发,如下图所示,我们将HOI任务重构为一个序列生成的问题,以此使得模型能够具有识别大量开放类别的能力。
其次,模型识别丰富的HOI类别需要大量的标注数据,但由于HOI标注成本较高实现这点并不现实。事实上,如图所示,大部分类别往往标注稀缺(tail class)或者干脆就没有标注(unseen class)。近来,研究人员探索了许多无监督或者自监督(比如预训练)的方法来解决数据稀缺的问题,因此,一个直观的思路是利用预训练来克服HOI监督数据缺失的挑战。但是,直接使用弱监督甚至无监督数据实现HOI预训练是件困难的事情,原因在于一个HOI模型必须有能力精确定位到图片上的交互区域,并且识别大量人类活动之间细微的差别,而这依靠非监督数据很难办到。
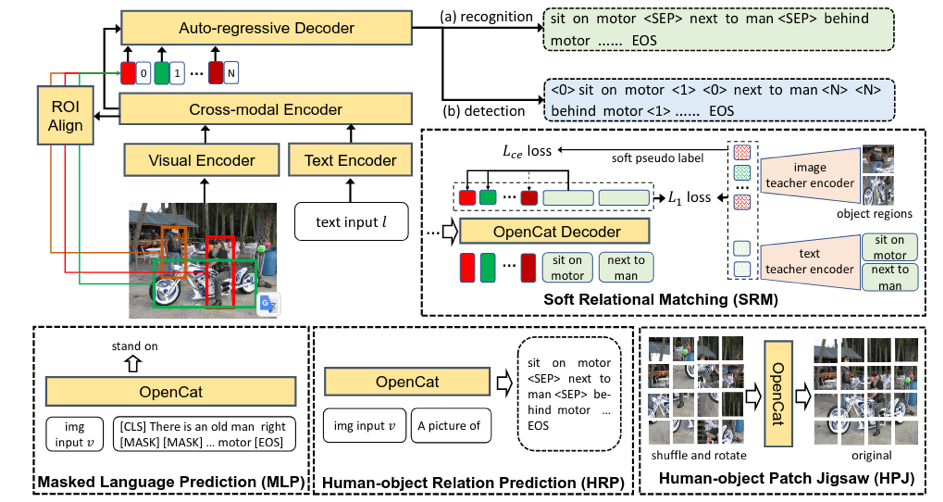
为此,我们设计了若干针对HOI学习的预训练任务,如图2所示,分别是:masked language prediction (MLP),human-object relation prediction (HRP),human-object patch jigsaw (HPJ)以及soft relation matching (SRM)。由于弱监督数据中不包含有位置信息,我们单独设计了SRM任务以此来学习人和物体在图像上的匹配关系,该任务从一个训练好的视觉语言模型中进行知识迁移,从而在物体的检测框和从图像文字描述中抽取的HOI三元组之间构建伪标签。
为了进行预训练,我们从几个现有的数据集中收集了大量和HOI相关的弱监督数据,如下表所示,我们所收集的数据在规模和类别数量上远远超出之前的有监督数据。特别地,利用数据中丰富的类别标签,我们的模型得以学习到针对所谓“开放类别”的识别能力。

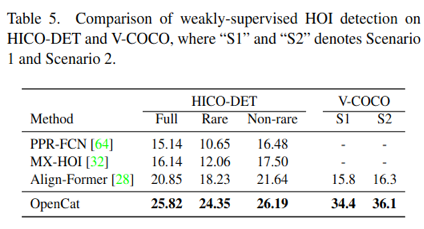
下面表格中的一系列实验表明,我们设计的基于生成的HOI预训练模型,在各个少样本、零样本、弱监督等实验设定下都表现出良好的实验性能,证明了我们所提出的OpenCat模型的有效性。


02
Minimizing Maximum Model Discrepancy for Transferable Black-box Targeted Attacks
作者:赵安琪,褚童,刘亚豪,李文*,李晶晶,段立新
单位:电子科技大学,电子科技大学(深圳)高等研究院
邮箱:
zhaoanqiii@gmail.com
uestcchutong@gmail.com
lyhaolive@gmail.com
liwenbnu@gmail.com
lxduan@gmail.com
