
2023年论文导读第二十一期
【论文导读】2023年论文导读第二十一期
CCF多媒体专委会 2023-10-24 08:00 发表于山东


论文导读
2023年论文导读第二十一期(总第八十七期)
目 录
|
1 |
NeuralPCI: Spatio-temporal Neural Field for 3D Point Cloud Multi-frame Non-linear Interpolation |
|
2 |
On the Difficulty of Unpaired Infrared-to-Visible Video Translation: Fine-Grained Content-Rich Patches Transfer |
|
3 |
Complexity-guided Slimmable Decoder for Efficient Deep Video Compression |
|
4 |
Deep Fair Clustering via Maximizing and Minimizing Mutual Information |
|
5 |
Adaptive Plasticity Improvement for Continual Learning |
|
5 |
Camouflaged Instance Segmentation via Explicit De-camouflaging |
01
NeuralPCI: Spatio-temporal Neural Field for 3D Point Cloud Multi-frame Non-linear Interpolation
基于时空神经场的多帧三维点云非线性插值
作者:郑泽涵*,吴丹妮*,卢睿思,卢凡,陈广#,蒋昌俊
单位:同济大学
邮箱:
zhengzehan@tongji.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/html/Zheng_NeuralPCI_Spatio-Temporal_Neural_Field_for_3D_Point_Cloud_Multi-Frame_Non-Linear_CVPR_2023_paper.html
代码:
https://github.com/ispc-lab/NeuralPCI
论文介绍网页:
https://dyfcalid.github.io/NeuralPCI
*共同作者 #通讯作者
一、研究背景与动机
我们通过3D扫描仪或者激光雷达等传感器采集到的点云序列由于硬件本身的限制,点云序列的帧率普遍较低,例如激光雷达的点云帧率通常只有10-20Hz,远低于相机的帧率,这也限制了我们对点云高帧率时序信息的利用。因此,点云插帧任务的目的是给定一个低时间分辨率的点云序列,通过估计每两帧之间的中间帧点云进行补充,从而得到更高时间分辨率的点云。
