
2023年论文导读第二十二期
【论文导读】2023年论文导读第二十二期
CCF多媒体专委会 2023-11-07 08:00 发表于山东


论文导读
2023年论文导读第二十二期(总第八十八期)
目 录
|
1 |
Robust RGB-T Tracking via Adaptive Modality Weight Correlation Filters and Cross-Modality Learning |
|
2 |
LION: Label Disambiguation for Semi-supervised Facial Expression Recognition with Progressive Negative Learning |
|
3 |
Fluid Dynamics-Inspired Network for Infrared Small Target Detection |
|
4 |
GPLight: Grouped Multi-agent Reinforcement Learning for Large-scale Traffic Signal Control |
|
5 |
ProxyFormer: Proxy Alignment Assisted Point Cloud Completion with Missing Part Sensitive Transformer |
|
5 |
Timestamp-Supervised Action Segmentation from the Perspective of Clustering |
01
Robust RGB-T Tracking via Adaptive Modality Weight Correlation Filters and Cross-Modality Learning
基于自适应模态权重和跨模态学习的相关滤波跟踪
作者:周明亮,赵鑫文,罗福婷,罗均*,浦华燕,向涛
单位:重庆大学
邮箱:
mingliangzhou@cqu.edu.cn,
202114131110@cqu.edu.cn,
lft@cqu.edu.cn,
luojun@cqu.edu.cn,
phygood_2001@shu.edu.cn,
txiang@cqu.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3630100
代码:
https://github.com/LDating/AWCM
*通讯作者
视觉目标跟踪是计算机视觉中的基础问题,广泛应用于智能监控、自动驾驶等领域。多模态跟踪使用可见光和红外信息,可以提高跟踪鲁棒性。现阶段直接融合多模态信息面临两大挑战:1)不同模态信号的特性差异,简单融合特征可能无法充分利用互补信息;2)单一模态失效会对跟踪性能产生极大的影响。如何通过自适应调整模态权重及跨模态学习,有效利用两种模态的互补性,实现稳定可靠的RGB-T目标跟踪,是当前研究的重要方向之一。
针对上述问题,如图1所示,本文提出了一种具有自适应模态权重和跨模态学习的相关滤波器跟踪器,并使用ADMM求解,以实现稳健的RGB-T目标跟踪。跟踪器通过自适应调整RGB和红外两种模态的权重,以减少单一模态失效对跟踪性能的影响。另外,跟踪器通过跨模态学习,利用两种模态的互补信息,而不是简单融合特征。实验结果表明,提出的跟踪器能够有效地整合双模态信息,并适应环境变化,从而实现稳定可靠的RGB-T目标跟踪。
本研究的主要贡献总结如下:
1) 提出了一种结合了相关滤波和特征融合的跟踪框架。特征融合利用加权激活来融合热红外和可见光模态,在激活共享特征的同时保留了模态的特异性。
2) 所提出的跟踪器结合了APCE系数和模态权重。具体而言,使用APCE系数更新模态可靠性,进一步提高了模型的鲁棒性。
3) 引入了交互式跨模态学习,共享模态作为中间辅助模态来优化滤波器学习,提供了使用相似性滤波器和空间惩罚与中间模态进行学习调整的见解,以规避模态间差异的影响。
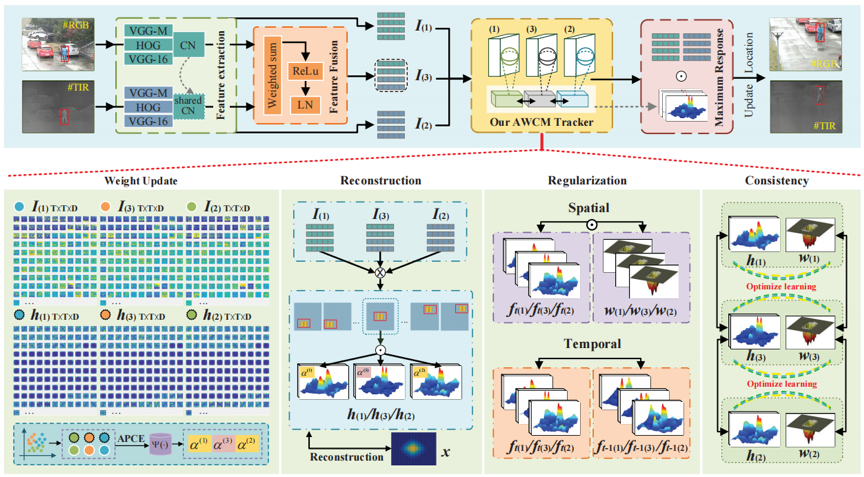
图1 提出的算法整体框架

图2 不同方法的数据集跟踪效果对比
如图2所示,提出的AWCM跟踪器在多个数据集上均优于现有跟踪器。为验证模型的泛化能力,还测试了不同的特征提取器,结果表明框架对特征提取器和特征层的选择都具有鲁棒性。
02
LION: Label Disambiguation for Semi-supervised Facial Expression Recognition with Progressive Negative Learning
作者:杜忠璟,蒋旭,王鹏,周奇正,吴锡,周激流,王艳
单位:四川大学,纽约州立大学,成都信息工程大学
邮箱:
duzhongjing@stu.scu.edu.cn,
jiangxu@stu.scu.edu.cn
wpen@scu.edu.cn,