lijin117@yeah.net
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Zhao_Minimizing_Maximum_Model_Discrepancy_for_Transferable_Black-Box_Targeted_Attacks_CVPR_2023_paper.pdf
*通讯作者
1. 引言
对抗样本通过在输入数据中添加微小且人类无法察觉的噪声,来欺骗深度学习模型的预测结果。由于对抗样本具有迁移性,对抗样本的攻击性能可以迁移至不同的模型,这也就意味着攻击者可以在对于目标模型的模型结构,参数等信息一无所知的情况下进行攻击,这种攻击方式就叫做黑盒迁移攻击。目前主流做法通常会在替代模型上制作对抗样本然后用来攻击未知的黑盒模型。尽管这种方式已经取得了不错的成绩,但依然缺少保证攻击成功效果的理论分析。
2. 方法概述
为了进一步提升对抗攻击样本的定向迁移性,本文首先提出了黑盒定向攻击的泛化误差界,通过该误差界,可以得知攻击黑盒模型的误差依赖于对抗样本在替代模型上的经验攻击误差和替代模型与目标黑盒模型之间的模型差异。虽然黑盒模型无法获取,但该模型差异可以被假设空间 中的最大模型差异所约束,从而可以通过优化该最大模型差异来减小对抗样本在未知黑盒模型上的泛化误差。
定理1: 对于任意∂≥0, 以1-∂的概率, 对于黑盒模型hb∈H以及替代模型hs∈H,有如下的泛化界:

在此h和h'是从H采样的两个分类器, \hat{ℇz}是经验误差, Ω是其中一个子项。由此可知,对于模型变化鲁棒的对抗样本不仅需要攻击成功替代模型,还需要能够最小化假设空间H中的最大模型差异,由此,我们设计了一种基于最小化最大模型差异的攻击方法。如图1所示,在训练时的每轮迭代中,需要交替的训练判别器和生成器,通过对抗的方式去寻找假设空间当中的最大模型差异。具体来讲,在训练判别器的时候,固定生成器,一方面最小化替代模型在干净样本的分类误差,以保证替代模型的分类能力,另一方面最大化两个模型对于生成器产生的对抗样本的差异。在训练生成器的时候,固定判别器,然后训练生成器使得对抗样本能成功攻击两个判别器D1和D2,与此同时希望产生的对抗样本能最小化两个模型的模型差异。

图1 M3D方法流程图
图2是本方法一个直观的示意图,之前的方法主要集中于在一个固定的替代模型上生成对抗样本, 然而这些对抗样本即使能攻击成功替代模型,却可能因为替代模型和黑盒模型之间的模型差异而导致攻击失败。本文的方法在训练过程中对抗样本需要同时攻击成功两个替代模型,并且这两个替代模型需要保持对生成的对抗样本的差异尽可能的大。通过生成器和判别器的对抗,能够找到对于模型变化鲁棒的对抗样本,从而提高在未知黑盒模型上的攻击性能。

