
2023年论文导读第十七期
【论文导读】2023年论文导读第十七期
CCF多媒体专委会 2023-08-29 19:02 发表于山东


论文导读
2023年论文导读第十七期(总第八十三期)
目 录
|
1 |
Rethinking and Improving Feature Pyramids for One-Stage Referring Expression Comprehension |
|
2 |
Backdoor Defense via Deconfounded Representation Learning |
|
3 |
Extracting Motion and Appearance via Inter-Frame Attention for Efficient Video Frame Interpolation |
|
4 |
Foundation Model Drives Weakly Incremental Learning for Semantic Segmentation |
|
5 |
DIP: Dual Incongruity Perceiving Network for Sarcasm Detection |
|
6 |
Fine-Grained Categorization From RGB-D Images |
01
Rethinking and Improving Feature Pyramids for One-Stage Referring Expression Comprehension
作者:索伟1,孙梦阳1,王鹏1,张艳宁1,吴琦2
单位:1西北工业大学,2阿德莱德大学
邮箱:
suowei1994@mail.nwpu.edu.cn
sunmenmian@mail.nwpu.edu.cn
peng.wang@nwpu.edu.cn
ynzhang@nwpu.edu.cn
qi.wu01@adelaide.edu.au
论文:
https://ieeexplore.ieee.org/document/9982652
代码:
https://github.com/Suo-Wei/Dynamic_FPN-for-REC
1. 引言
指代表达理解(Referring Expression Comprehension, REC)任务旨在通过自然语言指令定位图像中具有相应语义的区域,其在视觉问答、图像描述和跨模态检索等领域中已被广泛应用。为获得速度和精度之间的平衡,现有的研究通常采用一阶段的研究范式。然而,这些框架大多忽视了多尺度特征的价值,甚至仅依靠单尺度特征定位目标。在本文中,我们聚焦于重新思考和提高特征金字塔(Feature Pyramid Network, FPN)对于一阶段REC任务的影响。通过大量的实验,我们首先证明了目标检测任务中常见的FPN结构对该任务的影响有限,并通过可视化分析揭示了传统结构中存在的语义模糊问题。基于上述洞察,本文提出了一种新的语言引导的FPN结构(Language Guided FPN, LG-FPN)。该方法利用语言门控和联合门控动态分配和选择细粒度信息以消除歧义。一系列对比和消融实验均验证了所提方法的有效性和可靠性。
2. 方法