qizheng_zhou@163.com,
wuxi@cuit.edu.cn,
zhoujl@scu.edu.cn,
wangyanscu@hotmail.com
论文:
https://www.ijcai.org/proceedings/2023/0078.pdf
半监督深度面部表情识别(SS-DFER)由于其更实用的大量未标记数据而引起了越来越多的研究兴趣。然而,目前的SS-DFER方法有两个主要问题没有考虑: 1)标签模糊性,即给定标签与面部表情不匹配;2)未标记数据的置信度低。在本文中,我们提出了一种新的SS-DFER方法,包括一个标签去歧义模块和一个渐进式负学习模块,即LION,以同时解决这两个问题。具体来说,标签消歧模块对带有标签的数据进行操作,包括标签准确的数据(清晰的数据)和不明确的标签(不明确的数据)。它首先使用清晰的数据来计算所有表情类别的原型,然后为所有模糊的数据重新分配一个候选标签集。基于原型和候选标签集,模糊数据可以更准确地重新标记模糊数据。对于低置信度的未标记数据,开发渐进式负学习模块,迭代挖掘更完整的互补标签,可以指导模型减少数据与相应互补标签之间的关联。在三个具有挑战性的数据集上的实验表明,我们的方法在SS-DFER中显著优于目前最先进的方法,并超过了全监督的基线。
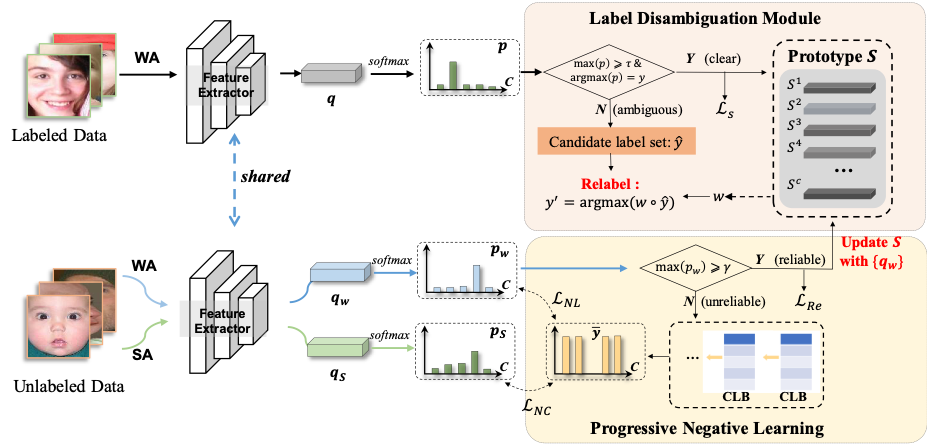
图1 模型框架图总览
方法总览如图一所示,具体来说,将有标签的图像被分为有歧义的和清晰的两组。清晰的图像用于计算所有表情类别的原型,并通过Ls损失来训练模型。有歧义的图像通过标签消除歧义模块进行重新标记。未标记的图像被分成可靠的和不可靠的组。对于可靠的图像,它们也有助于原型的计算,并通过LRe损失来优化模型。对于不可靠的图像,我们提出了一个渐进的负学习模块来挖掘它们的互补标签,利用LNL损失来监督模型。此外,在弱增强和强增强图像之间施加负一致性损失LNc。
03
Fluid Dynamics-Inspired Network for Infrared Small Target Detection
作者:陈天翔,储琪,刘斌,俞能海
单位:中国科学技术大学网络空间安全学院
邮箱:
txchen@mail.ustc.edu.cn,
qchu@ustc.edu.cn,
flowice@ustc.edu.cn,
ynh@ustc.edu.cn
论文:
https://www.ijcai.org/proceedings/2023/0066.pdf
代码:
https://github.com/txchen-USTC/FDI-Net
1. 介绍
目前多数红外小目标检测(ISTD)算法专注于构建有效的神经块或特征融合模块,但没有从特征图演化角度看待这一过程的。我们发现,受卷积,池化和周围的像素影响的图像特征图定向演化过程可类比于受周围的变量和粒子约束的流体定向流动过程。受此启发,我们尝试通过将ISTD特征图演化过程抽象为流体动力学中的流体流动过程,设计了一种新的流体力学启发的网络(FDI-Net)以实现红外小目标检测。具体而言,我们基于泰勒中心差分法(TCD)设计了TCD特征提取模块,结合了卷积和transformer结构以获取局部和全局信息。我们从Navier-Stokes(N-S)方程推导出了图像域的像素流动方程,并基于此构造一个N-S精修模块(N-S Refinement Module),用于细化提取的目标边缘特征。TCD特征提取模块确定检测过程中像素移动的主要方向,而N-S精修模块纠正少许的移动偏斜以提升边缘细节。
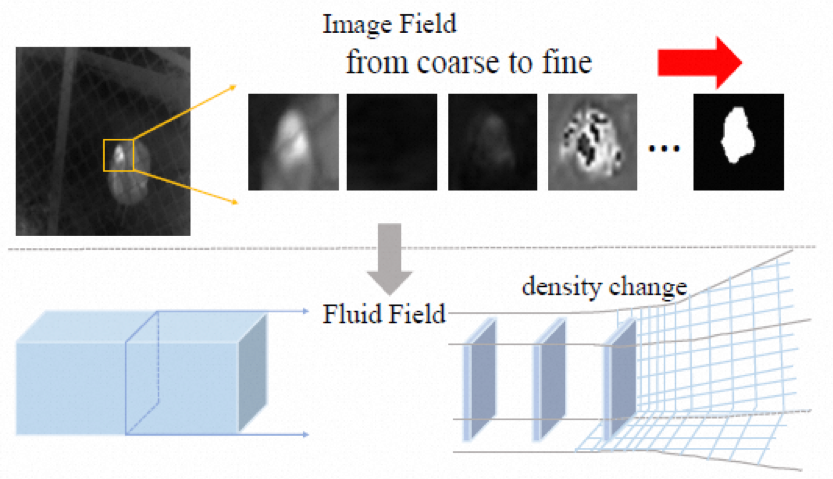
图1 特征图定向演化过程(网络注意力逐渐聚向小目标区域)与流体定向流动过程做类比
2.方法
网络总体结构框图如图2所示,主要设计集中在一个双分支的encoder。这其中TCD 特征提取模块分支关注小目标主体部分,从特征图演化角度解释则是负责确定检测过程中像素移动的主要方向。但在此过程中难免有少许的像素移动偏斜,这会造成对小目标边缘部分检测的不准确,故添加N-S精修模块分支纠正像素流动偏斜以改善小目标边缘特征细节。
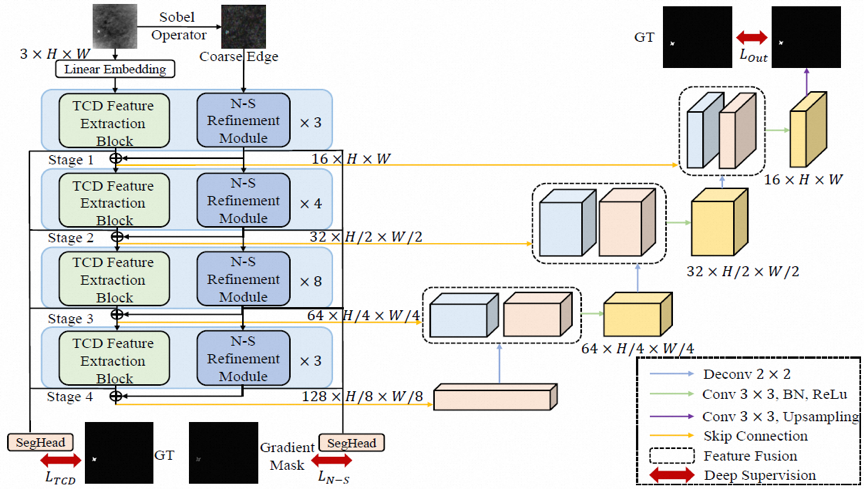
图2 FDI-Net总体结构框图
TCD 特征提取模块基于泰勒中心差分法设计,相较于ResNet所基于的Euler法具有更好的精度,更有利于目标主体区域特征的提取。表达式如公式(4)所示,具体结构如图3所示。
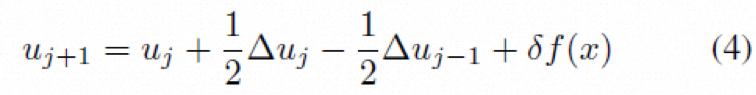
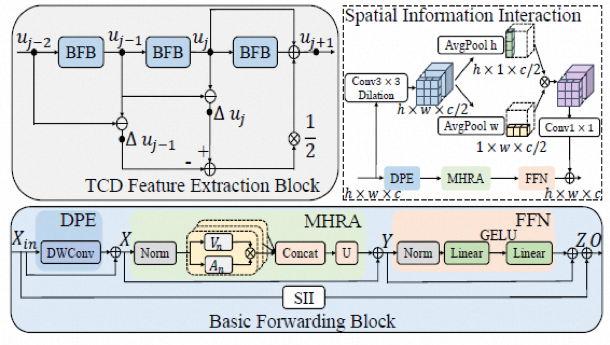
图3 TCD 特征提取模块
N-S精修模块基于流体的连续性方程推导而来,最终表达式为公式(10),设计为ResBlock和Sobel 算子的组合。
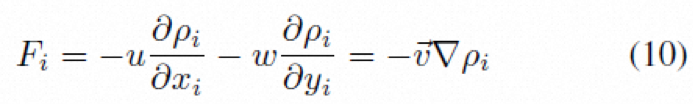