图2 M3D方法示意图
3. 实验
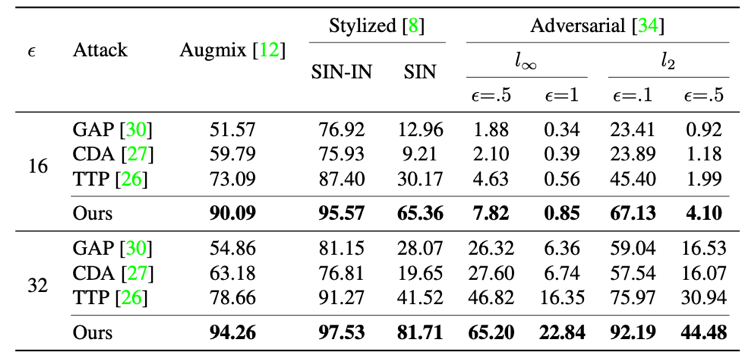
本文利用不同的模型在ImageNet数据集上进行了大量的实验,实验结果证明了本文的方法相比于其他业界最优方法性能有较大的提升,特别是当替代模型和黑盒模型结构差异巨大的时候。
表1 攻击普通模型的结果
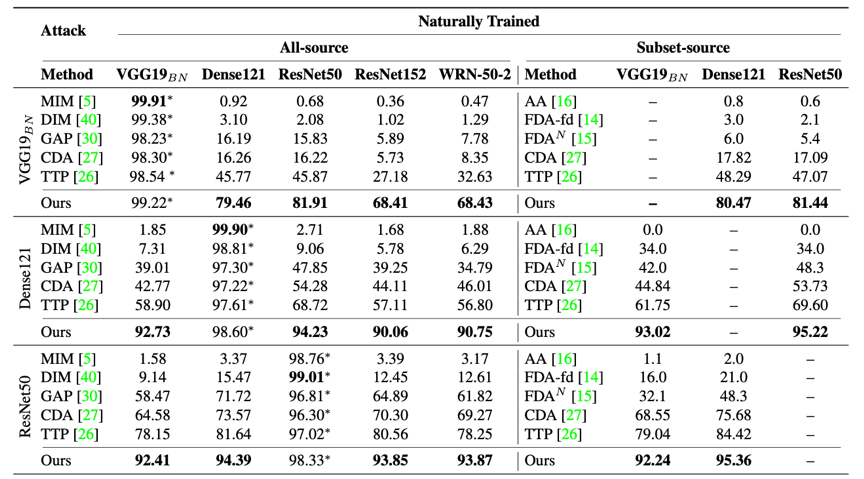
表2 攻击带防御模型的结果
03
SCPNet: Semantic Scene Completion on Point Cloud
作者:夏朝阳,刘有权,李鑫,祝新革,马月昕,李怡康,侯跃南,乔宇
单位:上海人工智能实验室
邮箱:
xiazhaoyang@pjlab.org.cn;
houyuenan@pjlab.org.cn;
liyikang@pjlab.org.cn;
qiaoyu@pjlab.org.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/html/Xia_SCPNet_Semantic_Scene_Completion_on_Point_Cloud_CVPR_2023_paper.html
代码:
https://github.com/SCPNet/Codes-for-SCPNet
语义场景补全旨在从不完整、稀疏的观测中推断场景的几何形状和语义,是三维场景理解的一个关键组成部分。室外大尺度交通场景的语义场景补全任务存在很多挑战,包括:单帧激光雷达点云通常是稀疏不完整的;单帧激光雷达点云中包含大量不同尺度的对象;现有公开数据集的语义场景补全标签中存在运动对象拖影问题。
针对上述问题,我们提出以下三种解决方案:1)重新设计补全子网络,提升语义场景补全任务中对不同尺度对象,尤其是对小尺度目标和远距离目标的补全性能;2)设计让单帧网络从多帧模型蒸馏有用知识的密集到稀疏知识蒸馏方法,提升输入单帧点云的语义场景补全表现;3)设计一种简单有效的补全标签修正策略,可以使用现有的全景分割标签来去除补全标签中运动对象的拖影,大大提高对运动对象的语义场景补全性能。
具体来说,我们首先对补全子网络进行全面设计。采用补全优先原则,让补全模块直接处理原始体素特征。此外,我们避免使用下采样操作,因为它们不可避免地会引入信息丢失,并对那些小物体和拥挤场景造成严重的补全和分类错误。为了提高不同尺度对象的补全质量,我们设计了具有不同卷积核大小的多路径块(Multi-Path Blocks,MPB),它聚集了多尺度特征并可以充分利用丰富的上下文信息。