如图1所示,。针对传统FPN结构导致的语义模糊问题,本文提出了一种简单有效的LG-FPN结构,该方法通过堆叠由语言门控和联合门控组成的路由节点,实现了细粒度信息的动态选择和分配。具体而言,本文首先利用多级特征图构建了一个动态的路由空间,对于每个路由节点,如图1(c)所示,其输入由两部分组成:多级特征图和基于注意机制的语言向量。同时,在每个路由节点内部,多尺度的细粒度信息将利用语言门控进行硬性选择以筛选相应的信息,并通过简单的平均机制聚合多尺度特征图。此外,由于REC是一个多模态任务,本文也设计了一个基于数据依赖的联合门控以进一步的消除语义歧义。

图1 LG-FPN框架示意图
3. 实验
如表1所示,在ReferItGame、RefCOCO、RefCOCO+和RefCOCOg数据集上,相较于现有的一阶段或两阶段策略,我们的方法取得了最优的性能。同时为进一步探索所提方法的有效性,本文将LG-FPN作为一个“即插即用”的FPN模块插入到当前最先进的模型中,结果表明我们的方法能够进一步帮助这些框架提升性能。最后,如图2可视化结果所示,随着深度的增加,LG-FPN方法能够自适应地关注到目标区域中的重要上下文区域,并逐步消除歧义以确定指代目标。
表1 在ReferItGame、RefCOCO、RefCOCO+和RefCOCOg数据集上本文方法和目前主流方法的性能对比结果。
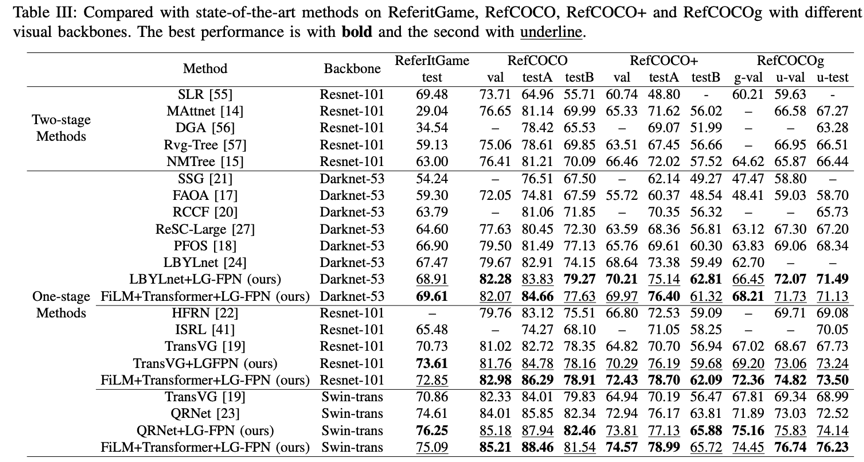

图2 本文提出的LG-FPN结构的推理过程可视化结果。
02
Backdoor Defense via Deconfounded Representation Learning
作者:张载熙1,刘淇1,王志才1,卢泽普1,胡清泳2
单位:1中国科学技术大学,2香港科技大学
邮箱:
zaixi@mail.ustc.edu.cn
qiliuql@ustc.edu.cn
wangzhic@mail.ustc.edu.cn
zplu@mail.ustc.edu.cn
qhuag@cse.ust.hk
论文:
https://arxiv.org/abs/2303.06818
代码:
https://github.com/zaixizhang/CBD
深度神经网络(DNNs)最近被发现容易受到后门攻击的影响。攻击者通过向训练数据集中注入一些有毒样本,嵌入隐藏的后门(backdoor)于DNN模型中。尽管研究者们已经做了大量的努力来检测和清除后门,但仍不清楚是否可以直接从污染数据集中直接训练得到一个无后门(backdoor-free)的干净模型。在本文中,我们首先构建一个因果图来模拟污染数据的生成过程,并发现后门攻击作为混淆因子(Confounder),会在输入图像和目标标签(target label)之间带来虚假的关联,使模型的预测变得不可靠。在因果推理的启发下,我们提出了基于因果的后门防御(Causality-inspired Backdoor Defense),学习去除混淆因子的表征(Deconfounded representation),以实现可靠的分类。具体来说,我们故意训练一个后门模型来捕获混淆效应,另一个干净模型则致力于通过最小化与后门模型的混淆表征之间的互信息和采用逐个样本加权方案来学习因果关系。我们在多个基准数据集上进行的广泛实验,针对6种最先进的攻击方式验证了我们提出的CBD在减少后门威胁的同时,仍能在预测良性样本时保持高准确性。进一步的分析表明,CBD还可以抵抗潜在的自适应攻击。