3. 实验
我们在两个最常用的公开红外小目标数据集(SIRST,IRSTD-1k)上进行了实验,如表1和图4所示。我们的方法对小目标的检测效果达到sota,能显著提升对不规则形状的小目标的检测精度。
表1 定量结果对比
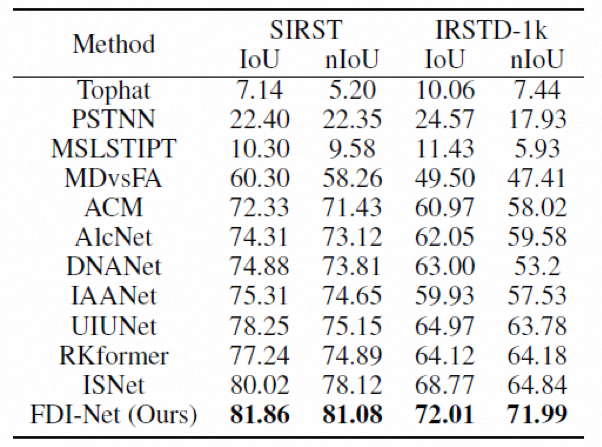

图4(a)可视化结果对比 (b)TCD和N-S分支输出结果可视化
04
GPLight: Grouped Multi-agent Reinforcement Learning for Large-scale Traffic Signal Control
作者:刘奕琳,罗贵阳*,袁泉,李静林,金磊,陈博,潘锐
单位:北京邮电大学网络与交换技术国家重点实验室交换与智能控制研究中心
邮箱:
luoguiyang@bupt.edu.cn
论文:
https://www.ijcai.org/proceedings/2023/23
*通讯作者
摘要:多智能体强化学习(MARL)方法在交通信号灯协同控制(CTL)方面的应用越来越受欢迎,通常将每个路口视为一个智能体。然而,现有的MARL方法或将每个智能体视为完全相同的模型,或将每个智能体视为完全不同的模型。这在大规模CTL中导致了其准确性和复杂性之间难以平衡。为了解决这一问题,本文提出了一种名为GPLight的MARL方法。
方法:由于道路拓扑信息是非欧几里德数据,本文应用GCN网络来提取每个路口的特征。整体前向传播公式如图所示。静态和动态特征经过GCN嵌入层进行提取。
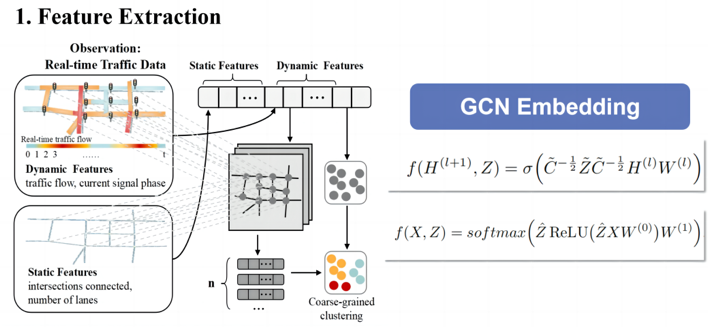
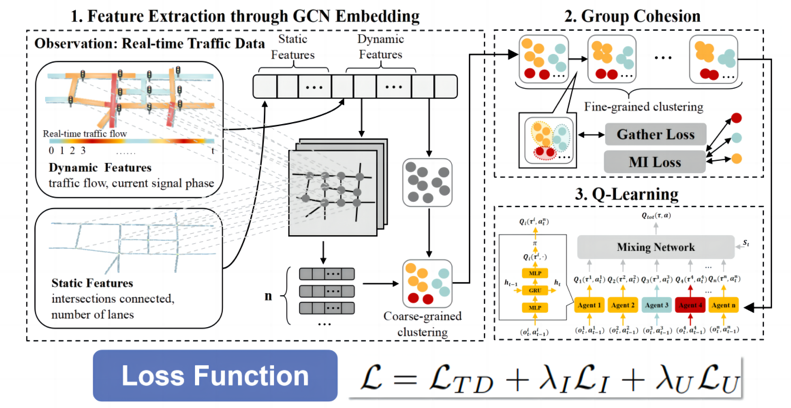
进行动静态多维特征提取后,本文引入了两个损失函数来辅助智能体相似度的挖掘。一是为了适应动态环境并避免导致学习不稳定的快速变化,在给定当前观察情况下通过最大化个体动作与环境之间的条件互信息,以确保智能体的平稳变化。另一个损失函数则最大化了组之间的可分离性,实现了同一组多智能体群组中的智能体具有高度相似的特征,以确保共享决策的准确性;同时最大程度区分不同多智能体群组,以确保群组划分合理。

得到根据相似度划分的多智能体群组后,本文将Q-Learning与多智能体群组相结合。同一组多智能体将在决策方面呈现出高度的相似性,不同类型的多智能体将通过其网络参数的变化进行区分。各个智能体群组的成员会随着实时特征的不同而不断变化。