如图2所示,我们的SCPNet由两个子网络组成,即补全子网络(图3)和分割子网络。提出对构建强大的补全子网络至关重要的设计原则,包括保持稀疏性,无下采样和融合多尺度特征。分割子网络建立在Cylinder3D的基础上,并进行了一些小的修改。
其次,为了对抗稀疏和不完整的输入信号,我们让单帧学生模型从多帧教师模型中提取知识。然而,模仿每个点/体素的概率知识会带来边际收益。相比而言,我们建议提取成对相似性信息。考虑到特征的稀疏性和无序性,我们使用它们的索引对齐特征,然后强制学生特征和教师特征的成对相似图之间的一致性,使学生从教师的关系知识中受益。由此产生的密集到稀疏知识蒸馏(Dense-to-Sparse Knowledge Distillation)目标被称为DSKD,它是专门为场景补全任务设计的。
从图4中可以明显看出,多帧输入包含场景中更多的点,并且更容易识别物体,可以明显降低补全难度。补全难度会随着输入点云帧的数量增加而降低。因此,我们构建了以更密集的点云作为输入并获得更好补全表现的多帧教师网络。
最后,为了解决补全标签中运动对象的长拖影,我们提出了一种简单而有效的标签修正策略。核心思想是利用现有的全景分割标签去除补全标签中运动对象的长拖影。修正后的补全标签更加准确可靠,大大提高了模型在运动对象上的补全质量。我们设计的补全标签修正方法的伪代码如表1所示。如图5所示,所提出的标签修正方法可以有效去除运动对象的长拖影,使补全标签更加准确。
SCPNet在SemanticKITTI语义场景补全挑战赛中排名第一,在SemanticKITTI测试集上取得了36.7mIoU,超过了有竞争力的S3CNet[3] 7.2 mIoU。SCPNet在SemanticPOSS数据集上的表现也优于现有的补全算法。与直接模仿教师特征的FitNets相比,我们提出的DSKD方法可以带来2.8 mIoU的提升,显示了所提出的基于关系的蒸馏算法的有效性。本文提出的补全标签修正方法可以分别为汽车、人、骑自行车的人和骑摩托车的人带来8.1、24.5、26.1和17.6的IoU改进,有力地证明了标签校正算法的有效性。
表1 补全标签修正的伪代码

getInd(A, b): 获得数值b在矩阵A中的索引
bound(M): 获得三元数组的边界
difference(A, B): A减去B的差集
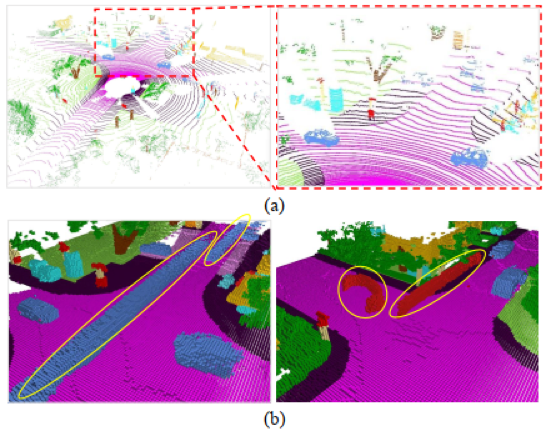
图1 SemanticKITTI数据集语义场景补全任务中存在的挑战(a)稀疏和不完整的输入、大量不同尺度的对象(b)运动对象的固有标签噪声