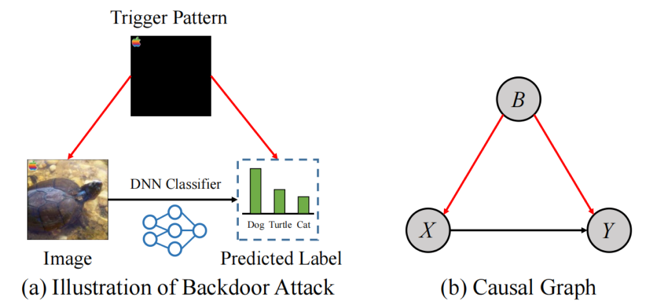
受因果推断的启发,我们首先构建因果图来分析基于污染的后门攻击。下图中(a)是后门攻击的示意图,(b)是构建的因果图。在因果图中,我们用节点表示抽象的数据变量(X表示输入图像,Y表示标签,B表示后门攻击),有向边表示它们之间的关系。如图 (b) 所示,除了X对Y的因果作用 (X→Y) 外,后门攻击者还可以在图像上附加触发图案trigger (B→X) 并将标签更改为目标标签 (B→Y)。因此,作为X和Y之间的一个混淆因素,后门攻击B打开了虚假路径X←B←Y(令B=1表示图像被污染,B=0表示图像是干净的)。我们所谓的“虚假”指的是这条路径在从X到Y的直接因果路径之外,使X和Y出现虚假的相关性,并在触发模式被激活时产生错误的影响。深度神经网络很难区分虚假相关性和因果关系。因此,直接在可能被污染的数据集上训练深度神经网络存在被后门攻击的风险。
根据后门攻击更容易被学习到的特点,我们设计了两阶段的防御方法:我们故意训练一个后门模型fB来捕获后门攻击的虚假相关性,另一个干净模型fC则致力于学习因果关系。CBD的模型图如下所示:

我们把fC的训练目标通过互信息的形式表达出来:
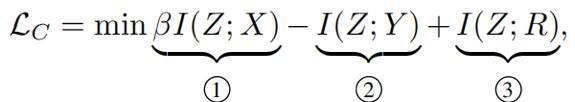
其中前两项构成了信息瓶颈information bottleneck,使得fC可以尽量学习到简洁的表示。最后一项则是使得fC和fB在嵌入空间中的表示区分开来(最小化互信息), 使得fC学习因果的关系。我们通过WGAN来近似计算最后一项。经过一些列化简和推导,我们得到最终的损失函数:
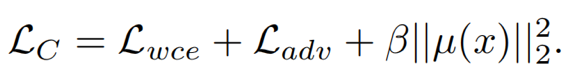
值得注意的是,我们使用加权的交叉熵损失函数来提升训练效果,权重是:
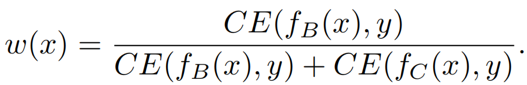
下面是CBD训练的伪代码,T1一般设置为5epoch, 以区分backdoor和正常的因果关系:

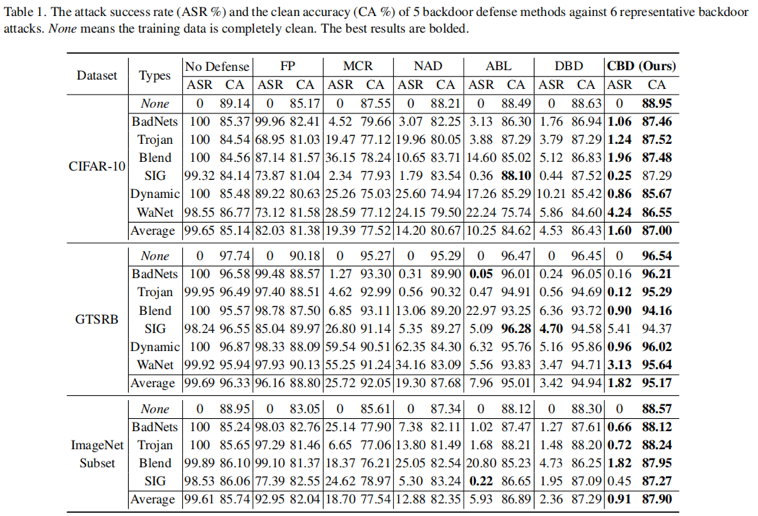
我们在多个数据集和6种常用的backdoor攻击下,都可以取得优越的防御效果:
总结一下:我们受因果推断视角的启发,我们提出了Causality-inspired Backdoor Defense(CBD)来学习去混淆表示以进行可靠的分类。我们针对6种最先进的后门攻击进行的广泛实验,展示了CBD的有效性和鲁棒性。
我们的工作开辟了一个有趣的研究方向,即利用因果推断来分析和抵御机器学习中的后门攻击。未来可能的工作包括将CBD扩展到其他领域,包括图学习、联邦学习和自监督学习。
03
Extracting Motion and Appearance via Inter-Frame Attention for Efficient Video Frame Interpolation
作者:张国珍,朱雨涵,王浩男,陈宥鑫,武港山,王利民
单位:南京大学
邮箱:
zgzaacm@gmail.com
lmwang@nju.edu.cn
论文:
https://arxiv.org/pdf/2303.00440.pdf
代码:
https://github.com/MCG-NJU/EMA-VFI