综上,整体框架如下图所示。GPLight在同时考虑实时动态交通流和静态道路拓扑的情况下挖掘智能体特征的相似性,然后进行一个可学习且动态的聚类以对智能体进行分组。以往的研究提出,即使在提取特征时GCN嵌入使用随机权重也可以自动进行聚类。然而这种聚类的精确度欠佳,无法保证后续MARL任务达到最佳性能。因此本文引入了两个损失函数,即MI Loss和Gather Loss,以监督GCN网络进行更精确的聚类。此外,分组也受强化学习任务(如交通信号控制性能)的监督,即MARL Loss。这三个损失共同充当监督信号,引导GCN网络提取有效的特征,为MARL任务提供最佳的分组结果用于Q-Learning。
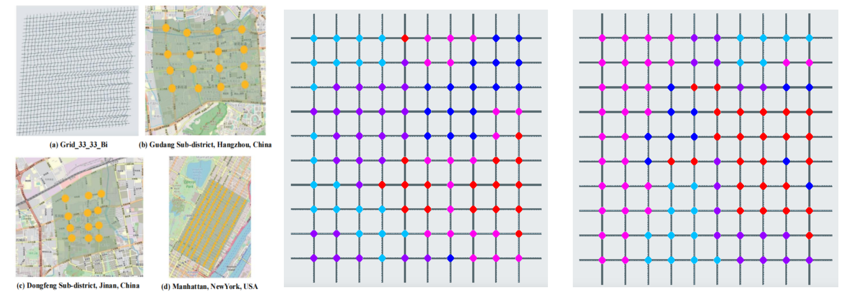
实验:合成数据集最多达1089个路口。真实数据集包括中国杭州、济南,美国曼哈顿。图中相同颜色的路口即为一组,这意味着它们提取到的特征具有很高的相似性。每个路口隶属的分组在实时中不断变化。相比于baseline模型,GPLight在总通行时间方面表现出更好的性能,尤其是在大规模场景中。

05
ProxyFormer: Proxy Alignment Assisted Point Cloud Completion with Missing Part Sensitive Transformer
作者:黎山山,高攀,谭晓阳,魏明强
单位: 南京航空航天大学计算机科学与技术学院
邮箱:
markli@nuaa.edu.cn
pan.gao@nuaa.edu.cn
x.tan@nuaa.edu.cn
mqwei@nuaa.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Li_ProxyFormer_Proxy_Alignment_Assisted_Point_Cloud_Completion_With_Missing_Part_CVPR_2023_paper.pdf
研究背景
相对于二维图像,三维信息能够提供对现实世界更立体、更全面、更结构化的描述。点云是一种常见的三维信息存储形式,随着虚拟现实(VR),混合现实(MR)以及自动驾驶的兴起,点云正在受到越来越多的关注。然而,不论是使用 RGBD 传感器、激光雷达拍摄点云还是通过图像恢复点云,都存在设备分辨率有限且容易受到遮挡的问题,直接导致采集到的点云点云稀疏或残缺,大大限制了它们的应用范围。