由于点云本身无序、不规则,且各帧之间的点不存在一一对应的关系,不能直接插值得到中间帧的点云。现有的点云插帧算法以两帧点云为输入,先基于点云场景流的估计来预测各点运动,再通过线性插值得到中间帧点云。然而在实际室内外场景中存在着大量的非线性运动,例如在自动驾驶场景下的加减速或转弯等,不能满足线性运动假设,只使用两帧点云线性插值的结果会导致较大的偏差。因此点云插帧算法需要具备对非线性运动的预测能力,使用多帧点云作为输入是必然的选择,相邻的多帧点云能够引入额外的时空信息,例如不同的视角、互补的几何形状和隐式的高阶运动信息。
二、方法
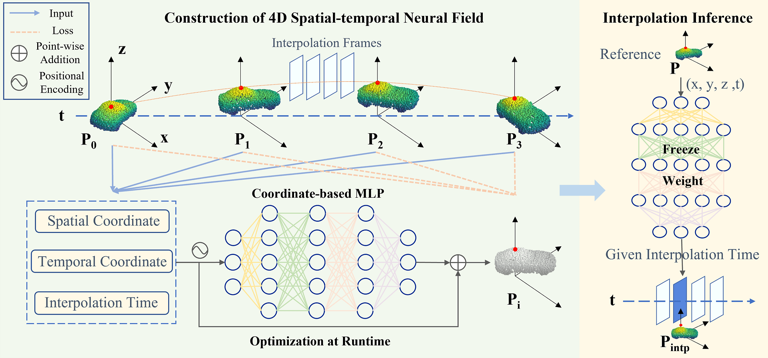
图1 NeuralPCI总体框架
本文提出了一种基于时空神经场的多帧三维点云非线性插值的算法NeuralPCI,通过构建点云4D时空神经场对连续点云序列进行参数化,从而隐式地聚合多帧点云的时空信息,在统一框架下实现点云插值和外推,可以处理室内外场景的复杂非线性运动。
网络主体使用基于坐标的MLP网络F⍬来表征场景,它将三维空间坐标x∊R3和一维时间t∊R坐标作为输入,并输出运动向量∆x∊R3,可以看作是从坐标场到运动场的映射。此外,我们利用一个独立的输入,即插帧时刻tintp∊R来控制网络的输出,得到该时刻的相对运动,来生成最终的三维插帧点云xintp∊R3。
对于每帧输入点云,我们将插帧时刻分别设置为每个输入帧对应的时间戳,以预测相应时空位置的点云并与原始输入点云计算损失。在不依赖真值的情况下,NeuralPCI以自监督的方式端到端实时优化,最小化输入点云和预测点云之间的分布损失来更新网络参数。损失函数使用Chamfer Distance (CD)来计算两帧点云之间的分布差异,并引入Earth Mover's Distance (EMD)和平滑度损失。最后在推理阶段,NeuralPCI输入给定的参考点云和任意设置的中间帧时刻,就能得到相应的插帧点云输出。
三、实验
室内数据集采用DHB数据集,其包含了非刚性变形的三维人体运动点云序列。此外对于室外数据集,我们从三个公开的大规模自动驾驶数据集KITTI、Argoverse和Nuscenes中收集了具有大位移的非线性运动样本,构建了一个具有挑战性的多帧点云插帧数据集NL-Drive。最终NeuralPCI在室内外数据集上均取得最先进的性能。
表1 DHB数据集定量实验结果

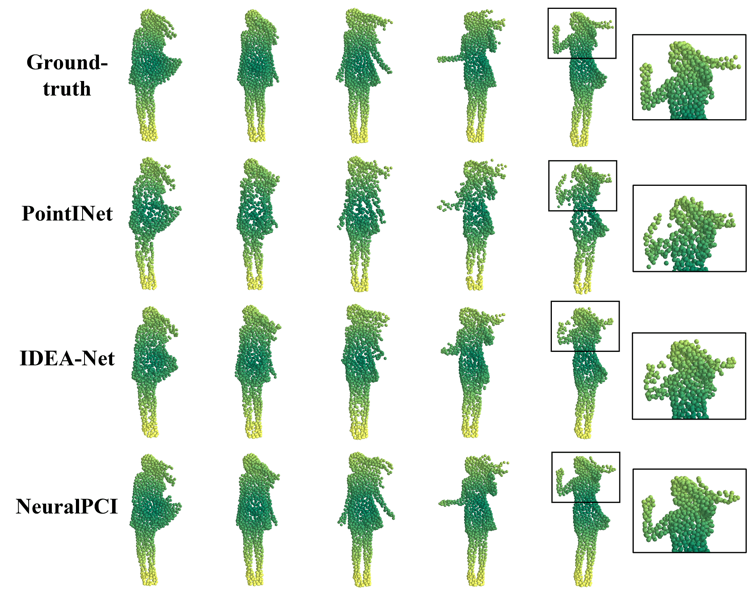
图2 DHB数据集的可视化对比表2 NL-Drive数据集定量实验结果
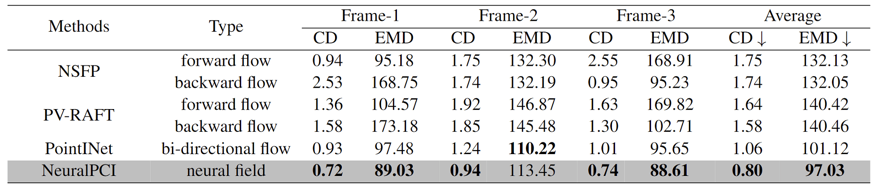
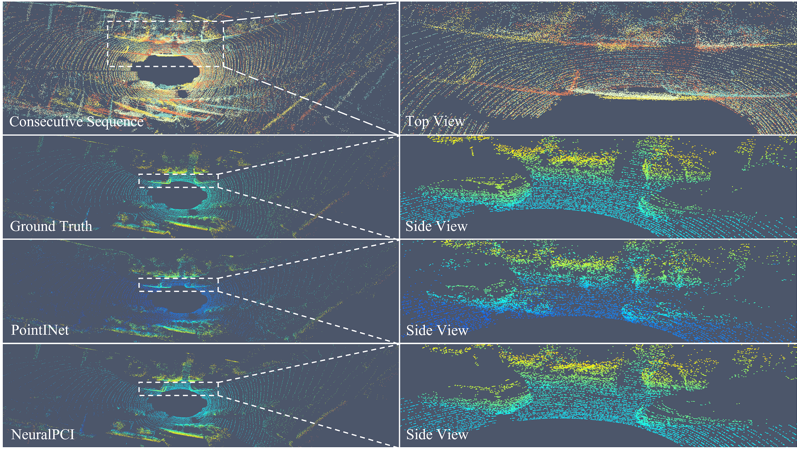
图3 NL-Drive数据集的可视化对比
02
On the Difficulty of Unpaired Infrared-to-Visible Video Translation: Fine-Grained Content-Rich Patches Transfer
作者:俞振杰1,李爽1,*,沈以睿1,刘驰1,王水根2
单位:1北京理工大学,2烟台艾睿光电
邮箱:
zjyu@bit.edu.cn,
shuangli@bit.edu.cn,