在本文中,我们提出利用帧间的注意力机制来同时提取运动信息和两帧之间的交互过的外观信息。具体来说,对于当前帧中的任何一个区域,我们将其作为注意力机制中的查询(query),并将其在另一帧的空间上的相邻的所有区域作为键和值(key&value)来推导出代表其当前区域与另一帧相邻区域的注意力图。随后,该注意力图被用来汇总邻居的外观特征,并和当前区域的外观特征进行聚合,从而得到同一个区域在两帧不同位置的外观信息的聚合特征(Inter-Frame Appearance Feature)。此外,注意力图也被用来对另一帧的相邻区域的位移进行加权,以获得当前区域从当前帧到相邻帧的近似运动向量(Motion Vector),并经过一个线性层得到两帧之间的运动特征。
这样,通过一次注意力操作,我们通过注意力图的复用同时独立的提取出了两种特征。值得注意的是,这样得到的外观特征没有混淆位置信息,所以可以进一步在此基础上提取新的外观信息和运动信息。遵循目前主流的结构设计思路,我们将帧间注意力机制放在了Transformer的结构中。这样的设计让我们只需要改变特征的通道数和Transformer block的个数就能控制提取的两种特征的质量和多样性。
04
Foundation Model Drives Weakly Incremental Learning for Semantic Segmentation
作者:于超辉,周强,李井亮,袁建龙,王志斌,王帆
单位:阿里巴巴达摩院
邮箱:
huakun.ych@alibaba-inc.com
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Yu_Foundation_Model_Drives_Weakly_Incremental_Learning_for_Semantic_Segmentation_CVPR_2023_paper.pdf
1. 简介
当前增量学习语义分割算法通常基于dense的像素级标注来学习新类别。尽管取得了不错的结果,但像素级标注成本高且耗时。弱监督增量语义分割(WILSS)是一项新颖有吸引力的任务,旨在不遗忘旧知识的同时,从廉价且广泛可用的图像级标签中学习分割新类别。尽管结果还不错,但图像级标签无法提供定位每个分割的细节信息,从而限制了WILSS的性能。这激发了我们思考如何去改进并有效利用在给定图像级标签的情况下学习新类别的分割,并且同时避免忘记旧类知识。在这项工作中,我们提出了一种新颖且数据高效的WILSS框架,名为FMWISS。具体而言,我们首先提出基于自训练模型的联合分割来蒸馏互补的预训练基础模型的知识,以生成dense伪标签。然后,我们进一步使用teacher-student架构去优化带噪声的伪标签,其中,我们提出dense contrastive loss去优化teacher模块。此外,我们引入基于Memory的copy-paste数据增强来改善旧类别的灾难性遗忘问题。
2. 我们的方案:FMWISS
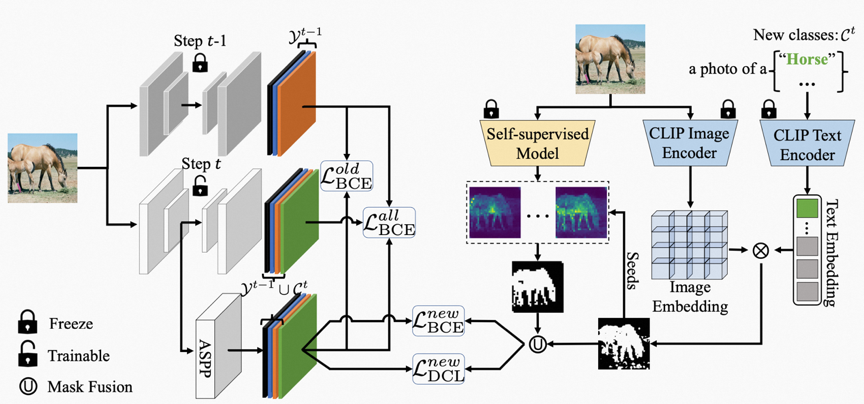
如上图FMWISS框架图所示,我们的方法主要包括3个部分。首先,为了在仅给定图像级标签的情况下提升新类的监督信号的质量,我们提出基于自训练模型的联合分割;然后,为了进一步优化伪监督信号,我们提出基于teacher-student架构配合dense contrastive loss的伪标签优化方法;最后,为了缓解对旧类的灾难性遗忘,我们提出基于Memory的copy-paste数据增强策略。