现有方法通过对ShapeNet等数据集中的不完整点云进行特征提取,并形成与完整点云之间的映射,取得了一定的成果。但是,现有成果也暴露出三点问题:1、点云逐点特征通过最大池化层后,会产生巨大的特征损失;2、原有的不完整点云部分也被重新生成,导致精度丢失;3、训练数据集中能够提取出的丢失部分点云没有被利用起来,即先验知识运用不充分。

图1 自适应可塑性改进(API)
研究方案
为了解决上述问题,团队提出了一个基于Transformer的丢失部分敏感的点云补全网络,用于正确预测点云的丢失部分。论文采用的数据集为PCN和ShapNet-55等,其中PCN和ShapeNet-55数据集分别包含8类和55类真实场景扫描点云,PCN共计30974个模型,ShapNet-55共计52470个模型。图1为论文的网络结构图。
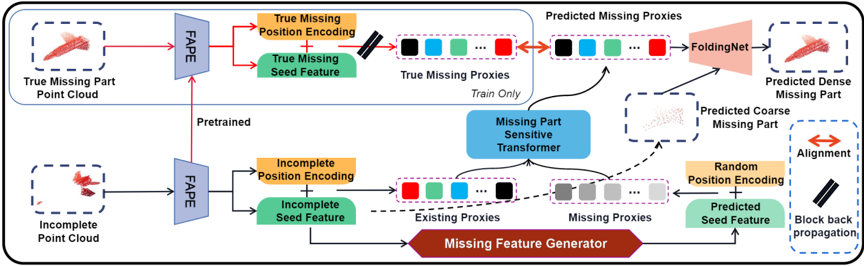
图1 ProxyFormer网络结构图
提出的方案将点云分为已存在部分和丢失部分。首先两部分点云通过位置和特征提取模块以得到对应的点云代理,接着将代理送入Transformer中进行学习,随后构建真实丢失部分代理和预测丢失部分代理之间的对齐损失,以此矫正预测的丢失部分代理,最终送入点云精细化网络中生成稠密的丢失点云。
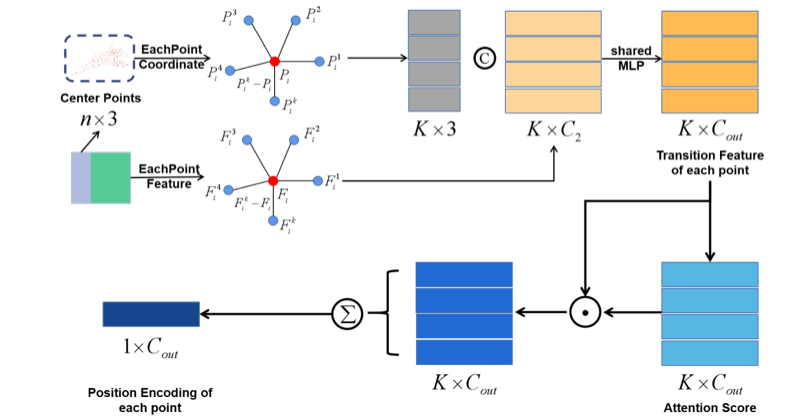
图2 点云位置提取器
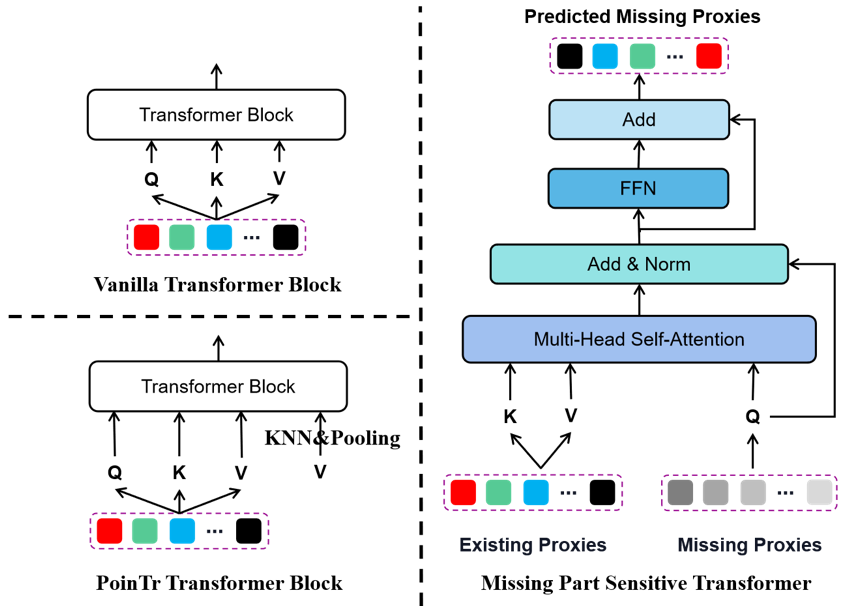
图3 丢失部分敏感的Transformer与其余Transformer的对比
研究结果
在PCN等数据集上的实验结果表明我们的方法不仅能够很好地预测出点云的残缺部分,同时能够保留原有部分并较好地回复细节。此外,我们的模型还具有较小的参数量及最快的推理速度。
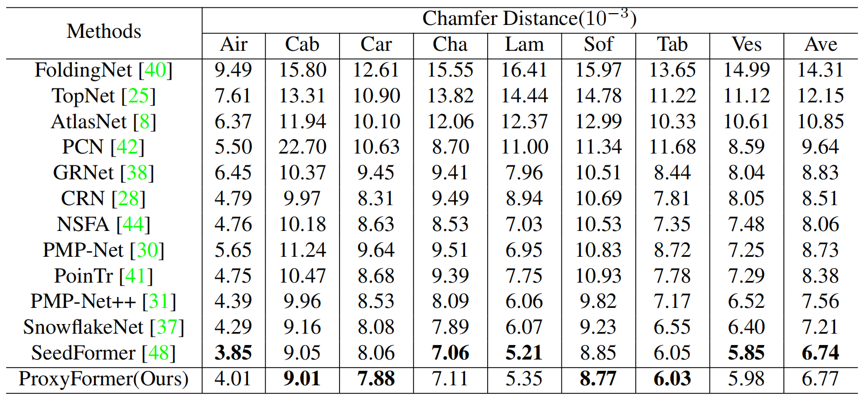
图4 不同方法在PCN数据集上的CD对比

图5 不同方法在ShapNet-55数据集上的推理时间对比
06
Timestamp-Supervised Action Segmentation from the Perspective of Clustering
作者:杜大钊,李恩晗,司凌宇,徐帆江,孙富春
单位:
中国科学院软件研究所天基综合信息系统重点实验室,清华大学
邮箱:
dudazhao20@mails.ucas.ac.cn,