yiruishen@bit.edu.cn,
chiliu@bit.edu.cn,
shuigen.wang@iraytek.com
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Yu_On_the_Difficulty_of_Unpaired_Infrared-to-Visible_Video_Translation_Fine-Grained_Content-Rich_CVPR_2023_paper.pdf
代码:
https://github.com/BIT-DA/ROMA
*通讯作者
1. 引言
可见光成像结果(彩色图片/视频)在计算机视觉领域有着广泛的应用。可见光成像结果包含有颜色、纹理、形状等信息,有利于大部分视觉算法模型(如目标检测、语义分割)提取特征,取得优异的推理结果。然而,可见光成像受制于拍摄环境的光线条件,其结果在恶劣天气下表现糟糕。另一方面,红外传感器能够在恶劣天气下更稳定地成像,因此被应用在安保监控和自动驾驶等领域。尽管红外成像技术在稳定性上优于可见光成像技术,大多数的流行视觉算法模型仍然在可见光数据上完成训练,并不能用红外结果替代可见光结果作为输入。这种情况下,本任务旨在于通过迁移技术将稳定的红外视频转化为精细化的可见光视频,以推动视觉算法在恶劣天气下的应用。先前工作在迁移时没有考虑到现实环境中不同物体存在的长尾问题(如图1(a)所示),导致优化器更关注于内容匮乏区域像素(大面积的天空、路面等),忽视了更重要的内容丰富区域像素(小面积的车辆、路牌等),无法生成精细化的可见光结果(如图1(b)所示)。本文中,我们CPTrans转换框架,实现内容丰富区域的精细化生成。
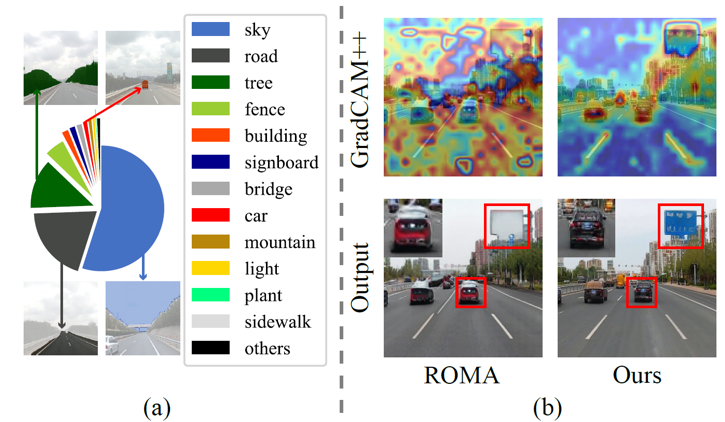
图1 (a)现实场景中的长尾现象以及(b)GradCAM++可视化优化偏见现象
2. 方法概述

图2 CPTrans框架示意图
如图2所示,针对非配对红外视频到可见光视频转换任务中存在的优化偏见问题,CPTrans框架自适应地平衡不同区域优化梯度,最终实现取得精细化的可见光生成结果。具体而言,Content-aware Optimization策略鼓励模型沿着内容丰富区域的梯度进行优化,以确保重要区域在长尾现象下仍有精细化的生成结果。该策略根据各区域优化梯度向量和最终优化梯度向量之间的余弦值计算权重图,再利用权重图修正各个区域的优化力度,确保内容丰富区域能够得到真正平等的优化。而Content-aware Temporal Normalization策略旨在于优化内容丰富区域在运动下的生成效果。
3. 实验结果
我们在各种场景下均取得了最优的性能(如表1、2所示),且本方法通过红外视频生成的可见光视频在下游视觉任务:目标检测(如图3所示)和语义分割(如图4所示)中均取得了最优的表现结果。
表1 在InfraredCity-Lite数据集上取得了SOTA的性能
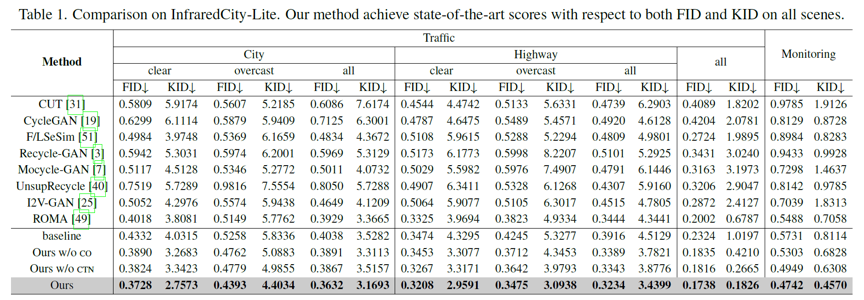
表2 在IRVI数据集和InfraredCity-Adverse数据集上取得了SOTA的性能