2.1 基于自训练模型的联合分割
2.1.1 初始Mask
为了高效利用图像标签信息,我们提出基于pre-trained CLIP模型的初始伪标签生成。给定图像,先通过image encoder获得image feature,然后,根据对应的图像标签,通过text encoder获得text embeddings,最后,计算pixel-text score map作为初始Mask。
2.1.2 精细化Mask
通过视觉-文本预训练CLIP模型可以获得category-aware的dense伪标签,但由于CLIP的特征擅长做instance-level 的分类任务,所以Initial Mask是noise的并且可能含有多类object的。为了提取category-specific的dense mask,我们提出通过种子指引进行mask refine。具体来说,我们利用自监督视觉预训练模型提取视觉特征,通过Initial Mask随机获得前景的n个采样点作为种子点去提取category-agnoistic的attention mask,从而提去到了某个category某个object的前景mask。最后,我们通过一种简单的融合策略,得到更好的mask,能进一步提升性能。
2.2 伪标签优化
在改善了新类的监督信号后,如何进一步有效利用这样的监督信息?我们提出一个teacher-student结构去优化带噪声的mask,引入一个teacher模块去动态优化伪标签mask。我们首先提出pixel-wise binary cross-entropy loss对新类进行监督:
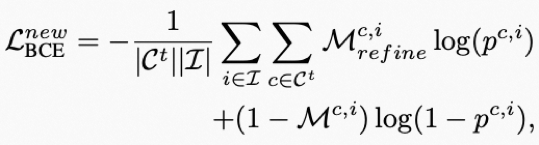
然而BCE loss更关注每一个类目的前景,忽略了多类间的知识,受对比学习的启发,我们提出dense contrastive loss去进一步优化带噪声的pseudo mask:
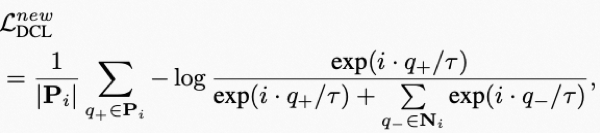
2.3 基于Memory的copy-paste数据增强
为了改善旧类的学习,缓解灾难性遗忘问题,我们提出了一种简单有效的数据增强策略来对每个旧类缓存若干实例,在学习新类的时候进行重放:
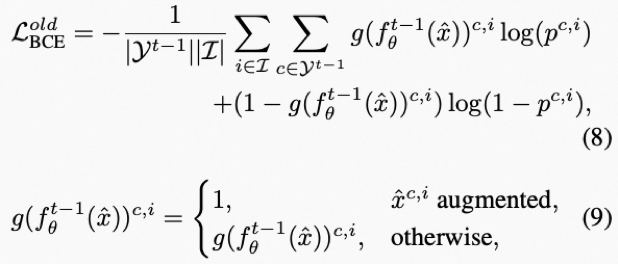
3. 实验结果
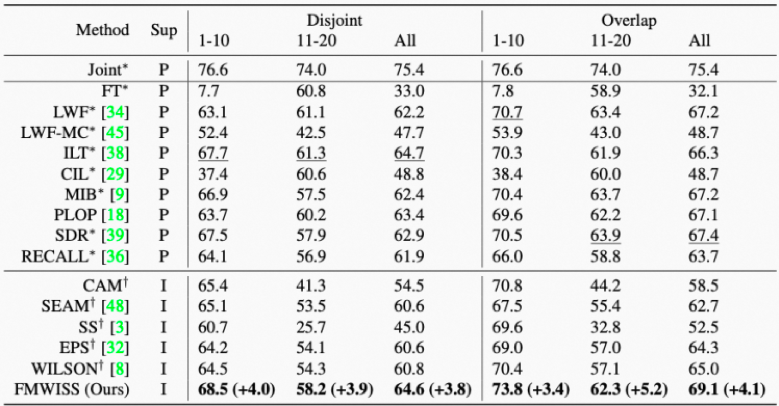
在Pascal VOC和COCO数据集的大量实验证明了FMWISS框架的出色性能,例如,在15-5 VOC设置中达到70.7%和73.3%,分别优于最先进的方法3.4%和6.1%。
15-5 VOC:

VOC 10-10:
05
DIP: Dual Incongruity Perceiving Network for Sarcasm Detection
作者:文长崧,贾国力,杨巨峰
单位: 南开大学计算机学院
邮箱:
downdric@163.com,
exped1230@gmail.com,
yangjufeng@nankai.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/html/Wen_DIP_Dual_Incongruity_Perceiving_Network_for_Sarcasm_Detection_CVPR_2023_paper.html