lienhan20g@ict.ac.cn,
lingyu@iscas.ac.cn,
fanjiang@iscas.ac.cn,
fcsun@mail.tsinghua.edu.cn
论文:
https://www.ijcai.org/proceedings/2023/0077.pdf
代码:
https://github.com/ddz16/TSASPC
1.背景
视频时序动作分割旨在将包含多个动作的长视频分割为若干个动作段,是视频理解领域中的重要任务。由于全监督下获取长视频逐帧标注的成本很高,研究团队希望寻求弱监督下的解决方法。新兴的弱监督方法之一是时间戳监督下的算法,它通常采用的做法仅为训练视频中每个动作段随机标注一帧,然后根据视频帧的视觉特征为每帧都生成伪标签,形成完整的伪标签序列来训练分割模型。然而,处于动作变化区域的帧的动作语义信息一般不够明确(研究团队将这部分区域称为“语义模糊区间”),在语义模糊区间内,时间戳监督算法为视频帧赋予低质量的伪标签会误导模型训练、影响训练过程。
2.方法
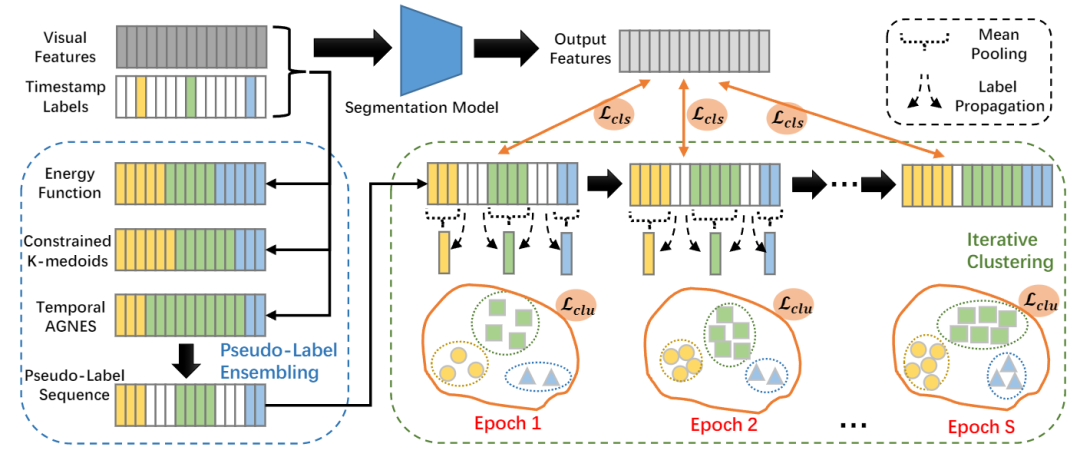
研究团队为解决上述问题,显式建模语义模糊区间,设计了一个新的时间戳监督时序动作分割框架TSASPC(如下图所示),将每个动作段视为一个类簇,将动作分割视为一个特殊的聚类问题。该框架由两个主要算法组成,分别是伪标签集成和迭代聚类。伪标签集成算法综合三种时域聚类算法生成伪标签的结果,得到带有未标注区间的伪标签序列,即包含语义模糊区间的伪标签序列。迭代聚类算法以伪标签集成算法生成的伪标签序列为初始化,通过特征聚类迭代地为语义模糊区间的帧生成伪标签。此过程缩小了语义模糊区间,并能利用不断更新的伪标签序列训练分割模型。研究团队还通过在训练过程中引入聚类损失,提高了学习获取特征的质量。
3,实验
研究团队将设计的TSASPC框架与多种不同监督设置下的动作分割算法在GTEA、50Salads和Breakfast三个重要数据集上进行了对比。结果表明,TSASPC框架在衡量分割性能的多个指标上均有提升,例如 F1分数指标、编辑距离指标和分割准确率指标。TSASPC框架甚至在Breakfast数据集上超过了全监督方法的分割性能。团队还通过大量的消融实验说明了伪标签集成和迭代聚类算法的作用,并证明了所提出框架的合理性。

 京公网安备11010802017125号
京公网安备11010802017125号