图3 本方法生成的可见光结果在目标检测上有更优秀的性能

图4 本方法生成的可见光结果在语义风格上有更优秀的性能
03
Complexity-guided Slimmable Decoder for Efficient Deep Video Compression
作者:Zhihao Hu,Dong Xu
单位:北京航空航天大学,香港大学
邮箱:
huzhihao@buaa.edu.cn
dongxu@hku.hk
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Hu_Complexity-Guided_Slimmable_Decoder_for_Efficient_Deep_Video_Compression_CVPR_2023_paper.pdf
引言
最近,基于学习的视频编解码器取得了令人瞩目的编码性能,甚至超过了广泛使用的商用编码器如H.264和H.265。然而,这些基于学习的视频编解码器在计算复杂性方面效率较低且不同设备承受不同计算复杂性的能力也存在差异。
为了实现实用的视频编解码器,在解码过程中有两个关键方面需要考虑。首先是针对不同的复杂度约束,精心设计不同模块的网络结构,如运动解码器、残差解码器和运动补偿网络等。这样能够满足不同模块对于通道宽度的需求,提高解码器的性能。其次是在编码过程中,要充分利用已经精确预测的特征图元素,避免对整个特征图进行低效的熵编码,以提高编解码效率。
考虑到这两个方面,在这项工作中,我们提出了一种基于复杂度引导的精简解码器(cgSlimDecoder),结合跳过适应性熵编码(SaEC),用于高效的深度视频编码。
方法概述
在这项工作中,我们提出复杂度引导的可减小解码器(cgSlimDecoder)结合适应性跳过熵编码(SaEC),用于高效的深度视频压缩。具体来说,在我们的cgSlimDecoder中,鉴于目标复杂度约束,我们引入了一组新的通道宽度选择模块,自动决定每个可减小卷积层的最佳通道宽度。通过优化复杂度-速率-失真相关的目标函数,直接学习新引入的通道宽度选择模块和解码器中的其他模块的参数,我们的cgSlimDecoder可以自动分配不同类型模块的最佳参数数量(例如运动/残差解码器和运动补偿网络),并且可以使用单个已学习的解码器同时支持多个复杂度级别而不是多个解码器。此外,我们提出的SaEC可以通过简单地跳过由超先验网络已经很好预测的编码特征图中的元素的熵编码过程,进一步加速运动和残差解码器的熵解码过程。通过我们全面的实验表明,我们新提出的方法cgSlimDecoder和SaEC是通用的,可以轻松地纳入三种广泛使用的深度视频编解码器(即DVC、FVC和DCVC)中,显着提高它们的编码效率并几乎不会影响性能。

实验结果
我们使用Vimeo-90K数据集作为训练集,该数据集包含89,800个视频序列。随后,我们在HEVC B、C、D、E等级的数据集,UVG数据集和MCL-JCV数据集上评估我们的方法。