代码:
https://github.com/downdric/MSD.git
Demo:
https://exped1230.github.io/demo/sarcasm/sarcasm.html
一.动机
互联网隐式情感挖掘是当前研究的热点。其中,讽刺是一种典型的隐式情感,是用户表达与字面含义相反意见的方式。随着社交平台的发展,讽刺检测在产品评论分析、政治观点挖掘等领域的广泛应用吸引了越来越多的关注。基于深度学习的多模态讽刺检测虽然取得了一定进展,仍面临两个方面的挑战。首先,与关注于图文语义内容的多模态识别任务不同,讽刺检测旨在从多模态数据中发现用户隐含的潜在意图,增加了识别的难度。其次,在传统的多模态识别任务中,图像和文本表达互相匹配的一致信息,但具有讽刺意味的图文内容往往是矛盾的,这对模态间的融合和对齐带来了挑战。
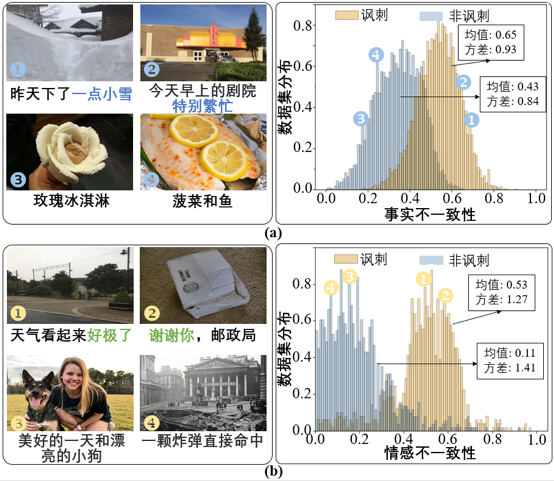
图1 讽刺数据集的示例(左)及语义和情感层面不一致性的分布(右)
对于隐式的讽刺表达,心理学家发现当图文表达的意义与观察到的事实相反时就会出现讽刺,并且用户的态度对于发现模糊的讽刺尤其有效。基于这些理论,本文利用图文的语义相似度和情感极性来验证讽刺数据集中的不一致性。具体的,本文计算了由CLIP输出的图文语义特征之间的相似度,并用1减去此相似度作为事实的不一致性值。在情感方面,本文使用在情感数据集FI和IMDB上训练的网络对图文数据情感极性分别进行预测,计算其差值度量情感的不一致性。如图1所示,数据集中讽刺与非讽刺的数据在情感和事实层面的不一致性分布具有明显差异,是发现讽刺的重要线索。基于此,本文提出了一个双重感知网络,从事实和情感两方面建模讽刺数据中的不一致性来检测讽刺。针对第二个挑战,本文对编码器输出的特征进行隐式的对齐,避免显式的对齐方法破坏图文特征中关键的不一致性信息。
二.方法
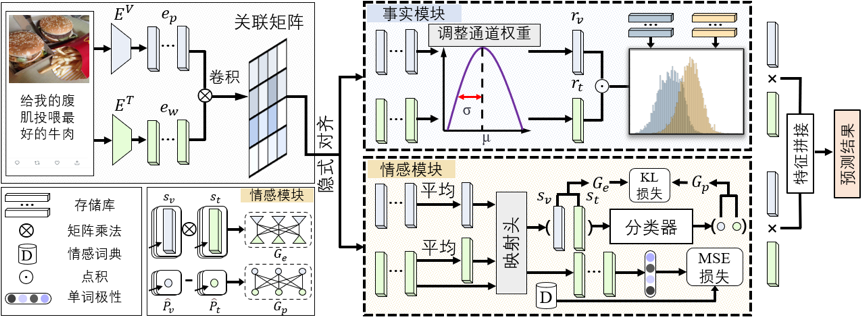
图2 网络结构图
图2展示了本文方法的结构图。本文首先使用VIT和BERT网络对图文特征进行提取。为了对齐图文相关的特征,本文使用基于相关矩阵的跨模态注意力模块来隐式实现模态之间的融合。在事实不一致性建模模块,本文引入了一个通道加权策略来增强与讽刺相关的表征,并分别维护了讽刺和非讽刺样本的相似性分布。本文通过计算当前特征属于讽刺与非讽刺数据高斯分布的概率差值作为语义不一致性因子的值。在情感层面,由于数据集缺少准确的情感标注,本文藉由情感词典SenticNet引入文本情感的监督信息。由于图文模态在之前已进行跨模态隐式对齐,本文采用孪生网络层对图文情感特征进行提取,并采用连续对比学习的方法增强情感特征。最终,本文以图文情感极性的差值作为情感层面的不一致性因子。在通过事实和情感的不一致性建模后,本文融合输出的特征以进行讽刺的预测。来自同一个方面的模态间特征通过点积进行融合,然后将语义和情感层面的表征拼接起来送入分类器,获得最终的预测结果。
三.实验
表1 在MSD数据集上与先进方法进行对比

本文方法在主流的MSD数据集上准确率达到89.59%,相比之前的先进方法提升2.04%。在二分精确率上,DIP方法比最优的CMGCN方法提高了4.13%。这一结果表明DIP擅长识别类别为讽刺的数据。同时,本文还提供了详细的消融实验并证明了基于隐式对齐的特征融合方法相比于显式对齐的优势,更详细的实验部分内容请参见论文。