图2 SCPNet的框架图

图3 补全子网络示意图

图4 单帧点云和多帧拼接点云的对比

图5 标签修正方法处理前后的补全标签示例
04
Exploiting Completeness and Uncertainty of Pseudo Labels for Weakly Supervised Video Anomaly Detection
作者:张晨1,2,李国荣3*,齐元凯4,王树徽5, 6, 卿来云3, 黄庆明1, 2, 3, 5, 杨明玄7, 8
单位:
1中国科学院信息工程研究所, 2 中国科学院大学网络空间安全学院, 3 中国科学院大学计算机科学与技术学院, 4 阿德莱德大学澳大利亚机器学习研究所, 5 中国科学院计算技术研究所, 6 鹏城实验室, 7 加利福尼亚大学默塞德分校, 8 延世大学
邮箱:
zhangchen@iie.ac.cn,
liguorong@ucas.ac.cn,
qykshr@gmail.com,
wangshuhui@ict.ac.cn,
lyqing@ucas.ac.cn,
qmhuang@ucas.ac.cn,
mhyang@ucmerced.edu
论文:
https://openaccess.thecvf.com/content/CVPR2023/html/Zhang_Exploiting_Completeness_and_Uncertainty_of_Pseudo_Labels_for_Weakly_Supervised_CVPR_2023_paper.html
代码:
https://github.com/ArielZc/CU-Net
*通讯作者
弱监督视频异常检测旨在仅使用视频级标签来识别视频中的异常事件。 最近,两阶段自训练方法通过生成伪标签并使用这些伪标签改进异常分数取得了显著的性能提升。 然而这些方法在伪标签生成阶段(第一阶段)忽略了异常事件的完整性,且在第二阶段未考虑生成的伪标签的不确定性。伪标签通常是包含噪声的,直接使用它们来训练最终的分类器可能会影响其性能。由于伪标签起着至关重要的作用,我们提出了一个通过利用完整性和不确定性属性来增强自训练的框架。 具体地,我们首先设计了一个具有多样性损失的多头分类模块(每个头充当一个分类器),同时最大化各个头之间预测伪标签的分布差异, 使伪标签覆盖尽可能多的异常事件。然后,我们设计了一种迭代式不确定性感知的伪标签改进策略。大量的实验结果表明,所提出的方法在三个基准数据集上取得了较优的性能。
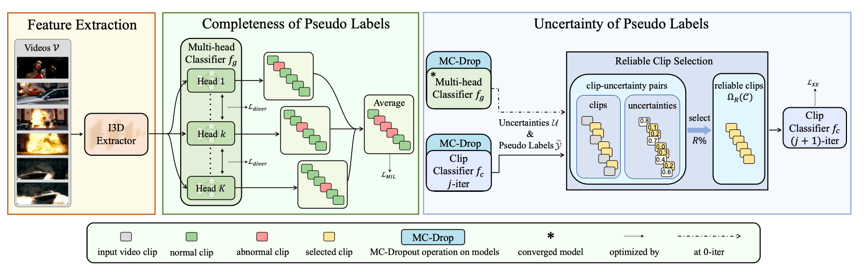
图1 方法总体框架