我们使用三种广泛使用的深度视频编解码器作为基准方法,分别是DVC、FVC和DCVC。我们将它们与我们的cgSlimDecoder和cgSlimDecoder+SaEC结合使用,并将其分别命名为cgSlimbDecoder(DVC)、cgSlimbDecoder(FVC)、cgSlimbDecoder(DCVC),以及cgSlimbDecoder+SaEC(DVC)、cgSlimbDecoder+SaEC(FVC)、cgSlimbDecoder+SaEC(DCVC)。

04
Deep Fair Clustering via Maximizing and Minimizing Mutual Information
作者:曾鹏鑫,李云帆,胡鹏,彭德中,吕建成,彭玺
单位:四川大学
邮箱:
zengpengxin.gm@scu.edu.cn,
yunfanli.gm@scu.edu.cn,
penghu.ml@scu.edu.cn,
pengx.gm@gmail.com;
pengdz@scu.edu.cn,
lvjiancheng@scu.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Zeng_Deep_Fair_Clustering_via_Maximizing_and_Minimizing_Mutual_Information_Theory_CVPR_2023_paper.pdf
代码:
https://github.com/XLearning-SCU/2023-CVPR-FCMI
背景:公平聚类的目的是将数据划分为不同的聚类,同时防止敏感属性,例如性别,种族,RNA测序技术,主导聚类结果。虽然近年来进行了大量的工作并取得了巨大的成功,但这些工作大多是启发式的,并且缺乏统一的算法设计理论。在这项工作中,论文提出了一个用于深度公平聚类的互信息理论来填补这一空白,并相应地设计了一种新的算法,称为FCMI。简而言之,通过同时最大化和最小化互信息,FCMI被设计来实现深度公平聚类所高度期望的四个目标,即“紧致、平衡和公平的聚类,以及信息丰富的特征”。除了对理论和算法的贡献外,这项工作的另一个重要贡献是提出了一种基于信息论的新型公平聚类测度。与现有的评价指标不同,论文的指标将聚类质量和公平性作为一个整体来衡量,而不是单独衡量其一。为了验证所提出的FCMI的有效性,论文在六个数据集上进行了实验,包括一个单细胞RNA-seq图谱,并在五个指标上与11个当时最优的方法进行了比较。
创新:论文从数学上定义了深度公平聚类的四个重要性质——紧致、平衡和公平聚类,及信息丰富的特征,证明了公平性可形式化为最小化敏感性和聚类指派间的互信息,紧凑性及平衡性可可形式化为最大化给定敏感性条件下输入与聚类指派间的互信息,信息丰富的特征可通过最大化输入与其后验近似间的互信息实现。除上述理论和算法创新外,论文还对公平聚类算法的性能衡量做出了贡献。简要地,几乎所有现有的方法都是分开评估聚类质量和公平性,难以从整体角度对公平聚类质量进行衡量。因此,论文基于信息论设计了一种新的评价指标,可同时衡量聚类质量和公平性。