06
Fine-Grained Categorization From RGB-D Images
作者:檀彦豪1, Mohammad Muntasir Rahman1,2,闫衍芙1,薛健1,邵岭4,5,吕科1,3#
单位:
1中国科学院大学
2伊斯兰大学
3鹏城实验室
4穆罕默德·本·扎耶德人工智能大学
5起源人工智能研究院
邮箱:
tanyanhao15@mails.ucas.ac.cn
muntasir@mails.ucas.ac.cn
yanyanfu16@mails.ucas.ac.cn
xuejian@ucas.ac.cn
luk@ucas.ac.cn
ling.shao@ieee.org
论文:
https://ieeexplore.ieee.org/document/9361197
#通讯作者
在计算机视觉研究中,细粒度分类是最基本和最具挑战的任务之一。目前研究所使用的数据集大多由RGB图像组成,而基于RGB图像的细粒度分类具有一定的局限性,例如在复杂场景下较难获取物体的特征信息。最近几年,深度传感器已经广泛应用于多个领域,它能够提供物体的三维空间信息,该信息可用于描述物体在真实世界中的几何形状,并且不受物体周围环境光照变化的影响。根据目前基于RGB-D图像的研究结果表明,使用RGB-D图像可以显著提高物体分类任务的准确率,因此,基于RGB-D图像的细粒度分类研究具有重要意义。本文首先构建了一个用于细粒度物体分类研究的RGB-D数据集(图1):RGBD-FG,它由日常生活中常见的水果和蔬菜作为主要对象,总共包含50个子类,93,051张RGB-D图像;并使用多个不同配置的多模态卷积神经网络模型(图2)对该数据集进行实验验证,并将实验结果作为数据集的基准结果。

图1 数据集样例
实验所用的多模态卷积神经网络模型包含多个卷积神经网络分支,各分支分别对RGB图像和深度信息进行特征提取,基准实验模型的配置主要包含五种模态数据:RGB、Raw Depth、Jet Color、HHA和Surface Normal,以及多种经典卷积神经网络模型,基准实验结果见表1。

图2 多模态卷积神经网络模型框架
表1 基准实验结果

虽然以上基于多模态卷积神经网络模型方法的准确性有了明显提高,但是该类方法具有一定的局限性:首先多模态模型各分支使用经典的卷积神经网络,在训练阶段需要对各分支的网络进行权重参数的初始化,而权重参数是网络经过对大规模RGB图像数据集训练后得到的,由于之前没有类似的大规模RGB-D数据集,导致缺少针对深度信息的预训练模型。而深度信息不同于RGB图像,使用针对RGB图像的预训练模型提取深度信息的特征必然会造成一定的缺失;并且目前基于多模态卷积神经网络的模型通常由多个经典神经网络构建而成,整体模型参数多,训练阶段耗时长且需要消耗和占用很大存储空间。针对以上问题,本文提出一种基于特定模态特征提取的多模态卷积神经网络模型(图3)。在RGBD-FG数据集上的实验验证和对比(表2)表明该模型能更有效地提取RGB-D图像特征,并提高RGB-D物体的细粒度分类的性能。

表2 本文提出方法的实验结果


 京公网安备11010802017125号
京公网安备11010802017125号