所提方法的框架如图1所示,包括两个阶段: (1) 完整性增强的伪标签生成器:首先,我们使用预训练的 3D CNN 来提取视频特征。 然后,这些特征被输入到受多样性损失约束的多头分类器中,鼓励模型检测完整的异常事件。 同时,使用多示例排名损失来约束异常片段的异常分数大于正常片段的异常分数。 (2) 迭代式不确定性感知伪标签改进:在第一次迭代中,我们从第一阶段的多头分类器获得初始片段级伪标签,并通过蒙特卡罗 Dropout 计算其不确定性。 然后我们根据不确定性选择可靠的片段来训练新的片段分类器。 在剩余的迭代中,使用新的片段分类器来更新伪标签。
如图2所示, 我们将UCF-Crime、TAD 和 XD-Violence 数据集上的异常评分结果进行可视化,证明了所提方法的有效性。图 2(a) 和图 2(b) 表明我们的方法对于UCF-Crime数据集中的多段异常事件(Explosion)和TAD数据集中的长时异常事件(PedestrianOnRoad)可以预测相对准确的异常分数。 图2(c)和图2(d)展示了XD-Violence数据集中异常事件(Fighting)和正常事件的异常分数,我们的方法可以完整检测异常视频中的两个异常区间,并为正常事件预测接近0的异常分数。

图2 异常分数可视化结果
05
LG-BPN: Local and Global Blind-Patch Network for Self-Supervised Real-World Denoising
作者:王子淳1,付莹1,刘吉2,张宇伦3
单位: 1北京理工大学,2百度, 3苏黎世联邦理工学院
邮箱:
xiaoding12345@126.com
fuying@bit.edu.cn
liuji04@baidu.com
yulun100@gmail.com
论文:
https://arxiv.org/abs/2304.00534
代码:
https://github.com/Wang-XIaoDingdd/LGBPN
SIDD数据集:
https://www.eecs.yorku.ca/~kamel/sidd/dataset.php
DND数据集:
https://noise.visinf.tu-darmstadt.de/
基础背景:图像去噪是图像处理领域中的一个基础问题。近年来,基于学习的方法显示出了显著的进步,但却依赖大量的标记图像对进行训练。这不能简单地通过合成加性白高斯噪声(AWGN)对来解决: AWGN 和真实的噪声之间的巨大差距,严重降低了其在真实场景中的泛化性能。另一方面,尽管人们在收集真实世界的数据集方面做了一些努力和尝试,但收集过程受到严格控制的拍摄条件以及大量劳动的阻碍。例如,拍摄干净图像在运动的动态场景中是不可用的。