方法:本文基于互信息理论的深度公平聚类框架,如图1所示,来实现公平聚类的四个目标,即紧致、平衡和公平的聚类,以及信息丰富的特征。具体来讲,论文同时最大最小化化互信息,即
![]()
其中α是一个超参数。可推导出
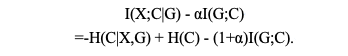
其中 -H(C|X,G) 将每个样本推到其相应的聚类中心,并远离其他样本,即鼓励模型产生紧致的聚类。H(C) 惩罚过大或过小的类,以避免由于过分强调公平性而导致的平凡解,从而产生平衡的聚类。I(G;C) 鼓励聚类结果对敏感属性是独立的,从而产生公平的聚类。除此以外,论文还通过最大化I(X|X’)提取信息丰富的特征。

图1. FCMI概述。简而言之,FCMI通过最大化互信息 I(X|X’) 实现为一个自动编码器。为了在隐空间中学习紧致和平衡的聚类,论文最大化条件互信息 I(C;X|G) 。同时,论文最小化互信息 I(G;C) 使聚类对敏感属性具有鲁棒性。
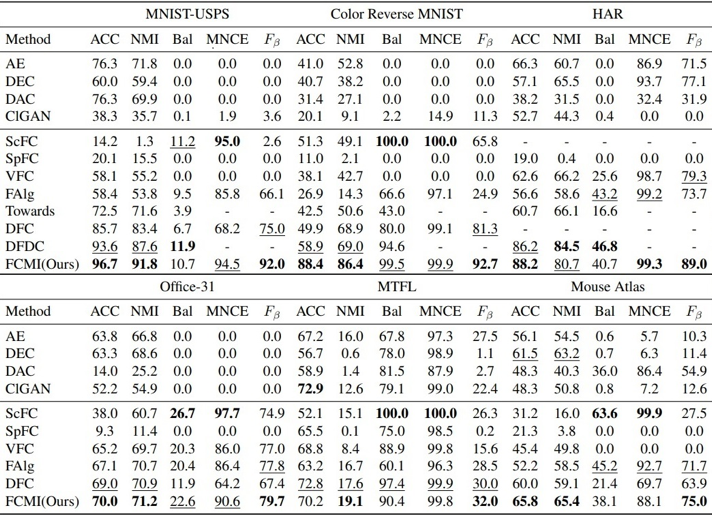
结果:为了验证所提出的FCMI的有效性,论文在六个数据集上进行了实验,其中包括单细胞RNA-seq图谱,并在五个指标上与11个最先进的方法进行了比较。部分结果如图1所示。
表1 FCMI与标准聚类方法和公平聚类方法在六个数据集上的比较。最好的和次好的结果分别用粗体和下划线标记。
05
Adaptive Plasticity Improvement for Continual Learning
作者:梁宴硕,李武军
单位: 计算机软件新技术国家重点实验室,南京大学计算机科学与技术系
邮箱:
liangys@smail.nju.edu.cn,
liwujun@nju.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Liang_Adaptive_Plasticity_Improvement_for_Continual_Learning_CVPR_2023_paper.pdf
代码:
https://github.com/liangyanshuo/Adaptive-Plasticity-Improvement-for-Continual-Learning
研究概述:持续性学习希望模型能够先后在多个任务上进行学习,并在所有的任务上取得好的表现效果。许多现有的研究尝试解决持续性学习中的灾难性遗忘问题,即如何让模型克服对于旧任务的遗忘,从而保证自身的稳定性。然而,追求在旧任务上的不遗忘可能会削弱模型改变自身以适应新任务的能力,即损害模型对新任务的可塑性。尽管有些方法提出了稳定性和可塑性的权衡方法,但没有方法考虑评估模型的可塑性并在需要时自适应地改进模型对新任务的可塑性。在这项工作中,我们提出了一种新的方法,称为自适应可塑性改进(adaptive plasticity improvement简称API),用于持续性学习。除了能够克服旧任务上的遗忘,我们的方法还试图评估并自适应地提高模型的可塑性。
方法介绍:我们的方法API如下图1所示,蓝色部分是模型的原结构,红色部分是为了改进模型的可塑性而做的扩张。对于每个新任务,API首先在克服遗忘时使用当前参数来评估模型的可塑性。然后,根据评估结果,API自适应地扩张每一层的参数以提高模型的可塑性。最后,API在克服的遗忘的同时学习新任务。

图1 自适应可塑性改进(API)
我们的方法采用了梯度修正策略来保证模型的稳定性。基于这一策略的方法会修正新任务的梯度,以确保它不会干扰模型在旧任务上的性能(见图2)。现有的梯度修正方法通常会维护一个大小不断增加的记忆以保存旧任务的梯度信息。和这些方法不一样,我们提出了对偶梯度投影记忆(dual gradient projection memory简称DualGPM)来保证模型的稳定性,并使得模型维护的记忆先增加后减少。具体来说,当旧任务的梯度空间的维度小于其补空间维度时,DualGPM仅维护旧任务的梯度空间的一组标准正交基。反之,DualGPM仅维护补空间的一组标准正交基。借助于维护的标准正交基,我们的方法按照图2所示的方式,移除新任务的梯度和旧任务梯度重叠的部分,从而保证模型的稳定性。
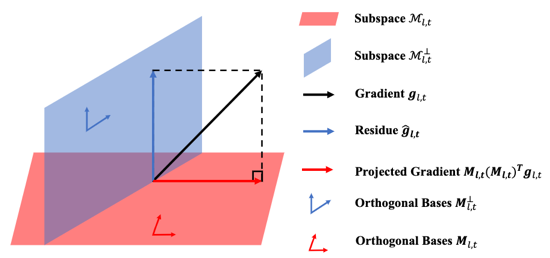
图2 基于梯度投影的梯度修正方法
此外,基于对偶梯度投影记忆,我们按照如下公式定义了一个新的度量,称为梯度保留比,用于评估并改善模型的可塑性。其中||(\hat(gl,x))x||2代表修正后的新任务梯度||(gl,x)x||2,代表修正前的新任务梯度。这个公式希望通过衡量修正后梯度的保留比例来衡量模型的可塑性。基于该公式,API自适应地扩张每一层的参数以改进模型的可塑性。具体地,对于GRR较小的层,API扩张更多的参数。对于较大的层,API扩张更少的参数甚至不扩张参数。
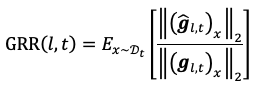
实验结果:我们在多个常用的持续性学习数据集上进行了测试。结果如下表所示,可以看出,我们的API优于所有的baseline。此外,我们对比了我们的方法和其他基于梯度修正的方法的记忆大小,结果展示在图3中。可以看出,基线方法的记忆大小随着任务的数量增加或者不减少。相反,借助于我们的DualGPM,我们的方法可以让维护的记忆先增加后减少。

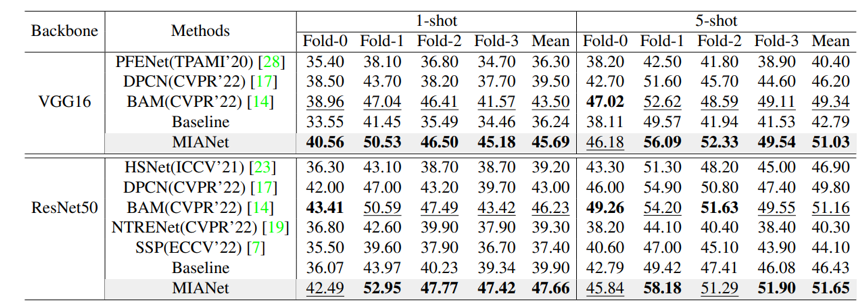
图3 不同方法的记忆大小对比
06
Camouflaged Instance Segmentation via Explicit De-camouflaging
基于显式去除伪装的伪装实例分割方法
作者:罗乃淞,潘裕文,孙锐,张天柱,熊志伟,吴枫
单位:
中国科学技术大学,合肥综合性国家科学中心人工智能研究院,深空探测实验室
邮箱:
lns6@mail.ustc.edu.cn,
panyw@mail.ustc.edu.cn,
issunrui@mail.ustc.edu.cn,
tzzhang@ustc.edu.cn,
zwxiong@ustc.edu.cn,