无监督去噪方法:为了缓解对大规模配对数据集的依赖,无监督去噪方法已经引起了越来越多的关注。一些开拓性的工作,如Noise2Noise,使用成对的噪声观测进行训练,消除了对干净图像的需求。但是在同一场景下获得这样的噪声对还是不太可行的。因此,人们希望从单个,而不是成对的有噪声图像中学习。例如,盲点网络通过利用邻近的像素来恢复干净的像素,从而能够在单张有噪声图像上进行训练。
真实噪声无监督去噪方法&动机:尽管上述方法在简单的噪声上取得了很好的效果,但仍然不适合真实的噪声,因为其噪声分布极其复杂,并呈现出强烈的空间相关性。因此,人们提出了其他方法用于真实图像自监督去噪。例如,CVF-SID基于一个循环的多变量函数将噪声从噪声图像中分离出来。但它假定真实噪声是空间不变的,忽略了空间相关性,与真实的噪声分布相矛盾。另外一些方法,如AP-BSN结合了像素下采样(PD)和盲点网络 (BSN)。如图1所示,尽管可以利用 PD 来满足盲点网络的噪声假设,但这会对局部细节造成破坏,从而给采样图像带来伪影。
另外,以前基于卷积的盲点网络无法捕捉长距离依赖,且有限的感受野和推理时的静态权重,都大大限制了它的性能。另外,尽管更先进的盲点网络已经被提出,但基于卷积的盲点网络由于其卷积算子而无法捕捉到长距离的相互作用,在盲点要求下仍会受到有限感受野的约束。
本文方法:首先,对于局部信息,我们引入Densely-Sampled Patch-Masked Convolution。基于真实噪声空间相关性的先验统计,将更多的相邻像素纳入考虑范围,使得网络有一个更密集的感受野,使网络能够恢复更精细的结构,如图2所示。
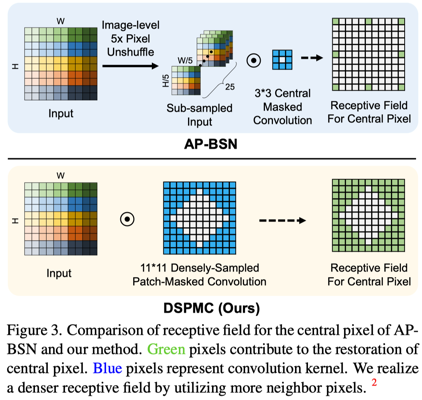
图1
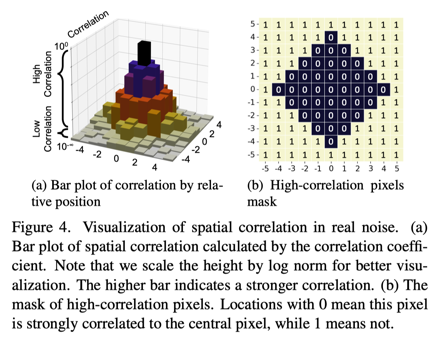
图2
第二,对于全局信息,引入了Dilated Transformer Block,可以更好地利用长距离的相互作用。在特殊的盲点要求下,与以前基于卷积的盲点网络相比,极大地扩大了感受野,允许在预测中利用更多的邻居信息。如图三所示,通过上述两种设计,能够分别充分地利用局部和远距离信息。
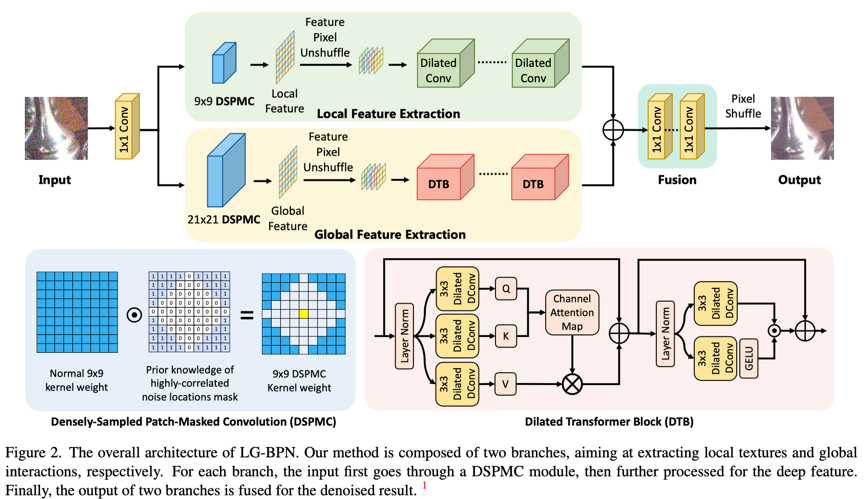
图3
实验结果:实验表明,我们的方法在真实图像去噪上的表现优于其他最先进的无/自监督方法。
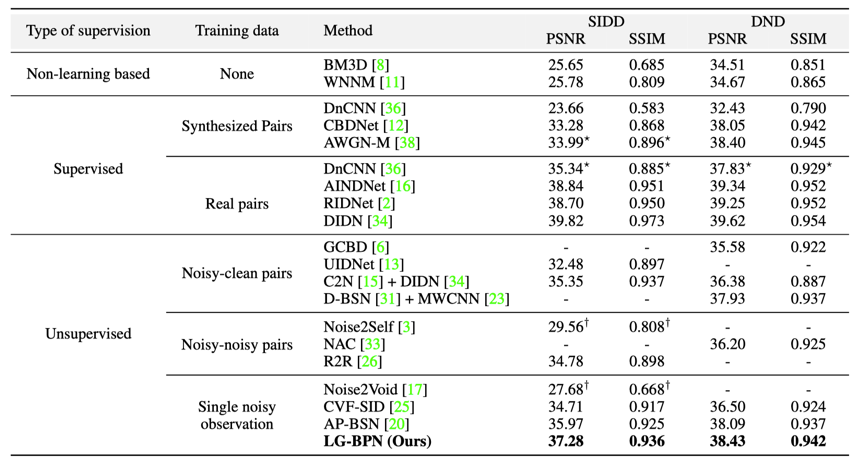
相应的可视化结果也印证了我们的结论。

 京公网安备11010802017125号
京公网安备11010802017125号