fengwu@ustc.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2023/papers/Luo_Camouflaged_Instance_Segmentation_via_Explicit_De-Camouflaging_CVPR_2023_paper.pdf
代码:
https://github.com/USTCL/DCNet
研究背景
在生物学领域,“伪装”被定义为动物为了达到隐蔽和避免被捕食者猎杀的目的,使自己的身体外观(如颜色和图案)与周围环境相匹配的一种策略,伪装实例分割任务(CIS)旨在识别伪装对象的位置并预测其实例级掩码。伪装对象与背景缺乏明显的对比,这使得一般的实例分割方法在此任务中效果不佳。而最近的方法一般都是基于传统的实例分割模型,它们很容易受到相似背景的干扰。因此,我们提出探索 CIS 的核心:去伪装,即消除目标对象的伪装特征。直觉上,人类首先会在像素层面反复分辨真实目标特征和伪装特征,然后汇总像素信息,从背景中分辨出整个目标实例。人类的这种视觉机制促使我们探索从像素级到实例级的渐进去伪装策略。
像素级去伪装
我们发现,傅立叶频谱振幅包含与伪装特征相符的低层次统计信息。因此,如图1,我们可以借助频域信息提取伪装特征,然后计算原始图像每个像素特征与伪装特征之间的差异,从而将伪装特征与有价值的目标信息分离开来。相位图像虽然包含语义信息,但其背景区域也存在大量像素级噪声,不利于伪装的去除。
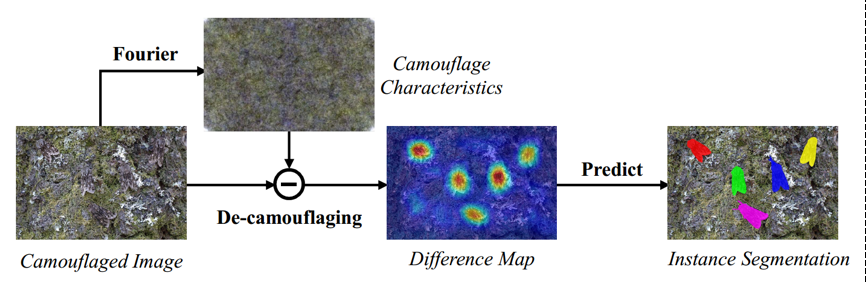
图1 利用傅立叶频谱信息实现像素级去伪装示意图
实例级去伪装
为了实现最终的实例分割,我们引入了一组实例原型,通过长距离上下文感知交互来捕捉每个伪装实例。然而,原型在交互过程中会经常吸收与对象相似度较高的欺骗性背景信息,从而无法准确发现预期目标。如图2左所示,鱼类原型与像素之间的成对相似度总是错误的。如图2右,我们选择了一些像素点作为高置信度的参考点。原型和与之匹配的像素在参考点上的相似度分布是保持一致的。
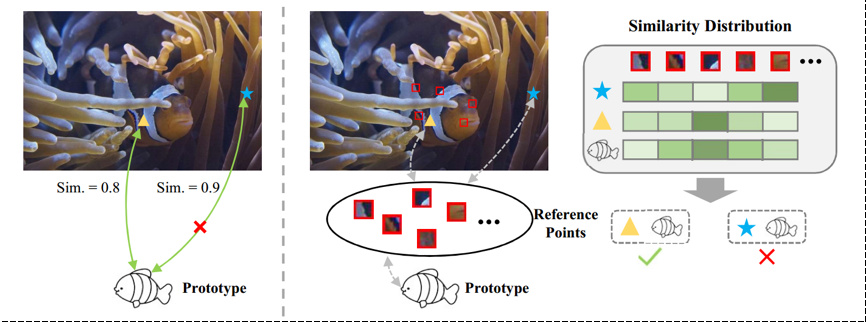
图2 利用高置信度参考点实现实例级去伪装示意图
整体框架
基于上述动机,我们建立了去伪装网络(DCNet)。如图3,DCNet主要由两个模块组成:(1)像素级伪装解耦模块,目的是根据傅立叶频谱的振幅信息提取伪装特征,并通过提出的差分注意机制消除伪装特征。(2)实例级伪装抑制模块,负责从与像素特征的交互中学习实例原型,通过参考注意力机制抑制欺骗性背景造成的错误关联。

图3 整体方法框架图
实验结果
如表1和图4所示,DCNet在COD10K 和 NC4K 数据集上的表现远远优于现有的方法。实验表明,我们的网络可以去除混淆的背景并定位出准确的突出区域,这些突出区域就是伪装实例所在的位置。并且在参考点的帮助下,原型的高响应集中在前景区域,原型很少关注背景区域。进一步证明了两个模块的有效性。
表1 在COD10K 和 NC4K 数据集上的性能比较
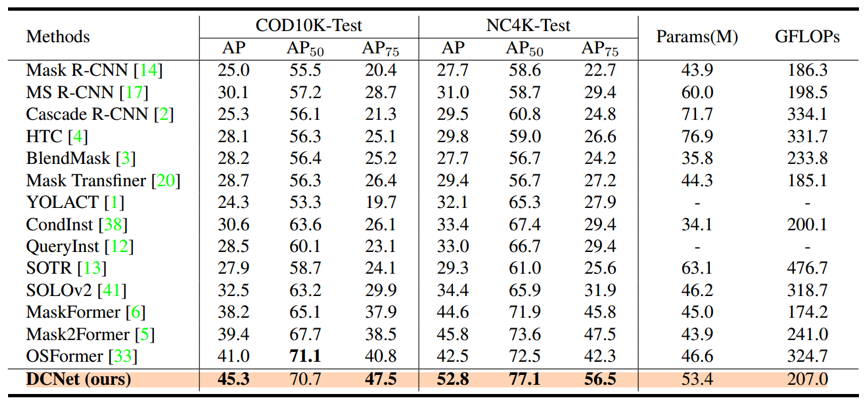

图4 与其他方法的可视化比较

 京公网安备11010802017125号
京公网安备11010802017125号